
Descubrimos que asignar un dominio (publicación) a otro (el lenguaje de dominio específico de SQL) encaja bien con los puntos fuertes de LLM.
Traducido de Generación de esquemas SQL con modelos de lenguaje grandes , autor David Eastman.
He analizado la persistencia de expresiones regulares y JSON generadas con LLM , pero muchos creen que la IA maneja bien el lenguaje de consulta estructurado (SQL) . Para celebrar el 50 cumpleaños de SQL , analicemos las tablas e introduzcamos terminología técnica cuando sea necesario. Sin embargo, no quiero simplemente probar la consulta con una tabla existente . El mundo de las bases de datos relacionales comienza con Schema .
Un esquema describe un conjunto de tablas que interactúan para permitir que las consultas SQL respondan preguntas sobre un modelo de un sistema del mundo real. Usamos varias restricciones para controlar cómo se relacionan las tablas entre sí. En este ejemplo, desarrollaré un esquema para libros, autores y editores. Luego veremos si LLM puede replicar este trabajo.
Empezamos por las relaciones entre nuestras cosas . Un libro está escrito por un autor y publicado por una editorial. De hecho, la publicación de un libro define la relación entre autor y editor.
Entonces, específicamente, queremos producir los siguientes resultados:
| Libro | Autor | Editor | Fecha de lanzamiento |
|---|---|---|---|
| La fábrica de avispas | Bancos Ian | Ábaco | 16 de febrero de 1984 |
| Considere Flebas | Ian M. Bancos | Orbita | 14 de abril de 1988 |
Es agradable leer esto (volveremos a ello más adelante), pero la tabla en sí no es una buena manera de mantener más información.
Si el nombre del editor fuera solo una cadena, es posible que deba ingresarlo varias veces, lo cual es ineficiente y propenso a errores. El autor también. Aquellos de ustedes con inclinación literaria sabrán que el autor de ambos libros (Iain Banks) es la misma persona, pero utilizó seudónimos ligeramente diferentes cuando escribía ciencia ficción.
¿Qué sucede si el libro es reeditado posteriormente por una editorial diferente? Para garantizar que se distingan estos dos eventos de publicación, debemos proporcionar tanto el título del libro como la fecha de publicación, por lo que nuestra clave principal o identificador único debe incluir ambos. Queremos que el sistema rechace dos libros con el mismo título y fecha de publicación.
En lugar de utilizar una tabla grande, utilizamos tres tablas y hacemos referencia a ellas cuando es necesario. Uno para el autor, otro para el editor y otro para el libro. Escribimos los detalles de los autores en la tabla Autores y luego hacemos referencia a ellos en la tabla Libros usando claves externas .
Entonces, la siguiente es una tabla de esquema escrita usando el lenguaje de definición de datos ( DDL ). Estoy usando una variante de MySQL; resulta molesto que todos los proveedores aún mantengan dialectos ligeramente diferentes.
Primero, está la tabla de autores. Agregamos un índice de columna de ID automático como clave principal. En realidad, no hemos resuelto el problema del seudónimo (eso se lo dejo al lector):
CREATE TABLE Authors (
ID int NOT NULL AUTO_INCREMENT,
Name varchar(255) not null,
Birthday date not null,
PRIMARY KEY (ID)
);
La tabla de editores sigue el mismo patrón. "NOT NULL" es otra restricción que impide que se agreguen datos sin contenido.
CREATE TABLE Publishers (
ID int NOT NULL AUTO_INCREMENT,
Name varchar(255) not null,
Address varchar(255) not null,
PRIMARY KEY (ID)
);
La tabla de libros hará referencia a una clave externa, lo que la hace lógica pero un poco difícil de entender. Tenga en cuenta que respetamos que el título del libro y su fecha de publicación juntos formen la clave principal.
CREATE TABLE Books (
Name varchar(255) NOT NULL,
AuthorID int, PublisherID int,
PublishedDate date NOT NULL,
PRIMARY KEY (Name, PublishedDate),
FOREIGN KEY (AuthorID) REFERENCES Authors(ID),
FOREIGN KEY (PublisherID) REFERENCES Publishers(ID)
);
Para ver una tabla ordenada en la parte superior, necesitamos una vista . Esta es solo una forma de unir las tablas para que podamos seleccionar la información que necesitamos mostrar mientras mantenemos el esquema intacto. Ahora que tenemos el esquema escrito, podemos construir nuestra vista:
CREATE VIEW ViewableBooks AS
SELECT Books.Name 'Book', Authors.Name 'Author', Publishers.Name 'Publisher', Books.PublishedDate 'Date'
FROM Books, Publishers, Authors
WHERE Books.AuthorID = Authors.ID
AND Books.PublisherID = Publishers.ID;
Veamos si podemos generar nuestro esquema en un patio de juegos en línea para no tener que instalar una base de datos.
DB Fiddle debería hacer el trabajo.
Si ingresa DDL y luego agrega los datos reales:
INSERT INTO Authors (Name, Birthday)
VALUES ('Iain Banks', '1954-02-16');
INSERT INTO Authors (Name, Birthday)
VALUES ('Iain M Banks', '1954-02-16');
INSERT INTO Publishers (Name, Address)
VALUES ('Abacus', 'London');
INSERT INTO Publishers (Name, Address)
VALUES ('Orbit', 'New York');
El resultado de ver la vista aparece como "Consulta 3" en DB Fiddle, que es exactamente los datos que queríamos ver:
¿LLM también puede crear patrones?
Bien, ahora queremos preguntarle a LLM sobre la creación del esquema. Para resumir cómo esperamos guiar LLM:
- Al solicitar el esquema en inglés, queremos que genere DDL para las tres tablas, incluidos índices y restricciones.
- También podemos implicar la necesidad de restricciones (claves primarias, claves externas, etc.) si es necesario.
- Podemos pedir verlo.
- Podemos indicarle que utilice la sintaxis MySQL si es necesario.
Usaré Llama 3 , pero también miré el LLM de OpenAI y obtuve aproximadamente los mismos resultados.
Nuestra primera consulta: "Crear un esquema de base de datos relacional para describir libros, editores y autores".
resultado:
Hasta ahora, todo bien. Aún no ha creado el DDL, pero podemos solicitarlo por separado. De alguna manera describe mejor el patrón en inglés. Veamos el resto de la respuesta:
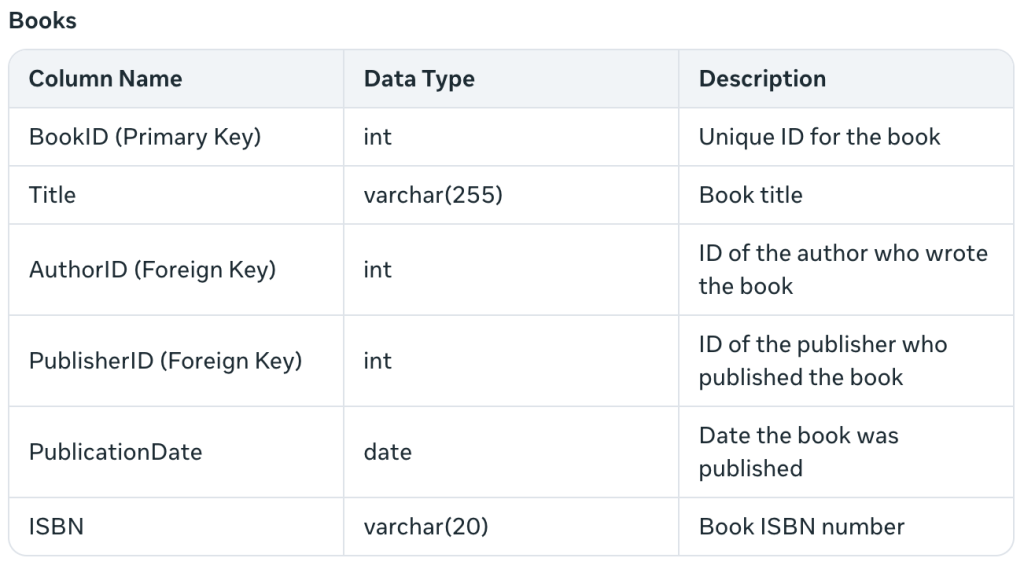
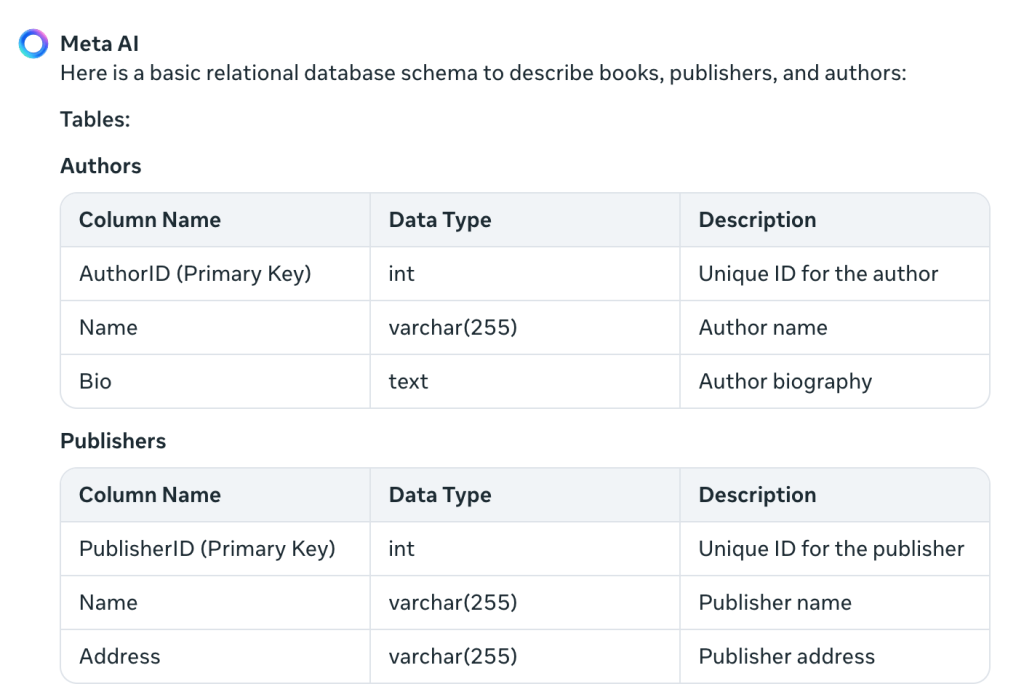
Describe las restricciones de clave externa y agrega el ISBN, lo cual no esperaba. Además, "PublicationDate" es más idiomático que mi "PublishedDate". También crea una tabla:
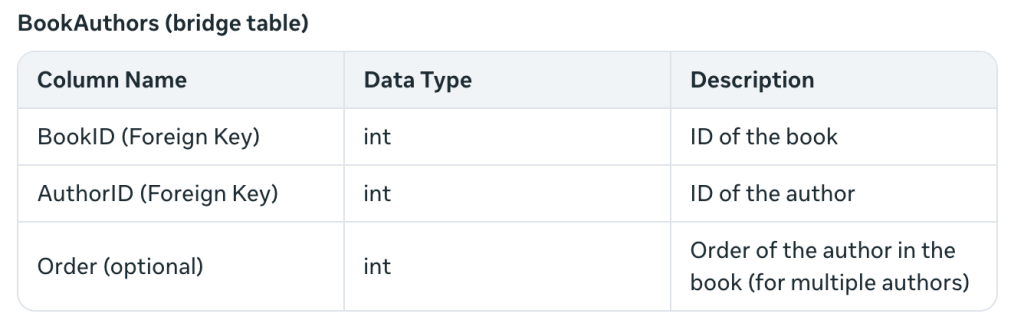
Esto resuelve el problema de crear varios autores para un libro, algo que no había considerado antes. El término tabla puente indica que dos tablas (libros y autores) están unidas por una clave externa.
Preguntémosle a DDL: "Muéstrame el lenguaje de definición de datos para este esquema".
Estos se devuelven correctamente, incluidos NOT NULL, para garantizar que no haya entradas vacías. También afirma que el DDL es "universal" en algunos aspectos debido a las diferencias del mundo real entre los SQL de los proveedores.
Finalmente, pidamos una vista:

Esto es más complicado que mi versión; sin embargo, funciona bien en DB Fiddle cuando me ajusto a la denominación de mi esquema. El nombre de alias de la tabla que se ve aquí no es útil para la comprensión.
Conclusión: LLM de hecho puede crear patrones
Creo que esta es una gran victoria para LLM porque convirtieron mi descripción en inglés en un patrón bien restringido y luego en DDL ejecutable, al tiempo que proporcionaron explicaciones (aunque esas explicaciones se convirtieron en detalles más técnicos de la relación). Ni siquiera utilicé un LLM o servicio dedicado, así que funcionó muy bien.
En cierto modo, se trata de una asignación de un dominio (el mundo editorial) a otro (el lenguaje de dominio específico de SQL), y es una gran ventaja para LLM. Cada área está bien definida y rica en detalles.
¡Feliz cumpleaños a SQL y espero que LLM lo mantenga relevante durante algunas décadas más!
Un programador nacido en los años 90 desarrolló un software de portabilidad de vídeo y ganó más de 7 millones en menos de un año. ¡El final fue muy duro! Los estudiantes de secundaria crean su propio lenguaje de programación de código abierto como una ceremonia de mayoría de edad: comentarios agudos de los internautas: debido al fraude desenfrenado, confiando en RustDesk, el servicio doméstico Taobao (taobao.com) suspendió los servicios domésticos y reinició el trabajo de optimización de la versión web Java 17 es la versión Java LTS más utilizada. Cuota de mercado de Windows 10. Alcanzando el 70%, Windows 11 continúa disminuyendo. Open Source Daily | Google apoya a Hongmeng para hacerse cargo de los teléfonos Android de código abierto respaldados por Docker; Electric cierra la plataforma abierta Apple lanza el chip M4 Google elimina el kernel universal de Android (ACK) Soporte para la arquitectura RISC-V Yunfeng renunció a Alibaba y planea producir juegos independientes para plataformas Windows en el futuroEste artículo se publicó por primera vez en Yunyunzhongsheng ( https://yylives.cc/ ), todos son bienvenidos a visitarlo.