Los requisitos de este experimento son bastante claros (en comparación con el semestre anterior). Este blog está implementado en python, se usa la biblioteca de computación científica numpyy se usa el dibujo matplotlib.pyplot. Para simplificar, importe lo siguiente al comienzo del archivo:
import numpy as np
import matplotlib.pyplot as plt
Las funciones numpy utilizadas en este experimento
Generalmente numpyabreviado como np(importar numpy como np). La siguiente es una breve introducción a las funciones numpy utilizadas en el experimento. El siguiente código debe agregarse en la parte superior import numpy as np.
np.matriz
Esta función devuelve un numpy.ndarrayobjeto, que puede entenderse como una matriz multidimensional (en este experimento, solo se usará unidimensional (puede considerarse como un vector de columna) y bidimensional (matriz). Use minúsculas x debajo de \pmb xXx es un vector columna,AAA representa una matriz. A.TsignificaAATranspuesta de A. Las operaciones en paresndarrayson generalmente por elementos.
>>> x = np.array([1,2,3])
>>> x
array([1, 2, 3])
>>> A = np.array([[2,3,4],[5,6,7]])
>>> A
array([[2, 3, 4],
[5, 6, 7]])
>>> A.T # 转置
array([[2, 5],
[3, 6],
[4, 7]])
>>> A + 1
array([[3, 4, 5],
[6, 7, 8]])
>>> A * 2
array([[ 4, 6, 8],
[10, 12, 14]])
np.aleatorio
np.randomEl módulo contiene varias funciones para generar números aleatorios. En este experimento, se utilizan parámetros de inicialización aleatorios (método de descenso de gradiente) para agregar ruido a los datos.
>>> np.random.rand(3, 3) # 生成3 * 3 随机矩阵,每个元素服从[0,1)均匀分布
array([[8.18713933e-01, 5.46592778e-01, 1.36380542e-01],
[9.85514865e-01, 7.07323389e-01, 2.51858374e-04],
[3.14683662e-01, 4.74980699e-02, 4.39658301e-01]])
>>> np.random.rand(1) # 生成单个随机数
array([0.70944563])
>>> np.random.rand(5) # 长为5的一维随机数组
array([0.03911319, 0.67572368, 0.98884287, 0.12501456, 0.39870096])
>>> np.random.randn(3, 3) # 同上,但每个元素服从N(0, 1)(标准正态)
función matemática
Solo usado en este experimento np.sin. Estas funciones matemáticas np.ndarrayoperan por elementos:
>>> x = np.array([0, 3.1415, 3.1415 / 2]) # 0, pi, pi / 2
>>> np.round(np.sin(x)) # 先求sin再四舍五入: 0, 0, 1
array([0., 0., 1.])
Además, hay np.logfunciones similares np.expa la biblioteca de python math(solo para operaciones de elementos en matrices multidimensionales).
np.punto
Devuelve el producto de dos matrices. Consistente con la multiplicación de matrices en álgebra lineal. Se requiere que las columnas de la primera matriz sean iguales al número de filas de la segunda matriz. En particular, cuando uno de ellos es un arreglo unidimensional, la forma se adapta automáticamente a n × 1 n\times1norte×1 o1 × n .1\veces n.1×norte _
>>> x = np.array([1,2,3]) # 一维数组
>>> A = np.array([[1,1,1],[2,2,2],[3,3,3]]) # 3 * 3矩阵
>>> np.dot(x,A)
array([14, 14, 14])
>>> np.dot(A,x)
array([ 6, 12, 18])
>>> x_2D = np.array([[1,2,3]]) # 这是一个二维数组(1 * 3矩阵)
>>> np.dot(x_2D, A) # 可以运算
array([[14, 14, 14]])
>>> np.dot(A, x_2D) # 行列不匹配
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<__array_function__ internals>", line 5, in dot
ValueError: shapes (3,3) and (1,3) not aligned: 3 (dim 1) != 1 (dim 0)
np.ojo
np.eye(n)Devuelve una matriz unitaria de orden n.
>>> A = np.eye(3)
>>> A
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
Correlación de álgebra lineal
np.linalges una biblioteca relacionada con el álgebra lineal.
>>> A
array([[1, 0, 0],
[0, 2, 0],
[0, 0, 3]])
>>> np.linalg.inv(A) # 求逆(本实验不考虑逆不存在)
array([[1. , 0. , 0. ],
[0. , 0.5 , 0. ],
[0. , 0. , 0.33333333]])
>>> x = np.array([1,2,3])
>>> np.linalg.norm(x) # 返回向量x的模长(平方求和开根号)
3.7416573867739413
>>> np.linalg.eigvals(A) # A的特征值
array([1., 2., 3.])
Generar datos
Generar los datos requiere agregar ruido (error). El ejemplo dado en clase es la función seno, también usamos la función seno estándar y = sin x . y=\sin x.y=pecadox ( después de agregar ruido, esy = sin x + ϵ , y=\sin x+\epsilon,y=pecadoX+ϵ , conϵ ∼ N ( 0 , σ 2 ) \epsilon\sim N(0, \sigma^2)ϵ∼norte ( 0 ,pags2 ), ya quesin x \sin xpecadoEl valor máximo de x es 1 11 , establecemos la varianza del error para que sea menor, aquí se establece en1 25 \frac{1}{25}251).
'''
返回数据集,形如[[x_1, y_1], [x_2, y_2], ..., [x_N, y_N]]
保证 bound[0] <= x_i < bound[1].
- N 数据集大小, 默认为 100
- bound 产生数据横坐标的上下界, 应满足 bound[0] < bound[1], 默认为(0, 10)
'''
def get_dataset(N = 100, bound = (0, 10)):
l, r = bound
# np.random.rand 产生[0, 1)的均匀分布,再根据l, r缩放平移
# 这里sort是为了画图时不会乱,可以去掉sorted试一试
x = sorted(np.random.rand(N) * (r - l) + l)
# np.random.randn 产生N(0,1),除以5会变为N(0, 1 / 25)
y = np.sin(x) + np.random.randn(N) / 5
return np.array([x,y]).T
El conjunto de datos resultante tiene un punto en un plano por fila. Los datos resultantes se ven así:
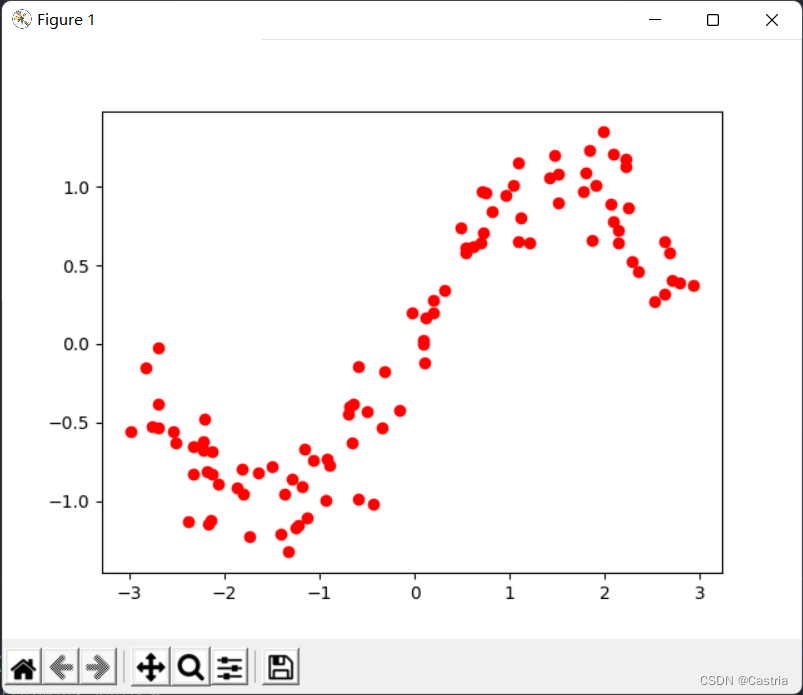
vagamente en la forma de una función seno. El código que produce la imagen de arriba es el siguiente:
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
plt.show()
Ajuste de mínimos cuadrados
A continuación, utilizamos cuatro métodos (mínimos cuadrados, término regular/regresión de cresta, descenso de gradiente, gradiente conjugado) para ajustar las sinusoides perturbadas anteriores con polinomios.
Derivación de soluciones analíticas
Simplemente recuerda el principio del método de los mínimos cuadrados: ahora queremos usar un mmPolinomio f ( x ) de grado m
= w 0 + w 1 x + w 2 x 2 + . . . + wmxmf(x)=w_0+w_1x+w_2x^2+...+w_mx^mf ( x )=en0+en1X+en2X2+...+enmXm
para aproximar la función verdaderay = sin x .y=\sin x.y=pecadox Nuestro objetivo es minimizar los conjuntos de datos ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) (x_1,y_1),(x_2,y_2),. . .,(x_N,y_N)( X1,y1) ,( X2,y2) ,... ,( Xnorte,ynorte) sobre la pérdidaLLL (pérdida), donde la función de pérdida toma el error al cuadrado:
L = ∑ i = 1 N [ yi − f ( xi ) ] 2 L=\sum\limits_{i=1}^N[y_i-f(x_i) ]^ 2L=yo = 1∑norte[yyo−f ( xyo) ]2
Para encontrar los parámetrosw 0 , w 1 , . . . , wm , w_0,w_1,...,w_m,en0,en1,... ,enm, necesitamos encontrar la pérdidaLLL relacionado con w 0 , w 1 , . . . , wm w_0, w_1,...,w_men0,en1,... ,enmderivado de . Por conveniencia, usamos la notación de álgebra lineal:
X = ( 1 x 1 x 1 2 ⋯ x 1 m 1 x 2 x 2 2 ⋯ x 2 m ⋮ ⋮ 1 x N x N 2 ⋯ x N m ) N × ( m + 1 ) , Y = ( y 1 y 2 ⋮ y norte ) norte × 1 , W = ( w 0 w 1 ⋮ wm ) ( metro + 1 ) × 1 . X=\begin{pmatrix}1 & x_1 & x_1 ^2 & \cdots & x_1^m\\ 1 & x_2 & x_2^2 & \cdots & x_2^m\\ \vdots & & & &\vdots\\ 1 & x_N & x_N^2 & \cdots & x_N^ m\ \\end{pmatrix}_{N\times(m+1)},Y=\begin{pmatrix}y_1 \\ y_2 \\ \vdots \\y_N\end{pmatrix}_{N\times1}, W= \begin{pmatrix}w_0 \\ w_1 \\ \vdots \\w_m\end{pmatrix}_{(m+1)\times1}.X=⎝
⎛11⋮1X1X2XnorteX12X22Xnorte2⋯⋯⋯X1mX2m⋮Xnortem⎠
⎞N × ( metro + 1 ),Y=⎝
⎛y1y2⋮ynorte⎠
⎞norte × 1,En=⎝
⎛en0en1⋮enm⎠
⎞( metro + 1 ) × 1
Bajo esta representación, (
f ( x 1 ) f ( x 2 ) ⋮ f ( x N ) ) = XW . \begin{pmatrix}f(x_1)\\ f(x_2) \\ \vdots \ \ f(x_N )\end{pmatriz}= XW.⎝
⎛f ( x1)f ( x2)⋮f ( xnorte)⎠
⎞=X W.
Si tienes dudas, puedes comprobarlo tú mismo con la multiplicación de matrices . Continuando, la suma de los términos de error se puede expresar como
( f ( x 1 ) − y 1 f ( x 2 ) − y 2 ⋮ f ( x N ) − y N ) = XW − Y . \begin{pmatrix}f (x_1) -y_1 \\ f(x_2)-y_2 \\ \vdots \\ f(x_N)-y_N\end{pmatrix}=XW-Y.⎝
⎛f ( x1)−y1f ( x2)−y2⋮f ( xnorte)−ynorte⎠
⎞=X W−Y. Por lo
tanto, la función de pérdida
L = ( XW − Y ) T ( XW − Y ) . L=(XW-Y)^T(XW-Y).L=( XA _−Y)T (XAN−Y ) .
(Para encontrar el vectorx = ( x 1 , x 2 , . . . , x N ) T \pmb x=(x_1,x_2,...,x_N)^TXX=( X1,X2,... ,Xnorte)La suma de los cuadrados de las componentes de T , que se puede usar para x \pmb xXx es el producto interno, es decir,x T x .\pmb x^T \pmb x.XXTXx . )
para obtener laLLL más pequeñoWWW (esteWWW es unvector columna), necesitamosEncuentre la derivada parcial de L y sea 0 : 0:0:
∂ L ∂ W = ∂ ∂ W [ ( XW − Y ) T ( XW − Y ) ] = ∂ ∂ W [ ( WTXT − YT ) ( XW − Y ) ] = ∂ ∂ W ( WTXTXW − WTXTY − YTXW + YTY ) = ∂ ∂ W ( WTXTXW − 2 YTXW + YTY ) ( 容易验证 , WTXTY = YTXW , 因而可以将其合并 ) = 2 XTXW − 2 XTY \begin{alineado}\frac{\parcial L}{\parcial W} &=\frac{\parcial}{\parcial W}[(XW-Y)^T(XW-Y)]\\ &=\frac{\parcial}{\parcial W}[(W^TX^TY^ T)(XW-Y)] \\ &=\frac{\parcial}{\parcial W}(W^TX^TXW-W^TX^TY-Y^TXW+Y^TY)\\ &=\frac {\parcial}{\parcial W}(W^TX^TXW-2Y^TXW+Y^TY)\\ &=2X^ TXW-2X^TY\end{alineado}∂ W∂L _=∂ W∂[( X W−Y)T (XAN−Y)]=∂ W∂[( WTX _T−YT )(XAN−Y)]=∂ W∂( w.TX _T XAN−EnTX _TY _−YT XAN+YTY) _=∂ W∂( w.TX _T XAN−2 añosT XAN+YT Y)(fácil de verificar,EnTX _TY _=YT XW,por lo tanto se pueden combinar )=2X _T XAN−2X _TY _
Descripción:
(1) De la línea 3 a la línea 4, debido a WTXTYW^TX^TYEnTX _T Y和YTXWY^TXWYT XWson todos los números (o1 × 1 1\times11×1 matriz), los dos se transponen entre sí, por lo que los valores son los mismos y se pueden combinar en un solo elemento.
(2) Derivación de la matriz de la fila 4 a la fila 5, el primer término∂ ∂ W ( WT ( XTX ) W ) \frac{\partial}{\partial W}(W^T(X^TX)W )∂ W∂( w.T (XT X)W)se trata deWWLa forma cuadrática de W , su derivada es2XTXW .2X^TXW.2X _T XW.(
3) Para el término primario− 2 YTXW -2Y^TXW− 2 añosLa derivación de T XW, si la derivación según el campo de números reales, debería ser− 2 YTX .-2Y^TX.− 2 añosT X.Peroverifique y descubra que el tipo de matriz no es correcto, debe hacer una transposición, se convierte en− 2 XTY .-2X^TY.− 2 XT Y.
El álgebra lineal de matrices no se ha enseñado sistemáticamente en la clase, solo para explicar lo que aparece aquí. ( No lo haré si hay más )
Deje que la derivada parcial sea 0, obtenga
XTXW = YTX, X^TXW=Y^TX,XT XAN=YT X,
multiplicar por la izquierda( XTX ) − 1 (X^TX)^{-1}( XTX )_− 1 (XTXX^TX)XConsulte la nota complementaria a continuación para conocer la reversibilidad de T X
W = ( XTX ) − 1 XTY . W=(X^TX)^{-1}X^TY.En=( XTX )_− 1 XT Y.
Este es elWWqueremosPara la solución analítica de W , solo necesitamos llamar a la función para calcular este valor.
'''
最小二乘求出解析解, m 为多项式次数
最小二乘误差为 (XW - Y)^T*(XW - Y)
- dataset 数据集
- m 多项式次数, 默认为 5
'''
def fit(dataset, m = 5):
X = np.array([dataset[:, 0] ** i for i in range(m + 1)]).T
Y = dataset[:, 1]
return np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), Y)
Explique un poco el código: la primera línea genera el XX acordado anteriormenteLa matriz Xdataset[:,0] , que es la columna 0 del conjunto de datos( x 1 , x 2 , . . . , x N ) T (x_1,x_2,...,x_N)^T( X1,X2,... ,Xnorte)T ; la segunda línea esYYMatriz Y ; la tercera fila devuelve la solución analítica anterior. (Si no está familiarizado con la sintaxis onumpylas bibliotecas de Python, es bastante hostil)
Simplemente verificamos el resultado de la función que hemos completado: Para ello, primero escribimos una drawfunción para convertir el WW obtenidoEl polinomiof ( x ) f(x) correspondiente a WDibuja f ( x )pyplot en la imagen de la biblioteca:
'''
绘制给定系数W的, 在数据集上的多项式函数图像
- dataset 数据集
- w 通过上面四种方法求得的系数
- color 绘制颜色, 默认为 red
- label 图像的标签
'''
def draw(dataset, w, color = 'red', label = ''):
X = np.array([dataset[:, 0] ** i for i in range(len(w))]).T
Y = np.dot(X, w)
plt.plot(dataset[:, 0], Y, c = color, label = label)
Entonces la función principal:
if __name__ == '__main__':
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
# 最小二乘
coef1 = fit(dataset)
draw(dataset, coef1, color = 'black', label = 'OLS')
# 绘制图像
plt.legend()
plt.show()
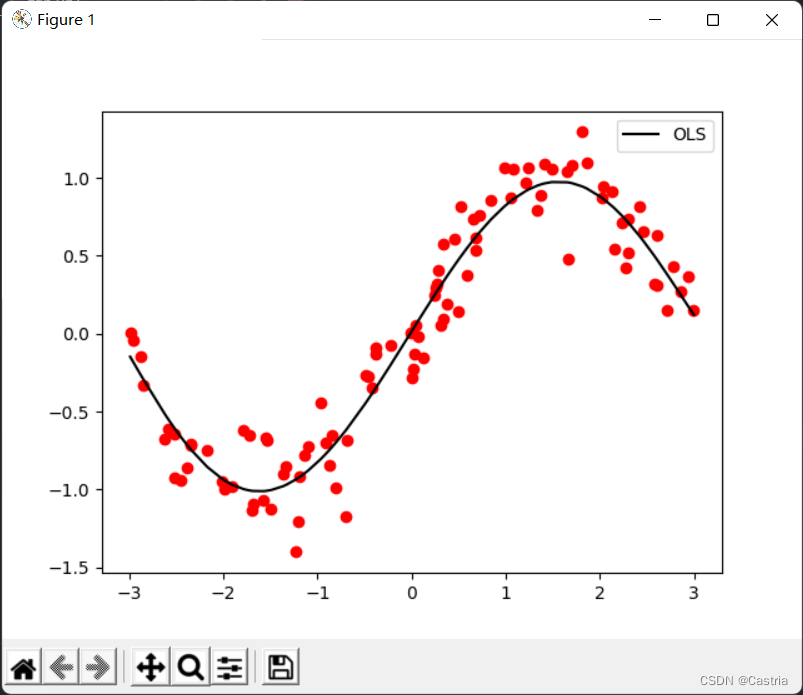
Se puede ver que el efecto del ajuste polinomial de quinto grado es bastante bueno (el conjunto de datos se genera aleatoriamente cada vez, por lo que es diferente de la primera imagen).
A partir de todo el código de esta parte, ya no se describen las siguientes funciones del mismo nombre:
import numpy as np
import matplotlib.pyplot as plt
'''
返回数据集,形如[[x_1, y_1], [x_2, y_2], ..., [x_N, y_N]]
保证 bound[0] <= x_i < bound[1].
- N 数据集大小, 默认为 100
- bound 产生数据横坐标的上下界, 应满足 bound[0] < bound[1]
'''
def get_dataset(N = 100, bound = (0, 10)):
l, r = bound
x = sorted(np.random.rand(N) * (r - l) + l)
y = np.sin(x) + np.random.randn(N) / 5
return np.array([x,y]).T
'''
最小二乘求出解析解, m 为多项式次数
最小二乘误差为 (XW - Y)^T*(XW - Y)
- dataset 数据集
- m 多项式次数, 默认为 5
'''
def fit(dataset, m = 5):
X = np.array([dataset[:, 0] ** i for i in range(m + 1)]).T
Y = dataset[:, 1]
return np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), Y)
'''
绘制给定系数W的, 在数据集上的多项式函数图像
- dataset 数据集
- w 通过上面四种方法求得的系数
- color 绘制颜色, 默认为 red
- label 图像的标签
'''
def draw(dataset, w, color = 'red', label = ''):
X = np.array([dataset[:, 0] ** i for i in range(len(w))]).T
Y = np.dot(X, w)
plt.plot(dataset[:, 0], Y, c = color, label = label)
if __name__ == '__main__':
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
coef1 = fit(dataset)
draw(dataset, coef1, color = 'black', label = 'OLS')
plt.legend()
plt.show()
Instrucciones complementarias
Hay una pieza menos rigurosa arriba: para una matriz XXPara X ,XTXX^TXXTX no es necesariamente reversible. En este experimento, sin embargo, se puede demostrar que es una matriz invertible. Dado que esta clase no es una clase de álgebra lineal, no dedicaremos demasiado espacio a esto, solo un breve recordatorio:
(1)XXX es unN × ( m + 1 ) N\times(m+1)norte×( metro+1 ) de la matriz. donde el número de datos esNNN es mucho mayor que el polinomio gradommm , hayN > m + 1, N > m+1;norte>metro+1 ;
(2) Para ilustrarXTXX^TXXT Xes invertible, necesito explicar( XTX ) ( m + 1 ) × ( m + 1 ) (X^TX)_{(m+1)\times(m+1)}( XTX )_( metro + 1 ) × ( metro + 1 )Rango completo, es decir, R ( XTX ) = m + 1 , R(X^TX)=m+1;R ( XTX )_=metro+1 ;
(3) En álgebra lineal, hemos probado queR ( X ) = R ( XT ) = R ( XTX ) = R ( XXT ) ; R(X)=R(X^T)=R(X^TX )=R(XX^T);R ( X )=R ( Xt )=R ( XTX )_=R ( X Xt );
(4)XXX es unamatriz de Vandermondecuyo rango es igual amin { N , m + 1 } = m + 1. min\{N,m+1\}=m+1.mi {
n ,metro+1 }=metro+1.
Agregar término de regularización (regresión de cresta)
El método de mínimos cuadrados es propenso al sobreajuste. Para ilustrar este defecto, usamos los primeros 50 puntos del conjunto de datos generado para el entrenamiento (para que el muestreo no sea lo suficientemente uniforme, aquí es solo para ilustrar el sobreajuste), obtenemos los parámetros y luego dibujamos la imagen de la función completa para comprobar el efecto de ajuste:
if __name__ == '__main__':
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
# 取前50个点进行训练
coef1 = fit(dataset[:50], m = 3)
# 再画出整个数据集上的图像
draw(dataset, coef1, color = 'black', label = 'OLS')
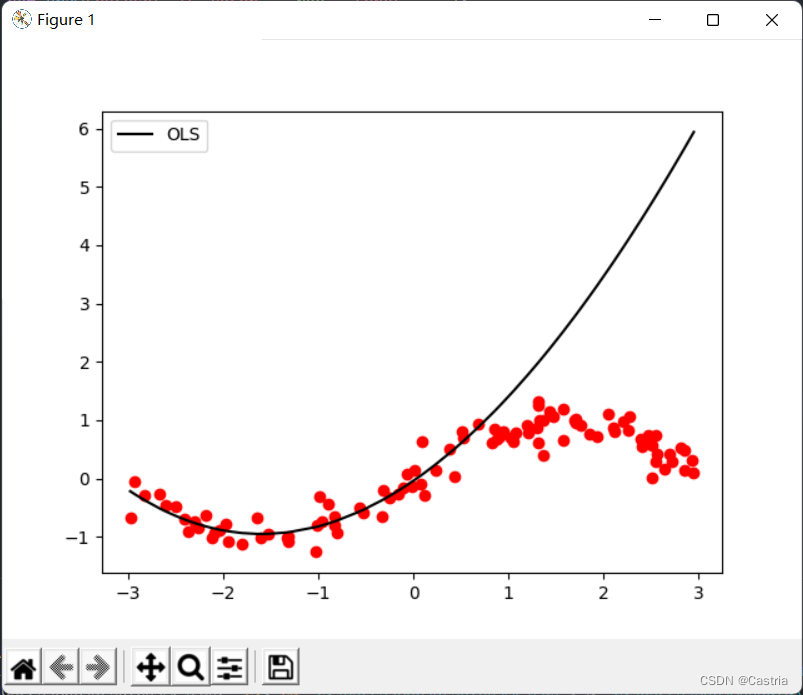
Sobreajuste en mmEsto es especialmente grave cuando m es grande ( m = 3 m = 3metro=3 en punto). A medida que aumenta el grado del polinomio, para estar lo más cerca posible del conjunto de datos dado, la magnitud de los coeficientes calculados será cada vez mayor y el rendimiento en muestras no vistas será peor. Como se muestra arriba, puede ver que el ajuste está en los primeros 50 puntos (aproximadamente en la abscisa[ − 3 , 0 ] [-3,0][ - 3 ,0 ] ) es muy bueno; en el equipo de prueba el rendimiento es muy pobre ([ 0 , 3 ] [0,3][ 0 ,3 ] ). Para evitar el sobreajuste, se puede introducir un término de regularización. En este momento, la función de pérdidaLLL变为
L = ( XW − Y ) T ( XW − Y ) + λ ∣ ∣ W ∣ ∣ 2 2 L=(XW-Y)^T(XW-Y)+\lambda||W||_2^2L=( XA _−Y)T (XAN−Y)+λ ∣∣ W ∣ ∣22
donde ∣ ∣ ⋅ ∣ ∣ 2 2 ||\cdot||_2^2∣∣⋅∣ ∣22Indica L 2 L_2L2El cuadrado de la norma, en este caso WTW ; λ W^TW;\lambdaEnTW; _λ es el coeficiente de regularización. Esta fórmula también se llama Regresión de Ridge. Su idea es tener en cuenta la función de pérdida y el parámetro resultanteWWMódulo de longitud de W (enL 2 L_2L2norma), previniendo WWEl parámetro en W es demasiado grande.
Por ejemplo (los números se componen aleatoriamente): cuando el coeficiente de regularización es 1 11 , si el error cuadrático del esquema 1 en el conjunto de datos es0.5, 0.5,0,5 , en este momentoW = (100, − 200, 300, 150) TW=(100,-200,300,150)^TEn=( 100 ,− 200 ,300 ,150 )T ; el error cuadrático del esquema 2 en el conjunto de datos es10, 10,10 , en este momentoW = ( 1 , − 3 , 2 , 1 ) W=(1,-3,2,1)En=( 1 ,− 3 ,2 ,1 ) , luego elegimosW.W.W. Coeficiente de regularización λ \lambdaλ caracteriza esto paraWWLa importancia de la longitud del módulo W : λ \lambdaCuanto mayor sea λ , mejor será WWCuanto mayor sea la longitud del módulo de W , mayor será la penalización. Cuandoλ = 0 , \lambda=0,yo=0 , la regresión de cresta se convierte en el método de mínimos cuadrados ordinarios. Similar a la regresión de cresta es LASSO, que reemplaza el término de regularización conL 1 L_1L1norma.
Repitiendo la derivación anterior, podemos obtener la solución analítica como
W = ( XTX + λ E m + 1 ) − 1 XTY . W=(X^TX+\lambda E_{m+1})^{-1}X^TY .En=( XTX _+λE _metro + 1)− 1 XT Y.
dondeEm + 1 E_{m+1}Ymetro + 1es m + 1 m + 1metro+Matriz unitaria de primer orden. Es fácil obtener( XTX + λ E m + 1 ) (X^TX+\lambda E_{m+1})( XTX _+λE _metro + 1) también es reversible.
Esta parte del código es la siguiente.
'''
岭回归求解析解, m 为多项式次数, l 为 lambda 即正则项系数
岭回归误差为 (XW - Y)^T*(XW - Y) + λ(W^T)*W
- dataset 数据集
- m 多项式次数, 默认为 5
- l 正则化参数 lambda, 默认为 0.5
'''
def ridge_regression(dataset, m = 5, l = 0.5):
X = np.array([dataset[:, 0] ** i for i in range(m + 1)]).T
Y = dataset[:, 1]
return np.dot(np.dot(np.linalg.inv(np.dot(X.T, X) + l * np.eye(m + 1)), X.T), Y)
La comparación de los dos métodos es la siguiente:
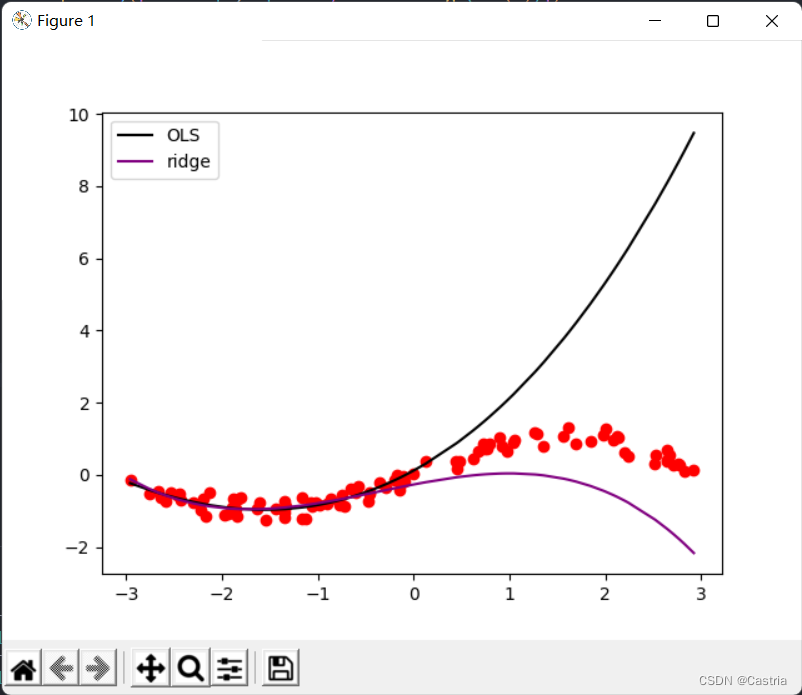
puede verse a partir de la comparación que la regresión de la cresta reduce significativamente el sobreajuste (en este momento m = 3, λ = 0,3 m=3, \lambda=0,3metro=3 ,yo=0.3 ).
Descenso de gradiente
El descenso de gradiente no es la mejor manera de resolver este problema y puede fallar fácilmente en la convergencia. Primero introduzca brevemente la idea básica del método de descenso de gradiente: si queremos encontrar la función compleja f ( x ) f(x)El valor mínimo (punto máximo) de f ( x ) (este xxx puede ser un vector, etc.), es decir,
xmin = arg min xf ( x ) x_{min}=\argmin_{x}f(x)Xminuto=Xargumentominutof ( x )
gradiente de descenso repite las siguientes operaciones:
(0) (al azar) inicializarx 0 ( t = 0 ) x_0(t=0)X0( t=0 ) ;
(1) Seaf ( x ) f(x)f ( x ) enxt x_tXtgradiente en (cuando xxCuando x es unidimensional, es la derivada)∇ f ( xt ) \nabla f(x_t)∇ f ( xt);
(2)xt + 1 = xt − η ∇ f ( xt ) x_{t+1}=x_t-\eta\nabla f(x_t)Xt + 1=Xt−η ∇ f ( xt)
(3) Sixt + 1 x_{t+1}Xt + 1con xt x_tXtSi hay poca diferencia (alcanza el rango preestablecido) o el número de iteraciones alcanza el límite superior preestablecido, detenga el algoritmo; de lo contrario, repita (1) (2).
Entre ellos η\ etaη es la tasa de aprendizaje, que determina el tamaño del paso del descenso del gradiente.
El siguiente es un método de descenso de gradiente para encontrary = x 2 y=x^2y=XEjemplo de programa para el punto mínimo de 2 :
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return x ** 2
def draw():
x = np.linspace(-3, 3)
y = f(x)
plt.plot(x, y, c = 'red')
cnt = 0
# 初始化 x
x = np.random.rand(1) * 3
learning_rate = 0.05
while True:
grad = 2 * x
# -----------作图用,非算法部分-----------
plt.scatter(x, f(x), c = 'black')
plt.text(x + 0.3, f(x) + 0.3, str(cnt))
# -------------------------------------
new_x = x - grad * learning_rate
# 判断收敛
if abs(new_x - x) < 1e-3:
break
x = new_x
cnt += 1
draw()
plt.show()
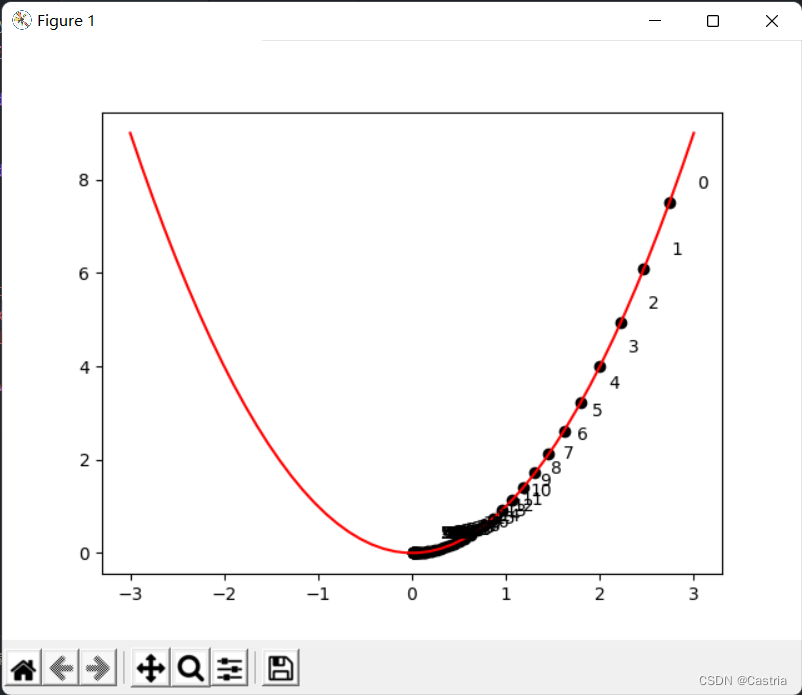
La imagen de arriba indica xxx A medida que evoluciona la iteración, puede verxxx sigue acercándose a cero a lo largo del semieje positivo. Cabe señalar que la tasa de aprendizaje no puede ser demasiado grande (aunque en el programa anterior, la tasa de aprendizaje se establece un poco pequeña), debe ajustarse manualmente, de lo contrario, es fácil de imaginar,xxx oscila de un lado a otro en los semiejes positivo y negativo, lo que dificulta la convergencia.
En mínimos cuadrados, la función que necesitamos optimizar es la función de pérdida
L = (XW − Y) T (XW − Y) L=(XW-Y)^T(XW-Y).L=( XA _−Y)T (XAN−Y ) A
continuación resolvemos el problema con gradiente descendente. En la derivación anterior,
∂ L ∂ W = 2 XTXW − 2 XTY , \begin{alineado}\frac{\parcial L}{\parcial W}=2X^TXW-2X^TY\end{alineado},∂ W∂L _=2X _T XAN−2X _TY _,
por lo que cada vez que realizamos una iteración enWWW resta este gradiente hasta el parámetroWWW converge. Sin embargo, después de los experimentos, el error cuadrático hará que el gradiente sea demasiado grande y el proceso no pueda converger. Por lo tanto, se usa el error cuadrático medio (MSE) para reemplazarlo, que consiste en dividir la fórmula original porNNnorte :
'''
梯度下降法(Gradient Descent, GD)求优化解, m 为多项式次数, max_iteration 为最大迭代次数, lr 为学习率
注: 此时拟合次数不宜太高(m <= 3), 且数据集的数据范围不能太大(这里设置为(-3, 3)), 否则很难收敛
- dataset 数据集
- m 多项式次数, 默认为 3(太高会溢出, 无法收敛)
- max_iteration 最大迭代次数, 默认为 1000
- lr 梯度下降的学习率, 默认为 0.01
'''
def GD(dataset, m = 3, max_iteration = 1000, lr = 0.01):
# 初始化参数
w = np.random.rand(m + 1)
N = len(dataset)
X = np.array([dataset[:, 0] ** i for i in range(len(w))]).T
Y = dataset[:, 1]
try:
for i in range(max_iteration):
pred_Y = np.dot(X, w)
# 均方误差(省略系数2)
grad = np.dot(X.T, pred_Y - Y) / N
w -= lr * grad
'''
为了能捕获这个溢出的 Warning,需要import warnings并在主程序中加上:
warnings.simplefilter('error')
'''
except RuntimeWarning:
print('梯度下降法溢出, 无法收敛')
return w
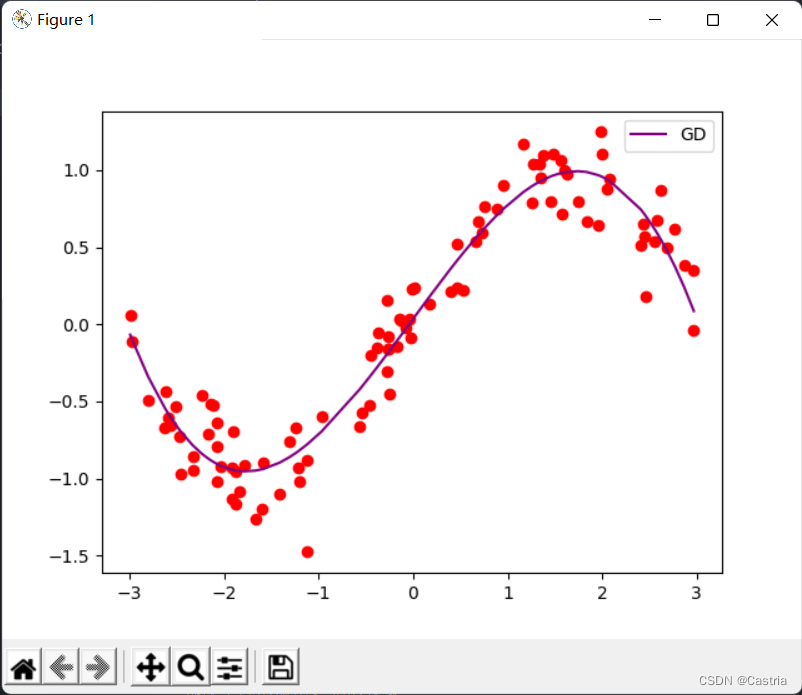
En este momento si mmSi m se establece un poco más grande (digamos 4), el gradiente se desbordará durante la iteración, haciendo que los parámetros no puedan converger. Al converger, el efecto de ajuste está bien:
método de gradiente conjugado
Los gradientes conjugados se pueden usar para resolver la forma A x = b A\pmb x=\pmb bAXX=bSistema de ecuaciones para b , o minimizar la forma cuadrática f ( x ) = 1 2 x TA x − b T x + c . f(\pmb x)=\frac12\pmb x^TA\pmb x-\pmb b^ T \pmbx+c.f (Xx )=21XXTA _XX−bbTXX+c . (Se puede demostrar que paraAAA , los dos son equivalentes) dondeAAA es unamatrizdefinida positivaEn este problema, pedimos resolver XTXW = YTX , X^TXW=Y^TX,XT XAN=YT X,
entoncesA ( m + 1 ) × ( m + 1 ) = XTX , b = YT . A_{(m+1)\times(m+1)}=X^TX,\pmb b=Y^ T .A( metro + 1 ) × ( metro + 1 )=XTX ,_bb=YT. Si queremos agregar un término regular, se convierte en la solución.
(X^TX+\lambda E)W=Y^TX.( XTX _+λ E ) W=YT X.,
déjame explicarte:XTXX^TXXTX noes necesariamente definido positivo, pero debe ser semidefinido positivo (ver). Pero en el experimento básicamente no tenemos que preocuparnos por este problema, porqueXTXX^TXXEs muy probable que TX sea definido positivo, solo agregamos una aserción al código y no prestamos mucha atención a esta condición.
La idea del método del gradiente conjugado y el proceso de prueba son relativamente largos. Puede consultaresta serie. Aquí solo se dan los pasos del algoritmo (al comienzo del tercer artículo vinculado anteriormente):
(0) Inicializar x ( 0 );x_{(0)};X( 0 );
(1) Inicializard ( 0 ) = r ( 0 ) = b − A x ( 0 ) ; d_{(0)}=r_{(0)}=b-Ax_{(0)};d( 0 )=r( 0 )=b−una x( 0 );
(2)令α ( yo ) = r ( yo ) T r ( yo ) re ( yo ) TA re ( yo ) ; \alpha_{(i)}=\frac{r_{(i)}^Tr_{(i)}}{d_{(i)}^TAd_{(i)}};a( yo )=d( yo )Tuna d( yo )r( yo )Tr( yo );
(3)迭代x ( yo + 1 ) = x ( yo ) + α ( yo ) re ( yo ) ; x_{(i+1)}=x_{(i)}+\alpha_{(i)}d_{(i)};X( yo + 1 )=X( yo )+a( yo )d( yo );
(4)令r ( yo + 1 ) = r ( yo ) − α ( yo ) UN re ( yo ) ; r_{(i+1)}=r_{(i)}-\alpha_{(i)}Ad_{(i)};r( yo + 1 )=r( yo )−a( yo )una d( yo );
(5)令β ( yo + 1 ) = r ( yo + 1 ) T r ( yo + 1 ) r ( yo ) T r ( yo ) , re ( yo + 1 ) = r ( yo + 1 ) + β ( yo + 1 ) re ( yo ) . \beta_{(i+1)}=\frac{r_{(i+1)}^Tr_{(i+1)}}{r_{(i)}^Tr_{(i)}},d_{( i+1)}=r_{(i+1)}+\beta_{(i+1)}d_{(i)}.b( yo + 1 )=r( yo )Tr( yo )r( yo + 1 )Tr( yo + 1 ),d( yo + 1 )=r( yo + 1 )+b( yo + 1 )d( yo ).
(6)当∣ ∣ r ( i ) ∣ ∣ ∣ ∣ r ( 0 ) ∣ ∣ < ϵ \frac{||r_{(i)}||}{||r_{(0)}||}<\ épsilon∣∣ r( 0 )∣∣∣∣ r( yo )∣∣<ϵ , detenga el algoritmo; de lo contrario, continúe iterando desde (2). ϵ \epsilonϵ es un pequeño valor preestablecido, tomo aquí1 0 − 5 . 10^{-5}.1 0− 5. A continuación seguimos este proceso para
implementar el código:
'''
共轭梯度法(Conjugate Gradients, CG)求优化解, m 为多项式次数
- dataset 数据集
- m 多项式次数, 默认为 5
- regularize 正则化参数, 若为 0 则不进行正则化
'''
def CG(dataset, m = 5, regularize = 0):
X = np.array([dataset[:, 0] ** i for i in range(m + 1)]).T
A = np.dot(X.T, X) + regularize * np.eye(m + 1)
assert np.all(np.linalg.eigvals(A) > 0), '矩阵不满足正定!'
b = np.dot(X.T, dataset[:, 1])
w = np.random.rand(m + 1)
epsilon = 1e-5
# 初始化参数
d = r = b - np.dot(A, w)
r0 = r
while True:
alpha = np.dot(r.T, r) / np.dot(np.dot(d, A), d)
w += alpha * d
new_r = r - alpha * np.dot(A, d)
beta = np.dot(new_r.T, new_r) / np.dot(r.T, r)
d = beta * d + new_r
r = new_r
# 基本收敛,停止迭代
if np.linalg.norm(r) / np.linalg.norm(r0) < epsilon:
break
return w
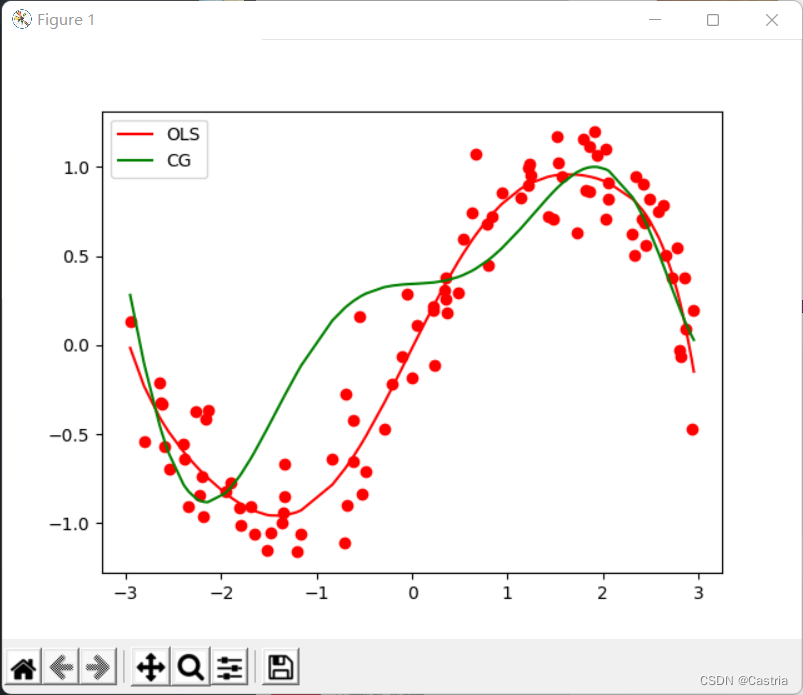
En comparación con el método de descenso de gradiente ingenuo, el método de gradiente conjugado converge de forma rápida y estable. Sin embargo, a medida que aumenta el grado del polinomio, el ajuste empeora: en m = 7 m=7metro=7 , se compara con el método de los mínimos cuadrados de la siguiente manera:
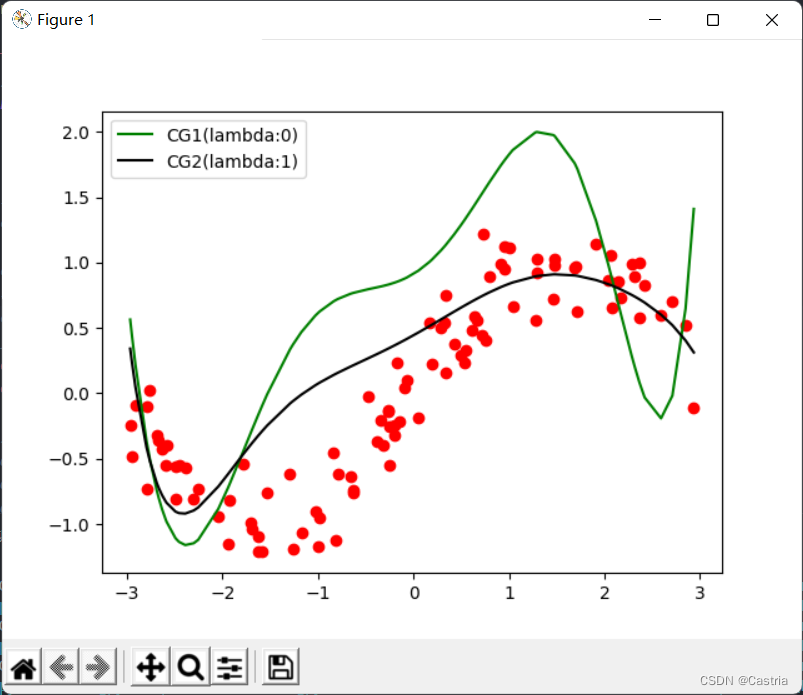
en este momento, todavía puede aliviarse parcialmente con el término regular (la cifra esm = 7 , λ = 1 m=7,\lambda=1metro=7 ,yo=1 ):
finalmente, se adjuntan las imágenes de ajuste de los cuatro métodos (básicamente lo mismo) y la función principal, y los parámetros se pueden ajustar de acuerdo con los requisitos experimentales:
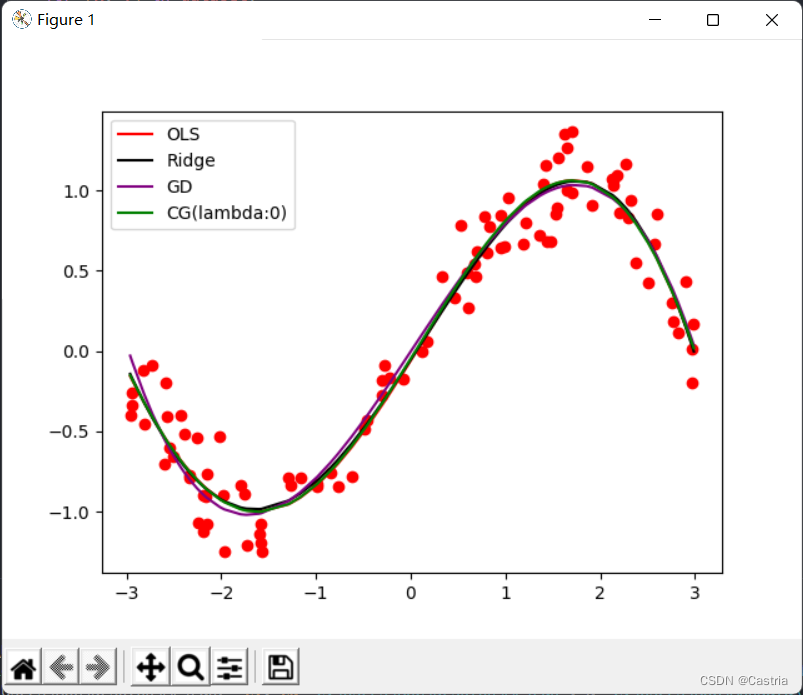
if __name__ == '__main__':
warnings.simplefilter('error')
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
# 最小二乘法
coef1 = fit(dataset)
# 岭回归
coef2 = ridge_regression(dataset)
# 梯度下降法
coef3 = GD(dataset, m = 3)
# 共轭梯度法
coef4 = CG(dataset)
# 绘制出四种方法的曲线
draw(dataset, coef1, color = 'red', label = 'OLS')
draw(dataset, coef2, color = 'black', label = 'Ridge')
draw(dataset, coef3, color = 'purple', label = 'GD')
draw(dataset, coef4, color = 'green', label = 'CG(lambda:0)')
# 绘制标签, 显示图像
plt.legend()
plt.show()