Today, we mainly to solve the following problem: a blacklist data stored in excel, because the large amount of data, duplicate data now need to find a column by pandas, processed and then stored to excel in.
pandas NumPy is a tool, the tool to solve data analysis tasks created based on two main data structures class:
DataFrame: can be understood as a table, similar to Excel tables pandas.core.frame.DataFrame
Series: It represents a single column. DataFrame contains multiple columns, ie, multiple Series, each Series has a name. pandas.core.series.Series
Data type (dtype) Pandas supported:
1. a float (float64)
2. int (Int64, UInt64)
3. BOOL
4. datetime64 [NS] (2013-01-02)
5. The datetime64 [NS, TZ]
. 6. timedelta [NS]
7. the category
8. the Object (string)
the default data type is int64, float64
The following is the original excel file

To view files in the data type of each column Series
import pandas as pd
# 更改数据类型
def change_data_type():
print(excel_df.dtypes)
if __name__ == '__main__':
excel_df = pd.read_excel('E:\zenglingwei\\test\\5.xlsx')
change_data_type()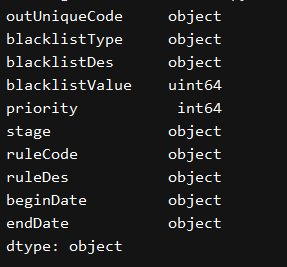
We found blacklistValue default is int type, but we know the identity card 18, when stored behind several excel again becomes 0, so we need to convert data types of these columns. There are two ideas, one is reading conversion excel, another reading after conversion.
First, read of all converted to a string, dtype = 'object' or dtype = 'str'
import pandas as pd
# 更改数据类型
def change_data_type():
print(excel_df.dtypes)
if __name__ == '__main__':
excel_df = pd.read_excel('E:\zenglingwei\\test\\5.xlsx',dtype='object') # dtype='str'
change_data_type()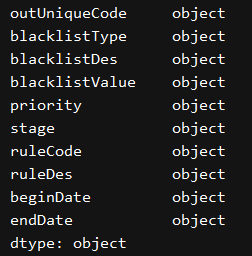
Second, the designated column is converted to a string, object or reading str
# 更改数据类型
def change_data_type():
print(excel_df.dtypes)
if __name__ == '__main__':
excel_df = pd.read_excel('E:\zenglingwei\\test\\5.xlsx',dtype = {'blacklistValue' : object,'priority':str}) # dtype='str'
change_data_type()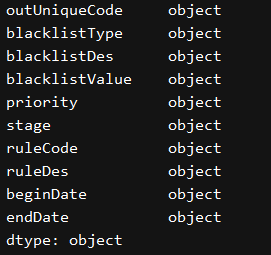
Third, after the reading is converted to a string: astype (str), not using astype (object) -> to excel when stored or int.
import pandas as pd
# 更改数据类型
def change_data_type():
excel_df[['blacklistValue','priority']] = excel_df[['blacklistValue','priority']].astype(str)
print(excel_df.dtypes)
excel_df.to_excel('excel_to_python.xls',sheet_name='sheet', index=False)
if __name__ == '__main__':
excel_df = pd.read_excel('E:\zenglingwei\\test\\5.xlsx') # dtype='str'
change_data_type()
