
Con el desarrollo de la tecnología de modelos de lenguaje grande (LLM), la tecnología RAG (Generación Aumentada de Recuperación) ha sido ampliamente discutida e investigada, y se han descubierto métodos de recuperación de RAG cada vez más avanzados. En comparación con la recuperación de RAG ordinaria, el RAG avanzado proporciona más precisión y precisión. Resultados de recuperación de información más relevantes y ricos a través de detalles técnicos más profundos y estrategias de búsqueda más complejas. Este artículo analiza primero estas tecnologías y ofrece un caso de implementación basado en Milvus.
01.RAG Junior
Definición de RAG primario
El paradigma de investigación principal de RAG representa la metodología más antigua y ganó importancia poco después de la adopción generalizada de ChatGPT. El RAG primario sigue el proceso tradicional, que incluye indexación, recuperación y generación. A menudo se describe como un marco de "recuperación-lectura" y su flujo de trabajo incluye tres pasos clave:
-
El corpus se divide en fragmentos discretos y luego se utiliza un modelo de codificador para construir índices vectoriales.
-
RAG identifica y recupera fragmentos basándose en la similitud de vectores entre consultas y fragmentos indexados.
-
El modelo genera respuestas basadas en información contextual obtenida en el fragmento recuperado.
Limitaciones del RAG primario
El RAG primario enfrenta desafíos importantes en tres áreas clave: "recuperación", "generación" y "mejora".
Existen muchos problemas con la calidad de recuperación del RAG primario, como baja precisión y baja recuperación. La baja precisión puede provocar una desalineación de los bloques recuperados, así como posibles problemas como alucinaciones. Una tasa de recuperación baja dará como resultado la incapacidad de recuperar todos los bloques relevantes, lo que resultará en una respuesta insuficientemente completa de LLM. Además, el uso de información antigua agrava aún más el problema y puede generar resultados de búsqueda inexactos.
La calidad de las respuestas generadas enfrenta desafíos ilusorios, es decir, las respuestas generadas por LLM no se basan en el contexto proporcionado, no son relevantes para el contexto o las respuestas generadas tienen el riesgo potencial de contener contenido dañino o discriminatorio.
Durante el proceso de mejora, el RAG primario también enfrenta desafíos considerables sobre cómo integrar efectivamente el contexto de los pasajes recuperados con la tarea de la generación actual. La integración ineficiente puede dar lugar a resultados incoherentes o fragmentados. La redundancia y la duplicación también son un tema espinoso, especialmente cuando varios pasajes recuperados contienen información similar y puede aparecer contenido duplicado en las respuestas generadas.
02. RAG avanzado
Para solucionar las deficiencias del RAG primario, nació el RAG avanzado y sus funciones se mejoraron de manera específica. Primero analizamos estas técnicas, que pueden clasificarse como optimización previa a la recuperación, optimización a mitad de la recuperación y optimización posterior a la recuperación.
Optimización previa a la búsqueda
La optimización previa a la recuperación se centra en la optimización del índice de datos y la optimización de consultas. La tecnología de optimización del índice de datos tiene como objetivo almacenar datos de una manera que mejore la eficiencia de la recuperación:
-
Ventana deslizante: Utiliza la superposición entre bloques de datos, esta es una de las técnicas más sencillas.
-
Mejore la granularidad de los datos: aplique técnicas de limpieza de datos, como eliminar información irrelevante, confirmar la exactitud de los hechos, actualizar información desactualizada, etc.
-
Agregue metadatos: como fecha, propósito o información del capítulo para filtrar.
-
La optimización de la estructura del índice implica diferentes estrategias de indexación de datos: como ajustar el tamaño del bloque o utilizar una estrategia de índice múltiple. Una técnica que implementaremos en este artículo es la recuperación de ventanas de oraciones, que incorpora oraciones individuales en el momento de la recuperación y las reemplaza con ventanas de texto más grandes en el momento de la inferencia.
Optimizar durante la búsqueda
La fase de recuperación se centra en identificar el contexto más relevante. Normalmente, la recuperación se basa en la búsqueda vectorial, que calcula la similitud semántica entre la consulta y los datos indexados. Por lo tanto, la mayoría de las técnicas de optimización de búsqueda giran en torno a la incorporación de modelos:
-
Ajuste los modelos de incrustación: personalice los modelos de incrustación para contextos de dominio específicos, especialmente para dominios con terminología rara o de desarrollo. Por ejemplo,
BAAI/bge-small-enes un modelo de integración de alto rendimiento que se puede ajustar. -
Incrustación dinámica: se adapta al contexto en el que se utilizan las palabras, a diferencia de la incrustación estática que utiliza un vector por palabra. Por ejemplo, OpenAI
embeddings-ada-02es un modelo de integración dinámico complejo que captura la comprensión contextual. Además de la búsqueda vectorial, existen otras técnicas de recuperación, como la búsqueda híbrida, que generalmente se refiere al concepto de combinar la búsqueda vectorial con la búsqueda basada en palabras clave. Esta técnica de búsqueda es beneficiosa si la búsqueda requiere coincidencias exactas de palabras clave.
Optimización posterior a la recuperación
Para el contenido del contexto recuperado, encontraremos ruido como el contexto que excede el límite de la ventana o el ruido introducido por el contexto, lo que distraerá la atención de la información clave:
-
Compresión de mensajes: reduzca la longitud total del mensaje eliminando contenido irrelevante y resaltando el contexto importante.
-
Reclasificación: utilice un modelo de aprendizaje automático para recalcular la puntuación de relevancia del contexto recuperado.
Las técnicas de optimización posteriores a la búsqueda incluyen:
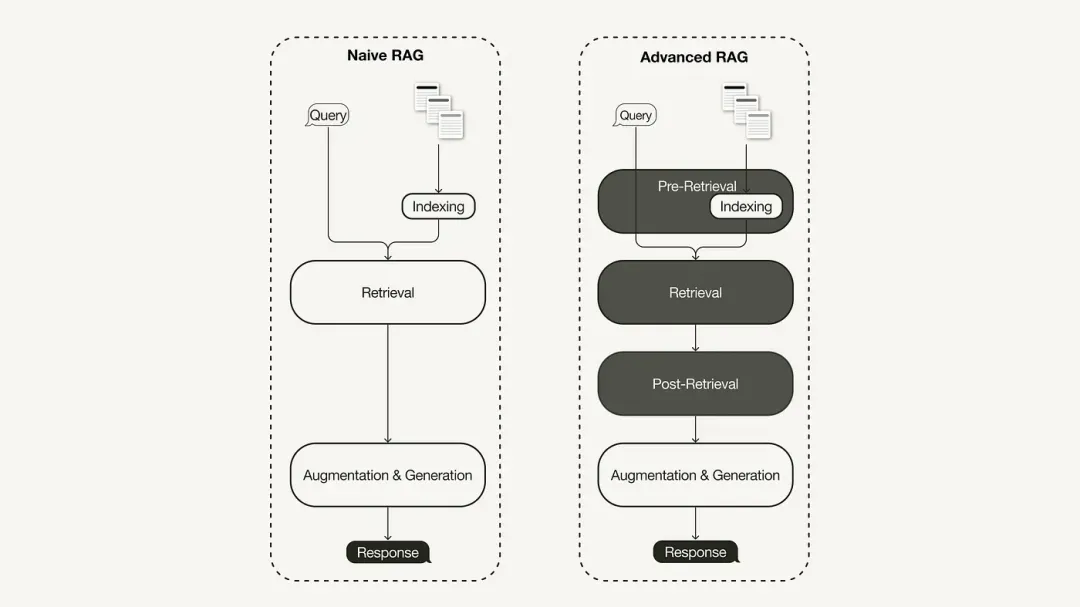
03. Implementar RAG avanzado basado en Milvus + LlamaIndex
El RAG avanzado que implementamos utiliza el modelo de lenguaje OpenAI, el modelo de reordenamiento BAAI alojado en Hugging Face y la base de datos vectorial Milvus.
Crear índice Milvus
from llama_index.core import VectorStoreIndex
from llama_index.vector_stores.milvus import MilvusVectorStore
from llama_index.core import StorageContext
vector_store = MilvusVectorStore(dim=1536,
uri="http://localhost:19530",
collection_name='advance_rag',
overwrite=True,
enable_sparse=True,
hybrid_ranker="RRFRanker",
hybrid_ranker_params={"k": 60})
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex(
nodes,
storage_context=storage_context
)
Ejemplo de optimización de índice: recuperación de ventana de oración
Usamos SentenceWindowNodeParser en LlamaIndex para implementar la tecnología de recuperación de ventanas de oraciones.
from llama_index.core.node_parser import SentenceWindowNodeParser
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
SentenceWindowNodeParser realiza dos operaciones:
Separa el documento en oraciones separadas, que se incrustan.
Para cada oración, crea una ventana de contexto. Si especifica window_size = 3, la ventana resultante contendrá tres oraciones, comenzando con la oración anterior a la oración incrustada y extendiéndose hasta la oración posterior. Esta ventana se almacenará como metadatos. Durante la recuperación, se devuelve la frase que mejor coincide con la consulta. Después de la recuperación, debe reemplazar la oración con la ventana completa de los metadatos definiendo a MetadataReplacementPostProcessory usándola en la lista.node_postprocessors
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
postproc = MetadataReplacementPostProcessor(
target_metadata_key="window"
)
...
query_engine = index.as_query_engine(
node_postprocessors = [postproc],
)
Ejemplo de optimización de búsqueda: búsqueda híbrida
La implementación de la búsqueda híbrida en LlamaIndex requiere solo dos cambios de parámetros en el motor de consultas, siempre que la base de datos vectorial subyacente admita consultas de búsqueda híbrida. La versión 2.4 de Milvus no admitía la búsqueda híbrida antes, pero en la versión 2.4 lanzada recientemente, esta característica ya es compatible.
query_engine = index.as_query_engine(
vector_store_query_mode="hybrid", #Milvus 2.4开始支持, 在2.4版本之前使用 Default
)
Ejemplo de optimización posterior a la recuperación: reclasificación
Agregar una nueva clasificación al RAG avanzado requiere solo tres pasos simples:
Primero, defina un modelo de reclasificación usando Hugging Face BAAI/bge-reranker-base.
En el motor de consultas, agregue el modelo de reorden a node_postprocessorsla lista.
Aumento del motor de consultas similarity_top_kpara recuperar más fragmentos de contexto, que se pueden reducir a top_n después de la reorganización.
from llama_index.core.postprocessor import SentenceTransformerRerank
rerank = SentenceTransformerRerank(
top_n = 3,
model = "BAAI/bge-reranker-base"
)
...
query_engine = index.as_query_engine(
similarity_top_k = 3,
node_postprocessors = [rerank],
...,
)
Para obtener un código de implementación detallado, consulte el enlace de Baidu Netdisk: https://pan.baidu.com/s/1Cj_Fmy9-SiQFMFNUmO0OZQ?pwd=r2i1 Código de extracción: r2i1
Los recursos pirateados de "Qing Yu Nian 2" se cargaron en npm, lo que provocó que npmmirror tuviera que suspender el servicio unpkg: No queda mucho tiempo para Google. Sugiero que todos los productos sean de código abierto. time.sleep(6) aquí juega un papel. ¡Linus es el más activo en "comer comida para perros"! El nuevo iPad Pro utiliza 12 GB de chips de memoria, pero afirma tener 8 GB de memoria. People's Daily Online revisa la carga estilo matrioska del software de oficina: Sólo resolviendo activamente el "conjunto" podremos tener un futuro para Flutter 3.22 y Dart 3.4 . nuevo paradigma de desarrollo para Vue3, sin necesidad de `ref/reactive `, sin necesidad de `ref.value` Lanzamiento del manual chino de MySQL 8.4 LTS: le ayudará a dominar el nuevo ámbito de la gestión de bases de datos Tongyi Qianwen Precio del modelo principal de nivel GPT-4 reducido en un 97%, 1 yuan y 2 millones de tokens