
Como motor de búsqueda distribuido, ES no tiene rival en términos de capacidades de expansión y funciones de búsqueda. Sin embargo, tiene sus propias debilidades. Como sistema de almacenamiento casi en tiempo real, sus principios de diseño de fragmentación y replicación también lo hacen No puede competir con OLTP. (Procesamiento de transacciones en línea) en términos de latencia y coherencia de datos.
Debido a esto, sus datos generalmente se sincronizan desde otros sistemas de almacenamiento para filtrado y análisis secundarios. Esto presenta un nodo clave, es decir, el método de escritura síncrona de datos ES. Este artículo presenta el método ES síncrono de MySQL.
Al escribir datos MySQL en ES, lo primero que me viene a la mente es consumir Binlog y escribir directamente en ES. Este método es simple y claro. Sin embargo, si considera más dimensiones, encontrará algunas desventajas de este método. Por lo tanto, existe otra forma, es decir, la ecología integrada
[RocketMQ
+ Flink Consumer + ES Bulk]. Evaluaremos estos dos métodos de acceso desde cuatro aspectos: retraso de sincronización, características de consumo, rendimiento de escritura de ES y tolerancia a desastres del sistema . que inspire a todos y elija el método de sincronización que mejor se adapte a su negocio.
ES principios básicos de escritura
La escritura ES es un proceso de escritura tipo anexo que primero forma segmentos de un tamaño específico y luego fusiona periódicamente segmentos de datos pequeños en segmentos de datos grandes para reducir la fragmentación de la memoria y mejorar la eficiencia de las consultas. Un índice consta de N fragmentos y sus copias. Almacena documentos del mismo tipo. Su método de indexación está definido por Mapeo. Cada fragmento es un índice de Lucene completo y completamente funcional. la unidad de procesamiento de ES; el segmento es la unidad de procesamiento de datos más pequeña de ES, y cada segmento es un índice invertido independiente.
La escritura ES en realidad escribe datos continuamente en el mismo segmento (memoria) y luego activa Actualizar para actualizar el segmento a la caché del sistema operativo (los 1 predeterminados se pueden consultar en este momento y la caché del sistema operativo activará el vaciado por parte del sistema operativo). Las operaciones se conservan en el disco.
Te hace pensar: ¿Cómo garantiza ES que no se pierdan datos? ¿Cuáles son las ventajas y desventajas de escribir anexos? ¿Cómo maneja la escritura de anexos los problemas de actualización de datos? ¿A qué método de escritura pertenece MySQL? El enfoque de este artículo no está aquí, puede leer el artículo por separado.

ES conceptos básicos
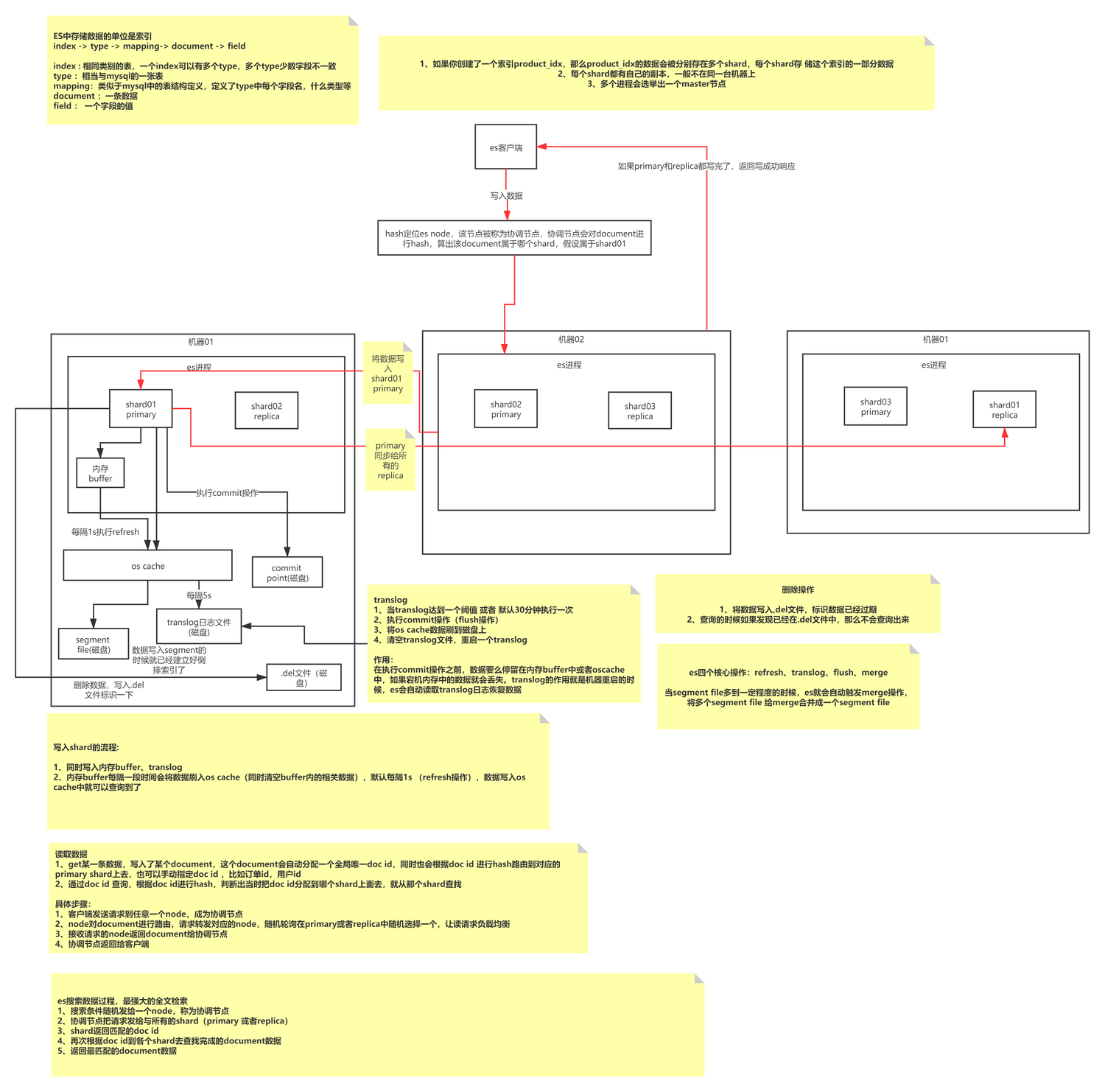
ES escritura directa

La ventaja de utilizar la escritura de conexión directa de ES es que la ruta es corta y hay pocos componentes dependientes. Además, Dsyncer (sistema de conversión de almacenamiento heterogéneo) generalmente proporciona un mecanismo completo de reintento de limitación de corriente, por lo que el retraso en el consumo y la integridad de los datos de consumo son ambos. Garantizado.
defecto:
-
No es fácil acceder a la implementación de recuperación ante desastres de varias salas de computadoras. Actualmente, todas las salas de computadoras de recuperación ante desastres de ES se implementan de forma independiente y en modo de lectura y escritura independientes. Por lo tanto, si se adopta este método, será difícil controlar las escrituras. varias salas de ordenadores al mismo tiempo y no se logrará el efecto de recuperación ante desastres. Binlog-->Dsyncer Por lo general, una tabla MySQL corresponde a una tarea de conversión. Si inicia varias tareas de conversión repetidas para escribir varias salas de computadoras, parece un poco estúpido.
-
Si su propio escenario empresarial implica la escritura simultánea del mismo registro, pero es posible que no todas las escrituras provengan de Binlog, es más probable que se produzcan conflictos de escritura si considera la escritura directa en ES globalmente porque no hay garantía de una cola ordenada.
Construya un sistema integrado ES a través de Flink

Flink construye un sistema integrado de ES, lo que significa que todas las escrituras de ES se completan mediante tareas de Flink. Flink monitorea los flujos de datos en tiempo real de RocketMQ, lo que no solo garantiza el orden de las particiones de datos, sino que también aprovecha al máximo las capacidades de escritura por lotes de ES. La capacidad de escritura por lotes es muchas veces mayor que el rendimiento de escritura única. Al mismo tiempo, debido a la tolerancia a fallas del propio Flink, se puede garantizar la máxima coherencia de los datos incluso en escenarios anormales.
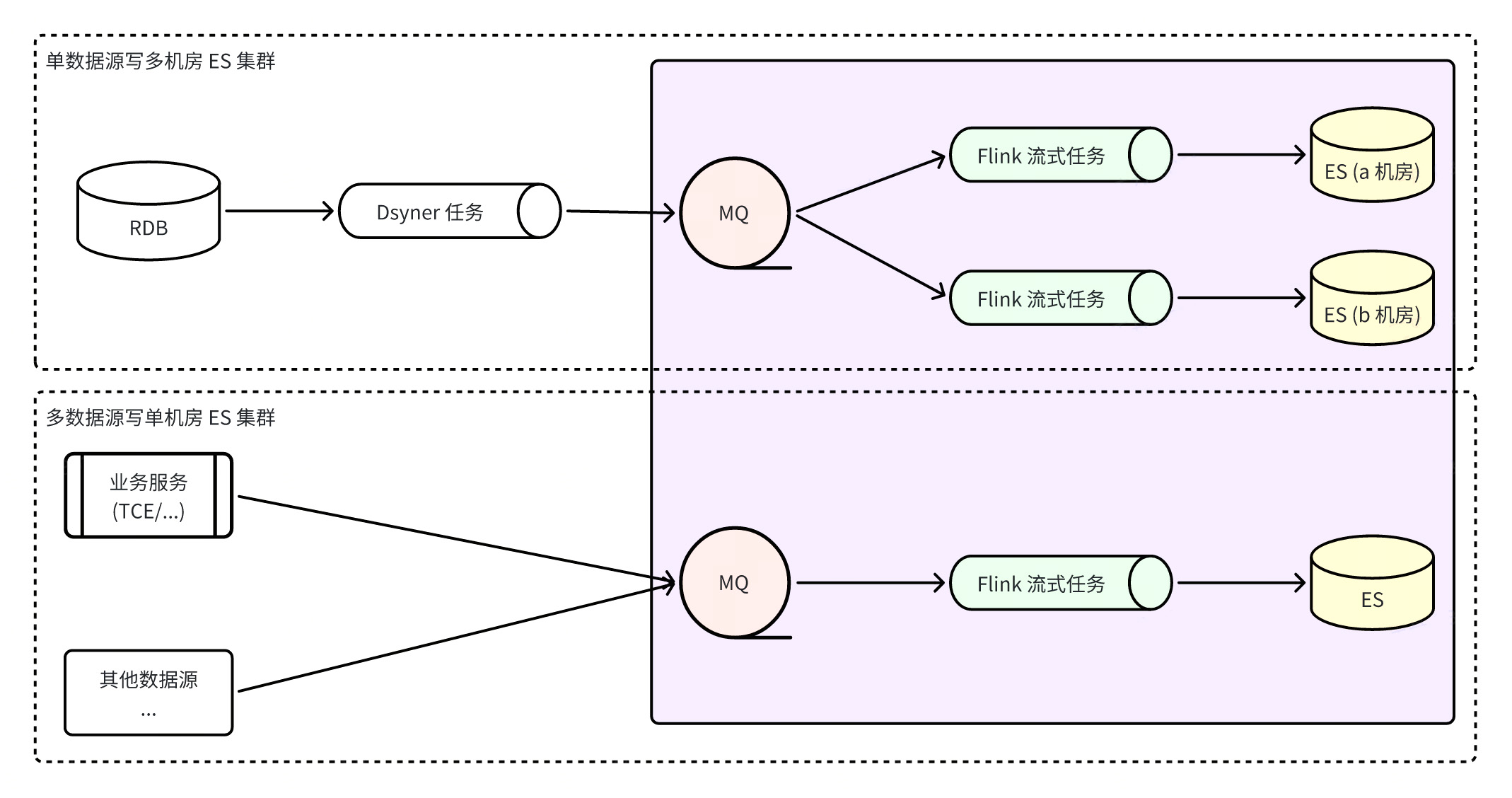
ventaja
:
-
MQ se puede utilizar para acceder más rápidamente a grupos ES de salas de máquinas múltiples y las escrituras se desacoplan. Los consumidores en las tres salas de computadoras escriben datos de forma independiente . Cuando falla una sola sala de computadoras, siempre que haya una sala de computadoras disponible. el tráfico de lectura se cortará directamente. Sí, el plan de recuperación ante desastres es simple y claro ;
-
Cuando problemas como la inquietud de la red hacen que ES no pueda escribir temporalmente, RocketMQ almacenará temporalmente el mensaje sin afectar la escritura de otros clústeres, y Flink guardará la instantánea del consumo y seguirá intentando hasta que tenga éxito, lo que garantiza mejor la coherencia final de los datos. sexo ;
-
Escribir desde múltiples fuentes de datos puede garantizar la coherencia de la partición global.
defecto
:
-
Depender de más componentes aumentará el retraso de sincronización de datos de todo el enlace, y la frecuencia de actualización predeterminada de ES es una vez por segundo. Después de la prueba, el retraso de datos del enlace en circunstancias normales es de segundo nivel, lo que no es completamente inaceptable;
-
Depende de más componentes y tiene mayores requisitos para la estabilidad de los componentes básicos. Las excepciones de RocketMQ o las excepciones de tareas de Flink causarán problemas de enlace de sincronización y aumentarán el riesgo de excepciones comerciales.
Un problema que necesita atención aquí es que algunas personas pueden considerar conectarse a un clúster ES de sala de máquinas múltiples ¿Cómo garantizar que varias salas de computadoras funcionen correctamente al mismo tiempo y cómo garantizar que los datos se puedan consultar después de una escritura exitosa? En la actualidad, estos dos puntos no se pueden lograr porque varias salas de computadoras escriben de forma independiente sin afectarse entre sí, y el clúster ES es un clúster de consistencia de datos débil, por lo que no hay garantía de que se puedan encontrar escrituras exitosas de inmediato.
Requisitos previos para crear y ejecutar un programa de consumo de ES Flink :
-
Entorno de ejecución de Flink : en primer lugar, debe tener un entorno de ejecución para las tareas de Flink. Por lo general, las tareas de Flink a nivel empresarial se programarán como trabajos YARN en el sistema distribuido y asignarán recursos para su ejecución, pero al mismo tiempo, Flink. También se puede utilizar como un proceso independiente o para crear una operación de clúster independiente.
-
Formato de mensaje ES : Es necesario acordar un formato de transmisión de mensajes ES y un método de serialización. Un conjunto de paradigmas puede resolver todos los escenarios de sincronización. El método de serialización actualmente popular es el formato pb o json. Formato de datos Definición del esquema:
|
Nombre del campo
|
tipo de valor
|
Requerido/Opcional
|
describir
|
|
_índice
|
cadena
|
requerido
|
El nombre o alias del documento a indexar.
|
|
_tipo
|
cadena
|
Requerido/Opcional
|
Tipo de Documento
|
|
_en_tipo
|
cadena
|
requerido
|
Tipo de operación de escritura de documento
, rango de valores:
indexar, crear, actualizar,
insertar
, eliminar
|
|
_identificación
|
cadena
|
Opcional
|
ID del documento
Si no se especifica, se generará
automáticamente
cuando se escriba en ES . Sin embargo, si los mismos datos se consumen y escriben repetidamente en ES, se generarán varios documentos.
|
|
_enrutamiento
|
cadena
|
Opcional
|
Enrutamiento
del documento Si no se especifica, el valor del campo _id se utilizará de forma predeterminada.
|
|
_versión
|
int64
|
Opcional
|
Versión del documento
. Cuando se especifica, es mayor que 0
y solo es válida para operaciones de indexación/eliminación
. El tipo de versión
external_gte
se utiliza de forma predeterminada.
|
|
_fuente
|
objeto
|
Requerido/Opcional
|
Contenido del documento
, no es necesario especificarlo cuando se elimina el tipo de operación.
|
|
_guion
|
objeto
|
Opcional
|
Script de documento
, válido cuando el tipo de operación es actualizar/upsert, pero no puede existir con _source al mismo tiempo
|
syntax = "proto3";
message ESIndexInfo {
string Name = 1; // 文档要写入索引的名称或别名
}
enum ESOPType { // 文档写入操作类型
DELETE = 0; // 删除文档
INDEX = 1; // 创建新文档或更新老文档,只能全量更新 (替换老文档)
UPDATE = 2; // 更新老文档,支持部分更新 (合并老文档)
UPSERT = 3; // 创建新文档或更新老文档,支持部分更新 (合并老文档)
CREATE = 4; // 创建新文档,存在时报错丢弃
}
message ESDocAction {
ESIndexInfo IndexInfo = 1; // 索引信息 (必需)
ESOPType OPType = 2; // 操作类型 (必需)
string ID = 3; // 文档 ID (可选)
string Doc = 4; // 文档内容 (JSON 格式, 删除操作时不需要)
int64 Version = 5; // 文档版本 (可选, 大于 0 且操作为 index/create/delete 有效)
string Routing = 6; // 文档路由 (可选, 非空有效)
string Script = 7; // 文档脚本 (JSON 格式, 操作类型为 update/upsert 有效,但和 Doc 不能同时存在)
}-
Configuración necesaria para las tareas de Flink : información del tema RocketMQ monitoreada, escritura de información del clúster ES;
-
Función de ejecución de Flink : Flink procesa la transmisión de mensajes de dos maneras: la transmisión de SQL y las aplicaciones personalizadas están sujetas a algunas limitaciones propias, como no admitir múltiples mensajes de índice en el mismo MQ, mientras que la programación personalizada es más flexible. Se recomienda este método para agregar varias funciones de administración, registros, procesamiento de códigos de error, etc.;
-
Configuración de recursos de Flink : configuración de recursos de JobManager, configuración de recursos de TaskManager, etc.;
-
Configuración de parámetros personalizados de Flink : puede personalizar algunas configuraciones dinámicas estrechamente relacionadas con la aplicación para facilitar el ajuste dinámico de las capacidades de consumo de Flink, como:
|
nombre del parámetro
|
usar
|
valor por defecto
|
|
job.writer.connector.bulk-flush.max-acciones
|
El número máximo de documentos en un solo lote, si excede el número, se realizará un vaciado (es decir, se ejecutará una solicitud masiva de ES)
|
Predeterminado 300
|
|
job.writer.connector.bulk-flush.max-size
|
El número máximo de bytes en un solo lote; si excede el límite, se realizará una descarga (es decir, se ejecutará una solicitud masiva de ES)
|
Predeterminado10 MB
|
|
conector.de.escritor.de.trabajo.intervalo.de.descarga masiva
|
El intervalo máximo entre dos lotes, si hay más de una descarga (es decir, ejecutar una solicitud masiva de ES)
|
Predeterminado 1000 ms
|
|
job.writer.connector.límite-de-tasa-global
|
Valor límite de velocidad de escritura global
|
Predeterminado -1, sin límite de velocidad
|
|
trabajo.escritor.conector.controlador-de-fallos
|
Especifique un controlador de fallas personalizado, como manejar errores 4xx, errores 5xx de diferentes maneras, 429 reintentar siempre infinitamente, etc.;
|
|
|
num_paralelismo_global
|
concurrencia global de tareas de flink
|
rmq es cola/4, bmq/kafka es partición/3
|
|
max_paralelismo_num
|
Máxima concurrencia de tareas de flink
|
El número de colas/particiones de mq
|
|
intervalo_punto de control
|
El intervalo para crear el punto de control, unidad ms (5min=300000)
|
Predeterminado 15 min
|
|
punto de control_tiempo de espera
|
Tiempo de espera para crear punto de control, unidad ms (5min=300000)
|
Predeterminado 10 min
|
|
reequilibrio_enable
|
Habilitar consumo fuera de orden
|
Falso predeterminado
|
Sugerencias de comparación
|
Método de escritura
|
Retraso de sincronización
|
Escribir propiedades
|
Rendimiento de escritura ES
|
consumidor
|
Tolerancia a los desastres
|
|
conexión directa
|
Menos componentes dependientes y baja latencia
|
Orden de una sola clave de Binlog
|
escritura masiva
|
FaaS
|
Pobre
|
|
RocketMQ+Flink+ES
|
Hay muchos componentes dependientes y el retraso es alto/segundo nivel.
|
Orden global de clave única
|
escritura masiva
|
Considerable
|
bien
|
Después de la introducción anterior, si la empresa puede aceptar retrasos de segundo nivel, el uso de RocketMQ + Flink puede lograr mejor el orden y las capacidades de recuperación ante desastres. Flink también es muy superior a FaaS en términos de capacidades de procesamiento de tareas de transmisión, pero el método de conexión directa obviamente tiene. Enlaces más simples, arquitectura más liviana y menores costos de integración y mantenimiento del sistema. Por lo tanto, aún es necesario elegir el más adecuado en función de las características del negocio.
Equipo fuente | Plataforma empresarial de comercio electrónico ByteDance
{{o.name}}
{{m.name}}