
En la mente del autor, la cola de mensajes , el caché y la subbase de datos y la subtabla son los tres espadachines de las soluciones de alta concurrencia.
En mi carrera, he utilizado colas de mensajes conocidas como ActiveMQ, RabbitMQ, Kafka y RocketMQ.
En este artículo, el autor combina su propia experiencia real para compartir con usted siete escenarios de aplicación clásicos de colas de mensajes.
1 asíncrono y desacoplado
El autor alguna vez fue responsable del servicio de atención al usuario de una empresa de comercio electrónico, que proporcionaba funciones básicas como registro, consulta y modificación de usuarios. Una vez que el usuario se registra correctamente, se le debe enviar un mensaje de texto.
En la imagen, agregar nuevos usuarios y enviar mensajes de texto están incluidos en el servicio del centro de usuarios. Las desventajas de este método son muy obvias:
-
El canal SMS no es lo suficientemente estable y tarda unos 5 segundos en enviar un mensaje de texto. Esto hace que la interfaz de registro del usuario consuma mucho tiempo y afecta la experiencia del usuario front-end;
-
Si la interfaz del canal SMS cambia, se debe modificar el código del centro de usuarios. Pero el Centro de usuarios es el sistema central. Debe tener cuidado cada vez que se conecta a Internet. Esto resulta muy incómodo, ya que las funciones no centrales afectan al sistema central.
Para resolver este problema, el autor utilizó la cola de mensajes para reconstruirlo.

-
asincrónico
Una vez que el servicio del centro de usuarios guarda con éxito la información del usuario, envía un mensaje a la cola de mensajes e inmediatamente devuelve el resultado al front-end. Esto puede evitar el problema de tomar mucho tiempo y afectar la experiencia del usuario.
-
desacoplamiento
Cuando el servicio de tareas recibe el mensaje, llama al servicio de SMS para enviar el SMS, lo que separa los servicios principales de las funciones no principales y reduce significativamente el acoplamiento entre sistemas.
2 Eliminación de picos
En escenarios de alta concurrencia, los picos repentinos de solicitudes pueden hacer que el sistema se vuelva inestable fácilmente. Por ejemplo, una gran cantidad de solicitudes para acceder a la base de datos ejercerá una gran presión sobre la base de datos, o los recursos del sistema, CPU e IO, pueden sufrir cuellos de botella. .
El autor una vez sirvió al equipo de pedidos de automóviles privados de Shenzhou. Durante el ciclo de vida del pasajero del pedido, la operación de modificación del pedido primero modifica el caché del pedido y luego envía el mensaje a MetaQ. El servicio de colocación del pedido consume el mensaje y determina si el pedido. La información es normal (por ejemplo, si está fuera de servicio), si los datos del pedido son correctos, se almacenarán en la base de datos.

Cuando se enfrenta a un pico de solicitudes, dado que la concurrencia de los consumidores está dentro de un rango umbral y la velocidad de consumo es relativamente uniforme, no tendrá un gran impacto en la base de datos. Al mismo tiempo, los productores del sistema de pedidos que realmente enfrentan el problema. El front-end también se volverá más estable.
bus de 3 mensajes
El llamado bus es como el bus de datos de la placa base, con la capacidad de transmitir e interactuar datos. Las partes no se comunican directamente y utilizan el bus como interfaz de comunicación estándar .
Una vez, el autor trabajó con el equipo de pedidos de una empresa de lotería. Durante el ciclo de vida de un pedido de lotería, pasó por muchos pasos, como la creación, la división de subórdenes, la emisión de boletos y el cálculo de premios. Cada enlace requiere un procesamiento de servicio diferente, cada sistema tiene su propia tabla independiente y las funciones comerciales son relativamente independientes. Si cada aplicación tuviera que modificar la información en la tabla maestra de pedidos, sería bastante confuso.
Por lo tanto, el arquitecto de la empresa diseñó el servicio de <font color="red"> Centro de despacho </font>. El Centro de despacho mantiene la información de los pedidos, pero no se comunica con los subservicios, sino a través de colas de mensajes y sistemas de emisión de boletos. como los servicios de cálculo de premios transmiten e intercambian información.
El diseño arquitectónico del bus de mensajes puede desacoplar más el sistema y permitir que cada sistema realice sus propias funciones.
4 tareas retrasadas
Cuando un usuario realiza un pedido en la aplicación Meituan y no paga inmediatamente, se mostrará una cuenta regresiva al ingresar los detalles del pedido. Si se excede el tiempo de pago, el pedido se cancelará automáticamente.
Una forma muy elegante es utilizar mensajes retrasados de la cola de mensajes .
Una vez que el servicio de pedidos genera el pedido, envía un mensaje retrasado a la cola de mensajes. La cola de mensajes entrega el mensaje al consumidor cuando el mensaje llega al tiempo de vencimiento del pago. Una vez que el consumidor recibe el mensaje, determina si el estado del pedido es pago. Si no se paga, se ejecuta la lógica de cancelar el pedido.

El código para que el productor RocketMQ 4.X envíe mensajes retrasados es el siguiente:
Message msg = new Message();
msg.setTopic("TopicA");
msg.setTags("Tag");
msg.setBody("this is a delay message".getBytes());
//设置延迟level为5,对应延迟1分钟
msg.setDelayTimeLevel(5);
producer.send(msg);
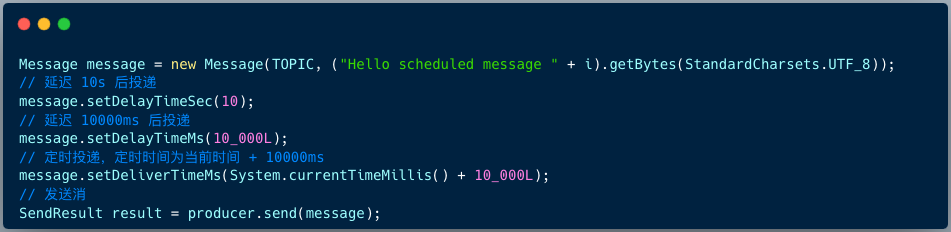
La versión RocketMQ 4.X admite 18 niveles de mensajes retrasados de forma predeterminada, lo que está determinado por el elemento de configuración messageDelayLevel en el lado del intermediario.

La versión RocketMQ 5.X admite retrasar mensajes en cualquier momento. El cliente proporciona 3 API para especificar el tiempo de retraso o el tiempo de sincronización al construir el mensaje.
5 Consumo de radio
Consumo de transmisión : cuando se utiliza el modo de consumo de transmisión, cada mensaje se envía a todos los consumidores en el clúster, lo que garantiza que cada consumidor consuma el mensaje al menos una vez.
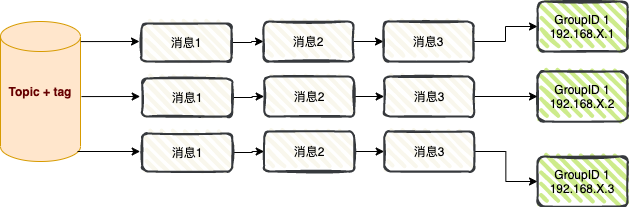
El consumo de transmisión se utiliza principalmente en dos escenarios: envío de mensajes y sincronización de caché .
01 Mensaje push
La siguiente figura muestra el mecanismo de empuje del lado del conductor de un automóvil privado. Después de que el usuario realiza un pedido, el sistema de pedidos genera un pedido de automóvil especial. El sistema de despacho enviará el pedido a un conductor según el algoritmo relevante, y el conductor. -end recibirá el mensaje push de envío.
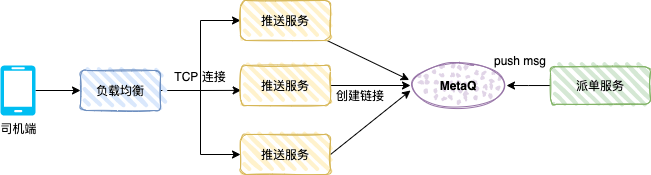
El servicio push es un servicio TCP (protocolo personalizado) y un servicio de consumidor, y el modo de mensaje es consumo de transmisión.
Después de que el controlador abre la aplicación del controlador, la aplicación creará una conexión larga a través del equilibrio de carga y el servicio push, y el servicio push guardará la referencia de la conexión TCP (como el número del controlador y la referencia del canal TCP).
El servicio de envío es el productor y envía los datos de envío a MetaQ. Cada servicio de envío consumirá el mensaje. El servicio de envío determina si el canal TCP del controlador existe en la memoria local. a través de la conexión TCP.
02 Sincronización de caché
En escenarios de alta concurrencia, muchas aplicaciones utilizan el caché local para mejorar el rendimiento del sistema.
El caché local puede ser HashMap, ConcurrentHashMap o el marco de almacenamiento en caché Guava Cache o Caffeine cache.

Como se muestra en la figura anterior, después de iniciar la aplicación A, como consumidor de RocketMQ, el modo de mensaje se configura para transmitir consumo. Para mejorar el rendimiento de la interfaz, cada nodo de la aplicación carga la tabla del diccionario en el caché local.
Cuando los datos de la tabla del diccionario cambian, se puede enviar un mensaje a RocketMQ a través del sistema empresarial, y cada nodo de la aplicación consumirá el mensaje y actualizará el caché local.
6 transacciones distribuidas
Tomando como ejemplo el escenario de transacciones de comercio electrónico, la operación central del pago de pedidos por parte del usuario también implicará cambios en múltiples subsistemas, como la entrega logística posterior, cambios de puntos y compensación del estado del carrito de compras.
![]()
1. Solución de transacciones XA tradicional: rendimiento insuficiente
Para garantizar la coherencia de los resultados de ejecución de las cuatro ramas anteriores, una solución típica es implementar un sistema de transacciones distribuidas basado en el protocolo XA. Encapsule las cuatro ramas de llamadas en una transacción grande que contenga cuatro ramas de transacciones independientes. La solución basada en transacciones distribuidas XA puede cumplir con la exactitud de los resultados del procesamiento comercial, pero la mayor desventaja es que en un entorno de múltiples sucursales, el rango de bloqueo de recursos es grande y la concurrencia es baja. El rendimiento del sistema empeorará cada vez más.
2. Basado en un esquema de mensajes ordinario: dificultad para garantizar la coherencia
![]()
En esta solución, la rama descendente del mensaje y la rama principal del cambio del sistema de pedidos son propensas a tener inconsistencias, por ejemplo:
- El mensaje se envió correctamente, pero la orden no se ejecutó correctamente y es necesario revertir toda la transacción.
- La orden se ejecutó con éxito, pero el mensaje no se envió correctamente y se requirió una compensación adicional para descubrir la inconsistencia.
- Se desconoce el tiempo de espera para el envío de mensajes y es imposible determinar si es necesario revertir el pedido o enviar los cambios.
3. Basado en mensajes de transacciones distribuidas RocketMQ: admite coherencia eventual
En la solución de mensajes ordinarios mencionada anteriormente, la razón por la que no se puede garantizar la coherencia de los mensajes ordinarios y las transacciones de pedidos es esencialmente porque los mensajes ordinarios no pueden tener la capacidad de confirmar, revertir y coordinar unificadamente como las transacciones de bases de datos independientes.
La función de mensajes de transacciones distribuidas implementada en base a RocketMQ admite capacidades de envío de dos etapas basadas en mensajes ordinarios. Vincule el envío en dos fases a transacciones locales para lograr coherencia en los resultados del envío global.
Los mensajes de transacciones de RocketMQ admiten garantizar la coherencia final de la producción de mensajes y las transacciones locales en escenarios distribuidos . El proceso de interacción se muestra en la siguiente figura:
![]()
1. El productor envía el mensaje al Broker.
2. Después de que el Broker persiste exitosamente el mensaje, devuelve un Acuse de recibo al productor para confirmar que el mensaje se envió exitosamente. En este momento, el mensaje se marca como " temporalmente no entregable ". El mensaje en este estado es semi- mensaje de transacción .
3. El productor comienza a ejecutar la lógica de transacción local .
4. El productor envía un resultado de confirmación secundario (Commit o Rollback) al servidor en función del resultado de la ejecución de la transacción local. Después de que el Broker recibe el resultado de la confirmación, la lógica de procesamiento es la siguiente:
- El resultado de la confirmación secundaria es Compromiso: el corredor marca el mensaje de semitransacción como entregable y lo entrega al consumidor.
- El resultado de la confirmación secundaria es la reversión: el corredor revertirá la transacción y no entregará el mensaje de semitransacción al consumidor.
5. En circunstancias especiales en las que se desconecta la red o se reinicia la aplicación del productor, si el corredor no recibe el resultado de la confirmación secundaria enviado por el remitente, o el resultado de la confirmación secundaria recibido por el corredor está en estado Desconocido, después de un tiempo fijo Durante un período de tiempo, el servicio El terminal iniciará una revisión de mensajes .
- Una vez que el productor recibe la revisión del mensaje, debe verificar el resultado final de la ejecución de la transacción local correspondiente al mensaje.
- El productor envía nuevamente una confirmación secundaria basada en el estado final de la transacción local que se verifica , y el servidor aún procesa el mensaje de media transacción de acuerdo con el paso 4.
7 Centro de transferencia de datos
En los últimos 10 años, han surgido sistemas especiales como almacenamiento KV (HBase), búsqueda (ElasticSearch), procesamiento de transmisión (Storm, Spark, Samza), bases de datos de series temporales (OpenTSDB) y otros sistemas especiales. Estos sistemas se crearon con un único objetivo en mente y su simplicidad hace que sea más fácil y rentable construir sistemas distribuidos en hardware básico.
A menudo, es necesario inyectar el mismo conjunto de datos en varios sistemas especializados.
Por ejemplo, cuando los registros de aplicaciones se utilizan para el análisis de registros fuera de línea, la búsqueda de registros individuales también es indispensable. Obviamente, no es práctico crear flujos de trabajo independientes para recopilar cada tipo de datos y luego importarlos a sus propios sistemas dedicados. Sirve como centro de transferencia de datos y los mismos datos se pueden importar a diferentes sistemas dedicados.
La sincronización de registros consta principalmente de tres partes clave: cliente de recopilación de registros, cola de mensajes de Kafka y aplicación de procesamiento de registros de fondo.
- El cliente de recopilación de registros es responsable de recopilar datos de registro de varios servicios de aplicaciones de usuario y envía los registros "en lotes" y "asincrónicamente" al cliente Kafka en forma de mensajes. El cliente Kafka envía y comprime mensajes en lotes, lo que tiene muy poco impacto en el rendimiento de los servicios de la aplicación.
- Kafka almacena registros en archivos de mensajes, lo que proporciona persistencia.
- Las aplicaciones de procesamiento de registros, como Logstash, se suscriben y consumen mensajes de registro en Kafka y, finalmente, el servicio de búsqueda de archivos recupera los registros, o Kafka pasa los mensajes a otras aplicaciones de big data como Hadoop para su almacenamiento y análisis sistemáticos.

Si mi artículo te resulta útil, dale me gusta, léelo y reenvíalo . Tu apoyo me animará a producir artículos de mayor calidad. ¡Muchas gracias!
