
Autor | Cheng Wei, ingeniero de I + D de big data de MetaAPP
ByConity es el almacén de datos nativo de la nube de código abierto de ByteDance. Satisface las necesidades de los usuarios del almacén de datos en cuanto a expansión y contracción elástica de recursos, separación de lectura y escritura, aislamiento de recursos, sólida consistencia de datos, etc., al mismo tiempo que proporciona un excelente rendimiento de consultas y escritura.
MetaApp es un desarrollador y operador de juegos líder en China, que se centra en la distribución eficiente de información móvil y está comprometido con la construcción de un mundo virtual para todas las edades. En 2023, MetaApp tiene más de 200 millones de usuarios registrados, ha colaborado en 200.000 juegos y tiene un volumen de distribución acumulado de más de mil millones.
MetaApp prestó atención a ByConity en los primeros días del código abierto y fue uno de los primeros usuarios en probarlo y lanzarlo en el entorno de producción. Con la idea de comprender las capacidades de los proyectos de almacenamiento de datos de código abierto, el equipo de I+D de big data de MetaApp realizó una prueba preliminar en ByConity. Su arquitectura de separación de almacenamiento-cómputo y su excelente rendimiento, especialmente en escenarios de análisis de registros, soporte para consultas complejas en datos a gran escala, atrajeron a MetaApp para realizar pruebas en profundidad de ByConity y, finalmente, reemplazó por completo a ClickHouse en el entorno de producción, reduciendo los costos de recursos. en más del 50%.
Este artículo presentará principalmente las funciones de la plataforma de análisis de datos MetaApp, los problemas y soluciones encontrados en escenarios comerciales y la ayuda para introducir ByConity en su negocio.
Arquitectura y funciones de la plataforma de análisis de datos MetaApp OLAP
Con el crecimiento del negocio y la introducción de operaciones refinadas, los productos han planteado mayores requisitos para el departamento de datos, incluida la necesidad de consultar y analizar datos en tiempo real y ajustar rápidamente las estrategias operativas para realizar experimentos AB en un pequeño grupo de personas; verificar la efectividad de nuevas funciones. Reduce el tiempo y la dificultad de la consulta de datos, permitiendo a los no profesionales analizar y explorar datos de forma independiente. Para satisfacer las necesidades comerciales, MateApp ha implementado una plataforma de análisis de datos OLAP que integra análisis de eventos, análisis de conversión, retención personalizada, agrupación de usuarios, análisis de flujo de comportamiento y otras funciones .
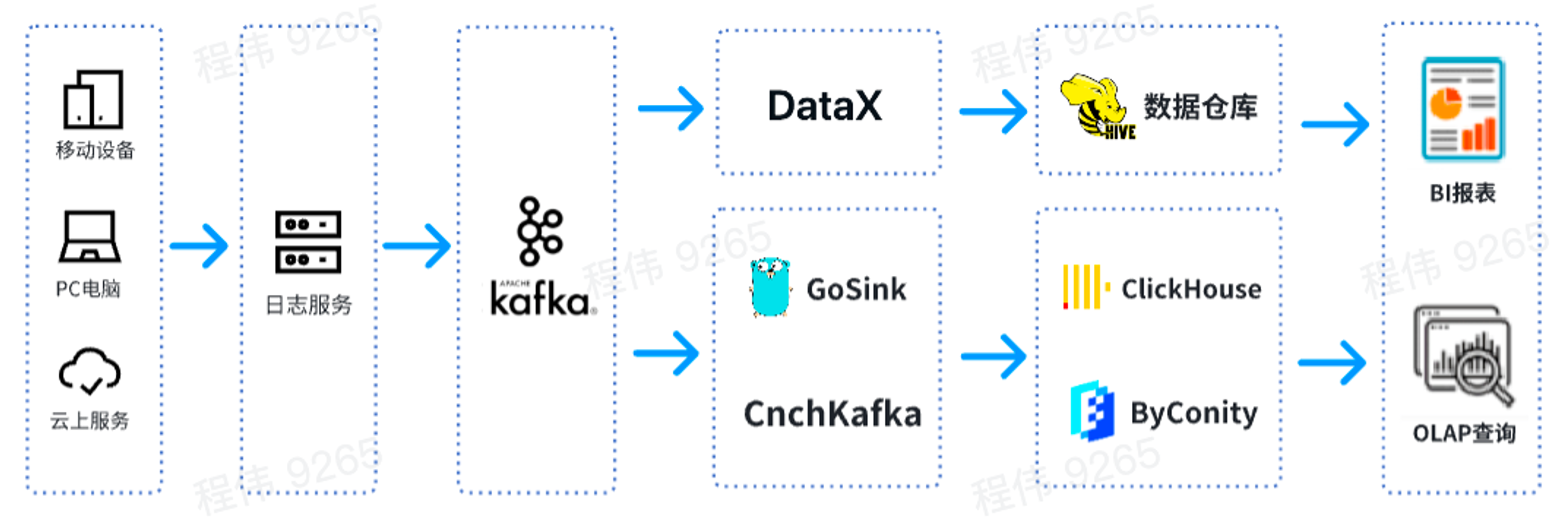
Esta es una arquitectura OLAP típica, dividida en dos partes, una fuera de línea y la otra en tiempo real.
En el escenario fuera de línea , utilizamos DataX para integrar los datos de Kafka en el almacén de datos de Hive y luego generar informes de BI. Los informes de BI utilizan el componente Superconjunto para mostrar resultados;
En un escenario en tiempo real , una línea usa GoSink para la integración de datos e integra los datos de GoSink en ClickHouse, y la otra línea usa CnchKafka para integrar los datos en ByConity. Finalmente los datos se obtienen a través de la plataforma de consulta OLAP para su consulta.
Comparación de funciones entre ByConity y ClickHouse
ByConity es un almacén de datos nativo de la nube de código abierto desarrollado en base al núcleo de ClickHouse y adopta una arquitectura de separación de almacenamiento y computación. Ambos tienen las siguientes características:
- La velocidad de escritura es muy rápida, adecuada para escribir grandes cantidades de datos y la cantidad de datos escritos puede alcanzar entre 50 MB y 200 MB/s.
- La velocidad de consulta es muy rápida. Con datos masivos, la velocidad de consulta puede alcanzar 2-30 GB/s.
- Alto índice de compresión de datos, bajo costo de almacenamiento, el índice de compresión puede alcanzar 0,2 ~ 0,3
ByConity tiene las ventajas de ClickHouse, mantiene una buena compatibilidad con ClickHouse y se ha mejorado en términos de separación de lectura y escritura, expansión y contracción elástica y una sólida coherencia de datos . Ambos son aplicables a los siguientes escenarios OLAP:
- Los conjuntos de datos pueden ser grandes: miles de millones o billones de filas.
- La tabla de datos contiene muchas columnas.
- Consultar solo columnas específicas
- Los resultados deben devolverse en milisegundos o segundos.
En intercambios anteriores, la comunidad de ByConity comparó los dos [desde una perspectiva de uso]
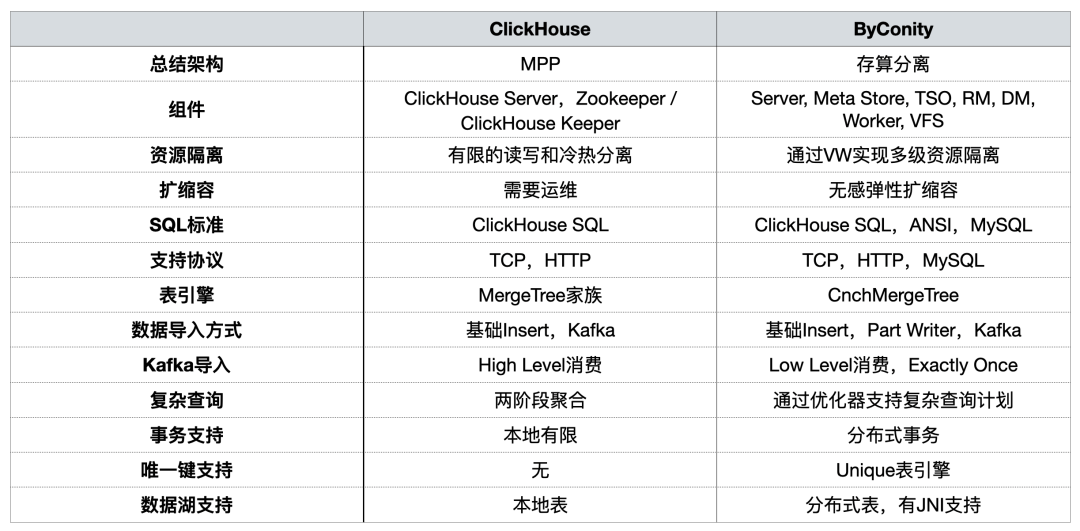
Durante la construcción de la plataforma OLAP, nos centramos principalmente en el aislamiento de recursos, la expansión y contracción de la capacidad , las consultas complejas y el soporte para transacciones distribuidas .
Problemas encontrados al usar ClickHouse
Problema 1: la lectura y escritura integradas pueden apoderarse fácilmente de los recursos y no pueden garantizar una lectura/escritura estable.
Durante los períodos comerciales pico, la escritura de datos ocupará una gran cantidad de recursos de IO y CPU, lo que afectará las consultas (los tiempos de consulta serán más largos). Lo mismo ocurre con las consultas de datos.
Problema 2: la expansión/reducción es problemática y lleva mucho tiempo
- Largo tiempo de expansión/reducción: dado que la máquina está en un IDC y pertenece a una nube privada, uno de los problemas es que el ciclo de adición de nodos es extremadamente largo. Desde el momento en que se emite la demanda de nodos hasta la adición real de nodos buenos, pasan de una a dos semanas, lo que afecta el negocio;
- No se puede ampliar y reducir rápidamente: los datos deben redistribuirse después de la ampliación; de lo contrario, la presión del nodo será muy alta.
Problema tres: la operación y el mantenimiento son engorrosos y no se puede garantizar el SLA durante los períodos de mayor actividad comercial.
- A menudo, debido a fallas en los nodos comerciales, las consultas de datos son lentas y la escritura de datos se retrasa (de unas pocas horas a unos días);
- Hay una grave escasez de recursos durante los períodos de mayor actividad comercial y es imposible ampliar los recursos en el corto plazo. La única forma es eliminar los datos de algunos servicios para brindar servicios de alta prioridad;
- Durante los períodos de escasez de negocios, una gran cantidad de recursos están inactivos y los costos están inflados. Aunque estamos en IDC, la compra de máquinas IDC también está sujeta a control de costos y la expansión del nodo no puede ser ilimitada. Además, existe un cierto consumo de costos durante el uso normal;
- No se puede interactuar con los recursos de la nube.
Mejoras tras la introducción de ByConity
En primer lugar, la separación de ByConity de los recursos informáticos de lectura y escritura puede garantizar que las tareas de lectura y escritura sean relativamente estables. Si las tareas de lectura no son suficientes, los recursos correspondientes se pueden ampliar para compensar la escasez, incluido el uso de recursos de la nube para la expansión.
En segundo lugar, aumentar y reducir la escala es relativamente simple y se puede realizar en un nivel de minutos. Dado que se utiliza almacenamiento distribuido HDFS/S3 y la informática y el almacenamiento están separados, no se requiere la redistribución de datos después de la expansión y se pueden usar directamente después de la expansión.
Además, la implementación, operación y mantenimiento nativos de la nube son relativamente simples.
- Los componentes de HDFS/S3 son relativamente maduros y estables, con expansión y contracción de capacidad, soluciones maduras de recuperación ante desastres y los problemas se pueden resolver rápidamente;
- Durante los períodos de mayor actividad comercial, el SLA se puede garantizar mediante una rápida expansión de los recursos;
- Durante los períodos de menor actividad comercial, los costos se pueden reducir reduciendo los recursos de almacenamiento/cómputo.
El uso y funcionamiento de ByConity
Uso del clúster ByConity
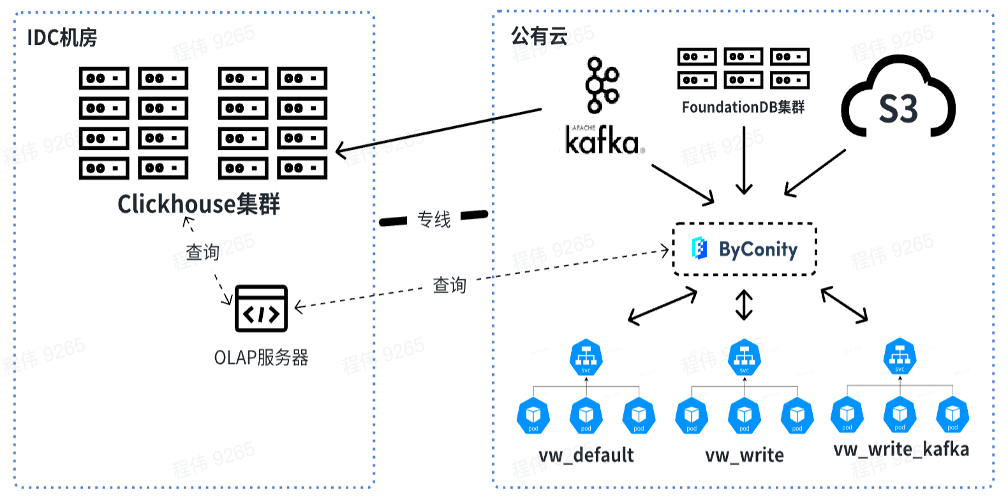
Actualmente, nuestra plataforma ha utilizado ByConity de manera estable en escenarios comerciales. A través de sucesivas migraciones, ByConity se ha hecho cargo por completo de los datos del cluster ClickHouse y ha comenzado a prestar servicios de forma estable. Construimos el clúster ByConity usando S3 plus K8 en la nube. También utilizamos una solución de expansión y contracción programada, que se puede expandir a las 10 a. m. y reducir a las 8 p. m. de lunes a viernes. día. . Según los cálculos, este método reduce los recursos entre un 40% y un 50% en comparación con el uso directo de suscripciones anuales y mensuales. Además, también estamos impulsando la combinación de nube privada + nube pública para lograr el propósito de reducir costos y mejorar la estabilidad del servicio.
La siguiente figura muestra nuestro uso actual, utilizando el servidor OLAP para realizar consultas conjuntas en el clúster ClickHouse y ByConity en la sala de computadoras IDC fuera de línea. A corto plazo, el clúster de ClickHouse seguirá utilizándose como transición para las empresas que dependen parcialmente de ClickHouse.
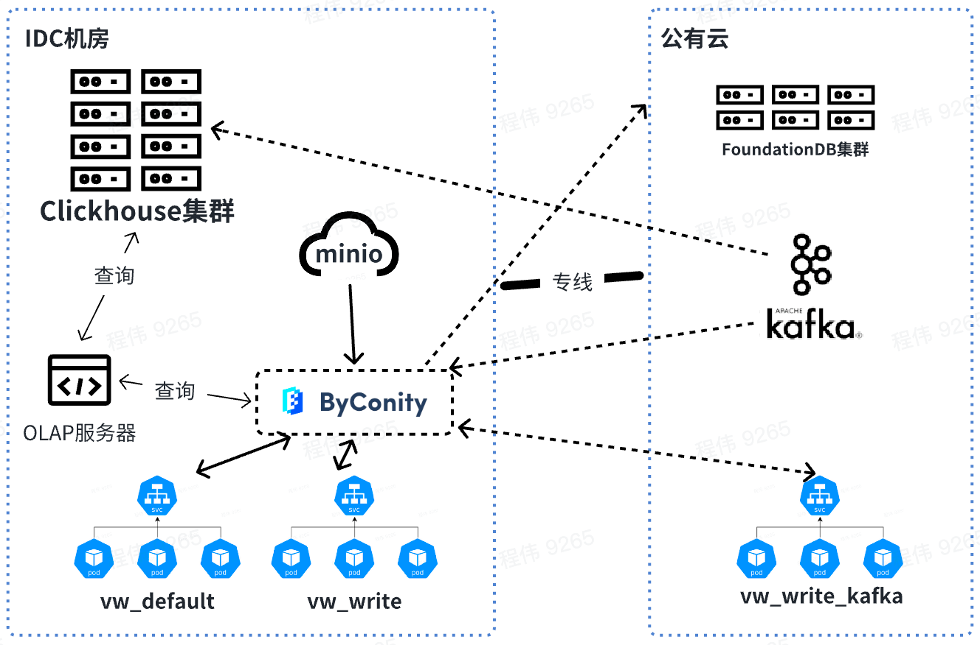
En el futuro, consultaremos y fusionaremos datos sin conexión, mientras que los recursos consumidos por Kafka se utilizarán en línea. Al expandir los recursos, puede expandir los recursos de vw_default y vw_write en línea y utilizar racionalmente los recursos de la nube pública para abordar el problema de los recursos insuficientes. Al mismo tiempo, la capacidad se reduce durante los picos comerciales bajos para reducir el consumo de la nube pública.
Comparación de consultas ByConity y ClickHouse en datos comerciales
Conjunto de datos de prueba y configuración de recursos.
- Número de elementos de datos: particionados por fecha, 4 mil millones de elementos en un solo día, 40 mil millones en total en 10 días
- Datos tabulares: 2800 columnas
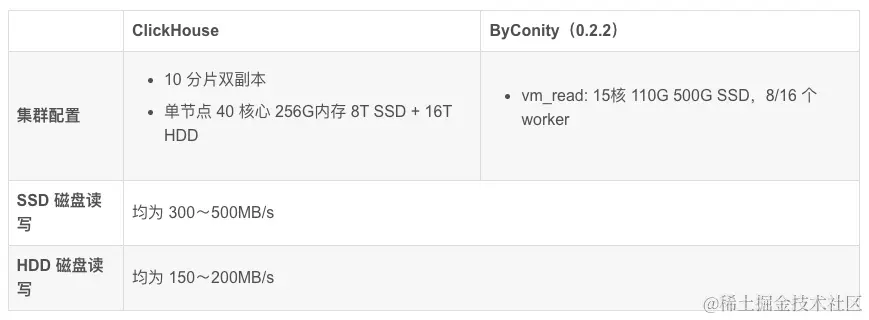
Como se puede ver en la tabla anterior:
Los recursos utilizados por la consulta del clúster ClickHouse son: 400 núcleos y 2560G de memoria
Los recursos utilizados por la consulta del clúster de trabajadores de ByConity 8 son: 120 núcleos y 880G de memoria
Los recursos utilizados por la consulta del clúster de trabajadores ByConity 16 son: 240 núcleos y 1760G de memoria
Resumen de los resultados de la consulta SQL empresarial
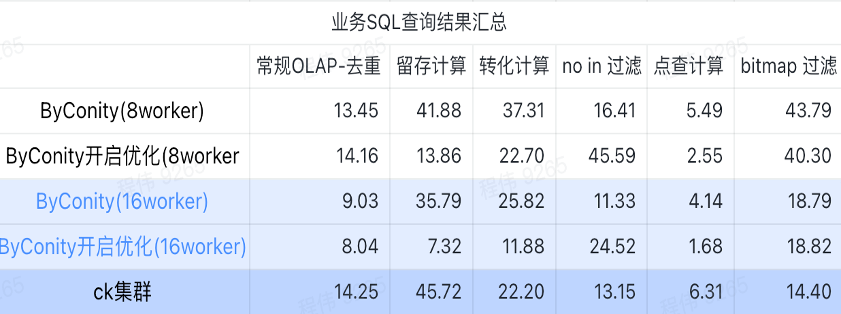
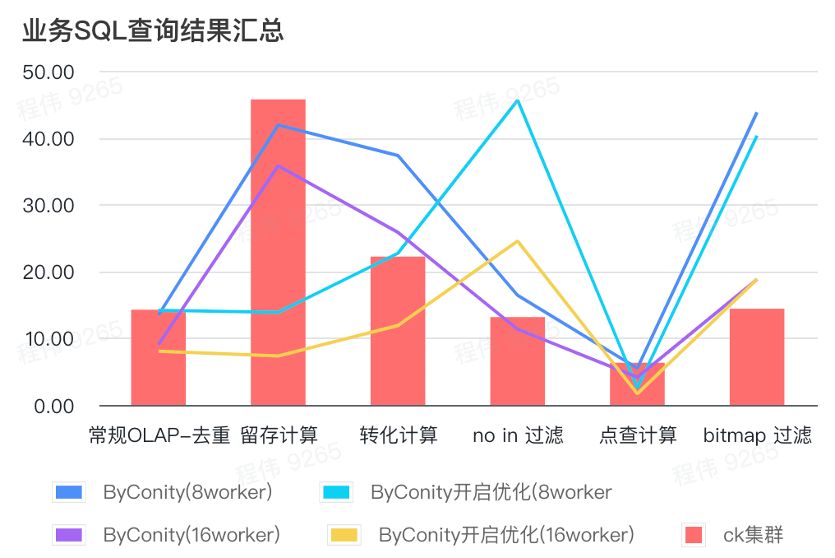
El resumen aquí utiliza el valor promedio, como puede ver:
- OLAP convencional: la deduplicación, retención, conversión y enumeración pueden lograr el mismo efecto de consulta que el clúster ClickHouse (400C, 2560G) con un costo de recursos relativamente pequeño (120C, 880G) y se puede duplicar expandiendo los recursos (240C, 1760G). ) para lograr el efecto de duplicar la velocidad de consulta. Si se requiere una mayor velocidad de consulta, se pueden ampliar más recursos;
- No estar en el filtrado puede requerir un costo de recursos moderado (240C, 1760G) para lograr efectos similares al clúster ClickHouse (400C, 2560G);
- El mapa de bits puede requerir mayores costos de recursos para lograr efectos similares a los de los clústeres de ClickHouse.
Consulta general/consulta de análisis de eventos
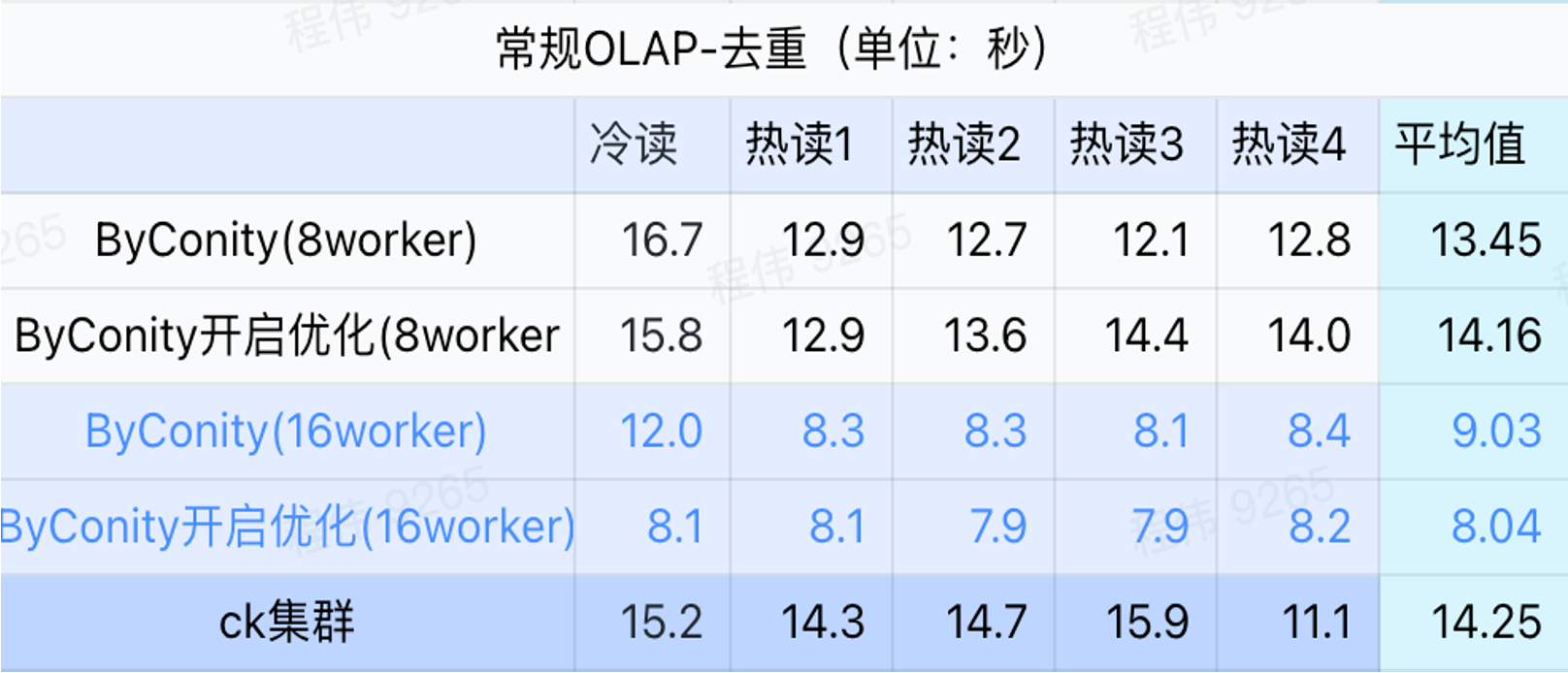
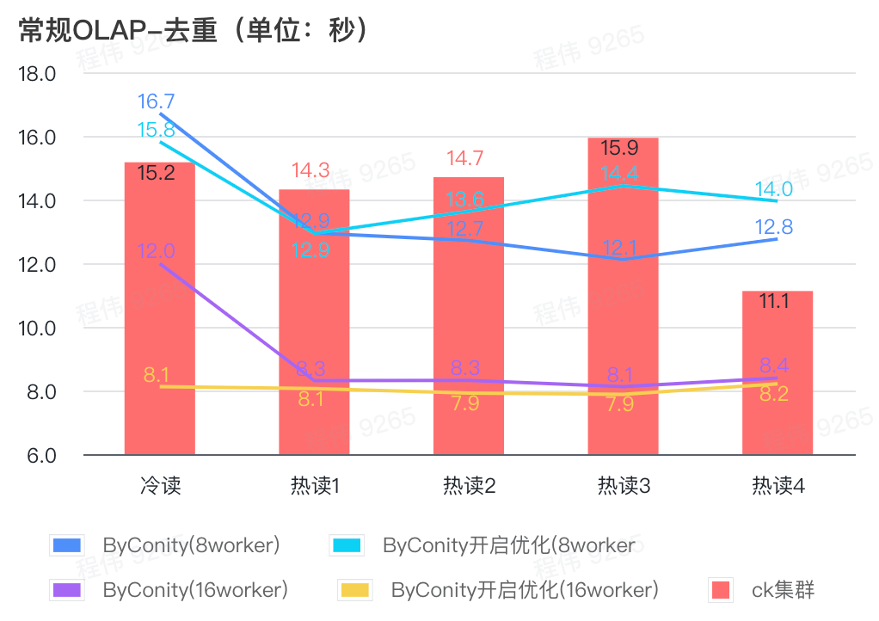
Como se puede ver en la figura anterior:
- En el escenario de consulta de deduplicación, no hay mucha diferencia entre activar la optimización ByConity y no activar la optimización;
- 8 trabajadores (120C 880G) básicamente logran un tiempo de consulta cercano al de ClickHouse;
- En escenarios de deduplicación, la velocidad de consulta se puede acelerar ampliando los recursos informáticos.
Cálculo de retención
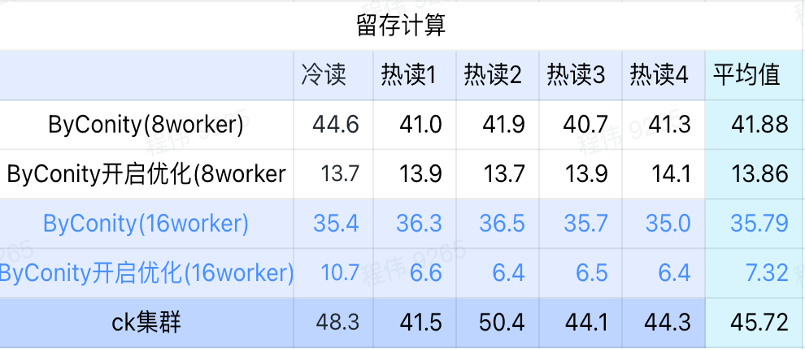
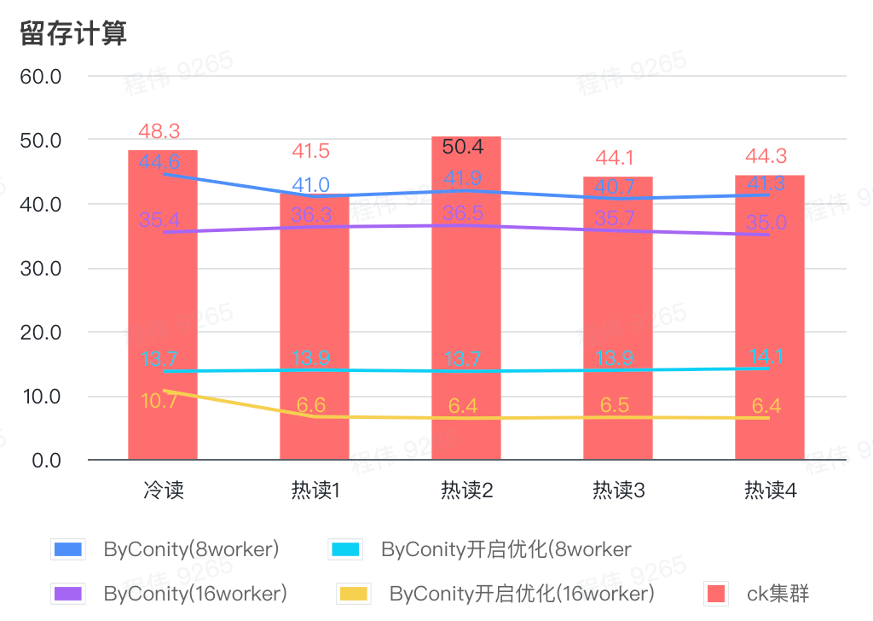
Como se puede ver en la figura anterior:
- En el escenario de computación retenida, el tiempo de consulta después de que ByConity activa la optimización es el 33% del tiempo de consulta sin activar la optimización;
- 8 trabajadores (120C 880G) El tiempo de consulta con la optimización activada es el 30% del tiempo de consulta;
- En el escenario informático retenido, la velocidad de consulta se puede acelerar al 16% del tiempo de consulta CK ampliando los recursos informáticos + optimización.
Cálculo de conversión
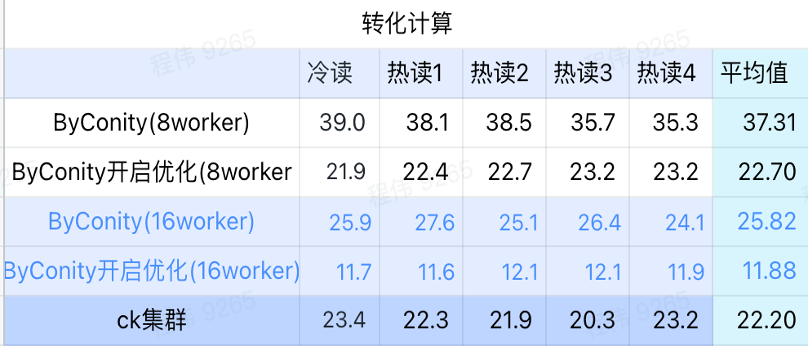
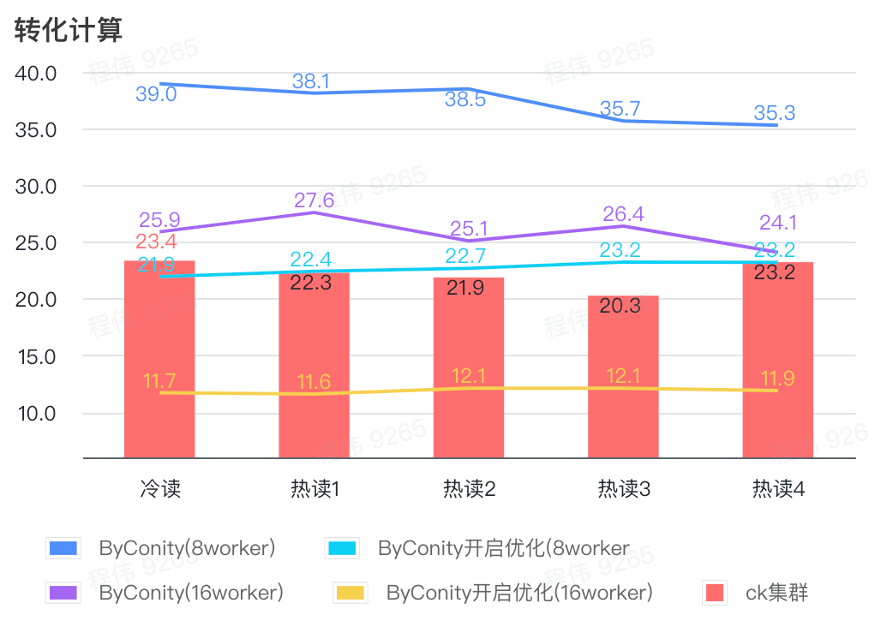
Como se puede ver en la figura anterior:
- En el escenario de cálculo de conversión, el tiempo de consulta después de habilitar ByConity para la optimización es el 60% del tiempo de consulta sin optimización;
- El tiempo de consulta de 8 trabajadores (120C 880G) con la optimización activada está cerca del tiempo de consulta de ClickHouse;
- Al transformar los escenarios informáticos, la velocidad de consulta se puede acelerar al 53% del tiempo de consulta de ClickHouse ampliando los recursos informáticos + optimización.
no en el filtro
No en el filtrado se utiliza principalmente en escenarios de agrupación de usuarios y escenarios de etiquetado de usuarios.

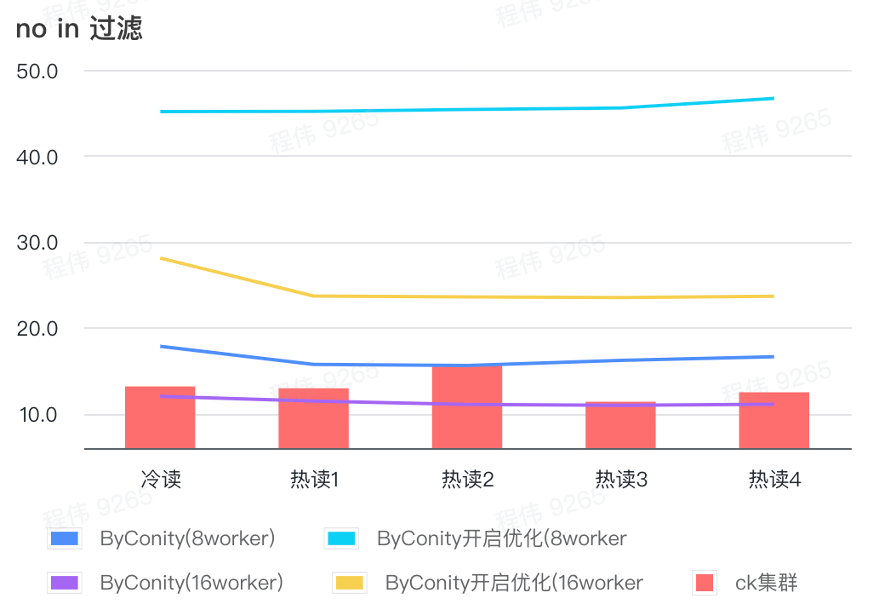
Como se puede ver en la figura anterior:
- En el escenario sin filtrado, ByConity con la optimización activada es peor que ByConity con la optimización no activada, por lo que en este escenario utilizamos directamente el método de no activar la optimización;
- El tiempo de consulta de 8 trabajadores (120C 880G) sin optimización es más lento que el tiempo de consulta de ClickHouse, pero no mucho;
- En ningún escenario de filtrado, la velocidad de consulta se puede acelerar al 86 % del tiempo de consulta de ClickHouse ampliando los recursos informáticos.
Cálculo de clic 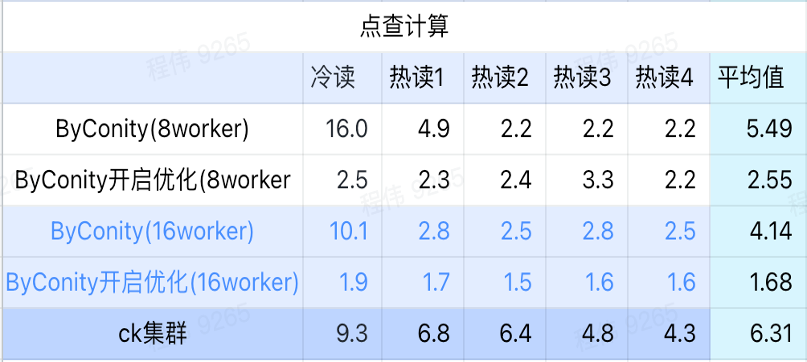
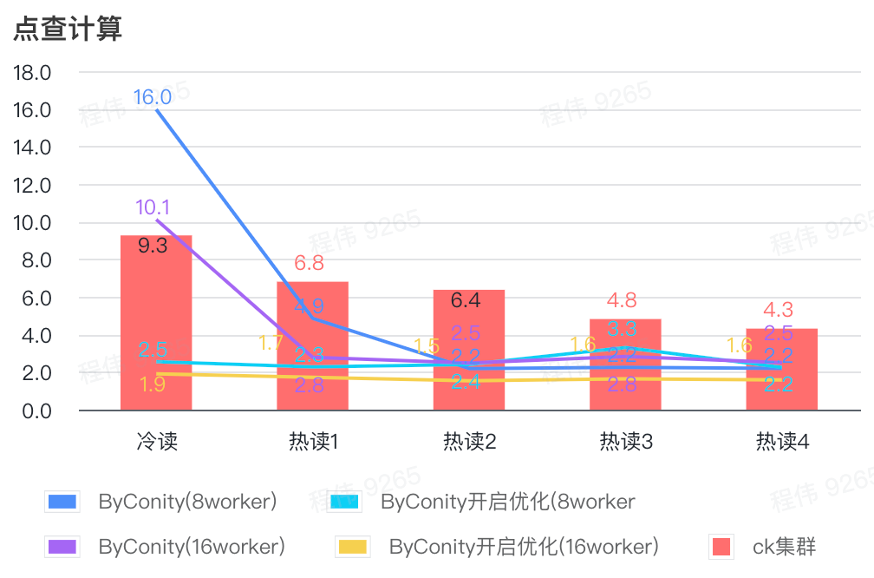
Como se puede ver en la figura anterior:
- Después de verificar la escena, es mejor activar ByConity y optimizar que ByConity no activar la optimización;
- El tiempo de consulta de 8 trabajadores (120C 880G) sin optimización está cerca del tiempo de consulta de ClickHouse;
- En el escenario de clic, la velocidad de consulta se puede acelerar al 26% del tiempo de consulta de ClickHouse ampliando los recursos informáticos y activando la optimización.
consulta de mapa de bits
La consulta de mapa de bits es un escenario que se utiliza más en las pruebas AB.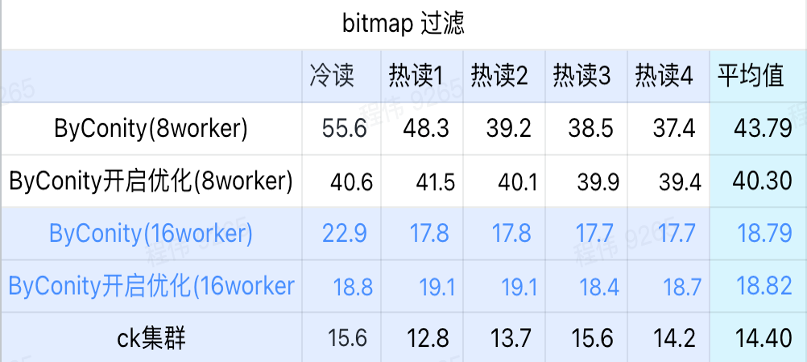
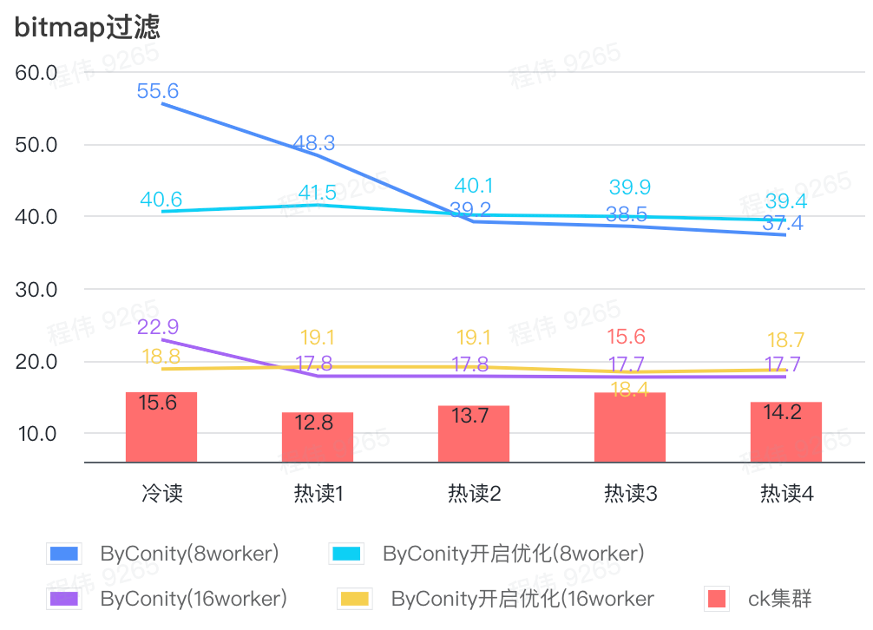
Como se puede ver en la figura anterior:
- En la escena del filtrado de mapas de bits, es mejor activar la optimización ByConity que sin la optimización ByConity;
- El tiempo de consulta de 8 trabajadores (120C 880G) sin optimización es mucho más lento que el tiempo de consulta de ClickHouse;
- La escena de filtrado de mapas de bits, la expansión de recursos a 16 trabajadores (240C 1769G) es más lenta que la consulta de ClickHouse.
Ganancias tras la migración completa de ByConity
Recursos reducidos
Lo siguiente no cuenta las diferencias de CPU, los datos son solo de referencia.
Después de la migración completa usando ByConity
- La comparación del consumo de recursos de consulta y fusión muestra que el consumo de CPU se reduce en aproximadamente un 75% en comparación con antes;
- Comparando los recursos de escritura de datos, el consumo de CPU se reduce en aproximadamente un 35% en comparación con antes;
- Solo es necesario comprar la mitad de los recursos fijos y la mitad restante depende de la flexibilidad de los días laborables (de 10 a. m. a 8 p. m. El costo se reduce en aproximadamente un 25% en comparación con la compra de la cantidad total de recursos);
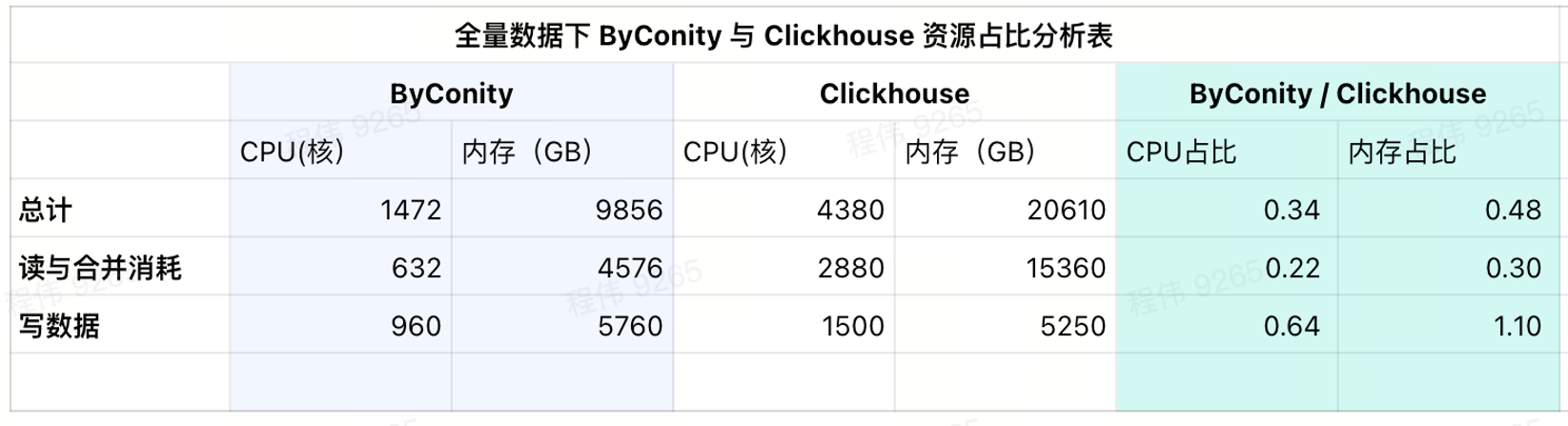
Consumo de uso actual
Como se puede ver en la tabla de resultados actual, las proporciones de CPU y memoria de ByConity son el 34% y el 48% de ClickHouse respectivamente.
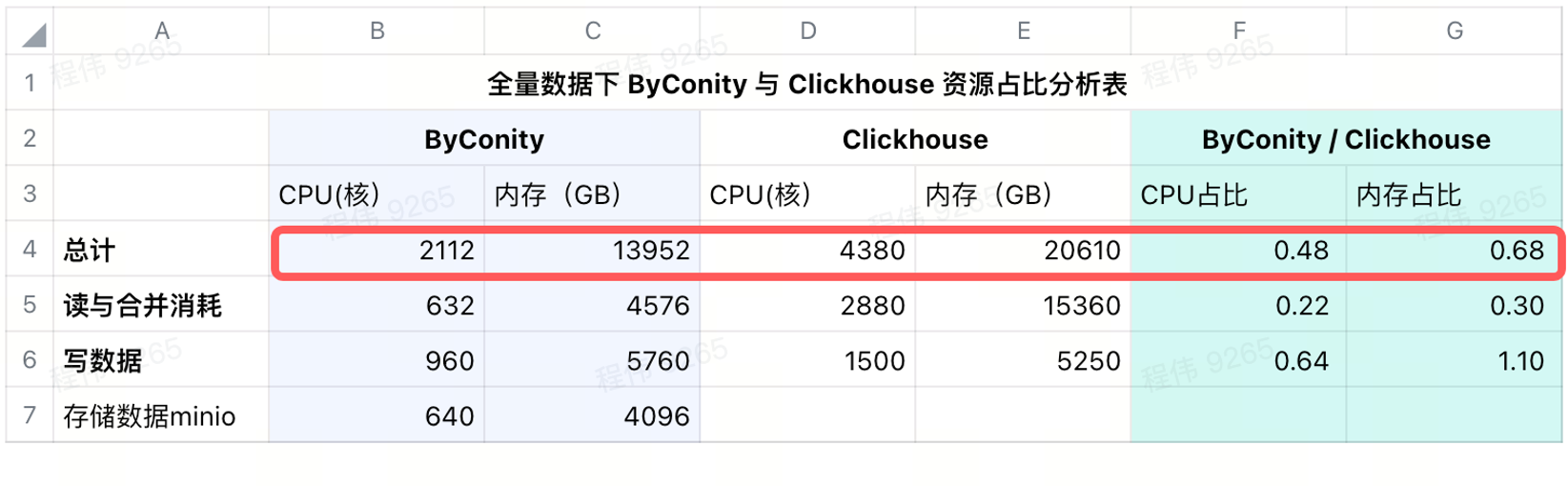
Consumo después de agregar almacenamiento remoto
Usamos minio para el almacenamiento de datos en IDC, usando una CPU de 640 núcleos, 4096G de memoria, 16 nodos, un solo nodo con 40 núcleos, 256G y un disco de 36T. Después de agregar estos costos a ByConity, la proporción de CPU y memoria de ByConity aún. inferior a ClickHouse, respectivamente 48% y 68% de ClickHouse. Se puede decir que en términos de uso de recursos, si se calcula anualmente y mensualmente, ByConity será al menos un 50% más bajo que antes, si se inicia y detiene según la demanda, el costo se reducirá en aproximadamente un 25%; en comparación con la compra de recursos en su totalidad .
Reducción de costos de operación y mantenimiento.
- Una forma más sencilla de escribir datos de configuración. En el pasado, el servicio de escritura que configuramos especialmente a menudo tenía problemas como Demasiadas partes.
- La expansión de consultas máximas es más fácil. Simplemente agregue la cantidad de pods y podrá expandir rápidamente la capacidad. Nadie preguntará "¿Por qué no aparecieron los datos después de media hora?"
Sugerencias para reemplazar ClickHouse con ByConity
- Pruebe si su SQL puede ejecutarse normalmente en la plataforma ByConity de su empresa. Si es compatible, básicamente se ejecutará. Si hay algunos problemas menores en casos individuales, puede plantearlos en la comunidad para obtener comentarios rápidos;
- Controle los recursos del clúster de prueba, pruebe el tamaño del conjunto de datos y compare los resultados de las consultas del clúster ByConity y el clúster ClickHouse para ver si cumplen con las expectativas. Si se espera, se puede planificar el reemplazo. Para tareas que están más centradas en la computación, ByConity puede funcionar mejor;
- Según el tamaño del conjunto de datos de prueba, el espacio S3 y HDF consumido, el ancho de banda y el uso de recursos informáticos QPS, se evalúan los recursos necesarios para el almacenamiento y el cálculo de la cantidad total de datos;
- Ingrese los datos en el clúster ByConity o ClickHouse al mismo tiempo y comience la ejecución dual durante un período de tiempo para resolver los problemas que surjan durante la ejecución dual. Por ejemplo, cuando nuestra empresa no tiene recursos suficientes, los usamos según el negocio. Primero podemos construir un clúster ByConity en la nube, movernos a una determinada parte del negocio y luego reemplazarlo gradualmente según el negocio. Recursos de IDC, podemos mover estos Parte de los datos se migran fuera de línea;
- Puede darse de baja del clúster de ClickHouse después de que no haya problemas con la ejecución dual.
Hay algunas consideraciones durante este proceso:
- El ancho de banda de lectura y el QPS del almacenamiento remoto S3 y HDFS pueden ser mayores y se requieren ciertos preparativos. Por ejemplo, nuestro ancho de banda máximo de lectura y escritura por segundo es: escribir 2,5 GB/leer 6 GB, y el QPS máximo por segundo es: 2 ~ 6k;
- Cuando el ancho de banda del nodo trabajador está lleno, también provocará un cuello de botella en las consultas;
- El disco de caché del nodo predeterminado (es decir, el nodo informático de lectura) se puede configurar para que sea apropiadamente más grande, lo que puede reducir la presión del ancho de banda de S3 durante la consulta y acelerar la consulta.
- Si encuentra datos no almacenados en caché, es posible que tenga problemas de inicio en frío. ByConity también tiene algunas sugerencias operativas para esto, que deben integrarse más con su propio negocio. Por ejemplo, utilizamos la verificación previa por la mañana para aliviar esta parte del problema del arranque en frío.
plan futuro
En el futuro, promoveremos las pruebas e implementación de la solución de lago de datos ByConity. Además, combinaremos la gestión de indicadores de datos con la teoría del almacén de datos, de modo que el 80% de las consultas recaerán en el almacén de datos. Todos son bienvenidos a unirse a la experiencia.
GitHub |https://github.com/ByConity/ByConity

Escanee el código QR para agregar ByConity Assistant
¡Compañero pollo deepin-IDE de "código abierto" y finalmente logró el arranque! Buen chico, Tencent realmente ha convertido Switch en una "máquina de aprendizaje pensante" Revisión de fallas de Tencent Cloud del 8 de abril y explicación de la situación Reconstrucción de inicio de escritorio remoto de RustDesk Cliente web Base de datos de terminal de código abierto WeChat basada en SQLite WCDB marcó el comienzo de una actualización importante Lista de abril de TIOBE: PHP cayó a un mínimo histórico, Fabrice Bellard, el padre de FFmpeg, lanzó la herramienta de compresión de audio TSAC , Google lanzó un modelo de código grande, CodeGemma , ¿te va a matar? Es tan bueno que es de código abierto: herramienta de edición de carteles e imágenes de código abierto