modèle d'évaluation
courbe ROC
question: comment calculer l' ASC?
répondre: Tout d' abord, la taille de la CUA se réfère à la surface sous la courbe ROC, la valeur de quantification peut se refléter sur la courbe ROC pour mesurer la performance du modèle. les valeurs d' AUC ont été calculées ne doivent faire l'intégration le long de l'axe horizontal ROC sur elle. La courbe ROC est généralement situé au-dessus de cette droite y = x (si non, tant que la prédiction du modèle de probabilité est inversé pour 1-p peut avoir une meilleure classificateur), l'AUC valeurs généralement 0,5 entre ~ 1. Plus la CUA, le classificateur d'explication plus susceptibles de mieux les échantillons vrais positifs debout à l'avant, la performance de classification.
Question: courbe ROC par rapport à PR ( https://wordpress.aberttsy.cn/index.php/2020/04/01/machine-learning-3/ courbe) Quelles sont les caractéristiques?
Réponse: Il PR par rapport à la courbe, une courbe caractéristique ROC, lorsque la distribution d'échantillons positifs et négatifs est changé, la forme de la courbe ROC peut être pratiquement inchangée, tandis que la forme de la courbe de PR sont généralement des changements plus drastiques se produisent.

Comme on peut le voir, la courbe PR des changements importants se sont produits, la forme de la courbe ROC pratiquement inchangée. Cette fonction permet à la courbe ROC peut minimiser les interférences causées par les différents jeux de tests, mesurer plus objectivement la performance du modèle lui-même. Quel est le sens réel de celui-ci? Dans de nombreux problèmes pratiques, le nombre d'échantillons positifs et négatifs sont souvent inégaux. Par exemple, la publicité implique souvent calculate la conversion du modèle, le nombre d'échantillons positifs ont tendance à être négatif nombre pair d'échantillons 1/1000 1/10000. Si vous sélectionnez un ensemble de test différent, la courbe de changement PR sera très grande, et la courbe ROC est plus refléter de manière stable la qualité du modèle lui-même. Ainsi, des scènes plus appropriées courbe ROC, est largement utilisé dans le tri, les recommandations, la publicité et ainsi de suite. Mais notez que le choix de la courbe courbe ou ROC PR est en raison des problèmes pratiques varient, si les chercheurs veulent voir plus modèle de performance sur un ensemble de données particulier, la courbe PR peut être mieux refléter directement ses performances.
la distance cosinus
question: Pourquoi certains scénarios à utiliser similitude cosinus au lieu de la distance euclidienne?
réponse: Pour deux vecteurs A et B, qui est défini comme la similitude cosinus à 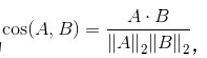 -dire cosinus deux vecteurs de l'angle, la relation angulaire entre les vecteurs concernés, ils ne sont pas concernés par la taille absolue est dans la plage [- 1,1]. Considérant que , si entre elles similarité cosinus, puis, quand une grande partie de la longueur de la similitude du texte de l' écart, mais le contenu est similaire, si le mot ou mot fréquence que le vecteur de caractéristique, laquelle distance euclidienne dans un espace caractéristique est généralement de grande taille l'angle peut être faible, et donc une grande similitude. En outre, dans le domaine du texte, des images, de la vidéo, les dimensions de caractéristique de l'objet d'étude est souvent élevé, il reste de similarité cosinus à un cas de grande dimension « le même est 1, 0 est orthogonal, opposé à -1 » nature, tandis qu'une valeur de la distance euclidienne est affectée par les dimensions de la gamme n'est pas fixe, et le sens plutôt ambigu.
-dire cosinus deux vecteurs de l'angle, la relation angulaire entre les vecteurs concernés, ils ne sont pas concernés par la taille absolue est dans la plage [- 1,1]. Considérant que , si entre elles similarité cosinus, puis, quand une grande partie de la longueur de la similitude du texte de l' écart, mais le contenu est similaire, si le mot ou mot fréquence que le vecteur de caractéristique, laquelle distance euclidienne dans un espace caractéristique est généralement de grande taille l'angle peut être faible, et donc une grande similitude. En outre, dans le domaine du texte, des images, de la vidéo, les dimensions de caractéristique de l'objet d'étude est souvent élevé, il reste de similarité cosinus à un cas de grande dimension « le même est 1, 0 est orthogonal, opposé à -1 » nature, tandis qu'une valeur de la distance euclidienne est affectée par les dimensions de la gamme n'est pas fixe, et le sens plutôt ambigu.
Dans certains scénarios, par exemple Word2Vec dans lequel vecteur de longueur matrice sont normalisées à travers, cette fois-ci avec une distance euclidienne la distance cosinus a une relation monotone, à savoir,
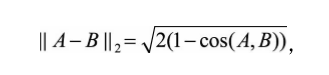
Où || || A-B 2 représente la distance euclidienne, cos (A, B) représente une similitude cosinus, (1-cos (A, B)) représenté par la distance de cosinus. Dans ce scénario, si vous sélectionnez des voisins minimum (similitude maximum), puis utilisez les résultats de similarité cosinus et la distance euclidienne est le même.
Dans l'ensemble, la valeur absolue de la différence reflète la distance euclidienne, et les différences par rapport reflètent la distance cosinus de direction. Par exemple, les statistiques deux jeux de comportement de visualisation utilisateur, l'utilisateur A est visualiser des couches vectorielles (0,1), l'utilisateur B est (1,0), ce qui cosinus temps une grande distance entre les deux, et la distance euclidienne est faible, nous pour l'analyse des deux préférences utilisateur vidéo différents, sont plus préoccupés par la différence relative, de toute évidence, il devrait être utilisé distance cosinus. Et lorsque nous analysons l'activité des utilisateurs aux temps d'atterrissage (unité: seconde) et la durée moyenne du temps de regarder: le temps (en minutes) comme une caractéristique, la distance cosinus sera considéré (1, 10), (10, 100) deux utilisateurs sont très proches, mais évidemment ces deux activités de l'utilisateur a une grande différence, à ce moment, nous sommes plus préoccupés par la valeur absolue de la différence doit être utilisée distance euclidienne.
question: si la distance cosinus est la distance strictement définie?
répondre: D' abord, regardez la définition de la distance: dans un ensemble, si chacun peut identifier de manière unique les éléments d'un nombre réel, faisant trois de l'axiome (positivité, la symétrie, l' inégalité triangulaire) détient, le nombre réel peut être appelé sur cet élément la distance entre les deux. satisfait à distance Cosinus positive et symétrie définitude, mais ne satisfait pas l'inégalité triangulaire, la distance ne soit pas strictement définie.
Un piège de test / B
question: Une fois le modèle a été entièrement évalué en ligne, pourquoi en ligne de test A / B?
réponse:
(1) modèle d'évaluation en ligne ne peut pas éliminer complètement les effets de surajustement, par conséquent, des résultats d'évaluation obtenus hors ligne ne peuvent pas remplacer entièrement l' évaluation en ligne.
(2) l' évaluation hors ligne ne peut pas être réduit complètement la ligne d'ingénierie environnementale. Dans l' évaluation générale, hors ligne ne considèrent pas l'environnement de ligne de retard, perte de données, perte d'étiquettes de données et ainsi de suite. Par conséquent, les résultats de l' évaluation hors ligne est dans un environnement d'ingénierie idéal.
Certains indicateurs commerciaux (3) système en ligne ne peut pas être calculé hors ligne évalué. évaluations hors ligne sont généralement évaluées en fonction du modèle lui - même, alors que d' autres indicateurs relatifs au modèle, en particulier les indicateurs d'activité, souvent ne peuvent pas être obtenus directement. Par exemple, en ligne un nouvel algorithme de recommandation, hors ligne ÉVALUER ont tendance à se concentrer sur est d'améliorer la courbe ROC, courbe PR, et l' évaluation en ligne peut bien comprendre la méthode recommandée permet aux utilisateurs taux de clics, durée de conservation, les changements de visites PV, etc. . Ceux - ci devront procéder à une évaluation complète par les tests A / B.
question: Comment faire test en ligne A / B?
répondre à: pour le premier moyen de kit de test A / B de pièces est un utilisateur, à savoir l'utilisateur divisé en groupe expérimental et le groupe témoin, le groupe expérimental d'utilisateurs à imposer le nouveau modèle, l'utilisateur du groupe de contrôle soumis à l'ancien modèle. Dans le processus de division de la baignoire, l'échantillon à noter que l'indépendance et le mode d'échantillonnage impartial afin d' assurer que le même ne peut être attribué à un utilisateur avec un seau, le seau dans un processus de séparation sélectionné user_id a besoin d' un nombre aléatoire , de manière à assurer que le godet d'échantillon est biaisé.
question: comment diviser le groupe expérimental et le groupe témoin (modèle récemment mis au point A, mais les utilisateurs existants utilisent un modèle B, demander comment divisé, peut valider le modèle A)?
réponse: Le User_id divisé en groupes d'essai et de contrôle, respectivement, en utilisant le modèle A, modèle B, afin de vérifier l'effet du modèle A.

Modèle méthode d'évaluation
question: Dans le processus d'évaluation du modèle, ce sont la principale méthode de vérification, de dire les avantages et les inconvénients.
réponse:
(1) Test de Irréductible est la méthode la plus simple et la plus directe de la vérification, l'ensemble d'échantillons d'origine sera divisé de manière aléatoire dans un ensemble d'apprentissage et un ensemble de validation en deux parties. Par exemple, un taux de clics pour le modèle de prédiction, nous échelle échantillon de 70% à 30% divisé en deux parties, 70% des échantillons pour la formation du modèle, 30% des échantillons sont utilisés pour la validation du modèle, y compris le dessin de la courbe ROC, pour calculer une précision et le taux de rappel et d'autres indicateurs pour évaluer la performance du modèle. lacunes d'inspection récalcitrantes est évident que calculé sur la validation mis en dernier indice d'évaluation et le paquet d'origine a beaucoup. Afin d'éliminer le caractère aléatoire, les chercheurs ont introduit l'idée de « vérification croisée » de.
(2) k fois la validation croisée: Tout d'abord, l'ensemble de l'échantillon est divisé en sous-ensembles de k d'échantillons de taille égale; parcourir séquentiellement les sous-ensembles de k, chaque sous-ensemble de l'ensemble actuel de vérification que tous les sous-ensembles restants de l'ensemble d'apprentissage pour modèles de formation et d'évaluation, la moyenne du dernier indice d'évaluation de k comme l'indice d'évaluation finale. Dans l'expérience réelle, k est souvent pris 10. Laisser une validation: chaque gauche un échantillon comme un ensemble de validation, tous les autres échantillons comme un ensemble de test. Le nombre total d'échantillons N, N échantillons, n fois traversés séquentiellement vérifiée, alors la moyenne pour obtenir l'indice d'évaluation de l'indice d'évaluation finale. Dans le cas du nombre total d'échantillons sont disponibles, ce qui laisse une grande validation de la surcharge de temps. En fait, en laissant une vérification est un cas particulier de séjour de vérification p. La validation est un temps de séjour p p échantillons gauche comme un ensemble de validation, et choisir les éléments p de n éléments dans une sorte probable, il est donc en tête de temps est beaucoup plus élevé que le congé d'une vérification, et donc ne fonctionne que rarement dans la pratique elle est appliquée.
补充:不管是Holdout检验还是交叉检验,都是基于划分训练集和测试集的方法进行 模型评估的。然而,当样本规模比较小时,将样本集进行划分会让训练集进一步 减小,这可能会影响模型训练效果。
(3) 自助法是基于自助采样法的检验方法。对于总数为n的样本集合,进行n次有 放回的随机抽样,得到大小为n的训练集。n次采样过程中,有的样本会被重复采 样,有的样本没有被抽出过,将这些没有被抽出的样本作为验证集,进行模型验 证,这就是自助法的验证过程。
question: 在自助法的采样过程中,对n个样本进行n次自助抽样,当n趋于无穷大时, 最终有多少数据从未被选择过?
answer:


因此,当样本数很大时,大约有36.8%的样本从未被选择过,可作为验证集。