
1. Antecedentes
ZooKeeper (ZK) es un servicio de coordinación de aplicaciones distribuidas nacido en 2007. Aunque por algunas razones históricas especiales, muchos escenarios empresariales todavía tienen que depender de él. Por ejemplo, Kafka, programación de tareas, etc. Especialmente cuando la implementación mixta de Flink y el desacoplamiento de ETCD, el lado comercial requería estabilidad absoluta y recomendaba encarecidamente no utilizar ZooKeeper de construcción propia. Por consideraciones de estabilidad, se utiliza MSE-ZK de Alibaba. Desde que comenzamos a usarlo en septiembre de 2022, no hemos encontrado ningún problema de estabilidad y, de hecho, la confiabilidad del SLA ha alcanzado el 99,99%.
En 2023, algunas empresas utilizaron clústeres ZooKeeper (ZK) de construcción propia, y luego ZK experimentó varias fluctuaciones durante el uso, y luego Dewu SRE comenzó a hacerse cargo de algunos clústeres de construcción propia e hizo varias rondas de intentos de refuerzo de estabilidad. Durante la adquisición, descubrimos que después de que ZooKeeper se haya estado ejecutando durante un período de tiempo, el uso de memoria seguirá aumentando, lo que puede provocar fácilmente problemas de falta de memoria (OOM). Teníamos mucha curiosidad por este fenómeno y por eso participamos en el proceso de exploración para resolver este problema.
2. Exploración y análisis
determinar la dirección
Al solucionar el problema, tuvimos mucha suerte de encontrar un sitio de falla en un entorno de prueba. Dos nodos en el clúster estaban en un estado de borde de OOM.

En el caso de la escena del fallo, normalmente sólo queda el 50% antes del punto final exitoso.
La memoria es alta Según la experiencia pasada, o no es del montón o hay un problema en el montón. Se puede confirmar a partir del gráfico de llamas y jstat que se trata de un problema en el montón.
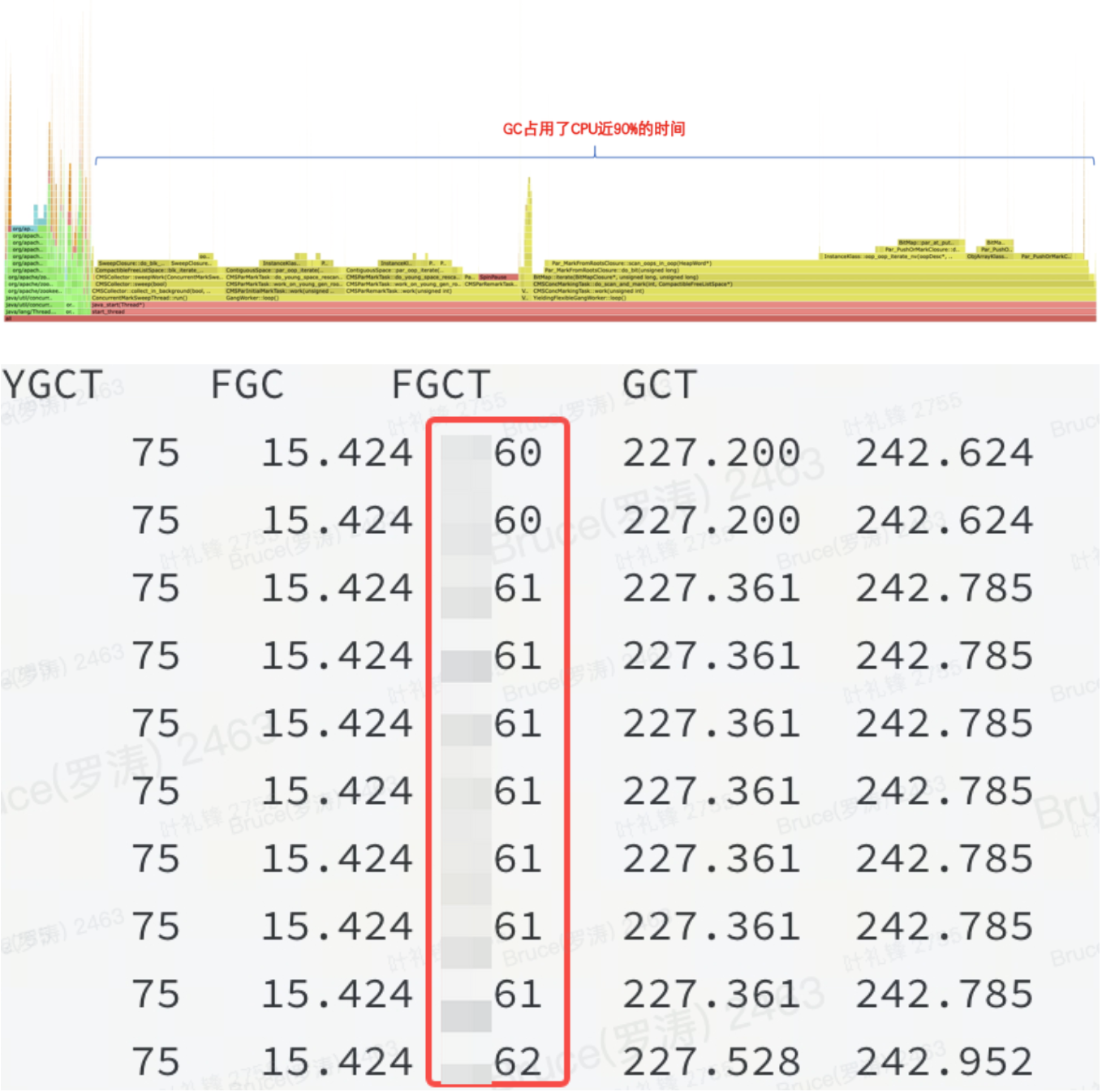
Como se muestra en la figura: significa que un determinado recurso en el montón de JVM ocupa una gran cantidad de memoria y FGC no puede liberarlo.
Análisis de memoria
Para explorar la distribución del uso de memoria en el montón de JVM, inmediatamente realizamos un volcado del montón de JVM. El análisis encontró que la memoria JVM está muy ocupada por childWatches y dataWatches.
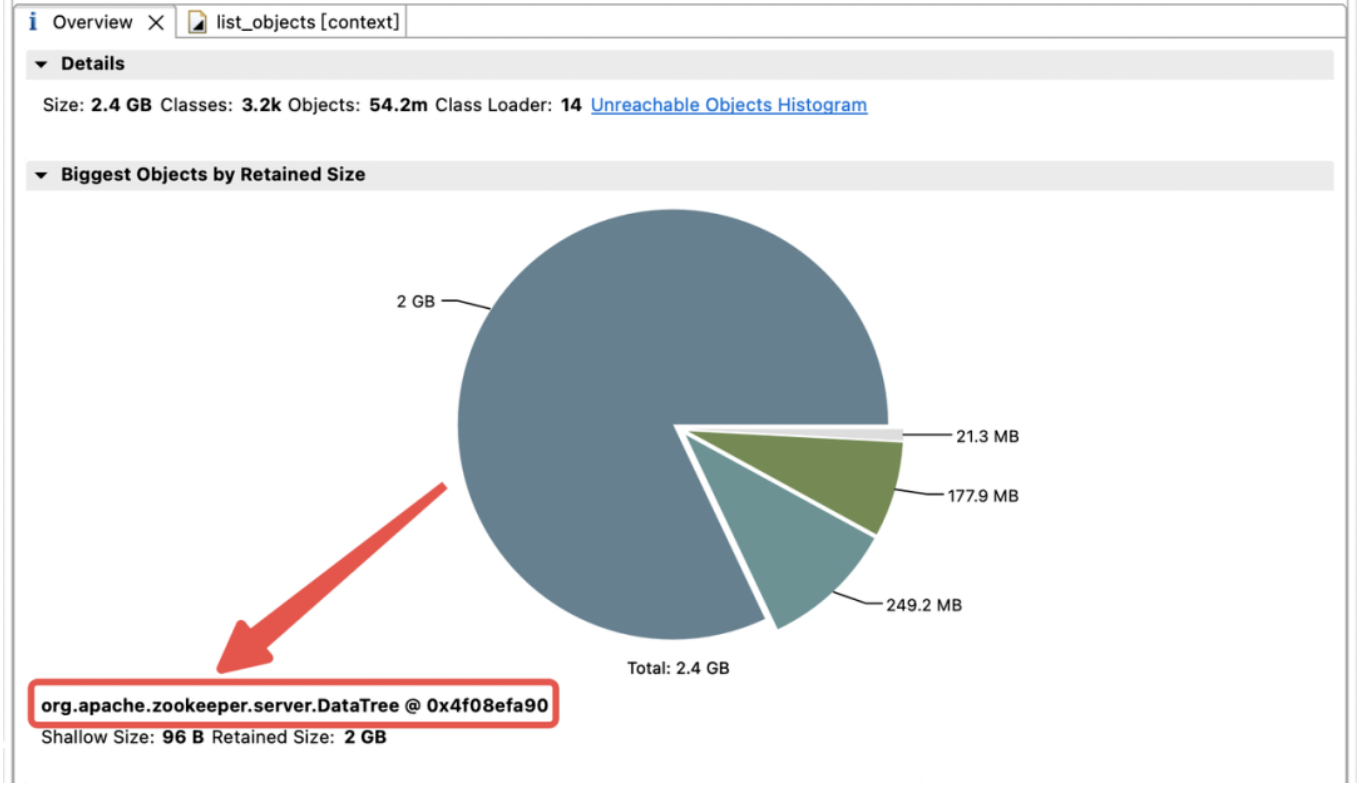
dataWatches: realiza un seguimiento de los cambios en los datos del nodo znode.
childWatches: realiza un seguimiento de los cambios en la estructura del nodo znode (árbol).
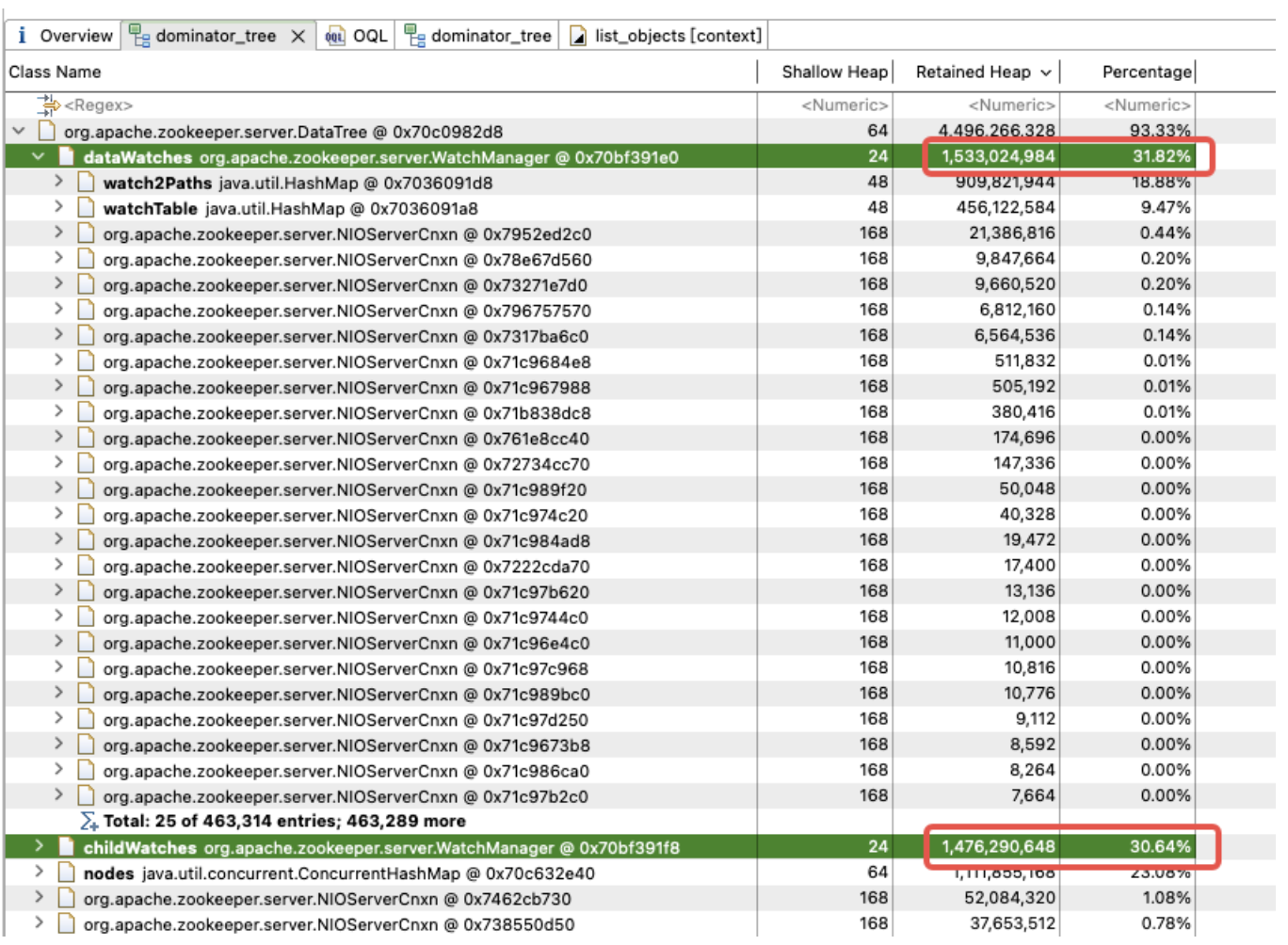
childWatches y dataWatches tienen el mismo origen que WatcherManager.
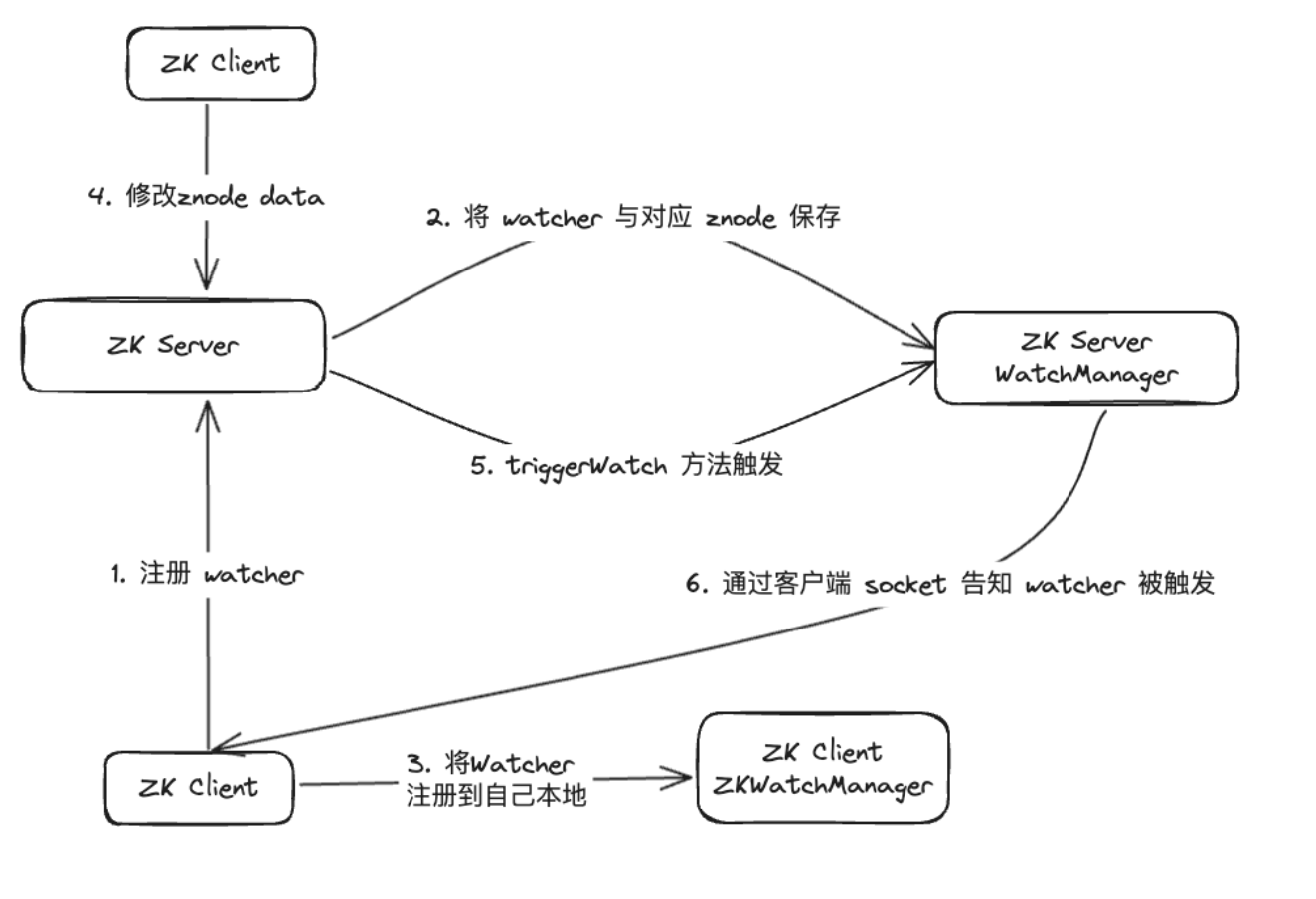
Después de la investigación de datos, descubrimos que WatcherManager es el principal responsable de administrar los Watchers. El cliente ZooKeeper (ZK) primero registra los Vigilantes en el servidor ZooKeeper y luego el servidor ZooKeeper utiliza WatcherManager para administrar todos los Vigilantes. Cuando los datos de un Znode cambian, WatchManager activará el Watcher correspondiente y se comunicará con el socket del cliente ZooKeeper suscrito a Znode. Posteriormente, el administrador de Watch del cliente activará la devolución de llamada de Watcher relevante para ejecutar la lógica de procesamiento correspondiente, completando así todo el proceso de publicación/suscripción de datos.
Un análisis más detallado de WatchManager muestra que la proporción de memoria de las variables miembro Watch2Path y WatchTables es tan alta como (18,88 + 9,47)/31,82 = 90%.
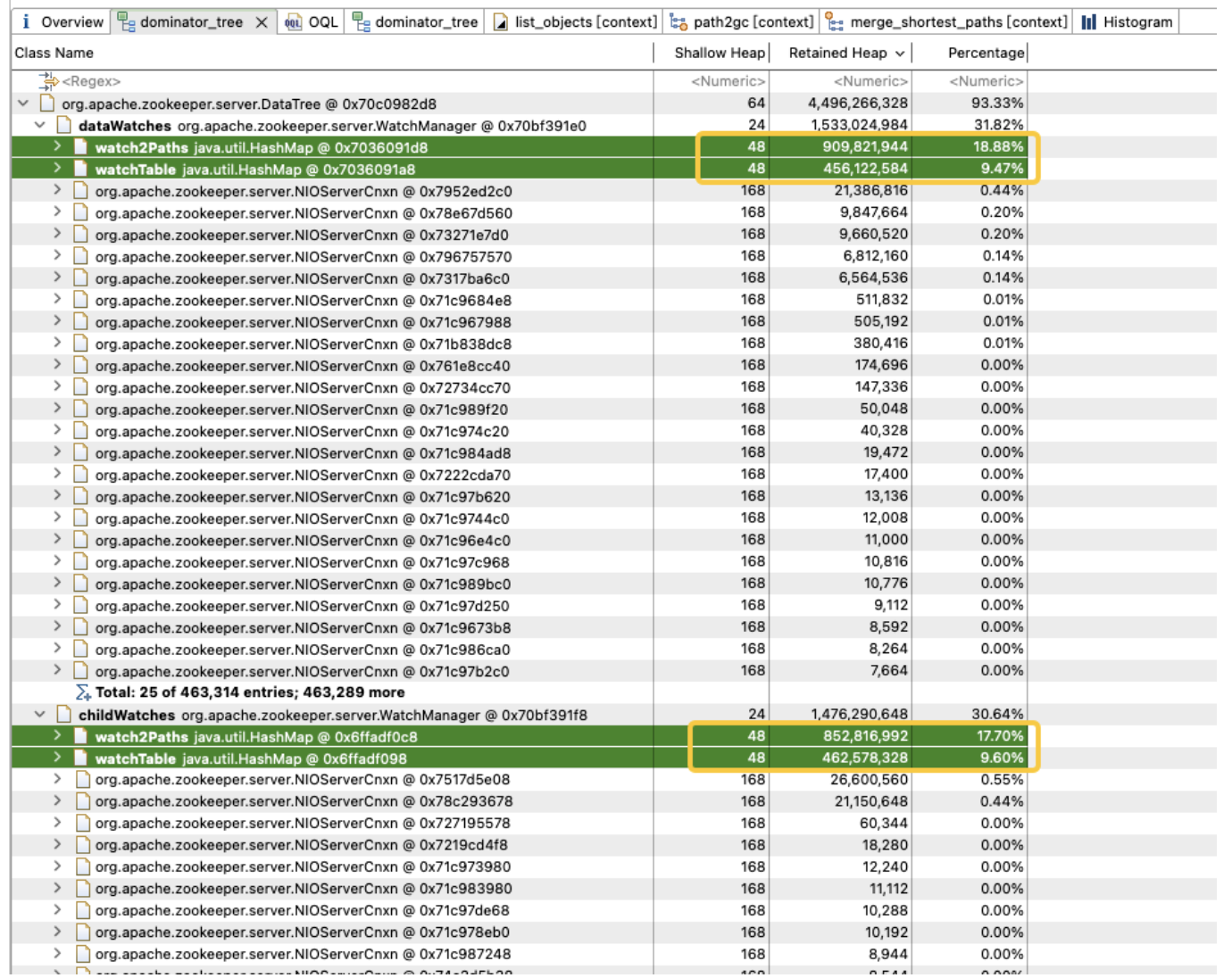
WatchTables y Watch2Path almacenan la relación de mapeo exacta entre ZNode y Watcher, como se muestra en el diagrama de estructura de almacenamiento:
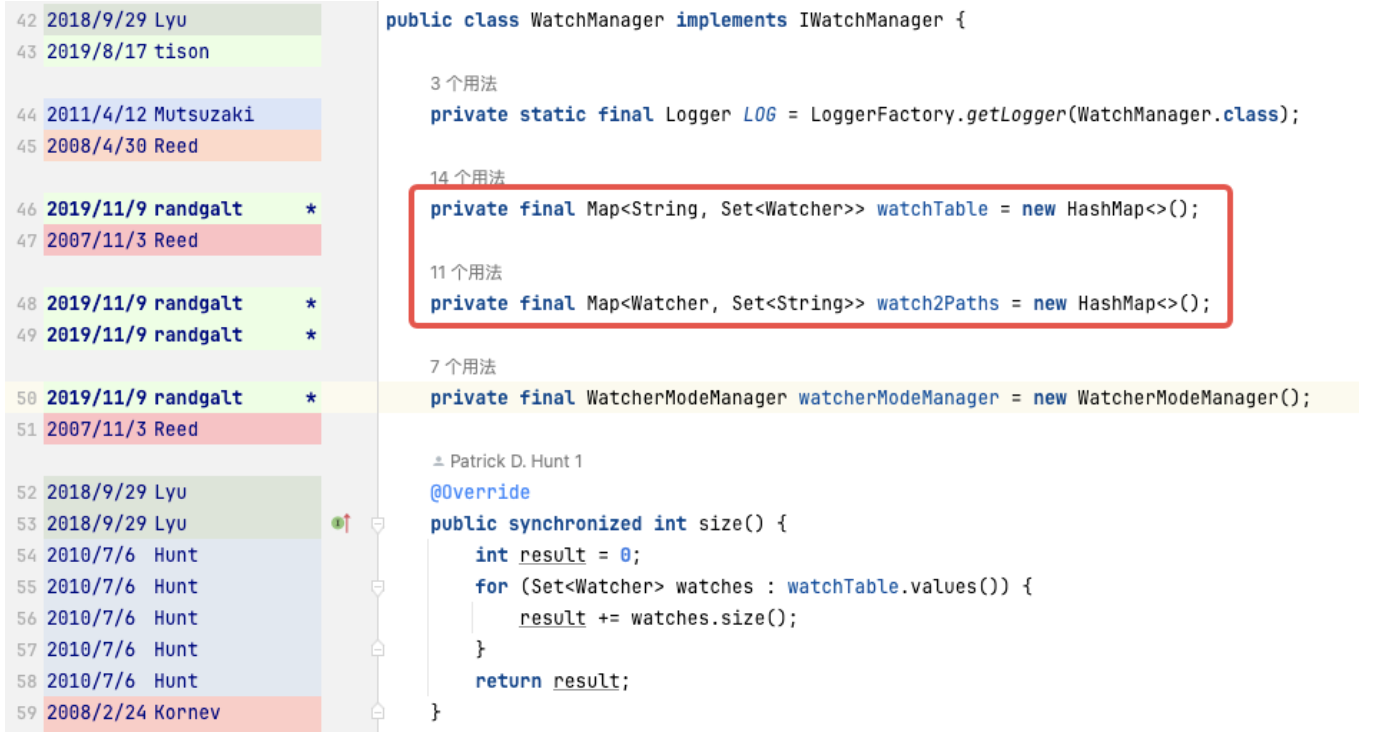
WatchTables [tabla de búsqueda directa]
HashMap<ZNodo, HashSet<Observador>>
Escenario: cuando un ZNode cambia, el observador suscrito al ZNode recibirá una notificación.
Lógica: use este ZNode para encontrar todas las listas de Vigilantes correspondientes a través de WatchTables y luego envíe notificaciones una por una.
Watch2Paths [tabla de búsqueda inversa]
HashMap<Observador, HashSet>
Escenario: contar a qué ZNodes se ha suscrito un determinado observador
Lógica: use este Watcher para encontrar todas las listas de ZNode correspondientes a través de Watch2Paths
Watcher es esencialmente NIOServerCnxn, que puede entenderse como una sesión de conexión.
Si hay una gran cantidad de ZNodes y Watchers, y el cliente se suscribe a una gran cantidad de ZNodes, incluso puede estar suscrito por completo. ¡La relación registrada en estas dos tablas Hash crecerá exponencialmente y eventualmente alcanzará una cantidad enorme!
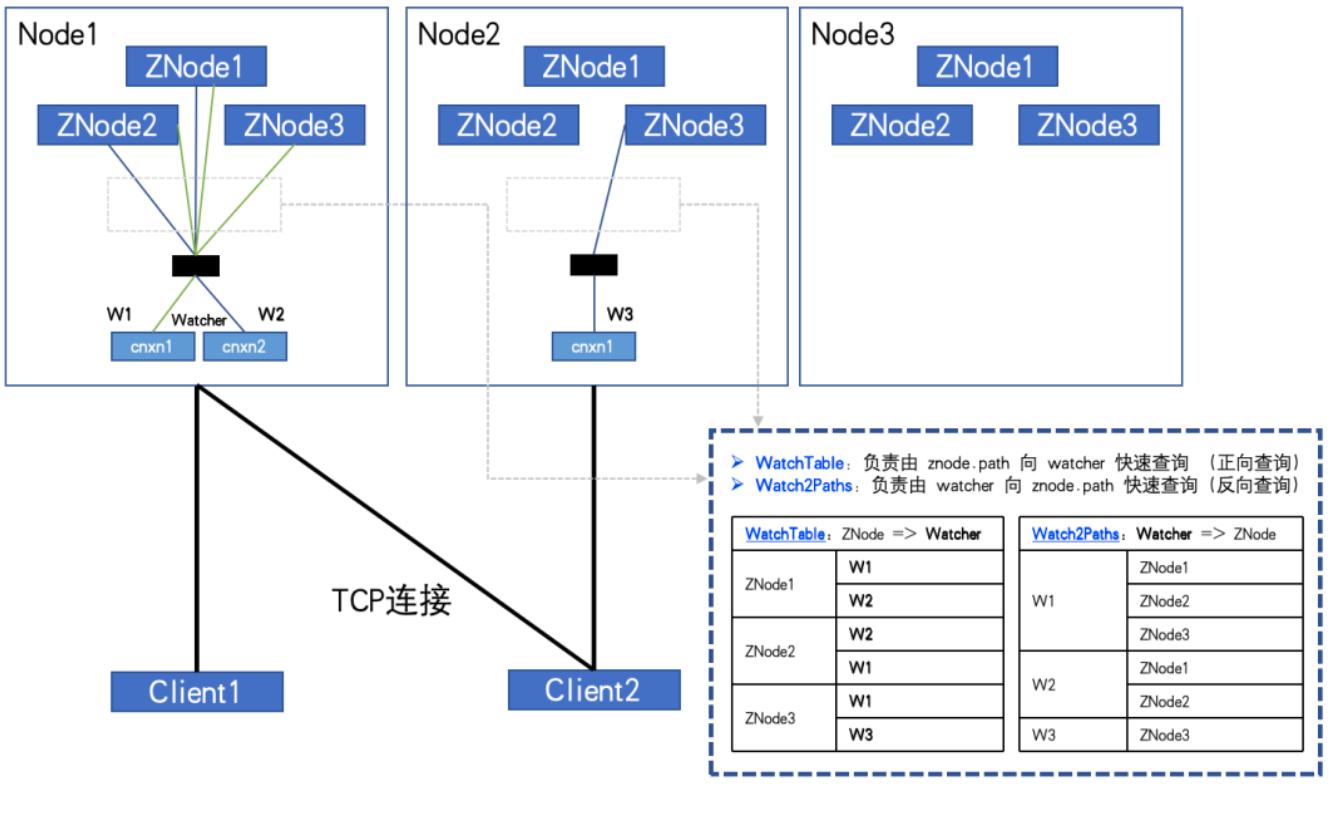
Cuando esté completamente suscrito, como se muestra en la figura:
Cuando el número de ZNodes: 3, el número de Watchers: 2, WatchTables y Watch2Paths tendrán cada uno 6 relaciones.
Cuando el número de ZNodes: 4, el número de Watchers: 3, WatchTables y Watch2Paths tendrán cada uno 12 relaciones.
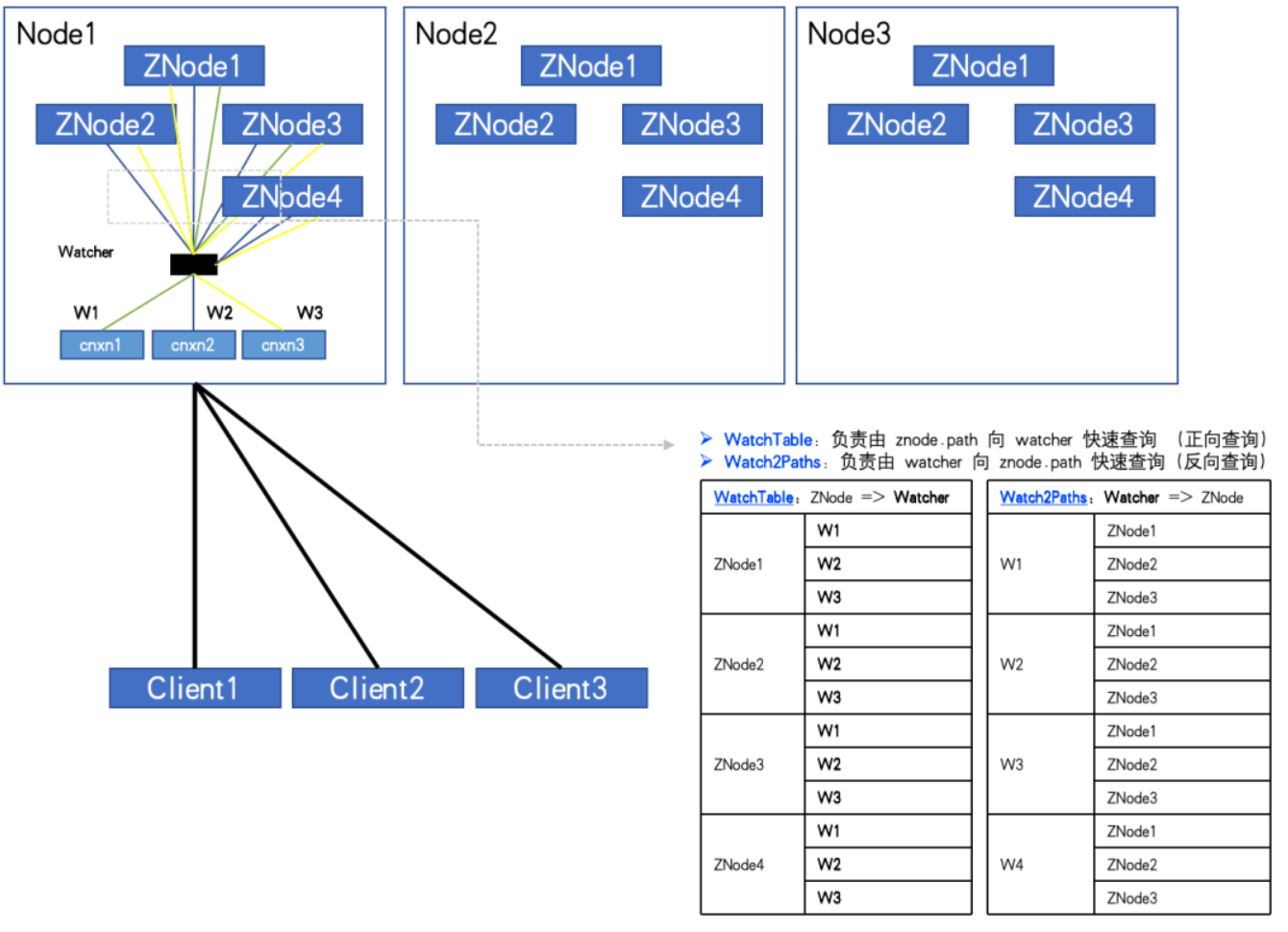
A través del monitoreo, encontramos un ZK-Node anormal. La cantidad de ZNodes es de aproximadamente 20 W y la cantidad de Watchers es de 5000. El número de relaciones entre Watcher y ZNode ha alcanzado los 100 millones.
Si se necesita un HashMap&Node (32Byte) para almacenar cada relación, dado que hay dos tablas de relaciones, duplíquelo. Entonces no calcule nada más. Este "shell" por sí solo requiere 2*10000^2*32/1024^3 = 5,9 GB de sobrecarga de memoria no válida.
En este punto del análisis, todos deberían entenderlo. ¿Por qué nuestra memoria ZK siempre camina sobre la "cuerda floja" y, a menudo, OOM?
descubrimiento inesperado
Ahora que hemos identificado la causa del problema, debemos pensar en cómo solucionarlo.
Del análisis anterior, podemos saber que debemos evitar que el cliente se suscriba por completo a todos los ZNodes. Sin embargo, la realidad es que muchos códigos comerciales tienen esa lógica para atravesar todos los ZNodes comenzando desde el nodo raíz de ZTree y suscribirse completamente a ellos.
Es posible que podamos convencer a algunas partes comerciales para que realicen mejoras, pero no podemos imponer los patrones de uso de todas las partes comerciales. Por tanto, nuestro enfoque para solucionar este problema radica en el seguimiento y la prevención. Sin embargo, desafortunadamente, ZK no admite dicha función, lo que requiere la modificación del código fuente de ZK.
Mediante el seguimiento y análisis del código fuente, encontramos que la fuente del problema apuntaba a WatchManager y estudiamos cuidadosamente los detalles lógicos de esta clase. Después de una comprensión profunda, descubrimos que la calidad de este código parecía haber sido escrito por un recién graduado y que había muchos usos inapropiados de subprocesos y bloqueos. Al observar los registros de Git, descubrimos que este problema se remonta a 2007. Sin embargo, lo interesante es que durante este período apareció WatchManagerOptimized (2018). Al buscar en la información de la comunidad ZK, encontramos [ZOOKEEPER-1177], es decir, en 2011, la comunidad ZK ya se había dado cuenta de que una gran cantidad de Watch causó problemas de uso de memoria y finalmente proporcionó una solución en 2018. Es precisamente por este WatchManagerOptimized que parece que la comunidad ZK ya lo ha optimizado.
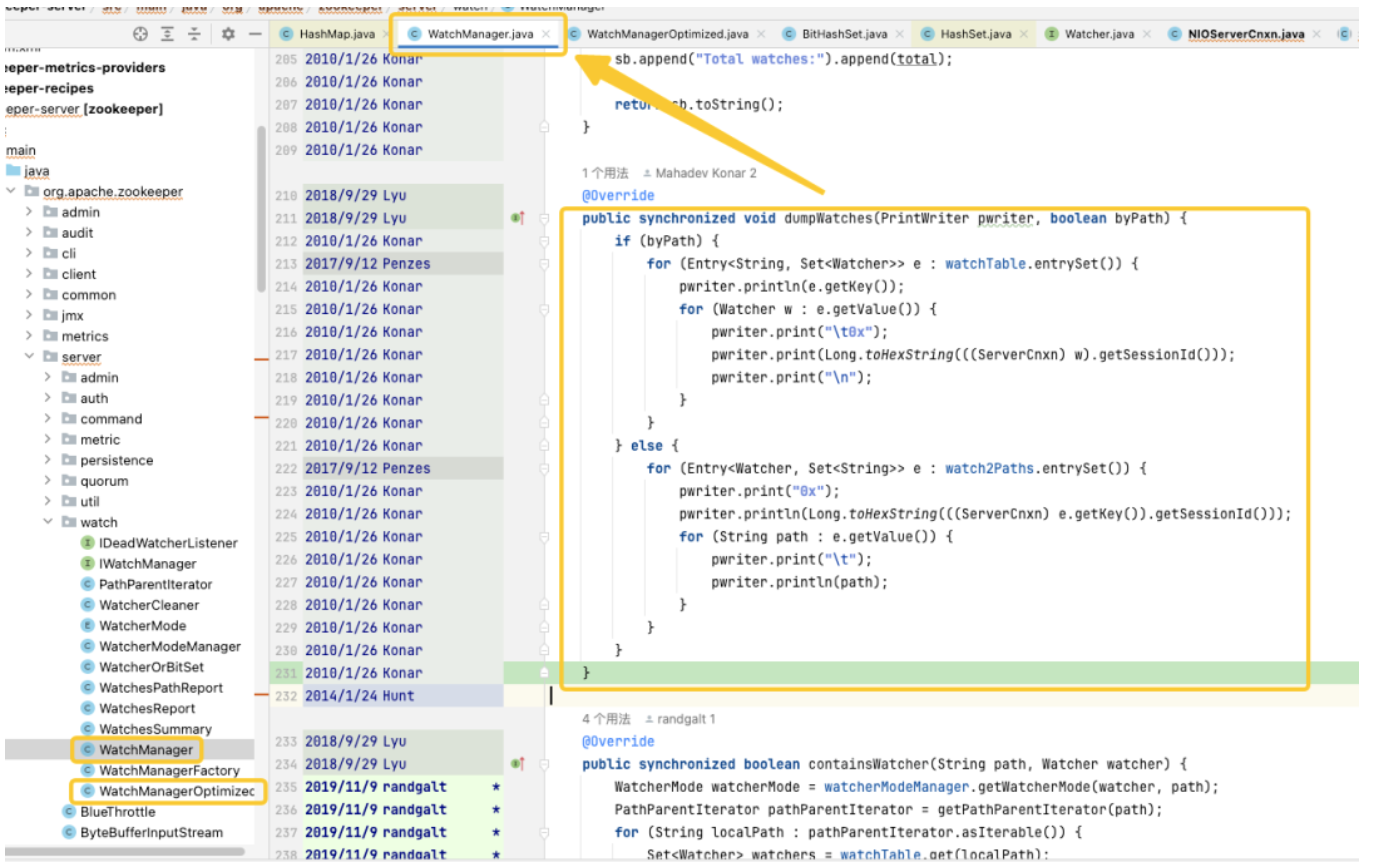
Curiosamente, ZK no habilita esta clase de forma predeterminada, incluso en la última versión 3.9.X, WatchManager todavía se usa de forma predeterminada. Quizás porque ZK es tan antiguo, la gente poco a poco le presta menos atención. Al preguntarles a nuestros colegas de Alibaba, confirmamos que MSE-ZK también habilitó WatchManagerOptimized, lo que confirmó aún más que nuestro enfoque estaba en la dirección correcta. Por ello, pensamos que era necesario profundizar en el potencial de esta clase.
Optimizar la exploración
Optimización de bloqueo
En la versión predeterminada, el HashSet utilizado no es seguro para subprocesos. En esta versión, los métodos de operación relacionados, como addWatch, removeWatcher y triggerWatch, se implementan agregando bloqueos pesados sincronizados a los métodos. En la versión optimizada, utilizamos una combinación de ConcurrentHashMap y ReadWriteLock para utilizar el mecanismo de bloqueo de una manera más refinada. De esta manera, se pueden lograr operaciones más eficientes durante el proceso de agregar Watch y activar Watch.
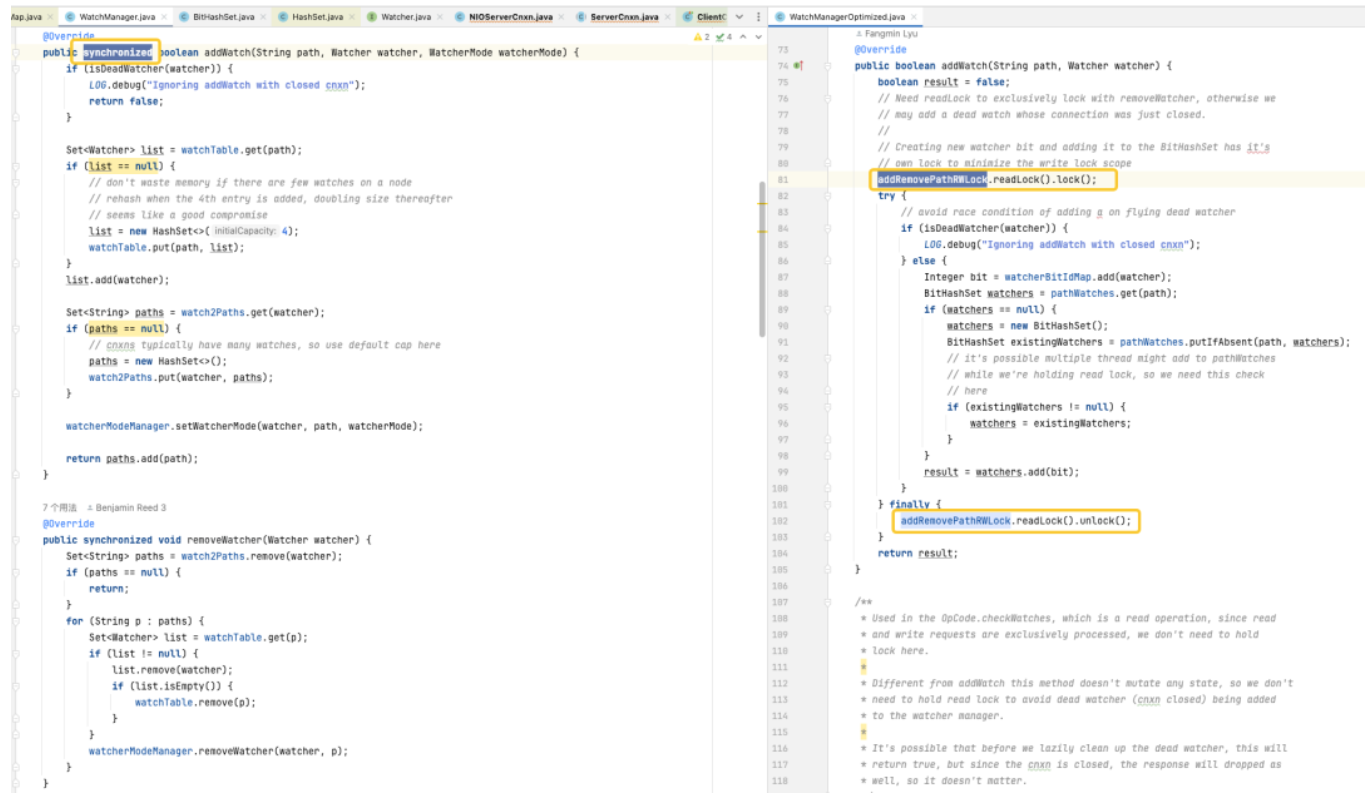
Optimización del almacenamiento
Este es nuestro enfoque. Del análisis de WatchManager, podemos ver que la eficiencia de almacenamiento al usar WatchTables y Watch2Paths no es alta. Si ZNode tiene muchas relaciones de suscripción, se consumirá una gran cantidad de memoria adicional no válida.
Para nuestra sorpresa, WatchManagerOptimized utiliza "tecnología negra" -> mapa de bits aquí.
El almacenamiento relacional está fuertemente comprimido utilizando mapas de bits para lograr la optimización de la reducción de dimensionalidad.
Características principales de Java BitSet:
-
Ahorro de espacio: BitSet utiliza matrices de bits para almacenar datos, lo que requiere menos espacio que las matrices booleanas estándar.
-
Procesamiento rápido: realizar operaciones bit a bit (como AND, OR, XOR, voltear) suele ser más rápido que las operaciones lógicas booleanas correspondientes.
-
Expansión dinámica: el tamaño de un BitSet puede crecer dinámicamente según sea necesario para acomodar más bits.
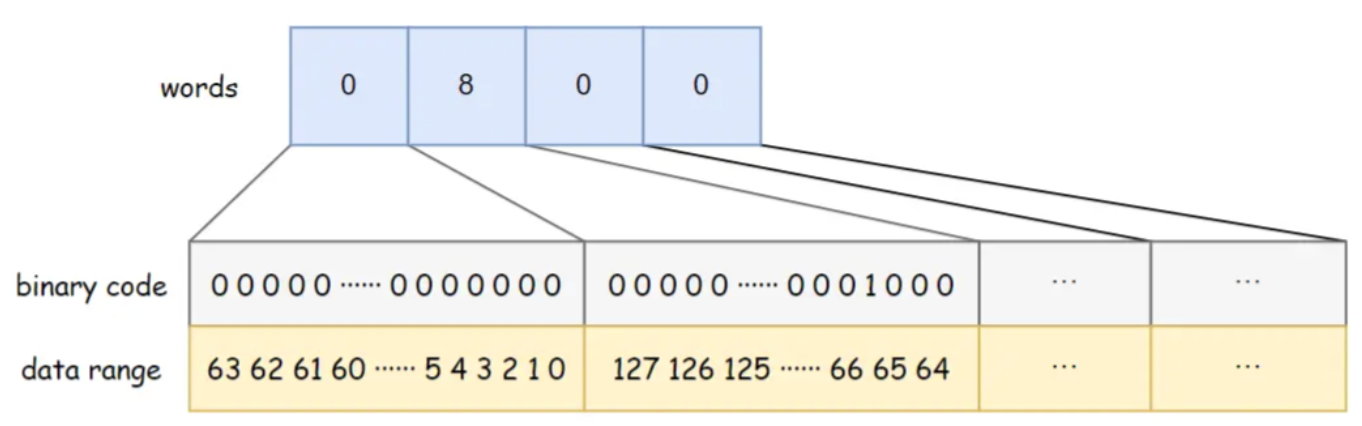
BitSet utiliza palabras largas [] para almacenar datos, el tipo largo ocupa 8 bytes y tiene 64 bits . Cada elemento de la matriz puede almacenar 64 datos y el orden de almacenamiento de los datos en la matriz es de izquierda a derecha, de menor a mayor .
Por ejemplo, el BitSet en la figura siguiente tiene una capacidad de 4 palabras. Las palabras [0] de menor a mayor indican si existen los datos 0 ~ 63, las palabras [1] de menor a mayor indican si existen los datos 64 ~ 127, y así en. Entre ellos, palabras [1] = 8, y el bit binario correspondiente 8 es 1, lo que indica que hay datos {67} almacenados en BitSet en este momento.
WatchManagerOptimized usa BitMap para almacenar todos los Watchers. De esta forma, incluso si hay un Vigilante de 1W. El consumo de memoria del mapa de bits es de solo 8 Byte*1W/64/1024= 1,2 KB . Si cambia a HashSet, necesitará al menos 32Byte*10000/1024=305KB y la eficiencia del almacenamiento será casi 300 veces diferente.
WatchManager.java:private final Map<String, Set<Watcher>> watchTable = new HashMap<>();private final Map<Watcher, Set<String>> watch2Paths = new HashMap<>();
WatchManagerOptimized.java:private final ConcurrentHashMap<String, BitHashSet> pathWatches = new ConcurrentHashMap<String, BitHashSet>();private final BitMap<Watcher> watcherBitIdMap = new BitMap<Watcher>();
El almacenamiento de mapeo de ZNode a Watcher se cambia de Map<string, set> a ConcurrentHashMap<string, BitHashSet >. Es decir, el conjunto ya no se almacena, pero el mapa de bits se utiliza para almacenar el valor del índice del mapa de bits.
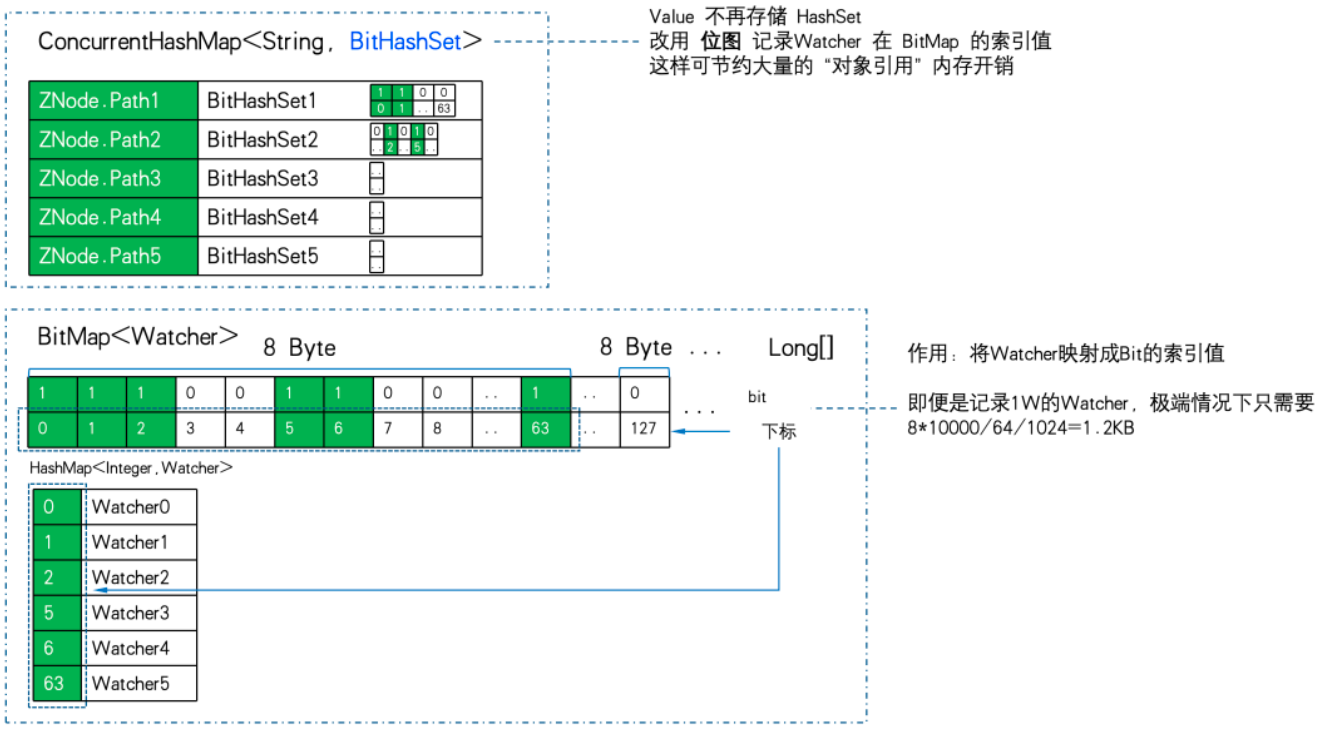
Usamos 1W ZNode, 1W Watcher y, en el extremo, usamos una suscripción completa (todos los Watchers se suscriben a todos los ZNodes) para realizar PK de eficiencia de almacenamiento:

Puede ver que 11,7 MB PK 5,9 GB , la diferencia en la eficiencia del almacenamiento de memoria es: 516 veces .
Optimización lógica
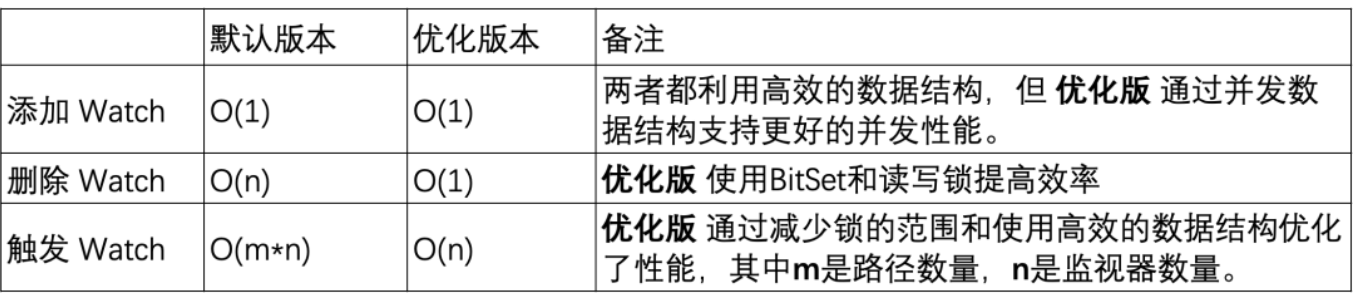
-
Agregar un monitor: ambas versiones pueden completar operaciones en tiempo constante, pero la versión optimizada proporciona un mejor rendimiento de concurrencia mediante el uso de ConcurrentHashMap .
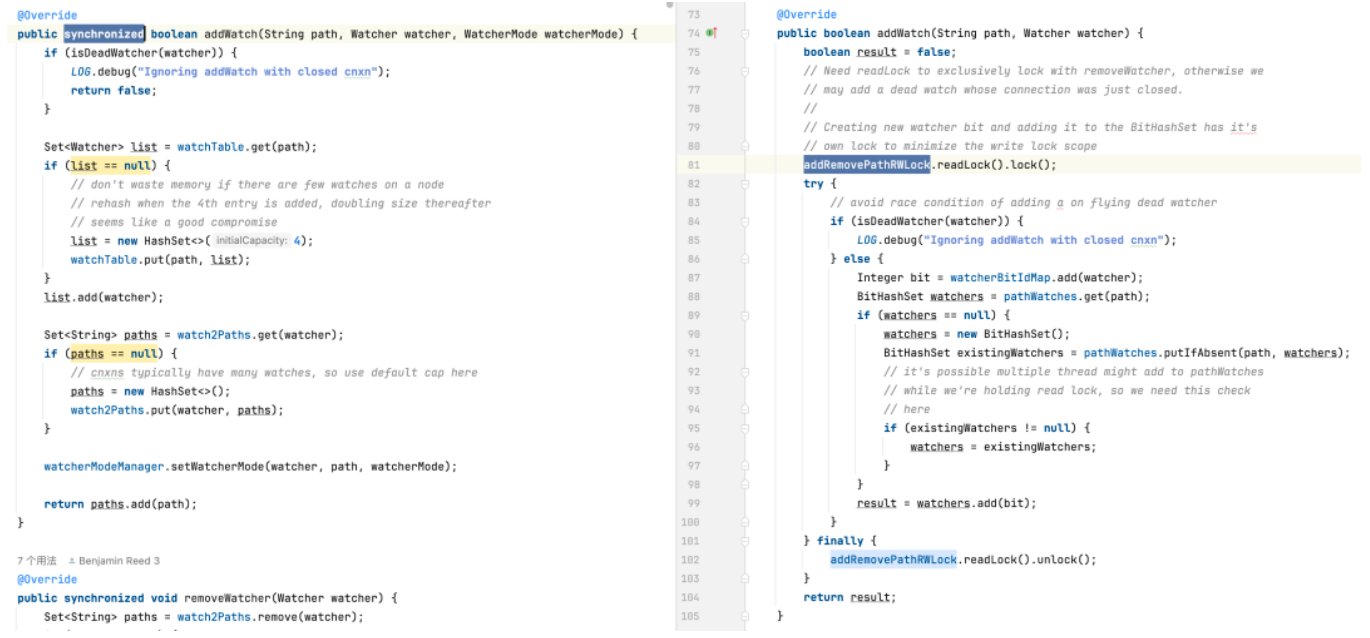
-
Eliminación de un monitor: es posible que la versión predeterminada deba recorrer toda la colección de monitores para buscar y eliminar el monitor, lo que genera una complejidad temporal de O(n). La versión optimizada utiliza BitSet y ConcurrentHashMap para localizar y eliminar rápidamente monitores en O(1) en la mayoría de los casos.
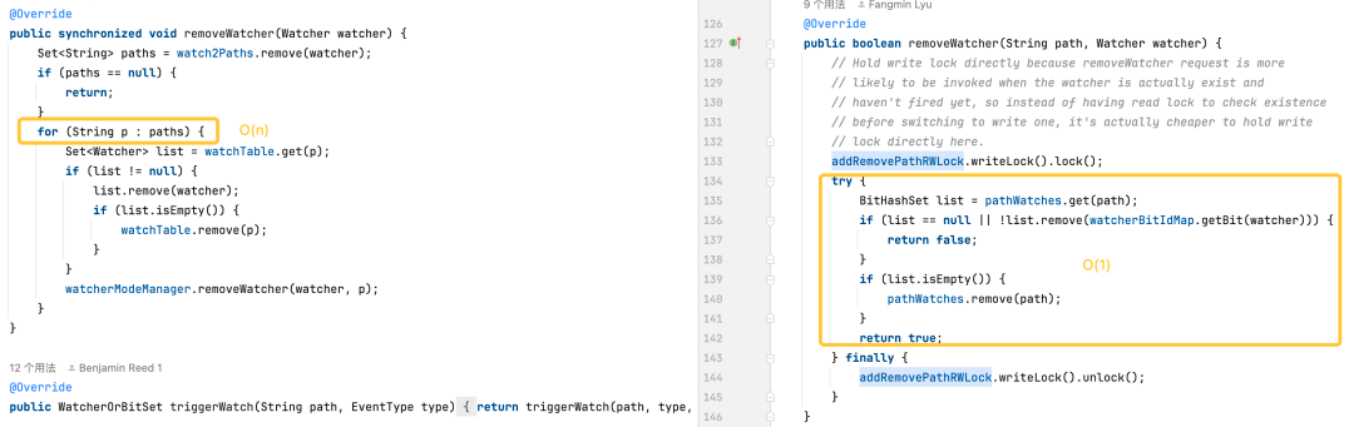
-
Activación de monitores: la versión predeterminada es más compleja porque requiere operaciones en cada monitor en cada ruta. La versión optimizada optimiza el rendimiento de los monitores de activación a través de estructuras de datos más eficientes y un uso reducido de bloqueos.
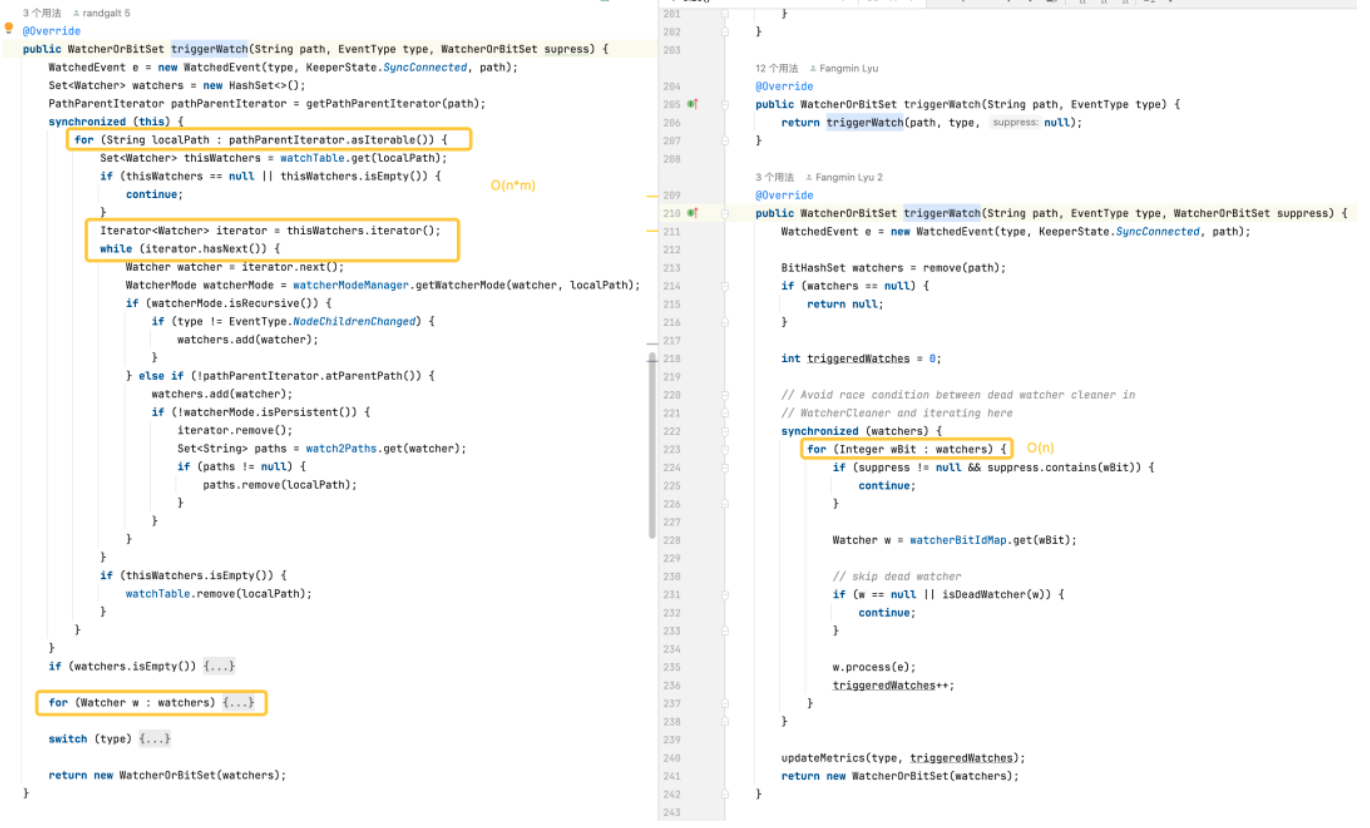
3. Prueba de estrés de desempeño
micropunto de referencia JMH
Compilación del código fuente de Zookeeper 3.6.4, prueba de estrés del micrófono JMH WatchBench.
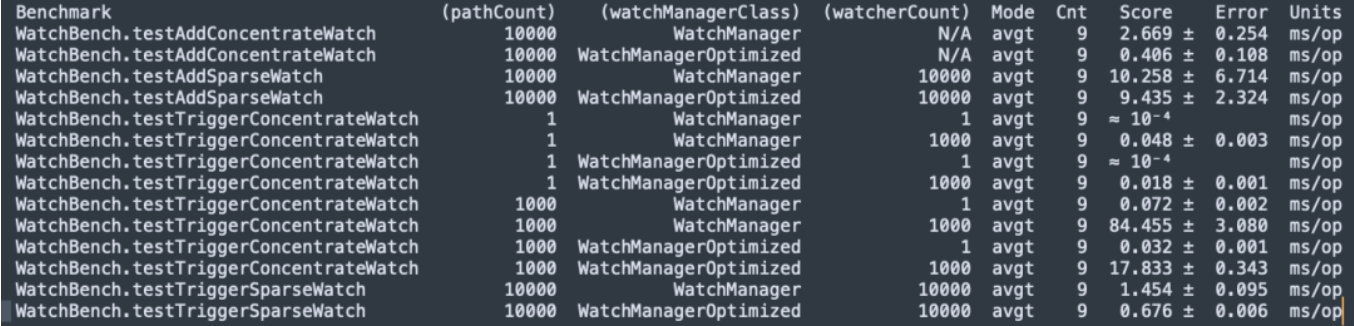
pathCount: indica el número de rutas de ZNode utilizadas en la prueba.
watchManagerClass: representa la clase de implementación WatchManager utilizada en la prueba.
watcherCount: Indica el número de observadores (Watchers) utilizados en la prueba.
Modo: indica el modo de prueba, aquí está avgt, que indica el tiempo de ejecución promedio.
Cnt: Indica el número de ejecuciones de prueba.
Puntuación: Indica la puntuación de la prueba, es decir, el tiempo medio de ejecución.
Error: Indica el rango de error de la puntuación.
Unidades: la unidad que representa la puntuación, aquí es milisegundos/operación (ms/op).
-
Hay 1 millón de suscripciones entre ZNode y Watcher: la versión predeterminada usa 50 MB y la versión optimizada solo requiere 0,2 MB y no aumentará linealmente.
-
Al agregar Watch, la versión optimizada (0,406 ms/op) es 6,5 veces más rápida que la versión predeterminada (2,669 ms/op).
-
Se activa una gran cantidad de vigilancias y la versión optimizada (17,833 ms/op) es 5 veces más rápida que la versión predeterminada (84,455 ms/op).
Prueba de estrés de rendimiento
A continuación, creamos un conjunto de zookeeper 3.6.4 de 3 nodos en una máquina (32C 60G), utilizando la versión optimizada y la versión predeterminada para realizar una comparación de pruebas de estrés de capacidad.
Escenario 1: ruta corta de znode de 20 W
Ruta corta de Znode: /demo/znode1

Escenario 2: ruta larga de znode de 20 W
Ruta larga de Znode: /sentinel-cluster/dev/xx-admin-interfaces/lock/_c_bb0832d5-67a5-48ab-8fe0-040b9ddea-lock/12

-
El uso de la memoria de vigilancia está relacionado con la longitud de la ruta de ZNode.
-
La cantidad de relojes aumenta linealmente en la versión predeterminada y funciona muy bien en la versión optimizada, lo cual es una mejora muy obvia para la optimización del uso de la memoria.
Prueba de escala de grises
Según las pruebas de referencia y las pruebas de capacidad anteriores, la versión optimizada tiene una optimización de memoria obvia en una gran cantidad de escenarios de Watch. A continuación, comenzamos a realizar observaciones de prueba de actualización en escala de grises en el clúster ZK en el entorno de prueba.
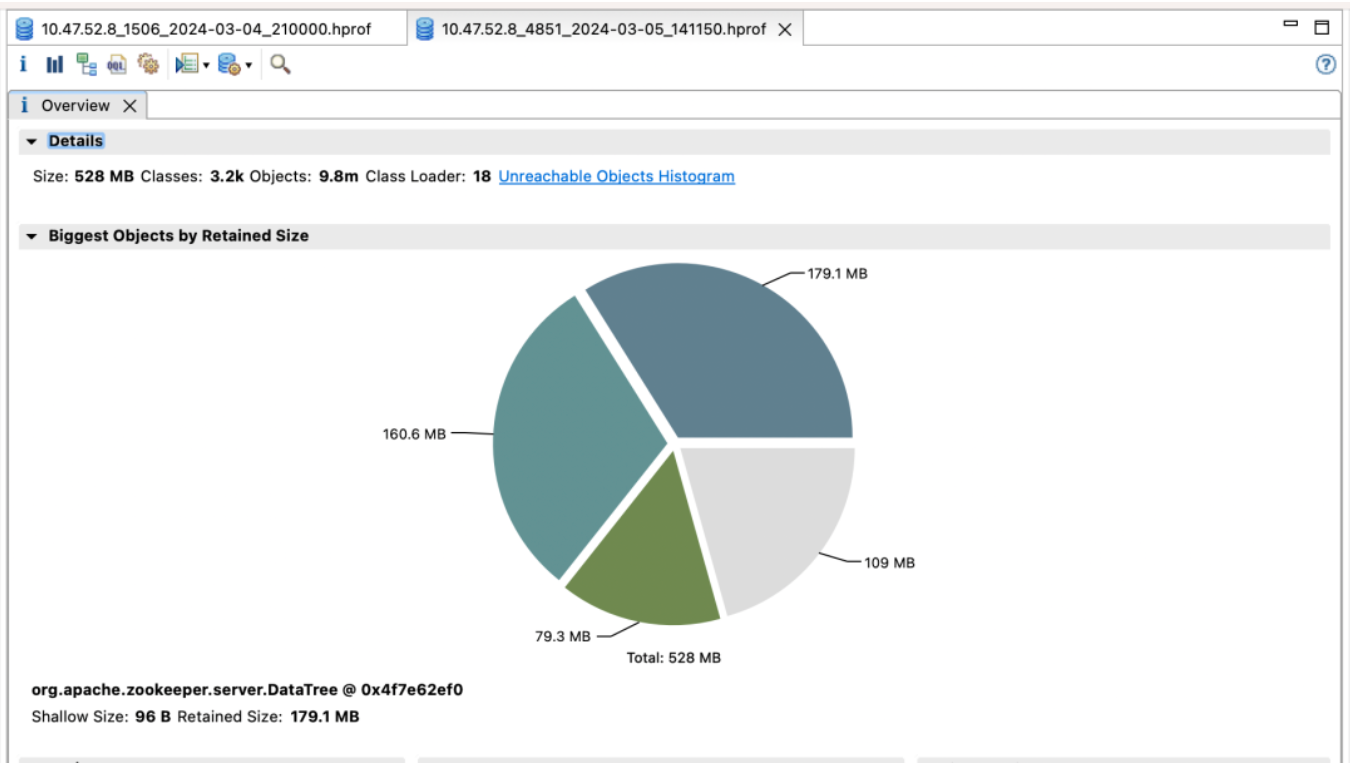
El primer grupo de cuidadores del zoológico y sus beneficios

Versión predeterminada
Versión optimizada
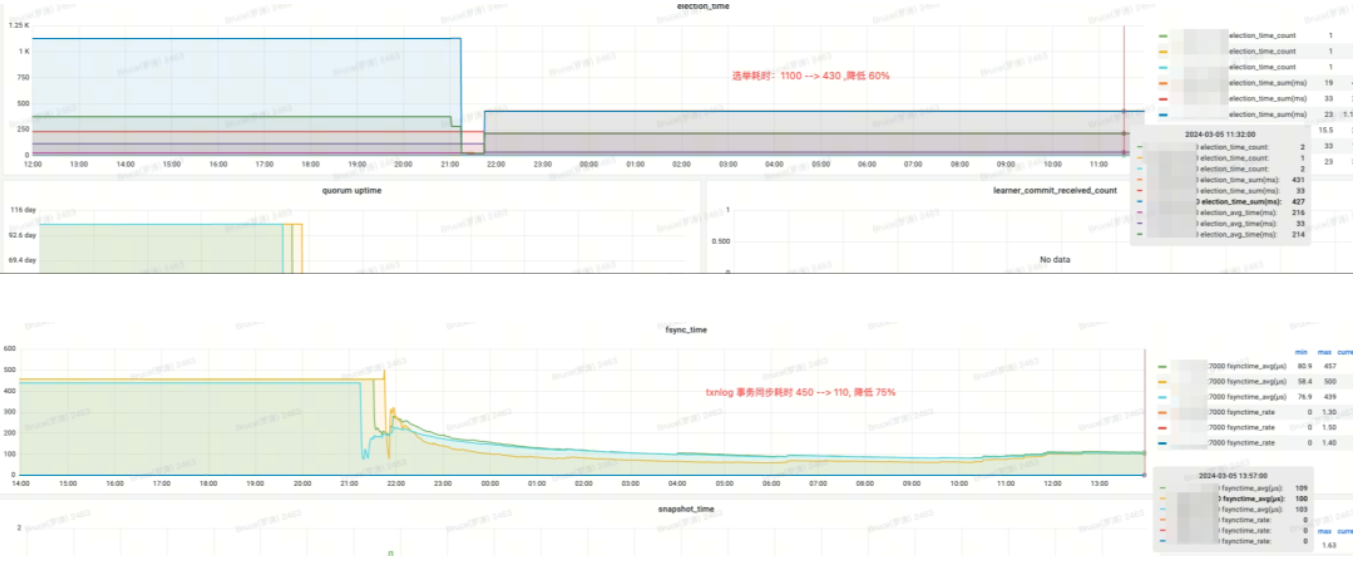
Efecto ingreso:
-
elección_time (tiempo de elección): reducido en un 60%
-
fsync_time (tiempo de sincronización de transacciones): reducido en un 75%
-
Uso de memoria: reducido en un 91%
El segundo grupo de cuidadores del zoológico y sus beneficios
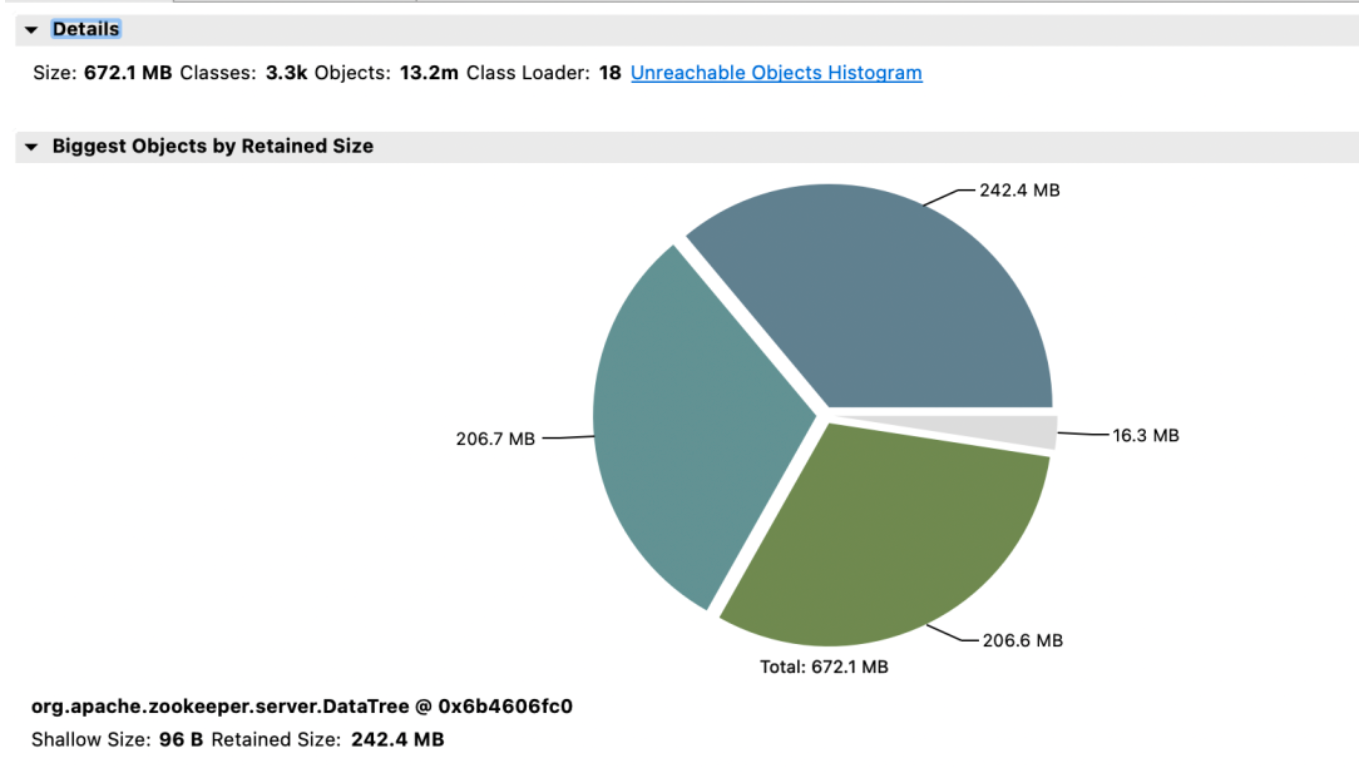
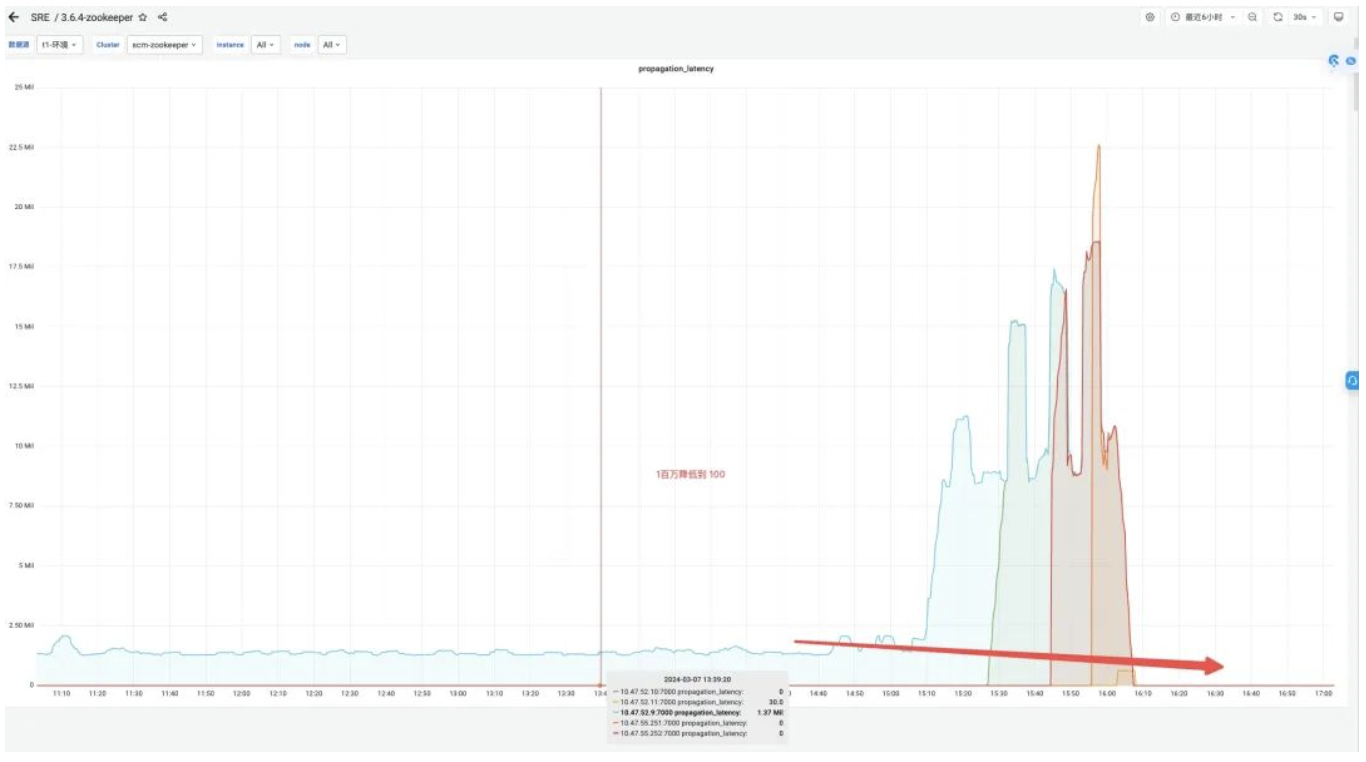
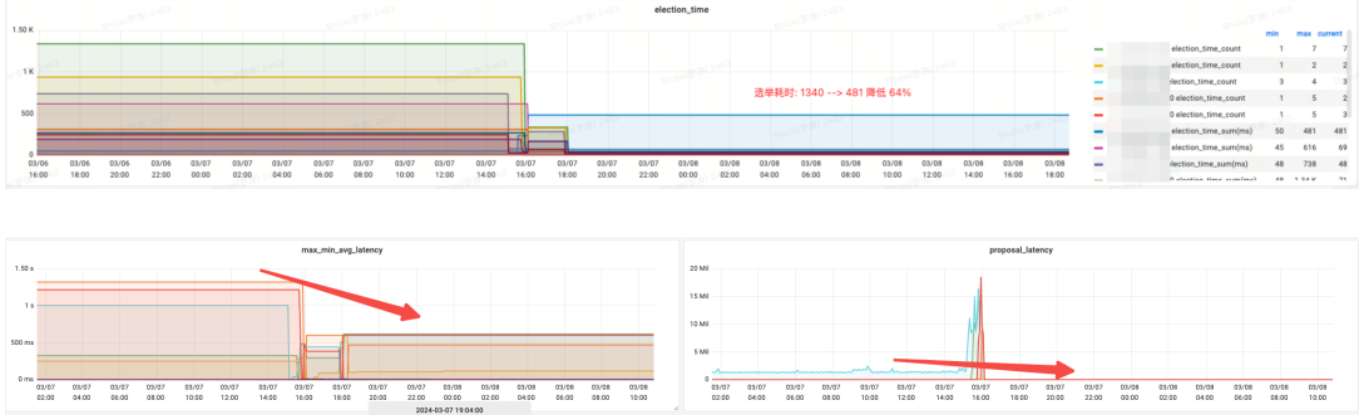
Efecto ingreso:
-
Memoria: antes del cambio, la respuesta JVM Attach no respondió y la recopilación de datos falló.
-
elección_time (tiempo de elecciones): reducido en un 64%.
-
max_latency (latencia de lectura): reducida en un 53%.
-
propuesta_latencia (retraso de la propuesta de procesamiento electoral): 1400000 ms --> 43 ms.
-
propagation_latency (retardo de propagación de datos): 1400000 ms --> 43 ms.
El tercer conjunto de grupos de cuidadores del zoológico y sus beneficios
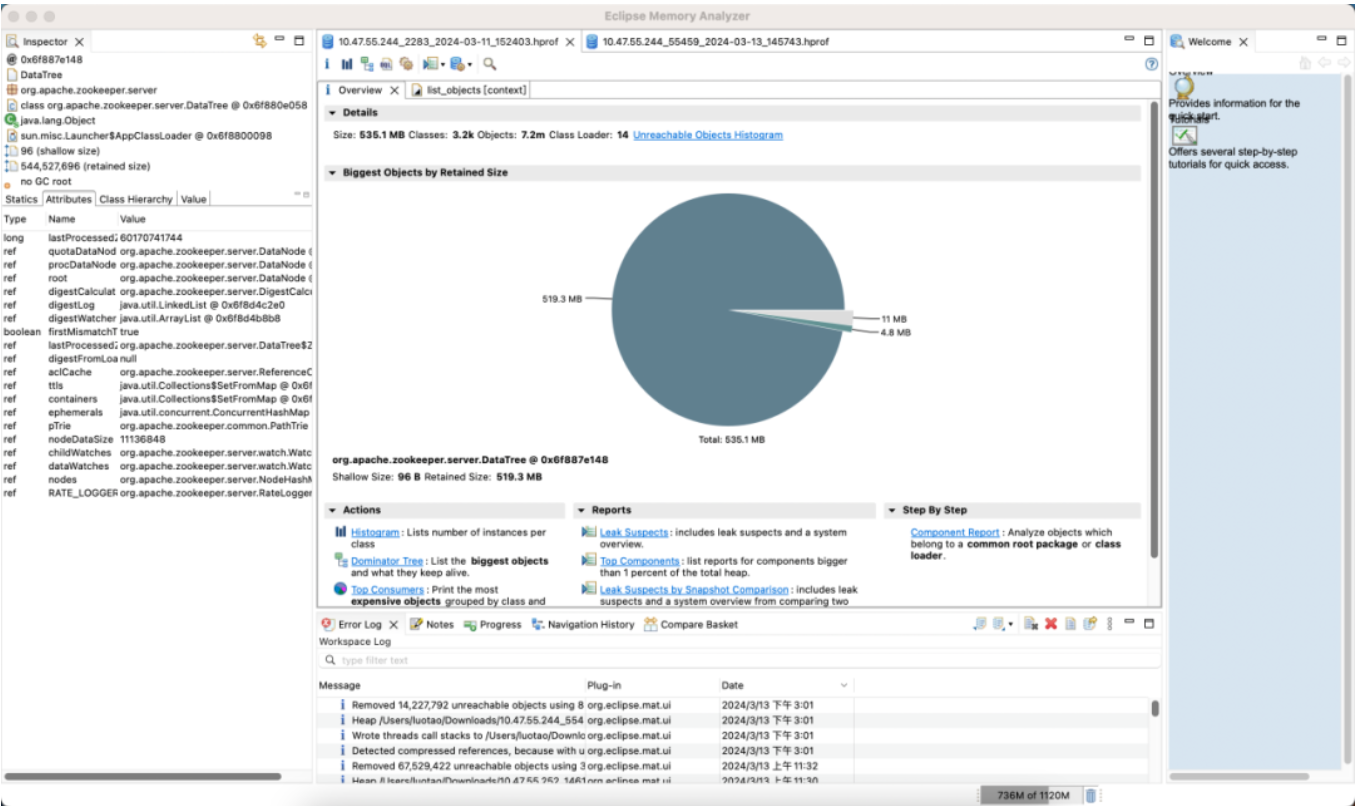
Versión predeterminada
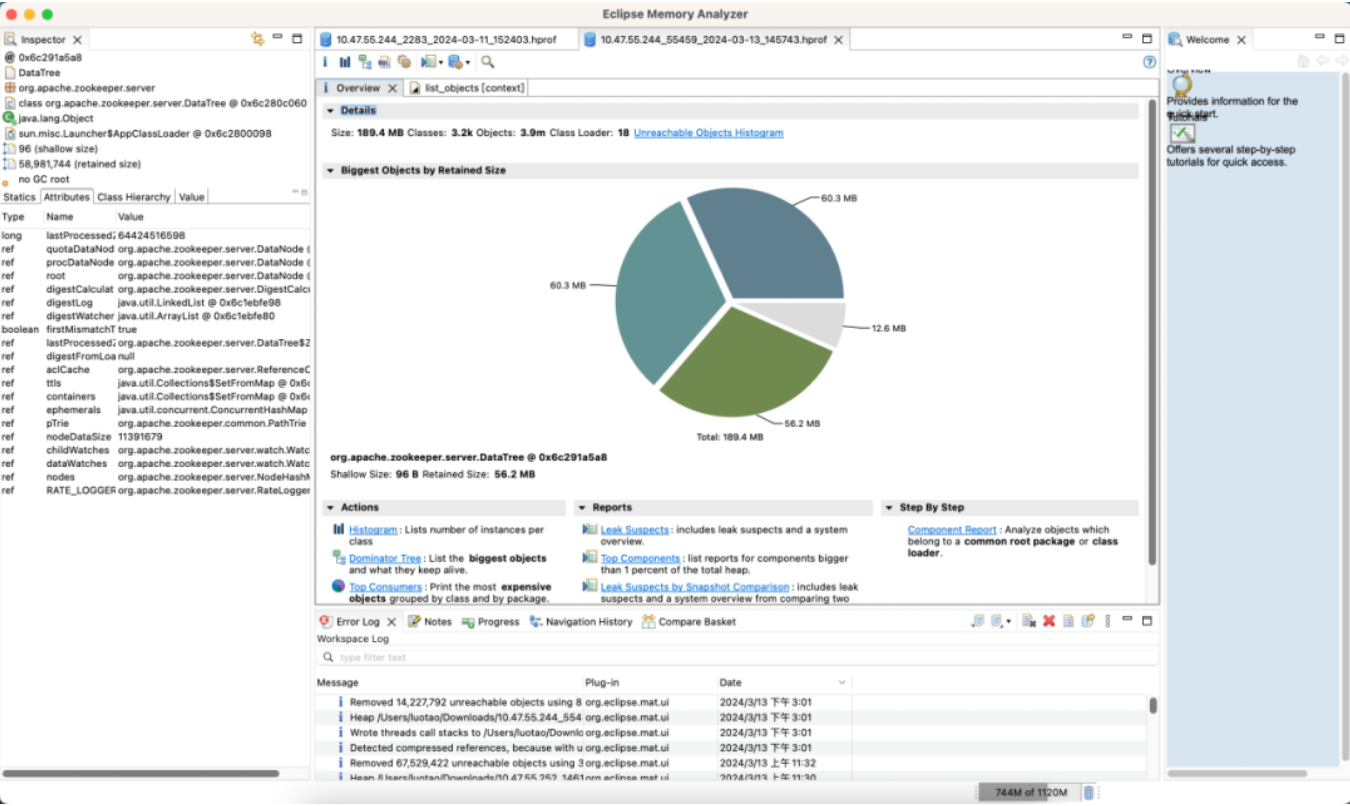
Versión optimizada
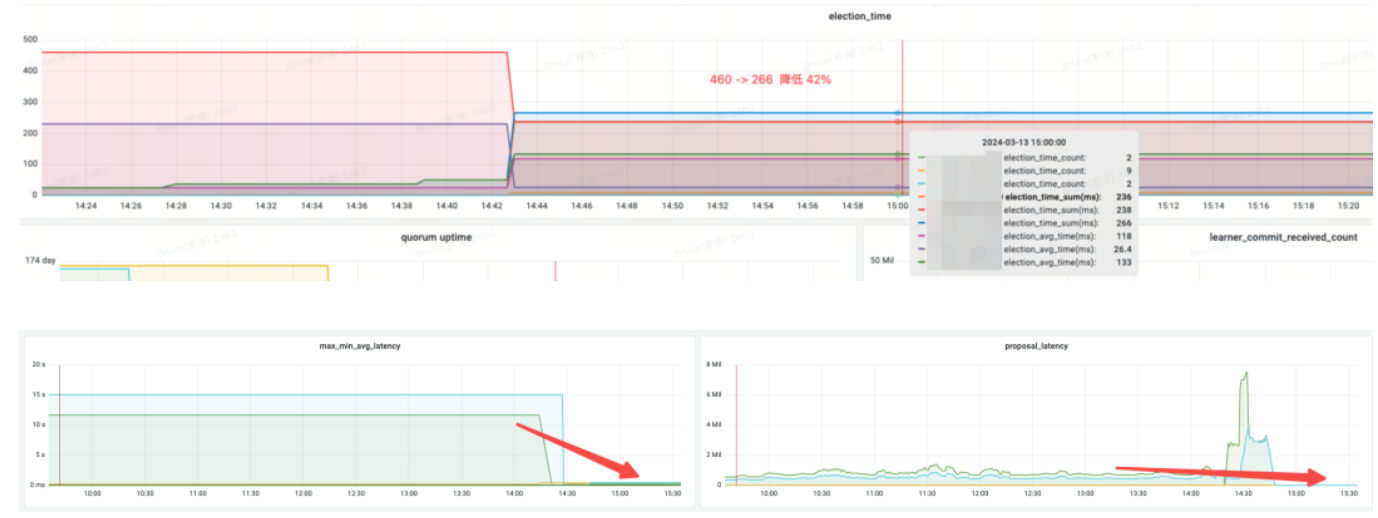
Efecto ingreso:
-
Memoria: Ahorre 89%
-
elección_time (tiempo de elecciones): reducido en un 42%
-
max_latency (latencia de lectura): reducida en un 95%
-
propuesta_latencia (retraso de la propuesta de procesamiento electoral): 679999 ms --> 0,3 ms
-
propagation_latency (retardo de propagación de datos): 928000 ms--> 5 ms
4. Resumen
A través de pruebas comparativas anteriores, pruebas de estrés de rendimiento y pruebas de escala de grises, descubrimos WatchManagerOptimized de Zookeeper. Esta optimización no solo ahorra memoria, sino que también mejora significativamente indicadores como la elección y la sincronización de datos entre nodos mediante la optimización de bloqueo, mejorando así la coherencia de Zookeeper. También tuvimos discusiones en profundidad con estudiantes de Alibaba MSE, cada uno de ellos simuló pruebas de estrés en escenarios extremos y llegamos a un consenso: WatchManagerOptimized mejora significativamente la estabilidad de Zookeeper. En general, esta optimización mejora el SLA de Zookeeper en un orden de magnitud.
ZooKeeper tiene muchas opciones de configuración, pero en la mayoría de los casos no se requiere ningún ajuste. Para mejorar la estabilidad del sistema, recomendamos las siguientes optimizaciones de configuración:
-
Monte dataDir (directorio de datos) y dataLogDir (directorio de registro de transacciones) en diferentes discos respectivamente y utilice almacenamiento en bloque de alto rendimiento.
-
Para ZooKeeper versión 3.8, se recomienda usar JDK 17 y habilitar el recolector de basura ZGC; para las versiones 3.5 y 3.6, se recomienda usar JDK 8 y habilitar el recolector de basura G1. Para estas versiones, simplemente configure -Xms y -Xmx.
-
Ajuste el valor predeterminado del parámetro SnapshotCount de 100.000 a 500.000, lo que puede reducir significativamente la presión del disco cuando ZNode cambia a altas frecuencias.
-
Utilice la versión optimizada de Watch Manager WatchManagerOptimized.
Árbitro:
https://issues.apache.org/jira/browse/ZOOKEEPER-1177
https://github.com/apache/zookeeper/pull/590
*Texto/ Bruce
Este artículo es original de Dewu Technology. Para obtener más artículos interesantes, consulte: Sitio web oficial de Dewu Technology
La reimpresión sin el permiso de Dewu Technology está estrictamente prohibida; de lo contrario, se perseguirá la responsabilidad legal de acuerdo con la ley.
La primera actualización importante de JetBrains 2024 (2024.1) es de código abierto. Incluso Microsoft planea pagar por ella. ¿Por qué todavía se le critica por ser de código abierto? [Recuperado] El backend de Tencent Cloud falló: una gran cantidad de errores de servicio y no hay datos después de iniciar sesión en la consola. Alemania también necesita ser "controlable de forma independiente". El gobierno estatal migró 30,000 PC de Windows a Linux deepin-IDE y finalmente logró ¡arranque! Se lanza Visual Studio Code 1.88. Buen chico, Tencent realmente ha convertido a Switch en una "máquina de aprendizaje pensante". El escritorio remoto de RustDesk inicia y reconstruye el cliente web. La base de datos de terminal de código abierto de WeChat basada en SQLite, WCDB, ha recibido una actualización importante.