

Con la exploración en profundidad de aplicaciones de modelos a gran escala, la tecnología de recuperación de generación aumentada ha recibido amplia atención y se ha aplicado en varios escenarios, como preguntas y respuestas de bases de conocimientos, asesores legales, asistentes de aprendizaje, robots de sitios web, etc.
Sin embargo, muchos amigos no tienen clara la relación y los principios técnicos de las bases de datos vectoriales y RAG. Este artículo le brindará una comprensión profunda de la nueva base de datos vectorial en la era RAG.
01.
La amplia gama de aplicaciones de RAG y sus ventajas únicas
Un marco RAG típico se puede dividir en dos partes: Recuperador y Generador. El proceso de recuperación incluye segmentación de datos (como Documentos), incrustación de vectores (Incrustación) y creación de índices (Vectores de fragmentos), y luego los resultados relevantes se recuperan mediante la recuperación de vectores. Y el proceso de generación utiliza un mensaje mejorado en función de los resultados de recuperación (Contexto) para activar LLM para generar respuestas (Resultado).
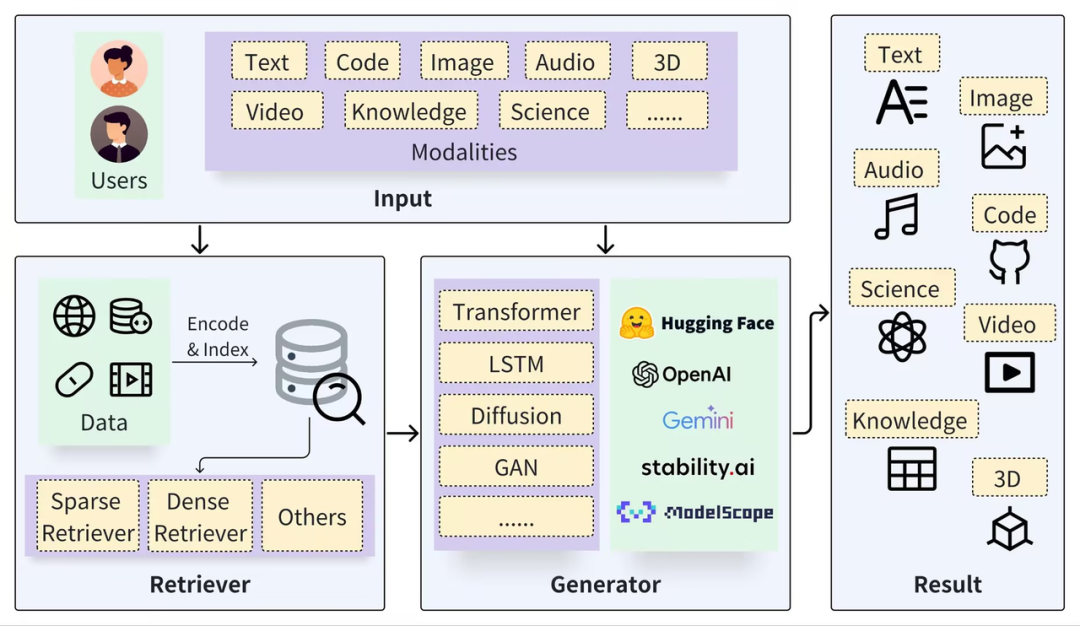
https://arxiv.org/pdf/2402.19473
La clave de la tecnología RAG es que combina lo mejor de ambos enfoques: un sistema de recuperación que proporciona hechos y datos específicos y relevantes, y un modelo generativo que construye respuestas de manera flexible e incorpora contexto e información más amplios. Esta combinación hace que el modelo RAG sea muy eficaz para procesar consultas complejas y generar respuestas ricas en información, lo cual es muy útil en sistemas de respuesta a preguntas, sistemas de diálogo y otras aplicaciones que requieren comprensión y generación de lenguaje natural. En comparación con los modelos nativos a gran escala, la combinación con RAG puede generar ventajas complementarias naturales:
Evite problemas de "alucinaciones": RAG ayuda a los modelos grandes a responder preguntas recuperando información externa como entrada. Este método puede reducir significativamente las preguntas sobre información generada inexacta y aumentar la trazabilidad de las respuestas.
Privacidad y seguridad de los datos: RAG puede utilizar la base de conocimientos como un archivo adjunto externo para gestionar los datos privados de una empresa o institución para evitar que los datos se filtren de manera incontrolable después del aprendizaje del modelo.
Naturaleza de la información en tiempo real: RAG permite la recuperación de información en tiempo real de fuentes de datos externas, de modo que se puedan obtener los conocimientos más recientes y específicos del dominio y se pueda resolver el problema de la puntualidad del conocimiento.
Aunque la investigación de vanguardia sobre modelos a gran escala también se dedica a resolver los problemas anteriores, como el ajuste basado en datos privados y la mejora de las capacidades de procesamiento de textos largos del modelo en sí, estos estudios ayudan a promover el avance de los modelos a gran escala. tecnología de modelos a escala. Sin embargo, en escenarios más generales, RAG sigue siendo una opción estable, confiable y rentable, principalmente porque RAG tiene las siguientes ventajas:
Modelo de caja blanca : en comparación con el efecto de "caja negra" del ajuste fino y el procesamiento de texto largo, la relación entre los módulos RAG es más clara y estrecha, lo que proporciona una mayor operabilidad e interpretabilidad en el ajuste de efectos, además, cuando la calidad y la confianza; (La certeza) del contenido recuperado y recuperado no es alta, el sistema RAG puede incluso prohibir la intervención de los LLM y responder directamente "no sé" en lugar de inventar tonterías.
Costo y velocidad de respuesta: RAG tiene las ventajas de un tiempo de entrenamiento corto y un costo bajo en comparación con los modelos ajustados, en comparación con el procesamiento de texto largo, tiene una velocidad de respuesta más rápida y un costo de inferencia mucho menor; En la etapa de investigación y experimentación, el efecto y la precisión son los más atractivos, pero en términos de industria e implementación industrial, el costo es un factor decisivo que no se puede ignorar;
Gestión de datos privados: al desacoplar la base de conocimientos de los modelos grandes, RAG no solo proporciona una base práctica segura e implementable, sino que también puede gestionar mejor el conocimiento nuevo y existente de la empresa y resolver el problema de la dependencia del conocimiento. Otro ángulo relacionado es el control de acceso y la gestión de datos, lo cual es fácil de hacer para la base de datos base de RAG, pero difícil para modelos grandes.
Por tanto, en mi opinión, a medida que se siga profundizando la investigación sobre modelos a gran escala, la tecnología RAG no será reemplazada, al contrario, mantendrá una posición importante durante mucho tiempo. Esto se debe principalmente a su complementariedad natural con LLM, que permite que las aplicaciones creadas en RAG brillen en muchos campos. La clave para mejorar RAG es, por un lado, la mejora de las capacidades de LLM y, por otro lado, se basa en diversas mejoras y optimizaciones de la recuperación (Recuperación).
02.
La base de las búsquedas RAG: bases de datos vectoriales
En la práctica industrial, la recuperación de RAG suele estar estrechamente integrada con las bases de datos vectoriales, lo que también ha dado lugar a una solución RAG basada en ChatGPT + Vector Database + Prompt, conocida como pila de tecnología CVP. Esta solución se basa en bases de datos vectoriales para recuperar de manera eficiente información relevante para mejorar los modelos de lenguaje grandes (LLM). Al convertir las consultas generadas por los LLM en vectores, el sistema RAG puede localizar rápidamente las entradas de conocimiento correspondientes en la base de datos de vectores. Este mecanismo de recuperación permite a los LLM utilizar la información más reciente almacenada en la base de datos de vectores cuando se enfrentan a problemas específicos, resolviendo eficazmente los problemas de retraso en la actualización del conocimiento y la ilusión inherentes a los LLM.
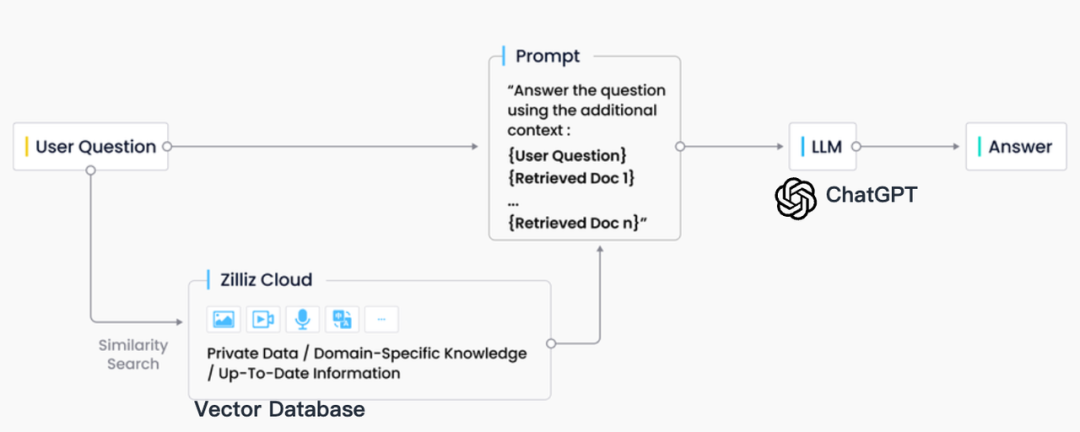
Aunque existen muchas tecnologías de almacenamiento y recuperación en el campo de la recuperación de información, incluidos motores de búsqueda, bases de datos relacionales, bases de datos de documentos, etc., las bases de datos vectoriales se han convertido en la primera opción de la industria en escenarios RAG. Detrás de esta elección está la excelente capacidad de las bases de datos vectoriales para almacenar y recuperar de manera eficiente una gran cantidad de vectores incrustados. Estos vectores de incrustación son generados por modelos de aprendizaje automático y no solo pueden caracterizar múltiples tipos de datos, como texto e imágenes, sino que también capturan su información semántica profunda. En el sistema RAG, la tarea de recuperación es encontrar de forma rápida y precisa la información que mejor coincida con la semántica de la consulta de entrada, y las bases de datos vectoriales se destacan por sus importantes ventajas en el procesamiento de datos vectoriales de alta dimensión y la realización de búsquedas rápidas de similitud.
La siguiente es una comparación horizontal de las bases de datos vectoriales representadas por la recuperación de vectores con otras opciones técnicas, así como un análisis de los factores clave que la convierten en una opción principal en los escenarios RAG:
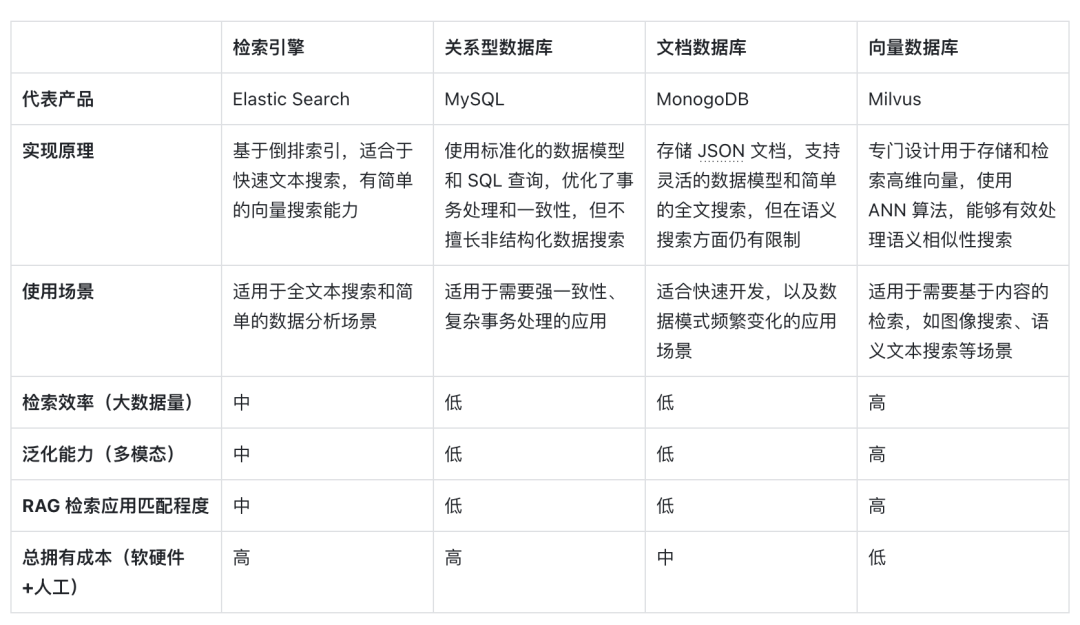
En primer lugar, en términos de principios de implementación , los vectores son la forma de codificación del significado semántico del modelo. Las bases de datos vectoriales pueden comprender mejor el contenido semántico de las consultas porque aprovechan la capacidad de los modelos de aprendizaje profundo para codificar el significado del texto, no solo la coincidencia de palabras clave. . Al beneficiarse del desarrollo de modelos de inteligencia artificial, la precisión semántica detrás de ellos también está mejorando constantemente. El uso de similitud de distancia vectorial para expresar similitud semántica se ha convertido en la forma principal de PNL, por lo que la incrustación ideográfica se ha convertido en la primera opción para procesar portadores de información.
En segundo lugar, en términos de eficiencia de recuperación , dado que la información se puede expresar como vectores de alta dimensión, se pueden agregar métodos especiales de optimización y cuantificación de índices a los vectores, lo que puede mejorar en gran medida la eficiencia de recuperación y comprimir los costos de almacenamiento. La base de datos vectorial se puede expandir horizontalmente, manteniendo el tiempo de respuesta de las consultas, lo cual es crucial para los sistemas RAG que necesitan procesar cantidades masivas de datos, por lo que las bases de datos vectoriales son mejores para procesar datos no estructurados a muy gran escala.
En cuanto a la dimensión de la capacidad de generalización , la mayoría de los motores de búsqueda tradicionales y las bases de datos relacionales o de documentos solo pueden procesar texto y tienen capacidades deficientes de generalización y expansión. Las bases de datos vectoriales no se limitan a datos de texto, sino que también pueden procesar imágenes, audio y otros datos no estructurados. . tipo de vector de incrustación, lo que hace que el sistema RAG sea más flexible y versátil.
Finalmente, en términos de costo total de propiedad , en comparación con otras opciones, las bases de datos vectoriales son más convenientes de implementar y más fáciles de usar. También proporcionan API enriquecidas, lo que las hace fáciles de integrar con los marcos de trabajo y flujos de trabajo de aprendizaje automático existentes, por lo que son populares. entre ellos. Un favorito entre muchos desarrolladores de aplicaciones RAG.
La recuperación de vectores se ha convertido en un recuperador RAG ideal en la era de los modelos grandes en virtud de su capacidad de comprensión semántica, su alta eficiencia de recuperación y su soporte de generalización para múltiples modalidades. Con el mayor desarrollo de la IA y los modelos de integración, estas ventajas pueden volverse más prominentes. en el futuro.
03.
Requisitos para bases de datos vectoriales en escenarios RAG
虽然向量数据库成为了检索的重要方式,但随着 RAG 应用的深入以及人们对高质量回答的需求,检索引擎依旧面临着诸多挑战。这里以一个最基础的 RAG 构建流程为例:检索器的组成包括了语料的预处理如切分、数据清洗、embedding 入库等,然后是索引的构建和管理,最后是通过 vector search 找到相近的片段提供给 prompt 做增强生成。大多数向量数据库的功能还只落在索引的构建管理和搜索的计算上,进一步则是包含了 embedding 模型的功能。
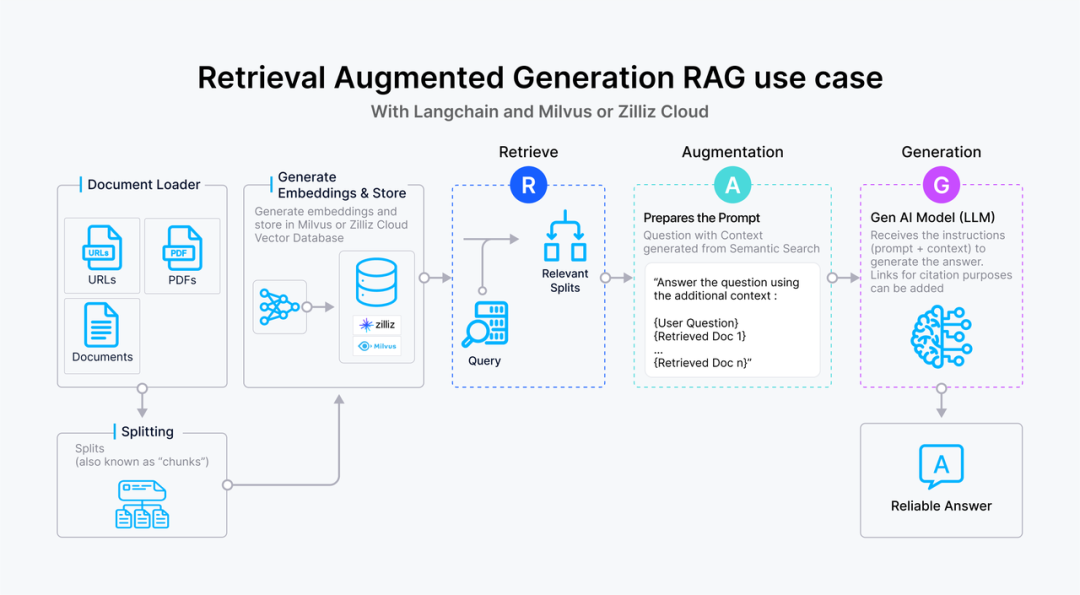
但在更高级的 RAG 场景中,因为召回的质量将直接影响到生成模型的输出质量和相关性,因此作为检索器底座的向量数据库应该更多的对检索质量负责。为了提升检索质量,这里其实有很多工程化的优化手段,如 chunk_size 的选择,切分是否需要 overlap,如何选择 embedding model,是否需要额外的内容标签,是否加入基于词法的检索来做 hybrid search,重排序 reranker 的选择等等,其中有不少工作是可以纳入向量数据库的考量之中。而检索系统对向量数据库的需求可以抽象描述为:
高精度的召回:向量数据库需要能够准确召回与查询语义最相关的文档或信息片段。这要求数据库能够理解和处理高维向量空间中的复杂语义关系,确保召回内容与查询的高度相关性。这里的效果既包括向量检索的数学召回精度也包括嵌入模型的语义精度。
快速响应:为了不影响用户体验,召回操作需要在极短的时间内完成,通常是毫秒级别。这要求向量数据库具备高效的查询处理能力,以快速从大规模数据集中检索和召回信息。此外,随着数据量的增长和查询需求的变化,向量数据库需要能够灵活扩展,以支持更多的数据和更复杂的查询,同时保持召回效果的稳定性和可靠性。
处理多模态数据的能力:随着应用场景的多样化,向量数据库可能需要处理不仅仅是文本,还有图像、视频等多模态数据。这要求数据库能够支持不同种类数据的嵌入,并能根据不同模态的数据查询进行有效的召回。
可解释性和可调试性:在召回效果不理想时,能够提供足够的信息帮助开发者诊断和优化是非常有价值的。因此,向量数据库在设计时也应考虑到系统的可解释性和可调试性。
RAG 场景中对向量数据库的召回效果有着严格的要求,不仅需要高精度和快速响应的召回这类基础能力,还需要处理多模态数据的能力以及可解释性和可调试性这类更高级的功能,以确保生成模型能够基于高质量的召回结果产生准确和相关的输出。在多模态处理、检索的可解释性和可调试性方面,向量数据库仍有许多工作值得探索和优化,而 RAG 应用的开发者也急需一套端到端的解决方案来达到高质量的检索效果。
本文作者


本文分享自微信公众号 - ZILLIZ(Zilliztech)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。