
Introducción a los antecedentes
En un sistema empresarial reciente, la base de datos esclava ha estado retrasada y no puede ponerse al día con la base de datos maestra, lo que genera mayores riesgos comerciales. Desde una perspectiva de recursos, el uso de CPU, IO y red de la biblioteca esclava es bajo y no existe ninguna situación en la que la reproducción se ralentice debido a una presión excesiva del servidor. La reproducción paralela está habilitada en la biblioteca esclava. Ejecutando show Processlist en la biblioteca esclava La biblioteca muestra que no hay subprocesos de reproducción. Bloqueando, la reproducción continúa; al analizar el archivo de registro de retransmisión, se descubre que no hay reproducción de transacciones grandes.
Análisis de proceso
Confirmación del fenómeno
Recibí comentarios de mis colegas de operación y mantenimiento de que un conjunto de bibliotecas esclavas estaba muy retrasado. Proporcioné show slave statusinformación de captura de pantalla del retraso.
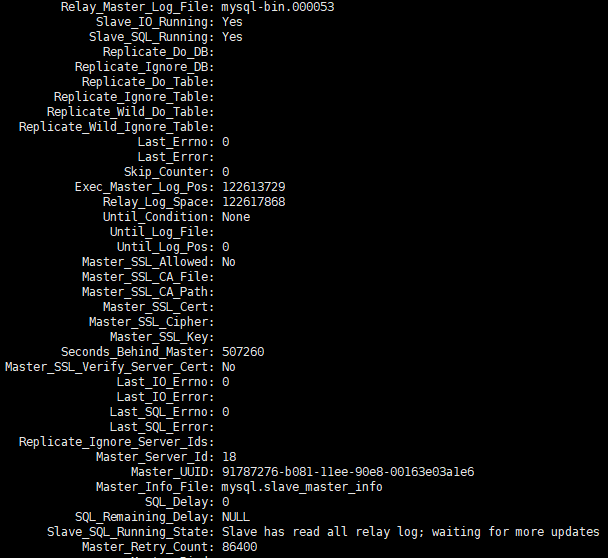
Después de continuar observando show slave statuslos cambios por un tiempo, descubrí que la información del punto POS cambiaba constantemente, Seconds_Behind_master también cambiaba constantemente y la tendencia general seguía creciendo.
El uso de recursos
Después de observar el uso de recursos del servidor, podemos ver que el uso es muy bajo.

Al observar el proceso esclavo, básicamente solo se puede ver un hilo reproduciendo el trabajo.
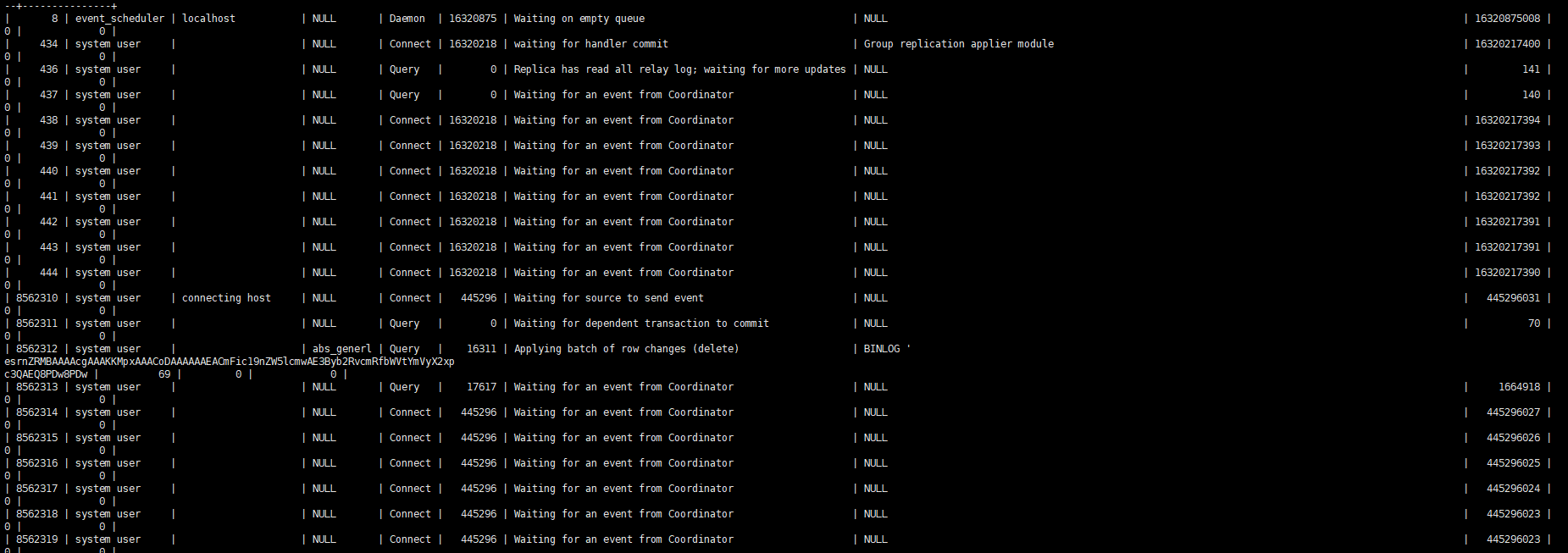
Descripción del parámetro de reproducción paralela
Ubicado en la biblioteca principal.binlog_transaction_dependency_tracking=WRITESET
En la biblioteca de esclavos, slave_parallel_type=LOGICAL_CLOCKel yslave_parallel_workers=64
comparación del registro de errores
Obtenga el registro de reproducción paralela del registro de errores para su análisis
$ grep 010559 100werror3306.log | tail -n 3
2024-01-31T14:07:50.172007+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3318582273; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348754579743300 waited (count) when Workers occupied = 34529247 waited when Workers occupied = 76847369713200
2024-01-31T14:09:50.078829+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3319256065; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348851330164000 waited (count) when Workers occupied = 34535857 waited when Workers occupied = 76866419841900
2024-01-31T14:11:50.060510+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3319894017; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348943740455400 waited (count) when Workers occupied = 34542790 waited when Workers occupied = 76890229805500
Para obtener una explicación detallada de la información anterior, consulte Monitoreo del desempeño de MTS ¿Cuánto sabe?
Se eliminaron las estadísticas que ocurrían con menos frecuencia y se mostró la comparación de algunos datos clave.
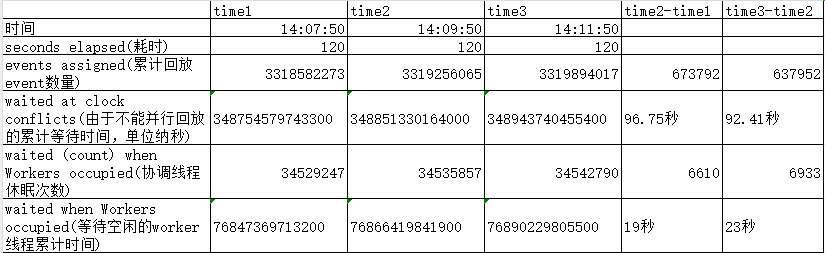
Se puede encontrar que en el tiempo natural de 120, el subproceso de coordinación de reproducción espera más de 90 segundos porque no puede reproducirse en paralelo y casi 20 segundos porque no hay subprocesos de trabajo inactivos que esperar, lo que se traduce en solo unos 10 segundos. para que el hilo de coordinación funcione.
Estadísticas de paralelismo
Como todos sabemos, la reproducción paralela de MySQL desde la biblioteca se basa principalmente en el último_committed en el binlog para hacer juicios. Si el último_committed de la transacción es el mismo, básicamente se puede considerar que estas transacciones se pueden reproducir en paralelo. A continuación se muestra las estadísticas aproximadas de obtención de un registro de retransmisión del entorno para reproducción paralela.
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>=1 && $2 <11){sum+=$2}} END {print sum}'
235703
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>10){sum+=$2}} END {print sum}'
314694
El primer comando anterior cuenta el número de transacciones con el mismo last_committed entre 1 y 10, es decir, el grado de reproducción paralela es bajo o no se puede reproducir en paralelo. El número total de estas transacciones es 235703, lo que representa el 43%. Análisis detallado de las transacciones con un grado relativamente bajo de reproducción paralela A partir de la distribución de transacciones, se puede ver que esta parte de last_committed es básicamente una transacción única. Deben esperar a que se complete la reproducción de la transacción de pedido anticipado antes de poder reproducirlo. Esto hará que la espera del hilo de coordinación observada en el registro anterior no pueda reproducirse en paralelo y entre en el estado de espera. Cuando el tiempo es relativamente largo
$ mysqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>=1 && $2 <11) {print $2}}' | sort | uniq -c
200863 1
17236 2
98 3
13 4
3 5
1 7
El segundo comando cuenta el número total de transacciones con más de 10 mismas transacciones last_committed. El número es 314694, lo que representa el 57%. Analiza estas transacciones con un grado relativamente alto de reproducción paralela en detalle. Se puede ver que cada grupo es entre 6500 y 9000. número de transacciones
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>11){print $0}}' | column -t
last_commited group_count Percentage
1 7340 1.33%
11938 7226 1.31%
23558 7249 1.32%
35248 6848 1.24%
46421 7720 1.40%
59128 7481 1.36%
70789 7598 1.38%
82474 6538 1.19%
93366 6988 1.27%
104628 7968 1.45%
116890 7190 1.31%
128034 6750 1.23%
138849 7513 1.37%
150522 6966 1.27%
161989 7972 1.45%
175599 8315 1.51%
189320 8235 1.50%
202845 8415 1.53%
218077 8690 1.58%
234248 8623 1.57%
249647 8551 1.55%
264860 8958 1.63%
280962 8900 1.62%
297724 8768 1.59%
313092 8620 1.57%
327972 9179 1.67%
344435 8416 1.53%
359580 8924 1.62%
375314 8160 1.48%
390564 9333 1.70%
407106 8637 1.57%
422777 8493 1.54%
438500 8046 1.46%
453607 8948 1.63%
470939 8553 1.55%
486706 8339 1.52%
503562 8385 1.52%
520179 8313 1.51%
535929 7546 1.37%
Introducción al mecanismo last_committed
Los parámetros de la biblioteca principal binlog_transaction_dependency_trackingse utilizan para especificar cómo generar la información de dependencia escrita en el registro binario para ayudar a la biblioteca esclava a determinar qué transacciones se pueden ejecutar en paralelo, es decir, este parámetro se utiliza para controlar el mecanismo de generación de last_committed. Los valores opcionales del parámetro son COMMIT_ORDER, WRITESET y SESSION_WRITESET. En el siguiente código, es fácil ver las relaciones de los tres parámetros:
- El algoritmo básico es COMMIT_ORDER
- El algoritmo WRITESET se calcula nuevamente según COMMIT_ORDER
- El algoritmo SESSION_WRITESET se calcula nuevamente en función de WRITESET
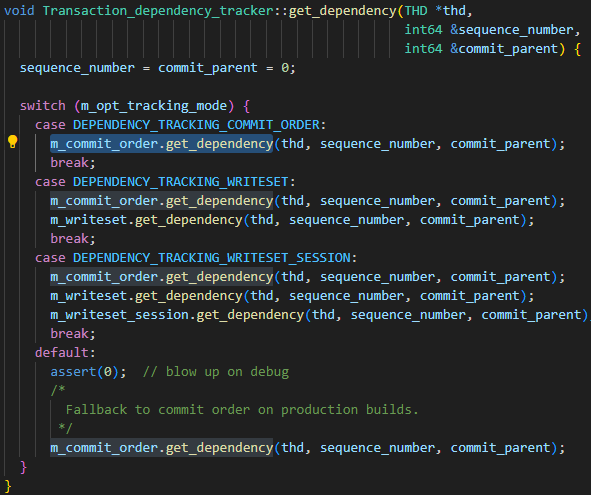
Dado que mi instancia está configurada en WRITESET, solo concéntrese en el algoritmo COMMIT_ORDER y el algoritmo WRITESET.
COMMIT_ORDER
Regla de cálculo COMMIT_ORDER: si se envían dos transacciones al mismo tiempo en el nodo maestro, significa que no hay conflicto entre los datos de las dos transacciones, entonces también se pueden ejecutar en paralelo en el nodo esclavo. Un caso típico ideal es como sigue.
| Sesión 1 | sesión-2 |
|---|---|
| COMENZAR | COMENZAR |
| INSERTAR valores t1(1) | |
| INSERTAR valores t2(2) | |
| confirmar (compromiso_grupo) | confirmar (compromiso_grupo) |
Pero para MySQL, group_commit es un comportamiento interno. Siempre que la sesión-1 y la sesión-2 ejecuten la confirmación al mismo tiempo, independientemente de si están fusionadas internamente en group_commit, los datos de las dos transacciones están esencialmente libres de conflictos; un paso atrás, siempre que la sesión-1 ejecute la confirmación y no se escriban datos nuevos en la sesión-2, las dos transacciones aún no tendrán conflictos de datos y aún se pueden replicar en paralelo.
| Sesión 1 | sesión-2 |
|---|---|
| COMENZAR | COMENZAR |
| INSERTAR valores t1(1) | |
| INSERTAR valores t2(2) | |
| comprometerse | |
| comprometerse |
Para escenarios con más subprocesos concurrentes, es posible que estos subprocesos no puedan replicarse en paralelo al mismo tiempo, pero algunas transacciones sí. Tomando la siguiente secuencia de ejecución como ejemplo, después de las confirmaciones de la sesión 3, la sesión 2 no tiene nuevas escrituras, por lo que las dos transacciones se pueden replicar en paralelo; después de las confirmaciones de la sesión 3, la sesión 1 inserta nuevos datos, los datos entran en conflicto no se puede determinar en este momento, por lo que las transacciones de la sesión-3 y la sesión-1 no se pueden replicar en paralelo; pero después de enviar la sesión-2, no se escriben datos nuevos después de la sesión-1, por lo que la sesión-2 y la sesión-1 son nuevamente Se puede replicar en paralelo. Por lo tanto, en este escenario, la sesión 2 se puede replicar en paralelo con la sesión 1 y la sesión 3 respectivamente, pero las tres transacciones no se pueden replicar en paralelo al mismo tiempo.
| Sesión 1 | sesión-2 | sesión-3 |
|---|---|---|
| COMENZAR | COMENZAR | COMENZAR |
| INSERTAR valores t1(1) | INSERTAR valores t2(1) | INSERTAR valores t3(1) |
| INSERTAR valores t1(2) | INSERTAR valores t2(2) | |
| comprometerse | ||
| INSERTAR valores t1(3) | ||
| comprometerse | ||
| comprometerse |
ESCRIBIR
En realidad, es una combinación de commit_order + writeset. Primero calculará un valor last_committed a través de commit_order, luego calculará un nuevo valor a través de writeset y finalmente tomará el valor más pequeño entre los dos como el valor last_committed de la transacción final gtid.
En MySQL, writeset es esencialmente un valor hash calculado para nombre_esquema + nombre_tabla + clave_primaria/clave_única. Durante la ejecución de la declaración DML, antes de generar row_event a través de binlog_log_row, todas las claves primarias/claves únicas en la declaración DML tendrán valores hash calculados. por separado y se agrega a la lista de escritura de la transacción misma. Y si hay una tabla sin una clave principal/índice único, también se establecerá has_missing_keys=true para la transacción.
El parámetro está establecido en WRITESET, pero no se puede utilizar. Las restricciones son las siguientes.
- Declaraciones o tablas que no son DDL con claves primarias o claves únicas o transacciones vacías
- El algoritmo hash utilizado por la sesión actual es coherente con el del mapa hash.
- No se utilizan claves foráneas
- La capacidad del mapa hash no excede la configuración de binlog_transaction_dependency_history_size. Cuando se cumplen las cuatro condiciones anteriores, se puede utilizar el algoritmo WRITESET. Si no se cumple alguna de las condiciones, degenerará al método de cálculo COMMIT_ORDER.
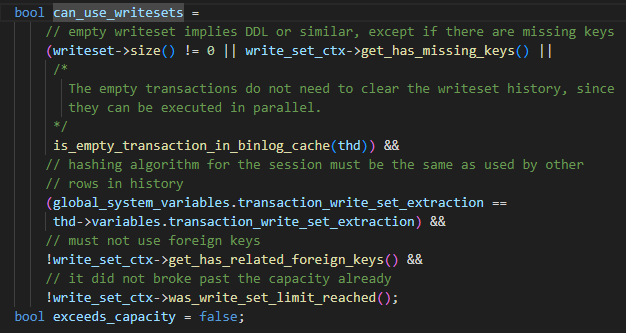
El algoritmo WRITESET específico es el siguiente, cuando se envía la transacción:
-
last_committed está establecido en m_writeset_history_start, este valor es el número de secuencia más pequeño en la lista m_writeset_history
-
Recorrer la lista de transacciones del conjunto de escritura
a Si un conjunto de escritura no existe en m_writeset_history global, construya un objeto par<writeset, secuencia_número> de la transacción actual e insértelo en la lista global m_writeset_history
b Si existe, last_committed = max (last_committed, el valor del número de secuencia del conjunto de escritura histórico) y, al mismo tiempo, actualice el número de secuencia correspondiente al conjunto de escritura en m_writeset_history al valor de transacción actual.
-
Si has_missing_keys = false, es decir, todas las tablas de datos de la transacción contienen claves primarias o índices únicos, entonces el valor mínimo calculado por commit_order y writeset se utilizará como el valor final de last_committed.
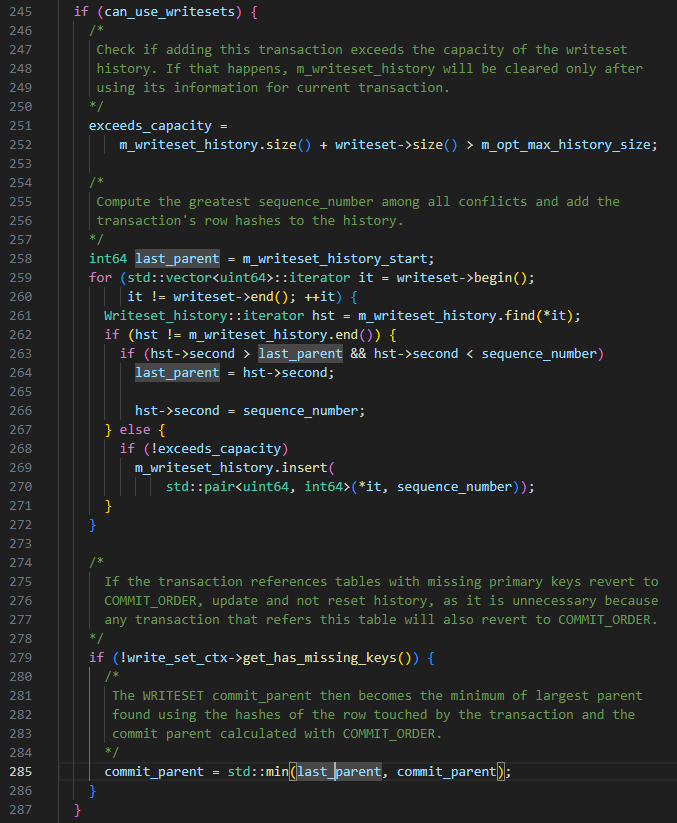
CONSEJOS: Según las reglas de WRITESET anteriores, habrá una situación en la que el último_committed de la transacción enviada más tarde será menor que la transacción enviada primero.
Análisis de conclusiones
Descripción de la conclusión
De acuerdo con las restricciones de uso de WRITESET, comparamos el registro de retransmisión y las estructuras de tabla involucradas en la transacción, analizamos la composición de la transacción de un único last_committed y encontramos las dos situaciones siguientes:
- Existe un conflicto de datos entre los datos involucrados en la última transacción confirmada y el número de secuencia.
- La tabla involucrada en una única transacción last_committed no tiene clave principal y existen muchas transacciones de este tipo.
Del análisis anterior, se puede concluir que hay demasiadas transacciones en la tabla sin una clave principal, lo que hace que WRITESET degenere en COMMIT_ORDER. Dado que la base de datos es una aplicación TP, las transacciones se envían rápidamente y no se pueden garantizar envíos múltiples de transacciones. estar dentro de un ciclo de confirmación, lo que resulta en COMMIT_ORDER. Las lecturas repetidas last_committed generadas por el mecanismo son muy bajas. La biblioteca esclava solo puede reproducir estas transacciones en serie, lo que provoca retrasos en la reproducción.
Medidas de optimización
- Modifique las tablas desde el lado comercial y agregue claves primarias a tablas relacionadas cuando sea posible.
- Intente aumentar los parámetros binlog_group_commit_sync_delay y binlog_group_commit_sync_no_delay_count de 0 a 10000. Debido a restricciones ambientales especiales, este ajuste no tiene efecto. Diferentes escenarios pueden tener diferentes rendimientos.
Disfruta de GreatSQL :)
Acerca de GreatSQL
GreatSQL es una base de datos nacional independiente de código abierto adecuada para aplicaciones de nivel financiero. Tiene muchas características principales, como alto rendimiento, alta confiabilidad, alta facilidad de uso y alta seguridad. Puede usarse como un reemplazo opcional de MySQL o Percona Server. y se utiliza en entornos de producción online, completamente gratuito y compatible con MySQL o Percona Server.
Enlaces relacionados: Comunidad GreatSQL Gitee GitHub Bilibili
Gran comunidad SQL:

Sugerencias y comentarios sobre recompensas de la comunidad: https://greatsql.cn/thread-54-1-1.html
Detalles de la presentación del premio del blog comunitario: https://greatsql.cn/thread-100-1-1.html
(Si tiene alguna pregunta sobre el artículo o tiene ideas únicas, puede ir al sitio web oficial de la comunidad para preguntarlas o compartirlas ~)
Grupo de intercambio técnico:
Grupo WeChat y QQ:
Grupo QQ: 533341697
Grupo WeChat: agregue GreatSQL Community Assistant (ID de WeChat:) wanlidbccomo amigo y espere a que el asistente de la comunidad lo agregue al grupo.