
Los índices de bases de datos son un componente clave para optimizar el rendimiento de cualquier sistema de base de datos. Sin índices efectivos, las consultas de su base de datos pueden volverse lentas e ineficientes, lo que resulta en una experiencia de usuario deficiente y una productividad reducida. En este artículo, exploraremos algunas de las mejores prácticas para crear y utilizar índices de bases de datos.
Autor: El sendero de Java
Fuente de este artículo y portada: https://medium.com/, traducido por la comunidad de código abierto de Axon.
Este artículo tiene aproximadamente 2700 palabras y se espera que su lectura demore 9 minutos.
En las bases de datos se utilizan varios algoritmos de indexación para mejorar el rendimiento de las consultas. Estos son algunos de los algoritmos de indexación más utilizados:
Índice de árbol B
Un índice B-Tree es una estructura de datos de árbol autoequilibrada que mantiene el orden de los datos y permite búsquedas, acceso secuencial, inserciones y eliminaciones en tiempo logarítmico. La estructura de índice B-Tree se usa ampliamente en bases de datos y sistemas de archivos. Los índices B-Tree se utilizan ampliamente en bases de datos relacionales como MySQL y PostgreSQL.
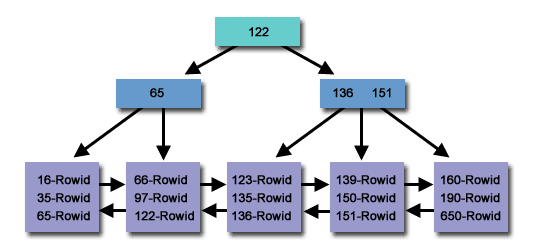
Los índices B-Tree están optimizados para consultas de rango porque pueden encontrar de manera eficiente todos los registros dentro de un rango de valores. Esto se debe a que los registros se almacenan ordenados en el índice. Aproveche el uso de comparaciones de columnas en expresiones que utilizan los operadores =, >, >=, <u .<=BETWEEN
Por ejemplo, supongamos que tenemos una tabla de productos con la siguiente estructura de tabla:
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255),
price DECIMAL(10,2)
);
pricePodemos agregar un índice B-Tree al campo mediante la siguiente declaración SQL .
CREATE INDEX products_price_index ON products (price);
índice hash
Los índices hash son otro algoritmo de indexación popular que se utiliza para acelerar las consultas. Los índices hash utilizan una función hash para asignar claves a ubicaciones de índice. Este algoritmo de indexación es más útil para consultas de coincidencia exacta, como la búsqueda de registros específicos basados en valores de clave principal . Los índices hash se utilizan comúnmente en bases de datos en memoria como Redis.
Los índices hash funcionan asignando cada registro de la tabla a un depósito único en función de su valor hash. Los valores hash se calculan utilizando una función hash, una función matemática que toma un elemento de datos como entrada y devuelve un valor entero único.
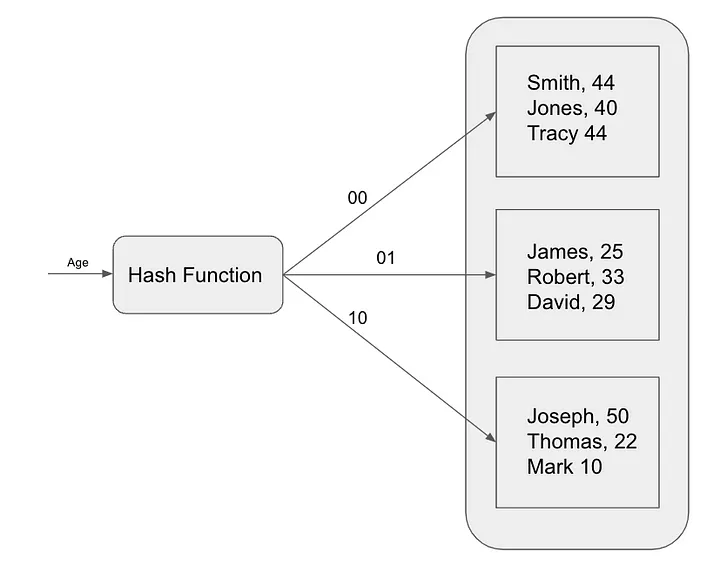
Para encontrar un registro en un índice hash, la base de datos calcula el hash de la clave de búsqueda y luego busca el depósito correspondiente. Si el registro está en el depósito, la base de datos devolverá el registro. De lo contrario, la base de datos realiza un escaneo completo de la tabla.
Los índices hash son muy rápidos para realizar búsquedas , pero no se pueden utilizar para consultar rangos de datos de manera eficiente . Esto se debe a que las funciones hash no conservan ningún orden entre los registros de la tabla.
Para ejecutar una consulta utilizando un índice hash:
- La base de datos calcula el valor hash de los criterios de consulta.
- Busque el depósito hash correspondiente en la tabla hash.
- Luego, la base de datos recupera un puntero a la fila de la tabla con el valor hash correspondiente.
- Utilice estos punteros para recuperar las filas reales de la tabla.
Supongamos que tenemos una tabla de productos con la siguiente estructura de tabla:
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255),
price DECIMAL(10,2)
);
P: ¿Los índices hash no están optimizados como B-Tree?
Hay algunas situaciones en las que un índice hash puede no ser la mejor opción:
- Los índices hash son más rápidos que los índices de árbol para búsquedas (para comparaciones de igualdad usando el operador
=o<=>), pero no se pueden usar para consultar rangos de datos de manera eficiente. - Los índices de árbol son más lentos que los índices hash al realizar búsquedas, pero se pueden utilizar para consultar rangos de datos de manera eficiente.
Consultas de rango: los índices hash no están optimizados para consultas de rango, donde es necesario buscar registros dentro de un rango de valores (usando los operadores =, >, >=, <u ). En este caso, un índice B-Tree sería más apropiado.<=BETWEEN
Clasificación: los índices hash no están optimizados para la clasificación, es necesario ordenar los registros según una columna específica. En este caso, sería más adecuado un índice B-Tree o un índice agrupado.
Conjuntos de datos grandes: los índices hash pueden consumir mucha memoria, por lo que pueden no ser adecuados para conjuntos de datos grandes donde el uso de la memoria es una preocupación.
Podemos namecrear un índice hash en la columna usando el siguiente comando:
CREATE INDEX products_name_hash ON products (name);
SELECT * FROM products WHERE name = 'iPhone 13 Pro';
CREATE INDEX products_name_tree ON products (name);
SELECT * FROM products WHERE name = 'iPhone 13 Pro';
Si utilizamos un índice hash, la base de datos calculará el valor hash de la clave de búsqueda "iPhone 13 Pro" y luego buscará el depósito correspondiente. Debido a que las funciones hash son deterministas, la base de datos siempre encontrará registros en el mismo depósito, independientemente del orden en que se almacenen los registros en la tabla.
Si utilizamos un índice de árbol, la base de datos comenzará en la raíz del árbol y comparará la clave de búsqueda "iPhone 13 Pro" con el valor de la clave almacenada en la raíz . Dado que el árbol está ordenado, la base de datos encontrará rápidamente el registro que contiene la clave de búsqueda.
P: ¿Por qué B-Tree está más optimizado para consultas de rango que el índice Hash?
Ahora, digamos que queremos encontrar todos los productos con un precio entre $100 y $200. Podemos utilizar la siguiente consulta:
SELECT * FROM products WHERE price BETWEEN 100 AND 200;
principio de funcionamiento
Árbol B
Los índices B-Tree funcionan almacenando registros en orden. Para buscar registros en un índice de árbol B,
- La base de datos comienza en la raíz del árbol y compara la clave de búsqueda con el valor de la clave almacenada en la raíz.
- Si la clave de búsqueda es igual a la clave raíz, la base de datos devuelve ese registro.
- De lo contrario, la base de datos determina qué subárbol buscar a continuación en función de los resultados de la comparación.
Picadillo
Los índices hash funcionan asignando cada registro de una tabla a un depósito único en función de su valor hash. El valor hash se calcula utilizando una función hash. Los índices hash distribuyen datos aleatoriamente entre depósitos, lo que hace que las consultas de rango sean ineficientes. Recuperar un rango de valores, como precios entre $100 y $200, requiere escanear todos los depósitos en ese rango, lo que efectivamente da como resultado un escaneo completo de la tabla. Los índices hash son buenos para realizar búsquedas rápidas de coincidencias exactas, pero carecen del ordenamiento de datos necesario para consultas de rango eficientes.
Pregunta, ¿por qué el índice B-Tree está más optimizado que el índice Hash en la clasificación?
Los índices de árbol B-Tree clasifican los datos de manera más eficiente que los índices hash porque almacenan registros en orden. Esto permite que la base de datos repita rápidamente los registros en orden.
Los índices hash funcionan asignando cada registro de una tabla a un depósito único en función de su valor hash. Esto significa que el orden de los registros en el depósito es aleatorio. Para ordenar los registros, la base de datos debe recorrer todos los depósitos y luego ordenar los registros en cada depósito. Esto es más lento que usar un índice B-Tree, que almacena registros ordenados.
Podemos pricecrear un índice B-Tree en la columna usando el siguiente comando:
CREATE INDEX products_price_index ON products (price);
Ahora, digamos que queremos ordenar los productos por precio en orden ascendente. Podemos utilizar la siguiente consulta:
SELECT * FROM products ORDER BY price ASC;
La base de datos utilizará un índice de árbol B para iterar rápidamente sobre los productos en orden.
Desventajas del índice hash:
- Los índices hash no admiten consultas de rango ni clasificación
- Los índices hash consumen mucha memoria.
- Los índices hash no son adecuados para bases de datos que se actualizan con frecuencia
índice de mapa de bits
Los índices de mapa de bits se utilizan para columnas con una pequeña cantidad de valores distintos, como columnas booleanas o de género. Los índices de mapa de bits son muy compactos y eficientes para columnas de cardinalidad más baja.
SELECT * FROM employees WHERE gender = 'Female';
Los índices de mapa de bits son muy eficientes en columnas de cardinalidad inferior, lo que permite operaciones de configuración rápida, como uniones e intersecciones. Ideal para informes ad hoc y almacenamiento de datos.
Índice de texto completo
La indexación de texto completo se utiliza para indexar grandes cantidades de datos de texto, como documentos o páginas web. Este algoritmo de indexación divide el texto en palabras o tokens y los indexa de manera que permite operaciones de búsqueda eficientes. Los índices de texto completo son más útiles para consultas que implican la búsqueda de palabras o frases específicas en el texto. La indexación de texto completo se utiliza habitualmente en motores de búsqueda como Elasticsearch.
Casos de uso para la indexación de texto completo de comercio electrónico:
La indexación de texto completo permite que las aplicaciones de comercio electrónico busquen rápidamente grandes catálogos de productos basándose en consultas de búsqueda ingresadas por el usuario. La indexación de texto completo permite realizar búsquedas basadas en múltiples palabras y frases, incluidos errores ortográficos, sinónimos e incluso conceptos relacionados. Esto hace que sea más fácil para los usuarios encontrar lo que buscan, incluso si no saben el nombre o la descripción exactos del producto.
Por ejemplo, imagine que un cliente busca un nuevo par de zapatillas para correr. Escriben "zapatillas para correr" en la barra de búsqueda. Con la indexación de texto completo, las aplicaciones de comercio electrónico pueden buscar rápidamente todas las descripciones, nombres y etiquetas de productos para encontrar todos los productos relacionados con zapatillas para correr. Los resultados de la búsqueda se ordenan por relevancia, que está determinada por la frecuencia con la que aparecen los términos de búsqueda en la información del producto.
Sin indexación de texto completo, una búsqueda solo puede centrarse en el nombre del producto, sin tener en cuenta otros factores que puedan ser relevantes para los clientes, como las descripciones o etiquetas del producto. Además, es posible que la búsqueda no admita errores ortográficos ni conceptos relacionados, como "zapatillas para correr" o "zapatillas deportivas".
Supongamos que tenemos una productstabla nombrada con las siguientes columnas: id, y .namedescriptiontags
CREATE FULLTEXT INDEX products_ft_index ON products(name, description, tags);
Ahora, imagine que un cliente busca "zapatillas para correr". Podemos utilizar la siguiente consulta para buscar productos relacionados con el término de búsqueda:
SELECT id, name, description, MATCH(name, description, tags) AGAINST('running shoes') as relevance
FROM products
WHERE MATCH(name, description, tags) AGAINST('running shoes' IN BOOLEAN MODE)
ORDER BY relevance DESC
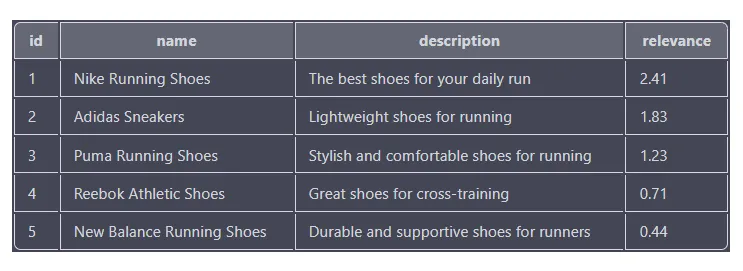
Las puntuaciones de relevancia se basan en qué tan bien coincide cada producto con los términos de búsqueda; las puntuaciones más altas indican una coincidencia más cercana. Los resultados se ordenan en orden descendente según la puntuación de relevancia, de modo que el producto con la puntuación de relevancia más alta (zapatillas Nike para correr) aparece en la parte superior de la lista.
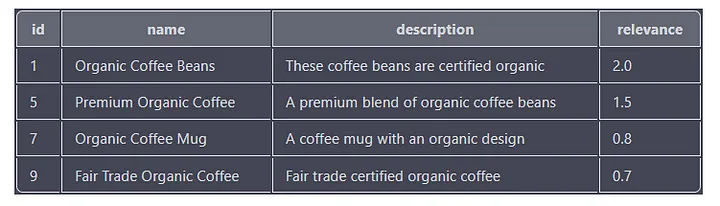
Aquí hay otro ejemplo de consulta que busca productos que contienen las palabras "orgánico" y "café":
SELECT id, name, description, MATCH(name, description, tags) AGAINST('+"organic" +"coffee"') as relevance
FROM products
WHERE MATCH(name, description, tags) AGAINST('+"organic" +"coffee"' IN BOOLEAN MODE)
ORDER BY relevance DESC;
Esta consulta busca todos los productos que tengan las palabras clave "orgánico" y "café" en las columnas de nombre, descripción o etiqueta. La puntuación de relevancia de cada resultado también se calcula en función del número de veces y la posición de la palabra clave en la columna.
El resultado contendrá las columnas "id", "nombre", "descripción" y "relevancia", con los resultados ordenados por la columna "relevancia" en orden descendente.
ventaja
- Los índices de texto completo funcionan muy bien para columnas basadas en texto
- Ideal para motores de búsqueda y sistemas de gestión de contenidos.
- Admite la clasificación por relevancia de los resultados de búsqueda
defecto
- La indexación de texto completo ocupa mucho espacio de almacenamiento
- Para conjuntos de datos muy grandes, el rendimiento puede degradarse
- La indexación de texto completo no es adecuada para datos numéricos o categóricos.
Para obtener más artículos técnicos, visite: https://opensource.actionsky.com/
Acerca de SQLE
SQLE es una plataforma integral de gestión de calidad de SQL que cubre la auditoría y gestión de SQL desde los entornos de desarrollo hasta los de producción. Admite bases de datos nacionales, comerciales y de código abierto convencionales, proporciona capacidades de automatización de procesos para el desarrollo, operación y mantenimiento, mejora la eficiencia en línea y mejora la calidad de los datos.
obtener SQLE
| tipo | DIRECCIÓN |
|---|---|
| Repositorio | https://github.com/actiontech/sqle |
| documento | https://actiontech.github.io/sqle-docs/ |
| noticias de lanzamiento | https://github.com/actiontech/sqle/releases |
| Documentación de desarrollo del complemento de auditoría de datos | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |