

Autor | Algún día
Introducción
Este artículo presenta principalmente los conceptos y aplicaciones de inteligencia empresarial (BI) y análisis de datos de Turing (TDA). BI ayuda a las empresas a tomar mejores decisiones y planificación estratégica mediante la recopilación, organización, análisis y presentación de datos. Sin embargo, existen problemas con las ideas tradicionales de construcción de BI, como la necesidad de redesarrollo cuando el negocio cambia los requisitos de datos y la baja eficiencia del análisis de los datos subyacentes. Por lo tanto, TDA surgió como una plataforma de análisis de autoservicio integral. Crea conjuntos de datos públicos de acuerdo con temas de análisis basados en datos detallados. Los usuarios pueden arrastrar y soltar análisis libremente y guardar los resultados con un solo clic, y también pueden compartirlos con otros para ver. Sin embargo, la construcción de TDA también enfrenta desafíos como indicadores de dimensiones de análisis integrales, calibre de datos precisos y rendimiento de consultas. En respuesta a estos desafíos, planteamos objetivos de integridad, precisión, eficiencia y velocidad, y logramos estos objetivos a través de mecanismos de procesos y construcción de funciones, así como el motor de datos MPP.
El texto completo tiene 4766 palabras y el tiempo estimado de lectura es de 15 minutos.
01 Antecedentes y objetivos
BI significa Business Intelligence, que ayuda a las empresas a mantenerse por delante de sus competidores y tomar mejores decisiones comerciales y planificación estratégica mediante la recopilación, organización, análisis y presentación de datos. El proceso de recopilación y organización es la construcción de un almacén de datos, y el análisis y presentación de datos es la construcción de una plataforma de análisis visual.
Una idea de construcción de BI común en la industria: si la empresa quiere ver los cambios de datos de un determinado indicador, solicita al middle office. Los datos RD se modelan capa por capa desde ODS>DWD>DWS>ADS, y luego se personalizan. La tabla de resultados de ADS se desarrolla e implementa en Palo/Mysql y, finalmente, configura varios gráficos y los guarda en informes para su visualización empresarial. Aunque esta idea de construcción satisface las necesidades de análisis de datos de la empresa, enfrenta dos problemas: 1. Cuando la empresa cambia los requisitos de datos, la tabla de resultados de ADS debe personalizarse y desarrollarse nuevamente, lo que ocupará repetidamente mano de obra de I + D; 2. Solo resuelve el problema; Problema del análisis empresarial. Si desea profundizar y analizar las razones de las fluctuaciones, será difícil porque la tabla subyacente es una tabla agregada que solo contiene los datos del gráfico actual. Si desea analizarlos, solo puede descargarlos. los datos detallados y luego analizarlos a través de Excel u otros métodos, lo cual es relativamente ineficiente.
TDA (Turing Data Analysis) es una plataforma de análisis de autoservicio integral creada para resolver el problema mencionado anteriormente de los enlaces de análisis largos en BI.
La idea de construcción de TDA: basándose en la tabla amplia detallada de DWD, los conjuntos de datos públicos se construyen de acuerdo con el tema de análisis (los datos de un solo día son decenas de millones +), los usuarios pueden arrastrar y soltar análisis basados en los conjuntos de datos públicos. libremente, y los resultados del análisis se pueden guardar en paneles personales o publicar con un solo clic. Cree un panel público y compártalo con otros; otros pueden verificar la tendencia de fluctuación en el panel público, profundizar en la página de análisis visual para continuar explorando el causas de las fluctuaciones y completar el análisis integral de "ver tendencias, descomponer dimensiones y descubrir detalles" Tres ejes.
La siguiente figura es el proceso general de las ideas de construcción de TDA:
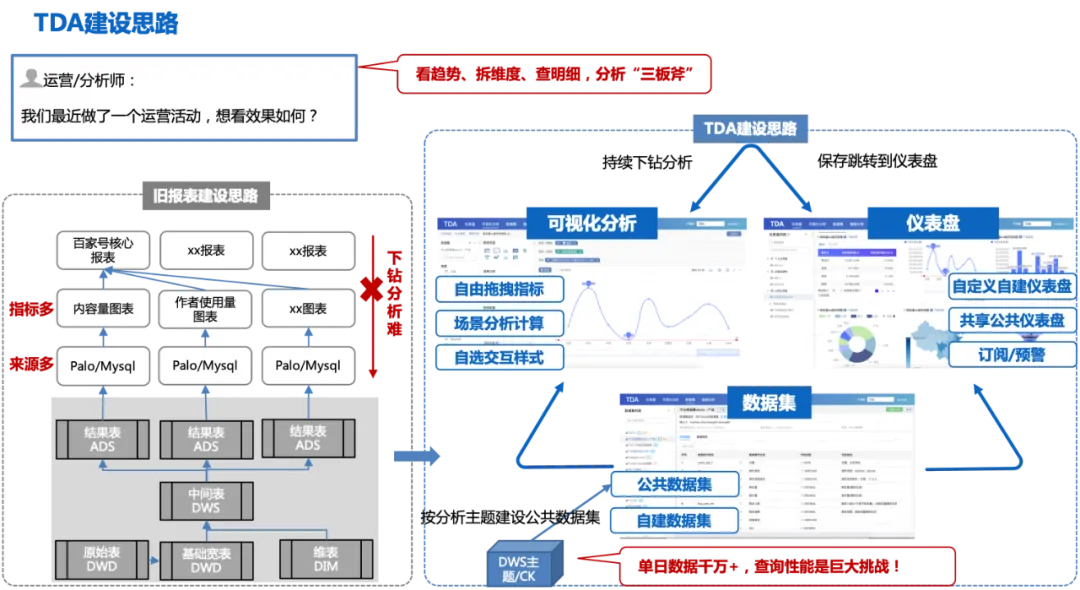
Esta idea de construcción también enfrentará algunos desafíos:
1. Los indicadores de la dimensión de análisis deben estar completos; de lo contrario, será necesario construir múltiples conjuntos de datos, lo que dará como resultado muchos conjuntos de datos dispersos, el mismo problema que la construcción del informe anterior;
2. El calibre de los datos debe ser preciso y autorizado;
3. Con decenas de millones de datos en un solo día, el rendimiento de las consultas es un gran desafío.
En respuesta a los desafíos anteriores, también hemos formulado objetivos correspondientes para satisfacer las necesidades de un análisis empresarial eficiente:
1. Completo (los indicadores de la dimensión de análisis deben estar completos y cubrir más del 80% de las necesidades comerciales);
2. Preciso (calibre uniforme, datos precisos);
3. Puntualidad (la puntualidad de la salida de datos es T+10h);
4. Rápido (consulta de datos de mil millones de niveles en 10 segundos).
La plataforma TDA garantizará una construcción de conjuntos de datos completa, precisa y eficiente desde la perspectiva del mecanismo de proceso y la construcción de funciones, se combinará con el motor de datos MPP para garantizar el rendimiento de las consultas y mejorará la eficiencia del análisis de los usuarios a través de arrastrar y soltar visual de BI, análisis de escenas. modelado de autoservicio y otras capacidades.
02 Solución técnica
Según el análisis anterior, el posicionamiento del producto de TDA es una plataforma de BI que permite a los usuarios realizar consultas de autoservicio integrales. Los usuarios pueden arrastrar y soltar libremente conjuntos de datos, realizar análisis de datos visuales y crear paneles de control centrales. Ayude a los usuarios a lograr una experiencia integral de análisis de consultas desde las siguientes perspectivas:
Iteración de Kanban empresarial y mejora de la eficiencia (autoservicio) : el modo de iteración del informe de datos ha cambiado, del modo de programación RD de solicitud de PM a una conversión gradual a operación de autoservicio de operación/PM (realización de Kanban/análisis de datos).
Mejora de la eficiencia del análisis de información de datos (extremadamente rápida) : una sola consulta de datos se reduce de minutos a segundos, la eficiencia del análisis de fluctuación del indicador aumenta 20 veces y el análisis de extremo a extremo de la atribución de fluctuación de un solo indicador se realiza en 2 horas -> 5 minutos.
Análisis empresarial de autoservicio integral (one-stop) : realiza observación de tendencias de datos, análisis detallado dimensional, exportación detallada y otras funciones, logrando una experiencia integrada de monitoreo y análisis de datos.
La matriz de funciones de este producto es la siguiente:
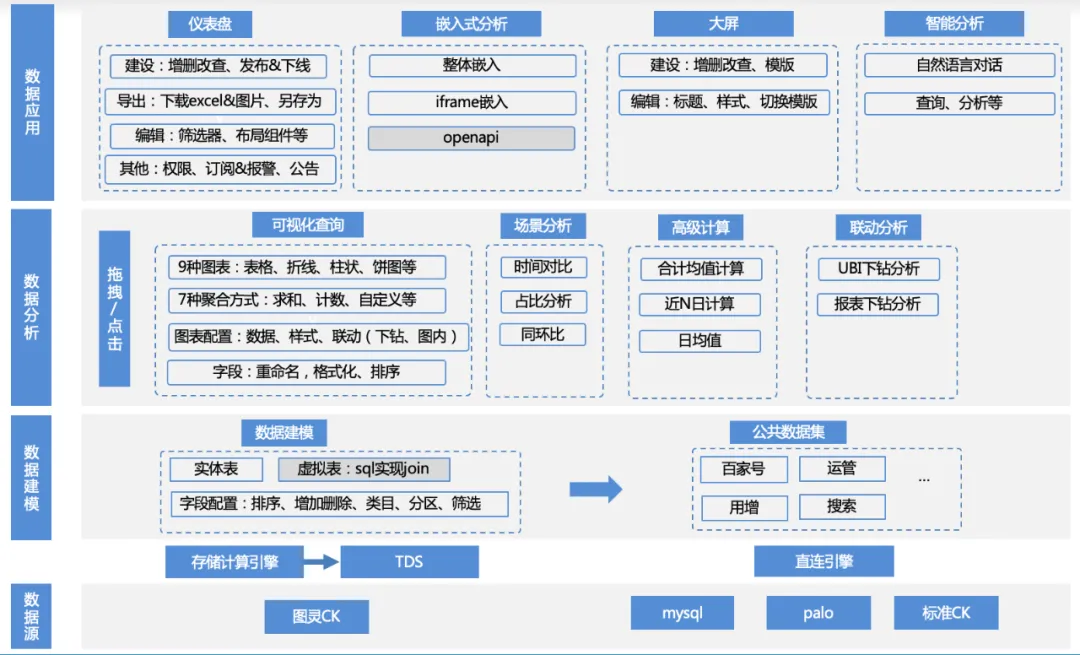
1. Acceso a la fuente de datos : la empresa utiliza TDS para calcular los datos de la tabla de Turing ascendente a través del motor de cálculo, luego escribe los datos en motores como clickhouse/mysql/palo y accede a ellos a través de una conexión directa, o la empresa proporciona su propio palo. / acceso a la fuente de datos mysql.
a Gestión de fuentes de datos: adición, eliminación, modificación y consulta de fuentes de datos, clickhouse/mysql/palo y otras adaptaciones del controlador del motor.
2. Modelado de datos : después de conectarse a la fuente de datos, los datos se pueden cargar en el producto escribiendo SQL y directamente desde la tabla original. Pero estas tablas normalmente requieren un procesamiento secundario simple para convertirlas en conjuntos de datos que puedan analizarse.
a. Gestión de conjuntos de datos: funciones como agregar, eliminar, modificar, vista previa de datos, visualización de esquemas, análisis visual con un solo clic, etc.
B. Gestión de campos del conjunto de datos: adición, eliminación, modificación, clasificación de campos, campos personalizados, etc.
c. Gestión de categorías de conjuntos de datos: adición, eliminación, modificación y clasificación personalizada de las categorías a las que pertenecen los campos, etc.
d. Gestión del directorio del conjunto de datos: adición, eliminación, modificación y clasificación personalizada del directorio del conjunto de datos, etc.
3. Análisis de datos : según el conjunto de datos, los usuarios pueden arrastrar y soltar libremente indicadores, dimensiones y filtros, seleccionar tipos de gráficos y métodos de análisis de escenarios apropiados, y realizar análisis y cálculos.
a. Configuración de datos: cambiar conjuntos de datos, agregar campos personalizados.
b. Configuración del gráfico: tabla, gráfico de líneas, gráfico de barras, gráfico circular y otras configuraciones de tipo gráfico, configuración de color de leyenda, configuración de formato de datos, etc.
c.Análisis de escenarios: soporte para múltiples capacidades de análisis de escenarios, como valor promedio diario, comparación año tras año, proporción, total, etc.
d. Análisis de atribución: capacidades de análisis de atribución de autoservicio.
e. Análisis interactivo: análisis detallado, etc.
4. Aplicación de datos : los usuarios pueden guardar los resultados del análisis en el panel, incrustarlos en una plataforma de terceros, guardarlos en la pantalla grande o usarlos directamente para análisis inteligentes, etc.
a. Gestión del panel: adición, eliminación, modificación del panel, clasificación personalizada, publicación y fuera de línea, exportación de datos, alertas de suscripción, etc.
b Análisis integrado: ifame integrado, sdk integrado y otros modos integrados.
c. Pantalla grande: pantalla grande en tiempo real.
d. Análisis inteligente: análisis conversacional LUI.
2.1 Diseño general
La arquitectura general de TDA se muestra en la siguiente figura:
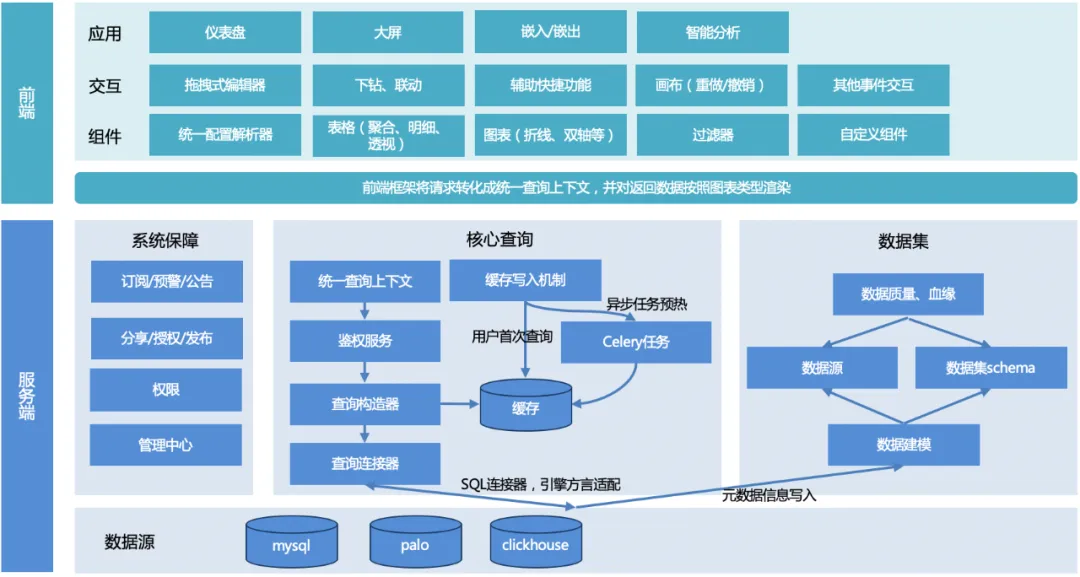
El proceso general: el usuario inicia una consulta, el servidor unifica el contexto de la consulta, construye el objeto de consulta, adapta el dialecto del motor subyacente, devuelve un formato de datos unificado y luego el marco de representación de front-end se adapta y representa de acuerdo con el tipo de gráfico. .
Servidor:
1. Contexto de consulta unificado : para facilitar la reutilización de funciones comunes al expandir otras funciones de gráficos más adelante, se diseña un contexto de consulta unificado.
2. Constructor de consultas : construye un objeto de consulta (puede ser múltiple, por ejemplo, para paginar una tabla, necesitas construir dos objetos de consulta, uno es un objeto de consulta de paginación y el otro es un objeto de consulta de conteo) de acuerdo con la solicitud. parámetros pasados desde el front-end.
3. Conector de consulta :
a. Actualmente solo existe un conector SQL, que se utiliza para satisfacer el motor de consulta SQL (mysql, palo, clickhouse, etc.). Diferentes motores, la sintaxis o algunas funciones pueden ser diferentes y deben adaptarse a través de diferentes motores. configuraciones de reglas;
b. Se pueden ampliar otros conectores para satisfacer consultas que no sean SQL en el futuro.
4. Escritura en caché : para garantizar el rendimiento de la consulta, existen dos métodos de escritura: escribir cuando el usuario accede por primera vez o precalentar el caché mediante tareas programadas de apio.
5. Módulo de conjunto de datos : proporcione soporte de datos, establezca vínculos con fuentes de datos subyacentes y garantice la calidad de los datos.
6. Módulo de garantía del sistema : la suscripción, la alerta temprana y el anuncio implementan capacidades de alerta temprana de datos. El intercambio, la publicación y la autorización mejoran la eficiencia de la circulación de datos. El centro de administración y los permisos brindan soporte de permisos y administración subyacente para los datos.
Interfaz:
1. Biblioteca de componentes : proporciona análisis de configuración, diferentes componentes de representación de gráficos, componentes de filtro y capacidades de componentes personalizados.
2. Interacción : encapsula las capacidades de interacción de la página, incluido el editor de arrastrar y soltar, enlaces detallados, funciones auxiliares de acceso directo, capacidades de lienzo y otras interacciones de eventos.
3. Aplicación : Implemente diferentes aplicaciones visuales para diferentes usuarios y escenarios de uso, como paneles, pantallas grandes, etc.
2.2 Diseño detallado
2.2.1 Consulta principal
La BI de autoservicio integral, a través de ideas de modelado de conjuntos de datos públicos, realiza la idea de análisis de tres puntos de "tendencias, dimensiones y detalles", que enfrentará muchos desafíos, entre ellos:
-
Datos de múltiples fuentes, presentación de múltiples gráficos y análisis y cálculos de múltiples escenarios : hay más de un motor de fuente de datos subyacente en el sistema de BI. Para expandir de manera flexible las fuentes de datos, el estilo de presentación también requiere un soporte de gráficos enriquecido y, al menos, Al mismo tiempo, para cumplir con el análisis en diferentes escenarios, el cálculo debe admitir capacidades de análisis comunes, como valores promedio mensuales y diarios.
-
Consultar decenas de millones de datos en segundos : la idea de construir conjuntos de datos públicos facilita el análisis pero también introduce nuevos desafíos. La cantidad de decenas de millones de datos en un solo día plantea un enorme desafío para el rendimiento de las consultas.
En respuesta a los problemas anteriores, se han formulado las soluciones correspondientes:
-
Consulta unificada : unifique el contexto de la consulta, construya el objeto de consulta, adapte el dialecto del motor subyacente, devuelva un formato de datos unificado y el marco de representación front-end adapta la representación según el tipo de gráfico.
-
Optimización de consultas : Ⅰ> Almacenamiento en caché + avance automático, que cubre el 70% de las solicitudes del panel público; Ⅱ> Optimización de la construcción de consultas SQL y aprovechamiento completo de las capacidades de agregación del lado del motor; III> Solicitudes simultáneas de múltiples nombres de dominio y procesamiento de respuestas de múltiples rutinas .
Consulta unificada:
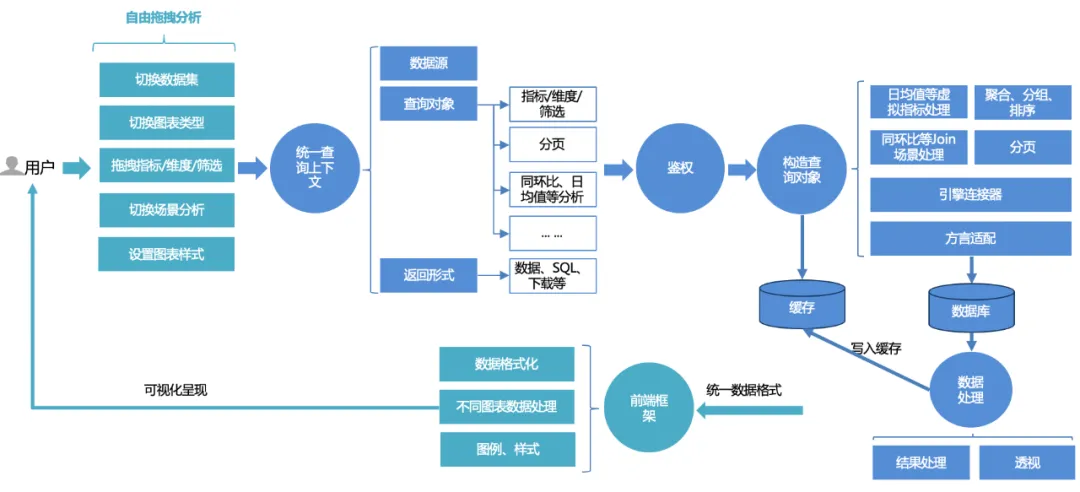
El proceso de consulta unificado para los usuarios de la plataforma es el siguiente:
1. Los usuarios pueden arrastrar y soltar análisis libremente en la página : cambiar conjuntos de datos, cambiar entre diferentes tipos de gráficos, arrastrar y soltar indicadores, dimensiones, filtros y consultas; o si desean utilizar algunas capacidades avanzadas de análisis de escenas, pueden cambiar Configuraciones con un solo clic.
2. La solicitud de front-end se procesará en un contexto de consulta unificado : que incluye fuente de datos, objeto de consulta y formulario de devolución. El objeto de consulta encapsula indicadores básicos, dimensiones, información de filtrado y configuraciones de análisis avanzado, como año tras año. comparación y valor medio diario.
3. Servicio de autenticación unificada : basado en el núcleo de autenticación dual del panel y el conjunto de datos, también admite un control de permisos más detallado de filas y permisos de filas.
4. Construya el objeto de consulta : primero complete la construcción SQL básica (agregación, agrupación, filtrado) basada en indicadores, dimensiones y triples de filtrado, luego ensamble la lógica de clasificación de acuerdo con las reglas de clasificación y agregue algunas opciones de análisis avanzadas (como mes a mes, promedio diario, etc.) La lógica de ensamblaje adicional y luego el procesamiento de paginación deben combinarse con la adaptación del dialecto. Al consultar datos, consulte diferentes bases de datos (como mysql, palo, clickhouse, etc.) de acuerdo con diferentes motores enlazadores.
5. Consultar y procesar datos : después de consultar los datos a través del vinculador, procese los datos (procesamiento de formato de fecha, perspectiva de gráficos de líneas, etc.).
6. Caché : los datos procesados se escriben en el caché o, si el caché se accede directamente durante la consulta, los datos almacenados en caché se leen y devuelven directamente.
7. Representación unificada del marco de renderizado front-end : Devuelve un formato de datos unificado y el front-end completa la representación adaptativa de gráficos, estilos, etc.
Optimización de consultas: Ⅰ>Caché + resumen automático, que cubre el 70% de las solicitudes de paneles públicos.
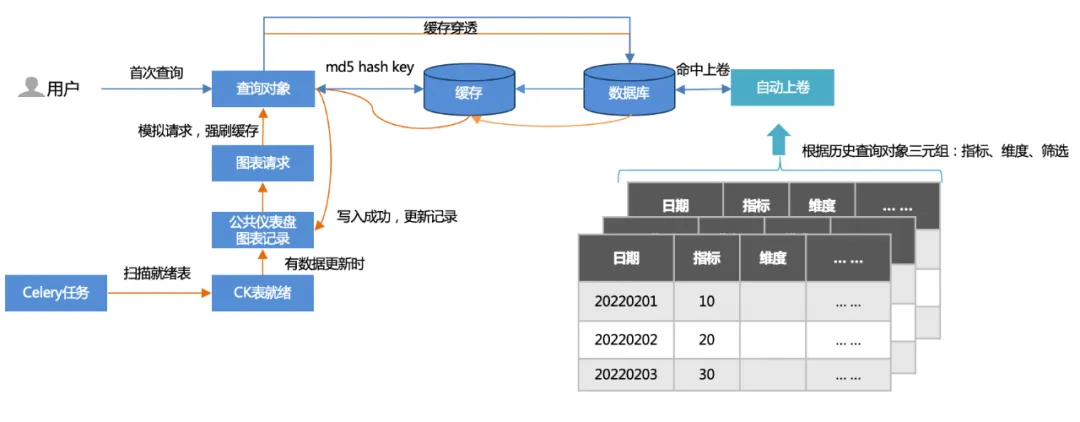
1. Dos métodos de almacenamiento en caché :
Primera consulta: el usuario primero accede (penetración de caché), consulta la base de datos y luego escribe en el caché.
Calentamiento de tareas sin conexión: escanee registros de gráficos del panel público y simule solicitudes de gráficos (más de 500 por actualización) para forzar el vaciado de caché.
2. Bobinado automático :
Sobre la base de los triples (indicadores, dimensiones, filtrado) de las consultas históricas, se establece una tabla acumulativa y la consulta llega a la tabla acumulativa, lo que reduce considerablemente la cantidad de datos consultados y acelera el rendimiento.
Optimización de consultas: Ⅱ> Optimice la construcción de consultas SQL y aproveche al máximo las capacidades de agregación de los motores de arquitectura MPP (como clickhouse/palo, etc.).

En el escenario de análisis de conjuntos de datos públicos, después de consultar los datos, es casi imposible agregarlos y calcularlos en la memoria (por ejemplo, (a + b) / c debe agregarse y calcularse en función de los datos detallados a, b , c), y debe utilizar la capacidad de consulta MPP del lado del motor de la arquitectura para refinar el cálculo de agregación en el lado del motor para su ejecución, al igual que la agregación mes a mes, el volumen de datos involucra decenas de miles de millones, los datos El volumen después del cálculo de agregación del lado del motor se reduce docenas de veces y el rendimiento también mejora varias veces.
Optimización de consultas: III> Solicitudes simultáneas de varios nombres de dominio, procesamiento de respuestas de múltiples rutinas.
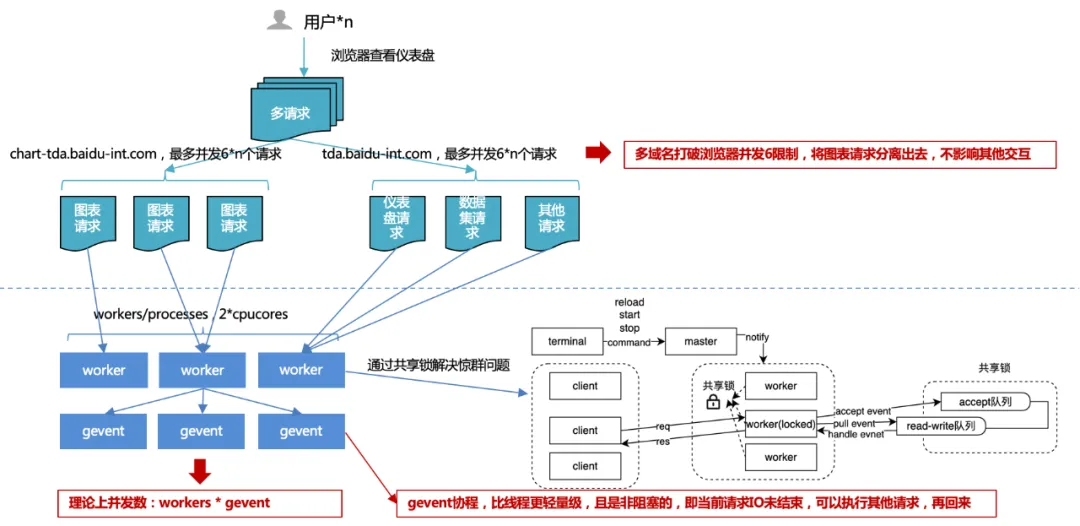
1. Límite de simultaneidad del navegador de 6 : al utilizar varios nombres de dominio, las solicitudes de gráficos se descargan de otras solicitudes para garantizar una interacción fluida con la plataforma y una mayor simultaneidad de solicitudes de gráficos, mejorando así el rendimiento general.
Considere los recursos de los puertos del sistema operativo: el número total de puertos de PC es 65536, por lo que un enlace TCP (http también es tcp) ocupa un puerto. El sistema operativo generalmente abre la mitad del total de puertos a solicitudes externas para evitar que la cantidad de puertos se agote rápidamente.
La concurrencia excesiva conduce a cambios frecuentes y problemas de rendimiento: un subproceso maneja una solicitud http, por lo que si la cantidad de concurrencias es enorme, se producirán cambios frecuentes de subprocesos. Y el cambio de contexto de subprocesos a veces no es un recurso liviano. Esto genera más pérdidas que ganancias, por lo que se generará un grupo de conexiones en el controlador de solicitudes para reutilizar conexiones anteriores. Por lo tanto, podemos pensar que el número máximo de grupos de conexiones bajo el mismo nombre de dominio es de 4 a 8. Si se utilizan todos los grupos de conexiones, las tareas de solicitud posteriores se bloquearán y las tareas posteriores se ejecutarán cuando haya enlaces libres.
Evite que una gran cantidad de solicitudes simultáneas del mismo cliente excedan el umbral de concurrencia del servidor: el servidor generalmente establece un umbral de concurrencia para el mismo origen del cliente para evitar ataques maliciosos. Si el navegador no establece límites de concurrencia para el mismo nombre de dominio, puede causar que se exceda el umbral de concurrencia del servidor.
Mecanismo de conciencia del cliente: para evitar que dos aplicaciones se apoderen de recursos, la parte más fuerte obtendrá recursos sin restricciones, lo que provocará que la parte más débil sea bloqueada permanentemente.
2. Concurrencia multiproceso + multirutina del lado del servidor :
Al desarrollar con múltiples procesos, puede encontrar el "problema de la manada atronadora", donde múltiples procesos esperan el mismo evento. Cuando ocurre un evento, todos los procesos serán despertados por el kernel, pero después de despertarse, solo un proceso obtiene el evento y lo procesa. Los otros procesos continúan entrando en el estado de espera después de descubrir que la adquisición de tiempo falló. Cuantos más procesos Escuche el mismo evento, cuantos más procesos haya, más grave será la disputa por la CPU, lo que generará graves costos de contexto.
Por lo tanto, en respuesta a esta situación, el servicio uwsgi diseñó e implementó un mecanismo de bloqueo compartido para garantizar que solo un proceso esté monitoreando eventos al mismo tiempo, resolviendo así el problema de la manada atronadora.
Pero aun así, la cantidad de procesos no se puede ampliar sin límite. Generalmente se recomienda igualar 2 veces la cantidad de núcleos de CPU.
Entonces, dado que la cantidad de procesos es limitada, ¿cómo mejorar el rendimiento? En circunstancias normales, IO está bloqueado Cuando está leyendo una base de datos o un archivo, el proceso o subproceso actual esperará hasta que la operación IO devuelva el resultado antes de continuar ejecutando el código posterior. Si aumentamos el rendimiento a través de subprocesos múltiples y encontramos un bloqueo de IO, el subproceso se atascará y el subproceso no procesará otras solicitudes concurrentes. La IO asincrónica se implementa a través de corrutinas, es decir, para cada subproceso, cuando es IO. En lugar de esperar el resultado de IO, primero procesamos la nueva solicitud, esperamos hasta que se complete el IO y luego volvemos al código que necesita esperar el IO. De esta manera, aprovechamos al máximo cada hilo del programa y siempre tenemos algo que hacer. Este método mejora el rendimiento general y reduce el tiempo total, sin afectar el tiempo individual.
2.2.2 Garantía del sistema
Suscríbete a las alertas:
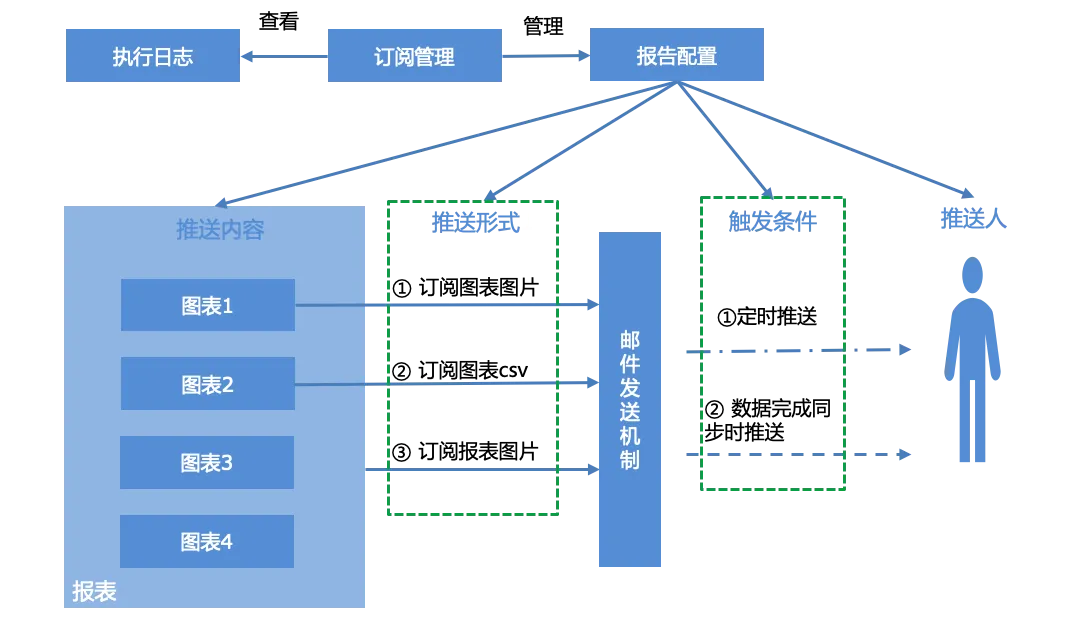
Los usuarios pueden configurar informes para informes, administrar informes de suscripción generados de acuerdo con la interfaz de administración de suscripciones y ver el registro de ejecución del sistema, es decir, el estado de envío de informes.
La configuración del informe incluye principalmente cuatro partes: contenido push, formulario push, condiciones de activación y pusher:
Contenido push : gráfico único, informe completo
Forma de empuje : tres formas de empuje
Captura de pantalla del gráfico
Archivo adjunto de correo electrónico con datos csv del gráfico
Reportar captura de pantalla
Condiciones desencadenantes :
Envío programado, envío programado basado en la expresión cron.
Se envía cuando se completa la sincronización de datos. Cuando los conjuntos de datos asociados con todos los gráficos del informe completan la sincronización de datos, se activan las condiciones de inserción y se completan las notificaciones por correo electrónico.
Pusher : Cuenta de correo electrónico, separe con "," si hay varias.
Permisos:

Gestión y control jerárquico de permisos de datos: basado en el núcleo de autenticación de doble capa del conjunto de datos y el panel, admite permisos de filas y columnas para solicitar autorización de acuerdo con la granularidad de las reglas y controla de manera flexible los permisos de los usuarios.
Colaboración eficiente: abra el servicio de autoridad unificado MPS (sistema unificado de gestión de autoridades), realice la aprobación de autoridades, la recuperación de vencimientos, el congelamiento de renuncias y otras capacidades, abra una oficina sin problemas y acelere la circulación de alta velocidad de la aprobación de autoridades.
03 Resumen y planificación
3.1 Resumen
Después de iteraciones continuas, TDA básicamente desarrolló capacidades de análisis de autoservicio integral y logró los siguientes indicadores:
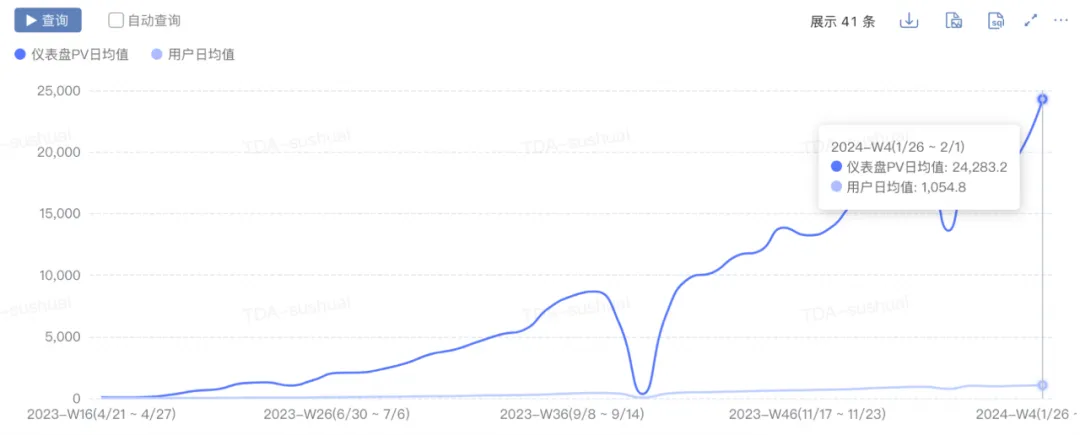
- Crecimiento de escala: pv aumentó de 0 a 2w+, uv aumentó de 0 a 1000+ y los nuevos gráficos diarios aumentaron de 0 a 300+.
-
Mejora del rendimiento: el tiempo necesario para alcanzar el percentil 90 de la primera pantalla del tablero se redujo de 10+ a 5s.
-
Mejora de la eficiencia empresarial: promueva una tasa de autoservicio superior al 80% del negocio principal, aumente la eficiencia del análisis de fluctuaciones 20 veces y el análisis de atribución de un extremo a otro de las fluctuaciones de un solo indicador de 2 horas a 5 minutos.
3.2 Planificación
Con la penetración de la tecnología nativa de IA en varios campos, TDA también combinará la tecnología de IA en el futuro para mejorar la experiencia de análisis inteligente de la plataforma. Los puntos principales son los siguientes:
-
Acceso a datos de autoservicio: se liberalizará el acceso a los datos, se ampliarán los tipos de fuentes de datos, etc.
-
AI+BI: las capacidades de BI, como el análisis de atribución, el análisis integrado y los informes de análisis, se combinan con IA de modelos grandes para mejorar los productos de análisis inteligente.
-
Cabina de gestión (Explorar): Panel de objetivos de OKR.
------FIN------
Lectura recomendada
Un breve análisis de cómo acelerar los servicios comerciales en tiempo real
Evolución del sistema de inicio de sesión, diseño e implementación de inicio de sesión convenientes
Este artículo le brindará una comprensión completa de la biblioteca básica de Go Language IO.
Conciliación del sistema del Baidu Trading Center
Revelando el secreto del motor informático de fusión del almacén de datos de Baidu
La primera actualización importante de JetBrains 2024 (2024.1) es de código abierto. Incluso Microsoft planea pagar por ella. ¿Por qué todavía se le critica por ser de código abierto? [Recuperado] El backend de Tencent Cloud falló: una gran cantidad de errores de servicio y no hay datos después de iniciar sesión en la consola. Alemania también necesita ser "controlable de forma independiente". El gobierno estatal migró 30,000 PC de Windows a Linux deepin-IDE y finalmente logró ¡arranque! Se lanza Visual Studio Code 1.88. Buen chico, Tencent realmente ha convertido a Switch en una "máquina de aprendizaje pensante". El escritorio remoto de RustDesk inicia y reconstruye el cliente web. La base de datos de terminal de código abierto de WeChat basada en SQLite, WCDB, ha recibido una actualización importante.