
Autor: Ye Jidong del equipo de big data de Internet de vivo
Este artículo presenta principalmente todo el proceso de análisis y solución del problema de desbordamiento de memoria causado por una pérdida de memoria en línea causada por la clase FileSystem.
Definición de pérdida de memoria : un objeto o variable que el programa ya no utiliza todavía ocupa espacio de almacenamiento en la memoria y la JVM no puede recuperar adecuadamente el objeto o variable modificado. Puede que una sola pérdida de memoria no parezca tener un gran impacto, pero la consecuencia de la acumulación de pérdidas de memoria es el desbordamiento de la memoria.
Desbordamiento de memoria (memoria insuficiente) : se refiere a un error en el que el programa no puede continuar ejecutándose debido a un espacio de memoria asignado insuficiente o un uso inadecuado durante la ejecución del programa. En este momento, se informará un error OOM, que es el el llamado desbordamiento de memoria.
1. Antecedentes
Xiaoye estaba matando gente en el Cañón de los Reyes durante el fin de semana, y su teléfono de repente recibió una gran cantidad de alarmas de CPU de la máquina. Si el uso de la CPU excede el 80%, emitirá una alarma. Al mismo tiempo, también recibió una alarma de GC completa. por el servicio. Este servicio es un servicio muy importante para el equipo del proyecto Xiaoye. Xiaoye rápidamente dejó el Honor de los Reyes y encendió la computadora para verificar el problema.


Figura 1.1 Alarma de CPU Alarma de GC completo
2. Descubrimiento de problemas
2.1 Monitoreo y visualización
Debido a que la CPU del servicio y el GC completo son alarmantes, abra el monitoreo del servicio para ver el monitoreo de la CPU y el monitoreo del GC completo. Puede ver que ambos monitores tienen un abultamiento anormal en el mismo momento. Puede ver eso cuando la CPU genera una alarma. La GC completa es particularmente frecuente. Se especula que la alarma de aumento en el uso de la CPU puede deberse a la GC completa .
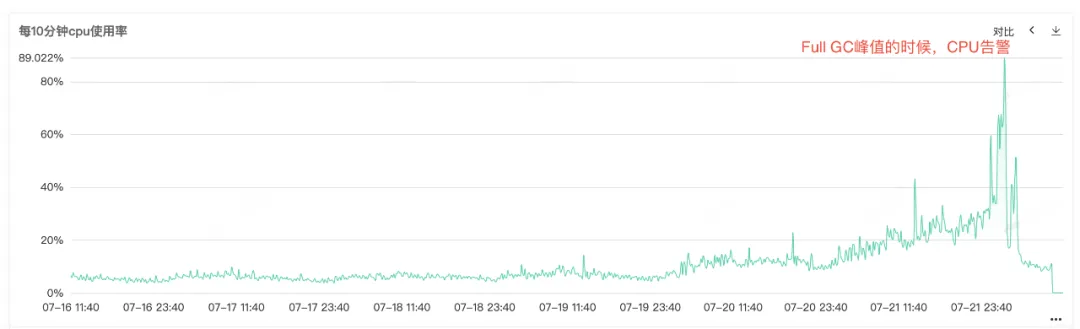
Figura 2.1 Uso de CPU
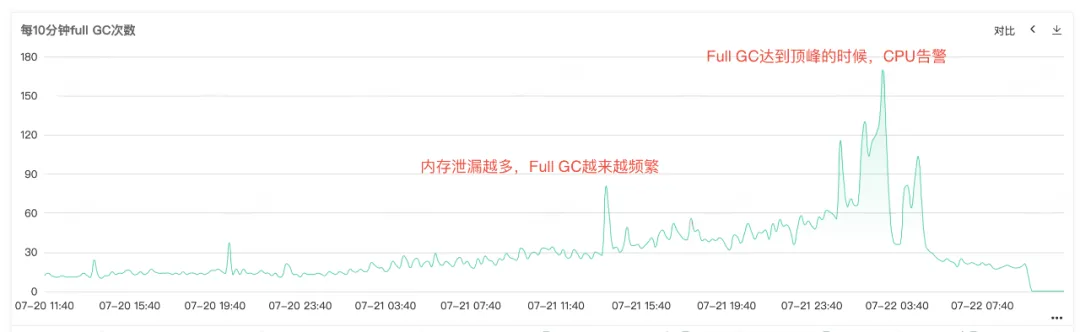
Figura 2.2 Tiempos completos de GC
2.2 Pérdida de memoria
A partir del frecuente Full Gc, podemos saber que debe haber problemas con el reciclaje de memoria del servicio. Por lo tanto, verifique el monitoreo de la memoria del montón, la memoria de generación anterior y la memoria de generación joven del servicio. En la generación anterior, podemos ver que la memoria residente de la generación anterior se hace cada vez más grande. Cada vez más objetos de la generación anterior no se pueden reciclar y, finalmente, toda la memoria residente está ocupada y se puede ver una pérdida de memoria obvia. .
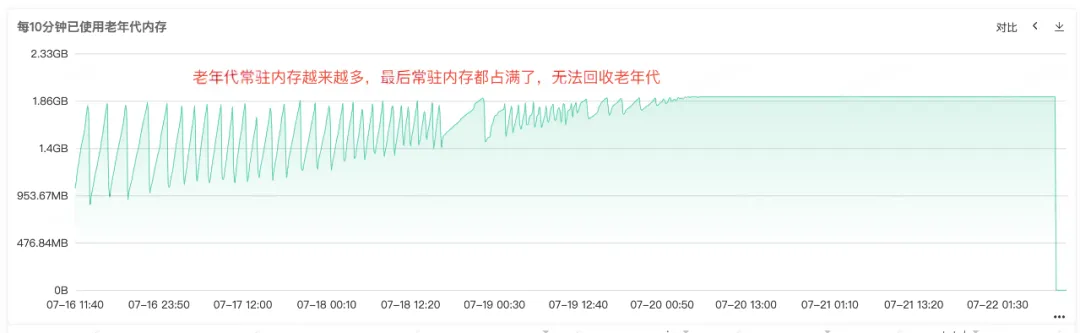
Figura 2.3 Memoria de vieja generación
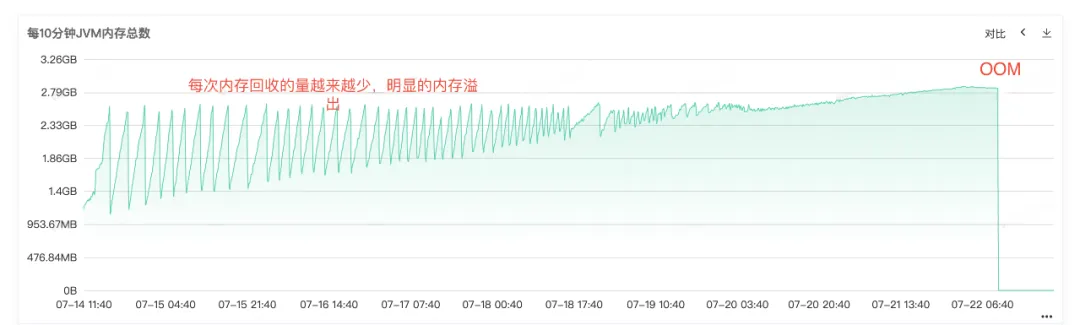
Figura 2.4 Memoria JVM
2.3 Desbordamiento de memoria
A partir del registro de errores en línea, también podemos saber claramente que el servicio terminó siendo OOM, por lo que la causa principal del problema es que la pérdida de memoria provocó que la memoria desbordara OOM y finalmente el servicio dejó de estar disponible .

Figura 2.5 Registro OOM
3. Solución de problemas
3.1 Análisis de memoria de montón
Después de que quedó claro que la causa del problema era una pérdida de memoria, inmediatamente volcamos la instantánea de la memoria del servicio e importamos el archivo de volcado a MAT (Eclipse Memory Analyzer) para su análisis. Sospechosos de fugas Ingrese la vista del punto de fuga sospechosa.
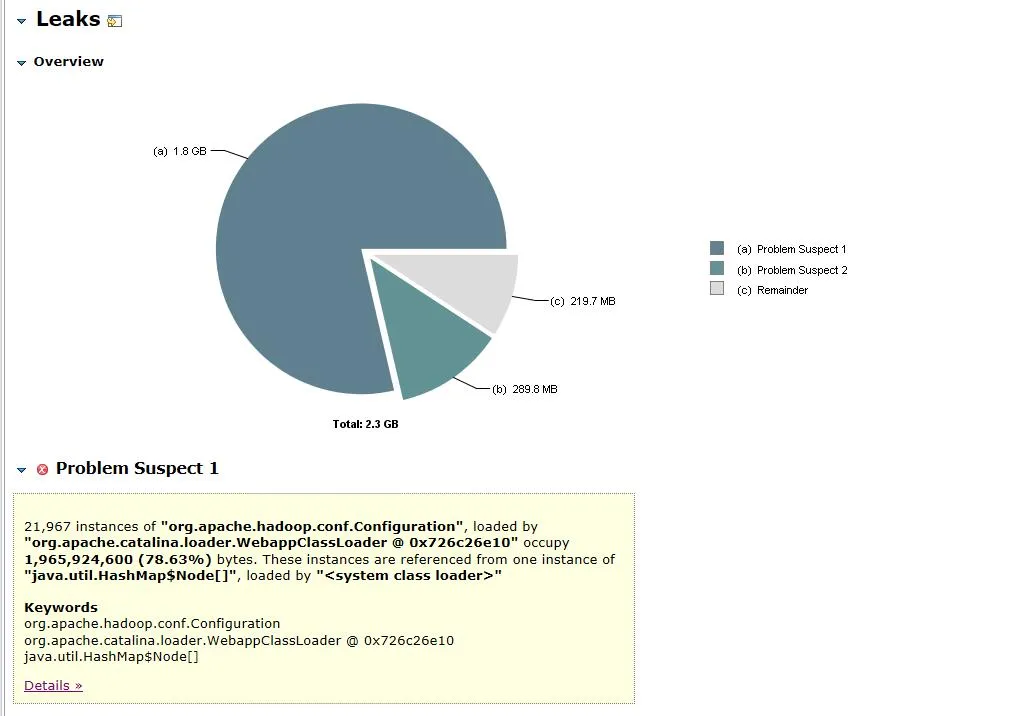
Figura 3.1 Análisis de objetos de memoria
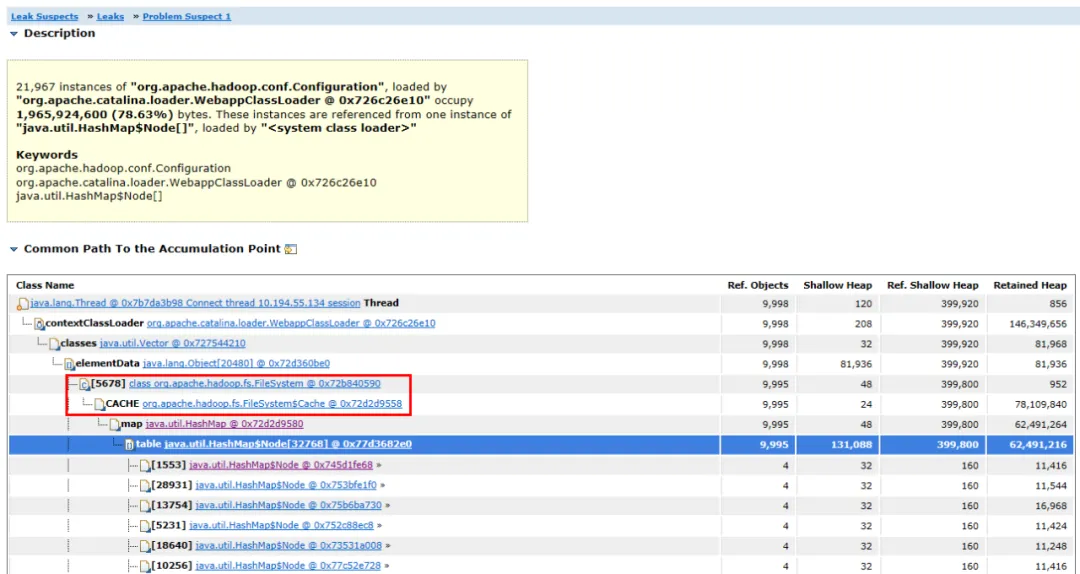
Figura 3.2 Diagrama de enlace de objetos
El archivo de volcado abierto se muestra en la Figura 3.1. El objeto org.apache.hadoop.conf.Configuration ocupa 1,8 G de la memoria del montón de 2,3 G, lo que representa el 78,63% de toda la memoria del montón .
Expanda los objetos asociados y las rutas del objeto, puede ver que el objeto ocupado principal es HashMap . El HashMap está sostenido por el objeto FileSystem.Cache y la capa superior es FileSystem . Se puede suponer que la pérdida de memoria probablemente esté relacionada con FileSystem.
3.2 Análisis del código fuente
Después de encontrar el objeto con pérdida de memoria, el siguiente paso es encontrar el código con pérdida de memoria.
En la Figura 3.3, podemos encontrar dicho fragmento de código en nuestro código. Cada vez que interactúa con hdfs, establecerá una conexión con hdfs y creará un objeto FileSystem. Pero después de usar el objeto FileSystem, no se llamó al método close() para liberar la conexión.
Sin embargo, la instancia de configuración y la instancia del sistema de archivos aquí son variables locales. Una vez ejecutado el método, la JVM debería poder reciclar estos dos objetos.
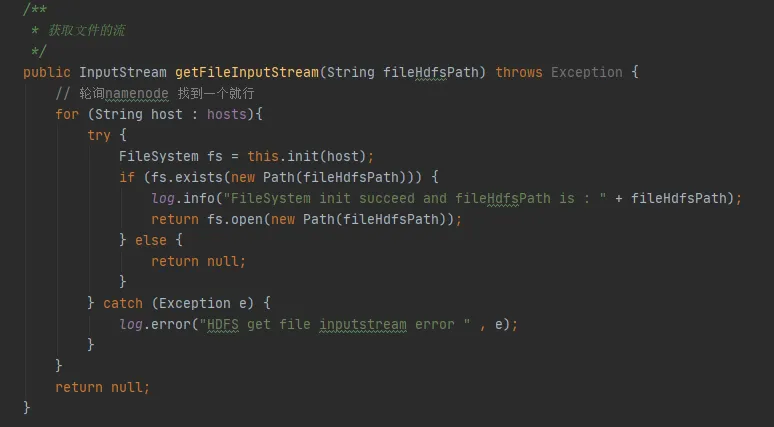
Figura 3.3
(1) Conjetura 1: ¿FileSystem tiene objetos constantes?
A continuación veremos el código fuente de la clase FileSystem. Los métodos init y get de FileSystem son los siguientes:
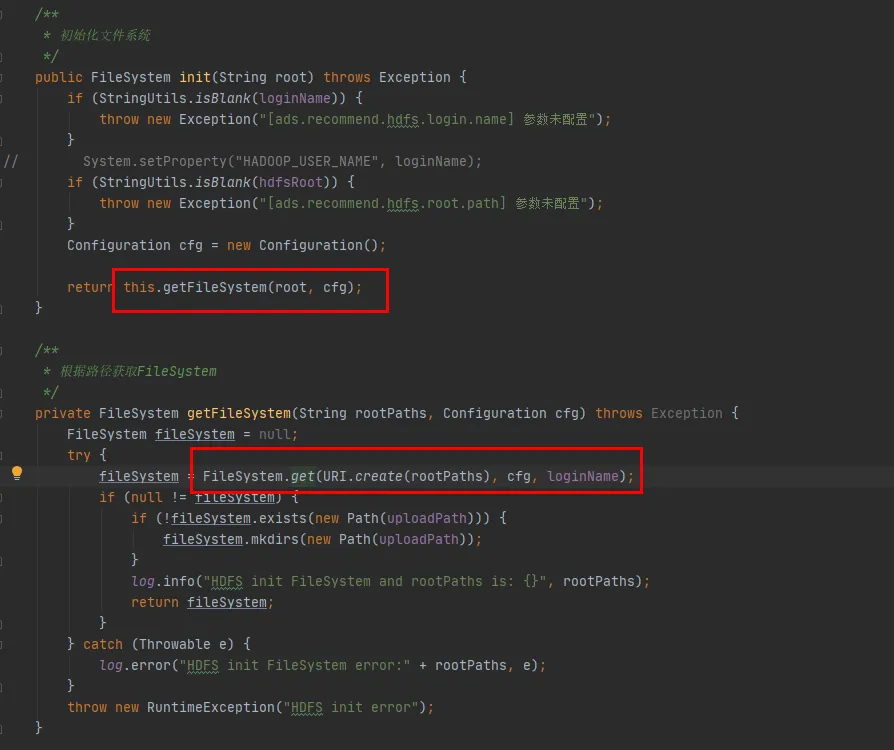

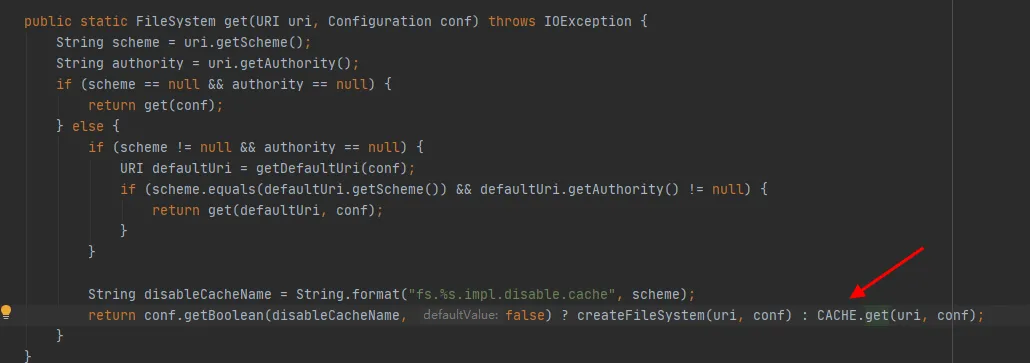
Figura 3.4
Como se puede ver en la última línea de código en la Figura 3.4, hay un CACHE en la clase FileSystem y enableCacheName se usa para controlar si se obtienen objetos del caché . El valor predeterminado de este parámetro es falso. Es decir, FileSystem se devolverá a través del objeto CACHE de forma predeterminada .

Figura 3.5
En la Figura 3.5, podemos ver que CACHE es un objeto estático de la clase FileSystem. En otras palabras, el objeto CACHE siempre existirá y no se reciclará. El objeto constante CACHE existe y la conjetura ha sido verificada.
Luego eche un vistazo al método CACHE.get:
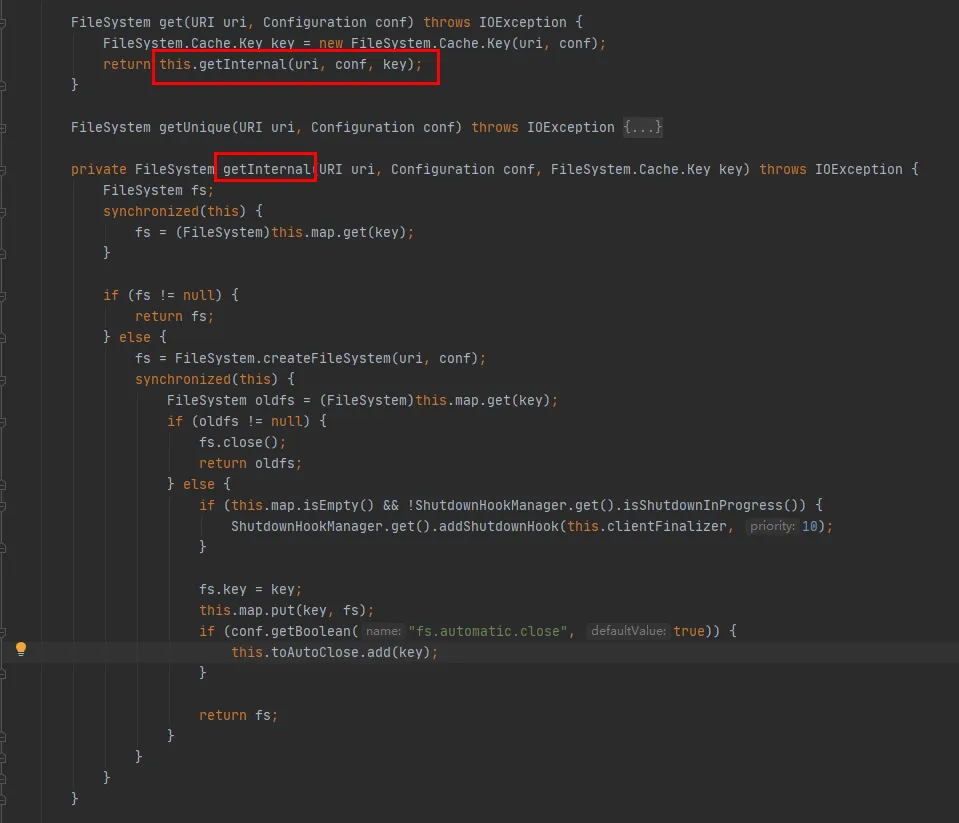
Como se puede ver en este código:
-
Un mapa se mantiene dentro de la clase Cache, que se utiliza para almacenar en caché los objetos FileSystem conectados. La clave del mapa es el objeto Cache.Key. FileSystem se obtendrá a través de Cache.Key cada vez. Si no se obtiene, el proceso de creación continuará.
-
Se mantiene un conjunto (toAutoClose) dentro de la clase Cache, que se utiliza para almacenar conexiones que deben cerrarse automáticamente. Las conexiones de esta colección se cierran automáticamente cuando se cierra el cliente.
-
Cada FileSystem creado se almacenará en el Mapa en la clase Cache con Cache.Key como clave y FileSystem como Valor. En cuanto a si habrá varios cachés para el mismo URI de hdfs durante el almacenamiento en caché, debe verificar el método hashCode de Cache.Key.
El método hashCode de Cache.Key es el siguiente:

Las variables de esquema y autoridad son de tipo Cadena. Si están en el mismo URI, su código hash es coherente. El valor del parámetro único es 0 cada vez. Luego, el código hash de Cache.Key está determinado por ugi.hashCode() .
Del análisis del código anterior, podemos ordenar:
-
Durante la interacción entre el código comercial y HDFS, se creará una conexión FileSystem para cada interacción y la conexión FileSystem no se cerrará al final.
-
FileSystem tiene un caché estático incorporado y hay un mapa dentro del caché para almacenar en caché el sistema de archivos que ha creado una conexión.
-
El parámetro fs.hdfs.impl.disable.cache se utiliza para controlar si FileSystem necesita almacenarse en caché. De forma predeterminada, es falso, lo que significa almacenamiento en caché.
-
Map en Cache, Key es la clase Cache.Key, que determina una clave a través de cuatro parámetros: esquema, autoridad, ugi y único , como se muestra arriba en el método hashCode de Cache.Key.
(2) Conjetura 2: ¿FileSystem almacena en caché el mismo URI de hdfs varias veces?
El constructor FileSystem.Cache.Key es el siguiente: ugi está determinado por getCurrentUser() de UserGroupInformation.

Continúe observando el método getCurrentUser() de UserGroupInformation, de la siguiente manera:

La clave es si el objeto Asunto se puede obtener a través de AccessControlContext. En este ejemplo, cuando se obtiene a través de get (URI URI final, configuración final de configuración, usuario de cadena final), durante la depuración, se descubre que aquí se puede obtener un nuevo objeto Asunto cada vez. En otras palabras, la misma ruta hdfs almacenará en caché un objeto FileSystem cada vez .
Se verificó la conjetura 2: el mismo URI HDFS se almacenará en caché varias veces, lo que provocará que la caché se expanda rápidamente y la caché no establece un tiempo de caducidad ni una política de eliminación, lo que eventualmente provocará un desbordamiento de la memoria.
(3) ¿Por qué FileSystem almacena en caché repetidamente?
Entonces, ¿por qué obtenemos un nuevo objeto Asunto cada vez? Miremos el código para obtener AccessControlContext, de la siguiente manera:
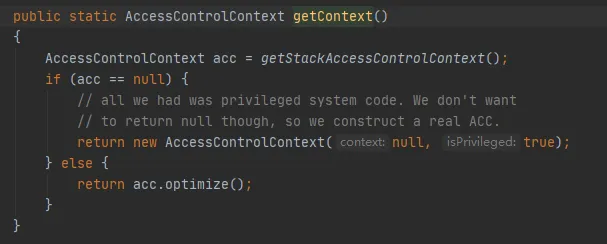
La clave es el método getStackAccessControlContext, que llama al método Native, de la siguiente manera:

Este método devuelve el objeto AccessControlContext de los permisos del dominio de protección de la pila actual.
Podemos verlo a través del método get(final URI uri, final Configuration conf, final String user) en la Figura 3.6 , de la siguiente manera:
-
Primero, se obtiene un objeto UserGroupInformation mediante el método UserGroupInformation.getBestUGI .
-
Luego , se llama al método get(URI uri, Configuration conf) a través del método doAs de UserGroupInformation.
-
Figura 3.7 Implementación del método UserGroupInformation.getBestUGI Aquí, concéntrese en los dos parámetros pasados, ticketCachePath y usuario . ticketCachePath es el valor obtenido al configurar hadoop.security.kerberos.ticket.cache.path. En este ejemplo, este parámetro no está configurado, por lo que ticketCachePath está vacío. El parámetro de usuario es el nombre de usuario pasado en este ejemplo.
-
ticketCachePath está vacío y el usuario no está vacío, por lo que eventualmente se ejecutará el método createRemoteUser de la Figura 3.7.

Figura 3.6

Figura 3.7
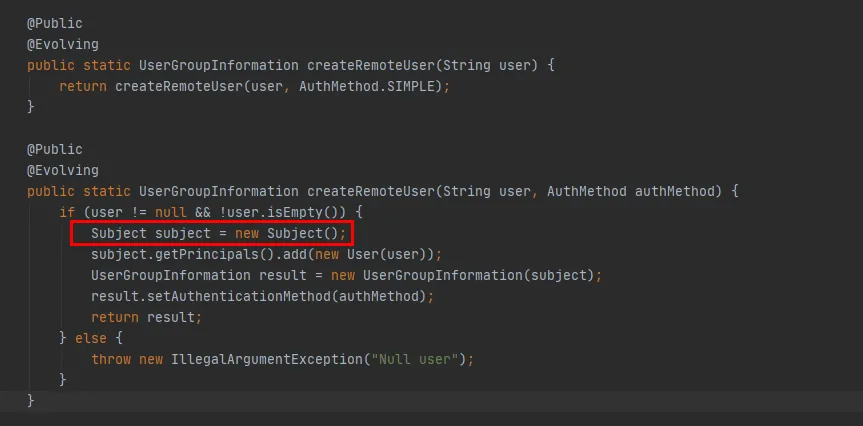
Figura 3.8
En el código rojo en la Figura 3.8, puede ver que en el método createRemoteUser, se crea un nuevo objeto Asunto y el objeto UserGroupInformation se crea a través de este objeto . En este punto, se completa la ejecución del método UserGroupInformation.getBestUGI.
A continuación, eche un vistazo al método UserGroupInformation.doAs (el último método ejecutado por FileSystem.get (URI URI final, configuración de configuración final, usuario de cadena final)), de la siguiente manera:
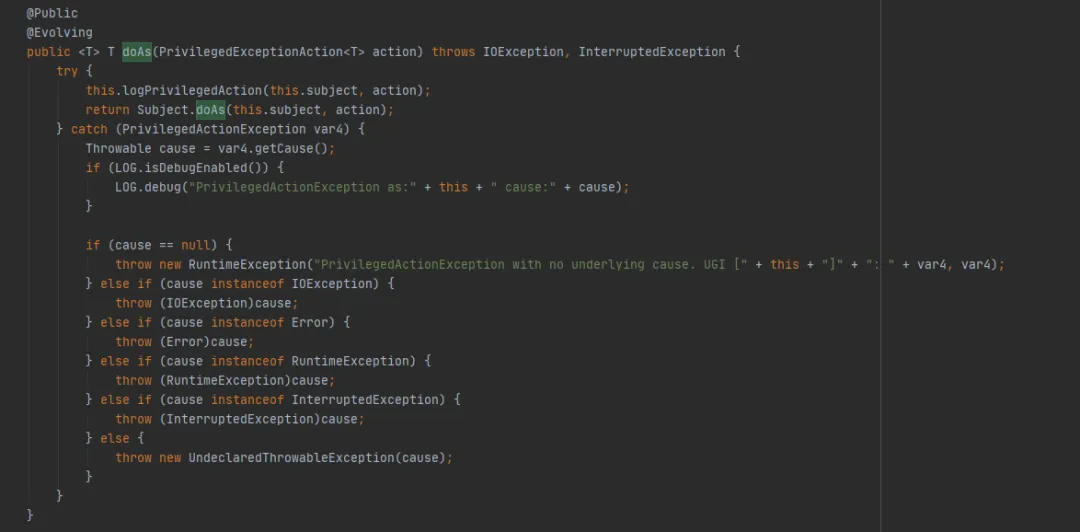
Luego llame al método Subject.doAs de la siguiente manera:
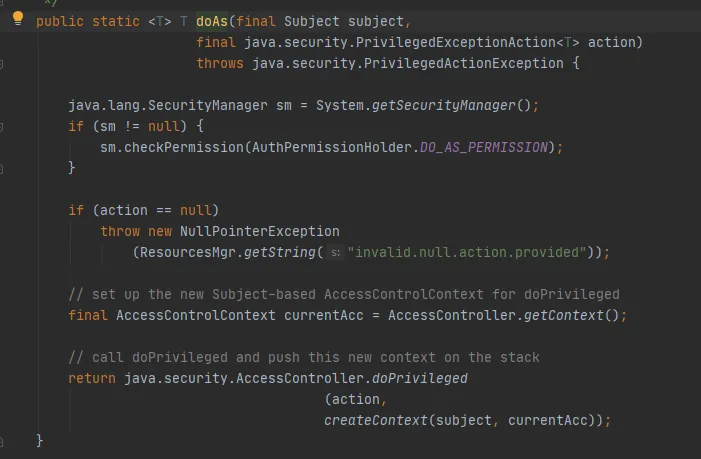
Finalmente, llame al método AccessController.doPrivileged, de la siguiente manera:
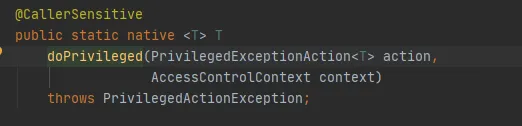
Este método es un método nativo, que utilizará el AccessControlContext especificado para ejecutar PrivilegedExceptionAction, es decir, llamar al método de ejecución de la implementación. Ese es el método FileSystem.get(uri, conf).
En este punto, se puede explicar que en este ejemplo, al crear FileSystem a través del método get (URI final uri, configuración final conf, usuario de cadena final), el código hash de Cache.key almacenado en la caché de FileSystem es inconsistente cada vez. .
Para resumir:
-
Al crear FileSystem a través del método get(final URI uri, final Configuration conf, final String user) , se crearán nuevos objetos UserGroupInformation y Subject cada vez.
-
Cuando el objeto Cache.Key calcula hashCode , lo que afecta el resultado del cálculo es la llamada al método UserGroupInformation.hashCode .
-
Método UserGroupInformation.hashCode, calculado como: System.identityHashCode(subject) . Es decir, si el Asunto es el mismo objeto, se devolverá el mismo código hash. Dado que en este ejemplo es diferente cada vez, el código hash calculado es inconsistente.
-
En resumen, el código hash de Cache.key calculado cada vez es inconsistente y el caché de FileSystem se escribirá repetidamente.
(4) Uso correcto de FileSystem
Del análisis anterior, dado que FileSystem.Cache no desempeña su función, ¿por qué debería diseñarse este caché? De hecho, es sólo que nuestro uso no es correcto.
En FileSystem, hay dos métodos get sobrecargados:
public static FileSystem get(final URI uri, final Configuration conf, final String user)
public static FileSystem get(URI uri, Configuration conf)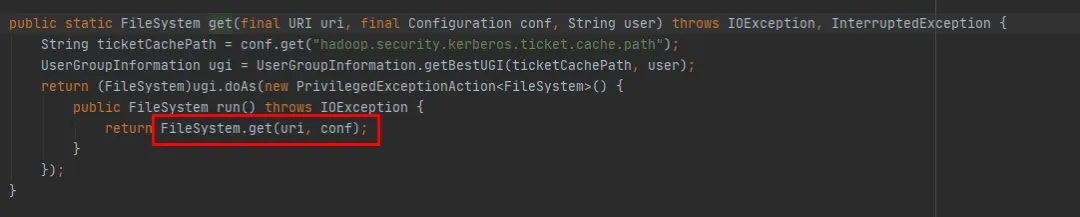
Podemos ver que el método FileSystem get(final URI uri, final Configuration conf, final String user) finalmente llama al método FileSystem get(URI uri, Configuration conf). La diferencia es que el método FileSystem get(URI uri, Configuration conf). Falta. Simplemente le falta la operación de crear un nuevo Asunto cada vez.

Figura 3.9
Si no hay ninguna operación para crear un nuevo Asunto, entonces el Asunto en la Figura 3.9 es nulo y se utilizará el último método getLoginUser para obtener loginUser. LoginUser es una variable estática, por lo que una vez que el objeto loginUser se inicializa correctamente, el objeto se utilizará en el futuro. El método UserGroupInformation.hashCode devolverá el mismo valor de hashCode. Es decir, el caché almacenado en FileSystem se puede utilizar con éxito.

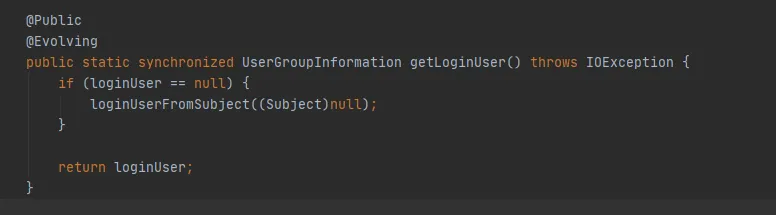
Figura 3.10
4. Solución
Después de la introducción anterior, si queremos solucionar el problema de pérdida de memoria de FileSystem, tenemos los dos métodos siguientes:
(1) Obtener sistema de archivos estático público (URI uri, configuración conf):
-
Este método puede utilizar la caché del sistema de archivos, lo que significa que solo habrá un objeto de conexión del sistema de archivos para el mismo URI de hdfs.
-
Configure el usuario de acceso a través de System.setProperty("HADOOP_USER_NAME", "hive").
-
De forma predeterminada, fs.automatic.close = true, es decir, todas las conexiones se cerrarán mediante ShutdownHook.
(2) Obtener sistema de archivos estático público (URI final URI, configuración final, usuario de cadena final):
-
Como se analizó anteriormente, este método hará que la caché del sistema de archivos deje de ser válida y se agregará al mapa de la caché cada vez, lo que provocará que no se recicle.
-
Al usarlo, una solución es asegurarse de que solo haya un objeto de conexión del sistema de archivos para el mismo URI de hdfs.
-
Otra solución es llamar al método close después de cada uso de FileSystem, lo que eliminará el FileSystem en la caché.
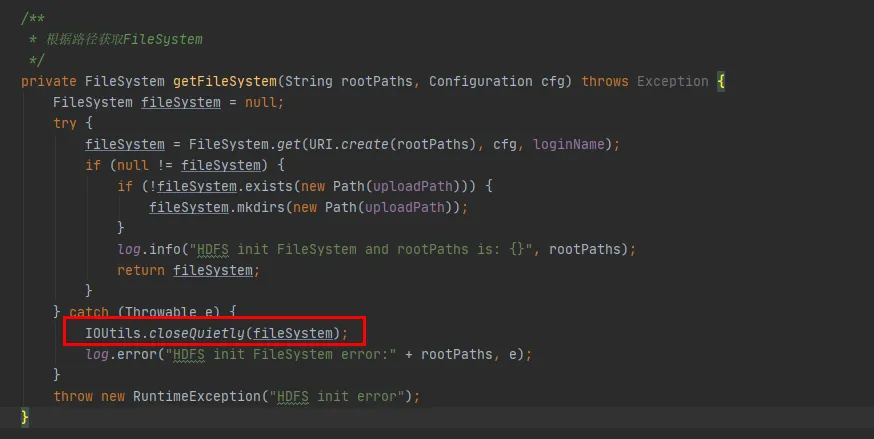
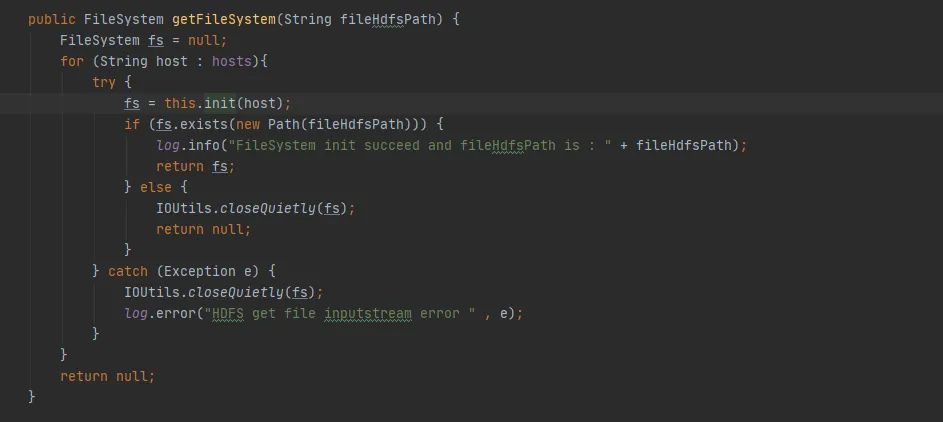
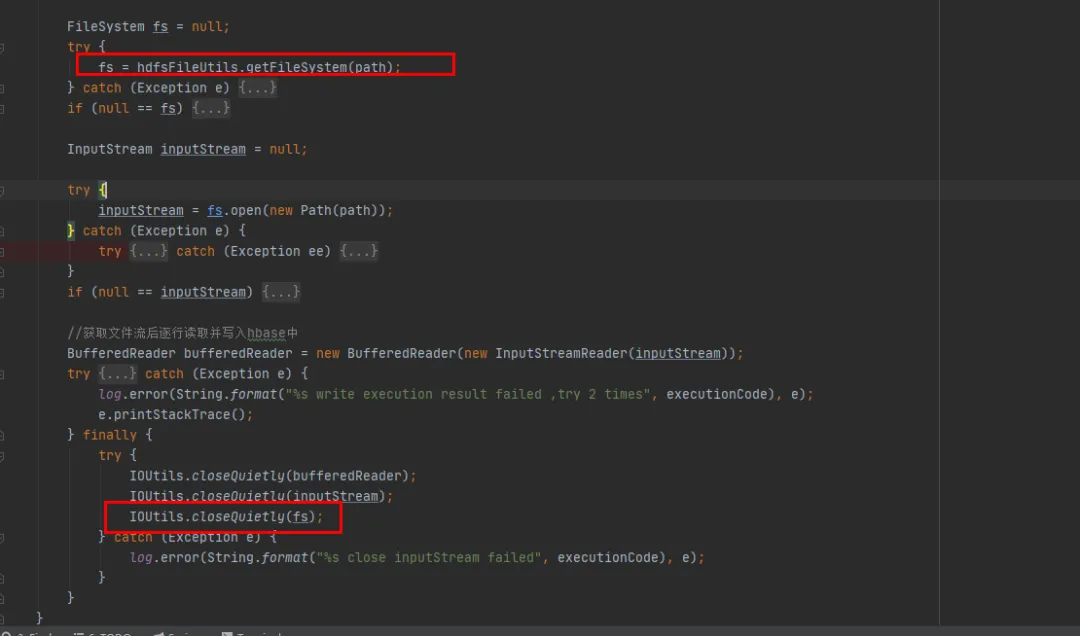
Basándonos en la premisa de cambios mínimos en nuestro código histórico existente, elegimos el segundo método de modificación. Cierre el objeto FileSystem después de cada uso de FileSystem.
5. Resultados de optimización
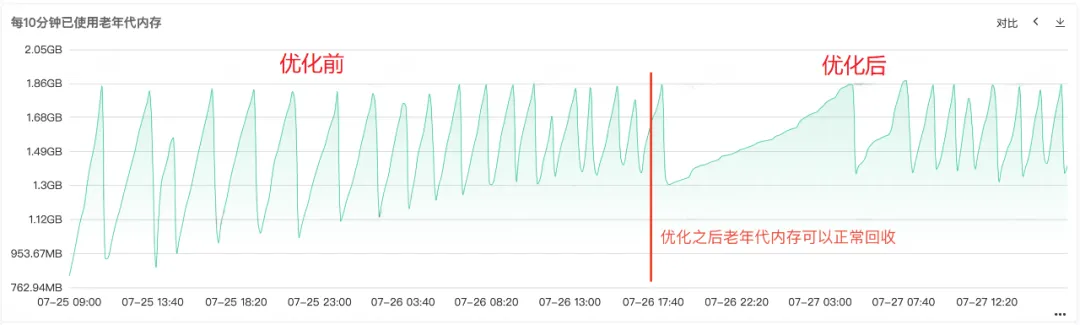
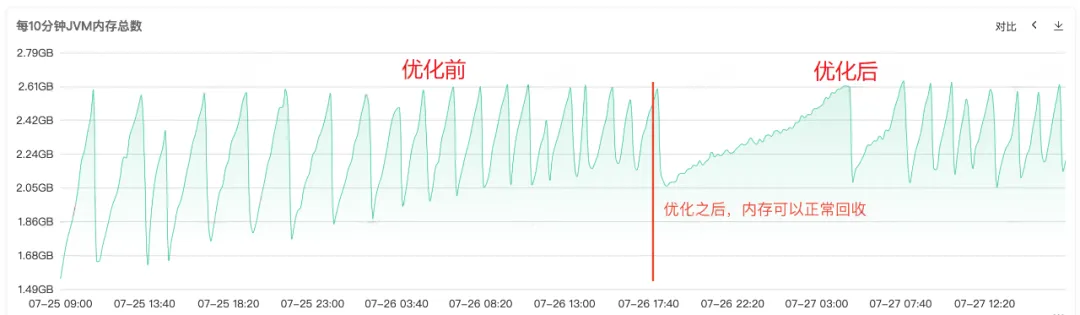
Después de reparar el código y publicarlo en línea, como se muestra en la Figura 1 a continuación, puede ver que la memoria de la generación anterior se puede reciclar normalmente después de la reparación. En este punto, el problema finalmente se resuelve.
6. Resumen
El desbordamiento de memoria es uno de los problemas más comunes en el desarrollo de Java. El motivo suele deberse a pérdidas de memoria que impiden que la memoria se recicle normalmente. En nuestro artículo, presentaremos en detalle un proceso completo de procesamiento de desbordamiento de memoria en línea.
Resuma nuestras soluciones comunes cuando se produce un desbordamiento de memoria:
(1) Generar archivo de memoria dinámica :
Agregue el comando de inicio del servicio
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/baseDeje que el servicio volque automáticamente los archivos de memoria cuando ocurra OOM, o use el comando jam para volcar archivos de memoria.
(2) Análisis de memoria de montón : Utilice herramientas de análisis de memoria para ayudarnos a analizar el problema de desbordamiento de memoria más profundamente y encontrar la causa del desbordamiento de memoria. Las siguientes son varias herramientas de análisis de memoria de uso común:
-
Eclipse Memory Analyzer : una herramienta de análisis de memoria Java de código abierto que puede ayudarnos a localizar rápidamente pérdidas de memoria.
-
VisualVM Memory Analyzer : Una herramienta basada en una interfaz gráfica que puede ayudarnos a analizar el uso de memoria de las aplicaciones java.
(3) Localice el código de pérdida de memoria específico según el análisis de la memoria del montón.
(4) Modifique el código de pérdida de memoria y vuelva a publicarlo para su verificación.
Las pérdidas de memoria son una causa común de desbordamiento de memoria, pero no son la única causa. Las causas comunes de los problemas de desbordamiento de memoria incluyen: objetos de gran tamaño, asignación de memoria de montón demasiado pequeña, llamadas de bucle infinito , etc., que pueden provocar problemas de desbordamiento de memoria.
Cuando nos encontramos con problemas de desbordamiento de memoria, debemos pensar en muchos aspectos y analizar el problema desde diferentes ángulos. A través de los métodos y herramientas que mencionamos anteriormente y varios monitoreos, podemos ayudarnos a localizar y resolver problemas rápidamente y mejorar la estabilidad y disponibilidad de nuestro sistema.
Un programador nacido en los años 90 desarrolló un software de portabilidad de vídeo y ganó más de 7 millones en menos de un año. ¡El final fue muy duro! Los estudiantes de secundaria crean su propio lenguaje de programación de código abierto como una ceremonia de mayoría de edad: comentarios agudos de los internautas: debido al fraude desenfrenado, confiando en RustDesk, el servicio doméstico Taobao (taobao.com) suspendió los servicios domésticos y reinició el trabajo de optimización de la versión web Java 17 es la versión Java LTS más utilizada. Cuota de mercado de Windows 10. Alcanzando el 70%, Windows 11 continúa disminuyendo. Open Source Daily | Google apoya a Hongmeng para hacerse cargo de los teléfonos Android de código abierto respaldados por Docker; Electric cierra la plataforma abierta Apple lanza el chip M4 Google elimina el kernel universal de Android (ACK) Soporte para la arquitectura RISC-V Yunfeng renunció a Alibaba y planea producir juegos independientes en la plataforma Windows en el futuro