Article Directory
1 Summary
FCN network for problems simply ignore the presence of small objects, break down large objects, then the practice is usually done using the CRF processing of segmentation results to adjust. The paper presents DeconvNet, the network can be broken down into deconvolution layer and anti-pooling layer, you can solve the above problems arise FCN and complete semantic segmentation tasks. The author concludes found DeconvNet and FCN can be very compatible to the merger, the authors finally FCN and DeconvNet combine to produce better results.
2 Highlights
2.1 Decoder Structure
Decoder architecture from the deconvolution layer and a counter pooled layers.
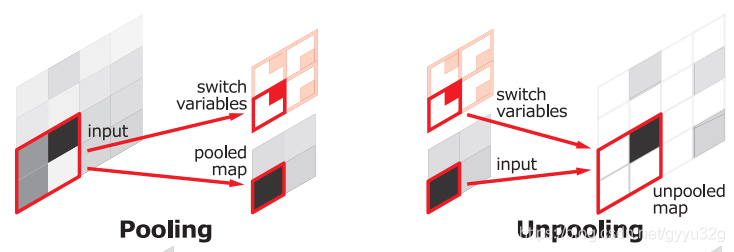
2.1.1 Anti-cell layer
Anti-cell layer is the location of the maximum pooled by recording during the preceding pooled, and then during the anti pooled utilizing small value map to fill position to a previously recorded elsewhere filled with 0s, this can largely back the picture looks like. Since only records the maximum value when the position of the pool, this can save a large amount of memory.
2.1.2 deconvolution layer
Characterized in the use of inverse image obtained pooled typically sparse (filled lot 0), this time can be reversed convolution layer becomes sparse dense feature information, the deconvolution process illustrated in Figure 17:
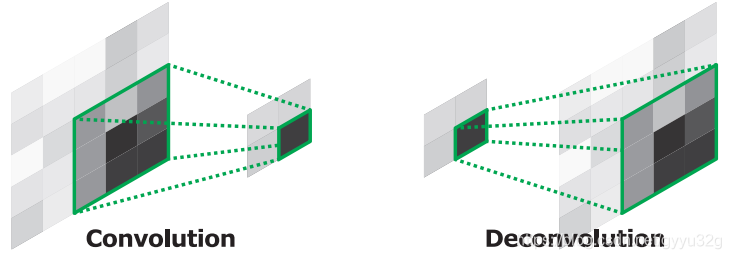
rewind the product can be characterized by a small sample on FIG reduction but the same size or larger than the FIG dense feature FIG.
2.1.3 Anti-pooling and deconvolution combination
The decoder uses anti-pooling and deconvolution binding, you can make an image by a sparse dense FIG step by step. Follows:
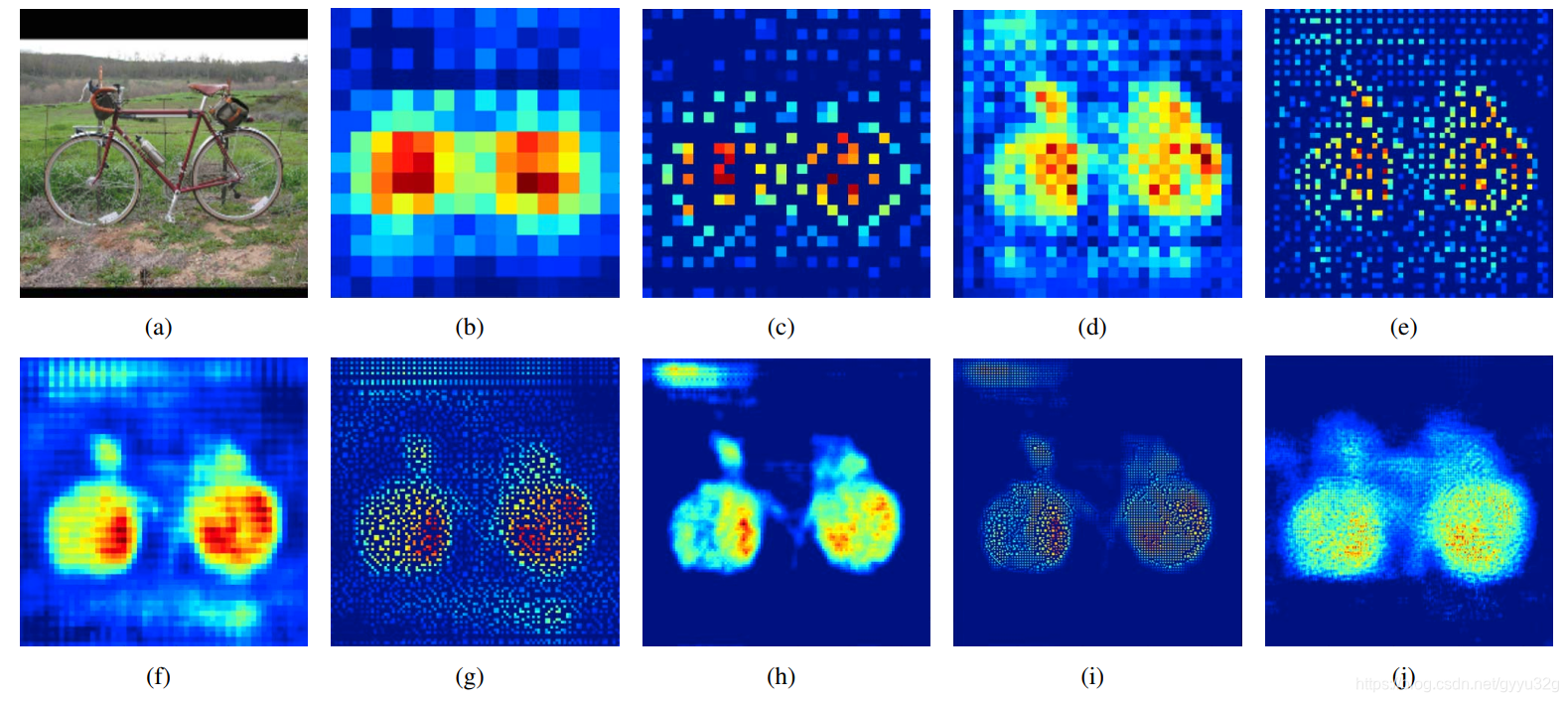
after (a) is an original image, feature extraction through the encoder obtained in (b) is an image of 14x14, obtained through a pooled on the 28x28 (c), visible (c) is very sparse. Is then obtained through deconvolution 3 (d), as used herein, deconvolution size has not changed, (d) remains 28x28; obtained through the pool of (e) 56x56, then three deconvolution to obtain (f) ; after the pooled to give (g) 112x112, then two deconvolution to give (H); after the pooled to give (i) 224x224, obtained by two deconvolution (j); visible (j) is already a FIG dense features, that is, through the layers of the pooled + deconvolution becomes so sparse dense wherein FIG.
2.2 overall network structure
The authors suggest simple to use FCN, FCN network there are two problems:
① due FCN receptive field is fixed, it is not suitable for image segmentation at different scales, if any, when the target size is too large and receptive field is not big enough, it will appear large goals down into small target of many problems, as shown below:
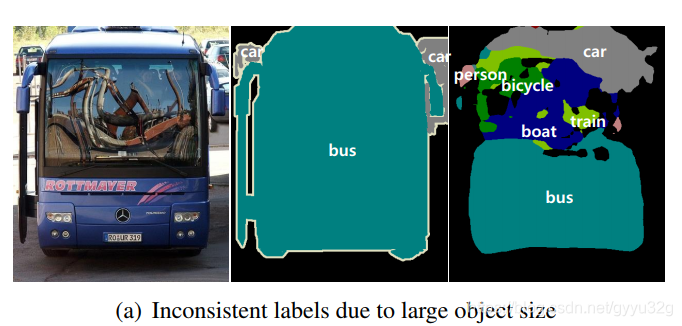
② Since the deconvolution stage decoder used too simple, although the jump structure was characterized by the integration, but there are still many details can not be recovered. If the size is too small a target as shown below, it will be ignored receptive field goal.

Therefore DeconvNet OF proposed only, while the key part is DeconvNet decoder section, the general structure shown below:
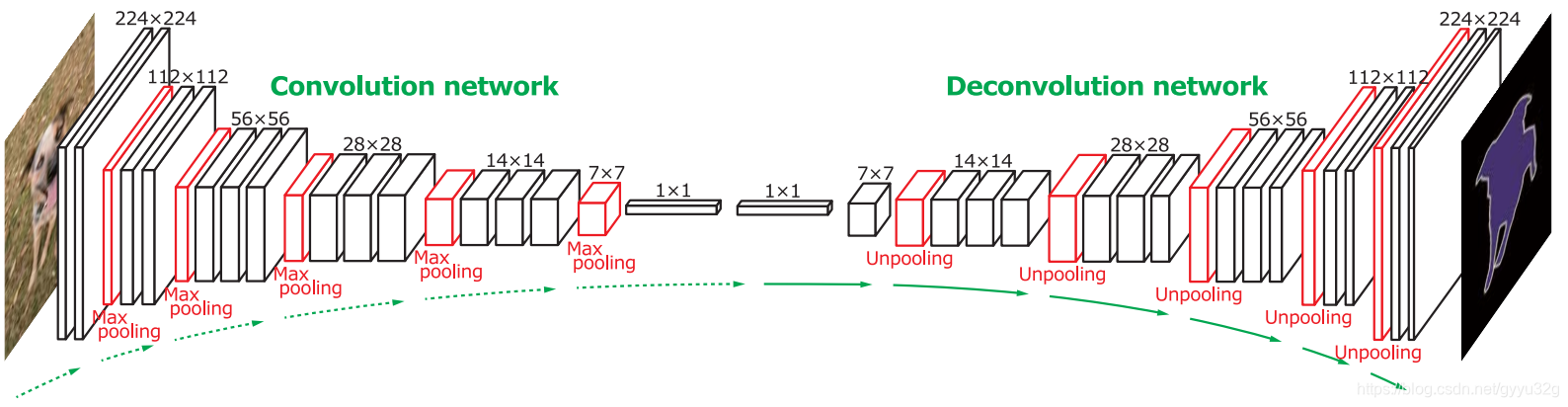
The encoder is improved VGG16 (the whole connection layer into a full convolution layer), by the decoder part is the pooling and wherein deconvolution FIG constantly on the encoder and amplifies the extracted feature dense. It can be said that the effect of extracting features encoder, the decoder functions to the feature size of an enlarged view of the small, but when the need for fine tuning an enlarged characteristic diagram that result does not look so sparse.
3 partially effective
Comparison of 3.1 FCN and DeconvNet

You can see from the chart, Deconvolution Network will be able to get a more detailed image segmentation.
Comparative effects of 3.2 each network
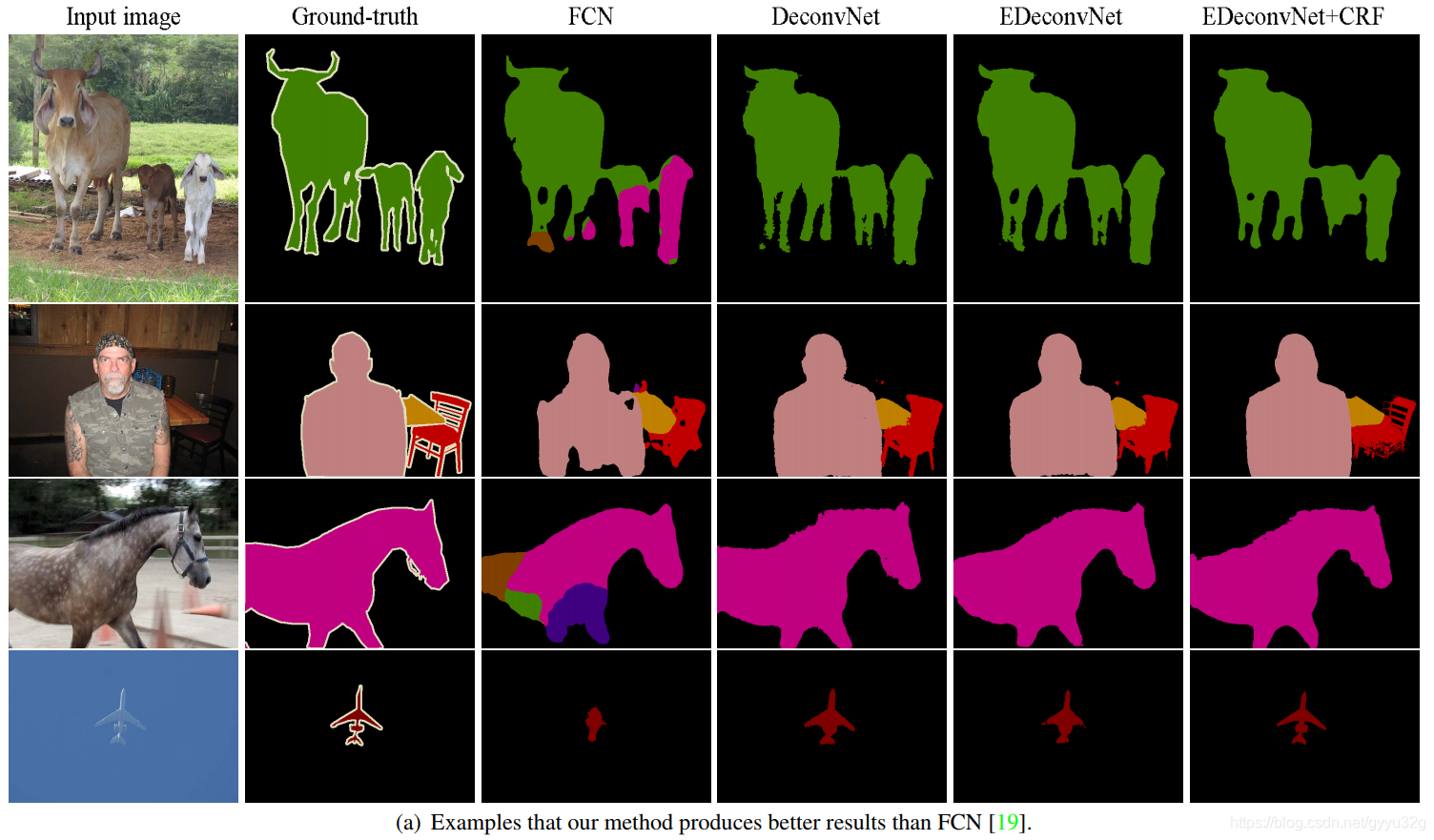
FCN, DeconvNet, EDeconvNet (FCN and DeconvNet incorporated methods), EDeconvNet + CRF (CRF done using post-processing), visible, and DeconvNet very compatible FCN, FCN method used in DeconvNet can achieve better results, if coupled with CRF do after the treatment, the better.
4 Conclusion
DeconvNet proposed a certain extent, solve some of the problems at the same receptive field FCN image segmentation brings, but, the authors found that the methods described herein and FCN and very compatible, the two can complement each other, so that higher accuracy.
5 References
(1) Learning Deconvolution Network for Semantic Segmentation
(2) paper reading notes sixteen: DeconvNet: Learning Deconvolution Network for Semantic Segmentation (ICCV2015)
