1. Datos de series temporales y sus características
Los datos de serie temporal son una serie de datos de monitoreo de indicadores que se generan continuamente en función de una frecuencia relativamente estable, como el índice Dow Jones dentro de un año, la temperatura medida en diferentes momentos del día, etc. Los datos de series temporales tienen las siguientes características:
- Invariancia de los datos históricos
- Disponibilidad de datos
- Puntualidad de los datos
- datos estructurados
- volumen de datos
En segundo lugar, la estructura básica de la base de datos de series temporales.
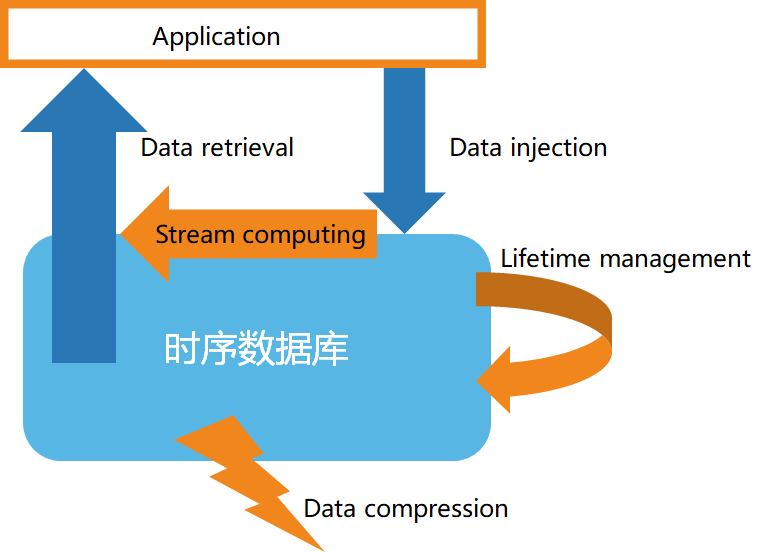
De acuerdo con las características de los datos de series temporales, las bases de datos de series temporales generalmente tienen las siguientes características:
- Almacenamiento de datos de alta velocidad
- Gestión del ciclo de vida de los datos
- Procesamiento de flujo de datos
- Consulta de datos eficiente
- Compresión de datos personalizada
3. Introducción a la computación de flujo
La computación de flujo se refiere principalmente a la adquisición en tiempo real de datos masivos de diferentes fuentes de datos, y al análisis y procesamiento en tiempo real para obtener información valiosa. Los escenarios comerciales comunes incluyen una respuesta rápida a eventos en tiempo real, alarmas en tiempo real para cambios en el mercado, análisis interactivo de datos en tiempo real, etc. La computación de flujo generalmente incluye las siguientes funciones:
1) Filtrado y conversión (filtro y mapa)
2) Funciones de agregación y ventana (reducir, agregación/ventana)
3) Fusión de múltiples flujos de datos y coincidencia de patrones (unión y detección de patrones)
4) Del flujo al procesamiento de bloques
4. Compatibilidad con bases de datos de series temporales para la computación de flujo
-
Caso 1: use una API de computación de transmisión personalizada, como se muestra en el siguiente ejemplo:
from(bucket: "mydb")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "mymeasurement")
|> map(fn: (r) => ({ r with value: r.value * 2 }))
|> filter(fn: (r) => r.value > 100)
|> aggregateWindow(every: 1m, fn: sum, createEmpty: false)
|> group(columns: ["location"])
|> join(tables: {stream1: {bucket: "mydb", measurement: "stream1", start: -1h}, stream2: {bucket: "mydb", measurement: "stream2", start: -1h}}, on: ["location"])
|> alert(name: "value_above_threshold", message: "Value is above threshold", crit: (r) => r.value > 100)
|> to(bucket: "mydb", measurement: "output", tagColumns: ["location"])
-
Caso 2: utilice instrucciones similares a SQL para crear secuencias informáticas y definir reglas de secuencias informáticas, de la siguiente manera:
CREATE STREAM current_stream
TRIGGER AT_ONCE
INTO current_stream_output_stb AS
SELECT
_wstart as start,
_wend as end,
max(current) as max_current
FROM meters
WHERE voltage <= 220
INTEVAL (5S) SLIDING (1s);