


Invitados compartidos: Qiu Lu, Tang Chunxu, Wang Beinan
Actualmente, los campos de la inteligencia artificial (IA) y el aprendizaje automático (ML) se están desarrollando rápidamente y cada vez es más importante manejar de manera efectiva grandes conjuntos de datos durante el entrenamiento. Ray se ha convertido en un actor importante en este campo, ya que permite el entrenamiento de conjuntos de datos a gran escala mediante un procesamiento eficiente de flujos de datos. Ray divide grandes conjuntos de datos en fragmentos manejables y divide los trabajos de capacitación en tareas más pequeñas sin la necesidad de almacenar todo el conjunto de datos localmente en la máquina de capacitación. Sin embargo, este enfoque innovador también enfrenta ciertos desafíos.
Si bien Ray facilita el entrenamiento con grandes conjuntos de datos, la carga de datos sigue siendo un obstáculo grave. Cada época requiere recargar todo el conjunto de datos desde el almacenamiento remoto, lo que reducirá seriamente la utilización de la GPU y aumentará el costo de transmisión de los datos almacenados. Por lo tanto, necesitamos un método más optimizado para administrar los datos durante el proceso de capacitación y mejorar la eficiencia.
Ray utiliza principalmente memoria para almacenar datos y su almacenamiento de objetos en memoria está diseñado para datos de tareas grandes. Sin embargo, este enfoque enfrenta cuellos de botella en tareas con uso intensivo de datos porque los datos necesarios para tareas grandes deben cargarse previamente en la memoria de Ray antes de su ejecución. Dado que el tamaño del almacenamiento de objetos generalmente no puede acomodar el conjunto de datos de entrenamiento, no es adecuado para almacenar en caché datos en múltiples épocas de entrenamiento, lo que también resalta la necesidad de una solución de administración de datos más escalable para el marco Ray.
Una de las ventajas importantes de Ray es que utiliza la GPU para el entrenamiento mientras utiliza la CPU para la carga y el preprocesamiento de datos. Este método garantiza una utilización eficiente de los recursos de GPU, CPU y memoria dentro del clúster de Ray, pero también da como resultado una subutilización de los recursos del disco y una falta de gestión eficaz. Surgió una idea revolucionaria: crear una capa de acceso a datos de alto rendimiento para almacenar en caché y acceder a conjuntos de datos de entrenamiento mediante la gestión inteligente de recursos de disco ineficientes en todas las máquinas. Esto puede mejorar significativamente el rendimiento general del entrenamiento y reducir el costo de acceso a la frecuencia del almacenamiento remoto.
Alluxio acelera el entrenamiento en conjuntos de datos a gran escala utilizando de manera inteligente y eficiente la capacidad de disco no utilizada en GPU y máquinas CPU adyacentes para el almacenamiento en caché distribuido. Este enfoque innovador mejora significativamente el rendimiento de la carga de datos, fundamental para la capacitación con conjuntos de datos a gran escala, al tiempo que reduce la dependencia del almacenamiento remoto y los costos de transferencia de datos asociados.
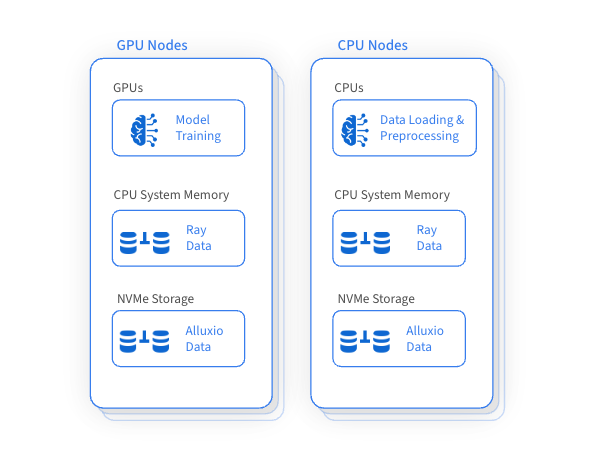
La integración de Alluxio mejora las capacidades de gestión de datos de Ray y aporta muchos beneficios:
√
Escalabilidad
El acceso a datos y el almacenamiento en caché son altamente escalables
√
Acelerar el acceso a los datos
Utiliza discos de alto rendimiento para almacenar datos en caché
Optimizado para lectura aleatoria de alta concurrencia de formatos de archivos de almacenamiento de columnas como Parquet
copia cero
√
confiabilidad y disponibilidad
No hay un solo punto de falla
Sólido acceso al almacenamiento remoto durante interrupciones
√
Gestión flexible de recursos
Asigne y libere dinámicamente recursos de caché según las necesidades de la carga de trabajo.
Ray puede orquestar eficazmente flujos de trabajo de aprendizaje automático e integrarse perfectamente con marcos de carga, preprocesamiento y capacitación de datos. Como capa de acceso a datos de alto rendimiento, Alluxio puede optimizar en gran medida las tareas de inferencia y entrenamiento de IA/ML, especialmente cuando es necesario acceder repetidamente a datos de almacenamiento remoto.
Ray utiliza PyArrow para cargar datos y convertir el formato de datos al formato Arrow, que luego utiliza el flujo de trabajo de Ray en la siguiente etapa. PyArrow delega los problemas de conexión de almacenamiento al marco fsspec y Alluxio sirve como una capa de caché intermedia entre Ray y los sistemas de almacenamiento subyacentes (como S3, Azure Blob Storage y Hugging Face).
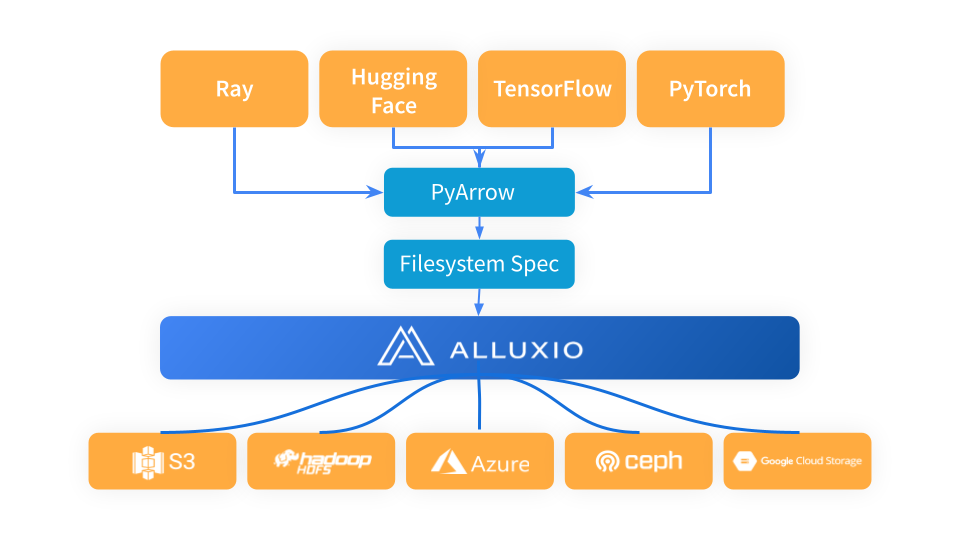
Cuando utilice Alluxio como capa de almacenamiento en caché entre Ray y S3, simplemente importe Alluxiofs, inicialice el sistema de archivos Alluxio y cambie el sistema de archivos Ray a Alluxio.
# Import fsspec & alluxio fsspec implementationimport fsspecfrom alluxiofs import AlluxioFileSystemfsspec.register_implementation("alluxio", AlluxioFileSystem)# Create Alluxio filesystem with S3 as the underlying storage systemalluxio = fsspec.filesystem("alluxio", target_protocol=”s3”, etcd_host=args.etcd_host)# Ray read data from Alluxio using S3 URLds = ray.data.read_images("s3://datasets/imagenet-full/train", filesystem=alluxio)
Utilizamos la prueba nocturna Ray Data de Ray Data para comparar el rendimiento de carga de datos de Alluxio y S3 en la misma región en diferentes épocas de entrenamiento. Los resultados de las pruebas comparativas muestran que los costos de almacenamiento se pueden reducir significativamente y mejorar el rendimiento integrando Alluxio con Ray.

√
Rendimiento de acceso a datos mejorado: observamos que cuando el almacenamiento de objetos de Ray no se ve afectado por la presión de la memoria, el rendimiento de Alluxio es 2 veces mayor que el de S3 en la misma área.
√
La ventaja es más obvia bajo presión de memoria: vale la pena señalar que cuando el almacenamiento de objetos de Ray enfrenta presión de memoria, la ventaja de rendimiento de Alluxio aumenta significativamente y su rendimiento es 5 veces mayor que el de S3.
Para las tareas de Ray, es de gran importancia estratégica utilizar recursos de disco no utilizados como almacenamiento para la caché distribuida. Este método mejora significativamente el rendimiento de la carga de datos y es especialmente útil cuando se entrena o ajusta con el mismo conjunto de datos en varias épocas. Además, cuando Ray enfrenta presión de memoria, puede proporcionar soluciones prácticas para optimizar y simplificar el proceso de gestión de datos en estos escenarios.
✦
[Agrega asistente para obtener más información]
✦

✦
【Popularidad reciente】
✦

✦
【Mercado Baodiano】
✦






Este artículo se comparte desde la cuenta pública de WeChat: Alluxio (Alluxio_China).
Si hay alguna infracción, comuníquese con [email protected] para eliminarla.
Este artículo participa en el " Plan de creación de fuentes OSC ". Los que están leyendo pueden unirse y compartir juntos.