
-
En primer lugar, las puntuaciones de diferentes tipos de consultas no se encuentran en la misma dimensión comparable, por lo que no se pueden realizar cálculos aritméticos simples directamente.
-
En segundo lugar, en un sistema de recuperación distribuido, las puntuaciones suelen estar en el nivel de fragmentos y las puntuaciones de todos los fragmentos deben normalizarse globalmente.
-
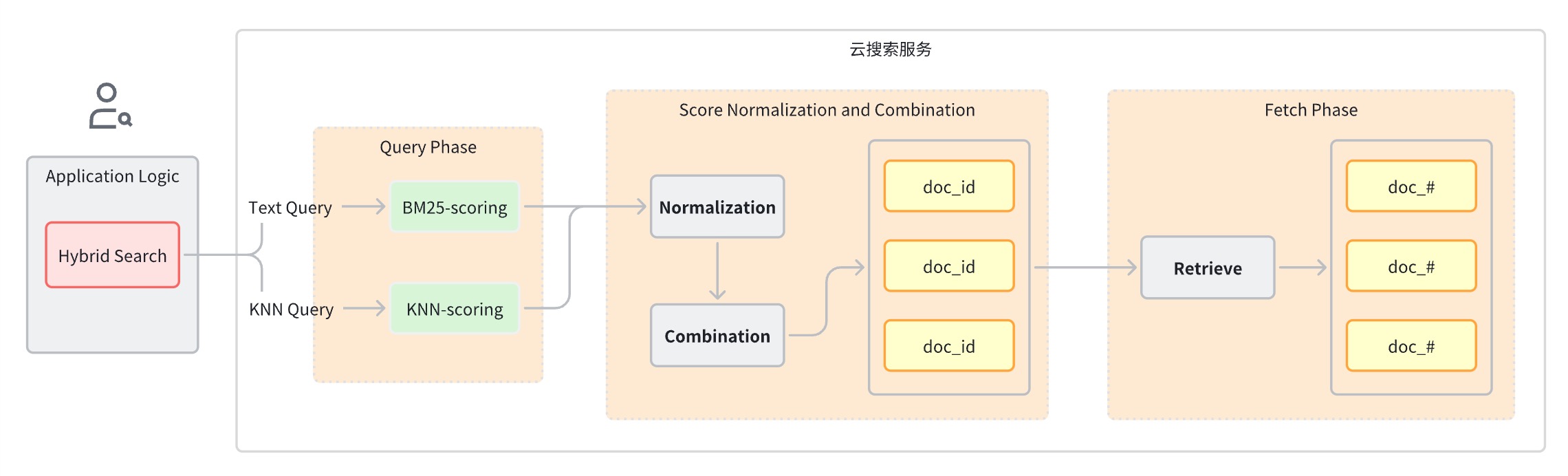
Fase de consulta: utilice cláusulas de consulta mixtas para la búsqueda por palabras clave y la búsqueda semántica.
-
Etapa de normalización y fusión de puntuaciones, que sigue a la etapa de consulta.
-
Dado que cada tipo de consulta proporcionará un rango diferente de puntuaciones, esta etapa realiza una operación de normalización en los resultados de puntuación de cada cláusula de consulta. Los métodos de normalización admitidos son min_max, l2 y rrf.
-
Para combinar las puntuaciones normalizadas, los métodos de combinación incluyen media_aritmética, media_geométrica y media_armónica.
-
-
Los documentos se reordenan según las calificaciones combinadas y se devuelven al usuario.
Ideas de implementación
-
Buscador de texto completo
-
motor de búsqueda vectorial
-
Modelo de aprendizaje automático para incrustación de vectores
-
Canalización de datos que convierte texto, audio, video y otros datos en vectores
-
Clasificación por fusión

-
Configurar y crear objetos relacionados.
-
Canalización de ingesta: admite llamar automáticamente al modelo para almacenar vectores de conversión de imágenes en el índice.
-
Canal de búsqueda: admite la conversión automática de declaraciones de consulta de texto en vectores para el cálculo de similitud
-
Índice k-NN: el índice donde se almacena el vector
-
-
Escriba los datos del conjunto de datos de imágenes en la instancia de OpenSearch y OpenSearch llamará automáticamente al modelo de aprendizaje automático para convertir el texto en un vector de incrustación.
-
Cuando el cliente inicia una consulta de búsqueda híbrida, OpenSearch llama al modelo de aprendizaje automático para convertir la consulta entrante en un vector de incrustación.
-
OpenSearch realiza un procesamiento de solicitudes de búsqueda híbrida, combina puntuaciones de búsqueda de palabras clave y búsqueda semántica y devuelve resultados de búsqueda.
Planificar el combate real
Preparación ambiental
-
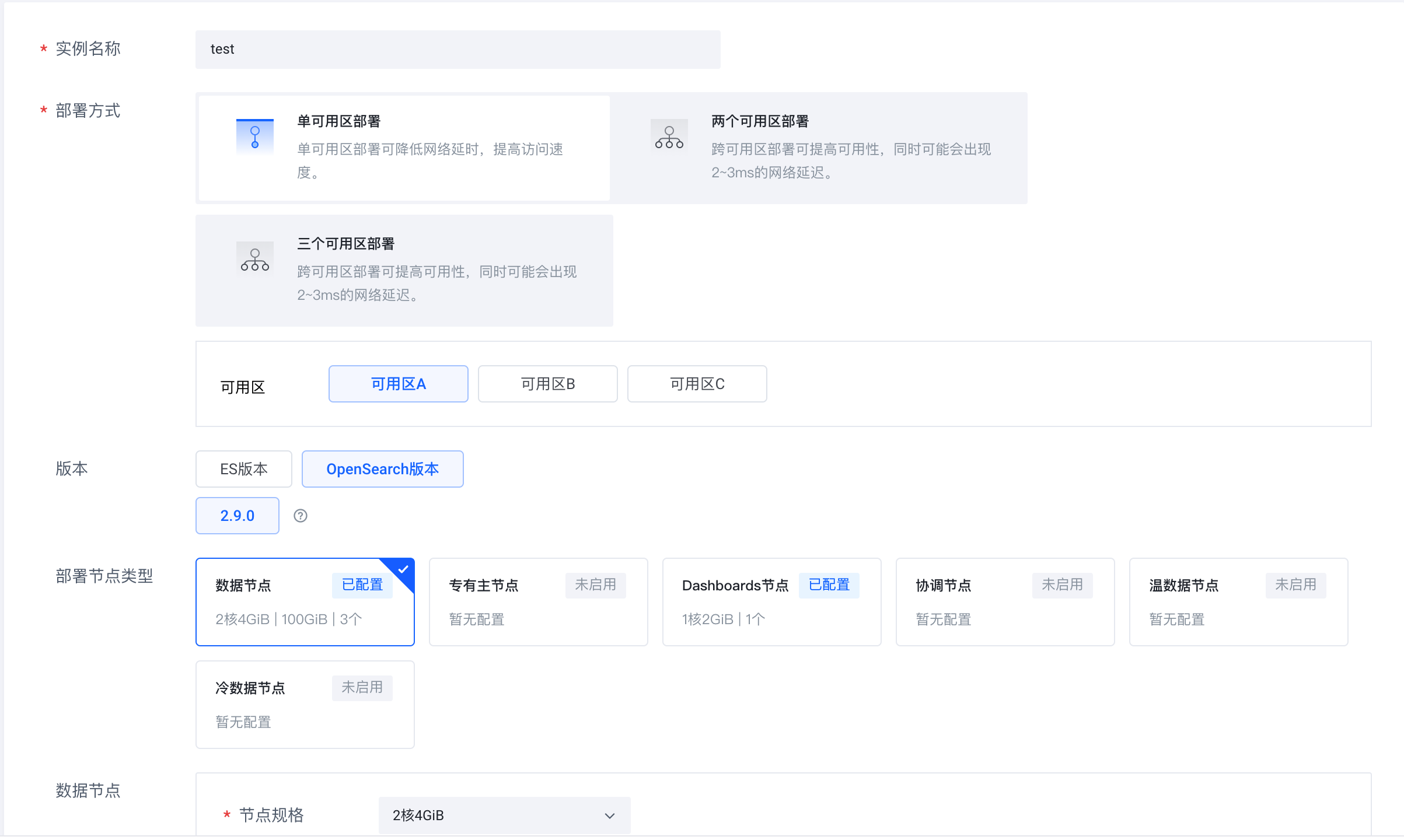
Inicie sesión en el servicio de búsqueda en la nube de Volcano Engine (https://console.volcengine.com/es), cree un clúster de instancias y seleccione OpenSearch 2.9.0 como versión.
-
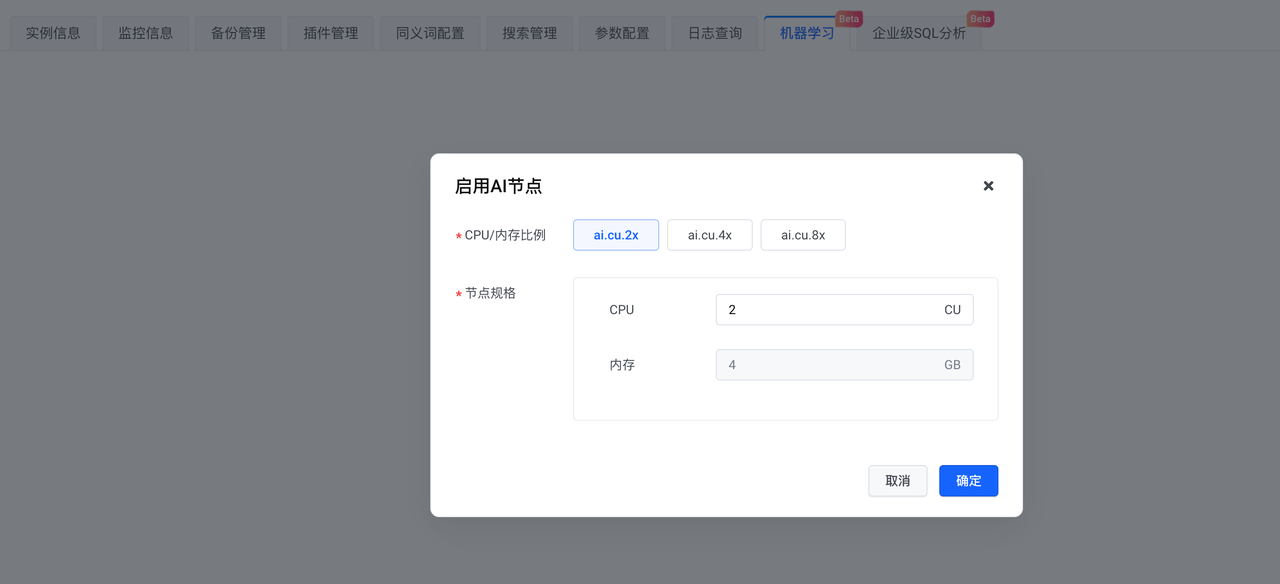
Una vez creada la instancia, habilite el nodo AI.
-
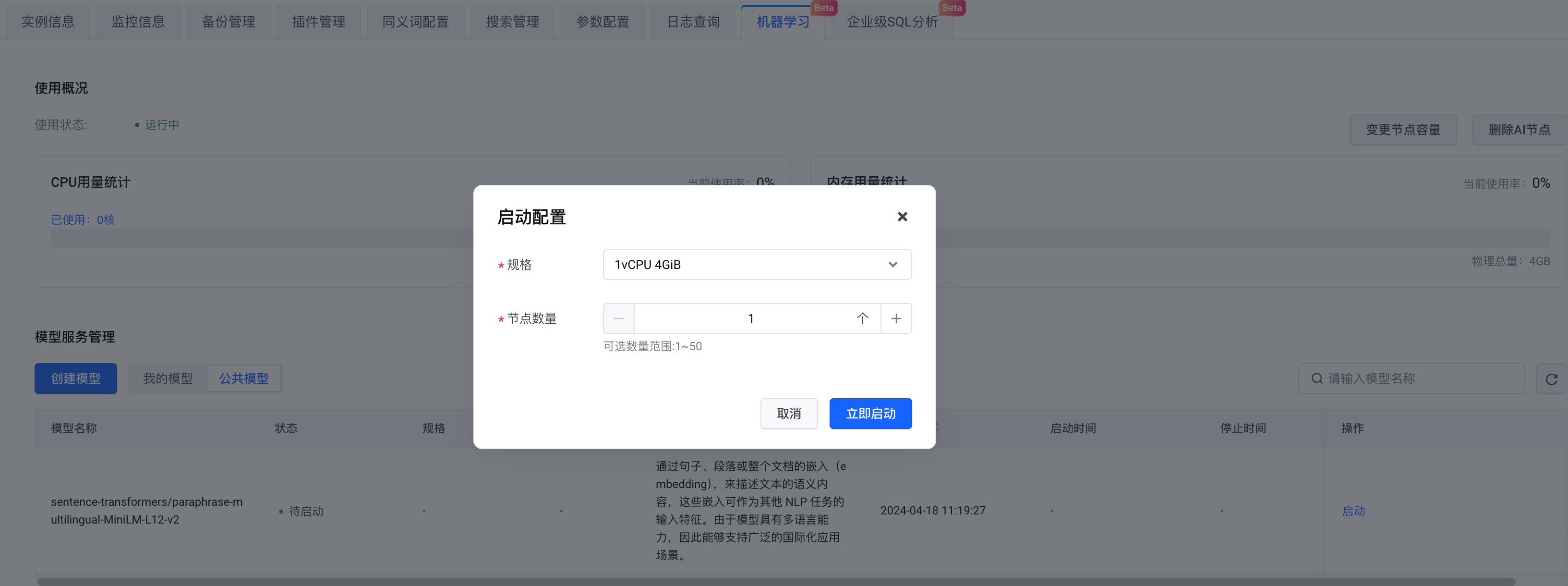
En términos de selección de modelo, puedes crear tu propio modelo o elegir un modelo público. Aquí seleccionamos el modelo público . Después de completar la configuración, hacemos clic en Iniciar ahora .
Preparación del conjunto de datos
Pasos
Instalar dependencias de Python
pip install -U elasticsearch7==7.10.1
pip install -U pandas
pip install -U jupyter
pip install -U requests
pip install -U s3fs
pip install -U alive_progress
pip install -U pillow
pip install -U ipythonConéctese a OpenSearch
# Prepare opensearch info
from elasticsearch7 import Elasticsearch as CloudSearch
from ssl import create_default_context
# opensearch info
opensearch_domain = '{{ OPENSEARCH_DOMAIN }}'
opensearch_port = '9200'
opensearch_user = 'admin'
opensearch_pwd = '{{ OPENSEARCH_PWD }}'
# remote config for model server
model_remote_config = {
"method": "POST",
"url": "{{ REMOTE_MODEL_URL }}",
"params": {},
"headers": {
"Content-Type": "application/json"
},
"advance_request_body": {
"model": "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
}
}
# dimension for knn vector
knn_dimension = 384
# load cer and create ssl context
ssl_context = create_default_context(cafile='./ca.cer')
# create CloudSearch client
cloud_search_cli = CloudSearch([opensearch_domain, opensearch_port],
ssl_context=ssl_context,
scheme="https",
http_auth=(opensearch_user, opensearch_pwd)
)
# index name
index_name = 'index-test'
# pipeline id
pipeline_id = 'remote_text_embedding_test'
# search pipeline id
search_pipeline_id = 'rrf_search_pipeline_test'-
Complete la dirección del enlace de OpenSearch y la información de nombre de usuario y contraseña. model_remote_config es la configuración de conexión del modelo de aprendizaje automático remoto, que se puede ver en la información de llamada del modelo. Copie todas las configuraciones de remote_config en la información de llamada a model_remote_config .
-
En la sección Información de instancia- > Acceso al servicio , descargue el certificado en el directorio actual.
-
Se le da un nombre de índice, un ID de canalización y un ID de canalización de búsqueda.
Crear canalización de ingesta
# Create ingest pipeline
pipeline_body = {
"description": "text embedding pipeline for remote inference",
"processors": [{
"remote_text_embedding": {
"remote_config": model_remote_config,
"field_map": {
"caption": "caption_embedding"
}
}
}]
}
# create request
resp = cloud_search_cli.ingest.put_pipeline(id=pipeline_id, body=pipeline_body)
print(resp)Crear canal de búsqueda
-
Método de normalización:
min_max,l2,rrf -
Método de suma ponderada:
arithmetic_mean,geometric_mean,harmonic_mean
# Create search pipeline
import requests
search_pipeline_body = {
"description": "post processor for hybrid search",
"request_processors": [{
"remote_embedding": {
"remote_config": model_remote_config
}
}],
"phase_results_processors": [ # normalization and combination
{
"normalization-processor": {
"normalization": {
"technique": "rrf", # the normalization technique in the processor is set to rrf
"parameters": {
"rank_constant": 60 # param
}
},
"combination": {
"technique": "arithmetic_mean", # the combination technique is set to arithmetic mean
"parameters": {
"weights": [
0.4,
0.6
]
}
}
}
}
]
}
headers = {
'Content-Type': 'application/json',
}
# create request
resp = requests.put(
url="https://" + opensearch_domain + ':' + opensearch_port + '/_search/pipeline/' + search_pipeline_id,
auth=(opensearch_user, opensearch_pwd),
json=search_pipeline_body,
headers=headers,
verify='./ca.cer')
print(resp.text)Crear índice k-NN
-
Configure la canalización de ingesta creada previamente en el campo index.default_pipeline ;
-
Al mismo tiempo, configure las propiedades y establezca caption_embedding en knn_vector. Aquí usamos hnsw en faiss.
# Create k-NN index
# create index and set settings, mappings, and properties as needed.
index_body = {
"settings": {
"index.knn": True,
"number_of_shards": 1,
"number_of_replicas": 0,
"default_pipeline": pipeline_id # ingest pipeline
},
"mappings": {
"properties": {
"image_url": {
"type": "text"
},
"caption_embedding": {
"type": "knn_vector",
"dimension": knn_dimension,
"method": {
"engine": "faiss",
"space_type": "l2",
"name": "hnsw",
"parameters": {}
}
},
"caption": {
"type": "text"
}
}
}
}
# create index
resp = cloud_search_cli.indices.create(index=index_name, body=index_body)
print(resp)Cargar conjunto de datos
# Prepare dataset
import pandas as pd
import string
appended_data = []
for character in string.digits[0:] + string.ascii_lowercase:
if character == '1':
break
try:
meta = pd.read_json("s3://amazon-berkeley-objects/listings/metadata/listings_" + character + ".json.gz",
lines=True)
except FileNotFoundError:
continue
appended_data.append(meta)
appended_data_frame = pd.concat(appended_data)
appended_data_frame.shape
meta = appended_data_frame
def func_(x):
us_texts = [item["value"] for item in x if item["language_tag"] == "en_US"]
return us_texts[0] if us_texts else None
meta = meta.assign(item_name_in_en_us=meta.item_name.apply(func_))
meta = meta[~meta.item_name_in_en_us.isna()][["item_id", "item_name_in_en_us", "main_image_id"]]
print(f"#products with US English title: {len(meta)}")
meta.head()
image_meta = pd.read_csv("s3://amazon-berkeley-objects/images/metadata/images.csv.gz")
dataset = meta.merge(image_meta, left_on="main_image_id", right_on="image_id")
dataset.head()Cargar conjunto de datos
# Upload dataset
import json
from alive_progress import alive_bar
cnt = 0
batch = 0
action = json.dumps({"index": {"_index": index_name}})
body_ = ''
with alive_bar(len(dataset), force_tty=True) as bar:
for index, row in (dataset.iterrows()):
if row['path'] == '87/874f86c4.jpg':
continue
payload = {}
payload['image_url'] = "https://amazon-berkeley-objects.s3.amazonaws.com/images/small/" + row['path']
payload['caption'] = row['item_name_in_en_us']
body_ = body_ + action + "\n" + json.dumps(payload) + "\n"
cnt = cnt + 1
if cnt == 100:
resp = cloud_search_cli.bulk(
request_timeout=1000,
index=index_name,
body=body_)
cnt = 0
batch = batch + 1
body_ = ''
bar()
print("Total Bulk batches completed: " + str(batch))Consulta de búsqueda híbrida
match
. La consulta contiene dos cláusulas de consulta, una es consulta y la otra es
remote_neural
consulta. Al realizar la consulta, especifique el canal de búsqueda creado previamente como parámetro de consulta. El canal de búsqueda convertirá el texto entrante en un vector y lo almacenará en
el campo caption_embedding
para consultas posteriores.
# Search with search pipeline
from urllib import request
from PIL import Image
import IPython.display as display
def search(text, size):
resp = cloud_search_cli.search(
index=index_name,
body={
"_source": ["image_url", "caption"],
"query": {
"hybrid": {
"queries": [
{
"match": {
"caption": {
"query": text
}
}
},
{
"remote_neural": {
"caption_embedding": {
"query_text": text,
"k": size
}
}
}
]
}
}
},
params={"search_pipeline": search_pipeline_id},
)
return resp
k = 10
ret = search('shoes', k)
for item in ret['hits']['hits']:
display.display(Image.open(request.urlopen(item['_source']['image_url'])))
print(item['_source']['caption'])Pantalla de búsqueda híbrida

Lo anterior toma la aplicación de búsqueda de imágenes como ejemplo para presentar el proceso práctico de cómo desarrollar rápidamente una aplicación de búsqueda híbrida con la ayuda de la solución de servicio de búsqueda en la nube Volcano Engine. ¡Bienvenidos a todos a iniciar sesión en la consola Volcano Engine para operar!
El servicio de búsqueda en la nube Volcano Engine es compatible con Elasticsearch, Kibana y otros software y complementos de código abierto de uso común. Proporciona recuperación de múltiples condiciones, estadísticas e informes de texto estructurado y no estructurado. Puede lograr una implementación elástica con un solo clic. escalado, operación y mantenimiento simplificados y creación rápida de registros, análisis de recuperación de información y otras capacidades comerciales.