
Autor: Equipo de Big Data de Internet de vivo - Huang Guihu, Chen Shengzun
HBase es una base de datos no relacional distribuida de código abierto con alta confiabilidad, alta escalabilidad y alto rendimiento. Se usa ampliamente en procesamiento de big data, computación en tiempo real, almacenamiento y recuperación de datos y otros campos. En un clúster distribuido, la falla de hardware es una ocurrencia común. La falla de hardware puede provocar interrupciones del servicio a nivel de nodo o clúster, daños en la metatabla, RIT, agujeros de región, superposiciones y otros problemas. Particularmente importante. Este artículo trata principalmente sobre Describir fallas comunes y las soluciones correspondientes en torno a las metatablas de HBase.
1. Antecedentes
Creo que los amigos que han realizado trabajos relacionados con el desarrollo, operación y mantenimiento de HBase tienen esta sensación hasta cierto punto. HBase, como líder en bases de datos distribuidas no relacionales, no solo es estable, de alto rendimiento y muy simple de instalar y expandir. , pero también carece de sistemas de monitoreo maduros que son extremadamente hostiles para la resolución de problemas. Si no tiene un conocimiento completo de HBase, a menudo no podrá lidiar con las fallas diarias. Como editores, hemos operado y mantenido más de 20 clústeres de HBase de varios tamaños que involucran las versiones 1.x ~ 2.x. Experimentamos corrupción en la metatabla y no pudimos conectarnos normalmente, las regiones se superponen. Hemos estado lidiando con problemas en línea, como agujeros de región y permisos perdidos, y también hemos buscado las respuestas correctas del código fuente de HBase con varios problemas. Solución común a la metatabla que los editores han resumido de muchas fallas.
2. Tabla de metainformación de HBase
La metatabla de HBase, también conocida como tabla de catálogo, es una tabla de HBase especial que almacena todas las regiones en el clúster de HBase y su información de RegionServer correspondiente. La precisión de los datos de la tabla de metainformación es crucial para el funcionamiento normal del clúster de HBase. por lo que es necesario garantizar que los datos correctos en la tabla de metainformación sean una condición necesaria para el funcionamiento estable del clúster. Si los datos en la metatabla son inconsistentes, causará RIT (Región en transición) o incluso el clúster no puede iniciarse normalmente porque HMaster no se puede inicializar normalmente. Esto muestra la importancia de la metatabla en el clúster HBase. la estructura de la metatabla, el formato de los datos, Inicie el proceso para analizarlos (este artículo se centra principalmente en la versión HBase 2.4.8 y también intercalará la versión HBase 1.x).
2.1 estructura de metatabla
La metatabla incluye principalmente tres familias de columnas: información, tabla y rep_barrier, que registran respectivamente la información de la región y el estado de la tabla:
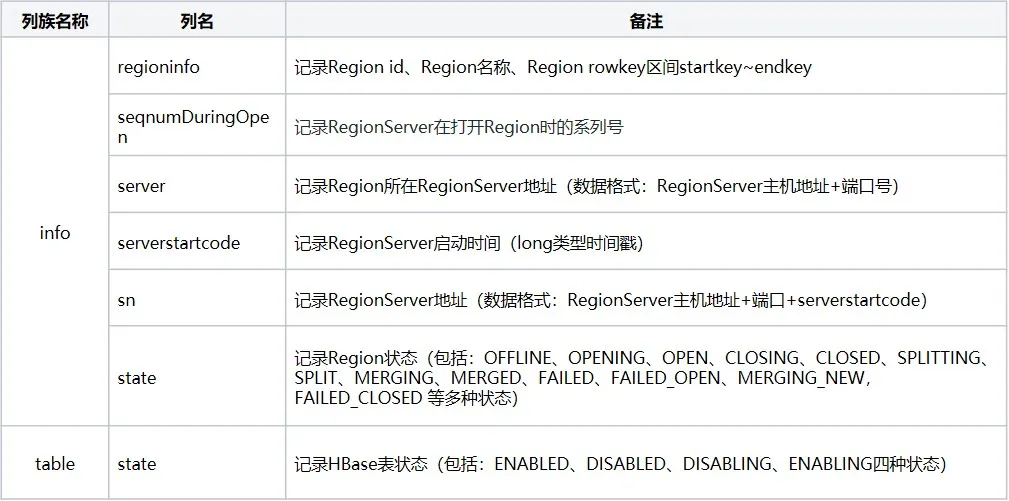
2.2 proceso de carga de metatabla
A través de la estructura de metatabla anterior, tenemos una comprensión general de la tabla. Los amigos que han realizado la operación y el mantenimiento de HBase creen que todos tienen esta experiencia. Algunos clústeres se inician más rápido, otros se inician más lentamente y, a veces, incluso el clúster se reinicia. Operación incorrecta. Se ha quedado atascado en la carga de la meta tabla y no puede continuar ejecutando procesos posteriores. Si tenemos una comprensión general del proceso de carga de la metatabla, tendremos una expectativa más o menos psicológica para cada momento de inicio del clúster. El siguiente es el proceso relacionado con la carga de la metatabla:
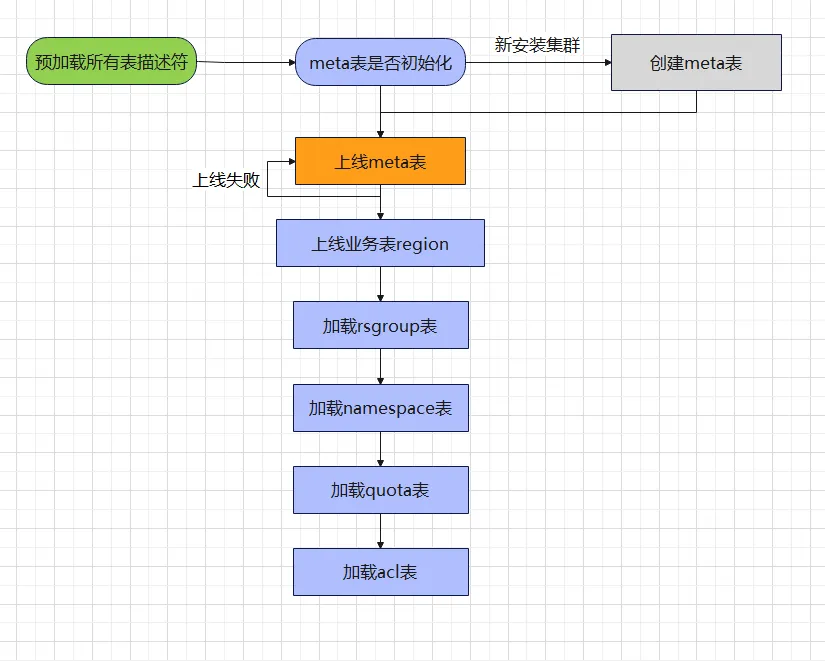
A través del diagrama de flujo de carga de la metatabla anterior, podemos descubrir fácilmente por qué algunos clústeres se inician lentamente y otros no se inician. A continuación analizamos dos tipos de escenarios:
- El clúster comienza lentamente:
Por lo general, los grupos nuevos o los grupos con menos tablas tienden a iniciarse más rápido, mientras que los grupos con más tablas tienden a iniciarse mucho más lentamente. Algunos grupos incluso tardan entre 15 y 30 minutos en iniciarse. A veces, el tiempo de inicio del grupo es largo, lo que hace que la gente sospeche. ¿Hay algún problema con el clúster? ¿Por qué no puede entrar en un estado normal durante tanto tiempo? Hay dos lugares que tardan mucho en todo el proceso de carga.
Precargue todos los descriptores de tablas : debe escanear todo el directorio de datos de HBase, analizar los archivos de datos en el directorio .tabledesc y almacenarlos en la memoria de HMaster. Si hay una gran cantidad de tablas (más de 10,000 tablas), este proceso es frecuente. tarda unos diez minutos. Cuando vemos que aparecen las palabras "Descriptores de tabla de precarga" en la página de HMaster, significa que el clúster está en la etapa de precarga. Solo tenemos que esperar pacientemente, porque la etapa de carga de la metatabla aún no ha llegado. alcanzó.
Región de la tabla de negocios en línea : el tamaño de los datos de la metatabla suele estar entre decenas de MB y cientos de MB. El tiempo de apertura de la región es relativamente rápido (segundos) durante la fase de inicio del clúster, si es necesario verificar la región fuera de línea. Si desea acelerar la velocidad de apertura, puede ajustar el valor de hbase de forma adecuada.
- Error al iniciar el clúster:
Fallo en línea de la metatabla : cuando el HRegionServer del grupo de recursos predeterminado cuelga y el código de inicio de la máquina cambia después de reiniciar, el fragmento de metadatos no puede encontrar el nodo abierto, lo que provoca que el clúster no se inicie.
3. Cómo reparar la metatabla
Dado que el estado del clúster HBase se mantiene principalmente a través de la metatabla, si la metatabla está dañada o es incorrecta, el clúster HBase dejará de estar disponible y correrá el riesgo de pérdida de datos. Sabemos que la coherencia de los datos de las metatablas es muy importante, entonces, ¿bajo qué circunstancias ocurrirá la inconsistencia de los datos? (Para conocer los comandos de reparación de HBase 2.4.8, consulte la herramienta hbase-operator-tools).
-
RegionServer está inactivo o es anormal : cuando RegionServer está inactivo o es anormal, la información de Región y RegionServer almacenada en la metatabla puede ser incorrecta o perderse.
-
Corrupción o errores de datos : cuando los datos de la metatabla están dañados o son incorrectos, puede provocar la falta de disponibilidad del clúster HBase y la pérdida de datos.
-
Operaciones ilegales : cuando se realizan operaciones ilegales en la metatabla, como eliminar o modificar datos en la metatabla, pueden causar errores o pérdida de la metatabla.
La falla de la metatabla es solo un término general. Podemos dividirla aproximadamente en RIT a largo plazo, agujero de región, superposición de regiones, pérdida de archivos de descripción de la tabla, ruta hdfs de la metatabla vacía, pérdida de datos de la metatabla, etc. Los discutiré respectivamente. Estos tipos de fallas se analizan y solucionan:
3.1 RIT
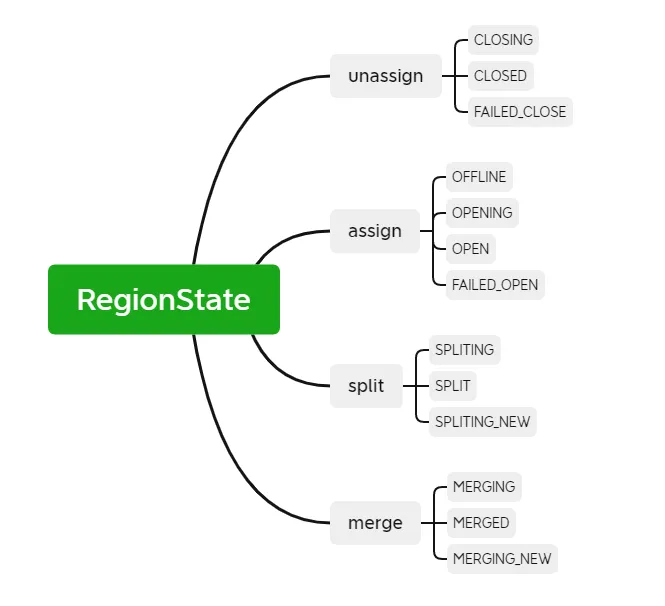
RIT (Región en transición) se refiere a la transición de estado en curso en el clúster de HBase. Las siguientes operaciones harán que el estado de la Región en el clúster de HBase cambie. Por ejemplo, el Servidor de Región está inactivo, la Región se está dividiendo, fusionando y. otras operaciones El estado de la región incluye principalmente los siguientes doce estados y diagrama de transformación:
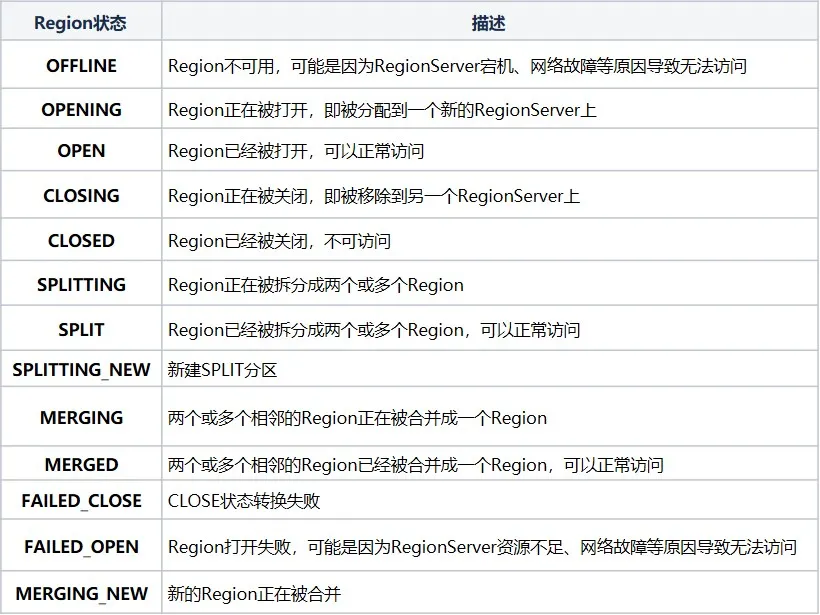
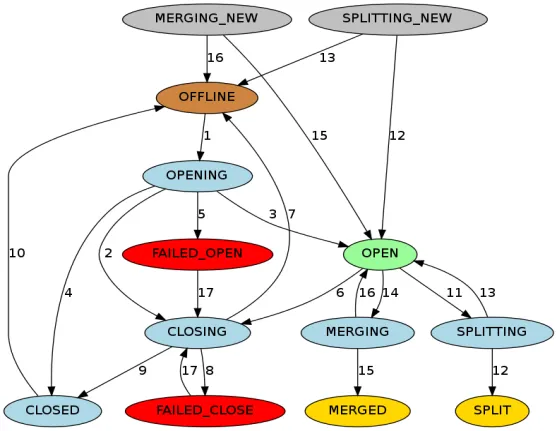
Para ser más claro sobre el estado de la Región, podemos dividirlo en asignar, desasignar, dividir y fusionar según el tipo de operación. Si el RegionServer está inactivo o es anormal, los datos están dañados o se producen errores durante la operación, RIT lo hará. Aunque RIT se encuentra a menudo en problemas de operación y mantenimiento de HBase, si la lógica subyacente es clara, será más fácil lidiar con los problemas de RIT. La mayoría de los casos se pueden restaurar sin intervención manual. Sólo se requiere intervención cuando el RIT se produce durante un período prolongado. Entonces, ¿cuál es el tiempo a largo plazo para el RIT? ¿Por qué ocurre el RIT a largo plazo?
Si ha utilizado las versiones HBase 1.x y HBase 2.x, obviamente sentirá que RIT es menos común en HBase 2.x. De hecho, la operación de la Región es principalmente transferir la Región a través de la clase AssignmentManager. En los códigos de las dos versiones, encontramos que hbase.assignment.maximum El valor predeterminado del parámetro de intentos (número de reintentos de asignación) es diferente en las dos versiones. El número de reintentos en HBase 2.4.8 es el número entero máximo. .MAX_VALUE (mientras que el valor predeterminado es 10 en HBase 1.x. Esta es la razón por la que en HBase las razones para RIT a largo plazo son relativamente raras en 2.x).
Método de procesamiento RIT:
-
Se producirá RIT al crear o eliminar tablas grandes. Esto se debe principalmente a la gran cantidad de regiones y la alta presión sobre el clúster, lo que resulta en largos tiempos de respuesta de asignación y desasignación. Para este tipo de problema, HBase generalmente no requiere manual. intervención y puede curarse a sí mismo.
-
Si la versión del clúster es 1.x, puede ajustar adecuadamente el valor hbase.assignment.maximum.attempts para aumentar el número de reintentos. Por ejemplo, FAILED_OPEN y FAILED_CLOSE generalmente pueden repararse automáticamente o ejecutar manualmente el comando de asignación para asignar cada uno. Región en línea (si hay muchas regiones, cambie a reparación HMaster).
-
Si la asignación de región falla y no hay RegionServer, la asignación manual no se puede restaurar. Por ejemplo, la región se asigna a bogus.example.com y los nodos 1 y 1 solo se pueden restaurar cambiando HMaster.
Preguntas para pensar:
¿Por qué la Región no puede conectarse normalmente incluso después de una intervención manual y se puede restaurar cambiando a HMaster? (Consulte el proceso de inicio de HMaster TransitRegionStateProcedure, código fuente de la clase HMaster)
3.2 Agujero de región
Cuando creamos una tabla HBase, si analizamos cuidadosamente las reglas de la Región, nos sorprenderá descubrir que la clave de inicio y la clave de finalización de la Región pertenecen a intervalos continuos que están cerrados a la izquierda y abiertos a la derecha. ¿Qué problemas ocurrirán si de repente uno? ¿Falta uno de estos intervalos (como se muestra a continuación)?
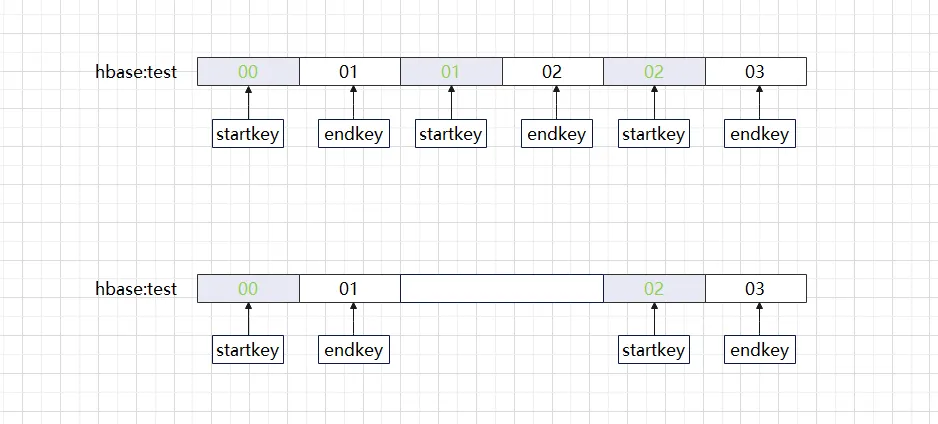
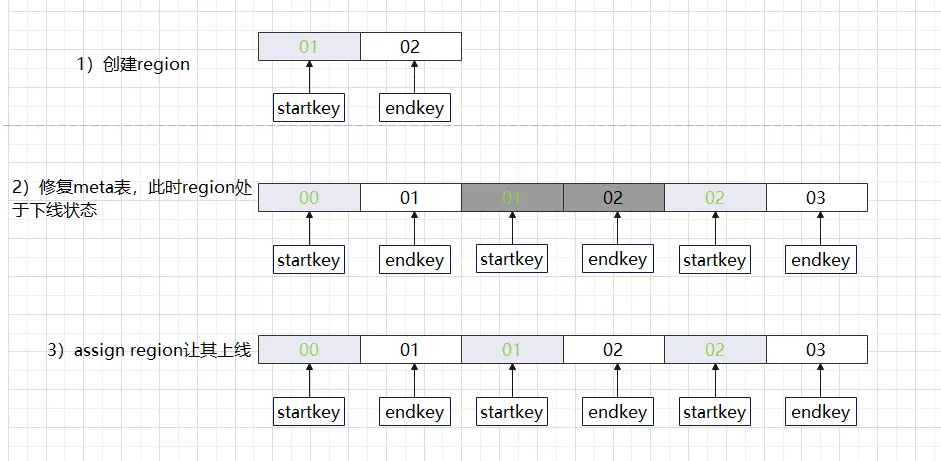
La situación anterior es lo que a menudo llamamos un agujero en la región. Si utiliza la herramienta hbck de HBase para verificar, verá el mensaje de error ERROR: hay un agujero en la cadena de regiones entre 01 y 02. Debe crear un agujero en la región. Nuevo .regioninfo y directorio de región en hdfs para tapar el agujero. Cuando aparece un agujero en un clúster HBase, a menudo no puede repararse por sí solo y requiere intervención manual para volver a la normalidad. Ahora que sabemos que falta una región, ¿no es así? ¿Será suficiente si simplemente completamos la Región en el intervalo en blanco? El enfoque normal es volver a agregar primero la Región en blanco, verificar si la información de la metatabla es correcta y finalmente conectarse con la Región. Si esta serie de operaciones se realiza manualmente, no solo será propensa a errores sino que también generará un error. Aquí están las diferentes versiones del método de reparación de HBase. De hecho, aunque los métodos de procesamiento de las diferentes versiones son ligeramente diferentes, el proceso de procesamiento es el mismo.
Método de procesamiento de agujeros de región:
(1) Método de reparación de HBase 1.x
-
HBase hbck –fixHdfsHoles : crea una ruta de archivo de región vacía en hdfs
-
HBase hbck -fixMeta : repara los datos de la metatabla donde se encuentra la región
-
HBase hbck –fixAssignments : Región después de la reparación en línea
-
O HBase hbck –repairHoles es equivalente a una combinación de (fixHdfsHoles, fixMeta, fixAssignments)
(2) Método de reparación de HBase 2.4.8 (consulte la herramienta hbase-operator-tools más adelante)
Dado que HBase 2.4.8 no proporciona comandos relevantes para agregar operaciones de directorio de regiones, es relativamente problemático. De hecho, muchas clases de herramientas en HBase 2.4.8 proporcionan métodos para crear regiones y la clase HBaseTestingUtility en hbase-server-2.4. El paquete de 8 pruebas los proporciona para operar la entrada relacionada con la región, nuestra solución a continuación se centra principalmente en la recuperación basada en este método.
-
extraRegionsInMeta -fix : primero elimine los registros que no existen en el directorio hdfs en la metatabla.
-
HBaseTestingUtility.createLocalHRegion : cree la ruta del archivo hdfs para garantizar la continuidad de la región
-
addFsRegionsMissingInMeta : agrega nueva información de región a la metatabla (la identificación de la región se devolverá después de que la adición sea exitosa)
-
asigna : finalmente poner en línea la región recién agregada
3.3 Superposición de regiones
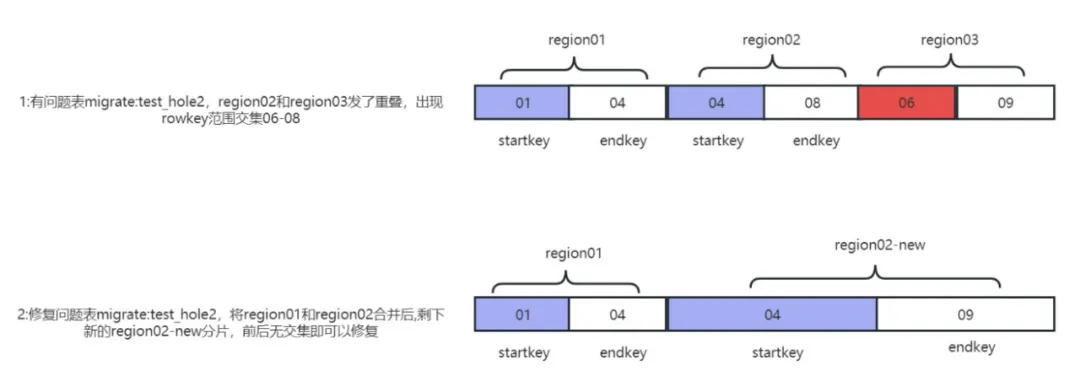
Dado que habrá agujeros en la Región, ¿sucederá esto? La respuesta es sí. Si la clave de inicio y la clave de finalización de varias regiones son la misma región, entonces llamamos a esta situación Regiones superpuestas. La superposición de regiones es difícil de simular en HBase y también es un problema difícil de manejar. Si verificamos hbck y aparece este tipo de registro ERROR: Varias regiones tienen la misma clave de inicio: 02

Otro tipo de región superpuesta se cruza con el rango de claves de fila de uno o dos fragmentos adyacentes. Este tipo de problema se denomina colectivamente problema de superposición. Para este escenario más difícil, utilizamos herramientas de desarrollo propio para simular la recurrencia del problema de superposición y repararlo. la superposición con un clic (plegado) y problemas de orificio (agujero).
función de simulación de problemas de superposición
El problema de la superposición de regiones es en realidad dos regiones diferentes. Los rangos de claves de fila se superponen. Por ejemplo, la clave de inicio y la clave de finalización de la Región01 son (01,03), y el rango de otra Región02 es (01,02). las dos regiones se cruzan (01,02), la detección de hbck informará un problema de superposición.
En el entorno de producción, el problema de superposición solo ocurrirá cuando la región se divida y la máquina se cuelgue al mismo tiempo. Las condiciones son relativamente duras y es difícil reproducir el problema. Reparaciones y simulacros de fallas. El problema de superposición. Principio de reproducción:
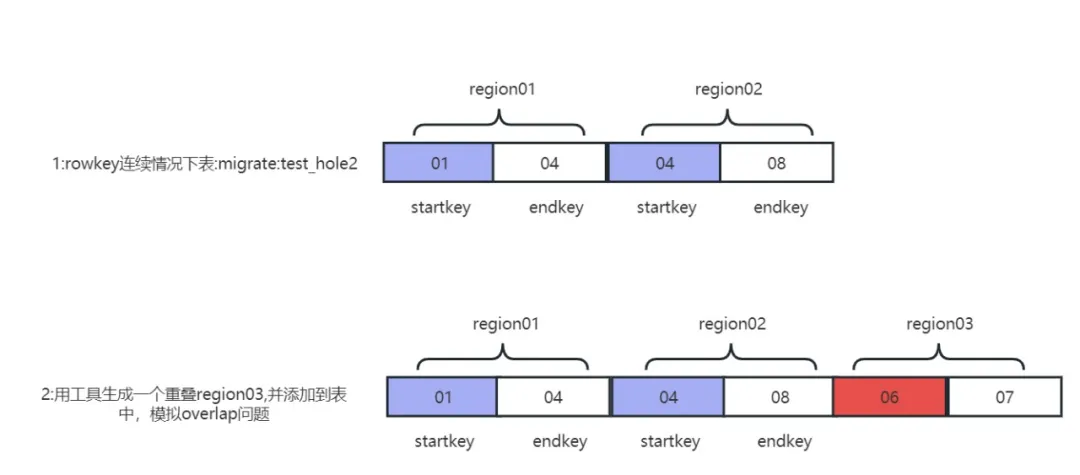
recurrencia del problema de superposición
1) Genere un fragmento de región con rangos de claves de fila superpuestas:
java -jar -Drepair.tableName=migrate:test_hole2 -Dfix.operator=createRegion -DRegion.startkey=06 -DRegion.endkey=07 hbase-meta-tool-0.0.1.jar
2) Mueva la región del problema de superposición al directorio de la tabla:
sudo -uhdfs hdfs dfs -mv /tmp/.tmp/data/migrate/test_hole2/c8662e08f6ae705237e390029161f58f /hbase/data/migrate/test_hole2
3) Elimine la información de la metatabla de la tabla normal migrar:test_hole2:
java -jar -Drepair.tableName=migrate:test_hole2 -Dfix.operator=delete hbase-meta-tool-0.0.1.jar
4) Reconstruya la información de metadatos de la tabla de problemas de superposición:
java -jar -Drepair.tableName=migrate:test_hole2 -Dfix.operator=fixFromHdfs hbase-meta-tool-0.0.1.jar
5) Después de reiniciar el clúster, hbck informó que la región se superpuso c8662e08f6ae705237e390029161f58f y el problema de superposición se reprodujo con éxito.

Método 1: reparar superposiciones y agujeros con un clic
Adecuada para casos en los que el número de pliegues no supera los 64, la herramienta de desarrollo propio hbase-meta-tool se puede utilizar para fusionar los rangos de regiones adyacentes con intersecciones de claves de fila y generar nuevas regiones si hay huecos o faltan rangos, por lo que que el problema se puede reparar Principio de reparación del problema Como se muestra en la imagen:
1) Solucione los problemas de superposición y orificios del grupo:
java -jar -Dfix.operator= fixOverlapAndHole hbase-meta-tool-0.0.1.jar
Método 2: reparación de plegados a gran escala
Adecuado para el plegado a gran escala de más de miles o decenas de miles de casos para reparar anomalías del lado del servidor, adopte los siguientes métodos de reparación
1) Borrar los metadatos de tablas con problemas de plegado con un solo clic:
java -jar -Drepair.tableName=migrate:test1 -Dzookeeper.address=zkAddress -Dfix.operator=delete hbase-meta-tool-0.0.1.jar
2) Haga una copia de seguridad de los datos de la tabla original:
hdfs dfs -mv /hbase/data/migrate/test/ /back
3) Elimine la tabla original e importe los datos de respaldo para cada fragmento de región:
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /back/test/region01-regionN migrate:test1
3.4 Reparación de datos de metatabla
Podemos encontrar los siguientes problemas difíciles en los clústeres en línea de HBase:
-
La tabla del coprocesador está configurada incorrectamente, no se puede encontrar la ruta del coprocesador y no se puede encontrar el jar durante la carga de la Región, lo que hace que el clúster se cuelgue repetidamente y el comando drop no pueda eliminarlo;
-
La cantidad de elementos en la metatabla de HBase es incorrecta, el código de inicio es incorrecto, la tabla del servidor no se puede encontrar durante el proceso en línea y la tabla nunca se conecta.
Necesitamos reparar la tabla problemática de forma independiente sin detener el servicio y sin afectar otros servicios de tabla en el clúster.
Reparación de metadatos de la tabla de problemas.
1) Suponiendo que hay un problema con la migración de la tabla: prueba1, puede eliminar los metadatos de la tabla problemática con un solo clic:
java -jar -Drepair.tableName=migrate:test1 -Dfix.operator=delete hbase-meta-tool-0.0.1.jar
2) Lea el contenido de la carpeta .regioninfo de la tabla hdfs y reconstruya los metadatos correctos con un clic:
java -jar -Drepair.tableName=migrate:test1 -Dfix.operator=fixFromHdfs hbase-meta-tool-0.0.1.jar
3.5 meta roto
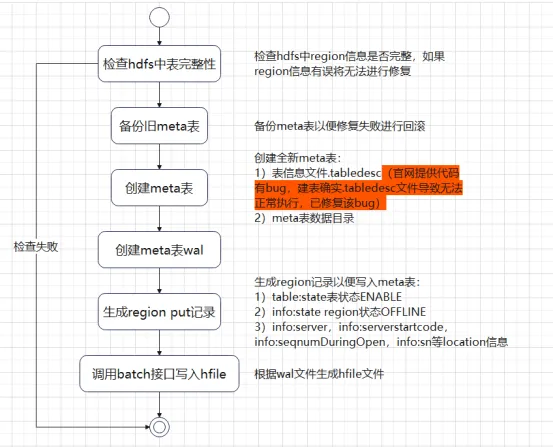
Las cinco situaciones anteriores se reparan bajo la premisa de que la metatabla está en línea normalmente. Si los datos de la metatabla están dañados y no pueden estar en línea, ¿cómo debemos repararlos? Por lo general, pensamos en reconstruir la metatabla y luego escribir la información de la región en la metatabla. Si el clúster está fuera de línea, el shell de HBase o la API de HBase generalmente no pueden ejecutar la creación para construir la tabla.
Analizamos la clase de inicialización de metatabla InitMetaProcedure y descubrimos que el proceso de creación de metatabla se divide aproximadamente en dos pasos:
1) Cree el directorio de región y el archivo .tabledesc
2) Asigne una región y conéctese.
Código fuente principal de InitMetaProcedure:
ProcedimientoInitMeta
protected Flow executeFromState(MasterProcedureEnv env, InitMetaState state) throws ProcedureSuspendedException, ProcedureYieldException, InterruptedException {
try {
switch (state) {
case INIT_META_WRITE_FS_LAYOUT:
Configuration conf = env.getMasterConfiguration();
Path rootDir = CommonFSUtils.getRootDir(conf);
TableDescriptor td = writeFsLayout(rootDir, conf);
env.getMasterServices().getTableDescriptors().update(td, true);
setNextState(InitMetaState.INIT_META_ASSIGN_META);
return Flow.HAS_MORE_STATE;
case INIT_META_ASSIGN_META:
addChildProcedure(env.getAssignmentManager().createAssignProcedures(Arrays.asList(RegionInfoBuilder.FIRST_META_RegionINFO)));
return Flow.NO_MORE_STATE;
default:
throw new UnsupportedOperationException("unhandled state=" + state);
}
} catch (IOException e) {
}
private static TableDescriptor writeFsLayout(Path rootDir, Configuration conf) throws IOException {
LOG.info("BOOTSTRAP: creating hbase:meta region");
FileSystem fs = rootDir.getFileSystem(conf);
Path tableDir = CommonFSUtils.getTableDir(rootDir, TableName.META_TABLE_NAME);
if (fs.exists(tableDir) && !fs.delete(tableDir, true)) {
LOG.warn("Can not delete partial created meta table, continue...");
}
TableDescriptor metaDescriptor = FSTableDescriptors.tryUpdateAndGetMetaTableDescriptor(conf, fs, rootDir);
HRegion.createHRegion(RegionInfoBuilder.FIRST_META_RegionINFO, rootDir, conf, metaDescriptor, null).close();
return metaDescriptor;
}
Podemos consultar la lógica del código InitMetaProcedure para escribir las herramientas correspondientes para crear tablas y conectarlas. Una vez que la metatabla se conecta, solo necesitamos escribir la información de la región de cada tabla en la meta y asignar todas las regiones para que se conecten y restaurar la normalidad. estado del cluster. A través del proceso anterior, descubrimos que el proceso de reparación de metatablas no es tan complicado. Sin embargo, si hay una gran cantidad de tablas en el entorno de producción o hay miles de regiones en tablas grandes individuales, la adición manual se vuelve muy lenta. Consumiendo, presentaremos el proceso a continuación que siempre ha sido relativamente simple Solución (HBase 1.x hbck tool, HBase 2.x hbase-operator-tools), echemos un vistazo al proceso de reparación fuera de línea.
Correcciones de HBase 1.x
-
Detener el clúster HBase
-
sudo -u hbase hbase org.apache.hadoop.hbase.util.hbck.OfflineMetaRepair -fix
-
Reinicie el clúster para completar la reparación.
Método de reparación de HBase 2.4.8 (herramienta hbase-operator-tools)
1) Generar metatabla automáticamente según la ruta hdfs
-
Detener el clúster HBase
-
sudo -u hbase hbase org.apache.hbase.hbck1.OfflineMetaRepair -fix
-
Reinicie el clúster para completar la reparación.
2) Método de reparación de una sola mesa
-
Eliminar el directorio raíz de HBase en zookeeper
-
Elimine el directorio hdfs WAL donde se encuentran HMaster y RegionServer
-
Después de reiniciar el clúster, no hay datos en meta y el clúster no puede ingresar al estado normal.
-
Ejecute el comando agregar región para agregar las tablas de cuatro caracteres hbase:namespace, hbase:quota, hbase:rsgroup y hbase:acl al clúster. Una vez completada la adición, el registro imprimirá las regiones seguidas de las asignaciones y estas tablas. Estas regiones deben registrarse para la siguiente operación de asignación.
sudo -u hbase hbase --config /etc/hbase/conf hbck -j hbase-tools.jar addFsRegionsMissingInMeta hbase:namespace hbase:quota hbase:rsgroup hbase:acl
- Agregue la Región de impresión en el paso anterior en línea
sudo -u hbase hbase --config /etc/hbase/conf hbck -j hbase-hbck2.jar assigns regionid
- La mesa de negocios está en línea (solo necesita repetir los pasos 4 y 5 para poner la mesa de negocios en línea gradualmente)
Precauciones
(Si hay muchas regiones en la tabla de negocios y la quinta región no está asignada, no todas las regiones podrán conectarse correctamente. Debe deshabilitar y habilitar el rendimiento para conectarse normalmente)
Nota: La herramienta hbase-operator-tools OfflineMetaRepair tiene los siguientes errores que deben corregirse.
1. La metatabla creada por el método createNewMeta de HBaseFsck carece del archivo .tabledesc.
antes de arreglar:
TableDescriptor td = new FSTableDescriptors(getConf()).get(TableName.META_TABLE_NAME);
Después de la modificación:
FileSystem fs = rootdir.getFileSystem(conf);
TableDescriptor metaDescriptor = FSTableDescriptors.tryUpdateAndGetMetaTableDescriptor(getConf(), fs, rootdir);
2. El estado de región predeterminado de HBaseFsck generatePuts es CERRADO porque HMaster solo se conecta en el estado SIN CONEXIÓN cuando se reinicia (si está CERRADO, la carga de trabajo de conectarse manualmente uno por uno es muy grande)
antes de arreglar:
addRegionStateToPut(p, org.apache.hadoop.hbase.master.RegionState.State.CLOSED);
Después de la modificación:
addRegionStateToPut(p, org.apache.hadoop.hbase.master.RegionState.State.OFFLINE);
defecto
1) La reparación sin conexión requiere detener el servicio del clúster. El tiempo de parada depende del tiempo de reparación (entre 10 y 15 minutos).
2) Si hay problemas como superposición de regiones y agujeros, deben procesarse manualmente antes de ejecutar el comando de reparación fuera de línea OfflineMetaRepair.
4. herramienta hbase-operator-tools
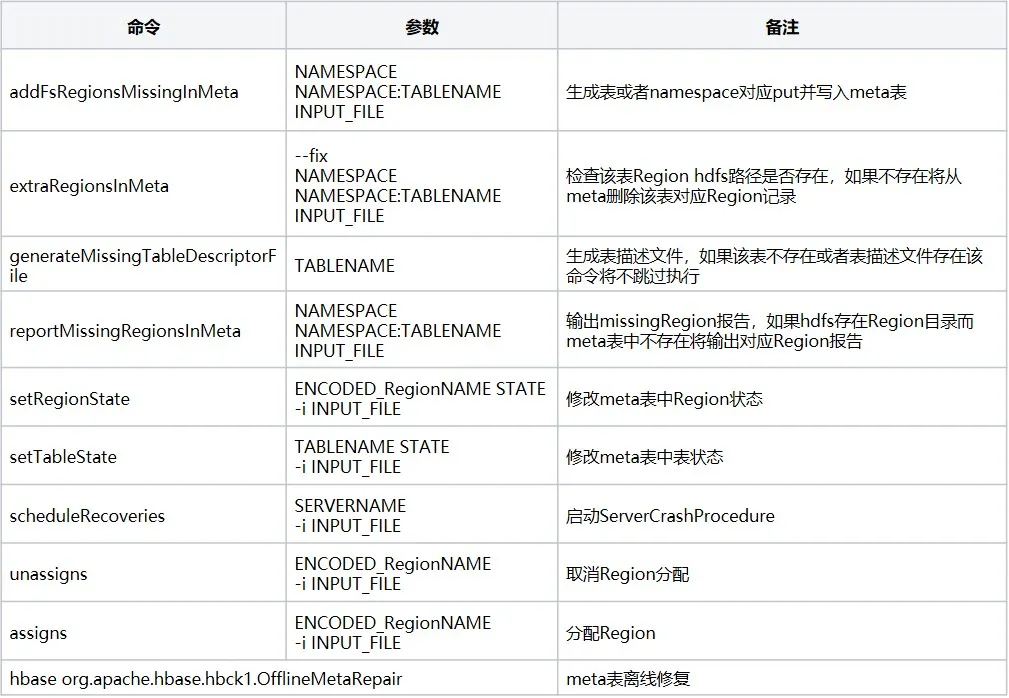
hbase-operator-tools es un conjunto de herramientas en HBase que se utilizan para ayudar a los administradores de HBase a administrar y mantener clústeres de HBase. hbase-operator-tools proporciona una serie de herramientas, incluidas herramientas de copia de seguridad y recuperación, herramientas de administración de regiones, herramientas de compresión y movimiento de datos, etc., que pueden ayudar a los administradores a administrar mejor los clústeres de HBase y mejorar la estabilidad y confiabilidad del clúster. Debe compilar el código fuente antes de poder usarlo. La dirección git del código fuente . Los comandos comunes son los siguientes:
5. Resumen
La precisión de los datos de la metatabla de HBase es crucial para el funcionamiento normal del clúster de HBase. Si no tiene una, es extremadamente importante cómo garantizar que los datos de la metatabla sean correctos y cómo repararlos rápidamente. Comprensión integral del meta, se sentirá perdido cada vez que el clúster falle. Este artículo se centra principalmente en el análisis del proceso de carga de la estructura de la metatabla, los problemas comunes y los métodos de reparación relacionados. Podemos dividir aproximadamente los métodos de reparación anteriores en las dos categorías siguientes:
-
Reparación en línea : la metatabla se puede reparar normalmente mediante hbck y herramientas de desarrollo propio para garantizar la integridad de los datos.
-
Reparación sin conexión : la metatabla no puede conectarse normalmente. La metatabla se reconstruye según la información de la región en HDFS para restaurar el servicio HBase.
Si la escala del clúster es relativamente grande y el tiempo de reparación fuera de línea es relativamente largo, el clúster debe detener los servicios durante un tiempo prolongado. En la mayoría de los casos, la empresa no puede tolerarlo según la situación real. a menos que el archivo de la metatabla esté dañado y no se pueda poner en línea normalmente). Se recomienda realizar comprobaciones hbck en el clúster con regularidad una vez que se produzca una inconsistencia en la metainformación, repararla lo antes posible para evitar la propagación del problema (por ejemplo, si la metainformación se ha estropeado y el clúster se reinicia y la región estropeada no se puede asignar, otras regiones no podrán conectarse normalmente). Si la inspección periódica encuentra que hay un desorden de metainformación en la tabla de negocios, reinícielo directamente. La metatabla elimina la información de la tabla y agrega la Región nuevamente a la metatabla según la información de la ruta hdfs (el comando addFsRegions-MissingInMeta puede agregar correctamente la Región a la metatabla según la ruta hdfs).
Artículo de referencia:
Los estudiantes de secundaria crean su propio lenguaje de programación de código abierto como una ceremonia de mayoría de edad: comentarios agudos de los internautas: confiando en la defensa, Apple lanzó el chip M4 RustDesk Los servicios nacionales fueron suspendidos debido al fraude desenfrenado Yunfeng renunció a Alibaba. En el futuro, planea producir un juego independiente en la plataforma Windows Taobao (taobao.com). Reiniciar el trabajo de optimización de la versión web, destino de los programadores, Visual Studio Code 1.89 lanza Java 17, la versión Java LTS más utilizada, Windows 10 tiene un cuota de mercado del 70%, Windows 11 continúa disminuyendo Open Source Daily | Google apoya a Hongmeng para que se haga cargo; Rabbit R1 de código abierto respalda los teléfonos Android; Haier Electric ha cerrado la plataforma abierta;