

▐ Lista negra de URL (filtro Bloom)
10 mil millones de URL de lista negra, cada 64 mil millones, ¿cómo guardar esta lista negra? Determinar si una URL está en la lista negra
Tabla de picadillo:
Si consideramos la lista negra como un conjunto y la almacenamos en un mapa hash, parece ser demasiado grande y requiere 640G, lo que obviamente no es científico.
Filtro de floración:
En realidad, es un vector binario largo y una serie de funciones de mapeo aleatorio.
Se puede utilizar para determinar si un elemento está en un conjunto . Su ventaja es que solo ocupa una pequeña cantidad de espacio de memoria y tiene una alta eficiencia de consulta. Para un filtro Bloom, su esencia es una matriz de bits : una matriz de bits significa que cada elemento de la matriz solo ocupa 1 bit y cada elemento solo puede ser 0 o 1.
Cada bit de la matriz es un bit binario. Además de una matriz de bits, el filtro Bloom también tiene funciones hash K. Cuando se agrega un elemento al filtro Bloom, se realizarán las siguientes operaciones:
Utilice funciones hash K para realizar cálculos K en el valor del elemento para obtener valores hash K.
Según el valor hash obtenido, el valor del subíndice correspondiente se establece en 1 en la matriz de bits.
▐Estadísticas de frecuencia de palabras (divididas en archivos)
Memoria de 2GB para encontrar el número más frecuente entre 2 mil millones de enteros
El método habitual es utilizar una tabla hash para hacer estadísticas de frecuencia de palabras para cada número que aparece. La clave de la tabla hash es un número entero y el valor registra la cantidad de veces que aparece el número entero. La cantidad de datos en esta pregunta es 2 mil millones. Es posible que un número aparezca 2 mil millones de veces. Para evitar el desbordamiento, la clave de la tabla hash es de 32 bits (4B) y el valor también es de 32 bits (4B). ). Entonces, un registro de una tabla hash debe ocupar 8B.
Cuando el número de registros de la tabla hash es 200 millones, se requieren 1,6 mil millones de bytes (8 * 200 millones) y al menos 1,6 GB de memoria (1,6 mil millones/2 ^ 30,1 GB == 2 ^ 30 bytes == 1000000000 ). Entonces, 2 mil millones de registros requieren al menos 16 GB de memoria, lo que no cumple con los requisitos de la pregunta.
La solución es utilizar la función hash para dividir el archivo grande con 2 mil millones de números en 16 archivos pequeños. Según la función hash, los 2 mil millones de datos se pueden distribuir uniformemente en los 16 archivos. la función hash en diferentes archivos pequeños, suponiendo que la función hash sea lo suficientemente buena. Luego use una función hash para cada archivo pequeño para contar el número de apariciones de cada número, de modo que obtengamos el número con más apariciones entre los 16 archivos, y luego seleccione la clave con mayor aparición de los 16 números.
▐Número que no aparece (matriz de bits)
Encuentra el número que no aparece entre 4 mil millones de enteros no negativos
Para el problema original, si se usa una tabla hash para guardar los números que han aparecido, entonces, en el peor de los casos, 4 mil millones de números son diferentes, entonces la tabla hash necesita guardar 4 mil millones de datos y se requiere un entero de 32 bits. 4B, luego 4 mil millones * 4B = 16 mil millones de bytes. Generalmente, alrededor de mil millones de bytes de datos requieren 1 G de espacio, por lo que se requieren alrededor de 16 G de espacio, lo que no cumple con los requisitos.
Cambiemos la forma y solicitemos una matriz de bits. El tamaño de la matriz es 4294967295, que son aproximadamente 4 mil millones de bits/8 = 500 millones de bytes, por lo que se necesitan 0,5 G de espacio para cada posición de la matriz de bits. 0 y 1. Entonces, ¿cómo utilizar esta matriz de bits? Jaja, la longitud de la matriz simplemente cumple con el rango numérico de nuestros números enteros, luego cada valor de subíndice de la matriz corresponde a un número en 4294967295 y atraviesa 4 mil millones de números sin signo uno por uno. Por ejemplo, si se encuentra 20, entonces bitArray. [20] = 1; cuando se encuentra 666, bitArray [666] = 1, después de atravesar todos los números, cambie la posición correspondiente de la matriz a 1.
Busque un número que no aparezca entre 4 mil millones de enteros no negativos. El límite de memoria es de 10 MB.
Mil millones de bytes de datos requieren aproximadamente 1 GB de espacio para procesarse, por lo que 10 MB de memoria pueden procesar 10 millones de bytes de datos, que son 80 millones de bits. Para 4 mil millones de enteros no negativos, si solicita una matriz de bits, 4 mil millones de bits. /080 millones de bits = 50, entonces su procesamiento costará al menos 50 bloques. Analicemos y respondamos usando 64 bloques.
Resumir las soluciones avanzadas
De acuerdo con el límite de memoria de 10 MB, determine el tamaño del intervalo estadístico, que es el tamaño de bitArr durante el segundo recorrido.
Utilice el conteo de intervalos para encontrar el intervalo con conteos insuficientes. Debe haber números en este intervalo que no aparecen.
Realice un mapeo de mapas de bits de los números en este intervalo y luego recorra el mapa de bits para encontrar un número que no aparece.
Mi propia opinion
Si solo está buscando un número, puede realizar operaciones de módulo de bits alto, escribirlo en 64 archivos diferentes y luego procesarlo todo a la vez a través de bitArray en el archivo más pequeño.
4 mil millones de enteros sin signo, 1 GB de memoria, encuentra todos los números que aparecen dos veces
Para el problema original, se puede utilizar un mapa de bits para representar la aparición de números. Específicamente, se aplica a una matriz de tipo de bits bitArr con una longitud de 4294967295 × 2. Se utilizan dos posiciones para representar la frecuencia de palabra de un número 1B, por lo que la matriz de tipo de bits con una longitud de 4294967295 × 2. Ocupa 1 GB de espacio. ¿Cómo utilizar esta matriz bitArr? Recorra estos 4 mil millones de números sin signo. Si encuentra num por primera vez, establezca bitArr[num 2+1] y bitArr[num 2] en 01. Si encuentra num por segunda vez, establezca bitArr[num 2+1]. y bitArr[num 2] se establecen en 10. Si se encuentra num por tercera vez, bitArr[num 2+1] y bitArr[num 2] se establecen en 11. Cuando vuelva a encontrar num en el futuro, encuentro que bitArr[num 2+1] y bitArr[num 2] se han configurado en 11 en este momento, por lo que no se realizan más configuraciones. Una vez completado el recorrido, recorra bitArr en secuencia. Si encuentra que bitArr [i 2 + 1] y bitArr [i 2] están configurados en 10, entonces i es el número que aparece dos veces.
▐URL duplicada (por máquina)
Encuentre URL duplicadas entre 10 mil millones de URL
La solución al problema original utiliza un método convencional para resolver problemas de big data: asignar archivos grandes a las máquinas mediante una función hash o dividir archivos grandes en archivos pequeños mediante una función hash. Esta división se realiza hasta que el resultado de la división cumpla con las restricciones de recursos. Primero, debe preguntarle al entrevistador cuáles son las limitaciones de recursos, incluidos los requisitos de memoria, tiempo de computación, etc. Después de aclarar los requisitos de restricción, cada URL se puede asignar a varias máquinas mediante una función hash o dividir en varios archivos pequeños. El número exacto de "varios" aquí se calcula en función de restricciones de recursos específicas.
Por ejemplo, un archivo grande de 10 mil millones de bytes se distribuye a 100 máquinas a través de una función hash, y luego cada máquina cuenta si hay URL duplicadas en las URL que se le asignan. Al mismo tiempo, la naturaleza de la función hash determina si. la misma URL es imposible distribuir la URL a diferentes máquinas o dividir el archivo grande en 1000 archivos pequeños a través de la función hash en una sola máquina y luego usar el recorrido de la tabla hash para cada archivo pequeño para encontrar URL duplicadas; distribuirlo a la máquina O después de dividir los archivos, ordenarlos y luego verificar si hay URL duplicadas después de ordenarlos. En resumen, tenga en cuenta que muchos problemas de big data son inseparables de la descarga. O bien la función hash distribuye el contenido del archivo grande a diferentes máquinas, o la función hash divide el archivo grande en archivos pequeños y luego procesa cada colección pequeña. .
▐ Búsqueda TOPK (pila raíz pequeña)
Busque una gran cantidad de palabras y encuentre las 100 palabras TOP más populares.
Al principio, utilizamos la idea de derivación de hash para desviar archivos de vocabulario que contienen decenas de miles de millones de datos a diferentes máquinas. El número específico de máquinas lo determinaba el entrevistador o más restricciones. Para cada máquina, si la cantidad de datos distribuidos aún es grande, por ejemplo debido a memoria insuficiente u otros problemas, se puede usar la función hash para dividir los archivos distribuidos de cada máquina en archivos más pequeños para su procesamiento.
Al procesar cada archivo pequeño, la tabla hash cuenta cada palabra y su frecuencia de palabras. Una vez establecido el registro de la tabla hash, se recorre la tabla hash durante el recorrido de la tabla hash, se utiliza un pequeño montón de raíz de tamaño 100 para seleccionar Obtener el. top100 de cada archivo pequeño (el top100 general sin clasificar). Cada archivo pequeño tiene su propio montón raíz pequeño de frecuencia de palabras (el top100 general sin clasificar). Al ordenar las palabras en el montón raíz pequeño según la frecuencia de palabras, se obtiene el top100 ordenado de cada archivo pequeño. Luego ordene los 100 primeros de cada archivo pequeño externamente o continúe usando el montón raíz pequeño para seleccionar los 100 primeros en cada máquina. Luego, los 100 primeros entre diferentes máquinas se clasifican externamente o continúan usando el pequeño montón raíz, y finalmente se obtienen los 100 primeros de las decenas de miles de millones de datos completos. Para el problema K superior, además de la desviación de la función hash y las estadísticas de frecuencia de palabras mediante tablas hash, a menudo se utilizan estructuras de montón y clasificación externa para solucionarlo.
▐Mediana (búsqueda binaria unidireccional)
10 MB de memoria, encuentre la mediana de 10 mil millones de números enteros
Suficiente memoria: si tienes suficiente memoria, ¿por qué preocuparte? Simplemente ordena los 10 mil millones de elementos. Puedes usar burbujeo... y luego encontrar el que está en el medio. ¿Pero crees que el entrevistador te dará memoria? ?
Memoria insuficiente: La pregunta dice que es un número entero, pero creemos que es un int con signo, por lo que tiene 4 bytes y ocupa 32 bits.
Suponga que se almacenan 10 mil millones de números en un archivo grande, lea parte del archivo en la memoria en secuencia (sin exceder el límite de memoria), represente cada número en binario y compare el bit más alto del binario (bit 32, bit de signo, 0 es positivo, 1 es negativo), si el bit más alto del número es 0, el número se escribe en el archivo file_0; si el bit más alto es 1, el número se escribe en el archivo file_1;
Por lo tanto, 10 mil millones de números se dividen en dos archivos. Supongamos que hay 6 mil millones de números en el archivo archivo_0 y 4 mil millones de números en el archivo archivo_1. Entonces, la mediana está en el archivo file_0 y es el número mil millones después de ordenar todos los números en el archivo file_0. (Los números en el archivo_1 son todos números negativos y los números en el archivo_0 son todos números positivos. Es decir, solo hay 4 mil millones de números negativos en total, por lo que el número 5 mil millones después de la clasificación debe ubicarse en el archivo_0)
Ahora, solo necesitamos procesar el archivo file_0 (ya no es necesario considerar el archivo file_1). Para el archivo file_0, tome las mismas medidas que arriba: lea parte del archivo file_0 en la memoria en secuencia (sin exceder el límite de memoria), represente cada número en binario, compare el segundo bit más alto del binario (el bit 31), si el segundo bit más alto del número es 0, escríbalo en el archivo file_0_0; si el segundo bit más alto es 1, escríbalo en el archivo file_0_1;
Ahora, suponiendo que hay 3 mil millones de números en archivo_0_0 y 3 mil millones de números en archivo_0_1, la mediana es: el número milmillonésimo después de que los números en archivo_0_0 estén ordenados de pequeño a grande.
Abandone el archivo file_0_1 y continúe dividiendo el archivo file_0_0 de acuerdo con el siguiente dígito más alto (la posición 30). Suponga que los dos archivos divididos esta vez son: hay 500 millones de números en file_0_0_0 y 2.5 mil millones de números en file_0_0_1. Luego, la mediana. es el número 500 millones después de ordenar todos los números en el archivo file_0_0_1.
De acuerdo con la idea anterior, hasta que el archivo dividido se pueda cargar directamente en la memoria, los números se pueden ordenar rápidamente y directamente para encontrar la mediana.
▐Sistema de nombres de dominio cortos (almacenamiento en caché)
Diseñe un sistema de nombres de dominio cortos para convertir URL largas en URL cortas.
Usando el asignador de números, el valor inicial es 0. Para cada solicitud de generación de enlace corto, el valor del asignador de números se incrementa y luego este valor se convierte a 62 hexadecimal (a-zA-Z0-9), como el primero solicitud En el momento de la solicitud, el valor del asignador de números es 0, correspondiente al hexadecimal a. En la segunda solicitud, el valor del asignador de números es 1, correspondiente al hexadecimal b. En la solicitud número 10001, el valor del asignador de números es 0. El asignador de números es 10000, correspondiente a La notación hexadecimal es sBc.
Concatene el nombre de dominio del servidor de enlace corto con el valor hexadecimal 62 del asignador como una cadena, que es la URL del enlace corto, por ejemplo: t.cn/sBc.
Proceso de redirección: después de generar un enlace corto, debe almacenar la relación de mapeo entre el enlace corto y el enlace largo, es decir, sBc -> URL Cuando el navegador accede al servidor de enlace corto, obtiene el enlace original de acuerdo con el. Ruta URL y luego realiza una redirección 302. Las relaciones de mapeo se pueden almacenar usando KV, como Redis o Memcache.
▐Almacenamiento masivo de comentarios (cola de mensajes)
Supongamos que existe tal escenario. Hay una noticia y la cantidad de comentarios en la noticia puede ser grande.
La página de inicio se muestra directamente al usuario y se almacena en la base de datos de forma asincrónica a través de la cola de mensajes.
▐Número de usuarios en línea/concurrentes (Redis)
-
Ideas de soluciones para mostrar el número de usuarios en línea en un sitio web
-
Mantener tabla de usuarios en línea -
Usando estadísticas de Redis
-
Mostrar el número de usuarios simultáneos del sitio web.
-
Cada vez que un usuario accede al servicio, la identificación del usuario se escribe en la cola ZSORT y el peso es la hora actual; -
Calcule el número de usuarios de la organización Zrange en un minuto en función del peso (es decir, el tiempo); -
Eliminar usuarios Zrem que hayan caducado durante más de un minuto;
▐Cadenas populares (árbol de prefijos)
Método HashMap
Aunque el número total de cadenas es relativamente grande, no excede los 300w después de la deduplicación. Por lo tanto, puede considerar guardar todas las cadenas y sus tiempos de aparición en un HashMap. El espacio ocupado es 300w*(255+4)≈777M (de los cuales). 4 Representa los 4 bytes que ocupa el número entero). Se puede ver que 1G de espacio de memoria es completamente suficiente.
La idea es la siguiente
Primero, recorra la cadena si no está en el mapa, guárdela directamente en el mapa y el valor se registra como 1; si está en el mapa, agregue 1 al valor correspondiente.O(N)
Luego recorra el mapa para construir un pequeño montón superior de 10 elementos. Si el número de apariciones de la cadena atravesada es mayor que el número de apariciones de la cadena en la parte superior del montón, reemplácelo y ajuste el montón a una parte superior pequeña. montón.
Una vez completado el recorrido, las 10 cadenas del montón son las que aparecen con más frecuencia. La complejidad temporal de este paso O(Nlog10).
método de árbol de prefijos
Cuando estas cadenas tienen una gran cantidad de prefijos iguales, puede considerar usar un árbol de prefijos para contar la cantidad de ocurrencias de la cadena. Los nodos del árbol guardan la cantidad de ocurrencias de la cadena, y 0 significa que no ocurre.
La idea es la siguiente
Al atravesar la cadena, busque en el árbol de prefijos. Si se encuentra, agregue 1 al número de cadenas almacenadas en el nodo. De lo contrario, cree un nuevo nodo para esta cadena. Una vez completada la construcción, agregue la aparición de la cadena. nodo hoja. El número de veces se establece en 1.
Finalmente, el montón superior pequeño todavía se usa para ordenar el número de apariciones de la cadena.
▐Algoritmo del sobre rojo
Método de corte lineal, cortando cuchillos N-1 en un intervalo. Cuanto antes mejor
Método de media doble, aleatorio en [0~cantidad restante/número de personas restantes*2], relativamente uniforme

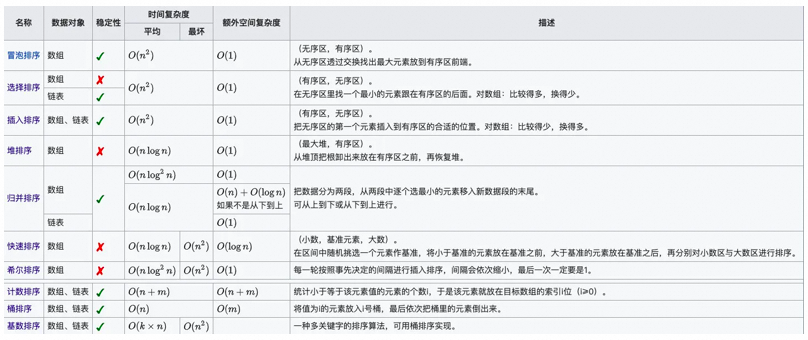
▐Clasificación rápida de escritura a mano
public class QuickSort {public static void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;}/* 常规快排 */public static void quickSort1(int[] arr, int L , int R) {if (L > R) return;int M = partition(arr, L, R);quickSort1(arr, L, M - 1);quickSort1(arr, M + 1, R);}public static int partition(int[] arr, int L, int R) {if (L > R) return -1;if (L == R) return L;int lessEqual = L - 1;int index = L;while (index < R) {if (arr[index] <= arr[R])swap(arr, index, ++lessEqual);index++;}swap(arr, ++lessEqual, R);return lessEqual;}/* 荷兰国旗 */public static void quickSort2(int[] arr, int L, int R) {if (L > R) return;int[] equalArea = netherlandsFlag(arr, L, R);quickSort2(arr, L, equalArea[0] - 1);quickSort2(arr, equalArea[1] + 1, R);}public static int[] netherlandsFlag(int[] arr, int L, int R) {if (L > R) return new int[] { -1, -1 };if (L == R) return new int[] { L, R };int less = L - 1;int more = R;int index = L;while (index < more) {if (arr[index] == arr[R]) {index++;} else if (arr[index] < arr[R]) {swap(arr, index++, ++less);} else {swap(arr, index, --more);}}swap(arr, more, R);return new int[] { less + 1, more };}// for testpublic static void main(String[] args) {int testTime = 1;int maxSize = 10000000;int maxValue = 100000;boolean succeed = true;long T1=0,T2=0;for (int i = 0; i < testTime; i++) {int[] arr1 = generateRandomArray(maxSize, maxValue);int[] arr2 = copyArray(arr1);int[] arr3 = copyArray(arr1);// int[] arr1 = {9,8,7,6,5,4,3,2,1};long t1 = System.currentTimeMillis();quickSort1(arr1,0,arr1.length-1);long t2 = System.currentTimeMillis();quickSort2(arr2,0,arr2.length-1);long t3 = System.currentTimeMillis();T1 += (t2-t1);T2 += (t3-t2);if (!isEqual(arr1, arr2) || !isEqual(arr2, arr3)) {succeed = false;break;}}System.out.println(T1+" "+T2);// System.out.println(succeed ? "Nice!" : "Oops!");}private static int[] generateRandomArray(int maxSize, int maxValue) {int[] arr = new int[(int) ((maxSize + 1) * Math.random())];for (int i = 0; i < arr.length; i++) {arr[i] = (int) ((maxValue + 1) * Math.random())- (int) (maxValue * Math.random());}return arr;}private static int[] copyArray(int[] arr) {if (arr == null) return null;int[] res = new int[arr.length];for (int i = 0; i < arr.length; i++) {res[i] = arr[i];}return res;}private static boolean isEqual(int[] arr1, int[] arr2) {if ((arr1 == null && arr2 != null) || (arr1 != null && arr2 == null))return false;if (arr1 == null && arr2 == null)return true;if (arr1.length != arr2.length)return false;for (int i = 0; i < arr1.length; i++)if (arr1[i] != arr2[i])return false;return true;}private static void printArray(int[] arr) {if (arr == null)return;for (int i = 0; i < arr.length; i++)System.out.print(arr[i] + " ");System.out.println();}}
▐Fusión de escritura a mano
public static void merge(int[] arr, int L, int M, int R) {int[] help = new int[R - L + 1];int i = 0;int p1 = L;int p2 = M + 1;while (p1 <= M && p2 <= R)help[i++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++];while (p1 <= M)help[i++] = arr[p1++];while (p2 <= R)help[i++] = arr[p2++];for (i = 0; i < help.length; i++)arr[L + i] = help[i];}public static void mergeSort(int[] arr, int L, int R) {if (L == R)return;int mid = L + ((R - L) >> 1);process(arr, L, mid);process(arr, mid + 1, R);merge(arr, L, mid, R);}public static void main(String[] args) {int[] arr1 = {9,8,7,6,5,4,3,2,1};mergeSort(arr, 0, arr.length - 1);printArray(arr);}
▐Pilas escritas a mano
// 堆排序额外空间复杂度O(1)public static void heapSort(int[] arr) {if (arr == null || arr.length < 2)return;for (int i = arr.length - 1; i >= 0; i--)heapify(arr, i, arr.length);int heapSize = arr.length;swap(arr, 0, --heapSize);// O(N*logN)while (heapSize > 0) { // O(N)heapify(arr, 0, heapSize); // O(logN)swap(arr, 0, --heapSize); // O(1)}}// arr[index]刚来的数,往上public static void heapInsert(int[] arr, int index) {while (arr[index] > arr[(index - 1) / 2]) {swap(arr, index, (index - 1) / 2);index = (index - 1) / 2;}}// arr[index]位置的数,能否往下移动public static void heapify(int[] arr, int index, int heapSize) {int left = index * 2 + 1; // 左孩子的下标while (left < heapSize) { // 下方还有孩子的时候// 两个孩子中,谁的值大,把下标给largest// 1)只有左孩子,left -> largest// 2) 同时有左孩子和右孩子,右孩子的值<= 左孩子的值,left -> largest// 3) 同时有左孩子和右孩子并且右孩子的值> 左孩子的值, right -> largestint largest = left+1 < heapSize && arr[left+1]> arr[left] ? left+1 : left;// 父和较大的孩子之间,谁的值大,把下标给largestlargest = arr[largest] > arr[index] ? largest : index;if (largest == index)break;swap(arr, largest, index);index = largest;left = index * 2 + 1;}}public static void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;}public static void main(String[] args) {int[] arr1 = {9,8,7,6,5,4,3,2,1};heapSort(arr1);printArray(arr1);}
▐Singleton escrito a mano
public class Singleton {private volatile static Singleton singleton;private Singleton() {}public static Singleton getSingleton() {if (singleton == null) {synchronized (Singleton.class) {if (singleton == null) {singleton = new Singleton();}}}return singleton;}}
▐ LRUcache escrito a mano
// 基于linkedHashMappublic class LRUCache {private LinkedHashMap<Integer,Integer> cache;private int capacity; //容量大小public LRUCache(int capacity) {cache = new LinkedHashMap<>(capacity);this.capacity = capacity;}public int get(int key) {//缓存中不存在此key,直接返回if(!cache.containsKey(key)) {return -1;}int res = cache.get(key);cache.remove(key); //先从链表中删除cache.put(key,res); //再把该节点放到链表末尾处return res;}public void put(int key,int value) {if(cache.containsKey(key)) {cache.remove(key); //已经存在,在当前链表移除}if(capacity == cache.size()) {//cache已满,删除链表头位置Set<Integer> keySet = cache.keySet();Iterator<Integer> iterator = keySet.iterator();cache.remove(iterator.next());}cache.put(key,value); //插入到链表末尾}}
//手写双向链表class LRUCache {class DNode {DNode prev;DNode next;int val;int key;}Map<Integer, DNode> map = new HashMap<>();DNode head, tail;int cap;public LRUCache(int capacity) {head = new DNode();tail = new DNode();head.next = tail;tail.prev = head;cap = capacity;}public int get(int key) {if (map.containsKey(key)) {DNode node = map.get(key);removeNode(node);addToHead(node);return node.val;} else {return -1;}}public void put(int key, int value) {if (map.containsKey(key)) {DNode node = map.get(key);node.val = value;removeNode(node);addToHead(node);} else {DNode newNode = new DNode();newNode.val = value;newNode.key = key;addToHead(newNode);map.put(key, newNode);if (map.size() > cap) {map.remove(tail.prev.key);removeNode(tail.prev);}}}public void removeNode(DNode node) {DNode prevNode = node.prev;DNode nextNode = node.next;prevNode.next = nextNode;nextNode.prev = prevNode;}public void addToHead(DNode node) {DNode firstNode = head.next;head.next = node;node.prev = head;node.next = firstNode;firstNode.prev = node;}}
▐Grupo de hilos de escritura a mano
package com.concurrent.pool;import java.util.HashSet;import java.util.Set;import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.BlockingQueue;public class MySelfThreadPool {//默认线程池中的线程的数量private static final int WORK_NUM = 5;//默认处理任务的数量private static final int TASK_NUM = 100;private int workNum;//线程数量private int taskNum;//任务数量private final Set<WorkThread> workThreads;//保存线程的集合private final BlockingQueue<Runnable> taskQueue;//阻塞有序队列存放任务public MySelfThreadPool() {this(WORK_NUM, TASK_NUM);}public MySelfThreadPool(int workNum, int taskNum) {if (workNum <= 0) workNum = WORK_NUM;if (taskNum <= 0) taskNum = TASK_NUM;taskQueue = new ArrayBlockingQueue<>(taskNum);this.workNum = workNum;this.taskNum = taskNum;workThreads = new HashSet<>();//启动一定数量的线程数,从队列中获取任务处理for (int i=0;i<workNum;i++) {WorkThread workThread = new WorkThread("thead_"+i);workThread.start();workThreads.add(workThread);}}public void execute(Runnable task) {try {taskQueue.put(task);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}}public void destroy() {System.out.println("ready close thread pool...");if (workThreads == null || workThreads.isEmpty()) return ;for (WorkThread workThread : workThreads) {workThread.stopWork();workThread = null;//help gc}workThreads.clear();}private class WorkThread extends Thread{public WorkThread(String name) {super();setName(name);}@Overridepublic void run() {while (!interrupted()) {try {Runnable runnable = taskQueue.take();//获取任务if (runnable !=null) {System.out.println(getName()+" readyexecute:"+runnable.toString());runnable.run();//执行任务}runnable = null;//help gc} catch (Exception e) {interrupt();e.printStackTrace();}}}public void stopWork() {interrupt();}}}package com.concurrent.pool;public class TestMySelfThreadPool {private static final int TASK_NUM = 50;//任务的个数public static void main(String[] args) {MySelfThreadPool myPool = new MySelfThreadPool(3,50);for (int i=0;i<TASK_NUM;i++) {myPool.execute(new MyTask("task_"+i));}}static class MyTask implements Runnable{private String name;public MyTask(String name) {this.name = name;}public String getName() {return name;}public void setName(String name) {this.name = name;}@Overridepublic void run() {try {Thread.sleep(1000);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}System.out.println("task :"+name+" end...");}@Overridepublic String toString() {// TODO Auto-generated method stubreturn "name = "+name;}}}
▐Patrón de productor de consumo escrito a mano
public class Storage {private static int MAX_VALUE = 100;private List<Object> list = new ArrayList<>();public void produce(int num) {synchronized (list) {while (list.size() + num > MAX_VALUE) {System.out.println("暂时不能执行生产任务");try {list.wait();} catch (InterruptedException e) {e.printStackTrace();}}for (int i = 0; i < num; i++) {list.add(new Object());}System.out.println("已生产产品数"+num+" 仓库容量"+list.size());list.notifyAll();}}public void consume(int num) {synchronized (list) {while (list.size() < num) {System.out.println("暂时不能执行消费任务");try {list.wait();} catch (InterruptedException e) {e.printStackTrace();}}for (int i = 0; i < num; i++) {list.remove(0);}System.out.println("已消费产品数"+num+" 仓库容量" + list.size());list.notifyAll();}}}public class Producer extends Thread {private int num;private Storage storage;public Producer(Storage storage) {this.storage = storage;}public void setNum(int num) {this.num = num;}public void run() {storage.produce(this.num);}}public class Customer extends Thread {private int num;private Storage storage;public Customer(Storage storage) {this.storage = storage;}public void setNum(int num) {this.num = num;}public void run() {storage.consume(this.num);}}public class Test {public static void main(String[] args) {Storage storage = new Storage();Producer p1 = new Producer(storage);Producer p2 = new Producer(storage);Producer p3 = new Producer(storage);Producer p4 = new Producer(storage);Customer c1 = new Customer(storage);Customer c2 = new Customer(storage);Customer c3 = new Customer(storage);p1.setNum(10);p2.setNum(20);p3.setNum(80);c1.setNum(50);c2.setNum(20);c3.setNum(20);c1.start();c2.start();c3.start();p1.start();p2.start();p3.start();}}
▐Cola de bloqueo de escritura a mano
public class blockQueue {private List<Integer> container = new ArrayList<>();private volatile int size;private volatile int capacity;private Lock lock = new ReentrantLock();private final Condition isNull = lock.newCondition();private final Condition isFull = lock.newCondition();blockQueue(int capacity) {this.capacity = capacity;}public void add(int data) {try {lock.lock();try {while (size >= capacity) {System.out.println("阻塞队列满了");isFull.await();}} catch (Exception e) {isFull.signal();e.printStackTrace();}++size;container.add(data);isNull.signal();} finally {lock.unlock();}}public int take() {try {lock.lock();try {while (size == 0) {System.out.println("阻塞队列空了");isNull.await();}} catch (Exception e) {isNull.signal();e.printStackTrace();}--size;int res = container.get(0);container.remove(0);isFull.signal();return res;} finally {lock.unlock();}}}public static void main(String[] args) {AxinBlockQueue queue = new AxinBlockQueue(5);Thread t1 = new Thread(() -> {for (int i = 0; i < 100; i++) {queue.add(i);System.out.println("塞入" + i);try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}}});Thread t2 = new Thread(() -> {for (; ; ) {System.out.println("消费"+queue.take());try {Thread.sleep(800);} catch (InterruptedException e) {e.printStackTrace();}}});t1.start();t2.start();}
▐ABC de impresión alternativa multiproceso manuscrita
package com.demo.test;import java.util.concurrent.locks.Condition;import java.util.concurrent.locks.ReentrantLock;public class syncPrinter implements Runnable{// 打印次数private static final int PRINT_COUNT = 10;private final ReentrantLock reentrantLock;private final Condition thisCondtion;private final Condition nextCondtion;private final char printChar;public syncPrinter(ReentrantLock reentrantLock, Condition thisCondtion, Condition nextCondition, char printChar) {this.reentrantLock = reentrantLock;this.nextCondtion = nextCondition;this.thisCondtion = thisCondtion;this.printChar = printChar;}@Overridepublic void run() {// 获取打印锁 进入临界区reentrantLock.lock();try {// 连续打印PRINT_COUNT次for (int i = 0; i < PRINT_COUNT; i++) {//打印字符System.out.print(printChar);// 使用nextCondition唤醒下一个线程// 因为只有一个线程在等待,所以signal或者signalAll都可以nextCondtion.signal();// 不是最后一次则通过thisCondtion等待被唤醒// 必须要加判断,不然虽然能够打印10次,但10次后就会直接死锁if (i < PRINT_COUNT - 1) {try {// 本线程让出锁并等待唤醒thisCondtion.await();} catch (InterruptedException e) {e.printStackTrace();}}}} finally {reentrantLock.unlock();}}public static void main(String[] args) throws InterruptedException {ReentrantLock lock = new ReentrantLock();Condition conditionA = lock.newCondition();Condition conditionB = lock.newCondition();Condition conditionC = lock.newCondition();Thread printA = new Thread(new syncPrinter(lock, conditionA, conditionB,'A'));Thread printB = new Thread(new syncPrinter(lock, conditionB, conditionC,'B'));Thread printC = new Thread(new syncPrinter(lock, conditionC, conditionA,'C'));printA.start();Thread.sleep(100);printB.start();Thread.sleep(100);printC.start();}}
▐Imprimir alternativamente FooBar
//手太阴肺经 BLOCKING Queuepublic class FooBar {private int n;private BlockingQueue<Integer> bar = new LinkedBlockingQueue<>(1);private BlockingQueue<Integer> foo = new LinkedBlockingQueue<>(1);public FooBar(int n) {this.n = n;}public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {foo.put(i);printFoo.run();bar.put(i);}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {bar.take();printBar.run();foo.take();}}}//手阳明大肠经CyclicBarrier 控制先后class FooBar6 {private int n;public FooBar6(int n) {this.n = n;}CyclicBarrier cb = new CyclicBarrier(2);volatile boolean fin = true;public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {while(!fin);printFoo.run();fin = false;try {cb.await();} catch (BrokenBarrierException e) {}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {try {cb.await();} catch (BrokenBarrierException e) {}printBar.run();fin = true;}}}//手少阴心经 自旋 + 让出CPUclass FooBar5 {private int n;public FooBar5(int n) {this.n = n;}volatile boolean permitFoo = true;public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; ) {if(permitFoo) {printFoo.run();i++;permitFoo = false;}else{Thread.yield();}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; ) {if(!permitFoo) {printBar.run();i++;permitFoo = true;}else{Thread.yield();}}}}//手少阳三焦经 可重入锁 + Conditionclass FooBar4 {private int n;public FooBar4(int n) {this.n = n;}Lock lock = new ReentrantLock(true);private final Condition foo = lock.newCondition();volatile boolean flag = true;public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {lock.lock();try {while(!flag) {foo.await();}printFoo.run();flag = false;foo.signal();}finally {lock.unlock();}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n;i++) {lock.lock();try {while(flag) {foo.await();}printBar.run();flag = true;foo.signal();}finally {lock.unlock();}}}}//手厥阴心包经 synchronized + 标志位 + 唤醒class FooBar3 {private int n;// 标志位,控制执行顺序,true执行printFoo,false执行printBarprivate volatile boolean type = true;private final Object foo= new Object(); // 锁标志public FooBar3(int n) {this.n = n;}public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {synchronized (foo) {while(!type){foo.wait();}printFoo.run();type = false;foo.notifyAll();}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {synchronized (foo) {while(type){foo.wait();}printBar.run();type = true;foo.notifyAll();}}}}//手太阳小肠经 信号量 适合控制顺序class FooBar2 {private int n;private Semaphore foo = new Semaphore(1);private Semaphore bar = new Semaphore(0);public FooBar2(int n) {this.n = n;}public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {foo.acquire();printFoo.run();bar.release();}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {bar.acquire();printBar.run();foo.release();}}}
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。