Otras plataformas del autor:
| CSDN: blog.csdn.net/qq_41153943
| Pepitas: juejin.cn/user/651387…
| Zhihu: www.zhihu.com/people/1024…
| GitHub: github.com/JiangXia-10…
| Cuenta oficial: nota 1024
Este artículo tiene un total de 5232 palabras, y el tiempo estimado de lectura es de 13 minutos
prefacio
En un sistema distribuido, el registro juega un papel importante y es un miembro indispensable del descubrimiento de servicios y el equilibrio de carga del cliente. Además de las funciones básicas del centro de registro, su estabilidad, disponibilidad y robustez tienen un gran impacto en el buen funcionamiento de todo el sistema distribuido. Como sistema distribuido principal en China, dubbo admite middleware de terceros, como zookeeper, nacos y redis en el registro.
El sistema de tecnología de desarrollo distribuido de alta concurrencia ya es muy grande. Me he estado preparando para encontrar un trabajo hace algún tiempo y participé en la entrevista. A través de la entrevista, puedo encontrar que RPC, Dubbo, zookeeper, nacos, distribuidos, microservicios , etc., se han convertido en herramientas de búsqueda de empleo Los requisitos de habilidades más básicos.
Un artículo anterior presentó cómo usar nacos como un centro de registro: SpringCloud: Building Nacos services and service discovery . De hecho, no solo los nacos se pueden usar como centro de registro, sino que zookeeper también se puede usar como centro de registro. Pero Zookeeper no solo se puede utilizar como centro de registro.
Para Zookeeper, la explicación en su documentación oficial es: es un marco de servicio distribuido y un subproyecto de Apache Hadoop, que se utiliza principalmente para resolver algunos problemas de gestión de datos que se encuentran a menudo en aplicaciones distribuidas, como: servicios de nombres unificados, estado servicios de sincronización, gestión de clústeres, gestión de elementos de configuración de aplicaciones distribuidas, etc. Se puede entender que zookeeper es un sistema de archivos + mecanismo de notificación de monitoreo.
El artículo de hoy es para aprender y aprender Zookeeper juntos. Yo también estoy en proceso de aprendizaje, así que si hay algo mal, ¡coméntenme y corríjanme!
que es zookeeper
Con la expansión de las aplicaciones del sistema y la garantía del volumen de datos, nuestro sistema a menudo se encuentra con estas situaciones:
¿Cómo garantizar que todos los servidores de un clúster de servidores mantengan la coherencia de la información de configuración compartida?
Si una máquina en el clúster de servidores cuelga, ¿cómo detectan otras máquinas este cambio y se hacen cargo de la tarea?
Para un sistema distribuido, ¿cómo coordinar de manera eficiente múltiples servicios para escribir en el mismo archivo de red y mantener la consistencia?
¿Cómo agregar máquinas sin reiniciar el clúster?
…
Para resolver los problemas anteriores, se necesita una herramienta similar al mecanismo de coordinación de subprocesos para permitir que varios servicios trabajen juntos. Zookeeper es una herramienta de este tipo.
Como se mencionó anteriormente, Zookeeper se explica en su documentación oficial: es un marco de servicio distribuido y un subproyecto de Apache Hadoop. Se utiliza principalmente para resolver algunos problemas de administración de datos que se encuentran a menudo en aplicaciones distribuidas, tales como: Servicio de nombres unificado, servicio de sincronización de estado, gestión de clústeres, gestión de elementos de configuración de aplicaciones distribuidas, etc.
Entonces se puede entender que zookeeper es un servicio de coordinación de alto rendimiento que puede ser utilizado en aplicaciones distribuidas, sus datos se almacenan en memoria y su persistencia se implementa en logs. Y su estructura de memoria es similar a una estructura de árbol, con las características de alto rendimiento y baja latencia. Zookeeper no solo puede ayudarnos a realizar un centro de configuración unificado distribuido, registro de servicios, bloqueos distribuidos, etc., sino que también mantiene imágenes de estado en la memoria, así como registros de transacciones e instantáneas en almacenamiento persistente. El servicio ZooKeeper está disponible siempre que la mayoría de los servidores estén disponibles. Los clientes se conectan a un único servidor de ZooKeeper. El cliente mantiene una conexión TCP a través de la cual envía solicitudes, obtiene respuestas, obtiene eventos de observación y envía tics. Si se pierde la conexión TCP con el servidor, el cliente se conectará a un servidor diferente. Entonces, simplemente puede pensar en zookeeper = sistema de archivos + mecanismo de notificación de monitoreo.
También podemos entenderlo así: el significado chino de zookeeper es el administrador del zoológico (zoom+keeper). El papel del cuidador del zoológico es administrar a los animales en el zoológico y mantenerlos en orden. Zookeeper es un proyecto de código abierto bajo apache. Muchos proyectos de código abierto bajo apache en realidad usan animales como íconos, como Hadoop (elefante), Hive (abeja), Pig (cerdo), tomcat (gato).
Así que cabe recordar que el proyecto bajo apache es el zoo, y zookeeper es el zookeeper encargado de gestionar estos animales (proyectos open source).

La estructura de datos de zookeeper
Zookeeper mantiene una estructura de datos jerárquica, que es muy similar a un sistema de archivos estándar:
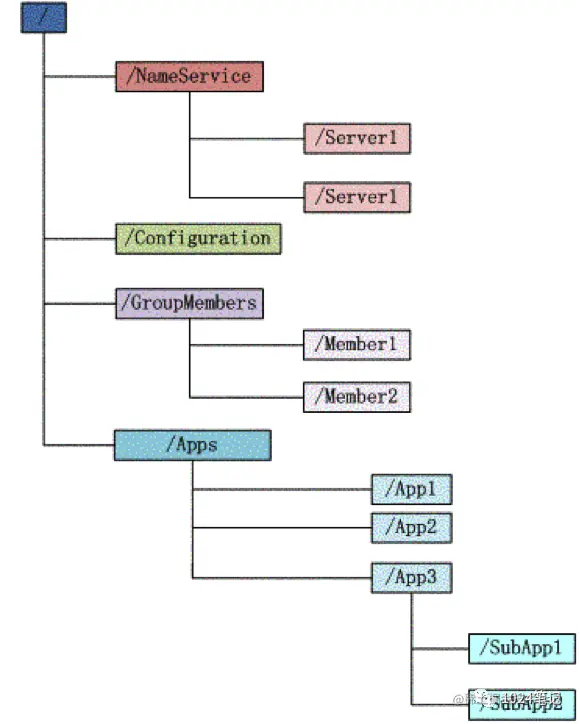
Cada nodo (elemento de directorio) en la estructura de árbol de la figura anterior, como NameService, se denomina znode (nodo de directorio). Las zonas se referencian mediante rutas, y las rutas deben ser absolutas, por lo que deben comenzar con un carácter de barra inclinada. Además, deben ser únicos, lo que significa que solo hay una representación de cada ruta, por lo que estas rutas no se pueden cambiar. En zookeeper, las rutas consisten en cadenas Unicode con algunas restricciones. La cadena "/ZooKeeper" se utiliza para guardar información de gestión, como información de cuota clave.
Un znode tiene las características de un archivo y un directorio. No solo mantiene estructuras de datos como datos, metainformación, lista de control de acceso), marca de tiempo, etc. como un archivo, sino que también se puede usar como parte del identificador de ruta como un directorio, y puede agregar y eliminar znodes libremente.
Cada znode se compone de tres partes:
stat: esta es información de estado, que describe la versión de znode, los permisos y otra información
datos: los datos asociados con este znode
niños: los nodos secundarios debajo del znode
Cabe señalar que los nombres de los subnodos bajo el mismo nodo no pueden ser iguales, y la denominación está estandarizada. Su ruta no tiene el concepto de ruta relativa, y es una ruta absoluta. Cualquier inicio comienza con "/", y el final es que el tamaño de los datos que almacena es limitado.
El tipo de nodo de zookeeper
Hay dos tipos de nodos en zookeeper, a saber, el nodo efímero y el nodo persistente. El tipo de un nodo se determina cuando se crea y no se puede cambiar.
La diferencia entre los dos nodos es si dependen de la sesión (Session) para sobrevivir. Una conexión entre un cliente y un servidor de ZooKeeper se denomina sesión. El cliente mantiene una sesión estableciendo una conexión TCP larga con el servidor. Cuando el cliente se inicia, primero establecerá una conexión TCP con el servidor. A través de esta conexión, el cliente puede mantener una sesión válida con el servidor a través de la detección de latidos, y también puede enviar El servidor de ZooKeeper envía solicitudes y obtiene respuestas.
(1) Nodos temporales: el ciclo de vida de los nodos depende de la sesión que los creó. Los nodos temporales se eliminarán automáticamente una vez que finalice la sesión, pero también se pueden eliminar manualmente. Aunque cada Znode efímero está vinculado a una sesión de cliente, aún son visibles para todos los clientes. Además, los nodos temporales de zookeeper no pueden tener nodos secundarios. Los nodos temporales se pueden subdividir en: nodos de directorio temporales y nodos de directorio numerados de secuencia temporal.
Nodo de directorio temporal (EFÍMERO): después de que el cliente se desconecta de zookeeper, el nodo se elimina;
Nodo de directorio de número secuencial temporal (EPHEMERAL_SEQUENTIAL): después de que el cliente se desconecta de zookeeper, el nodo se elimina, pero Zookeeper numera secuencialmente el nombre del nodo;
(2) Nodo permanente: el ciclo de vida de este nodo no depende de la sesión, y solo se pueden eliminar cuando el cliente muestra que se realizó la operación de eliminación. Los nodos temporales se pueden subdividir en: nodos de directorio persistentes y nodos de directorio de números secuenciales persistentes.
Nodo de directorio persistente (PERSISTENT): después de que el cliente se desconecte de zookeeper, el nodo aún existe
Nodo de directorio de número secuencial persistente (PERSISTENT_SEQUENTIAL): después de que el cliente se desconecta de zookeeper, el nodo aún existe, pero zookeeper numera secuencialmente el nombre del nodo.
La clasificación anterior tiene un concepto llamado nodos secuenciales: al crear nodos, los usuarios pueden solicitar agregar un conteo incremental al final de la ruta de zooKeeper. Este recuento es único para el nodo principal de este nodo. Cuando el cliente solicite crear este nodo, zookeeper escribirá un número único para este nodo de acuerdo con el estado zxid del nodo principal, y este número seguirá aumentando. Estos nodos se denominan nodos secuenciales.
Un concepto llamado zxid se menciona anteriormente: por cada operación que cambia el estado de un nodo zookeeper, este nodo recibirá una marca de tiempo en formato Zxid, y esta marca de tiempo se ordena globalmente. Se puede entender que cada operación que cambie el nodo generará una identificación de transacción única llamada Zxid. Si el valor de Zxid1 es menor que el valor de Zxid2, entonces se puede considerar que el evento correspondiente a Zxid1 ocurre antes que el evento correspondiente a Zxid2. De hecho, cada nodo de zookeeper mantiene dos valores Zxid, a saber: cZxid y mZxid.
-
cZxid: se refiere a la marca de tiempo del formato Zxid correspondiente a la hora de creación del nodo.
-
mZxid: se refiere a la marca de tiempo del formato Zxid correspondiente a la hora de modificación del nodo.
En la implementación, Zxid es un número de 64 bits, y sus 32 bits superiores son época (votación) para identificar si la relación del líder ha cambiado. Cada vez que se elige un líder, tendrá una nueva época. Los 32 bits inferiores son un conteo incremental.
Características del cuidador del zoológico
1. Orden
Zookeeper proporciona una variedad de formas de realizar un seguimiento del tiempo. Zookeeper añade un número (el zxid mencionado anteriormente) a cada actualización. Este número refleja el orden de todas las transacciones de zookeeper. El orden estricto significa que se puede lograr una sincronización compleja en el cliente. Además del zxid mencionado anteriormente, también hay configuraciones de ticks en version y zoo.cfg.
Números de versión (número de versión): el número de versión se utiliza para registrar las horas de modificación de los datos del nodo o la lista de nodos secundarios del nodo o la información de autoridad. Si la versión de un nodo es 1, significa que el nodo se ha modificado una vez desde que se creó.
Cada nodo mantiene tres números de versión, son:
-
versión: número de versión de los datos del nodo
-
cversion: número de versión del nodo secundario
-
aversión: número de versión de ACL propiedad del nodo
Una solicitud de escritura en un nodo hará que aumenten los tres números de versión del nodo, y el principio es similar al de un bloqueo optimista.
ticks : Configuración en el archivo zoo.cfg. Cuando se utiliza zookeeper multiservidor, el servidor usa un "tick" para definir el tiempo de los eventos, como la carga de estado, el tiempo de espera de la sesión, etc., que se expone indirectamente a través del tiempo de espera mínimo de la sesión (el valor predeterminado es el tiempo de tick x2), si la solicitud del cliente excede este tiempo, entonces el cliente ya no puede conectarse al servidor
tiempo real: zookeeper no usa tiempo real
¡Entonces se puede entender que el cuidador del zoológico es un coordinador, haciendo ordenadas algunas conexiones interactivas!
alta velocidad
Como se mencionó anteriormente, los datos del guardián del zoológico se cargan en la memoria, por lo que tienen el efecto de un alto rendimiento y una baja latencia. Y la velocidad de lectura es particularmente rápida, y el tamaño de znode de la operación está limitado a 1 m. Son estas características las que hacen que zookeeper sea adecuado para grandes sistemas distribuidos
2. Reproducibles
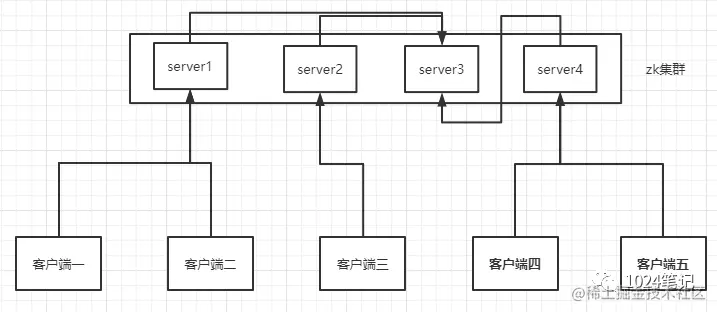
Los datos de Zookeeper se pueden replicar y respaldar. Zookeeper puede construir rápidamente un clúster, y viene con algunas herramientas y mecanismos internos. Solo necesitamos establecer algunas configuraciones para garantizar servicios confiables, para que no se convierta en un punto único de falla. como sigue:
mecanismo de vigilancia
Zookeeper permite a los usuarios registrar algunos Watchers en nodos designados. Cuando un nodo de datos cambia, el servidor de zookeeper enviará una notificación del cambio a los clientes interesados. Esta es la característica central de zookeeper, y muchas funciones de zookeeper se implementan en función de esta característica.
Si dos clientes tienen observadores registrados (escuchas de eventos) en el clúster de zookeeper, cuando cambien los datos del nodo en zookeeper, zookeeper enviará una notificación de este cambio al cliente, y cuando el cliente reciba Cuando se notifique este cambio, ciertas pre- se activarán las acciones definidas. En términos generales, zookeeper enviará solo una notificación al cliente.Si un reloj registra varias interfaces (existe, getData) al mismo tiempo, si el nodo se elimina en este momento, aunque este evento es válido tanto para existe como para getData, el El reloj solo se llamará una vez. Y puede haber retrasos en estas solicitudes, por lo que cada cambio que ocurre en cada nodo no se puede obtener de manera absolutamente confiable. Una vez que se activa el reloj, se eliminará inmediatamente. Si desea seguir supervisando los cambios, debe seguir proporcionando ajustes para el reloj. Y el cliente puede ver el resultado del cambio solo después de recibir la notificación del reloj.
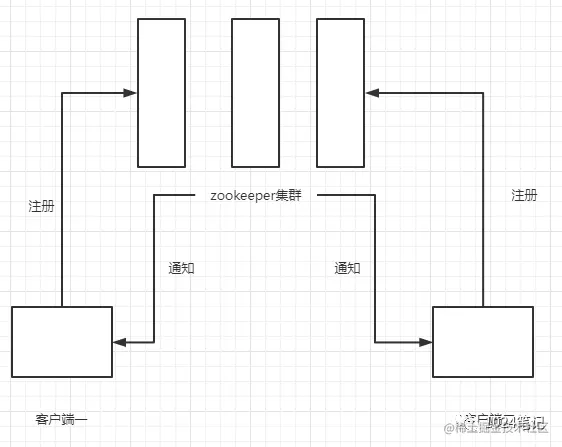
Hay 4 condiciones para activar el evento de observación, crear, eliminar, cambiar, hijo (evento de nodo hijo)
Así que las características del cuidador del zoológico se pueden resumir de la siguiente manera:
1. Atomicidad, la actualización tiene éxito o falla. sin resultados parciales;
2. Confiabilidad: Los cambios de datos no se perderán a menos que sean sobrescritos y modificados por el cliente;
3. Rendimiento en tiempo real: los datos leídos por el cliente del sistema en ese momento son los últimos;
4. Orden: Las operaciones de los clientes son todas efectivas en orden;
5. Coherencia: también conocida como imagen única del sistema, no importa qué servidor esté conectado, el contenido que ve el cliente es el mismo.
Resumir
Lo anterior es una breve introducción a zookeeper. También es un proceso de aprendizaje. Resumió algunos conceptos y puntos de conocimiento relacionados con el cuidador del zoológico, si hay algo mal, ¡indíquelo, intercambie y discuta!
¡El seguimiento presentará más contenido relacionado con el cuidador del zoológico!
sugerencia relacionada
-
Anotación de resorte (3): @scope establece el alcance del componente
-
¡Una colección completa de anotaciones comunes en Spring, digna de tu colección! ! !
-
Anotación de primavera (siete): use @Value para asignar atributos a Bean
-
SpringBoot desarrolla una interfaz de estilo Restful para realizar la función CRUD
-
SpringCloud: creación de servicios Nacos y detección de servicios