
Este artículo se comparte desde la comunidad de la nube de Huawei " Estadísticas y análisis de texto Python desde lo básico hasta lo avanzado " por Lemony Hug.
En la era digital actual, los datos de texto están en todas partes y contienen una gran cantidad de información, desde publicaciones en redes sociales hasta artículos de noticias y artículos académicos. El análisis estadístico es un requisito común para procesar estos datos de texto, y Python, como lenguaje de programación potente y fácil de aprender, nos proporciona una gran cantidad de herramientas y bibliotecas para implementar el análisis estadístico de datos de texto. Este artículo presentará cómo utilizar Python para implementar estadísticas de texto en inglés, incluidas estadísticas de frecuencia de palabras, estadísticas de vocabulario y análisis de opinión del texto.
estadísticas de frecuencia de palabras
El recuento de frecuencia de palabras es una de las tareas más básicas en el análisis de texto. Hay muchas formas de implementar estadísticas de frecuencia de palabras en Python, el siguiente es uno de los métodos básicos:
def count_words(text):
# Eliminar la puntuación del texto y convertirla a
texto en minúsculas = text.lower()
para char in '!"#$%&\'()*+,-./:;<=> ? @[\\]^_`{|}~':
text = text.replace(char, ' ')
# Dividir el texto en una lista de palabras
palabras = text.split()
# Crear un diccionario vacío para almacenar la palabra count
word_count = {}
# Recorre cada palabra y actualiza el recuento en el diccionario
para palabra en palabras:
if word in word_count:
word_count[palabra] += 1
else:
word_count[palabra] = 1
return word_count
#Código de prueba
si __nombre__ == " __main__":
text = "Este es un texto de muestra. Usaremos este texto para contar las apariciones de cada palabra."
word_count = count_words(text)
para palabra, cuenta en word_count.items():
print(f"{palabra } : {contar}")
Este código define una función que acepta una cadena de texto como parámetro y devuelve un diccionario que contiene cada palabra del texto y la cantidad de veces que aparece. Aquí hay un análisis línea por línea del código: count_words(text)
def count_words(text):: Define una función que acepta un parámetro , la cadena de texto a procesar. count_words text
text = text.lower(): convierte cadenas de texto a letras minúsculas, lo que hace que las estadísticas de palabras sean independientes de mayúsculas y minúsculas.
for char in '!"#$%&\'()*+,-./:;<=>?@[\\]^_{|}~':`: Este es un bucle que atraviesa todos los signos de puntuación del texto.
text = text.replace(char, ' '): Reemplaza cada signo de puntuación en el texto con un espacio, lo que elimina el signo de puntuación del texto.
words = text.split(): divide la cadena de texto procesada en una lista de palabras por espacios.
word_count = {}: Crea un diccionario vacío que almacena recuentos de palabras, donde las claves son palabras y los valores son la cantidad de veces que aparece esa palabra en el texto.
for word in words:: recorra en iteración cada palabra de la lista de palabras.
if word in word_count:: Compruebe si la palabra actual ya existe en el diccionario.
word_count[word] += 1: Si la palabra ya existe en el diccionario, agregue 1 al recuento de apariciones.
else:: Si la palabra no está en el diccionario, ejecute el siguiente código.
word_count[word] = 1: Agrega una nueva palabra al diccionario y establece su recuento de apariciones en 1.
return word_count: Devuelve un diccionario que contiene recuentos de palabras.
if __name__ == "__main__":: Compruebe si el script se está ejecutando como programa principal.
text = "This is a sample text. We will use this text to count the occurrences of each word.": Define un texto de prueba.
word_count = count_words(text): Llame a la función, pase el texto de prueba como parámetro y guarde el resultado en una variable. count_words word_count
for word, count in word_count.items():: itera a través de cada par clave-valor en el diccionario. word_count
print(f"{word}: {count}"):Imprime cada palabra y su número de apariciones.
Los resultados de ejecución son los siguientes.
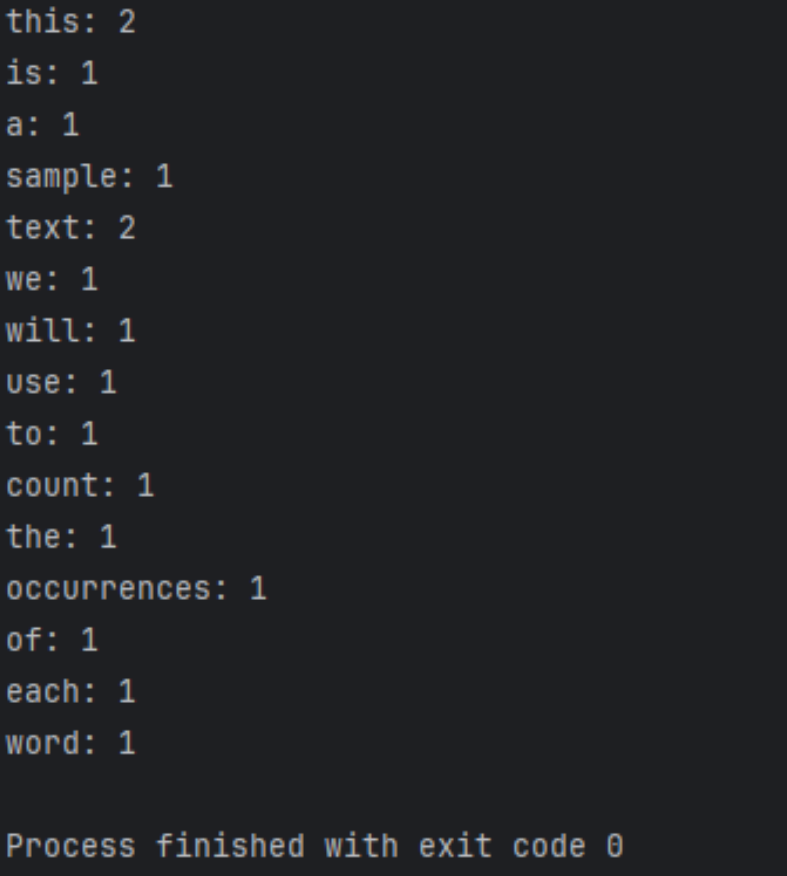
Mayor optimización y expansión
import re
from collections import Counter
def count_words(text):
# Use expresiones regulares para dividir el texto en una lista de palabras (incluidas las palabras con guiones)
palabras = re.findall(r'\b\w+(?:-\w+)* \ b', text.lower())
# Utilice Contador para contar rápidamente el número de apariciones de palabras
word_count = Contador(palabras)
return word_count
# Código de prueba
if __name__ == "__main__":
text = "Este es un texto de muestra. utilizará este texto para contar las apariciones de cada palabra."
word_count = count_words(text)
for word, count in word_count.items():
print(f"{word}: {count}")
Este código difiere del ejemplo anterior en los siguientes aspectos:
- Las expresiones regulares se utilizan para dividir el texto en listas de palabras. Esta expresión regular coincide con palabras, incluidas las palabras con guiones (como "alta tecnología").
re.findall()\b\w+(?:-\w+)*\b - Las clases de la biblioteca estándar de Python se utilizan para contar palabras, lo que es más eficiente y el código es más limpio.
Counter
Esta implementación es más avanzada, más sólida y maneja más casos especiales, como palabras con guiones.
Los resultados de ejecución son los siguientes.
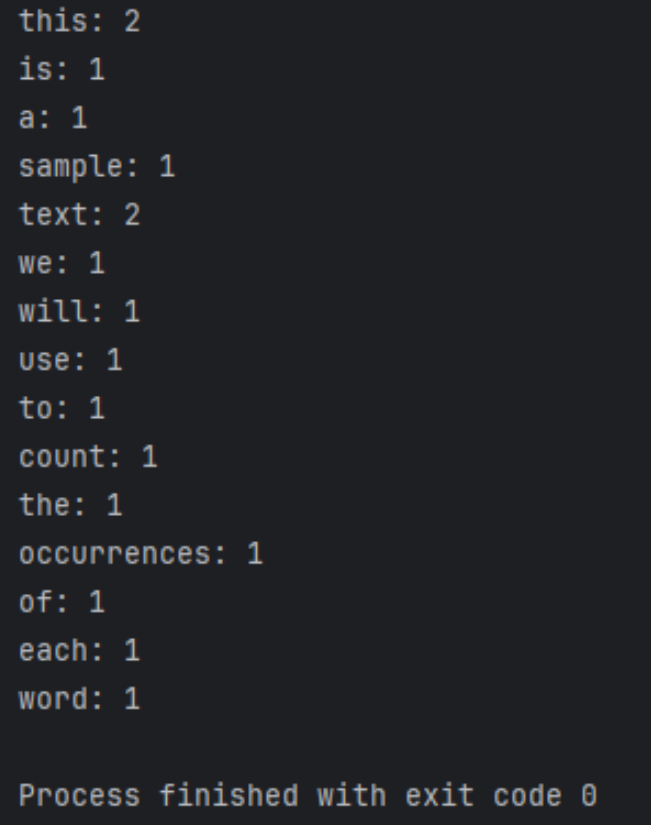
Preprocesamiento de texto
Antes del análisis de texto, generalmente se requiere un preprocesamiento del texto, incluida la eliminación de puntuación, el procesamiento de casos, la lematización y la derivación. Esto puede hacer que los datos de texto sean más estandarizados y precisos.
Utilice modelos más avanzados
Además de los métodos estadísticos básicos, también podemos utilizar modelos de aprendizaje automático y aprendizaje profundo para el análisis de texto, como clasificación de texto, reconocimiento de entidades con nombre y análisis de sentimientos. Hay muchas bibliotecas potentes de aprendizaje automático en Python, como Scikit-learn y TensorFlow, que pueden ayudarnos a construir y entrenar estos modelos.
Manejar datos a gran escala
Cuando nos enfrentamos a datos de texto a gran escala, es posible que debamos considerar tecnologías como el procesamiento paralelo y la computación distribuida para mejorar la eficiencia del procesamiento y reducir los costos informáticos. Existen algunas bibliotecas y marcos en Python que pueden ayudarnos a lograr estas funciones, como Dask y Apache Spark.
Combinar con otras fuentes de datos
Además de los datos de texto, también podemos combinar otras fuentes de datos, como datos de imágenes, datos de series temporales y datos geoespaciales, para realizar análisis más completos y multidimensionales. Hay muchas herramientas de visualización y procesamiento de datos en Python que pueden ayudarnos a procesar y analizar estos datos.
Resumir
Este artículo proporciona una introducción detallada sobre cómo usar Python para implementar estadísticas de texto en inglés, incluidas estadísticas de frecuencia de palabras, estadísticas de vocabulario y análisis de sentimiento de texto. Aquí hay un resumen:
Estadísticas de frecuencia de palabras :
- A través de funciones de Python
count_words(text), se procesa el texto y se cuenta la frecuencia de aparición de palabras. - El preprocesamiento de texto incluye convertir texto a minúsculas, eliminar puntuación, etc.
- Utilice un bucle para iterar sobre las palabras del texto y utilice un diccionario para almacenar las palabras y sus apariciones.
Mayor optimización y expansión :
- Introduzca expresiones y clases regulares
Counterpara que su código sea más eficiente y sólido. - Utilice expresiones regulares para dividir el texto en listas de palabras, incluido el manejo de palabras con guiones.
- El uso de
Counterclases para contar palabras simplifica el código.
Preprocesamiento de texto :
El preprocesamiento de texto es un paso importante en el análisis de texto, incluida la eliminación de puntuación, el procesamiento de casos, la lematización y la derivación, etc., para normalizar los datos del texto.
Utilice modelos más avanzados :
Se presentan las posibilidades de utilizar modelos de aprendizaje automático y aprendizaje profundo para el análisis de texto, como la clasificación de texto, el reconocimiento de entidades con nombre y el análisis de sentimientos.
Manejar datos a gran escala :
Se mencionan consideraciones técnicas al procesar datos de texto a gran escala, incluido el procesamiento paralelo y la computación distribuida para mejorar la eficiencia y reducir costos.
Combinado con otras fuentes de datos :
Se explora la posibilidad de combinar otras fuentes de datos para un análisis más completo y multidimensional, como datos de imágenes, datos de series temporales y datos geoespaciales.
Resumir :
Se enfatiza el contenido presentado en este artículo, así como las perspectivas de trabajo futuro, fomentando una mayor investigación y exploración para adaptarse a tareas de análisis de datos de texto más complejas y diversas.
Al estudiar este artículo, los lectores pueden dominar los métodos básicos del uso de Python para las estadísticas de texto en inglés y comprender cómo optimizar y ampliar aún más estos métodos para hacer frente a tareas de análisis de texto más complejas.
Haga clic para seguir y conocer las nuevas tecnologías de Huawei Cloud lo antes posible ~