guía
Este artículo se compila a partir del intercambio de temas del mismo nombre sobre el tema de la infraestructura de IA en la Conferencia de desarrollo de software global QCon (estación de Beijing) en febrero de 2023. Aplicaciones como ChatGPT, Bard y el "Wen Xin Yi Yan" que se reunirá con usted se basan en los modelos grandes lanzados por cada fabricante. GPT-3 tiene 175 mil millones de parámetros, y el modelo grande de Wenxin tiene 260 mil millones de parámetros. Tomando como ejemplo el uso de NVIDIA GPU A100 para entrenar GPT-3, teóricamente se necesitan 32 años para una sola tarjeta y un clúster distribuido con una escala de kilocalorías, después de varias optimizaciones, todavía necesita 34 días para completar el entrenamiento. Este discurso presentó los desafíos del entrenamiento de modelos a gran escala para la infraestructura, como muros de potencia informática, muros de almacenamiento, diseño de red de alto rendimiento de una sola máquina y clúster, acceso a gráficos y aceleración de back-end, división y mapeo de modelos, etc. compartió Baidu El método de respuesta y la práctica de ingeniería de la nube inteligente han construido una infraestructura de pila completa desde el marco hasta el clúster, combinando software y hardware, y acelerando el entrenamiento de extremo a extremo de modelos grandes.
En los últimos dos años, el gran modelo ha tenido el mayor impacto en la arquitectura de la tecnología de IA. En el proceso de generación, iteración y evolución de modelos grandes, plantea nuevos desafíos a la infraestructura subyacente.
El intercambio de hoy se divide principalmente en cuatro partes: la primera parte es presentar los cambios clave provocados por el gran modelo desde una perspectiva comercial. La segunda parte trata sobre los desafíos que plantea el entrenamiento de modelos grandes para la infraestructura en la era de los modelos grandes y cómo responde Baidu Smart Cloud. La tercera parte es combinar las necesidades de los modelos a gran escala y la construcción de plataformas, y explicar la optimización conjunta de software y hardware realizada por Baidu Smart Cloud. La cuarta parte son los pensamientos de Baidu Smart Cloud sobre el desarrollo futuro de modelos grandes y nuevos requisitos para la infraestructura.

1. GPT-3 abre la era de los modelos grandes
La era de los modelos grandes la abrió GPT-3, que tiene las siguientes características:
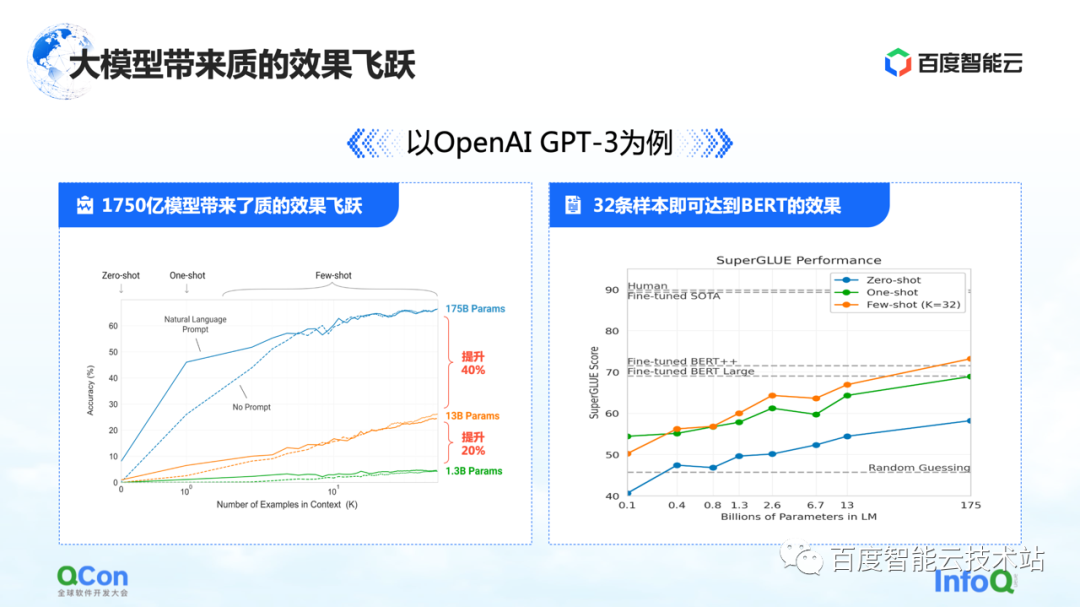
La primera característica es que los parámetros del modelo se han mejorado mucho, un solo modelo ha alcanzado los 175 mil millones de parámetros, lo que también ha supuesto un aumento significativo en la precisión. En la figura de la izquierda, podemos ver que con más y más parámetros del modelo, la precisión del modelo también está mejorando.
La imagen de la derecha muestra sus características más impactantes: basado en el modelo de 175 mil millones de parámetros entrenado previamente, solo necesita ser entrenado con una pequeña cantidad de muestras, y puede acercarse al efecto de BERT después de usar un entrenamiento de muestra grande. Esto refleja en cierta medida que la escala del modelo se vuelve más grande, lo que puede generar mejoras en el rendimiento y la versatilidad del modelo.
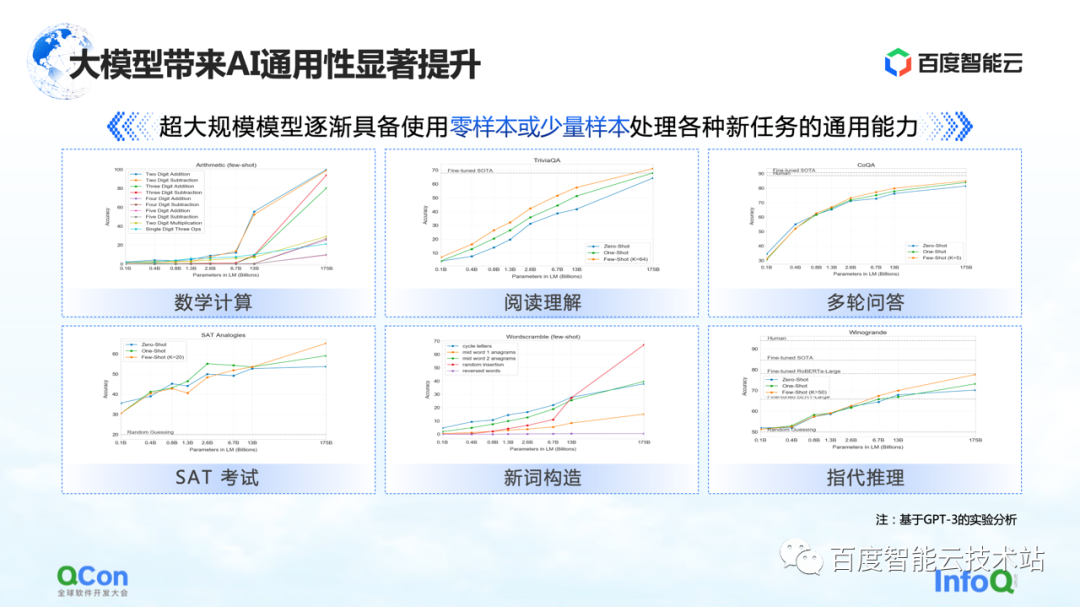
Además, GPT-3 también muestra un cierto grado de versatilidad en tareas como cálculos matemáticos, comprensión de lectura y múltiples rondas de preguntas y respuestas. Solo una pequeña cantidad de muestras puede hacer que el modelo alcance una mayor precisión, incluso cercana a la precisión humana. Gastar.
Debido a esto, el modelo grande también ha traído nuevos cambios al modelo general de investigación y desarrollo de IA. En el futuro, podemos entrenar previamente un modelo grande primero y luego realizar un ajuste fino con una pequeña cantidad de muestras para tareas específicas para obtener buenos resultados de entrenamiento. En lugar de entrenar el modelo como ahora, cada tarea debe repetirse por completo y entrenarse desde cero.
Baidu comenzó a entrenar modelos grandes muy temprano, y el modelo grande de Wenxin con 260 mil millones de parámetros se lanzó en 2021. Ahora, con Stable Diffusion, AIGC Vincent graph y el recientemente popular chat robot ChatGPT, etc., que han atraído la atención de toda la sociedad, todos se dan cuenta de que la era de los modelos grandes ha llegado.
Los fabricantes también están presentando productos relacionados con modelos grandes. Google acaba de lanzar Bard antes, y Baidu pronto lanzará "Wen Xin Yi Yan" en marzo.
¿Cuáles son las diferentes características del entrenamiento de modelos grandes?
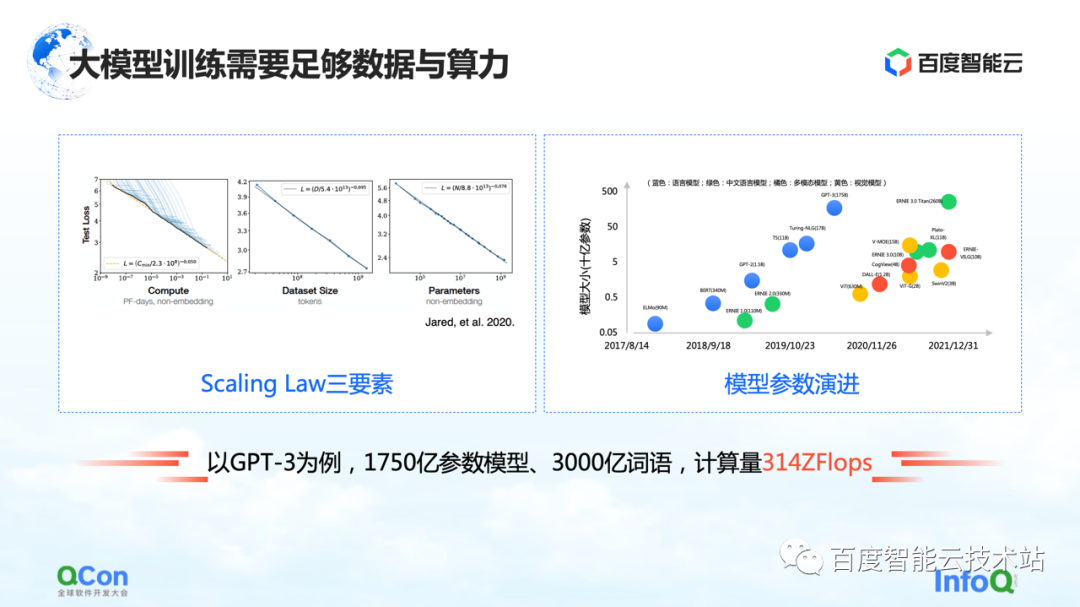
El modelo grande tiene una ley de escala, como se muestra en la figura de la izquierda, a medida que aumentan la escala de parámetros del modelo y los datos de entrenamiento, el efecto será cada vez mejor.
Pero hay una premisa aquí, los parámetros deben ser lo suficientemente grandes y el conjunto de datos es suficiente para respaldar el entrenamiento de todo el parámetro. La consecuencia de esto es que la cantidad de cálculos aumenta exponencialmente. Para un modelo pequeño ordinario, se puede hacer una sola máquina y una sola tarjeta. Pero para un modelo grande, sus requisitos de volumen de entrenamiento requieren recursos a gran escala para respaldar su entrenamiento.
Tomando GPT-3 como ejemplo, es un modelo con 175 mil millones de parámetros y necesita 300 mil millones de palabras de entrenamiento para respaldarlo y lograr un buen efecto. Su cálculo se estima en 314 ZFLOPs en el papel. En comparación con NVIDIA GPU A100, una tarjeta todavía tiene solo 312 TFLOPS de potencia informática AI, y el valor absoluto en el medio es diferente en 9 órdenes de magnitud.
Por lo tanto, para soportar mejor el cálculo, entrenamiento y evolución de modelos grandes, cómo diseñar y desarrollar infraestructura se ha convertido en un tema muy importante.
2. Panorama de infraestructura modelo a gran escala
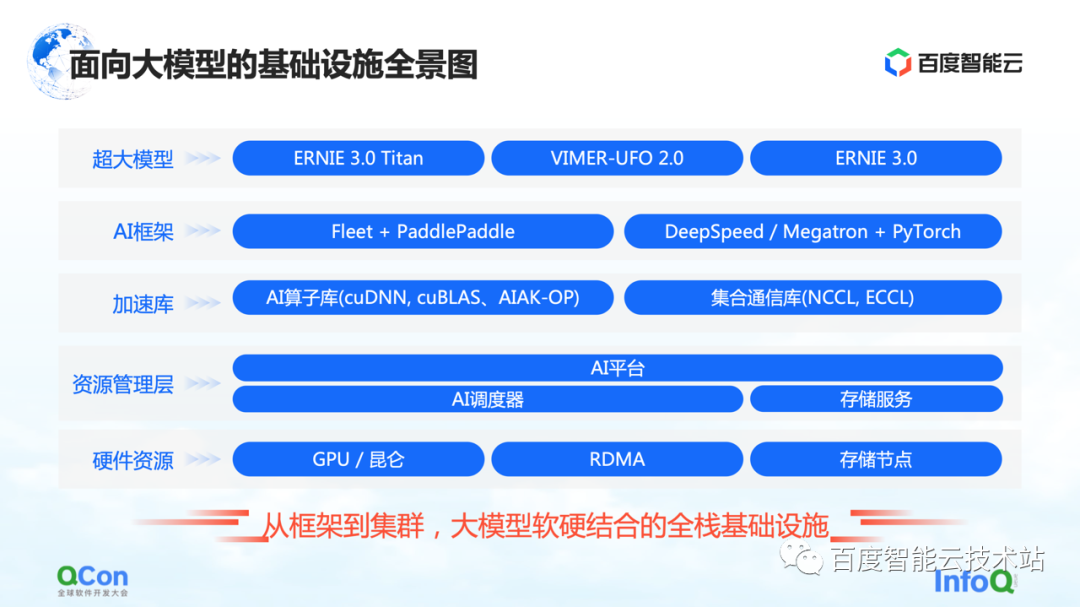
Este es un panorama de la infraestructura de Baidu Smart Cloud para modelos grandes. Esta es una infraestructura de pila completa que cubre desde el marco hasta el clúster, combinando hardware y software.
En el modelo grande, la infraestructura ya no solo cubre la infraestructura tradicional, como el hardware y las redes subyacentes. También necesitamos llevar todos los recursos relevantes a la categoría de infraestructura.
En concreto, se divide a grandes rasgos en varios niveles:
-
La capa superior es la capa del modelo, incluidos los modelos publicados internos y externos y algunos componentes de apoyo. Por ejemplo, la paleta voladora de Baidu PaddlePaddle y Fleet, Fleet es una estrategia distribuida en la paleta voladora . Al mismo tiempo, en la comunidad de código abierto, como PyTorch, existen algunos marcos de entrenamiento de modelos a gran escala y capacidades de aceleración basadas en el marco PyTorch, como DeepSpeed/Megatron.
-
Bajo el marco, también desarrollaremos capacidades relacionadas de la biblioteca de aceleración, incluida la aceleración del operador de IA, la aceleración de la comunicación, etc.
-
Las siguientes son algunas capacidades relacionadas con la gestión parcial de recursos o la gestión parcial de clústeres.
-
En la parte inferior se encuentran los recursos de hardware, como una sola tarjeta independiente, chips heterogéneos y capacidades relacionadas con la red.
Lo anterior es un panorama de toda la infraestructura. Hoy me centraré en comenzar con el marco de IA y luego extenderme a la capa de aceleración y la capa de hardware para compartir algunos trabajos específicos de Baidu Smart Cloud.
Comience primero con el marco superior de IA.
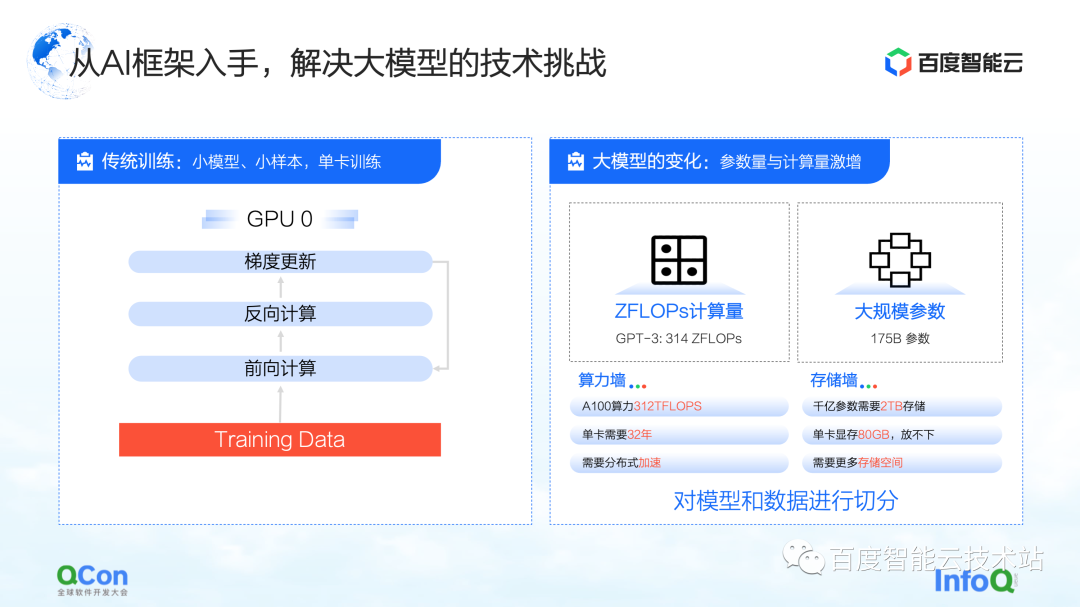
Para el entrenamiento tradicional de modelos pequeños en una sola tarjeta, podemos completar todo el entrenamiento utilizando los datos de entrenamiento para actualizar continuamente los gradientes hacia adelante y hacia atrás. Para el entrenamiento de modelos grandes, existen dos desafíos principales: el muro de potencia de cómputo y el muro de almacenamiento.
El muro de poder de cómputo se refiere a cómo podemos usar métodos distribuidos para resolver el problema de demasiado tiempo para un solo poder de cómputo si queremos completar el entrenamiento modelo de GPT-3, que requiere 314 ZFLOP de poder de cómputo, pero la tarjeta única solo tiene 312 TFLOPS de potencia de cómputo. . Después de todo, se necesitan 32 años para entrenar un modelo con una tarjeta, lo que obviamente no es factible.
El siguiente es el muro de almacenamiento. Este es un desafío mayor para los modelos más grandes. Cuando una sola tarjeta no puede contener el modelo, el modelo debe tener algún método de segmentación.
Por ejemplo, el almacenamiento de un modelo grande de 100 mil millones de niveles (incluidos parámetros, valores intermedios de entrenamiento, etc.) requiere 2 TB de espacio de almacenamiento, mientras que la memoria de video máxima de una sola tarjeta actualmente es de solo 80 GB. Por lo tanto, el entrenamiento de modelos grandes requiere algunas estrategias de segmentación para resolver el problema de que una sola tarjeta no puede caber.
El primero es el muro de potencia informática, que resuelve el problema de la potencia informática insuficiente de una sola tarjeta.
Una idea muy simple y familiar es el paralelismo de datos, que corta muestras de entrenamiento en diferentes tarjetas. En general, el proceso de entrenamiento de modelos grandes que estamos observando ahora adopta principalmente una estrategia de actualización de datos síncrona.

La atención se centra en la solución al problema de la pared de almacenamiento. La clave es la estrategia y el método de segmentación del modelo.
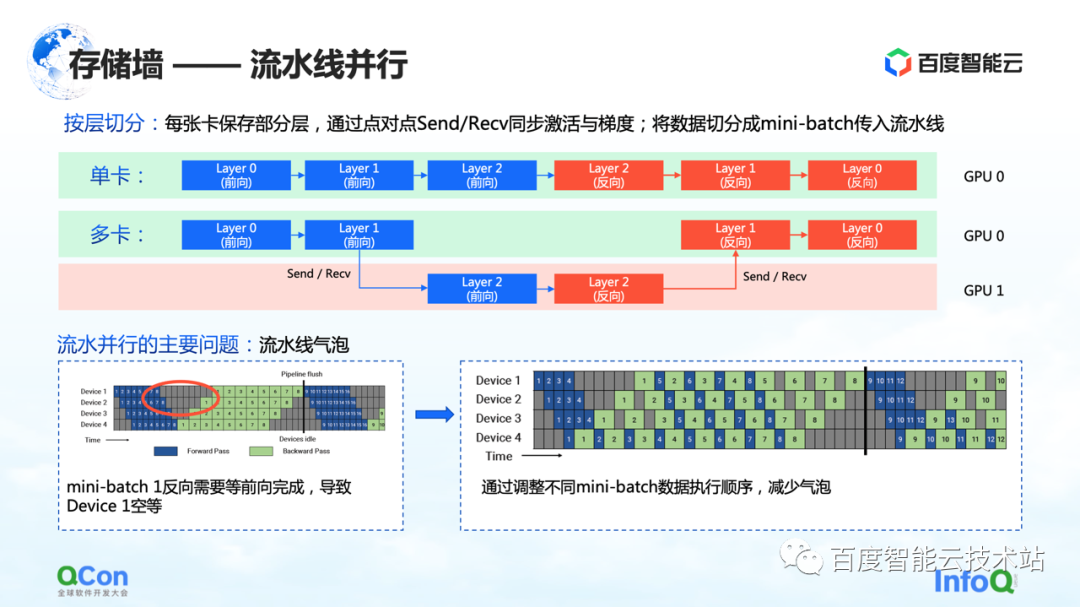
El primer método de corte es el paralelismo segmentado.
Usemos el ejemplo de la siguiente figura para ilustrar. Para un modelo, se compone de muchas capas. Al entrenar, avance primero y luego retroceda. Por ejemplo, las tres capas 0, 1 y 2 en la imagen no caben en una tarjeta. Después de dividir por capa, colocaremos algunas capas de este modelo en la primera tarjeta. Por ejemplo, en la siguiente figura, el área verde representa GPU 0 y el área roja representa GPU 1. Podemos poner las primeras capas en GPU 0 y las otras pocas capas en GPU 1. Cuando los datos fluyen, primero hará dos reenvíos en la GPU 0, luego hará uno hacia adelante y otro hacia atrás en la GPU 1 y luego volverá a la GPU 0 para hacer dos reversas. Dado que este proceso es particularmente similar a una canalización, lo llamamos paralelismo de canalización.
Pero hay un problema importante con el paralelismo de la tubería, a saber, las burbujas de la tubería. Debido a que habrá dependencias entre los datos, y el gradiente depende del cálculo de la capa anterior, por lo que en el proceso de flujo de datos se generarán burbujas, lo que provocará un vacío. En respuesta a tales problemas, reducimos el tiempo vacío de las burbujas ajustando las estrategias de ejecución de diferentes mini lotes.
Lo anterior es la perspectiva de un ingeniero de algoritmos o un ingeniero de marcos para analizar este problema. Desde la perspectiva de los ingenieros de infraestructura, estamos más preocupados por los diferentes cambios que traerá a la infraestructura.
Aquí nos centramos en su semántica de comunicación. Está entre adelante y atrás, y necesita pasar su propio valor de activación y valor de gradiente, lo que generará operaciones de envío/recepción adicionales. Y Enviar/Recibir es punto a punto, mencionaremos la solución más adelante en el artículo.
Lo anterior es la primera estrategia de segmentación de modelos paralelos que rompe el muro de almacenamiento: el paralelismo de canalización.
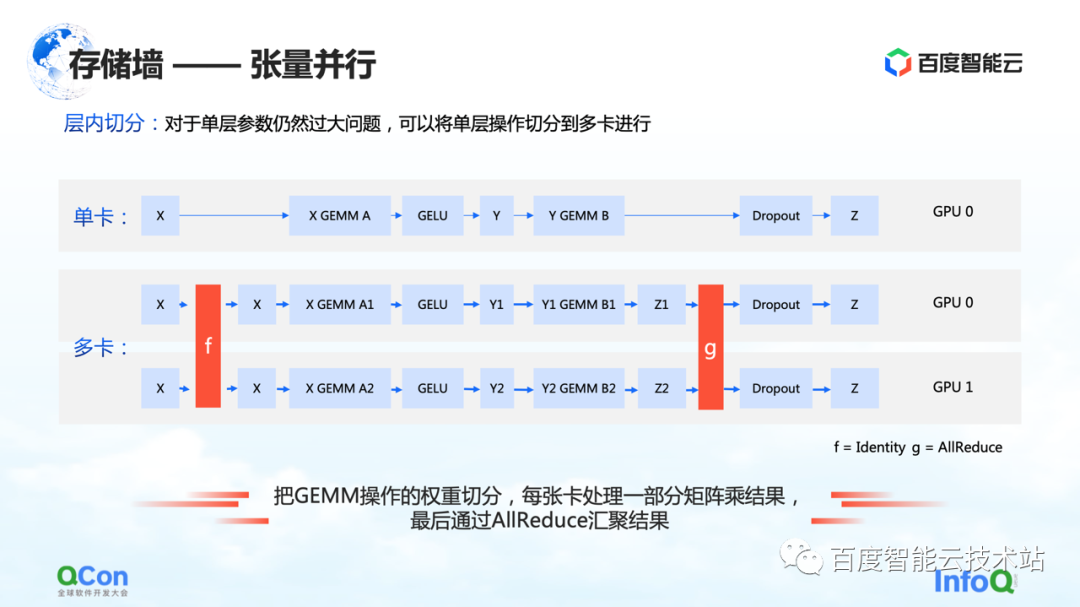
El segundo método de segmentación es el paralelismo tensorial , que resuelve el problema de los parámetros de una sola capa demasiado grandes.
Aunque el modelo tiene muchas capas, una de las capas es computacionalmente intensiva. En este momento, esperamos que la cantidad de cálculo de esta capa se calcule de forma conjunta entre máquinas o entre tarjetas. Desde la perspectiva de un ingeniero de algoritmos, la solución es dividir diferentes entradas en varias partes, luego usar diferentes partes para realizar cálculos parciales y finalmente realizar la agregación.
Pero desde la perspectiva de los ingenieros de infraestructura, aún prestamos atención a las operaciones adicionales que se introducen en este proceso. En el escenario que acabamos de mencionar, las operaciones adicionales son f y g en el gráfico. ¿Qué significan f y g? Cuando se hace hacia adelante, f es una operación invariable, y x se transmite de forma transparente a través de f, y algunos cálculos se pueden realizar más adelante. Sin embargo, cuando los resultados se agregan al final, se debe transmitir el valor total. Para este caso, es necesario introducir la operación de g. g es la operación de AllReduce, que agrega semánticamente dos valores diferentes para garantizar que la salida z pueda obtener los mismos datos en ambas tarjetas.
Entonces, desde la perspectiva de los ingenieros de infraestructura, verá que introduce operaciones de comunicación adicionales de AllReduce. El tráfico de comunicación de esta operación sigue siendo relativamente grande, porque los parámetros que contiene son relativamente grandes. También mencionaremos el método de afrontamiento más adelante en el artículo.
Este es el segundo método de optimización que puede romper los muros de almacenamiento.
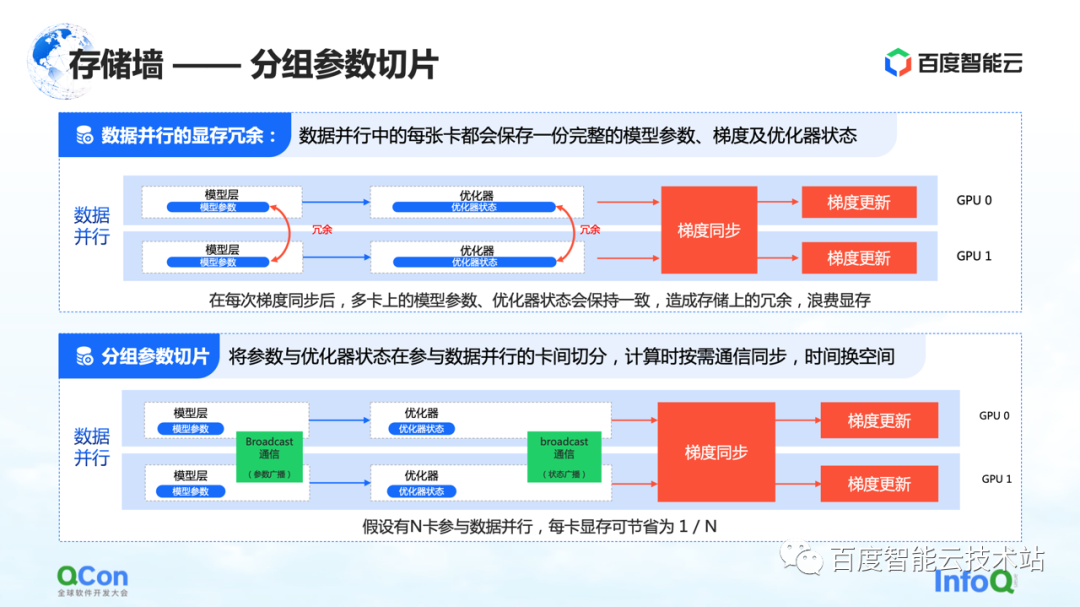
El tercer método de división es la división de parámetros agrupados . Este método reduce la redundancia de memoria en el paralelismo de datos hasta cierto punto. En las ejecuciones de datos tradicionales, cada tarjeta tendrá sus propios parámetros de modelo y estado del optimizador. Dado que deben sincronizarse y actualizarse durante sus respectivos procesos de entrenamiento, estos estados se respaldan por completo en diferentes tarjetas,
Para el proceso anterior, de hecho, los mismos datos y parámetros se almacenan de forma redundante en diferentes tarjetas. Tal almacenamiento redundante es inaceptable porque los modelos grandes tienen requisitos de espacio de almacenamiento extremadamente altos. Para resolver este problema, dividimos los parámetros del modelo y solo mantenemos una parte de los parámetros en cada tarjeta.
Cuando realmente se necesitan cálculos, intercambiamos tiempo por espacio: primero sincronizamos los parámetros y luego descartamos los datos redundantes una vez que se completa el cálculo. De esta manera, la demanda de memoria de video se puede comprimir aún más y la capacitación se puede realizar mejor en las máquinas existentes.
Del mismo modo, desde la perspectiva de los ingenieros de infraestructura, necesitamos introducir operaciones de comunicación como la transmisión, y el contenido de la comunicación es el estado de estos optimizadores y los parámetros del modelo.
El anterior es el tercer método de optimización para romper el muro de almacenamiento.
Además de los métodos y estrategias de optimización de memoria mencionados anteriormente, existe otra forma de reducir la cantidad de cálculo del modelo.
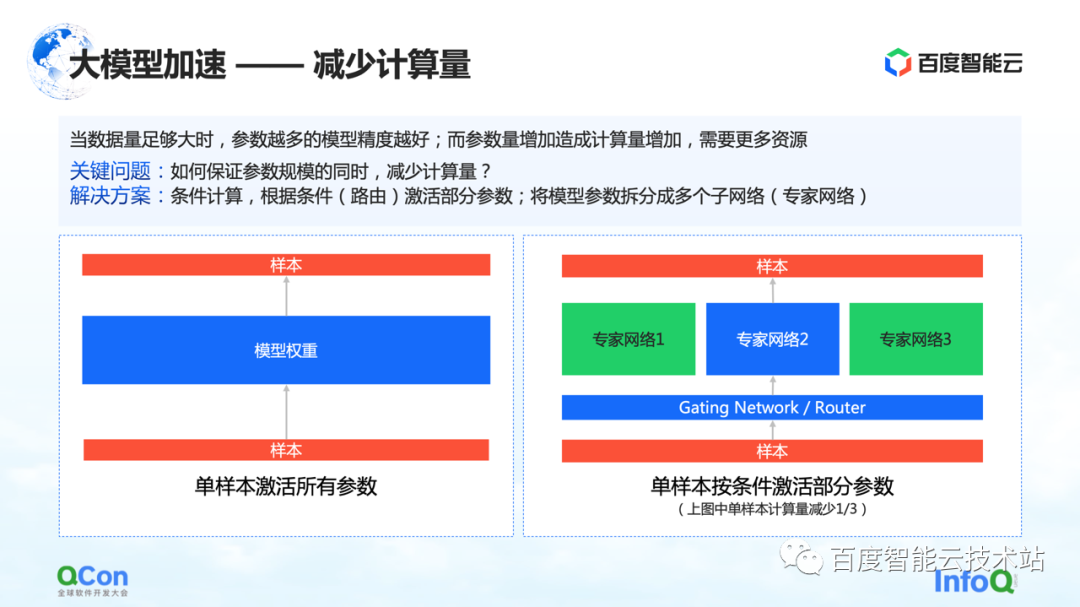
Cuando la cantidad de datos es lo suficientemente grande, cuantos más parámetros tenga el modelo, mejor será la precisión del modelo. Sin embargo, con el aumento de parámetros, la cantidad de cálculo también aumenta, lo que requiere más recursos y, al mismo tiempo, el tiempo de cálculo será mayor.
Entonces, ¿cómo garantizar que la cantidad de cálculo se reduzca mientras la escala del parámetro permanece sin cambios? Una de las soluciones es la computación condicional: según ciertas condiciones (es decir, la capa de activación de la figura de la derecha, o llamada capa de enrutamiento), seleccionar y activar algunos de los parámetros.
Por ejemplo, en la figura de la derecha, dividimos los parámetros en tres partes, y según las condiciones del modelo, solo una parte de los parámetros se activan para el cálculo en la red experta 2. Algunos parámetros en el experto 1 y el experto 3 no se calculan. De esta manera, la cantidad de cálculo se puede reducir mientras se asegura la escala del parámetro.
El anterior es un método basado en el cálculo condicional para reducir la cantidad de cálculo.
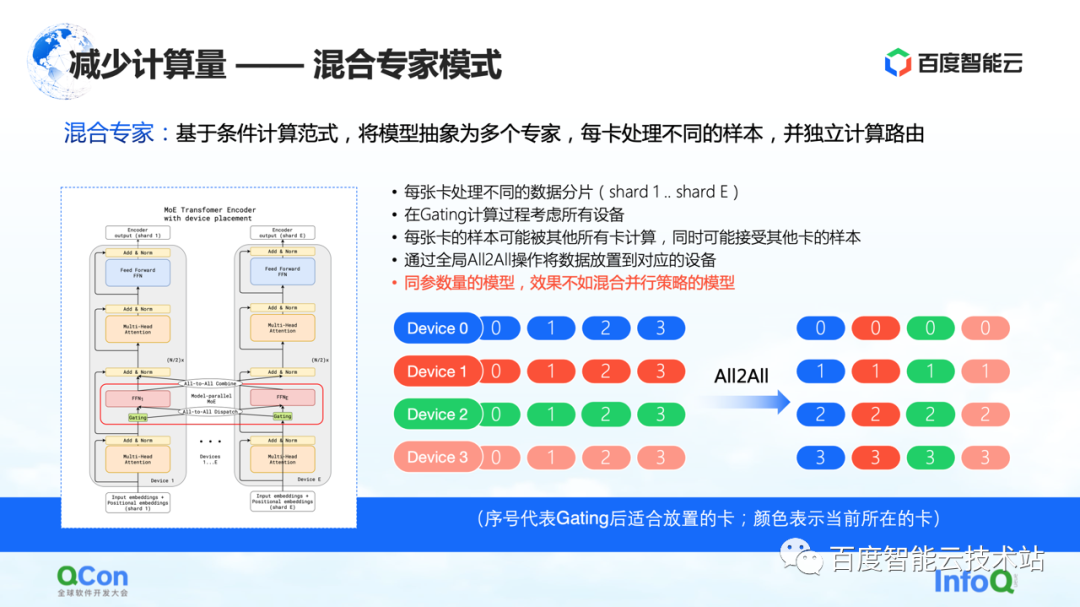
Con base en el método anterior, la industria propuso un modelo de expertos mixtos , que consiste en abstraer el modelo en múltiples expertos, y cada tarjeta procesa diferentes muestras. Específicamente, algunas opciones de enrutamiento se insertan en la capa del modelo y luego solo algunos de los parámetros se activan de acuerdo con esta elección. Al mismo tiempo, los parámetros de diferentes expertos se mantendrán en diferentes tarjetas. De esta forma, en el proceso de distribución de muestras, se asignarán a diferentes tarjetas para su cálculo.
Pero desde la perspectiva de un ingeniero de infraestructura, descubrimos que la operación All2All se introdujo en este proceso. Como se muestra en la figura de la derecha a continuación, las muestras como 0, 1, 2 y 3 se almacenan en varios dispositivos. El valor en Dispositivo indica qué tarjeta es adecuada para el cálculo o qué experto es adecuado para el cálculo. Por ejemplo, 0 significa que es adecuado para que lo calcule el experto n.° 0, es decir, la tarjeta n.° 0, etc. Cada tarjeta determinará quién es adecuado para que se calculen los datos almacenados. Por ejemplo, la tarjeta n.° 1 juzga que algunos parámetros son adecuados para el cálculo con la tarjeta n.° 0 y otros parámetros son adecuados para el cálculo con la tarjeta n.° 1. Luego, la siguiente acción es distribuir las muestras en diferentes tarjetas.
Después de las operaciones anteriores, las muestras en la tarjeta No. 0 son todas 0 y las muestras en la tarjeta No. 1 son todas 1. El proceso anterior se llama All2All en comunicación. Desde la perspectiva de los ingenieros de infraestructura, esta operación es relativamente pesada y necesitamos hacer algunas optimizaciones relacionadas sobre esta base. También introduciremos más en el siguiente texto.
En este modo, uno de los fenómenos que observamos es que si se usa el modo mixto-experto, su precisión de entrenamiento no es tan buena como las diversas estrategias paralelas y las estrategias de superposición híbrida mencionadas hace un momento bajo el modelo de los mismos parámetros. a la situación real.
Acabo de presentar varias estrategias paralelas y luego compartiré una práctica interna de Baidu Smart Cloud.
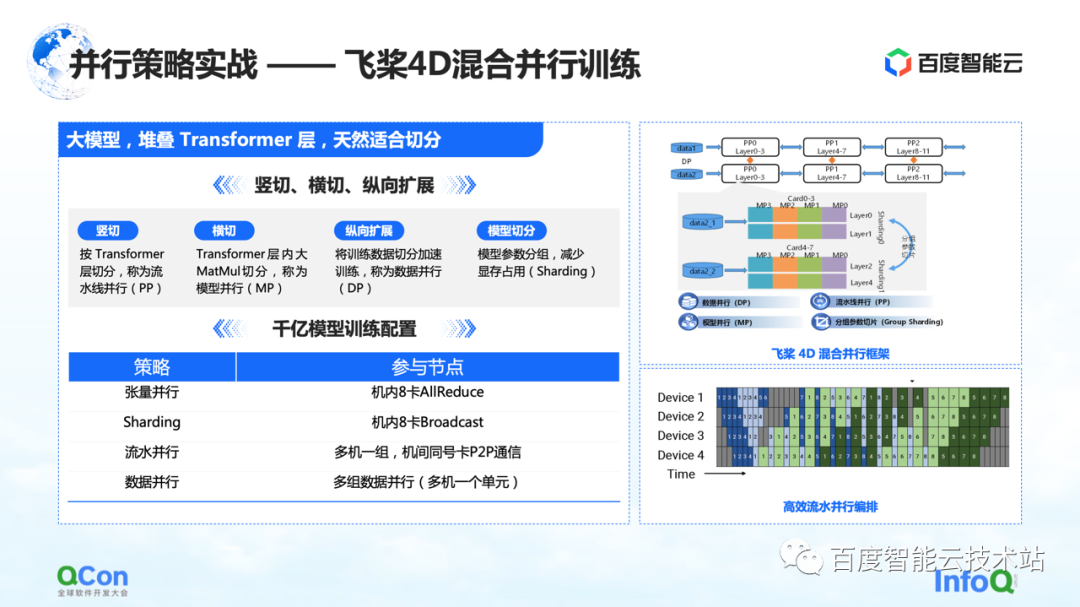
Entrenamos un modelo grande con 260 mil millones de parámetros usando Paddle , apilando algunas capas de clases de Transformer optimizadas. Podemos cortarlo horizontal y verticalmente, por ejemplo, cortar verticalmente el modelo de acuerdo con la capa del Transformador usando la estrategia paralela de canalización. Transversal es usar la estrategia paralela del modelo/estrategia paralela del tensor para dividir el cálculo de la multiplicación de matrices grandes como MetaMul dentro de Transformer. Al mismo tiempo, lo complementamos con la optimización vertical del paralelismo de datos y la optimización de la memoria de video de la segmentación de parámetros del modelo de agrupación en el paralelismo de datos. A través de los cuatro métodos anteriores, presentamos el marco de entrenamiento paralelo híbrido 4D de paletas voladoras .
En la configuración de entrenamiento del modelo de 100 mil millones de parámetros, usamos ocho tarjetas en la máquina para hacer el paralelismo de tensores y, al mismo tiempo, cooperamos con el paralelismo de datos para realizar algunas operaciones de segmentación de parámetros de agrupación. Al mismo tiempo, se utilizan múltiples grupos de máquinas para formar una tubería paralela para transportar 260 mil millones de parámetros de modelo. Finalmente, se utiliza el método de datos paralelos para computación distribuida para completar el entrenamiento mensual del modelo.
Lo anterior es un combate real de toda nuestra estrategia paralela del modelo de parámetros paralelos del modelo.
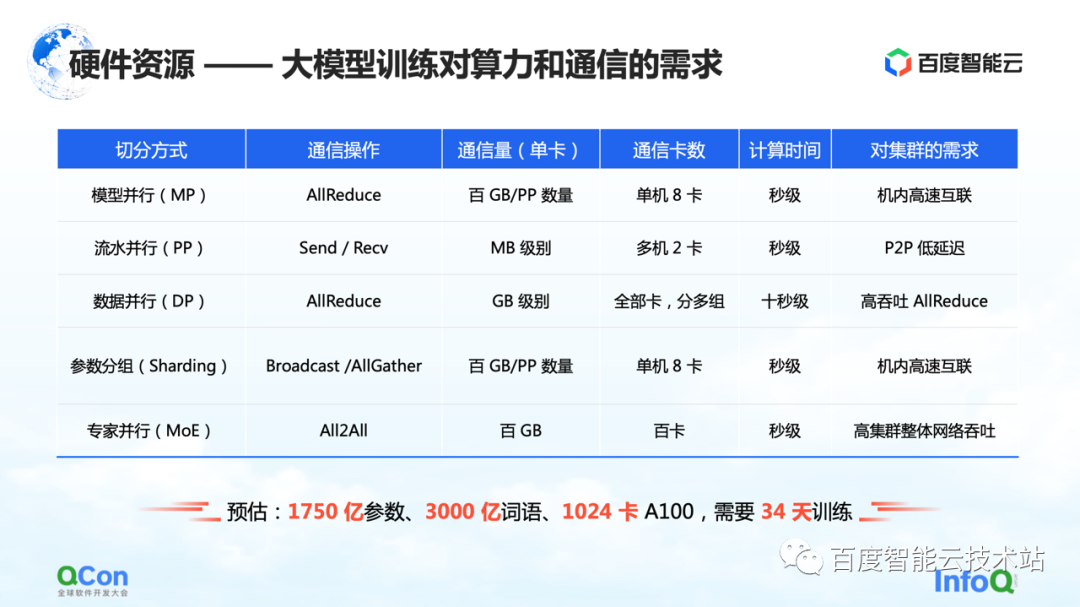
A continuación, volvamos a la perspectiva de la infraestructura para evaluar los requisitos de comunicación y poder de cómputo de diferentes estrategias de segmentación en el entrenamiento de modelos.
Como se muestra en la tabla, enumeramos el tráfico de comunicación y el tiempo de cómputo requerido para diferentes métodos de segmentación según la escala de 100 mil millones de parámetros. Desde la perspectiva de todo el proceso de formación, el mejor efecto es que el proceso de cálculo y el proceso de comunicación pueden cubrirse por completo o superponerse entre sí.
De esta tabla, podemos deducir los requisitos del modelo de 100 mil millones de parámetros para clústeres, hardware, redes y modos de comunicación en general. Basado en un modelo con aproximadamente 175 000 millones de parámetros entrenados en 1024 tarjetas A100 que usan 300 000 millones de palabras, se necesitan 34 días para completar la capacitación completa de extremo a extremo.
Lo anterior es nuestra evaluación del lado del hardware.
Con los requisitos de hardware, el siguiente paso es la selección de niveles independientes y de red.
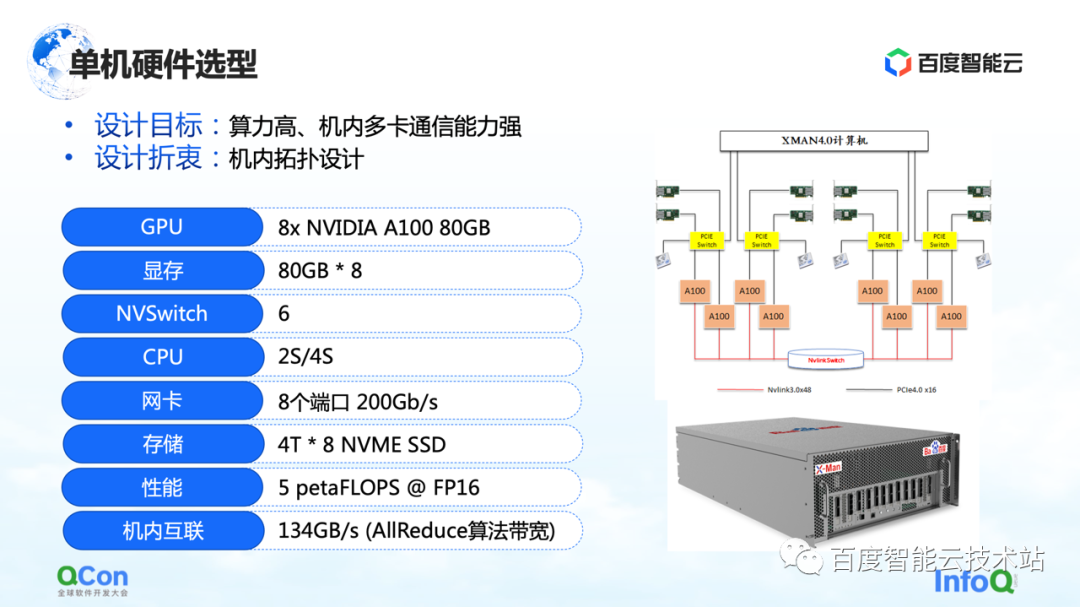
En el nivel independiente, dado que es necesario realizar una gran cantidad de operaciones AllReduce y Broadcast en la máquina, esperamos que la máquina pueda admitir conexiones de alto rendimiento y alto ancho de banda. Así que usamos el paquete A100 80G más avanzado en la selección de modelos en ese momento, usando 8 A100 para formar una sola máquina.
Además, en el método de conexión de red externa, lo más importante es el método de conexión de topología. Esperamos que la tarjeta de red y la tarjeta GPU puedan estar bajo el mismo conmutador PCIe tanto como sea posible, y que el cuello de botella de rendimiento de la interacción entre las tarjetas durante todo el proceso de entrenamiento pueda reducirse mejor de manera simétrica. Al mismo tiempo, intente evitar que pasen por el puerto raíz PCIe de la CPU.
Después de hablar sobre el stand-alone, echemos un vistazo al diseño de la red de clústeres.
En primer lugar, evalúemos los requisitos. Si nuestra expectativa comercial es completar la capacitación del modelo de extremo a extremo dentro de un mes, debemos alcanzar el nivel de kilocalorías en la capacitación de un solo trabajo y el nivel de 10,000 calorías en el modelo grande. grupos de entrenamiento. Por tanto, en el proceso de diseño de la red, debemos tener en cuenta dos puntos:
Primero, para cumplir con la operación punto a punto de Enviar/Recibir en la canalización, es necesario reducir la demora P2P.
En segundo lugar, dado que el tráfico del lado de la red en el entrenamiento de IA se concentra en la operación AllReduce de la misma tarjeta, también esperamos que tenga un alto rendimiento de comunicación.
para esta necesidad de comunicación. Diseñamos la topología de la arquitectura CLOS de tres niveles que se muestra a la derecha. Frente al método tradicional, lo más importante de esta topología es la optimización de los ocho carriles guía, de forma que el número de saltos en la comunicación de cualquier tarjeta con el mismo número en diferentes máquinas sea el menor posible.
En la arquitectura CLOS, la capa inferior es Unidad. Hay 20 máquinas en cada Unidad, y conectamos las tarjetas GPU del mismo número en cada máquina al mismo grupo de TOR con los números correspondientes. De esta forma, todas las tarjetas del mismo número en una sola unidad pueden completar la comunicación con un solo salto, lo que puede mejorar mucho la comunicación entre tarjetas del mismo número.
Sin embargo, solo hay 20 máquinas con un total de 160 tarjetas en una unidad, que no pueden cumplir con los requisitos para el entrenamiento de modelos grandes. Así que diseñamos la segunda capa Capa de hojas. La capa Leaf conecta tarjetas con el mismo número en diferentes unidades a los dispositivos de conmutación del mismo grupo de Leafs, lo que aún resuelve el problema de interconectar tarjetas con el mismo número. A través de esta capa, podemos interconectar 20 Unidades nuevamente. Hasta el momento hemos podido conectar 400 máquinas con un total de 3200 tarjetas. Para un grupo de 3200 tarjetas de este tipo, la comunicación entre dos tarjetas cualesquiera del mismo número se puede realizar saltando hasta 3 saltos.
¿Qué pasa si queremos soportar la comunicación de tarjetas con diferentes números? Agregamos una capa Spine en la parte superior para resolver el problema de la comunicación entre tarjetas con diferentes números.
A través de esta arquitectura de tres capas, hemos realizado una arquitectura general que admite 3200 tarjetas optimizadas para las operaciones de AllReduce. Si está en el equipo de red de IB, la arquitectura puede admitir la escala de 16000 tarjetas, que también es la escala más grande de redes tipo caja de IB en la actualidad.
Comparamos la arquitectura CLOS con otras arquitecturas de red, como Dragonfly, Torus, etc. En comparación con ellos, el ancho de banda de la red de esta arquitectura es más suficiente y la cantidad de saltos entre nodos es más estable, lo que es muy útil para estimar el rendimiento de entrenamiento predecible.
Lo anterior es un conjunto de ideas de construcción desde autónomo hasta red de clúster.

3. Optimización conjunta de la combinación de software y hardware
El entrenamiento de modelos a gran escala no significa comprar el hardware y ponerlo allí para completar el entrenamiento. También necesitamos una optimización conjunta de hardware y software.
En primer lugar, hablemos de la optimización del cálculo. El entrenamiento de modelos grandes sigue siendo un proceso computacionalmente intensivo en su conjunto. En términos de optimización informática, muchas ideas e ideas actuales se basan en la aceleración de múltiples back-end de gráficos estáticos. Los gráficos construidos por los usuarios, ya sea Paddle , PyTorch o TensorFlow, primero convertirán los gráficos dinámicos en gráficos estáticos a través de la captura de gráficos, y luego permitirán que los gráficos estáticos ingresen al backend para la aceleración.
La siguiente figura muestra toda nuestra arquitectura multi-backend basada en gráficos estáticos, que se divide en las siguientes partes**. **
El primero es el acceso a gráficos, que convierte gráficos dinámicos en gráficos estáticos.
El segundo es el método de acceso de múltiples backends, que proporciona capacidades de optimización basadas en el tiempo a través de diferentes backends.
El tercero es la optimización de gráficos. Hemos realizado algunas optimizaciones de cálculo y conversión de gráficos para gráficos estáticos, a fin de mejorar aún más la eficiencia informática.
Finalmente, usaremos algunos operadores personalizados para acelerar el proceso de entrenamiento del modelo grande como un todo.
Vamos a presentarlos por separado a continuación.

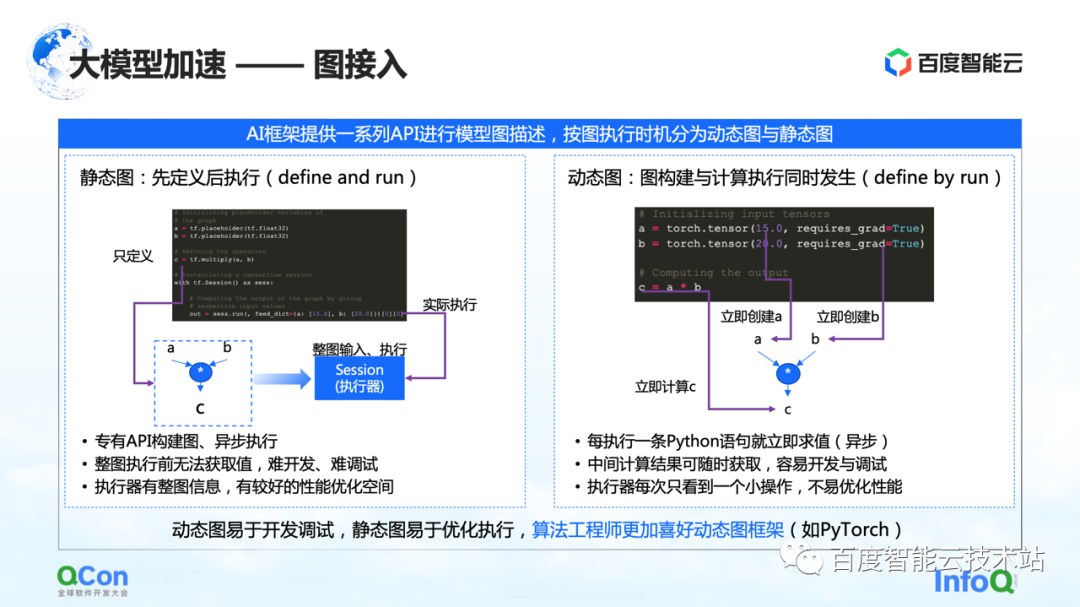
En la arquitectura de entrenamiento de modelos grandes, la primera parte es el acceso a gráficos. Cuando se describen gráficos en el marco de la IA, generalmente se dividen en gráficos estáticos y gráficos dinámicos.
El gráfico estático es que el usuario construye el gráfico antes de ejecutarlo y luego lo ejecuta en combinación con su entrada real. Combinado con tales características, se puede realizar una optimización de la compilación o la optimización de la programación por adelantado durante el proceso de cálculo, lo que puede mejorar el rendimiento del entrenamiento.
Pero le corresponde el proceso de construcción del grafo dinámico. El usuario escribe un código casualmente y se ejecuta dinámicamente durante el proceso de escritura. Por ejemplo, PyTorch, después de que el usuario escriba una declaración, realizará la ejecución y evaluación relacionadas. Para los usuarios, la ventaja de este enfoque es que es fácil de desarrollar y depurar. Pero para el ejecutor o el proceso de aceleración, porque cada vez que se ve es una pequeña parte de la operación, no está muy bien optimizado.
Para resolver este problema, la idea general es integrar gráficos dinámicos y gráficos estáticos, usar gráficos dinámicos para el desarrollo y luego ejecutar a través de gráficos estáticos. Hay principalmente dos caminos hacia la implementación que vemos ahora.
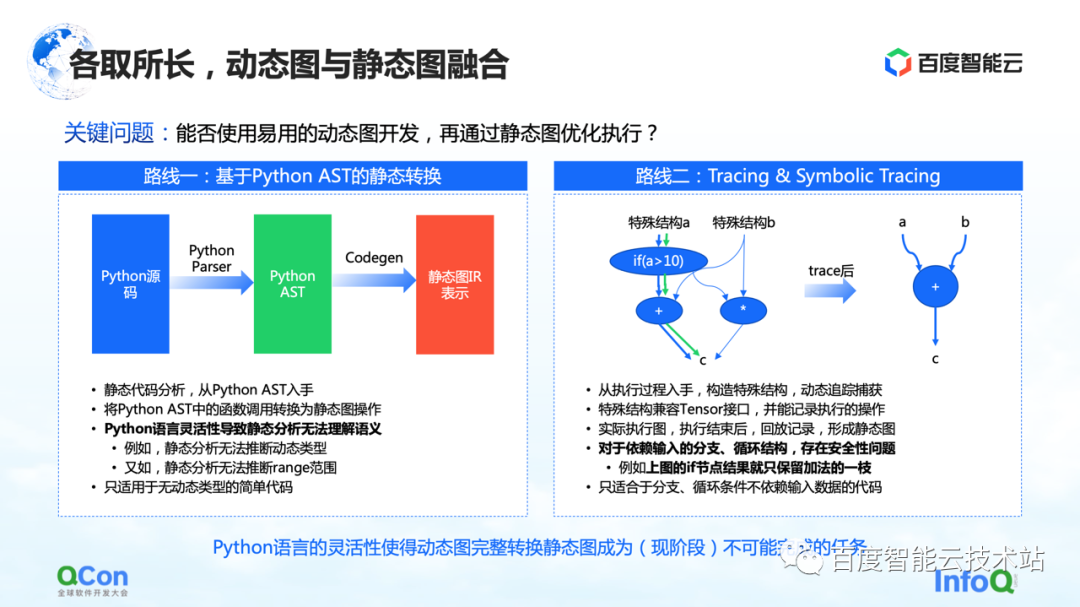
El primero es hacer una conversión estática basada en Python AST. Por ejemplo, obtenemos el código fuente de Python escrito por el usuario, lo convertimos en un árbol AST de Python y luego hacemos CodeGen basado en el árbol AST. En este proceso, el código fuente dinámico de Python se puede convertir en un gráfico estático utilizando el método y la API del gráfico de grupo estático.
Pero en este proceso, el mayor problema es la flexibilidad del lenguaje Python, lo que conduce a la incapacidad del análisis estático para comprender bien la semántica, y luego falla la conversión de imágenes dinámicas a imágenes estáticas. Por ejemplo, en el proceso de análisis estático, no tiene forma de inferir el tipo dinámico y, por ejemplo, el análisis estático no puede inferir el rango del rango, lo que genera fallas frecuentes en el proceso de conversión real. Por lo tanto, la conversión estática solo se puede aplicar a algunos escenarios de modelos simples.
La segunda vía es hacer ejecución y simulación simple mediante Trazado o Trazado Simbólico. Tracer registra algunos nodos informáticos encontrados durante el proceso de grabación. Después de registrar estos nodos informáticos, construye un gráfico estático completo a posteriori a través de la reproducción o la reorganización. La ventaja de este método es que puede capturar y calcular el gráfico dinámico general mediante la simulación de algunos métodos de entrada, o mediante la construcción de métodos de estructura especiales, y luego puede capturar una ruta con mayor éxito.
Pero en realidad hay algunos problemas en este proceso. Para las estructuras de bifurcación o bucle que dependen de la entrada, debido a que Tracer construye gráficos estáticos mediante la construcción de entradas simuladas, Tracer solo irá a algunas de las bifurcaciones, lo que genera problemas de seguridad.
Después de comparar estos métodos, encontramos que bajo la flexibilidad del lenguaje existente de Python, es básicamente una tarea imposible completar la conversión de gráficos dinámicos en gráficos estáticos en esta etapa. Por lo tanto, nuestro enfoque se ha desplazado hacia cómo proporcionar a los usuarios capacidades de conversión de imágenes en la nube más seguras y fáciles de usar. En esta etapa, hay varias opciones de la siguiente manera.
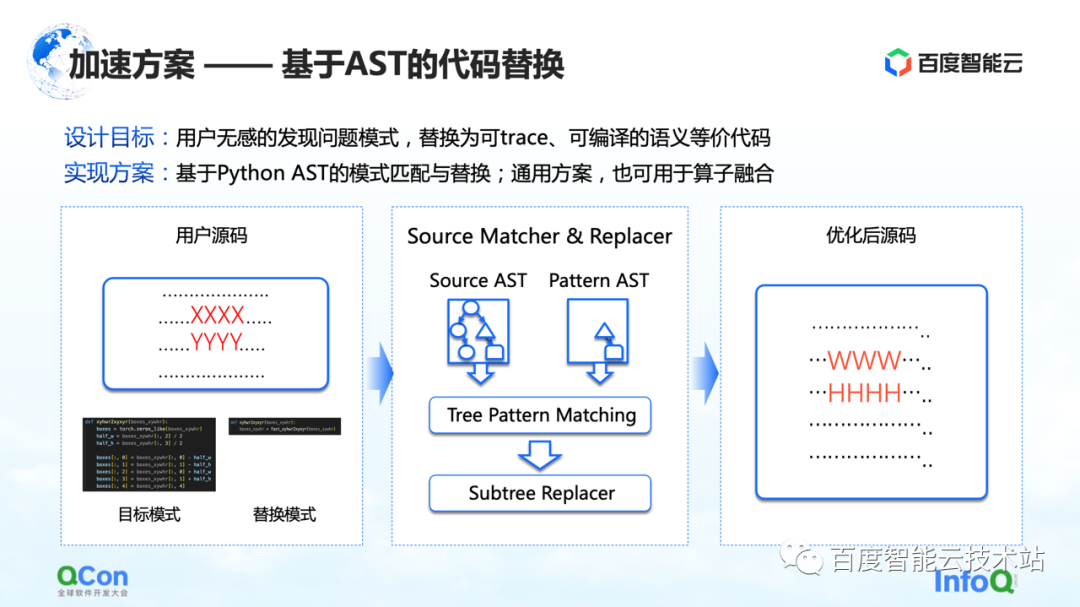
La primera solución es desarrollar un método basado en el reemplazo de código AST. En este método, Baidu Smart Cloud proporciona las capacidades de conversión y optimización del modelo correspondiente, que no es sensible a los usuarios. Por ejemplo, el usuario ingresa una parte del código fuente, pero parte del código (que se muestra como XXXX y YYYY en la figura) está en el proceso de captura de imágenes estáticas, optimización de gráficos y optimización de operadores. el código no puede convertir el gráfico dinámico en un gráfico estático, o el código tiene espacio para la optimización del rendimiento. Luego escribiremos un código de reemplazo, como se muestra en la imagen del medio. A la izquierda hay una pieza de código de Python que creemos que se puede reemplazar, y a la derecha hay otra pieza de código de Python que hemos reemplazado. Luego, usaremos el método de coincidencia AST para convertir la entrada del usuario y nuestro patrón de destino original en AST, y ejecutaremos nuestro algoritmo de coincidencia de árbol de subárbol en él.
De esta manera, podemos cambiar nuestra entrada original XXXX, YYYY en WWWW, HHHH, y convertirla en una solución que se pueda ejecutar mejor, lo que mejora la tasa de éxito de convertir imágenes dinámicas en imágenes estáticas hasta cierto punto, y mejora la Operador al mismo tiempo, rendimiento, y puede lograr el efecto de que el usuario es básicamente insensible.
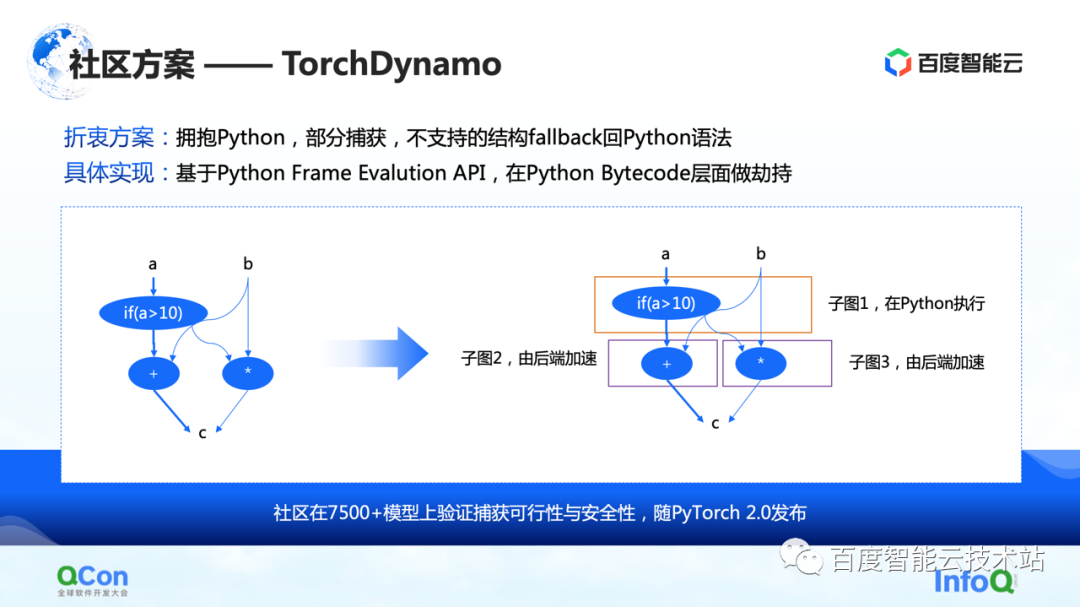
La segunda son algunas soluciones en la comunidad, especialmente la solución TorchDynamo propuesta por PyTorch 2.0, que también es una solución que hemos visto hasta ahora que es más adecuada para la optimización informática. Puede lograr una captura de gráficos parcial y las estructuras no compatibles pueden recurrir a Python. De esta manera, puede escupir algunos de los subgráficos al backend hasta cierto punto, y luego el backend puede acelerar aún más los cálculos en estos subgráficos.
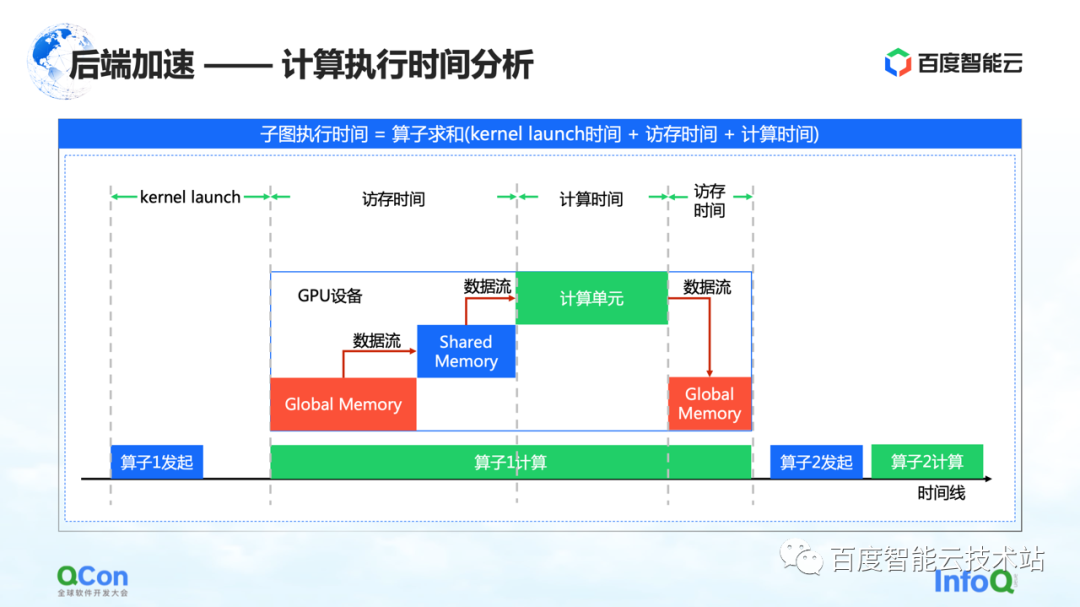
Una vez que hemos capturado el gráfico completo, el siguiente paso es comenzar a calcular la aceleración, es decir, la aceleración de back-end.
Creemos que los puntos clave en el diagrama de tiempo de la computación GPU son el tiempo de acceso a la memoria y el tiempo de computación. Aceleramos esta vez desde los siguientes ángulos.
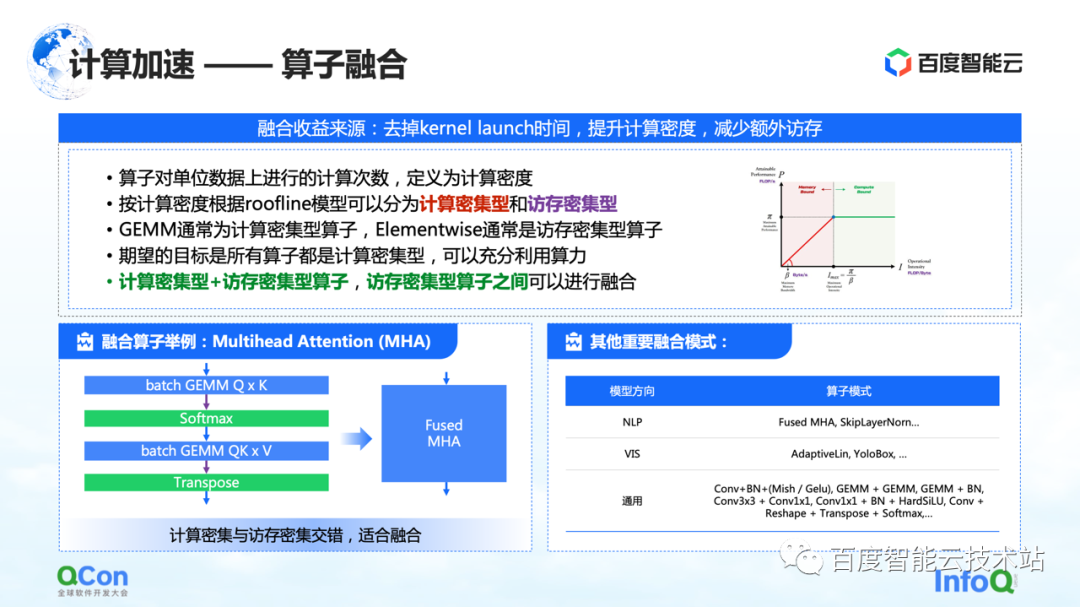
El primero es la fusión de operadores. El principal beneficio de la fusión de operadores es reducir el tiempo dedicado al lanzamiento del kernel, aumentar la densidad informática y reducir el acceso a la memoria adicional. Definimos el número de cálculos por unidad de acceso a la memoria de un operador como la densidad de cálculo.
De acuerdo con la diferencia en la densidad de computación, dividimos a los operadores en dos tipos: intensivos en computación e intensivos en memoria. Por ejemplo, GEMM es un operador típico de uso intensivo de computación y Elementwise es un operador típico de uso intensivo de memoria. Descubrimos que se puede hacer una buena fusión entre "operadores intensivos en computación + operadores intensivos en memoria" y "operadores intensivos en memoria + operadores intensivos en memoria".
Nuestro objetivo es convertir todos los operadores ejecutados en la GPU en operadores intensivos en cálculo parcial, para que podamos aprovechar al máximo nuestra potencia informática.
A la izquierda hay un ejemplo nuestro, por ejemplo, en la estructura del Transformador, la Atención Multicabezal más importante puede hacer una buena fusión. Al mismo tiempo, hay algunos otros modelos que encontramos a la derecha, y no los enumeraremos uno por uno debido a limitaciones de espacio.
Otro tipo de optimización informática es la optimización de la implementación del operador.
La cuestión esencial de la implementación del operador es cómo combinar la lógica informática con la arquitectura del chip, para realizar mejor todo el proceso informático. Actualmente vemos tres tipos de escenarios:
La primera categoría son los operadores escritos a mano. Los fabricantes relevantes proporcionarán bibliotecas de operadores como cuBLAS y cuDNN. El rendimiento del operador que proporciona es el mejor, pero las operaciones que admite son limitadas y el soporte para el desarrollo personalizado es relativamente deficiente.
La segunda categoría son las plantillas semiautomáticas, como CUTLASS. Este método crea una abstracción de código abierto, lo que permite a los desarrolladores realizar un desarrollo secundario en él. Este es también el método que usamos actualmente para lograr la fusión de operadores intensivos en computación y en memoria.
El tercero es la optimización basada en búsquedas. Prestamos atención a algunos métodos de compilación como Halide y TVM en la comunidad. En la actualidad, se encuentra que este método es efectivo en algunos operadores, pero necesita pulirse más en otros operadores.
En la práctica, estos tres métodos tienen sus propias ventajas, por lo que le proporcionaremos la mejor implementación a través de la selección de tiempo.

Después de hablar sobre la optimización de la informática, compartamos varios métodos de optimización de la comunicación.
El primero es la resolución del problema de colisión de hash de conmutadores. La siguiente figura es un experimento que hicimos: configuramos una tarea de 32 tarjetas y realizamos 30 operaciones de AllReduce cada vez. La siguiente figura muestra el ancho de banda de comunicación que medimos, podemos ver que hay una alta probabilidad de que disminuya la velocidad. Este es un problema serio en el entrenamiento de modelos grandes.
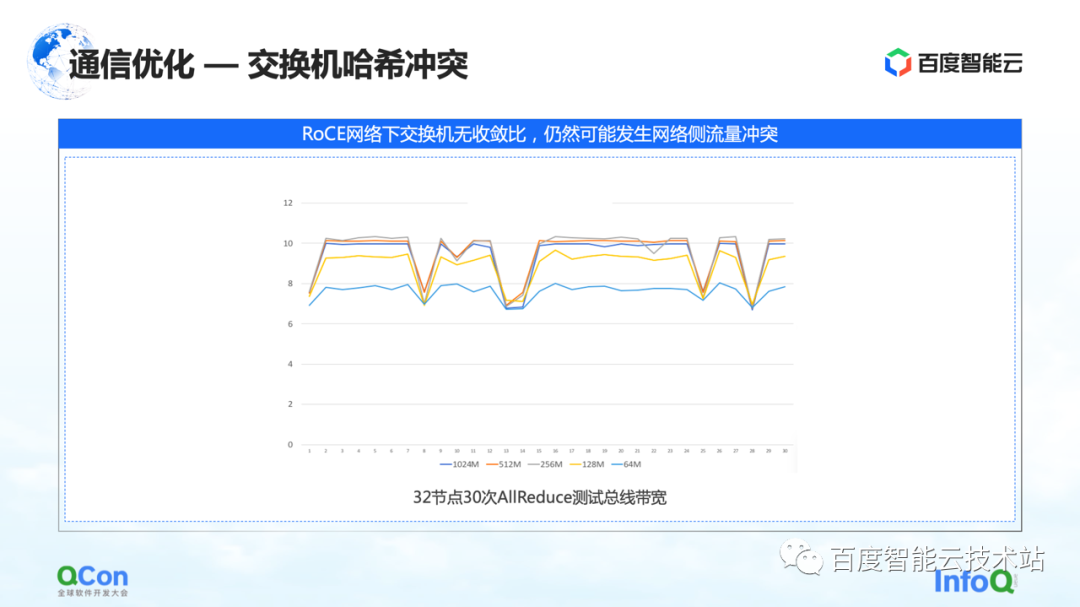
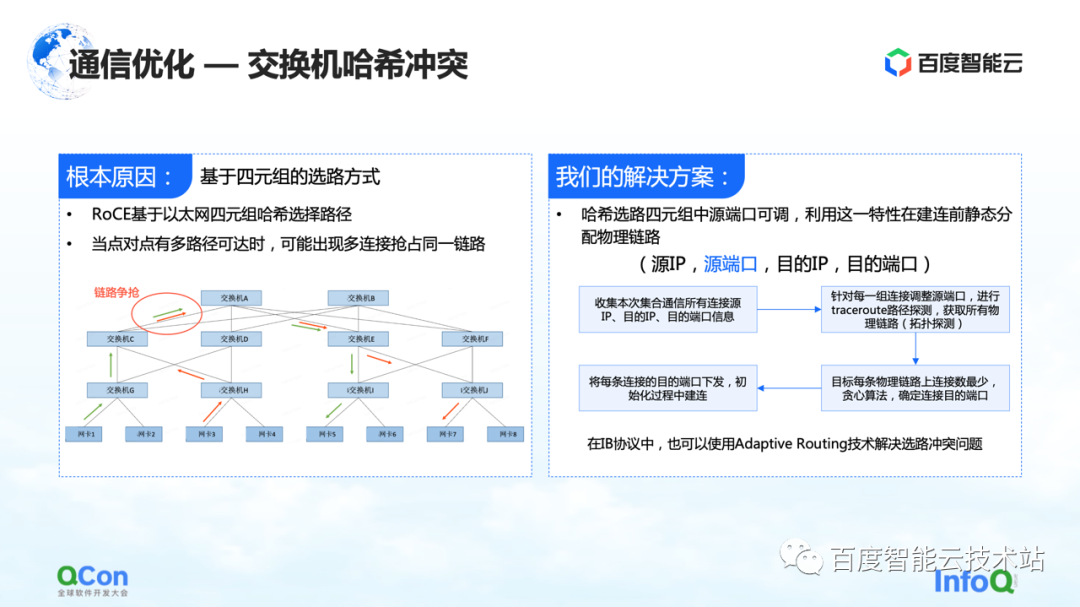
El motivo de la desaceleración se debe a las colisiones de hash. Aunque en el diseño de la red, el conmutador no tiene una relación de convergencia, es decir, los recursos de ancho de banda en nuestro diseño de red son suficientes, pero debido al uso de RoCE, un método basado en el enrutamiento cuádruple de Ethernet, es posible que aún existan conflictos de tráfico en el lado de la red. ocurrir
Por ejemplo, en el ejemplo de la figura a continuación, las máquinas verdes necesitan comunicarse entre sí, y las máquinas rojas también necesitan comunicarse entre sí. Luego, durante el proceso de selección de ruta, la comunicación de todos competirá por el mismo ancho de banda debido a Aunque el ancho de banda general de la red es suficiente, se seguirán formando puntos de acceso de la red local, lo que provocará una ralentización del rendimiento de la comunicación.
Nuestra solución es bastante simple. En todo el proceso de comunicación existen cuatro tuplas de IP de origen, puerto de origen, IP de destino y puerto de destino. La IP de origen, la IP de destino y el puerto de destino son fijos, mientras que el puerto de origen se puede ajustar. Aprovechando esta característica, ajustamos continuamente el puerto de origen para seleccionar diferentes rutas y luego usamos el algoritmo voraz general para minimizar la ocurrencia de colisiones de hash.
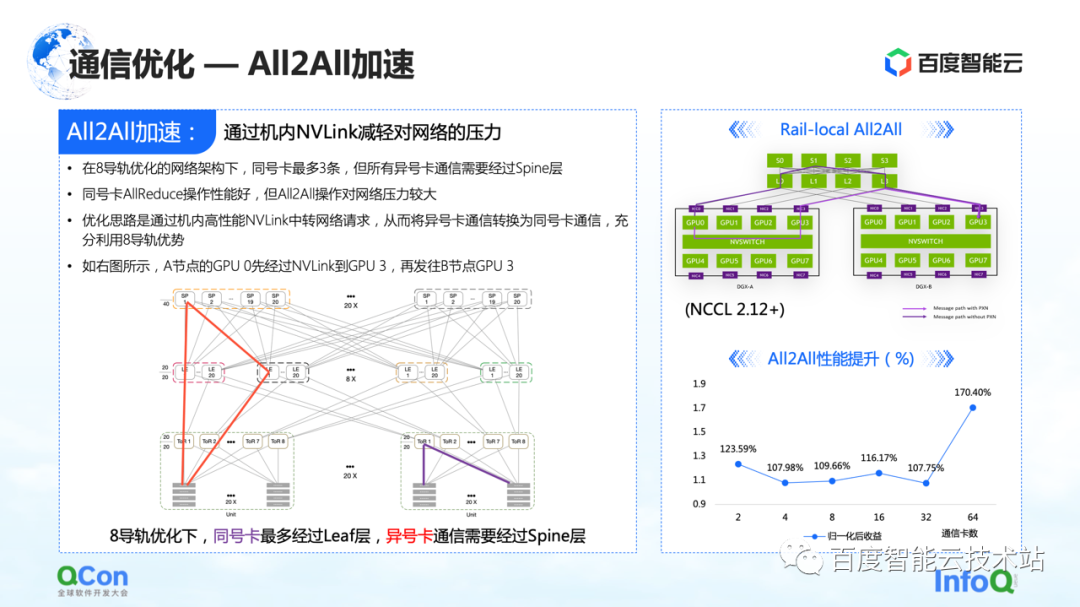
En la optimización de las comunicaciones, además de algunas optimizaciones en AllReduce que acabamos de mencionar, también hay cierto espacio para la optimización en All2All, especialmente nuestra red especialmente personalizada para ocho rieles.
Esta red ejercerá mucha presión sobre el interruptor de la columna vertebral de la capa superior en la operación de todo All2All. El método de optimización es usar Rail-Local All2All en NCCL, o la optimización de PXN. El principio es convertir la comunicación entre tarjetas de diferente número a la comunicación entre tarjetas del mismo número a través del NVLink de alto rendimiento dentro de la máquina.
De esta manera, convertimos toda la comunicación de red entre máquinas que originalmente subía a la capa de la columna vertebral en comunicación intra-máquina, de modo que solo la comunicación de la capa TOR o la capa hoja se puede utilizar para realizar la comunicación de tarjetas con diferentes números, y el rendimiento también mejorará. Hay una gran mejora.
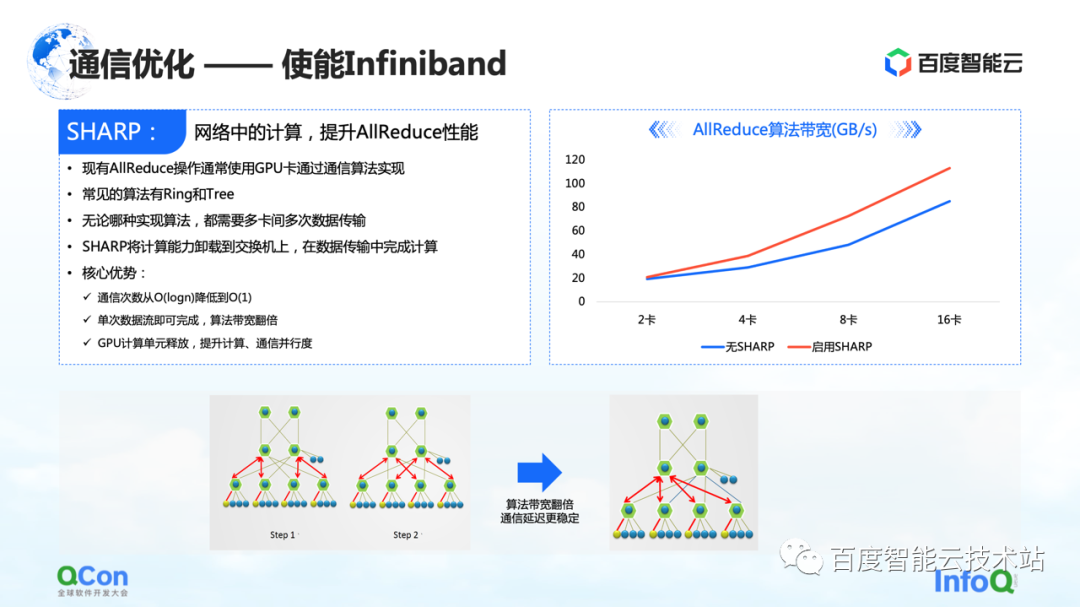
Además, además de estas optimizaciones realizadas en RoCE, existe otro efecto directo que se puede lograr al habilitar Infiniband. Por ejemplo, el conflicto de hash del conmutador que acabamos de mencionar puede manejarse mediante su propio enrutamiento adaptable. Para AllReduce, también tiene algunas funciones avanzadas como Sharp, que puede descargar parte de las operaciones informáticas de AllReduce a nuestros dispositivos de red, para liberar unidades informáticas y mejorar el rendimiento informático. A través de este método, podemos mejorar nuevamente el efecto de entrenamiento de AllReduce.
Acabo de terminar de hablar sobre la optimización de la informática y la comunicación, veamos este problema de principio a fin.
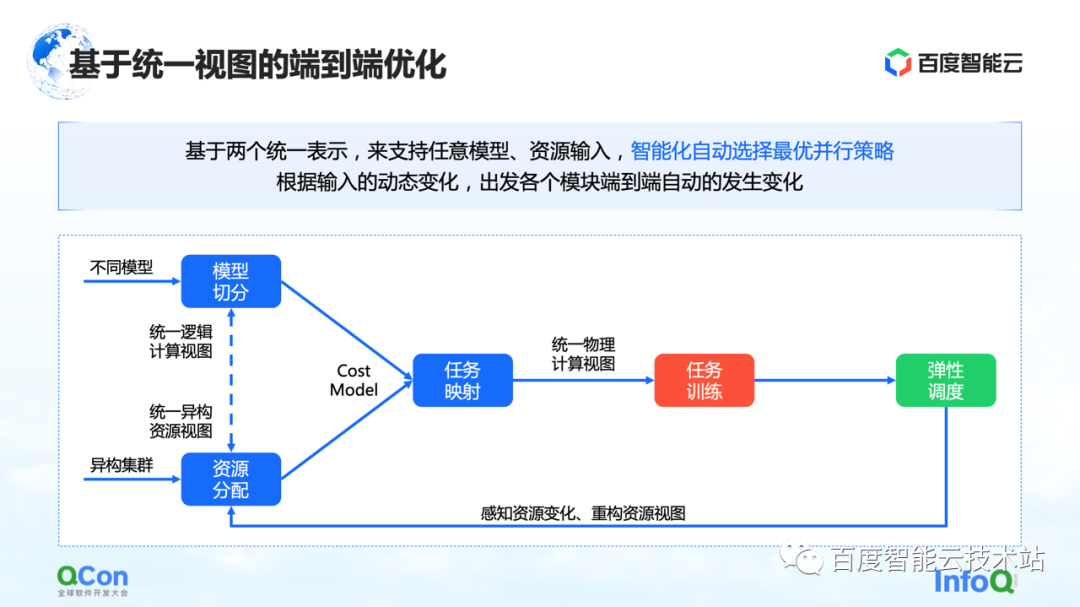
Desde la perspectiva de todo el entrenamiento del modelo grande, en realidad se divide en dos partes, la primera parte es el código del modelo y la segunda parte es la red de alto rendimiento. En estos dos niveles diferentes, hay un problema que debe resolverse con urgencia: ¿qué tarjeta es la más adecuada para colocar el modelo después de múltiples estrategias de segmentación?
Tomemos un ejemplo: cuando hacemos paralelismo de tensores, necesitamos dividir el cálculo de un tensor en dos partes. Dado que se requiere una gran cantidad de operaciones de AllReduce entre los resultados de cálculo de los bloques, se requiere un gran ancho de banda.
Si ponemos dos piezas de un corte de tensor en paralelo en dos tarjetas de máquinas diferentes, se introducirá la comunicación en red, lo que provocará problemas de rendimiento. Por el contrario, si ponemos estas dos piezas en la misma máquina, podemos completar eficientemente las tareas informáticas y mejorar la eficiencia del entrenamiento. Por lo tanto, el atractivo central del problema de ubicación es encontrar la relación de mapeo más adecuada o de mejor rendimiento entre el modelo segmentado y el hardware heterogéneo.
En nuestro entrenamiento inicial del modelo, el mapeo se realizó manualmente en base al conocimiento empírico experto. Por ejemplo, la imagen a continuación muestra que cuando cooperamos con el equipo comercial, cuando pensamos que el ancho de banda en la máquina es bueno, recomendamos ponerlo en la máquina. Si pensamos que puede haber mejoras en el cuarto de máquinas, se recomienda ponerlo en el cuarto de máquinas.
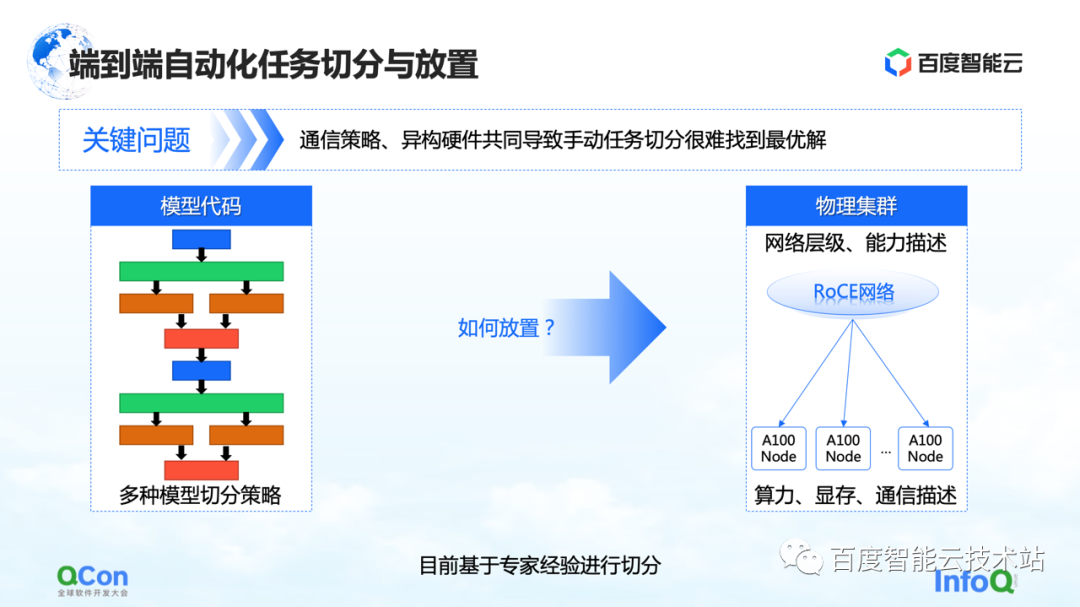
¿Hay alguna solución de ingeniería o sistemática?
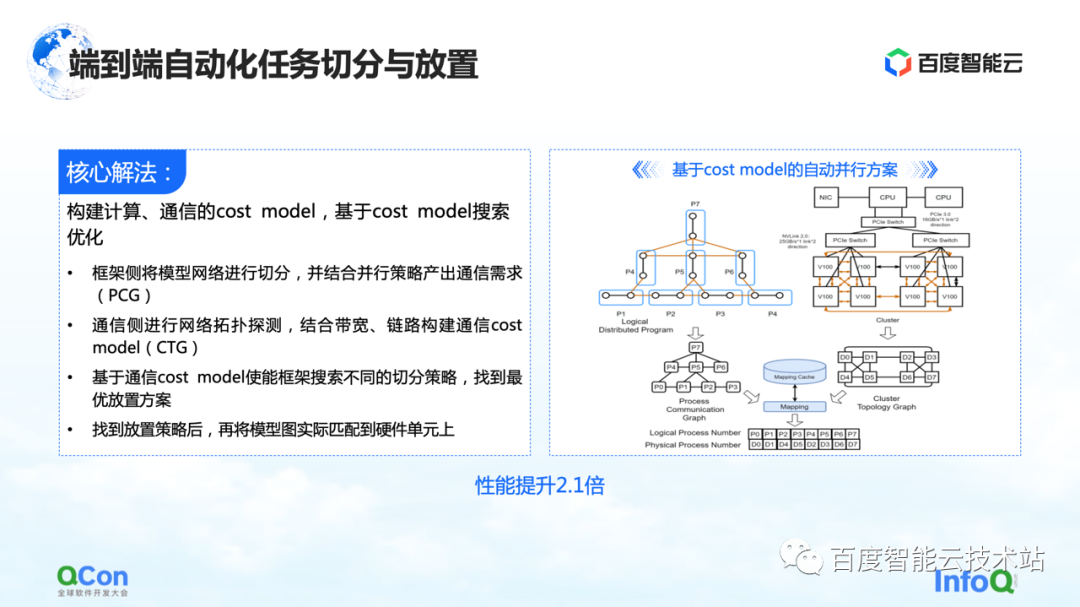
Nuestra solución central es construir un modelo de costos para computación y comunicación, y luego realizar una optimización de búsqueda basada en el modelo de costos. De esta manera se produce un mapeo óptimo.
En todo el proceso, la red modelo en el lado del marco se abstraerá y segmentará primero, y se mapeará en un diagrama de marco informático. Al mismo tiempo, se modelarán las capacidades informáticas y de comunicación del clúster autónomo y del clúster para crear un mapa de topología del clúster.
Cuando tenemos los requisitos de computación y comunicación en el modelo en el lado izquierdo de la imagen de la derecha, y las capacidades de computación y comunicación en el hardware en el lado derecho de la imagen, podemos dividir y mapear el modelo a través de algoritmos gráficos u otras búsquedas. métodos, y finalmente obtener una solución óptima en la parte inferior de la figura de la derecha.
En el proceso de entrenamiento del modelo grande real, el rendimiento final se puede mejorar 2,1 veces de esta manera.
4. El desarrollo de grandes modelos favorece la evolución de la infraestructura
Finalmente, discutiré con ustedes qué nuevos requisitos impondrá el modelo grande a la infraestructura en el futuro.
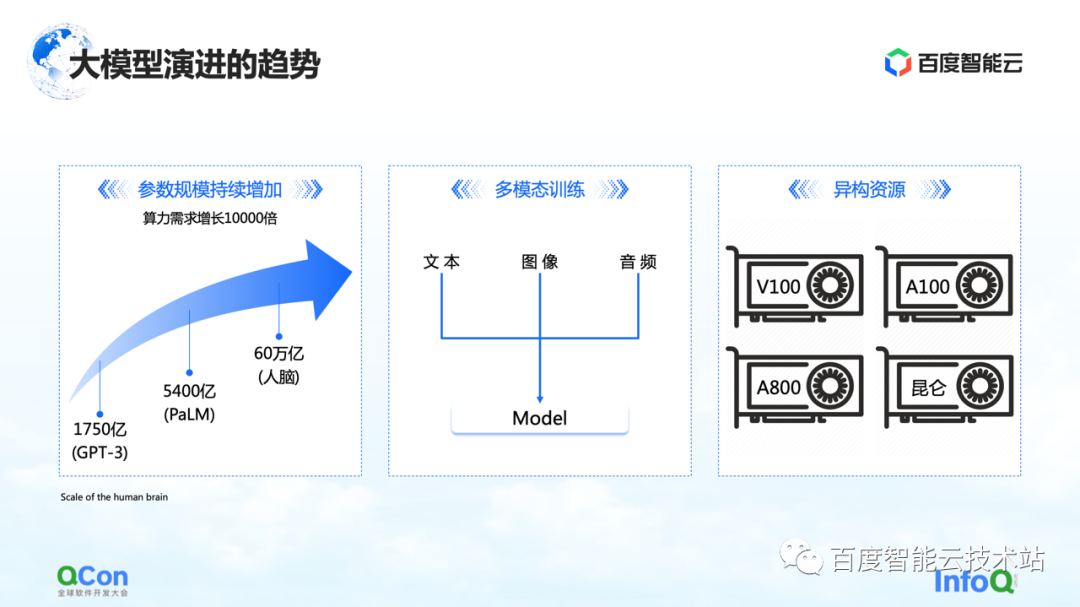
Hay tres cambios que estamos viendo hasta ahora. El primero son los parámetros del modelo, y los parámetros del modelo seguirán creciendo, de 175 000 millones en GPT-3 a 540 000 millones en PaLM. En cuanto al valor final del crecimiento futuro de los parámetros, podemos referirnos al cerebro humano con una escala de unos 60 billones de parámetros.
El segundo es el entrenamiento multimodal. En el futuro trataremos con más datos modales. Los diferentes datos modales traerán más desafíos para el almacenamiento, la computación y la memoria de video.
El tercero son los recursos heterogéneos. En el futuro tendremos recursos cada vez más heterogéneos. En el proceso de formación, varios tipos de poder de cómputo, cómo usarlos mejor es también un desafío urgente por resolver.
Al mismo tiempo, desde una perspectiva comercial, puede haber diferentes tipos de trabajos en un proceso de capacitación completo, y puede haber capacitación tradicional GPT-3, capacitación de aprendizaje por refuerzo y tareas de etiquetado de datos al mismo tiempo. Cómo ubicar mejor estas tareas heterogéneas en nuestro grupo heterogéneo será un problema mayor.
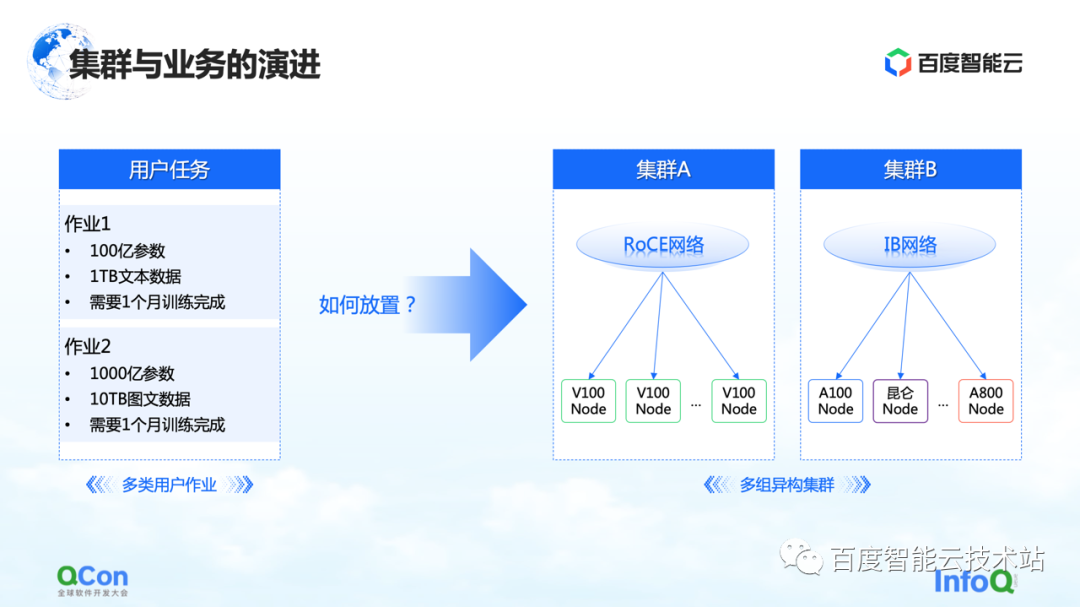
Hemos visto varios métodos ahora, uno de los cuales es la optimización de extremo a extremo basada en una vista unificada: unificar todo el modelo y los recursos heterogéneos en la vista, y extender el modelo de costos basado en la vista unificada, que puede admitir tarea y trabajo múltiple en Colocación bajo grupos de recursos heterogéneos. Combinado con la capacidad de programación elástica, puede detectar mejor los cambios de los recursos del clúster.
Todas las capacidades mencionadas anteriormente se han integrado en la plataforma informática heterogénea de IA de Baidu Baige.
--FIN--
Lectura recomendada :
Hablando sobre la aplicación del algoritmo gráfico en la escena de actividad en anti-trampas
Serverless: práctica de escalado flexible basada en retratos de servicio personalizados
Método de descomposición de acciones en la aplicación de animación de imágenes.
Carretera de aceleración de datos de la plataforma de rendimiento
Edición AIGC Proceso de producción de video Práctica de arreglos
Los ingenieros de Baidu hablan sobre la comprensión del video