1. Estructura de almacenamiento lógico:


Espacio de tablas (archivo ibd): una instancia de Mysql puede corresponder a varios espacios de tablas para almacenar registros, índices y otros datos.
Segmento: dividido en segmento de datos, segmento de índice, segmento de reversión,
InnoDB es una tabla de organización de índices, el segmento de datos es el nodo hoja del árbol B+, el segmento de índice es el nodo no hoja del árbol B+ y el segmento se usa para administrar múltiples áreas (Extensión)
Área: la estructura de la unidad en el espacio de tabla. El tamaño de cada área es 1 M. De forma predeterminada, el tamaño de página del motor de almacenamiento InnoDB es 16 K, es decir, hay 64 páginas consecutivas en un área.
Página: es la unidad más pequeña de administración de disco del motor de almacenamiento InnoDB. Cada tamaño de página es de 16 KB. Para garantizar la continuidad de la página, el motor de almacenamiento InnoDB se aplica a 4-5 áreas del disco cada vez.
Fila: el motor de almacenamiento InnoDB se almacena por fila
Trx_id: Cada vez que se cambie un registro, se asignará a la columna oculta trx_id el ID de la transacción correspondiente, que es el ID de la última transacción de operación
Roll_pointer: Cada vez que se modifica un registro, la versión anterior se escribirá en el registro de deshacer, y luego esta columna oculta es equivalente a un puntero, a través del cual se puede encontrar la información antes de la modificación del registro.
2. Arquitectura InnoDB

2.1 Estructura de la memoria
2.1.1 BufferPool: grupo de almacenamiento intermedio
El grupo de búfer es un área en la memoria, que puede almacenar en caché los datos reales que se operan con frecuencia en el disco. Al realizar adiciones, eliminaciones, modificaciones y consultas, los datos en el grupo de búfer se operarán primero (si no hay datos en el búfer en este momento, se cargarán desde el disco y la memoria caché), y luego se actualizarán en el disco con una cierta frecuencia o regla para reducir la cantidad de E/S del disco y acelerar el procesamiento.
Si no hay un búfer, cada operación de adición, eliminación, modificación y consulta operará en el espacio del disco y habrá una gran cantidad de E/S de disco. consume mucho rendimiento, por lo que es necesario reducir la E/S del disco tanto como sea posible.
La unidad de procesamiento del grupo de búfer es una página, y la capa inferior utiliza una estructura de datos de lista enlazada para administrar la página. Según el estado, la página se divide en tres tipos:
- página gratuita: página gratuita, no utilizada
- página limpia: página usada, los datos no han sido modificados
- Página sucia: página sucia, página usada, los datos se han modificado y los datos son inconsistentes con los datos en el disco
2.2.2 Cambiar búfer: cambiar el búfer
Al ejecutar una declaración DML, si las páginas de datos no están en el Buffer Pool, el disco no se operará directamente, pero los cambios de datos actuales se almacenarán en el Change Buffer (cambio de buffer), y cuando los datos se lean en el future y, a continuación, combine y restaure los datos en el Buffer Pool y, a continuación, actualice los datos combinados en el disco.
Función: cada operación de disco causará una gran cantidad de E/S de disco. Con ChangeBuffer, el proceso de fusión se puede realizar en el grupo de búfer, lo que reducirá en gran medida la E/S de disco.
2.2.3 Índice de hash adaptativo:
El índice de hash adaptativo se utiliza para optimizar la consulta de datos de Buffer Pool (grupo de búfer) InnoDB monitoreará la consulta de cada página de índice en la tabla y creará un índice de hash si encuentra que el índice de hash puede mejorar la velocidad. Nota: el sistema completa automáticamente el índice Hash adaptativo, sin intervención manual, según la situación.
El índice hash adaptativo tiene un interruptor de bandera para establecer si se habilita: adaptive_hash_index.
2.2.4 Búfer de registro: búfer de registro
Búfer de registro, guarde los datos de registro (rehacer registro, deshacer registro) para escribirlos en el disco, el valor predeterminado es 16 MB, el registro se actualizará periódicamente en el disco, si necesita actualizar, insertar o eliminar muchas filas de transacciones, aumentar el tamaño del búfer de registro Puede guardar disco IO
parámetro:
InnoDB_log_buffer_size: tamaño del búfer,
InnoDB_flush_log_at_trx_commit: cuando el registro se vacía en el disco (este parámetro tiene 3 valores: 1, 0, 2)
1. Cada vez que se confirma una transacción, se descarga en el disco
0. Los registros se escriben y descargan en el disco cada segundo
2. Después de confirmar cada transacción, se actualiza en el disco cada segundo
2.2 Estructura del disco
2.2.1 System Tablespace: El tablespace del sistema es el área de almacenamiento de [Change Buffer ] en la estructura de la memoria. Parámetros: innodb_data_file_path
2.2.2 Tablespace de archivo por tabla: el tablespace de cada archivo de tabla contiene los datos y los índices de una única tabla InnoDB y se almacena en un único archivo de datos en el sistema de archivos. Parámetro: innodb_file_per_table (habilitado por defecto)
2.2.3 Tablespace general: Tablespace general , que debe crearse a través de la sintaxis de creación de TableSpace, que se puede especificar al crear una tabla. (equivalente al hecho de que podemos crear manualmente el espacio de tabla nosotros mismos y luego especificar el espacio de tabla que creamos manualmente al crear una nueva tabla)
2.2.4 Undo Tablespace: undo tablespace , la instancia de MySQL creará automáticamente dos tablespaces de deshacer predeterminados (16 MB predeterminados) durante la inicialización para almacenar los registros de registro de deshacer.
2.2.5 Espacio de tabla temporal: Espacio de tabla temporal , InnoDB utilizará el espacio de tabla temporal de la sesión y el espacio de tabla temporal global para almacenar datos de tablas temporales creados por los usuarios, etc.
2.2.6 Archivos de búfer de doble escritura: búfer de doble escritura Antes de que el motor InnoDB vacíe la página de datos del grupo de búfer al disco, primero escribe la página de datos en el archivo de búfer de doble escritura, lo cual es conveniente para la recuperación de datos cuando el sistema es anormal.
2.2.7 Registro de rehacer: el registro de rehacer , que realiza la persistencia de las transacciones, consiste en un búfer de registro de redo (búfer de redo) y un archivo de registro de redo (redo de redo) , el primero está en la memoria y el segundo está en el disco. Cuando se confirma la transacción, toda la información de modificación se colocará en el registro, que se utiliza para la recuperación de datos cuando se producen errores al vaciar páginas sucias en el disco.
2.3 Hilos de fondo
Función: actualice los datos en el grupo de búfer de InnoDB en el archivo de disco en el momento adecuado.
2.3.1 Subproceso maestro
El subproceso de fondo principal es responsable de programar otros subprocesos y también es responsable de actualizar de forma asincrónica los datos en el grupo de búfer en el disco para mantener la consistencia de los datos. También incluye actualizar páginas sucias, fusionar e insertar cachés y reciclar páginas de deshacer.
2.3.2 Subproceso de E/S
En el motor de almacenamiento InnoDB, AIO se usa ampliamente para procesar solicitudes de IO, lo que puede mejorar en gran medida el rendimiento de la base de datos, y IO Thread es el principal responsable de la devolución de llamada de estas solicitudes de IO.

2.3.3 Hilo de purga
Se utiliza principalmente para reciclar el registro de deshacer que ha enviado la transacción. Una vez confirmada la transacción, es posible que no se utilice el registro de deshacer, por lo que se utiliza para reciclar
2.3.4 Subproceso de limpieza de página
Un subproceso que ayuda al subproceso maestro a eliminar las páginas sucias en el disco, lo que puede reducir la presión de trabajo del subproceso maestro y reducir el bloqueo.
3. Principio de negocio
Una transacción es una colección de operaciones. Es una unidad de trabajo indivisible. Una transacción envía o revoca una solicitud de operación al sistema como un todo. Estas operaciones tienen éxito o fallan al mismo tiempo .
1. Atomicidad Una transacción debe considerarse como una unidad mínima indivisible. Todas las operaciones en la transacción completa se envían con éxito o todas fallan. Para una transacción, es imposible realizar solo una parte de las operaciones.
2. Consistencia (Consistencia) Si la base de datos es consistente antes de ejecutar la transacción, entonces la base de datos sigue siendo consistente después de ejecutar la transacción;
3. Aislamiento Las operaciones de las Transacciones son independientes y transparentes sin afectarse entre sí. Las transacciones se ejecutan de forma independiente. Esto generalmente se logra usando cerraduras. Si el resultado del procesamiento de una transacción afecta a otras transacciones, se retirarán otras transacciones. El 100 % de aislamiento de las transacciones requiere sacrificar la velocidad.
4. Durabilidad (Durability) Una vez comprometida la transacción, el resultado es permanente. Incluso si ocurre una falla del sistema, se puede recuperar.
La atomicidad, la consistencia y la durabilidad están controladas por redolog y undo log
El aislamiento está controlado por cerraduras y MVCC
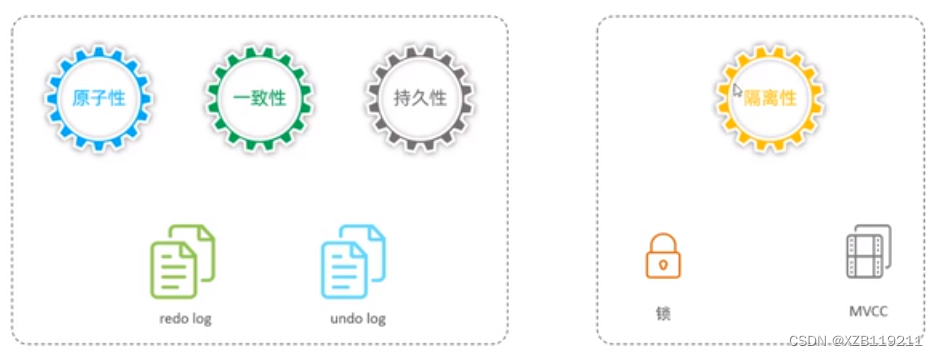
—> La persistencia está garantizada por el registro de rehacer
Redo Log: registro de redo, que se da cuenta de la persistencia de las transacciones. Consta de registro de redo (búfer de redo) y registro de redo (redo log). El primero está en la memoria y el segundo está en el disco. Después de confirmar la transacción, todos la información de modificación se coloca en el registro, que se utiliza para la recuperación de datos cuando se produce un error al vaciar páginas sucias en el disco.

Explicación: La figura muestra el mecanismo de procesamiento en InnoDB para garantizar la persistencia de la transacción después de que se confirme una transacción. Primero, después de que se confirme la transacción, irá a la página de datos correspondiente en el Buffer Pool en la estructura de memoria para modificar la datos Espere la operación, después de que se complete la operación, la transacción en la memoria se ha ejecutado en este momento, pero no se ha actualizado en el disco a tiempo, la página de datos actualizada en la memoria actual se llama página sucia, y cuando la operación se realiza en el Buffer Pool, la página de datos en la memoria. Todas las operaciones se registrarán en el Redolog Buffer en el área, y luego se actualizarán periódicamente en el Redo Log en el disco por el subproceso en segundo plano, y luego cuando un se produce un error cuando los datos en el Buffer Pool se actualizan en el disco, los datos se pueden procesar a través del Redo Log en la recuperación del disco. Cuando los datos del Buffer Pool están correctamente sincronizados con el disco, el redolog en el disco es inútil, por lo que los dos redologs en el disco se copian entre sí para lograr actualizaciones oportunas. Este método de escribir registros primero y luego sincronizar datos se llama WAL (Write-Ahead Log)
Entonces, ¿por qué molestarse, primero escribir en el Redolog Buffer y luego transferirlo al Redo Log? ¿No sería suficiente actualizar los datos del Buffer Pool al disco después de cada transacción? Aquí hay un problema. La mayoría de las operaciones en las páginas de datos en una transacción son aleatorias. Si cada transacción se descarga inmediatamente en el disco, se generarán múltiples E/S de disco, lo que consumirá una gran cantidad de rendimiento. Entonces, pasamos Redolog para asegurar los datos. persistencia de esta manera.
—> La atomicidad está garantizada por el registro de deshacer
registro de deshacer: registro de reversión, utilizado para registrar la información antes de que se modifiquen los datos, la función incluye: proporcionar reversión y MVCC (concurrencia de control de múltiples versiones)
El registro de deshacer y el registro de rehacer registran los registros físicos de manera diferente. Es un registro lógico. Se puede considerar que cuando se elimina un registro, se registrará un registro de inserción correspondiente en el registro de deshacer, y viceversa. Cuando se actualiza un registro, se se registrará el registro correspondiente. actualizar registros, al ejecutar la reversión, puede leer el contenido correspondiente de los registros lógicos en el registro de deshacer y revertir.
Destrucción del registro de deshacer: Se genera cuando se ejecuta la transacción. Cuando se confirma la transacción, el registro de deshacer no se eliminará de inmediato. Estos registros también se pueden usar para MVCC.
Almacenamiento de registro de deshacer: se administra y registra en forma de segmentos, almacenados en el segmento de reversión de reversión, que contiene 1024 segmentos de registro de deshacer.
4, MVCC
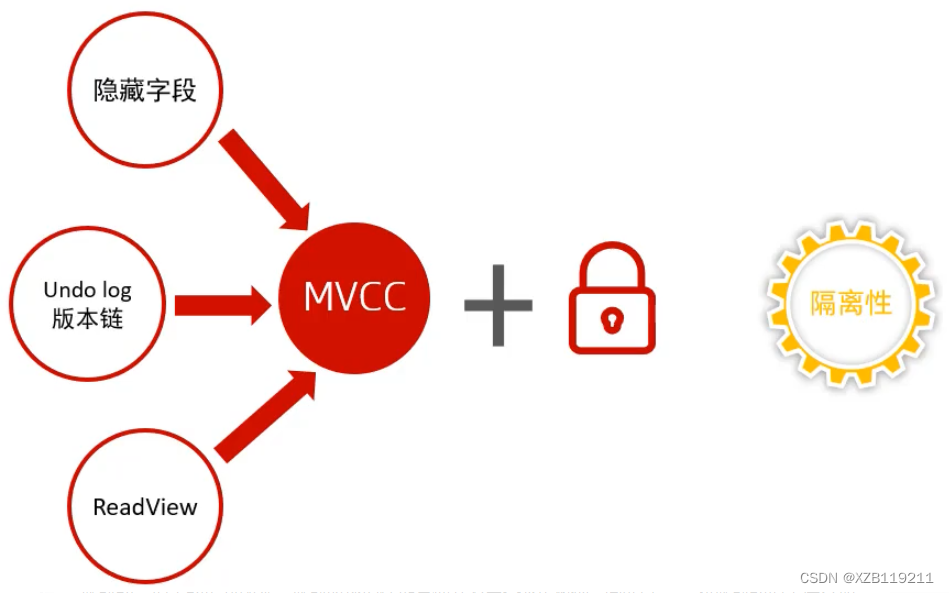
4.1 Concepto
¿Qué es MVCC?
MVCC es para administrar múltiples versiones de datos al acceder a la base de datos simultáneamente, para evitar bloquear la solicitud de lectura de datos debido a la necesidad de agregar un bloqueo de escritura al escribir datos, lo que genera el problema de que los datos no se pueden leer al escribir datos.
En términos sencillos, MVCC guarda la versión histórica de los datos y decide si mostrar los datos de acuerdo con el número de versión de los datos comparados. Puede lograr el efecto de aislamiento de la transacción sin agregar un bloqueo de lectura y, finalmente, puede leer los datos. Modificar al mismo tiempo, al modificar datos, puede leerlos al mismo tiempo, lo que mejora en gran medida el rendimiento de concurrencia de las transacciones.
4.2 Puntos básicos de conocimiento de la implementación de InnoDB MVCC
4.2.1 Número de versión de la transacción
Antes de que se inicie cada transacción, se obtendrá de la base de datos una ID de transacción que aumenta automáticamente, y el orden de ejecución de las transacciones se puede juzgar a partir de la ID de transacción.
4.2.2 Columnas ocultas de tablas
| DB_TRX_ID | Registre el ID de transacción de la transacción de datos; |
| DB_ROLL_PTR | Puntero al puntero de posición de los datos de la versión anterior en el registro de deshacer; |
| DB_ROW_ID | Id. oculto, al crear una tabla sin un índice adecuado como índice agrupado, el Id. oculto se utilizará para crear un índice agrupado; |
4.2.3 Deshacer registro
El registro de deshacer se utiliza principalmente para registrar el registro antes de que se modifiquen los datos. Antes de que se modifique la información de la tabla, los datos se copiarán en el registro de deshacer. Cuando se deshace la transacción, se pueden restaurar los datos en el registro de deshacer.
Propósito del registro de deshacer
(1) Garantizar la atomicidad y la consistencia cuando se revierte la transacción. Cuando se revierte la transacción, los datos del registro de deshacer se pueden usar para la recuperación.
(2) Los datos utilizados para la lectura de instantáneas de MVCC En el control de versiones múltiples de MVCC, al leer los datos de la versión histórica del registro de deshacer, diferentes números de versión de transacción pueden tener sus propias versiones de datos de instantáneas independientes.
4.2.4 Relación entre el número de versión de la transacción, la columna oculta de la tabla y el registro de deshacer
Utilizamos un proceso de simulación de modificación de datos para comprender la relación entre el número de versión de la transacción, las columnas ocultas y la cancelación del registro.
(1) Primero prepare una tabla de datos original
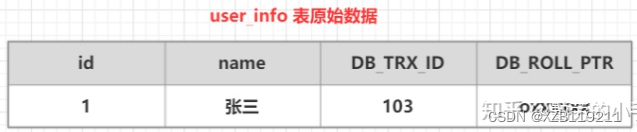
(2) Inicie una transacción A: ejecute update user_info set name = "Li Si" donde id=1 en la tabla de información de usuario, y se realizará el siguiente proceso
| 1. Primero obtenga un número de transacción 104 |
| 2. Copie los datos antes de la modificación de la tabla user_info en el registro de deshacer |
| 3. Modificar los datos de la tabla user_info id=1 |
| 4. Cambie el número de versión de transacción de datos modificado al número de versión de transacción actual y apunte la dirección DB_ROLL_PTR a la dirección de datos de registro de deshacer. |
(3) El resultado de la ejecución final se muestra en la figura

4.2.5 cadena de versión de deshacer registro
La modificación del mismo registro por diferentes transacciones o la misma transacción hará que el registro de deshacer del registro genere una lista vinculada de versión de registro. El encabezado de la lista vinculada es el último registro antiguo y el final de la lista vinculada es el más antiguo registro.

4.2.6 Vista de lectura
Después de abrir cada transacción en InnoDB, obtendrá una (vista de lectura). La copia guarda principalmente los números de ID de las transacciones que están activas (sin compromiso) en el sistema de base de datos actual. De hecho, simplemente hablando, esta copia guarda una lista de otras ID de transacciones en el sistema que no debería ver esta transacción. ( Cuando se abre cada transacción, se le asignará una identificación, que se incrementa, por lo que la última transacción tiene un valor de identificación mayor )
Así que sabemos que la vista de lectura se utiliza principalmente para el juicio de visibilidad, es decir, cuando ejecutamos una lectura instantánea para una determinada transacción, creamos una vista de lectura de vista de lectura para el registro y la comparamos con una condición para juzgar si la transacción actual puede ver qué versión de los datos pueden ser los últimos datos actuales, o una determinada versión de los datos en el registro de deshacer registrado en esta fila.
Read View sigue un algoritmo de visibilidad, principalmente extrayendo el DB_TRX_ID (es decir, el ID de la transacción actual) en el último registro de los datos que se van a modificar y comparándolo con los ID de otras transacciones activas en el sistema (mantenidas por Read View ), si sigue DB_TRX_ID Los atributos de Vista de lectura han hecho algunas comparaciones, que no se ajustan a la visibilidad, luego use el puntero de reversión DB_ROLL_PTR para sacar el DB_TRX_ID en el Registro de deshacer y compararlos nuevamente, es decir, recorrer el DB_TRX_ID de la lista enlazada (desde el principio de la cadena hasta el final de la cadena, es decir, desde el Modificar y verificar más reciente), hasta encontrar un DB_TRX_ID que cumpla con ciertas condiciones, entonces el registro antiguo donde se encuentra este DB_TRX_ID es el última versión antigua que la transacción actual puede ver
Varias propiedades importantes de la vista de lectura:
| m_ids: conjunto de números de versión de transacción activos (no comprometidos) del sistema actual |
| min_trx_id: ID mínimo de transacción activa |
| max_trx_id: ID de transacción preasignado, el ID de transacción máximo actual + 1 (porque el ID de transacción se incrementa automáticamente) |
| Creator_trx_id: crea el número de versión de la transacción de la vista de lectura actual |
Leer ver condiciones coincidentes:

1. ID de transacción de datos==creator_trx_id
Si se establece, puede acceder a esta versión, indicando que los datos fueron modificados por la transacción actual
2. Si el ID de la transacción de datos es <min_trx_id, se mostrará
Si la ID de la transacción de datos es menor que la ID de transacción activa mínima en la vista de lectura, es seguro que los datos ya existían antes de que se iniciara la transacción actual, por lo que se pueden mostrar.
3. No se mostrará el ID de transacción de datos>=max_trx_id
Si el ID de transacción de datos es mayor que el ID de transacción máximo del sistema actual en la vista de lectura, significa que los datos se generan después de crear la vista de lectura actual, por lo que los datos no se mostrarán.
4. Si min_trx_id<=ID de transacción de datos<max_trx_id, coincide con el conjunto de transacciones activas trx_ids
Si la ID de transacción de los datos es mayor que la ID de transacción activa más pequeña y menor o igual que la ID de transacción más grande del sistema, esta situación indica que es posible que los datos no se hayan enviado cuando comenzó la transacción actual.
Entonces, en este momento, debemos hacer coincidir el ID de transacción de los datos con el conjunto de transacciones activas trx_ids en la vista de lectura actual:
Caso 1: si el ID de transacción no existe en la colección trx_ids (significa que la transacción se ha confirmado cuando se genera la vista de lectura), se pueden mostrar los datos en este caso.
Caso 2: si el ID de transacción existe en trx_ids, significa que los datos no se han enviado cuando se genera la vista de lectura, pero si el ID de transacción de los datos es igual a author_trx_id, significa que los datos son generados por el la transacción actual en sí, y los datos generados por sí mismos se pueden ver por sí mismos, por lo que en este caso los datos también se pueden mostrar.
Caso 3: si el ID de la transacción existe en trx_ids y no es igual a created_trx_id, significa que los datos no se han enviado cuando se genera la vista de lectura y no se generan por sí mismos, por lo que los datos no se pueden mostrar en este caso. .
5. Cuando no se cumple la condición de vista de lectura, los datos se obtienen del registro de deshacer
Cuando el ID de transacción de los datos no cumple con la condición de vista de lectura, la versión histórica de los datos se obtiene del registro de deshacer, y luego el número de transacción de la versión histórica de los datos se compara con la condición de vista de lectura hasta que se obtiene una parte. de datos históricos que cumplen la condición se encuentra, o si no se encuentra, devuelve un resultado vacío;
4.3 El principio de InnoDB implementando MVCC

4.3.1 Simular el proceso de implementación de MVCC
A continuación, simulamos el flujo de trabajo de MVCC abriendo dos transacciones simultáneas.
(1) Cree una tabla de información de usuario e inserte datos de inicialización

(2) La transacción A y la transacción B modifican y consultan user_info al mismo tiempo
Transacción A: actualizar el nombre del conjunto de información de usuario = "Lisi"
Transacción B: seleccione * desde user_info donde id=1
pregunta:
Inicie la transacción A primero y ejecute la transacción B después de que la transacción A modifique los datos pero no se confirme. ¿Cuál es el resultado final de la devolución?
El flujo de ejecución es el siguiente:

La descripción del flujo de ejecución en la figura anterior:
1. Transacción A: para iniciar una transacción, primero obtenga un número de transacción 102;
2. Transacción B: Abra la transacción y obtenga el número de transacción 103;
3. Transacción A: Para modificar la operación, primero copie los datos originales en el registro de deshacer, luego modifique los datos, marque el número de transacción y la dirección de la última versión de datos en el registro de deshacer.

4. Transacción B: en este momento, la transacción B obtiene una vista de lectura y el valor correspondiente de la vista de lectura es el siguiente

5. Transacción B: Ejecute la declaración de consulta, y los datos modificados de la transacción A se obtienen en este momento

6. Transacción B: hacer coincidir los datos con la vista de lectura

Se encuentra que las condiciones de visualización de la vista de lectura no se cumplen, por lo que los datos de la versión histórica se obtienen de deshacer lo y luego se comparan con la vista de lectura, y finalmente los datos devueltos son los siguientes.

4.4 Lectura instantánea y lectura actual
Actualmente leyendo:
Lo que se lee es la última versión del registro. Al leer, se debe asegurar que otras transacciones concurrentes no puedan modificar el registro actual, y el registro de lectura se bloqueará. Para las operaciones diarias, tales como: seleccionar... bloquear en modo compartido (bloqueo compartido), seleccionar... para actualizar, actualizar, insertar, eliminar (bloqueo exclusivo) son lecturas actuales
Lectura instantánea:
Una selección simple (sin bloqueo) es una lectura de instantánea. La lectura de instantánea lee la versión visible de los datos registrados, que pueden ser datos históricos. Desbloqueado es un bloqueo sin bloqueo.
Lectura confirmada: cada vez que se selecciona, se genera una lectura instantánea
Lectura repetible: la primera declaración de selección después de iniciar la transacción es donde se lee la instantánea
Serializable: la lectura de la instantánea degenerará en la lectura actual
Hay tres tipos de escenarios de concurrencia de base de datos:
lectura-lectura: sin problemas y sin necesidad de control de concurrencia
Lectura-escritura: hay problemas de seguridad de subprocesos, que pueden causar problemas de aislamiento de transacciones y pueden encontrar lecturas sucias, lecturas fantasma y lecturas no repetibles
Escritura-escritura: hay problemas de seguridad de subprocesos y puede haber problemas con actualizaciones perdidas, como la primera categoría