Tabla de contenido
3.1 El statu quo del desarrollo de aplicaciones de Android en el extranjero
3.2 El statu quo del desarrollo de aplicaciones Android en China
3.3 Análisis de objetivos de construcción del sistema
3.4 Análisis de la función de construcción del sistema
3.4.1 La estructura general del sistema
3.4.2 Módulos de función del sistema
3.4.3 Diagrama de planificación de funciones de aplicación
4.1 Diseño detallado del subsistema de visualización de palabras de respaldo en la recepción
4.1.1 Módulo de funciones de revisión
4.1.2 Módulo de funciones estadísticas
4.1.3 Módulo de función de diccionario
4.1.4 Configuración de módulos de función
4.2 Diseño detallado del subsistema de gestión de datos de fondo
5.1.1 Tabla de resumen de la tabla de la base de datos
1. Sobre este tema
Este diseño es principalmente una revisión y aplicación consolidada del desarrollo de la tecnología Android, la base de datos y otros cursos aprendidos en la universidad. De acuerdo con el libro de palabras determinado por el usuario y la cantidad de aprendizaje personalizado en la configuración, este diseño requiere que el sistema ayude al usuario a organizar la revisión de palabras todos los días de manera planificada; el usuario puede elegir libremente reemplazar el libro de palabras y restablecer los registros de aprendizaje; se puede proporcionar a través de las principales plataformas de traducción API para encontrar palabras y oraciones de ejemplo, puede comprender sus propios registros de aprendizaje y memoria, y puede personalizar el tema del sistema;
2. Plataforma de desarrollo
La plataforma de desarrollo de esta asignatura es:
-
Sistema operativo: Microsoft Windows 10
-
Lenguajes de programación: Java, XML
-
Herramienta IDE: AndroidStudio 4.1.1
-
Complemento IDE: navegador de base de datos
-
Servidor de base de datos: SQLite
-
Otras herramientas: smartphones o emuladores con Android 7.0 o superior
3. Análisis del sistema
Este capítulo lleva a cabo principalmente análisis de requisitos más detallados, análisis de objetivos y análisis de funciones en la construcción del sistema.
3.1 El statu quo del desarrollo de aplicaciones de Android en el extranjero
Según la encuesta, la cantidad de usuarios de Internet en los Estados Unidos en 2019 alcanzó nada menos que los 290 millones, la tasa de uso de Internet alcanzó el 89,4 % y el uso promedio diario de teléfonos móviles supera las tres horas. Entre las aplicaciones gratuitas, los tipos más populares son las redes sociales, los juegos, la oficina y los videos en línea; entre las aplicaciones pagas, los tipos más populares son las herramientas y los juegos en línea. En la plataforma Android, GooglePlay tiene una gran cantidad de aplicaciones, su número y descargas son mucho más que cualquier tienda de aplicaciones nacional, lo que demuestra que la marea de usar aplicaciones móviles en el extranjero ya llegó, estimulando las necesidades de desarrollo de más aplicaciones móviles. [17] A diferencia de la mayoría de los desarrolladores nacionales que todavía usan Java como lenguaje de desarrollo en la elección del lenguaje de desarrollo de aplicaciones, la mayoría de los desarrolladores extranjeros generalmente eligen Kotlin como lenguaje de desarrollo. [18]
3.2 El statu quo del desarrollo de aplicaciones Android en China
El desarrollo doméstico de Android todavía se basa principalmente en el desarrollo de aplicaciones, que se divide principalmente en tres categorías: desarrollo de aplicaciones para empresas, desarrollo de juegos y desarrollo de aplicaciones en general.
- Las empresas desarrollan aplicaciones. Estas aplicaciones generalmente son requeridas por empresas de gran escala. Estas empresas diseñan principalmente soluciones generales para teléfonos móviles o tabletas para sus propias marcas o para otras marcas.
- Existen dos métodos principales de obtención de beneficios para el desarrollo de aplicaciones de uso general: la subcontratación del desarrollo para empresas extranjeras, la obtención de cuotas publicitarias a través de anuncios integrados y la obtención de beneficios mediante compras pagadas[19].
- Actualmente, el desarrollo de juegos es similar al segundo tipo de desarrollador. Dichas aplicaciones no solo pueden hacer que los usuarios se sientan frescos con respecto a la aplicación, sino que también facilitan ganar dinero a través de compras pagas al utilizar correctamente la psicología diversa de la mayoría de los usuarios.
3.3 Análisis de objetivos de construcción del sistema
El desarrollo de la aplicación de memorización de palabras requiere que los usuarios puedan operar los datos del usuario en cualquier momento y ajustar automáticamente la frecuencia de las tareas diarias y las palabras que aparecen en cada palabra, para satisfacer las necesidades de los usuarios de recitar palabras de manera eficiente; El cálculo de la frecuencia de palabras es particularmente importante.El objetivo de este sistema es maximizar la eficiencia de la recitación de palabras del usuario mediante la organización de la revisión de acuerdo con la combinación de la curva de olvido de Ebbinghaus y la familiaridad del usuario [20]. Además, la aplicación también debe proporcionar estadísticas de familiaridad de usuario intuitivas y mapas de estado de finalización en tiempo real:
- Darse cuenta de la frecuencia de palabras de cálculo de familiaridad
El usuario debe seleccionar la familiaridad de cada palabra al revisar la palabra; la familiaridad incluye cuatro opciones: memorización, comprensión, confusión y olvido. Cada familiaridad será juzgada por el sistema y la revisión se organizará nuevamente bajo la condición de garantizar tarea de hoy. Para garantizar que la memoria de recitación del usuario en el día pueda ser más consolidada y confiable.
- Realice la curva de olvido de Ebbinghaus para calcular la frecuencia de palabras
Esta aplicación hace un uso completo de la curva de olvido de Ebbinghaus para permitir a los usuarios realizar una revisión razonable de las tareas que no son de hoy; el método de cálculo de la curva de olvido de Ebbinghaus solo depende de la marca de tiempo del sistema; está organizada para la revisión del usuario debido al olvido de Ebbinghaus curva La palabra actualizará la tasa de olvido de la palabra (esto no tiene nada que ver con la familiaridad del usuario), asegurando así que la memoria de recitación del usuario de las palabras aprendidas en el pasado sea más consolidada y confiable.
- Realizar estadísticas de aprendizaje
A través de las estadísticas de la base de datos y utilizando la API para mostrar visualmente al usuario en forma de gráfico. Los gráficos estadísticos incluyen gráficos de progreso de aprendizaje de vocabulario actual, gráficos de curvas de olvido de Ebbinghaus y gráficos de estado de aprendizaje; entre ellos, los gráficos de estado de aprendizaje brindan a los usuarios una clara familiaridad del usuario, planes restantes y colecciones de palabras.
- Implementar la manipulación de datos de usuario
A través de la configuración de la interfaz de usuario, el usuario puede personalizar la cantidad de tareas diarias, el usuario puede aprender la gestión de tareas y los temas del sistema, etc., y mejorar aún más la experiencia del usuario y la eficiencia del aprendizaje.
3.4 Análisis de la función de construcción del sistema
3.4.1 La estructura general del sistema
El sistema consta de dos subsistemas: el subsistema de visualización y memorización de palabras en primer plano y el subsistema de gestión de datos en segundo plano. Al mismo tiempo, incluye principalmente dos tipos de análisis de datos JSON y un proceso de análisis de datos XML: análisis de datos de vocabulario y libro de vocabulario de API de palabras fantasma, análisis de datos de API de diccionario de iciba. Entre ellos, el análisis de datos de la API de memorización de palabras fantasma es la parte clave, y es la fuente de datos de todo el vocabulario relacionado.
3.4.2 Módulos de función del sistema
La recepción muestra el subsistema de memorización de palabras.

Una breve descripción del subsistema de devolución de palabras que se muestra en la recepción
- Módulo de revisión: la función principal de la aplicación para recitar palabras, organizar a los usuarios para recitar las palabras correspondientes, actualizar la información del usuario y la base de datos de información de vocabulario;
- Módulo estadístico: muestra el gráfico estadístico en forma de abanico del progreso del aprendizaje del usuario, el histograma del estado de aprendizaje del usuario y el gráfico estadístico de líneas de los datos olvidados de Ebbinghaus;
- Módulo de vocabulario: cambie el vocabulario actual en inglés, vea el vocabulario favorito y busque palabras;
- Módulo de configuración: configure el tema de la aplicación para recitar palabras, la tarea diaria de recitar palabras y operar los datos del usuario;
- Módulo de barra de navegación: ayude a los usuarios a cambiar rápidamente a los módulos funcionales correspondientes y muestre el estilo de cambio de módulo;
Subsistema de gestión de datos de fondo

Breve descripción del subsistema de gestión de datos de fondo
- Inicialización de datos del usuario: inicialice la base de datos de información del usuario actual, incluida la identificación del usuario, la identificación del diccionario utilizada por el usuario, el volumen de la tarea del usuario, el progreso de la tarea del usuario hoy, la marca de tiempo y otra información;
- Inicialización de datos de glosario: inicialice todas las bases de datos de información de vocabulario, incluida la información de solicitud de datos de vocabulario, ID de vocabulario, cantidad de vocabulario, si hay datos de vocabulario, etc.;
- Inicialización de datos de vocabulario: inicialice todas las bases de datos de información de vocabulario, incluida la identificación de vocabulario, información de solicitud de datos de vocabulario, identificación de libro de vocabulario, símbolos fonéticos de vocabulario, dirección de pronunciación de vocabulario, nombre de vocabulario, definición de vocabulario, si el vocabulario está guardado, marca de tiempo de vocabulario, nivel de memoria de vocabulario, vocabulario Familiaridad y frases de ejemplo de vocabulario y otra información;
- Inicialización de oraciones de ejemplo de vocabulario: use la API de iciba para consultar la oración de ejemplo de palabras del vocabulario correspondiente y actualice la base de datos de información de vocabulario;
3.4.3 Diagrama de planificación de funciones de aplicación
La planificación funcional principal del sistema se muestra en la Figura 3-3. Lo que se muestra aquí es solo un enlace general del proceso principal del sistema. La descripción detallada estará involucrada en el diseño detallado de los módulos funcionales más adelante.

4. Diseño del sistema
4.1 Diseño detallado del subsistema de visualización de palabras de respaldo en la recepción
4.1.1 Módulo de funciones de revisión
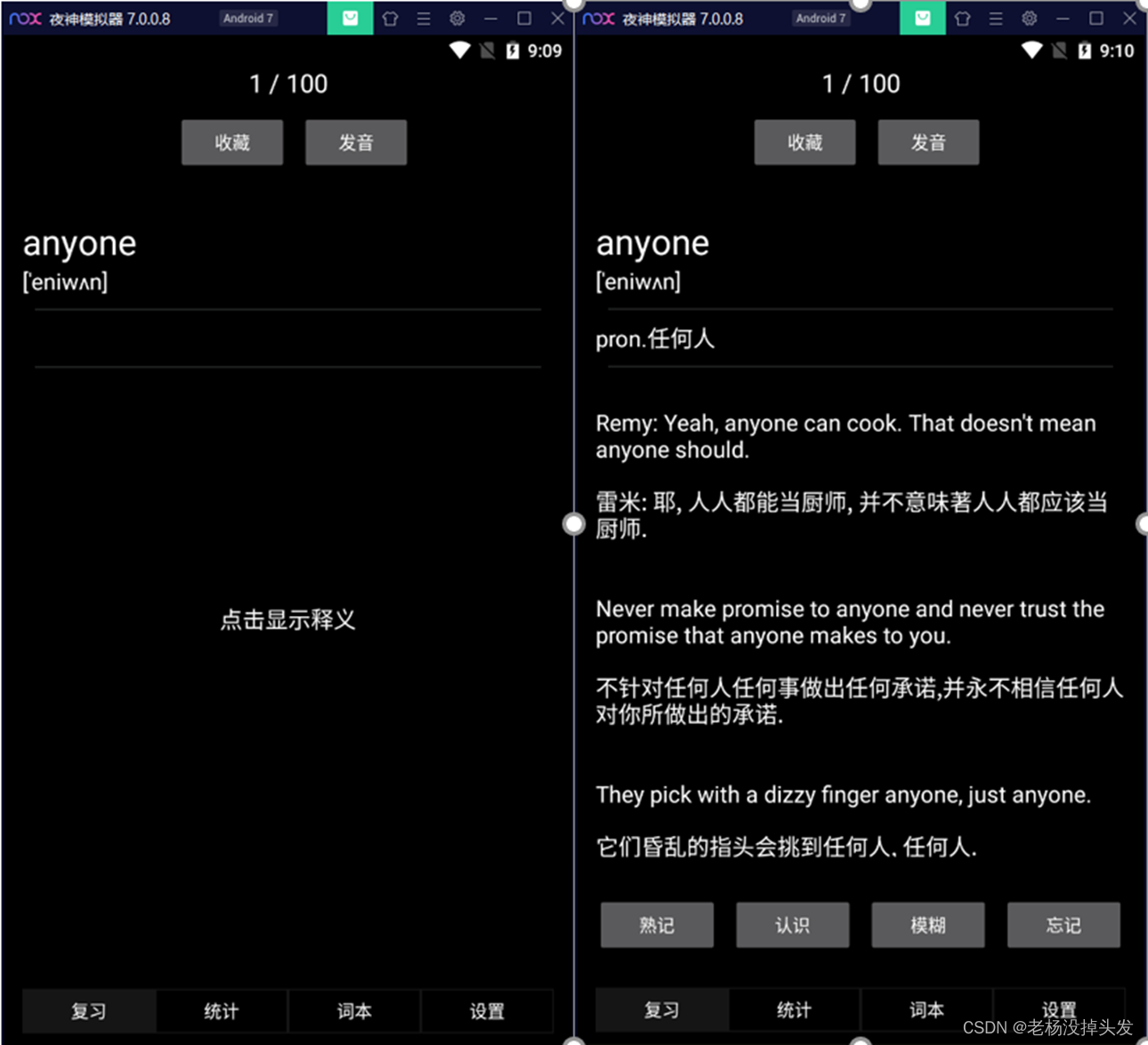
El módulo de función de revisión es el primer fragmento que se muestra al usuario. Su principio de funcionamiento y la interfaz de usuario son las partes más críticas de la aplicación Word Memorizing, que juegan un papel muy importante para motivar a los usuarios a continuar usando la aplicación. Por lo tanto, el diseño del módulo de función de revisión debe prestar atención a la experiencia del usuario y al diseño artístico y, al mismo tiempo, debe ser fácil de usar y completo en información. En el módulo de función de revisión, el cuerpo principal del fragmento se divide en tres marcos de arriba a abajo. El primer marco muestra el progreso del usuario y la información de la tarea de palabra para el día; el segundo marco es el marco de operación del usuario para la palabra actual ( por ejemplo, colección de palabras, pronunciación de palabras y selección de familiaridad, etc.); el tercer cuadro es definición de palabras, símbolos fonéticos, oraciones de ejemplo y otra información.
Para facilitar la descripción, comenzamos con la introducción del segundo cuadro y el tercer cuadro.
Para el usuario, si no se realiza ninguna operación, las partes visibles del segundo cuadro y del tercer cuadro solo tienen palabras, símbolos fonéticos de palabras, pronunciaciones de palabras y colecciones de palabras. La parte del discurso, la definición y las oraciones de ejemplo de la palabra y la parte de selección de familiaridad de la palabra están completamente ocultas. Este proyecto establecerá el evento de clic en la oración de ejemplo de palabra y la parte de palabra del control del discurso y hará clic en el texto al solicitarlo. Después de que el usuario realice la operación correspondiente, se mostrará la selección de familiaridad del usuario del segundo cuadro y el tercer cuadro, la palabra del discurso y la oración de ejemplo de la palabra. Entre ellos, hay cuatro opciones para la familiaridad del usuario, que son memorización, comprensión, confusión y olvido. Las funciones de operación de palabras y selección de familiaridad son las siguientes:
- Memorización: la tabla de datos de vocabulario del usuario registra el indicador de memorización de la palabra actual y existe un 0 % de posibilidades de que la palabra se programe para su revisión nuevamente, independientemente de la carga de tareas de hoy.
- Reconocimiento: la tabla de datos de vocabulario del usuario registra el indicador de reconocimiento de la palabra actual y existe un 20 % de posibilidades de que la palabra se programe para su revisión nuevamente, independientemente de la carga de tareas de hoy.
- Difuso: la tabla de datos de vocabulario del usuario registra el indicador difuso de la palabra actual y existe un 40 % de posibilidades de que la palabra se programe para su revisión nuevamente sin contar la carga de tareas de hoy.
- Olvidar: la tabla de datos de vocabulario del usuario registra el indicador de olvido de la palabra actual y existe un 60 % de posibilidades de que la palabra se programe para su revisión nuevamente, independientemente de la carga de tareas de hoy.
- Colección de palabras: la tabla de datos de vocabulario del usuario registra la marca de la palabra actual como favorita o no favorita, y puede verificar las operaciones favoritas y no favoritas nuevamente en "Mis favoritos" en el módulo de funciones del libro de palabras.
- Pronunciación de palabras: reproduce la pronunciación de personas reales según la dirección en la tabla de datos de vocabulario;
Mientras inicializa los datos, la aplicación preparará wordList y hitList. Entre ellos, la lista de palabras contiene todas las palabras que el usuario debe completar hoy, y la lista de aciertos contiene todas las palabras de aciertos (aquí, todas las palabras que están programadas para revisarse nuevamente debido a la familiaridad se convierten en las palabras de aciertos, lo mismo a continuación) . Los usuarios deben elegir uno de estos cuatro niveles de familiaridad para revisar la siguiente palabra. Al prepararse para organizar la próxima revisión de palabras, habrá un 50% de probabilidad de que la palabra provenga de la lista de aciertos;
Los datos del progreso de hoy y las tareas diarias en el primer marco son todos de la tabla de datos del usuario. Cuando el usuario está haciendo una selección de familiaridad y la siguiente palabra proviene de la lista de palabras, el progreso de hoy se incrementa en uno. El valor máximo del progreso de hoy no es mayor que la cantidad de tareas diarias; de lo contrario, aparecerá el mensaje de que la tarea se ha completado. Cuando el usuario no haya completado la tarea de ayer, el progreso de hoy se restablecerá a 1, pero al organizar la revisión, el cálculo aún comenzará a partir de la palabra que no se seleccionó ayer por familiaridad. Cuando el usuario restablece la cantidad de la tarea en el módulo de función de configuración, se divide en las siguientes situaciones:
- La cantidad de tareas diarias establecida por el usuario es mayor que la cantidad de tareas diarias original: el módulo de función de revisión agregará vocabulario recientemente ampliado a la lista de palabras y actualizará el valor de la cantidad de tareas diarias de acuerdo con el valor recién establecido;
- La cantidad de tareas diarias recién configurada por el usuario es más pequeña que la cantidad de tareas diarias original: el módulo de función de revisión eliminará las palabras redundantes en la lista de palabras de atrás hacia adelante en orden y actualizará el valor de la cantidad de tareas diarias de acuerdo con las nuevas valor ajustado. Si el nuevo valor es menor que el progreso de hoy, restablezca el progreso de hoy a la cantidad máxima de tareas diarias y avise que la tarea de hoy se ha completado. Pero mañana aún comenzará a contar desde la palabra que no ha sido seleccionada por familiaridad.
Revise la demostración del módulo de función (tema diurno y tema nocturno)

4.1.2 Módulo de funciones estadísticas
El módulo de función estadística es un fragmento diseñado para reflejar intuitivamente la situación de aprendizaje del usuario, y todos sus datos estadísticos provienen de la base de datos y se actualizan en tiempo real. Por lo tanto, a excepción de ciertos eventos de respuesta de clic (como gráficos estadísticos en forma de abanico que pueden rotar en su lugar con los gestos del usuario), los usuarios no pueden editar ni modificar gráficos estadísticos directamente. Utiliza el marco de dibujo de gráficos HelloChart, que puede dibujar varios gráficos estadísticos hermosos. A través de HelloChart, este módulo incluye un gráfico de abanico del progreso del aprendizaje del usuario, un gráfico de líneas de datos de olvido de Ebbinghaus y un gráfico de columnas del estado de aprendizaje del usuario:
- Gráfico estadístico en forma de abanico del progreso del aprendizaje: estadísticas realizadas para el vocabulario actual, incluido el vocabulario planificado restante, el vocabulario sin terminar hoy, el vocabulario completo, información breve del vocabulario actual y el progreso del aprendizaje;
- Gráfico de líneas de datos de olvido de Ebbinghaus: el psicólogo alemán Ebbinghaus realizó un estudio sistemático sobre el fenómeno del olvido. Usó sílabas sin sentido como materiales de memoria y dibujó los datos experimentales en una curva, llamada Curva de olvido de Ebbinghaus. La ordenada de la curva representa la cantidad de retención de la memoria, que muestra una ley de desarrollo del olvido: el proceso de olvido está desequilibrado. Al comienzo de la memorización, el olvido es muy rápido y luego se ralentiza gradualmente. Después de un cierto período de tiempo, ya casi no se olvida, es decir, el desarrollo del olvido es "primero rápido y luego lento". Cada palabra en este proyecto tiene un valor de memoria correspondiente y una marca de tiempo al revisar, que se usa para representar la ordenada de la curva de olvido de Ebbinghaus. Cabe señalar que el valor de la ordenada sólo está relacionado con su sello de tiempo correspondiente.
- Histograma de estado de aprendizaje: se realizan estadísticas de todas las palabras que el usuario ha aprendido. El eje vertical es el número de palabras, y el eje horizontal incluye estadísticas de familiaridad del usuario, palabras favoritas y el volumen pendiente restante de hoy.
Captura de pantalla larga de la demostración del módulo de función estadística (tema de día y tema de noche)

4.1.3 Módulo de función de diccionario
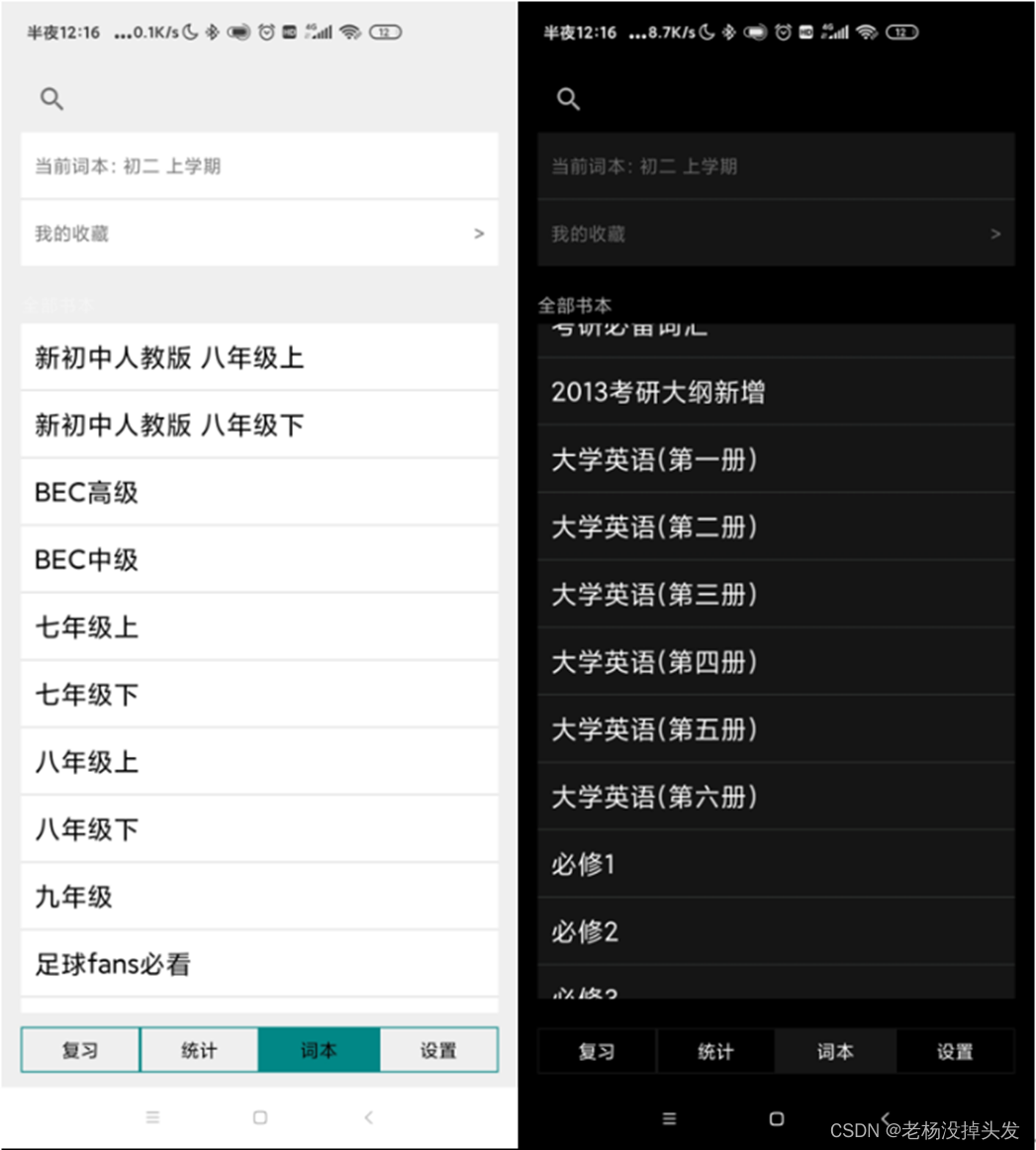
El módulo de función de libro de palabras también es uno de los módulos principales de la aplicación de recitación de palabras. Su función principal es ayudar a los usuarios a reemplazar el libro de palabras actual. Después de realizar esta operación, regrese al módulo de función de revisión y encontrará que el progreso de hoy será ser reiniciado, pero las tareas diarias del usuario permanecen sin cambios, y los datos estadísticos en forma de abanico del progreso del aprendizaje del vocabulario aprendido actualmente en el módulo de función estadística también cambian. Además, la función de libro de palabras también tiene una opción "Mis favoritos" para ver todas las palabras favoritas y los usuarios pueden cancelar una palabra a voluntad. También hay un cuadro de búsqueda para consultar palabras relacionadas en la base de datos y consultas de red. Aquí solo las más Se introducen importantes palabras de conmutación.Esta función. Todos los datos en el libro de palabras están precargados y sincronizados directamente con la base de datos y la interfaz de la aplicación a través de AsyncTask, pero es posible que cada libro de palabras no tenga datos de palabras, porque si todos los datos están precargados, se producirán errores frecuentes de acceso a la API. La solución final es que el usuario debe seleccionar un vocabulario, y luego AsyncTask sincronizará los datos del vocabulario en el vocabulario correspondiente a la base de datos y revisará el fragmento del módulo de funciones. Cuando el usuario utiliza esta aplicación por primera vez, todos los controles en el módulo de función de revisión no estarán disponibles y se le pedirá que seleccione una palabra, como se muestra en la figura;

También es muy simple realizar la operación del usuario de seleccionar un vocabulario. Todas las columnas del libro se pueden deslizar y hay eventos de clic, por lo tanto, el usuario solo necesita hacer clic directamente en el nombre del vocabulario enumerado. En este momento, la interfaz del módulo de función tendrá un aviso de cambio exitoso. Por supuesto, los datos correspondientes, como se mencionó anteriormente, también se agregarán y actualizarán automáticamente a la base de datos y a los principales módulos funcionales. La interfaz del módulo de función de diccionario se muestra en la figura:
Selección de Wordbook (tema diurno y tema nocturno)
4.1.4 Configuración de módulos de función
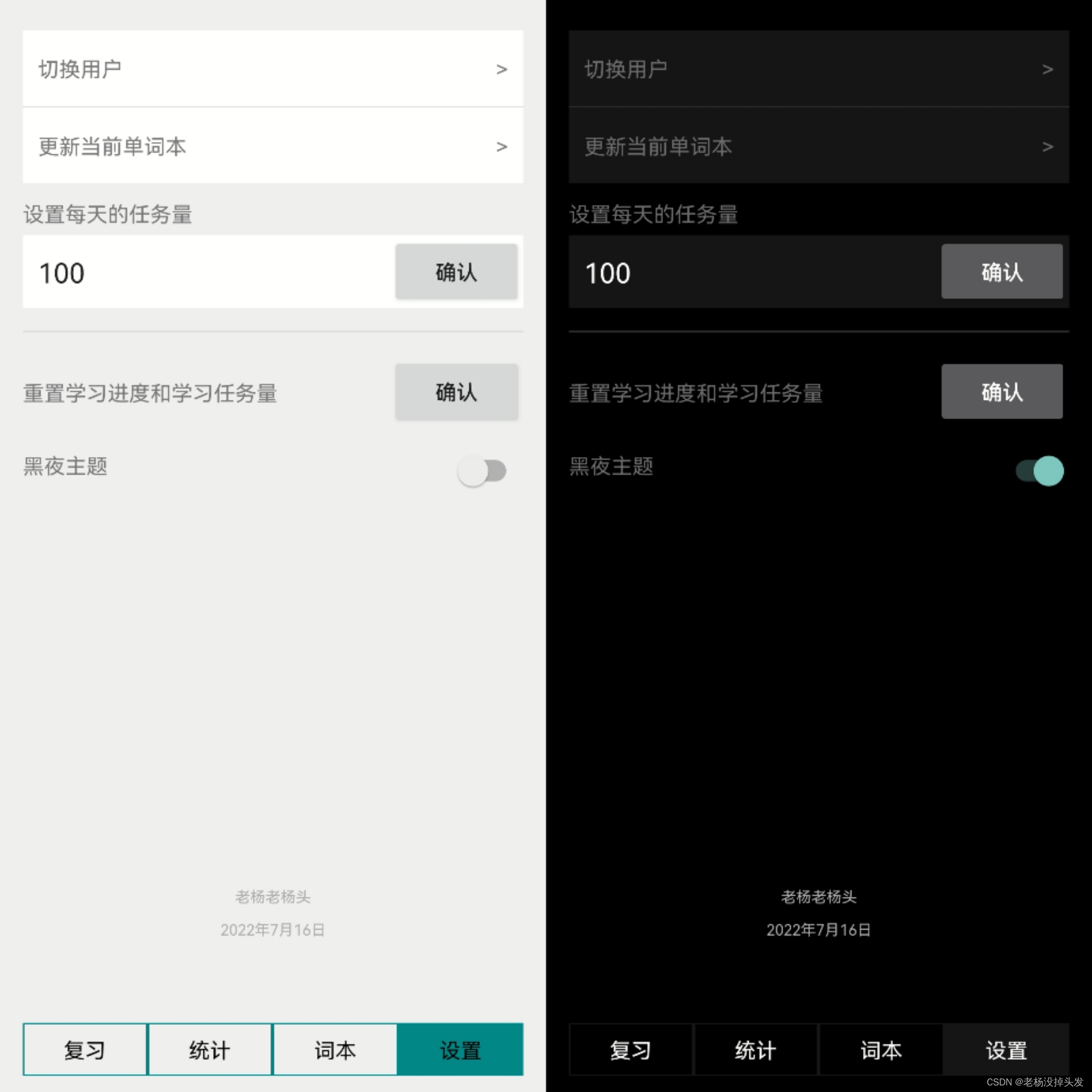
Las funciones del módulo de funciones de configuración incluyen principalmente la configuración de tareas diarias del usuario, el restablecimiento de los datos del usuario y el cambio de tema de la aplicación, además de las funciones de cambio de usuario y actualización del vocabulario actual; sus funciones son:
- Configuración de la tarea diaria del usuario: la configuración de la tarea del usuario la define el usuario y es una base importante para el funcionamiento de la tabla de datos de vocabulario del usuario en el módulo de función de revisión; su función se ha explicado en el módulo de función de revisión, por lo que no se repetirá aquí.
- Restablecimiento de datos de usuario: esta operación restablecerá todos los datos en la tabla de datos de usuario y la tabla de datos de vocabulario de usuario. Después del restablecimiento, el usuario ya no tendrá ningún registro de aprendizaje como un nuevo usuario, pero el contenido de la base de datos relevante no necesita para ser descargado y descargado nuevamente. Los cambios de datos relevantes también se sincronizarán con el módulo de datos estadísticos en tiempo real, por lo que verificar el contenido del módulo de función estadística también es la base para juzgar si los datos del usuario se han restablecido.
- Cambio de tema de la aplicación: Hay dos temas, noche y día, disponibles. La introducción del tema noche satisface la tendencia de desarrollo de Android y las crecientes necesidades de los usuarios. El cambio de tema de la aplicación también es un campo en la tabla de datos del usuario, que puede cambiar automáticamente al tema correspondiente según las diferentes necesidades del usuario.
- Cambio de usuario: dado que todas las fuentes de datos léxicos provienen de la API de datos fantasma, la identificación y la clave de usuario proporcionadas por la API ya son muy exclusivas y privadas. Por lo tanto, la cuenta de usuario y la contraseña se configuran directamente como ID de usuario y clave proporcionados por la API. Como se mencionó en la función del módulo de vocabulario, puede usar la precarga de los datos de vocabulario. Cuando lo usa por primera vez, puede juzgar si hay un estado de inicio de sesión antes de que la actividad principal use el fragmento de carga. Si hay un estado de inicio de sesión, cargue varios fragmentos directamente; si no, juzgue si el inicio de sesión es exitoso o no en función de los datos devueltos. Si tiene éxito, se registrará en la tabla de datos del usuario y se cargará el fragmento; de lo contrario, se rechazará el inicio de sesión y el fragmento no se cargará, y solo permanecerá en la página de inicio de sesión de la actividad principal (Figura 4-7). Por lo tanto, ya no se proporciona la función de registro de usuario.
- Actualización del vocabulario actual: esta operación eliminará la tabla de datos del vocabulario del usuario correspondiente al vocabulario del usuario actual y luego volverá a solicitar los datos de la API y reinicializará la tabla de datos del vocabulario del usuario.
Establezca el diagrama del módulo de función como se muestra en la figura (tema de día y tema de noche):
Interfaz de inicio de sesión de usuario:

Interfaz de código, prueba correcta 
4.2 Diseño detallado del subsistema de gestión de datos de fondo
Realización de la curva de olvido de Ebbinghaus
Hay una fórmula recomendada para la curva de olvido de Ebbinghaus. Pero para que el sistema sea más eficiente, el método de toma de puntos utiliza la curva de olvido de Ebbinghaus. Al actualizar la marca de tiempo en el subsistema de gestión de datos en segundo plano, la marca de tiempo actual se comparará con la marca de tiempo original. Si la diferencia alcanza el valor de la tabla a continuación, se actualizará a la marca de tiempo actual y se actualizará el valor de memoria correspondiente. La Tabla 4-1 muestra el método de procesamiento de la actualización de la diferencia de marca de tiempo:
Tabla 4-1 Métodos de procesamiento para actualizar la diferencia de marca de tiempo
| diferencia | justo | 15 minutos | 20 minutos | 1h | 8h | 1 día | 2 días | 6 días | 30 dias |
|---|---|---|---|---|---|---|---|---|---|
| valor de memoria | 100 | 58 | 44 | 36 | 34 | 28 | 25 | veintiuno | 15 |
En el módulo de función de revisión, primero seleccione las palabras contenidas en el libro actual, el valor de memoria es menor a 40 y mayor a 0 (es decir, las palabras se han aprendido y el valor de olvido es mayor a 60), y el valor de olvido se pasa a la función hit. Si la palabra es acertada, se colocará en la lista de palabras; de esta manera, el proceso de repasar todas las palabras aprendidas en el libro de vocabulario actual se realiza utilizando la curva de olvido de Ebbinghaus.
5. Diseño de base de datos


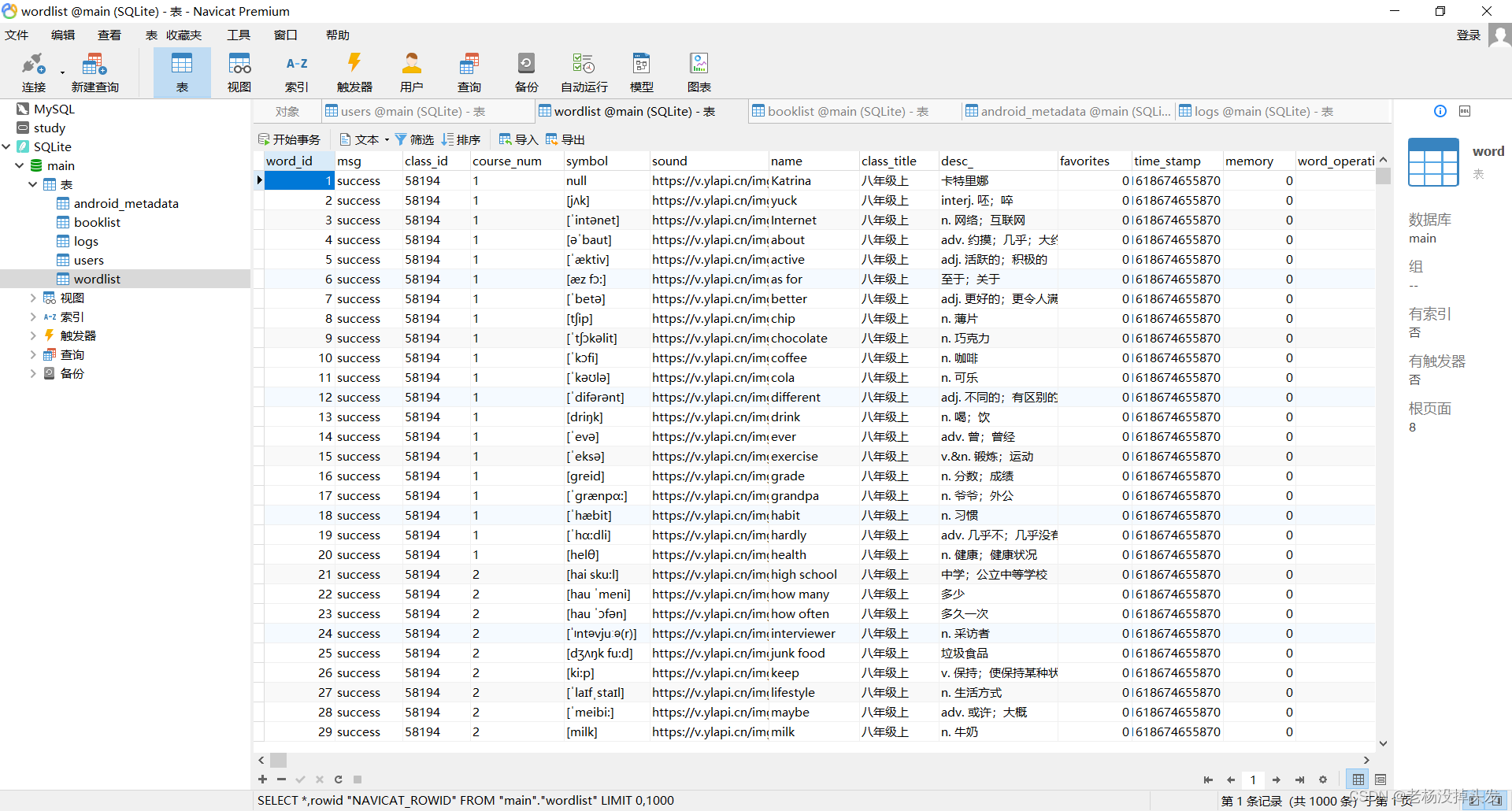
5.1 Resumen de la tabla
5.1.1 Tabla de resumen de la tabla de la base de datos
| Nombre de la tabla | Función descriptiva |
|---|---|
| registros | Tabla de registro de inicio de sesión, registro de éxito de inicio de sesión de usuario |
| usuarios | Tabla de información del usuario, registro de información específica del usuario |
| lista de palabras | Tabla de datos de vocabulario del usuario, que registra la información de uso del vocabulario del usuario y la información del vocabulario |
| lista de libros | Tabla de datos de vocabulario del usuario, que registra la información de uso del vocabulario del usuario y la información del vocabulario |
5.2 Mostrar detalles
tabla de registro de inicio de sesión
| Nombre de la tabla | registros | registros |
|---|---|---|
| campo | tipo de datos | ilustrar |
| id_usuario | entero | no vacío |
| usuario | texto | no vacío |
| clave de aplicación | texto | no vacío |
| núm_fecha | entero | fecha |
Formulario de información del usuario
| Nombre de la tabla | usuarios | usuarios |
|---|---|---|
| campo | tipo de datos | ilustrar |
| id_usuario | entero | PAQUETE |
| usuario | texto | no vacío |
| clave de aplicación | texto | no vacío |
| identificador de clase | texto | identificación del libro |
| posición_de_la_palabra | entero | predeterminado 100 |
| hoy_progreso | entero | predeterminado 1 |
| núm_fecha | entero | fecha |
| tema_noche | entero | 1: tema oscuro; 0: tema de día; predeterminado 0 |
usuario
| Nombre de la tabla | lista de libros | lista de libros |
|---|---|---|
| campo | tipo de datos | ilustrar |
| mensaje | texto | fallo por defecto |
| título | texto | Titulo del libro |
| identificador de clase | texto | identificación del libro |
| palabra_num | entero | predeterminado 0 |
| número_del_curso | entero | predeterminado 0 |
| existencia_elemento | entero | 1: existen datos léxicos; 0: no existen datos léxicos; predeterminado 0 |
Tabla de datos de vocabulario del usuario
| Nombre de la tabla | lista de palabras | lista de palabras |
|---|---|---|
| campo | tipo de datos | ilustrar |
| palabra_id | entero | PK, autoincremental |
| mensaje | entero | fallo por defecto |
| identificador de clase | entero | identificación del libro |
| número_del_curso | entero | predeterminado 0 |
| símbolo | texto | símbolos fonéticos |
| sonido | texto | dirección de pronunciación |
| nombre | texto | Vocabulario inglés |
| discriminación | texto | paráfrasis |
| favoritos | entero | 1: palabra favorita; ;0: palabra no favorita;;predeterminado 0 |
| marca de tiempo | entero | Marca de tiempo; predeterminado 1618674655870 |
| memoria | entero | Valor de memoria, predeterminado 0 |
| palabra_operacion | entero | 3—memoria; 2—conocimiento; 1—borroso; 0—olvidar;;predeterminado 0 |
| oración de ejemplo | texto | oraciones de ejemplo |