
Autor: Xingji, Changjun, Youyi, Liutao
Introducción al concepto de memoria de trabajo de contenedor WorkingSet
En el escenario de Kubernetes, las estadísticas de uso en tiempo real de la memoria del contenedor (Pod Memory) están representadas por la memoria de trabajo WorkingSet (abreviada como WSS).
El concepto de indicador de WorkingSet lo define cadvisor para escenarios de contenedores.
La memoria de trabajo WorkingSet también es un indicador de las decisiones de programación de Kubernetes para determinar los recursos de memoria, incluido el desalojo de nodos.
Fórmula de cálculo del conjunto de trabajo
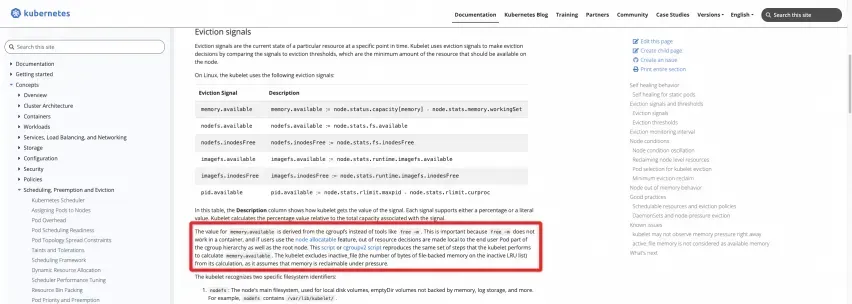
Definición oficial: consulte la documentación del sitio web oficial de K8
https://kubernetes.io/docs/concepts/scheduling-eviction/node-pression-eviction/#eviction-signals
Se pueden ejecutar los dos scripts siguientes en el nodo para calcular directamente los resultados:
GrupoCGV1
https://kubernetes.io/examples/admin/resource/memory-available.sh
#!/bin/bash
#!/usr/bin/env bash
# This script reproduces what the kubelet does
# to calculate memory.available relative to root cgroup.
# current memory usage
memory_capacity_in_kb=$(cat /proc/meminfo | grep MemTotal | awk '{print $2}')
memory_capacity_in_bytes=$((memory_capacity_in_kb * 1024))
memory_usage_in_bytes=$(cat /sys/fs/cgroup/memory/memory.usage_in_bytes)
memory_total_inactive_file=$(cat /sys/fs/cgroup/memory/memory.stat | grep total_inactive_file | awk '{print $2}')
memory_working_set=${memory_usage_in_bytes}
if [ "$memory_working_set" -lt "$memory_total_inactive_file" ];
then
memory_working_set=0
else
memory_working_set=$((memory_usage_in_bytes - memory_total_inactive_file))
fi
memory_available_in_bytes=$((memory_capacity_in_bytes - memory_working_set))
memory_available_in_kb=$((memory_available_in_bytes / 1024))
memory_available_in_mb=$((memory_available_in_kb / 1024))
echo "memory.capacity_in_bytes $memory_capacity_in_bytes"
echo "memory.usage_in_bytes $memory_usage_in_bytes"
echo "memory.total_inactive_file $memory_total_inactive_file"
echo "memory.working_set $memory_working_set"
echo "memory.available_in_bytes $memory_available_in_bytes"
echo "memory.available_in_kb $memory_available_in_kb"
echo "memory.available_in_mb $memory_available_in_mb"
GrupoCGV2
https://kubernetes.io/examples/admin/resource/memory-available-cgroupv2.sh
#!/bin/bash
# This script reproduces what the kubelet does
# to calculate memory.available relative to kubepods cgroup.
# current memory usage
memory_capacity_in_kb=$(cat /proc/meminfo | grep MemTotal | awk '{print $2}')
memory_capacity_in_bytes=$((memory_capacity_in_kb * 1024))
memory_usage_in_bytes=$(cat /sys/fs/cgroup/kubepods.slice/memory.current)
memory_total_inactive_file=$(cat /sys/fs/cgroup/kubepods.slice/memory.stat | grep inactive_file | awk '{print $2}')
memory_working_set=${memory_usage_in_bytes}
if [ "$memory_working_set" -lt "$memory_total_inactive_file" ];
then
memory_working_set=0
else
memory_working_set=$((memory_usage_in_bytes - memory_total_inactive_file))
fi
memory_available_in_bytes=$((memory_capacity_in_bytes - memory_working_set))
memory_available_in_kb=$((memory_available_in_bytes / 1024))
memory_available_in_mb=$((memory_available_in_kb / 1024))
echo "memory.capacity_in_bytes $memory_capacity_in_bytes"
echo "memory.usage_in_bytes $memory_usage_in_bytes"
echo "memory.total_inactive_file $memory_total_inactive_file"
echo "memory.working_set $memory_working_set"
echo "memory.available_in_bytes $memory_available_in_bytes"
echo "memory.available_in_kb $memory_available_in_kb"
echo "memory.available_in_mb $memory_available_in_mb"
Muéstrame el código
Como puede ver, la memoria de trabajo del WorkingSet del nodo es el uso de memoria del cgroup raíz, menos el caché de la parte Inactve (archivo). De manera similar, la memoria de trabajo del WorkingSet del contenedor en el Pod es el uso de la memoria del cgroup correspondiente al contenedor, menos el caché de la parte Inactve (archivo).
En el kubelet del tiempo de ejecución real de Kubernetes, el código real de esta parte de la lógica del indicador proporcionada por cadvisor es el siguiente:
En el Código cadvisor [ 1] , puede ver claramente la definición de memoria de trabajo de WorkingSet:
The amount of working set memory, this includes recently accessed memory,dirty memory, and kernel memory. Working set is <= "usage".
Y la implementación de código específico del cálculo de WorkingSet [ 2] de cadvisor :
inactiveFileKeyName := "total_inactive_file"
if cgroups.IsCgroup2UnifiedMode() {
inactiveFileKeyName = "inactive_file"
}
workingSet := ret.Memory.Usage
if v, ok := s.MemoryStats.Stats[inactiveFileKeyName]; ok {
if workingSet < v {
workingSet = 0
} else {
workingSet -= v
}
}
Casos de problemas comunes de usuarios relacionados con problemas de memoria del contenedor
En el proceso en el que el equipo de ACK brinda soporte de servicio para escenarios de contenedores a una gran cantidad de usuarios, muchos clientes han encontrado más o menos problemas de memoria de contenedor al implementar sus aplicaciones comerciales en contenedores. Después de experimentar una gran cantidad de problemas de los clientes, el equipo de ACK y el equipo del sistema operativo Alibaba Cloud resumieron los siguientes problemas comunes que enfrentan los usuarios en términos de memoria del contenedor:
Pregunta frecuente 1: Existe una brecha entre el uso de memoria del host y el uso agregado del contenedor por nodo. El host es aproximadamente el 40 % y el contenedor es aproximadamente el 90 %.
Lo más probable es que se deba a que el Pod del contenedor se considera un WorkingSet, que contiene cachés como PageCache.
El valor de la memoria del host no incluye caché, PageCache, memoria sucia, etc., mientras que la memoria de trabajo sí incluye esta parte.
Los escenarios más comunes son la contenedorización de aplicaciones JAVA, Log4J de aplicaciones JAVA y su implementación muy popular Logback. El Appender predeterminado comenzará a usar NIO de manera muy "simple" y usará mmap para usar Dirty Memory. Esto hace que la memoria caché aumente, lo que hace que aumente la memoria de trabajo del Pod.
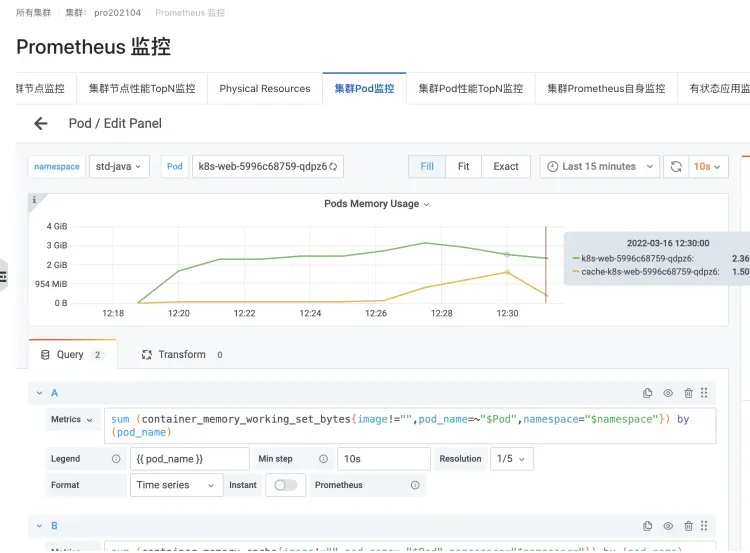
Escenario de registro de inicio de sesión de un Pod de una aplicación JAVA
Instancias que causan un aumento en la memoria caché y la memoria WorkingSet
Pregunta frecuente 2: Al ejecutar el comando top en un Pod, el valor obtenido es menor que el valor de la memoria de trabajo (WorkingSet) visto por kubectl top pod.
Ejecute el comando superior en el Pod. Debido a problemas como el aislamiento del tiempo de ejecución del contenedor, el aislamiento del contenedor en realidad se rompe y se obtiene el valor de monitoreo superior del host.
Por lo tanto, lo que ve es el valor de la memoria de la máquina host, que no incluye caché, PageCache, memoria sucia, etc., mientras que la memoria de trabajo incluye esta parte, por lo que es similar a la pregunta frecuente 1.
Pregunta frecuente 3: Problema del agujero negro de la memoria del pod
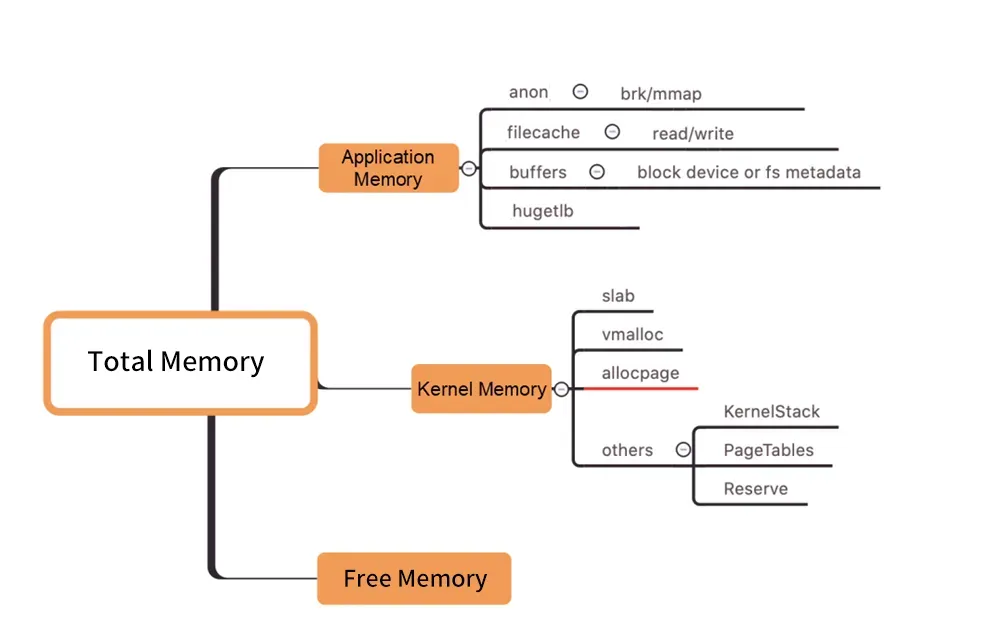
图/Distribución de memoria a nivel de kernel
Como se muestra en la figura anterior, la memoria de trabajo del Pod WorkingSet no incluye Inactivo (anno), y los otros componentes de la memoria del Pod utilizados por los usuarios no cumplen con las expectativas, lo que eventualmente puede causar que la carga de trabajo del WorkingSet aumente, lo que eventualmente conducirá a Node. Desalojo.
Cómo encontrar la causa real del aumento de la memoria de trabajo entre los muchos componentes de la memoria es tan ciego como un agujero negro. ("Agujero negro de la memoria" se refiere a este problema).
Cómo resolver el problema alto de WorkingSet
Por lo general, los retrasos en el reciclaje de la memoria van acompañados de un alto uso de la memoria del conjunto de trabajo. Entonces, ¿cómo resolver este tipo de problema?
Expansión directa
La planificación de la capacidad (expansión directa) es una solución general al problema de los altos recursos.
"Agujero negro de la memoria": qué hacer si es causado por costos de memoria profunda (como PageCache)
Sin embargo, si desea diagnosticar problemas de memoria, primero debe diseccionar, obtener información, analizar o, en términos humanos, ver claramente qué parte de la memoria está en manos de quién (qué proceso o qué recurso específico, como un archivo). Luego realice una optimización de convergencia dirigida para finalmente resolver el problema.
Paso uno: revisa la memoria
Primero, ¿cómo analizar los indicadores de memoria de monitoreo de contenedores a nivel de kernel del sistema operativo? El equipo de ACK cooperó con el equipo del sistema operativo para lanzar la función del producto SysOM (System Observer Monitoring) de monitoreo de contenedores en la capa del núcleo del sistema operativo, que actualmente es exclusiva de Alibaba Cloud al ver Pod Memory Monitor en el contenedor SysOM . Dimensión System Monitoring-Pod , puede obtener información sobre la distribución detallada del uso de memoria del Pod, como se muestra a continuación:
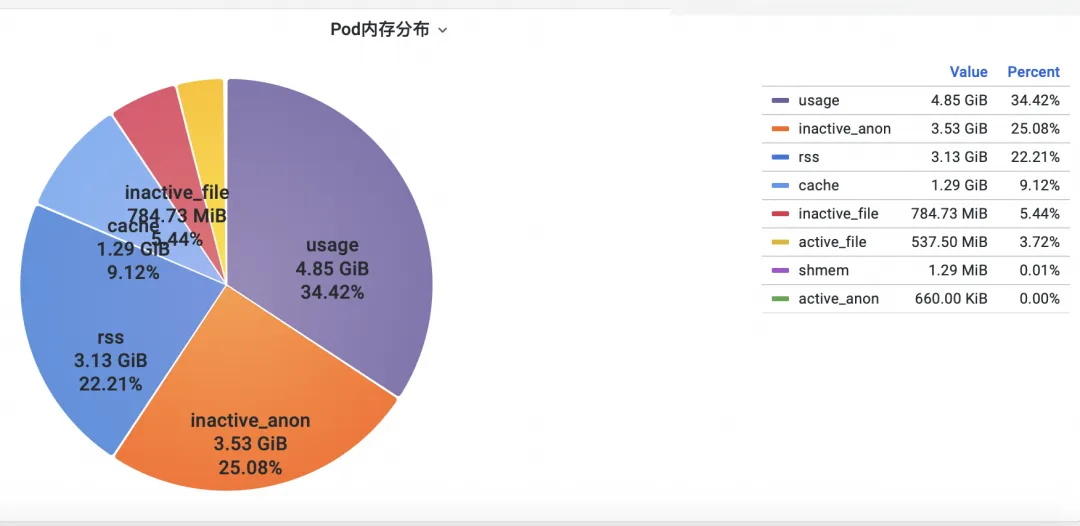
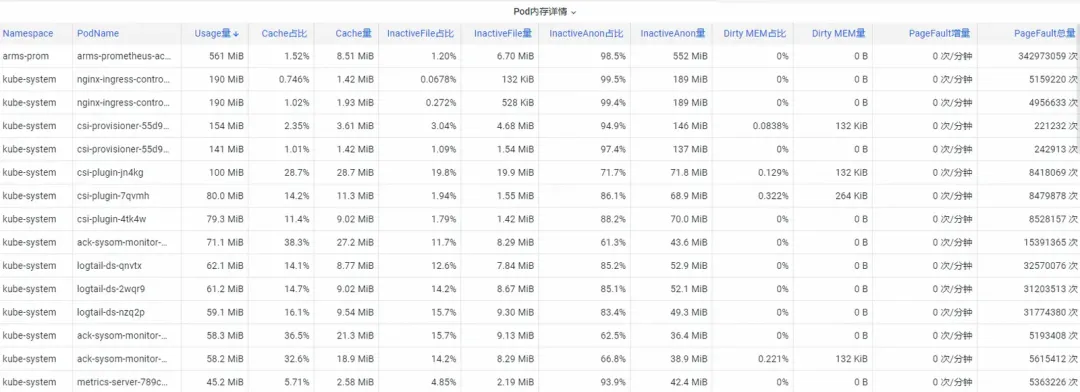
El monitoreo del sistema de contenedores SysOM puede ver la composición de memoria detallada de cada Pod a nivel granular. A través del monitoreo y visualización de diferentes componentes de la memoria, como Pod Cache (memoria caché), InactiveFile (uso de memoria de archivos inactivos), InactiveAnon (uso de memoria anónima inactiva), Dirty Memory (uso de memoria sucia del sistema), se detectan problemas comunes de agujeros negros en la memoria Pod. descubierto.
Para Pod File Cache, puede monitorear el uso de PageCache de los archivos actualmente abiertos y cerrados del Pod al mismo tiempo (eliminar los archivos correspondientes puede liberar la memoria caché correspondiente).
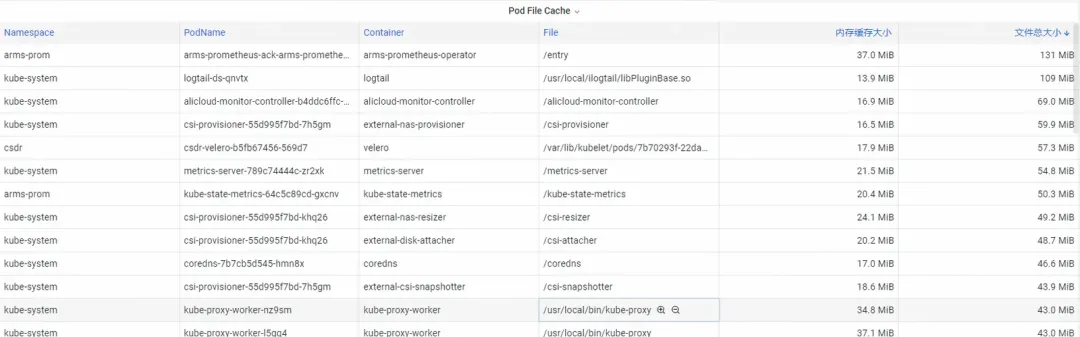
Paso 2: optimizar la memoria
Hay muchos consumos de memoria profundamente arraigados que los usuarios no pueden converger fácilmente incluso si los ven con claridad. Por ejemplo, PageCache y otra memoria que el sistema operativo recupera de manera uniforme requieren que los usuarios realicen cambios intrusivos en el código, como agregar flush(. ) al Appender de Log4J para llamar a sync() periódicamente.
https://stackoverflow.com/questions/11829922/logback-file-appender-doesnt-flush-immediately
Esto es muy poco realista.
El equipo de servicio de contenedores ACK lanzó la función de programación detallada Koordinator QoS .
Implementado en Kubernetes para controlar los parámetros de memoria del sistema operativo:
Cuando se habilita la ubicación conjunta de SLO diferenciada en el clúster, el sistema priorizará la calidad de servicio de la memoria de los pods LS (sensibles a la latencia) sensibles a la latencia y retrasará el tiempo de los pods LS que activan el reciclaje de memoria en toda la máquina.
En la siguiente figura, Memory.limit_in_bytes representa el límite superior de uso de la memoria, Memory.high representa el umbral del límite actual de la memoria, Memory.wmark_high representa el umbral de reciclaje en segundo plano de la memoria y Memory.min representa el umbral de bloqueo del uso de la memoria.
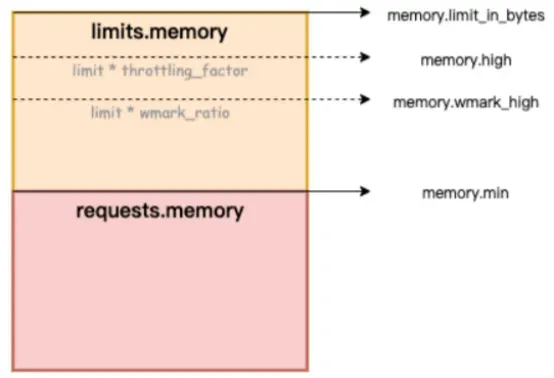
Figure/ack-koordinator proporciona capacidades de garantía de QoS (calidad de servicio) de memoria para contenedores
¿Cómo solucionar el problema del agujero negro de la memoria? Alibaba Cloud Container Service utiliza funciones de programación refinadas y se basa en el proyecto de código abierto Koordinator, que proporciona capacidades de garantía de calidad de servicio de memoria QoS (calidad de servicio) para contenedores, lo que mejora la equidad de la memoria. recursos bajo la premisa de garantizar la equidad de los recursos de memoria El rendimiento de la memoria de la aplicación en tiempo de ejecución. Este artículo presenta la función QoS de la memoria del contenedor. Para obtener instrucciones detalladas, consulte QoS de la memoria del contenedor [ 3] .
Los contenedores tienen principalmente las siguientes dos limitaciones cuando usan memoria:
1) Límite de memoria propia: cuando la memoria propia del contenedor (incluido PageCache) se acerca al límite superior del contenedor, se activará el reciclaje de memoria dimensional del contenedor. Este proceso afectará la aplicación de memoria y liberará el rendimiento de las aplicaciones dentro del contenedor. Si no se puede satisfacer la solicitud de memoria, se activará el contenedor OOM.
2) Límite de memoria del nodo: cuando la memoria del contenedor está sobrevendida (Límite de memoria> Solicitud) y toda la máquina tiene memoria insuficiente, se activará el reciclaje de memoria global en la dimensión del nodo. Este proceso tiene un gran impacto en el rendimiento y, en casos extremos. , incluso hace que toda la máquina sea anormal. Si no hay suficiente reciclaje, el contenedor será seleccionado para OOM Kill.
Para solucionar los problemas típicos de memoria del contenedor mencionados anteriormente, ack-koordinator proporciona las siguientes funciones mejoradas:
1) Nivel de agua de reciclaje en segundo plano de la memoria del contenedor: cuando el uso de la memoria del Pod está cerca del límite límite, una parte de la memoria se reciclará de forma asincrónica en segundo plano para aliviar el impacto en el rendimiento causado por el reciclaje directo de la memoria.
2) Reciclaje de bloqueo de memoria del contenedor/limitación del nivel de agua: implementar un reciclaje de memoria más justo entre Pods. Cuando los recursos de memoria de toda la máquina sean insuficientes, se dará prioridad al reciclaje de memoria de Pods con uso excesivo de memoria (Uso de memoria>Solicitud) para evitar individuos. Pods que causan fallas generales. La calidad de los recursos de memoria de la máquina se ha deteriorado.
3) Garantía diferenciada de reciclaje general de memoria: en el escenario de sobreventa de memoria BestEffort, se da prioridad a garantizar la calidad de funcionamiento de la memoria de los Pods garantizados/burstables.
Para obtener detalles sobre las capacidades del kernel habilitadas por la QoS de la memoria del contenedor ACK, consulte Descripción general de la interfaz y las funciones del kernel de Alibaba Cloud Linux [ 4] .
Una vez que se descubre el problema del agujero negro de la memoria del contenedor mediante el primer paso de observación, la función de programación fina ACK se puede combinar con la selección específica de Pods sensibles a la memoria para permitir que la función QoS de la memoria del contenedor complete la reparación de bucle cerrado.
Documentación de referencia:
[1] Documento de descripción de la función ACK SysOM
[2] Documentación de mejores prácticas
[3] Comunidad del lagarto dragón chino
https://mp.weixin.qq.com/s/b5QNHmD_U0DcmUGwVm8Apw
[4] Estación internacional inglés
https://www.alibabacloud.com/blog/sysom-container-monitoring-from-the-kernels-perspective_600792
Enlaces relacionados:
[1] Código cadvisor
[2] Implementación de código específico del cálculo de WorkingSet por cadvisor
[3] QoS de la memoria del contenedor
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/memory-qos-for-containers
[4] Descripción general de las funciones e interfaces del kernel de Alibaba Cloud Linux
https://help.aliyun.com/zh/ecs/user-guide/overview-23
El equipo de inteligencia artificial de China de Microsoft empacó colectivamente y se fue a los Estados Unidos, involucrando a cientos de personas. ¿Cuántos ingresos puede generar un proyecto desconocido de código abierto? Huawei anunció oficialmente que la posición de Yu Chengdong se ajustó en la estación espejo de código abierto de la Universidad de Ciencia y Tecnología de Huazhong. ¡Los estafadores abrieron oficialmente el acceso a la red externa y utilizaron TeamViewer para transferir 3,98 millones! ¿Qué deberían hacer los proveedores de escritorio remoto? La primera biblioteca de visualización front-end y fundador del conocido proyecto de código abierto de Baidu, ECharts, un ex empleado de una conocida empresa de código abierto que "se fue al mar" dio la noticia: después de ser desafiado por sus subordinados, el técnico El líder se puso furioso y grosero y despidió a la empleada embarazada. OpenAI consideró permitir que la IA genere contenido pornográfico. Microsoft informó a The Rust Foundation que donó 1 millón de dólares estadounidenses. Por favor, dígame cuál es el papel de time.sleep(6) aquí. ?