
Autor: Chen Xin (Shenxiu)
Hola a todos, soy Chen Xin, director técnico de producto de Tongyi Lingma. Durante los últimos ocho años, he estado trabajando en Alibaba Group en desempeño de I + D, es decir, trabajo relacionado con herramientas de I + D.
Comenzamos a construir una plataforma DevOps integral en 2015 y luego creamos Cloud Effect, que pretende nublar la plataforma DevOps. Para 2023, sentimos claramente que después de que llegue la era de los grandes modelos, las herramientas de software enfrentarán una innovación profunda. La combinación de grandes modelos y cadenas de herramientas de software llevará la investigación y el desarrollo de software a la próxima era.
¿Dónde está entonces su primera parada? De hecho, es programación auxiliar, por lo que comenzamos a crear el producto Tongyi Lingma , que es una herramienta auxiliar de IA basada en un modelo de código grande. Hoy aprovecho esta oportunidad para compartir con ustedes algunos detalles sobre la implementación de la tecnología Tongyi Lingma y cómo vemos el desarrollo de grandes modelos en el campo de la investigación y el desarrollo de software.
Lo compartiré en tres partes. La primera parte presenta primero el impacto fundamental de AIGC en la investigación y el desarrollo de software, y presenta las tendencias actuales desde una perspectiva macro; la segunda parte presentará el modelo Copilot y la tercera parte es el progreso del futuro desarrollo de productos de agentes. Por qué mencioné a Copilot Agent, te lo explicaré más adelante.
El impacto fundamental de AIGC en el desarrollo de software
Esta imagen es una imagen que dibujé en los últimos años. Creo que los factores centrales que influyen en la eficiencia de la I+D corporativa son estos tres puntos.
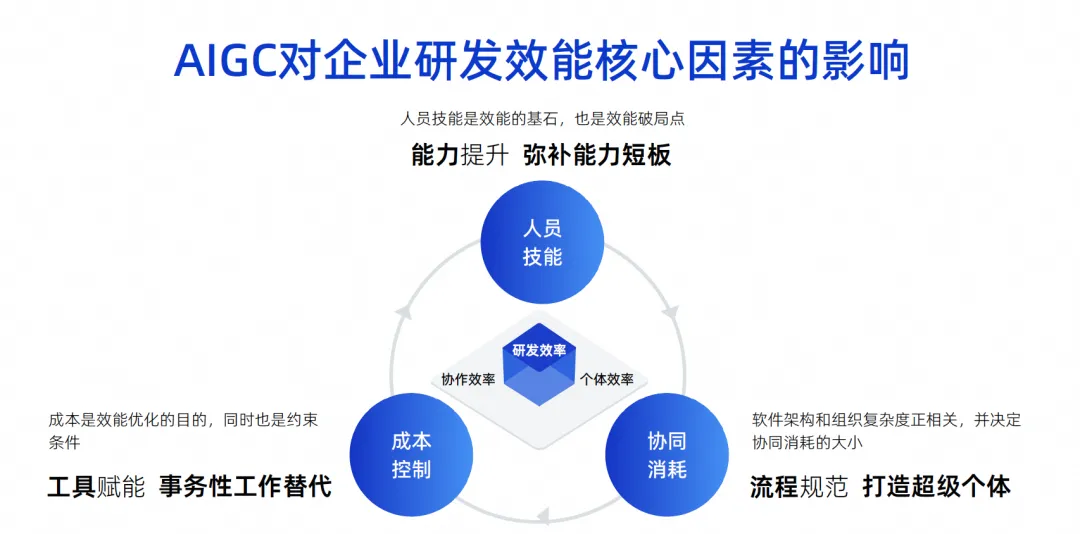
El primer punto es la habilidad con las personas. Las habilidades del personal determinan un factor muy importante en la eficiencia de la investigación y el desarrollo de una empresa. Por ejemplo, Google puede contratar ingenieros cuyas habilidades personales sean diez veces más fuertes que otras. Los ingenieros capaces tendrán una efectividad en combate muy poderosa e incluso podrán realizar la pila completa. Su división de roles puede ser muy simple, su trabajo es muy eficiente y su efectividad final también es muy grande.
Pero, de hecho, pocas de nuestras empresas, especialmente las chinas, pueden alcanzar el nivel de Google. Este es un factor de influencia objetivo. Creemos que las habilidades del personal son la piedra angular de la eficacia y, por supuesto, también el punto de ruptura de la eficacia.
El segundo punto es el consumo colaborativo. Partiendo de la base de que no podemos exigir que todos los ingenieros sean muy capaces, todos deben tener una división del trabajo profesional. Por ejemplo, algunos diseñan software y otros desarrollan, prueban y gestionan proyectos. A medida que aumenta la complejidad de la arquitectura de software del equipo compuesto por estas personas, la complejidad de la organización también aumentará proporcionalmente. Esto hará que aumente el consumo colaborativo, lo que en última instancia ralentizará la eficiencia general de la I + D.
El tercer punto es el control de costes. Descubrimos que cuando se trabaja en proyectos, la gente no siempre es rica, siempre hay escasez de mano de obra y es imposible tener fondos ilimitados para contratar diez veces más ingenieros, por lo que esto también es una limitación.
Hoy, en la era del AIGC, estos tres factores han producido algunos cambios fundamentales.
En términos de habilidades del personal, la asistencia de la IA puede mejorar rápidamente las capacidades de algunos ingenieros jóvenes. De hecho, hay algunos informes sobre esto en el extranjero. El efecto de que los ingenieros junior utilicen herramientas de asistencia de código es significativamente mayor que el de los ingenieros senior. Debido a que estas herramientas son muy buenos sustitutos del trabajo inicial o su efecto auxiliar, pueden compensar rápidamente las deficiencias de los ingenieros jóvenes.
En términos de consumo colaborativo, si la IA puede convertirse en un superindividual hoy, será realmente útil para reducir el consumo colaborativo de procesos. Por ejemplo, no es necesario tratar con personas para algunas tareas simples, la IA puede hacerlo directamente y no es necesario explicar a todos cómo probar los requisitos. La IA puede simplemente realizar pruebas simples, por lo que se mejora la eficiencia del tiempo. . Por tanto, el consumo colaborativo se puede reducir eficazmente a través de superindividuos.
En términos de control de costos, de hecho, una gran cantidad de usos de la IA reemplazan el trabajo transaccional, incluido el uso actual de modelos de código grandes para asistencia de código, que también se espera que reemplace el 70% del trabajo transaccional diario.
Si lo miramos específicamente, existirán estos cuatro desafíos y oportunidades para la inteligencia.

El primero es la eficiencia individual. Como les acabo de presentar, el trabajo repetitivo y la comunicación simple de una gran cantidad de ingenieros de I + D se pueden completar a través de la IA. Es un modelo Copilot.
Otro aspecto de la eficiencia de la colaboración es que la IA puede realizar algunas tareas simples directamente, lo que puede reducir el consumo de colaboración. Acabo de explicarlo claramente.
El tercero es la experiencia en I + D. ¿En qué se centró la cadena de herramientas DevOps en el pasado? Uno a uno, van formando una gran cadena de montaje y toda la cadena de herramientas. De hecho, cada cadena de herramientas puede tener diferentes hábitos de uso en diferentes empresas e incluso puede tener diferentes sistemas de cuentas, diferentes interfaces, diferentes interacciones y diferentes permisos. Esta complejidad genera costos muy grandes de cambio de contexto y costos de comprensión para los desarrolladores, lo que invisiblemente hace que los desarrolladores estén muy descontentos.
Pero se han producido algunos cambios en la era de la IA. Podemos utilizar el lenguaje natural para operar muchas herramientas a través de una entrada de diálogo unificada e incluso resolver muchos problemas en la ventana del lenguaje natural.
Déjame darte un ejemplo. Por ejemplo, si comprobamos si hay algún problema de rendimiento en una declaración SQL, ¿qué deberíamos hacer? Primero puede desenterrar la declaración SQL en el código, convertirla en una declaración ejecutable y luego colocarla en un sistema DMS para diagnosticarla y ver si usa índices y si hay algún problema, y luego juzgar manualmente si es Es necesario o no modificar este SQL para optimizarlo y finalmente cambiarlo en el IDE. Este proceso requiere cambiar varios sistemas y se deben hacer muchas cosas.
En el futuro, si tenemos herramientas de inteligencia de código, podemos rodear un código y preguntarle al modelo grande si hay algún problema con este SQL. Este modelo grande puede llamar de forma independiente a algunas herramientas, como el sistema DMS, para analizar y el. Los resultados obtenidos pueden decirme directamente cómo se debe optimizar SQL a través del modelo grande y decirme los resultados directamente. Solo necesitamos adoptarlo para resolver el problema. Se acortará todo el enlace de operación, se mejorará la experiencia y se realizará I + D. Se mejorará la eficiencia.
El cuarto son los activos digitales. En el pasado, todos escribían código y lo ponían allí, y se convertía en una montaña de código o pasivo. Por supuesto, hay muchas minas de oro pendientes que no han sido desenterradas y todavía hay muchos documentos. que quiero encontrar. El tiempo no se puede encontrar.
Pero en la era de la IA, una de las cosas más importantes que hacemos es ordenar nuestros activos y documentos y potenciar modelos grandes a través de SFT y RAG, para que los modelos grandes se vuelvan más inteligentes y más acordes con la personalidad del Por lo tanto, los cambios actuales en los métodos de interacción persona-computadora traerán cambios en la experiencia.

La inteligencia artificial acaba de analizar los factores que influyen. Su objetivo principal es lograr tres cambios en los métodos de interacción entre humanos y computadoras. La primera es que la IA se convertirá en un copiloto, combinada con herramientas, y luego las personas podrán ordenarla para ayudarnos a completar algunas herramientas de un solo punto. En la segunda etapa, todos deberían tener un consenso. Se convierte en un Agente, lo que significa que tiene la capacidad de completar tareas de forma independiente, incluida la escritura de código o la realización de pruebas de forma independiente. De hecho, la herramienta actúa como un experto multidominio. Sólo necesitamos dar el contexto y completar la alineación del conocimiento. En la tercera etapa, juzgamos que la IA puede convertirse en un tomador de decisiones, porque en la segunda etapa el tomador de decisiones sigue siendo un ser humano. En la tercera etapa, es posible que el modelo grande tenga algunas capacidades de toma de decisiones. incluyendo capacidades de análisis e integración de información más avanzadas. En este momento, la gente se centrará más en la creatividad y la corrección empresarial, y muchas cosas se pueden dejar en manos de modelos grandes. A través de este cambio en diferentes modos hombre-máquina, nuestra eficiencia laboral general será mayor.

Otro punto es que la forma de transferencia de conocimiento de la que acabamos de hablar también ha sufrido cambios fundamentales. En el pasado, el problema de la transferencia de conocimientos se resolvía mediante el boca a boca, la formación y lo viejo trayendo lo nuevo. Es muy probable que esto no sea necesario en el futuro. Solo necesitamos equipar el modelo con conocimiento empresarial y experiencia en el dominio, y dejar que cada ingeniero de desarrollo utilice herramientas inteligentes. Este conocimiento se puede transferir al proceso de investigación y desarrollo. herramientas, y se convertirá en la imagen de la derecha. Como se muestra arriba, ahora hay una cadena de herramientas integral para DevOps. Después de acumular una gran cantidad de activos de código y documentos, estos activos se clasifican y ensamblan con el modelo grande. A través de RAG y SFT, el modelo se integra en cada enlace de la herramienta DevOps, generando así más datos, formando dicho avance. ciclo, en este proceso, los desarrolladores de primera línea pueden disfrutar de los dividendos o capacidades que aportan los activos.
Lo anterior es mi introducción desde una perspectiva macro a los factores centrales que afectan la eficiencia de I+D de modelos grandes, así como a los dos cambios de forma más importantes: el primero es el cambio en la forma de interacción persona-computadora, y el segundo es el cambio en la forma de transferir el conocimiento. Debido a diversas limitaciones técnicas y problemas en la etapa de desarrollo de modelos grandes, lo que mejor hacemos es el modo de interacción persona-computadora Copilot, por lo que a continuación presentaremos algo de nuestra experiencia y cómo crear el mejor modo de interacción persona-computadora Copilot. .
Crea tu mejor pose de Copiloto
Creemos que el modelo de desarrollo de código de interacción humano-computadora actualmente solo puede resolver problemas como tareas pequeñas, problemas que requieren adopción manual y problemas de alta frecuencia, como la finalización del código. La IA nos ayuda a generar un párrafo, lo aceptamos. y luego generamos otro párrafo, tomemos otra sección, este es un problema muy frecuente, y también existe el problema de la salida corta, no generaremos un proyecto a la vez, ni siquiera generaremos una clase a la vez. función o algunas líneas cada vez. ¿Por qué hacemos esto? De hecho, tiene mucho que ver con las limitaciones de las capacidades propias del modelo.
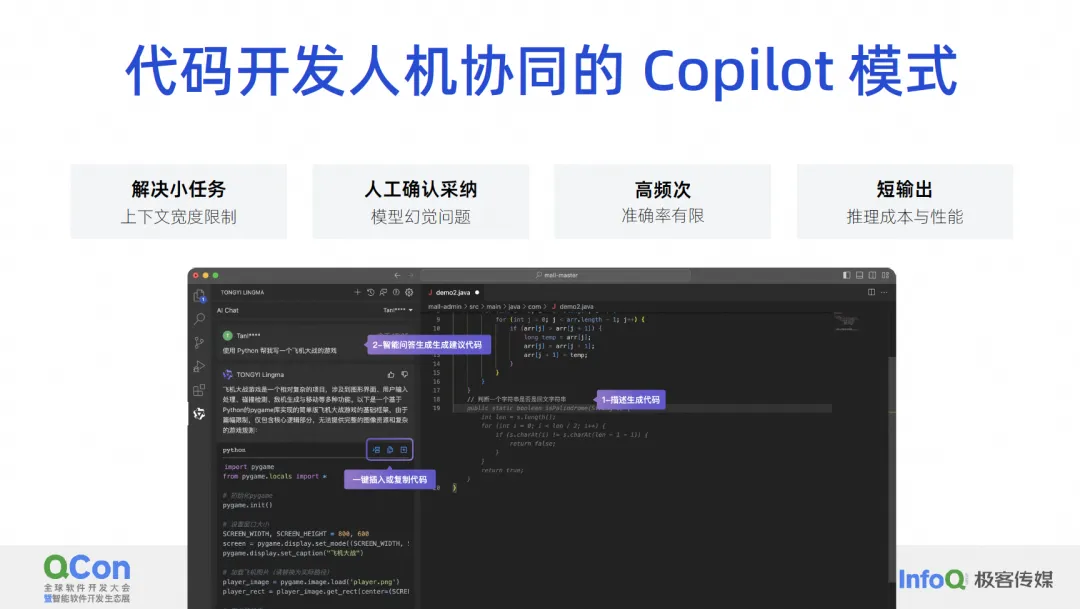
Debido a que nuestro ancho de contexto actual aún es muy limitado, si queremos completar un requisito, no hay forma de entregarle todo el conocimiento previo a la vez, por lo que podemos usar el Agente para dividirlo en un montón de tareas pequeñas. y resolverlos paso a paso. O déjelo completar la tarea más simple en modo Copilot, como generar un pequeño fragmento de código según un comentario. Esto es lo que llamamos resolver pequeñas tareas.
En términos de adopción manual, los humanos ahora tienen que emitir juicios sobre los resultados generados por modelos de código grandes. Lo que estamos haciendo bien actualmente puede ser una tasa de adopción del 30% al 40%, lo que significa que más de la mitad de nuestro código generado es en realidad inexacto o no cumple con las expectativas de los desarrolladores, por lo que debemos eliminar constantemente los problemas de ilusión.
Sin embargo, lo más importante para que los modelos grandes sean realmente utilizables a nivel de producción es la confirmación manual. Luego, no genere demasiados modelos de alta frecuencia, sino un poco cada vez, porque el costo de confirmar manualmente si este código es. OK también afecta el rendimiento. Este artículo hablará sobre algunos de nuestros pensamientos y lo que hacemos, y resolverá el problema de la precisión limitada a través de la alta frecuencia. Además, la escasez de producción se debe principalmente a cuestiones de rendimiento y costes.
El modelo actual de asistente de código en realidad supera con mucha precisión algunas limitaciones técnicas de los modelos grandes, por lo que dicho producto puede lanzarse rápidamente. En nuestra opinión, el modelo Copilot que más gusta a los desarrolladores son las siguientes cuatro palabras clave: necesidades rígidas y de alta frecuencia, al alcance, sabiendo lo que quiero y exclusivo para mí.

La primera es que necesitamos resolver escenarios de alta frecuencia y de necesidad urgente, para que los desarrolladores puedan sentir que esto es realmente útil, no solo un juguete.
El segundo está al alcance, es decir, se puede despertar en cualquier momento y puede ayudarnos a solucionar problemas en cualquier momento. Ya no necesito buscar códigos a través de varios motores de búsqueda como antes. Es como si estuviera a mi lado y puedo activarlo en cualquier momento para ayudarme a resolver problemas.
El tercero es saber lo que pienso, es decir, la precisión con la que responde a mis preguntas y el momento en que responde a mis preguntas son muy importantes.
Finalmente, debe pertenecerme. Puede comprender parte de mi conocimiento privado, en lugar de comprender únicamente cosas que son completamente de código abierto. Analicemos estos cuatro puntos en detalle.
Sólo se necesita alta frecuencia
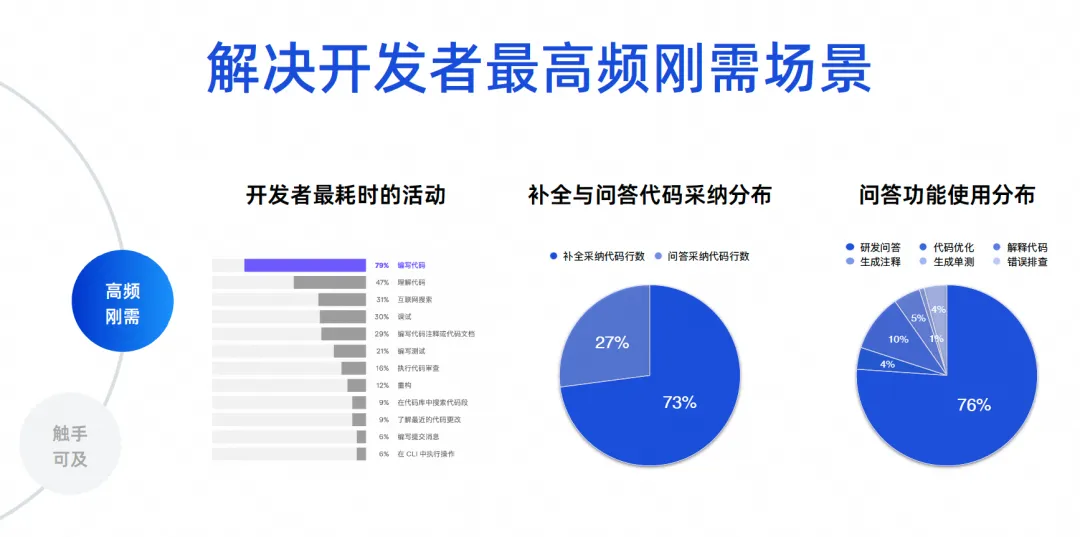
Necesitamos determinar cuáles son los escenarios más frecuentes para el desarrollo de software. Tengo algunos datos reales aquí. Los primeros datos provienen de un informe ecológico de desarrolladores realizado por JetBrains en 2023, que recopiló las actividades que consumen más tiempo de los desarrolladores. Se puede ver que entre el 70% y el 80% están escribiendo código y entendiendo el código. y buscar en Internet, depurar, escribir comentarios y escribir pruebas. Estos escenarios son en realidad funciones de herramientas de inteligencia de código. Los problemas centrales que resuelven productos como Tongyi Lingma son en realidad los problemas más frecuentes.
Los dos últimos datos son análisis de datos de cientos de miles de usuarios de Tongyi Lingma Online. El 73% del código que adoptamos actualmente en línea proviene de tareas de finalización y el 27% proviene de la adopción de tareas de preguntas y respuestas. Entonces, hoy en día, una gran cantidad de IA reemplaza a las personas al escribir código y todavía se generan entre líneas en IDE. Este es un resultado que se refleja en la situación real. El siguiente es la proporción de uso de la función de preguntas y respuestas: el 76% de la proporción proviene de preguntas y respuestas de I + D, y el 10% restante es una serie de tareas de código, como la optimización y la interpretación del código. Por lo tanto, la gran mayoría de los desarrolladores todavía utilizan nuestras herramientas para solicitar conocimientos comunes de I + D, o utilizan el lenguaje natural para generar algunos algoritmos a partir de modelos de código grandes para resolver algunos problemas pequeños.
El siguiente 23% son nuestras tareas de codificación realmente detalladas. Esto es para brindarles a todos una visión de los datos. Entonces tenemos nuestros objetivos principales. Primero, necesitamos resolver el problema de la generación de código, especialmente entre líneas. En segundo lugar, es necesario resolver las cuestiones de precisión y profesionalidad en materia de I+D.
Al alcance

En última instancia, de lo que queremos hablar es de crear una experiencia de programación inmersiva. Esperamos que la mayoría de los problemas que enfrentan los desarrolladores hoy en día se puedan resolver dentro del IDE en lugar de tener que saltar.
¿Cuál ha sido nuestra experiencia en el pasado? Cuando encuentre un problema, debe buscar en Internet o preguntar a otros y luego hacer su propio juicio después de preguntar. Finalmente, escriba el código, cópielo, colóquelo en el IDE para depurarlo y compilarlo, y verifique nuevamente si es así. falla. Esto llevará mucho tiempo. Esperamos poder preguntarle directamente al modelo grande en el IDE y dejar que el modelo grande genere código para mí, para que la experiencia sea muy placentera. A través de esta elección técnica, resolvimos el problema de la experiencia de programación inmersiva.
La tarea de finalización es una tarea sensible al rendimiento y su salida debe ser de 300 a 500 milisegundos, preferiblemente no más de un segundo, por lo que tenemos un modelo de parámetros pequeños, que se utiliza principalmente para generar código y la mayor parte de su entrenamiento. El corpus también proviene del código. Aunque los parámetros de su modelo son pequeños, la precisión de la generación de código es muy alta.
La segunda es realizar tareas especiales. Todavía tenemos entre el 20% y el 30% de las tareas reales provenientes de estas, incluidas siete tareas como generación de anotaciones, pruebas unitarias, optimización de código y resolución de problemas de errores operativos.
Actualmente utilizamos un modelo de parámetros moderados. Las principales consideraciones aquí son, en primer lugar, la eficiencia de la generación y, en segundo lugar, la sintonización. Para un modelo de parámetros muy grandes, nuestro costo de ajuste es muy alto, pero en este modelo de parámetros medios, su comprensión del código y sus efectos de generación de código ya son buenos, por lo que elegimos el modelo de parámetros medios.
Luego, en modelos grandes, especialmente al responder más del 70% de nuestras preguntas de I+D, buscamos alta precisión y conocimiento en tiempo real. Por lo tanto, superpusimos nuestra tecnología RAG a través de un modelo de parámetro máximo, lo que le permite conectarse a una base de conocimiento basada en Internet casi en tiempo real, por lo que la calidad y el efecto de sus respuestas son muy altos y puede eliminar en gran medida las ilusiones del modelo y mejorar la respuesta. calidad. Respaldamos toda la experiencia de programación inmersiva a través de tres de estos modelos.

El segundo punto es que necesitamos implementar múltiples terminales, porque solo cubriendo más terminales podemos cubrir a más desarrolladores. Actualmente, Tongyi Lingma admite código VS y JetBrains. Resuelve principalmente problemas de activación, problemas de visualización y algunos problemas de interactividad.
A nivel central, nuestro servicio de Agente local es un proceso independiente. Habrá comunicación entre este proceso y el complemento anterior. Este proceso aborda principalmente algunas capacidades centrales del código, incluida la finalización inteligente del código, la gestión de sesiones y los agentes.
Además, los servicios de análisis de sintaxis también son muy importantes. Necesitamos análisis de sintaxis para resolver problemas de referencia entre archivos. Si queremos mejorar la recuperación local, también necesitamos un motor de recuperación de vectores local liviano. Por lo tanto, de esta manera se puede ampliar rápidamente todo el servicio back-end.
También tenemos una función. Tenemos un pequeño modelo local fuera de línea de unas pocas décimas de B para implementar la finalización de una sola línea en idiomas individuales. Esto se puede hacer sin conexión, incluido JetBrains. Recientemente, JetBrains también lanzó un pequeño modelo que se ejecuta localmente. . De esta manera, algunos de nuestros problemas de privacidad y seguridad de datos, como la administración de sesiones locales y el almacenamiento local, se ubican en la computadora local.

se lo que pienso
Sé lo que pienso. Con respecto a la herramienta de complemento IDE, creo que hay varios puntos. El primero es el momento de activación. Cuando se activa, también tiene un gran impacto en la experiencia del desarrollador. Por ejemplo, ¿debería activarlo cuando entro en un espacio? ¿Debería activarse cuando el IDE haya generado un mensaje? ¿Debería activarse al eliminar este código? Probablemente tengamos más de 30 a 50 escenarios para resolver. Si activar el código en este escenario se puede resolver mediante reglas, siempre que lo exploremos detenidamente e investiguemos la experiencia del desarrollador, no es una tecnología muy profunda. .
Pero en términos de longitud de generación de código, creemos que es más difícil. Porque en diferentes ubicaciones en diferentes áreas de edición, la longitud del código que genera afecta directamente nuestra experiencia. Si los desarrolladores solo tienden a generar una sola línea de código, el problema es que el desarrollador no puede entender todo el contenido generado, por ejemplo al generar una función no sabe qué va a hacer la función, o al generar un if. declaración, no sabe qué hay dentro de la declaración if. ¿Cuál es la lógica empresarial? No hay forma de juzgar completamente las unidades funcionales, lo que afecta su experiencia.
Si usamos algunas reglas fijas para hacerlo, también causará un problema, es decir, será relativamente rígido. Entonces, nuestro enfoque en realidad se basa en la información semántica del código. A través del entrenamiento y una gran cantidad de muestras, el modelo comprende cuánto tiempo debe generarse y en qué escenario hoy hemos implementado el modelo para determinar automáticamente el nivel de clase y la función. nivel, La intensidad de generación en el nivel de bloque lógico y en el nivel de fila se denomina toma de decisiones de intensidad de generación adaptativa. Al realizar mucho entrenamiento previo, permitimos que el modelo perciba, mejorando así la precisión de la generación. Creemos que este también es un elemento técnico clave.
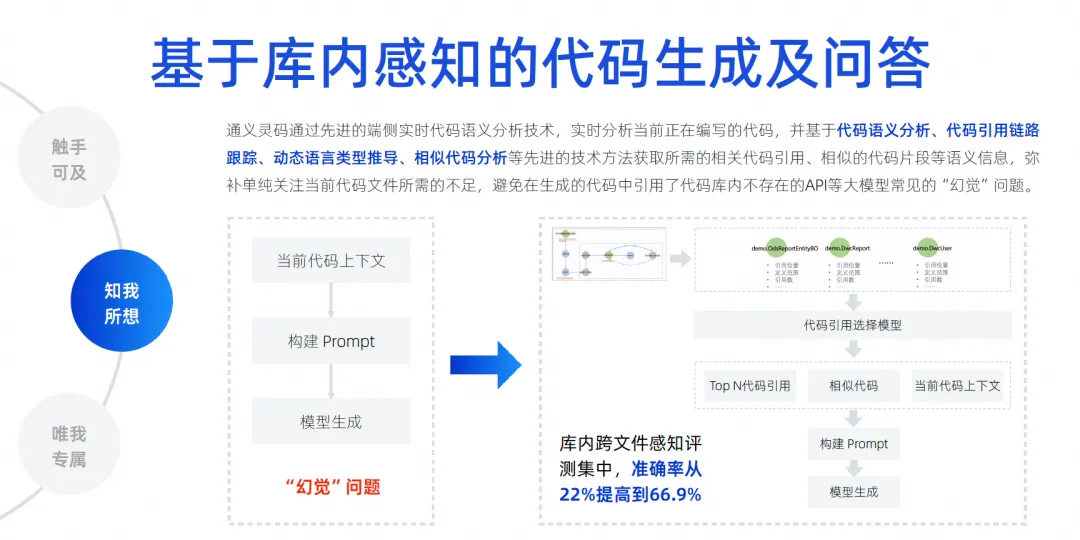
Lo más crítico en el futuro es cómo eliminar la ilusión del modelo, porque sólo cuando la ilusión se elimine lo suficiente se podrá mejorar nuestra tasa de adopción. Por lo tanto, debemos implementar el conocimiento del contexto entre archivos dentro de la biblioteca. Aquí, realizamos una gran cantidad de análisis semántico basado en código, seguimiento de cadenas de referencia, código similar y derivación de tipos de lenguaje dinámico.
Lo más importante es probar todos los medios para adivinar qué tipo de conocimiento previo puede necesitar el desarrollador para ocupar este puesto. Estas cosas también pueden involucrar algunos lenguajes, marcos, hábitos de usuario, etc. Usamos varias cosas para combinarlo. contexto, priorícelo, coloque la información más crítica en el contexto y luego entréguela al modelo grande para su derivación, permitiendo que el modelo grande elimine las ilusiones. A través de esta tecnología, podemos lograr un conjunto de pruebas de contexto entre archivos. Nuestra precisión ha aumentado del 22% al 66,9% . Seguimos mejorando constantemente el efecto de finalización.
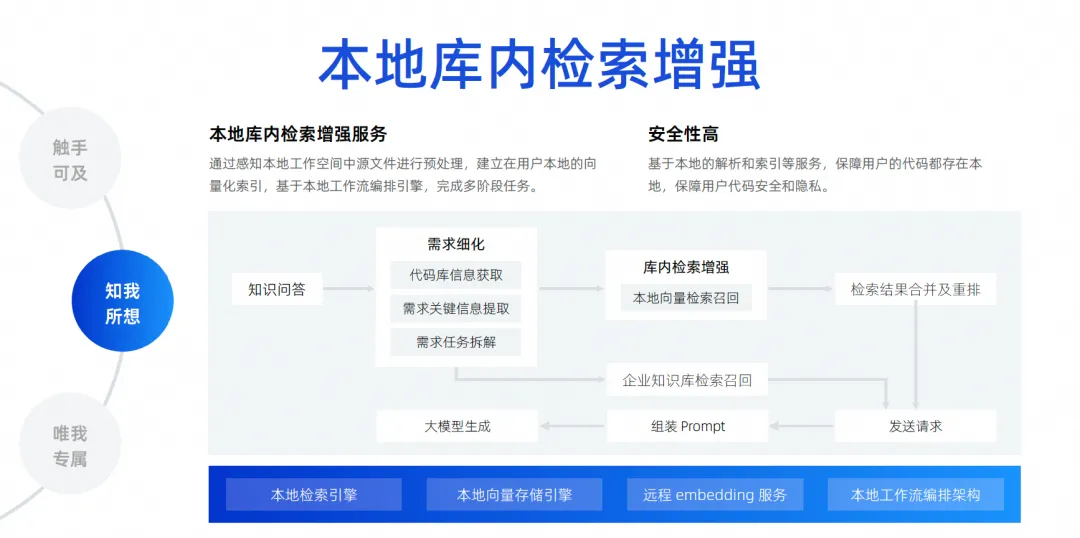
La última es nuestra mejora de búsqueda local en la biblioteca. Como acabo de decir, el conocimiento del contexto solo adivina el contexto del desarrollador en la ubicación del activador. Un escenario más común es que hoy los desarrolladores quieren hacer una pregunta y dejar que el modelo grande me ayude a resolver un problema basado en todos los archivos en la biblioteca local, como ayudarme a corregir un error, ayudarme a agregar un requisito, ayudarme. completar un archivo e implementar automáticamente adiciones, eliminaciones, modificaciones y búsquedas, e incluso agregar una nueva versión del paquete a mi archivo Pompt. En realidad, existen muchas necesidades como esta. Para lograr esto, necesitamos conectar un motor de búsqueda. para el modelo grande. Debido a que es imposible para nosotros meter todos los archivos de todo el proyecto en el modelo grande, debido al impacto del ancho del contexto, debemos usar una tecnología llamada mejora de búsqueda local en la biblioteca .
Esta función es para realizar nuestras preguntas y respuestas gratuitas basadas en la biblioteca y establecer un servicio de mejora de búsqueda local en la biblioteca. Consideramos que este método es el mejor para la experiencia de los desarrolladores y tiene la mayor seguridad.
No es necesario cargar el código en la nube para completar el enlace completo. Desde la perspectiva de todo el enlace, después de que un desarrollador haga una pregunta, iremos a la base del código para extraer la información clave necesaria para desarmar la tarea. Una vez completado el desarmado, realizaremos una búsqueda y recuperación de vectores locales, y luego. fusionar y reorganizar los resultados de la búsqueda y buscar en la base de conocimientos de datos internos de la empresa, porque la empresa tiene una gestión de la base de conocimientos unificada, que es de nivel empresarial. Finalmente, toda la información se resume y se envía al modelo grande, para que el modelo grande pueda generar y resolver problemas.

Sólo para mí
Creo que si las empresas quieren lograr un muy buen efecto con modelos de código grandes, no pueden escapar de este nivel. Por ejemplo, cómo realizar escenarios personalizados para datos empresariales, por ejemplo, en la etapa de gestión de proyectos, cómo generar modelos grandes de acuerdo con algunos formatos inherentes y especificaciones de requisitos/tareas/contenidos de defectos, ayudándonos a realizar el desmontaje automático y la renovación automática de algunos requisitos. Redacción, resumen automático, etc.
La etapa de desarrollo puede ser a lo que todos prestan más atención. Las empresas a menudo dicen que deben tener especificaciones de código que se ajusten a las propias de la empresa, hacer referencia a las bibliotecas de terceros de la empresa y llamar a API para generar SQL, incluido el uso de algunas interfaces. marcos, bibliotecas de componentes, etc. desarrollados por la empresa, todos estos pertenecen a escenarios de desarrollo. Los escenarios de prueba también deben generar casos de prueba que cumplan con las especificaciones empresariales e incluso comprendan el negocio. En escenarios de operación y mantenimiento, siempre debe buscar el conocimiento de operación y mantenimiento de la empresa y luego responder preguntas para obtener algunas de las API de operación y mantenimiento de la empresa para generar código rápidamente. Estos son los escenarios para la personalización de datos empresariales que creemos que debemos implementar. El enfoque específico es lograr esto mediante la mejora de la recuperación o el entrenamiento de ajuste.
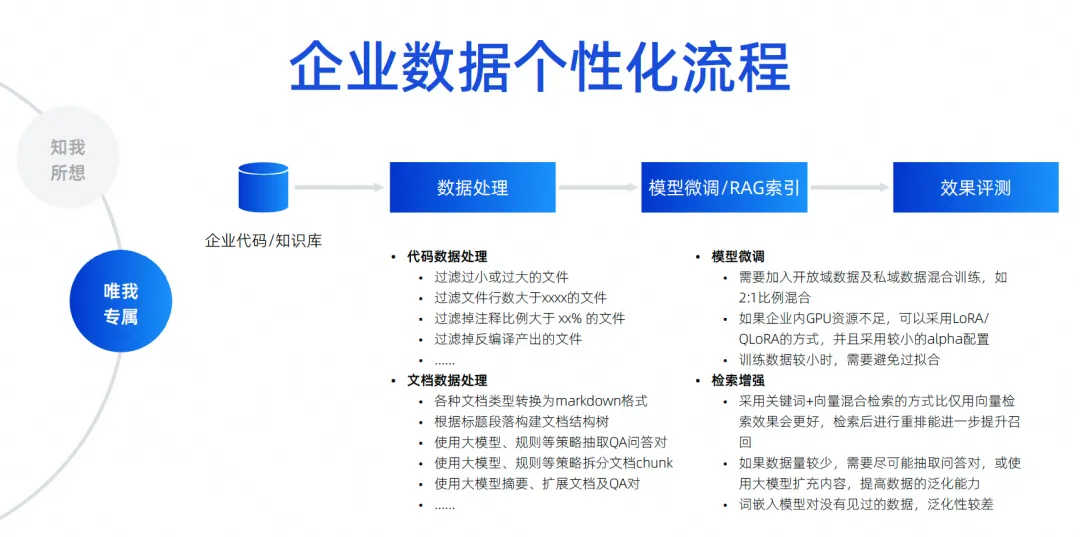
Aquí he enumerado algunos escenarios simples y cosas a las que prestar atención, incluido cómo se debe procesar el código, cómo se deben procesar los documentos y cómo se debe filtrar, limpiar y estructurar el código antes de poder usarlo.
Durante nuestro proceso de formación, debemos considerar la combinación de datos de dominio abierto y datos de dominio privado. Por ejemplo, necesitamos hacer algunos ajustes de parámetros diferentes. En términos de mejora de la recuperación, tenemos que considerar diferentes estrategias de mejora de la recuperación. De hecho, estamos explorando constantemente, incluido cómo obtener la información contextual que necesitamos en los escenarios de generación de código. Acceder a la información contextual de las respuestas que necesitamos en el escenario de preguntas y respuestas es una mejora de recuperación.
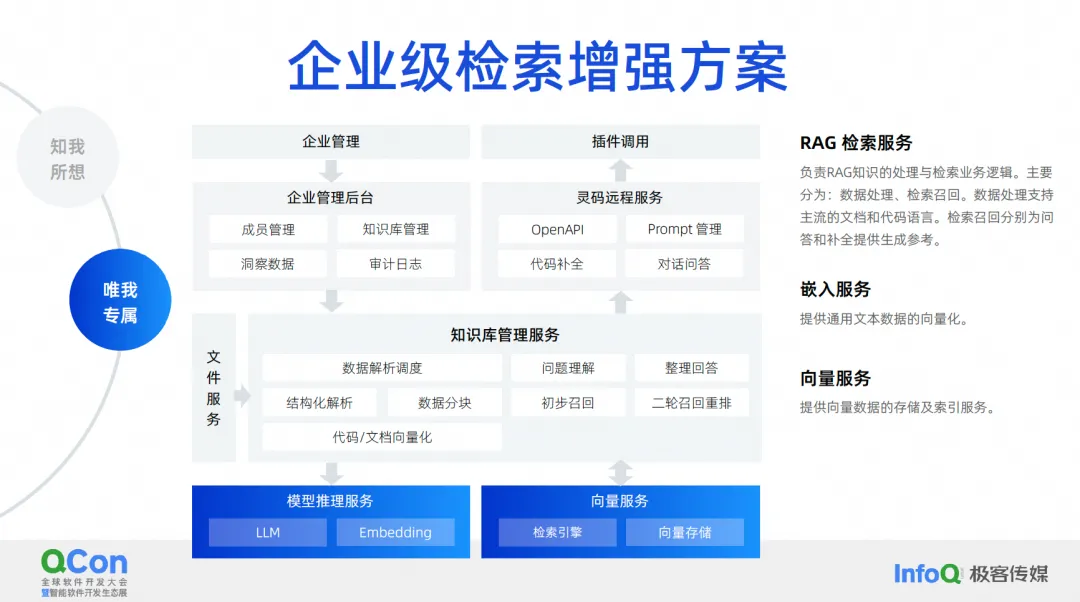
Lo que queremos hacer es una solución de mejora de la recuperación a nivel empresarial . El diagrama de arquitectura actual de la solución de mejora de la recuperación a nivel empresarial es más o menos así. En el medio está el servicio de gestión de la base de conocimientos, que incluye la programación del análisis de datos, la comprensión de preguntas, la organización de respuestas, el análisis estructurado, la segmentación de datos, etc. Las capacidades centrales están en el medio y hacia abajo están nuestros servicios de integración más utilizados. , incluidos servicios para modelos grandes, almacenamiento y recuperación de vectores.
Hacia arriba hay algunos backends que administramos. En este escenario, respaldan nuestra mejora de recuperación de documentos y mejora de recuperación de generación de código. La generación de código es para completar la recuperación y mejora de este escenario. Los métodos y tecnologías de procesamiento requeridos son en realidad ligeramente diferentes de los de los documentos.
En el pasado, hemos realizado investigaciones académicas con la Universidad de Fudan durante varios años y estamos muy agradecidos por sus esfuerzos. También publicamos algunos artículos. En ese momento, los resultados de nuestro conjunto de pruebas también se basaron en un modelo 1.1. a 1B, junto con la mejora de búsqueda, en realidad La precisión y el efecto pueden lograr el mismo efecto que el de un modelo 7B o superior.
Evolución futura del producto del agente de desarrollo de software
Creemos que el desarrollo de software futuro definitivamente entrará en la era del Agente, lo que significa que tiene cierta autonomía y puede usar nuestras herramientas muy fácilmente, luego comprender las intenciones humanas, completar el trabajo y, finalmente, formar un software multipropósito como se muestra en La figura. Modelo colaborativo de agentes.

Recién en marzo de este año, el nacimiento de Devin nos hizo sentir que este asunto estaba realmente acelerado. Nunca imaginamos que este asunto podría completar un proyecto empresarial real. Nunca lo habíamos imaginado en el pasado, e incluso sentimos que este asunto. Puede que todavía falte un año, pero su aparición nos hace sentir que hoy realmente podemos desmantelar cientos o miles de pasos a través de grandes modelos y ejecutarlos paso a paso. Si surgen problemas, también podemos autorreflexionar e iterar sobre nosotros mismos. La fuerte capacidad de desmontaje y capacidad de razonamiento nos sorprendió mucho.
Con el nacimiento de Devin, varios expertos y académicos comenzaron a invertir, incluido nuestro Laboratorio Tongyi, que inmediatamente lanzó un proyecto llamado OpenDevin. Este proyecto ha superado las 20.000 estrellas en apenas unas semanas. Se puede comprobar que todo el mundo está muy entusiasmado con este campo. Luego, inmediatamente abrimos el proyecto Agent de SWE, elevando la tasa de solución de banco SWE a más del 10%. En el pasado, los modelos grandes estaban en el rango de un pequeño porcentaje, y llevarlo al 10% ya está cerca del rendimiento de Devin, por lo que. consideramos que la investigación académica en este campo puede ser muy rápida,
Hagamos una suposición audaz: es muy probable que de junio a septiembre, a mediados de 2024, la tasa de solución del banco SWE supere el 30%. Hagamos una suposición audaz. Si puede lograr una tasa de resolución del 50 al 60 por ciento, su conjunto de prueba son en realidad algunos problemas reales de Github, deje que AI complete los problemas en Github, corrija errores y resuelva tales necesidades. Si este conjunto de pruebas puede hacer que la tasa de finalización autónoma de la IA alcance el 50 o 60%, creemos que realmente se puede implementar a nivel de producción. Con él se pueden solucionar al menos algunos defectos simples, que son algunos de los últimos desarrollos que hemos visto en la industria.
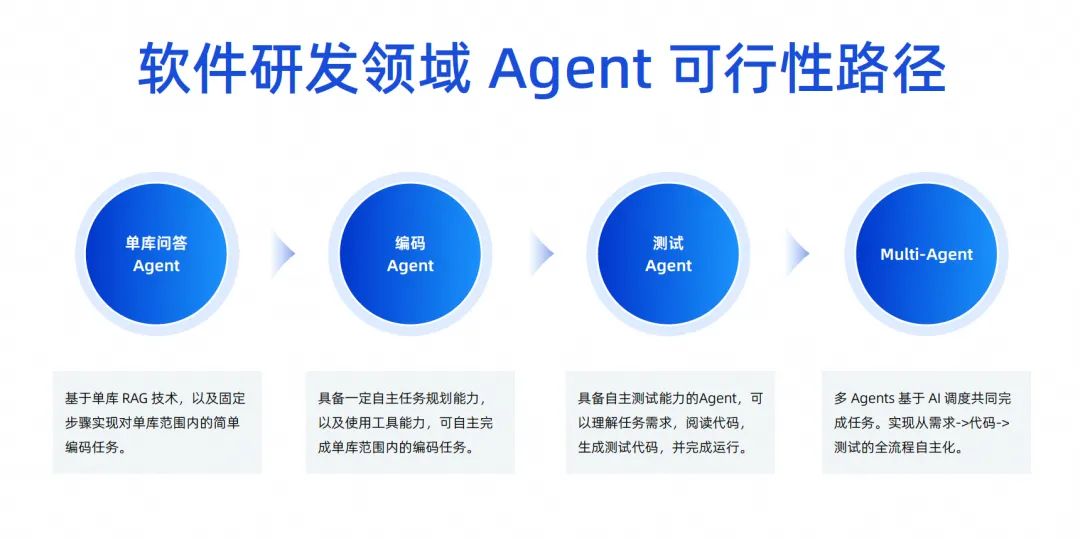
Sin embargo, esta imagen no se puede realizar de inmediato desde una perspectiva técnica, la implementaremos gradualmente en estos cuatro pasos.
En el primer paso, todavía estamos trabajando en un agente de preguntas y respuestas de base de datos única. Este campo es muy avanzado. Actualmente estamos trabajando en un agente de preguntas y respuestas de base de datos única, que estará en línea en un futuro próximo.
En el siguiente paso, esperamos lanzar un Agente que pueda completar tareas de codificación de forma independiente. Su función principal es tener un cierto grado de capacidades de planificación independientes. Puede utilizar algunas herramientas para comprender los conocimientos previos y completar tareas de codificación de forma independiente. biblioteca, no entre bibliotecas, puede imaginar que un requisito tiene múltiples bases de código, y luego también se cambia el front-end y el back-end, y finalmente se forma un requisito. .
Entonces, primero implementamos el agente de codificación de una sola biblioteca y luego haremos el agente de prueba. El agente de prueba puede completar automáticamente algunas tareas de prueba en función de los resultados generados por el agente de codificación, incluida la comprensión de los requisitos de la tarea y la lectura. código, generación de casos de prueba y ejecución autónoma.
Si la tasa de éxito de estos dos pasos es relativamente alta, pasaremos al tercer paso. Permita que varios agentes trabajen juntos para completar tareas basadas en la programación de IA, logrando así la autonomía de todo el proceso, desde los requisitos hasta el código y las pruebas.
Desde el punto de vista de la ingeniería, procederemos paso a paso para garantizar que cada paso alcance una mejor implementación a nivel de producción y, en última instancia, produzcamos productos. Pero desde una perspectiva académica, su velocidad de investigación será más rápida que la nuestra. Ahora estamos discutiendo desde perspectivas académicas y de ingeniería, y tenemos una tercera rama que es la evolución de modelos. Estos tres caminos son algunas de las investigaciones que estamos realizando actualmente junto con Alibaba Cloud y Tongyi Lab.
Con el tiempo, formaremos una arquitectura conceptual de múltiples agentes. Los usuarios podrán hablar con el modelo grande, y el modelo grande puede dividir las tareas, y luego habrá un sistema de colaboración de múltiples agentes. Este Agente puede conectar algunas herramientas y tener su propio entorno de ejecución. Luego, varios Agentes pueden colaborar entre sí y también compartirán algunos mecanismos de contexto.
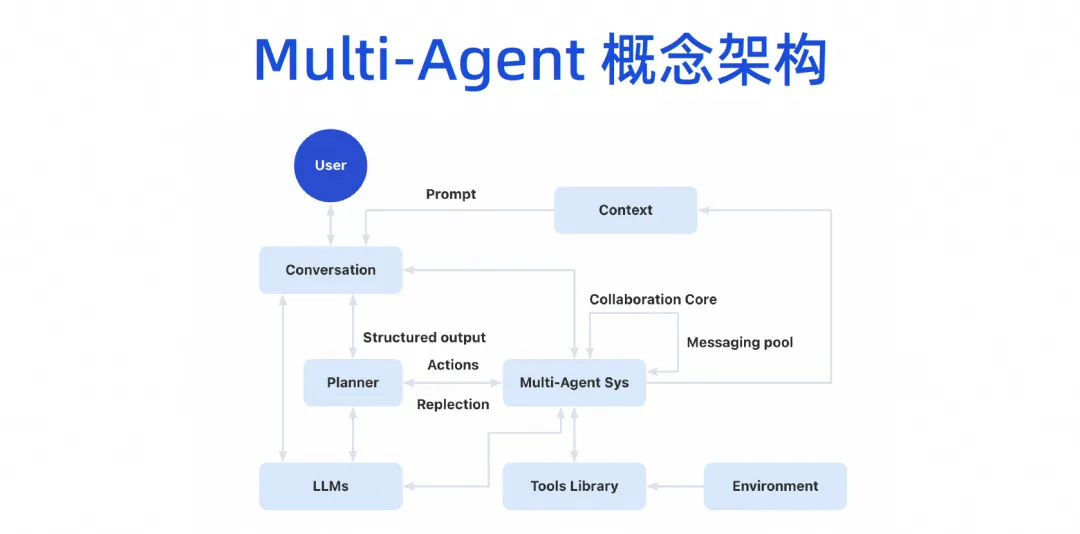
Esta imagen de producto se dividirá en tres capas. La parte inferior es la capa básica. Para las empresas, la capa básica se puede completar primero. Por ejemplo, ahora se puede introducir un modelo de código grande. Aunque no hemos implementado AI Bot de inmediato, ahora tenemos las capacidades del complemento de generación de código IDE y ya podemos hacer algo de trabajo, que es el modelo Copilot.
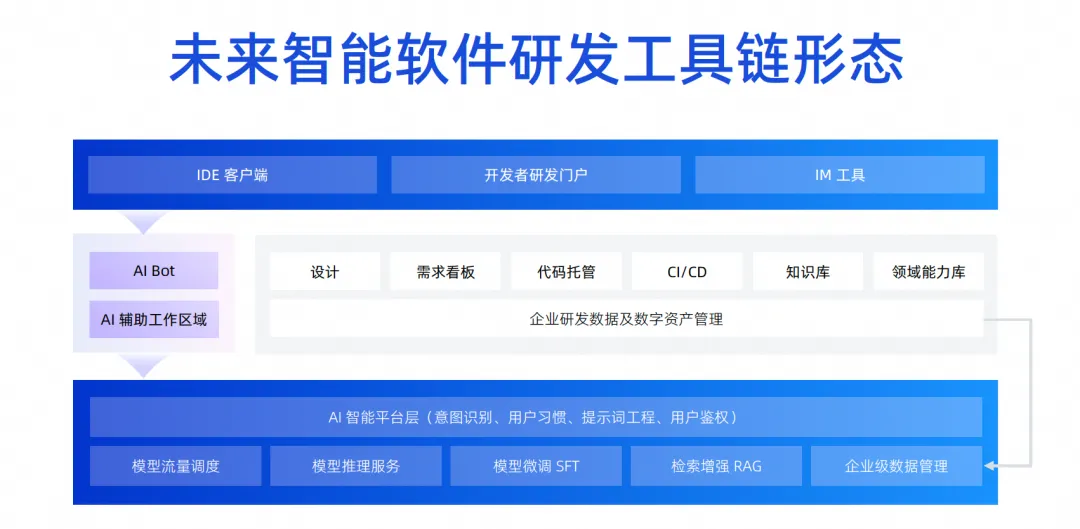
El modo copiloto evoluciona la capa de Agente por encima de la capa de infraestructura. De hecho, la infraestructura se puede reutilizar. La mejora de la recuperación, el perfeccionamiento de la capacitación y la base de conocimientos que se deben realizar se pueden realizar ahora. La clasificación de este conocimiento y la acumulación de activos provienen de la acumulación de la plataforma DevOps original. Ahora puede combinar la capa de capacidad básica actual con toda la cadena de herramientas DevOps a través de algunos proyectos de Word.
Hicimos algunos experimentos en la etapa de requisitos, si queremos que este modelo grande realice el desmontaje automático de un requisito, es posible que solo necesitemos combinar algunos datos de desmontaje anteriores y los requisitos actuales en un mensaje para que el modelo grande se pueda desarmar. y personal mejor asignado. En el experimento se encontró que la precisión de los resultados es bastante alta.
De hecho, toda la cadena de herramientas DevOps no requiere Agent o Copilot para todo. Ahora usamos algunos proyectos de palabras rápidas y hay muchos escenarios que se pueden habilitar de inmediato, incluida la depuración automática en nuestro proceso CICD, preguntas y respuestas inteligentes en el campo de la base de conocimientos, etc.
Después de implementar varios agentes, el agente puede exponerse en el IDE, el portal del desarrollador, la plataforma DevOps o incluso nuestra herramienta de mensajería instantánea. En realidad es una inteligencia antropomórfica. El propio agente tendrá su propio espacio de trabajo. En este espacio de trabajo, nuestros desarrolladores o administradores pueden monitorear cómo nos ayuda a completar la escritura del código, cómo nos ayuda a completar las pruebas y cómo se utiliza en Internet. Complete el trabajo, tendrá su propio espacio de trabajo y, en última instancia, realizará el proceso completo de toda la tarea.
Haga clic aquí para experimentar Tongyi Lingma.
El equipo de la Fundación Google Python fue despedido. Google confirmó los despidos y los equipos involucrados en Flutter, Dart y Python se apresuraron a la lista caliente de GitHub: ¿Cómo pueden ser tan lindos los lenguajes y marcos de programación de código abierto? Xshell 8 abre la prueba beta: admite el protocolo RDP y puede conectarse de forma remota a Windows 10/11 Cuando los pasajeros se conectan al WiFi del tren de alta velocidad , la "maldición de 35 años" de los codificadores chinos aparece cuando se conectan a la alta velocidad. Rail WiFi, la primera herramienta de búsqueda de IA con soporte a largo plazo de la versión 8.4 GA. Perplexica: completamente de código abierto y gratuito, una alternativa de código abierto a Perplexity. Los ejecutivos de Huawei evalúan el valor del código abierto. Hongmeng: todavía tiene su propio sistema operativo a pesar de la continua supresión. por países extranjeros, la empresa alemana de software para automóviles Elektrobit abrió una solución de sistema operativo para automóviles basada en Ubuntu.