Détection de bouclage Correction de bouclage (1): Principe de la détection de bouclage
1. L'importance de la détection et de la correction de bouclage
Référence:
[1] Xu Kuan. Recherche sur la vision binoculaire SLAM fusionnée avec des informations IMU [D]. Harbin Institute of Technology, 2018.
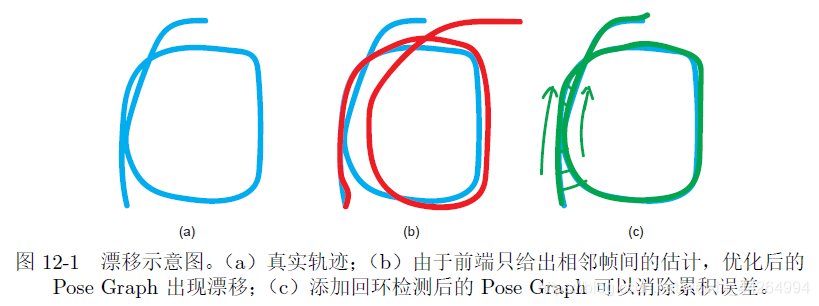
Après avoir effectué une estimation de mouvement, lorsque la pose initiale de la première image de trame est fixe, théoriquement, elle peut être La posture de chaque trame suivante est déduite, mais cela entraînera l'accumulation d'erreurs (les erreurs de posture estimées pour les deux trames adjacentes seront ajoutées à la trame suivante et l'erreur deviendra de plus en plus grande). En d'autres termes, nous ne pouvons pas construire de pistes et de cartes cohérentes à l'échelle mondiale.
Par conséquent, nous devons effectuer une détection de bouclage pour éliminer cette erreur accumulée.
Pour éliminer cette erreur, vous pouvez le faire: lorsque le système passe deux fois au même endroit, la posture obtenue par la récursivité sera très différente en raison de l'effet de l'erreur cumulative, mais nous pouvons forcer les deux postures à être les mêmes, puis Corrigez la pose des autres images pour réduire l'effet des erreurs accumulées.
Pour réaliser cette idée, nous devons faire deux choses:
1. Comment reconnaître avec précision que le système est passé deux fois au même endroit (détection de bouclage)
2. Comment utiliser les informations de bouclage pour corriger la pose d'autres images (correction de bouclage)
2. Détection de bouclage
La première chose est de savoir comment reconnaître avec précision que le système est passé deux fois au même endroit
1. Modèle de sac de mots
Présentation
Extrait de "SLAM Fourteen Lectures"


2. Dictionnaire
Création d'un dictionnaire: clustering K-means

b. Représentation et recherche du dictionnaire: k-tree


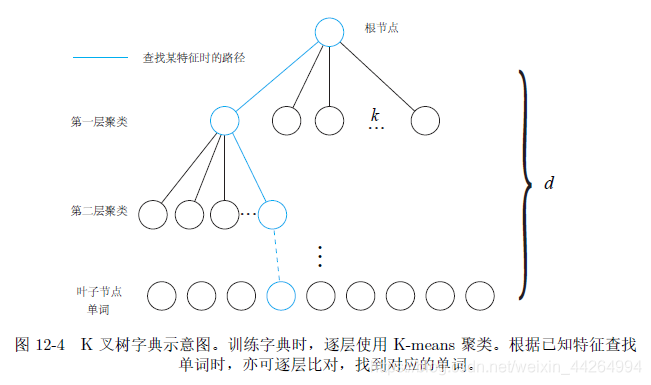
Avec l'arborescence du dictionnaire visuel, le modèle de sac de mots est construit comme suit:
1. Extraire des points caractéristiques et générer des descripteurs pour un cadre d'image à traiter
2. Pour chaque point caractéristique, interrogez sa position dans l'arborescence du dictionnaire pour obtenir sa description de mot. De cette façon, chaque point caractéristique peut être remplacé par un mot dans un dictionnaire visuel
3, tous les mots de l'image de trame sont comptés par un histogramme, et un vecteur décrivant la situation dans laquelle l'image de trame contient des mots peut être obtenu
c 、 TF-IDF
Dans l'approche ci-dessus, nous traitons tous les mots comme «égaux», c'est-à-dire que lors du comptage des histogrammes, il n'y a qu'un seul mot, il n'y en a pas. Cependant, l'importance de mots différents dans la différenciation n'est pas la même. Par conséquent, nous espérons évaluer la distinction ou l'importance des mots et leur donner différents poids pour obtenir de meilleurs résultats. Comment calculer le poids?
Calcul des poids des mots Nous utilisons la méthode TF-IDF pour calculer, également connue sous le nom de fréquence de document inverse de fréquence (fréquence de fichier inverse de fréquence de mot), l'idée de la partie TF est: un mot apparaît souvent dans une image, plus le degré de discrimination est élevé L'idée de la partie IDF est: plus la fréquence d'un mot dans le dictionnaire est faible, plus le degré de discrimination lors de la classification des images est élevé
Le processus de calcul spécifique est le suivant:


d. Calcul de la similitude (deux images)

e, indice d'ordre et indice d'ordre inverse
Dans l'arborescence du dictionnaire, l'index d'ordre et l'index d'ordre inverse seront ajoutés:
Indexation inverse, c'est-à-dire que pour chaque nœud feuille de l'arborescence du dictionnaire visuel, une liste est conservée. La liste stocke l'image contenant le mot et le poids du mot dans l'image de trame. Le poids du mot utilise TF-IDF;
L'index séquentiel stocke les points de caractéristique de l'image et les
nœuds où les points de caractéristique sont à un certain niveau de l'arborescence du dictionnaire visuel . L'indexation séquentielle peut être utilisée pour accélérer la mise en correspondance des points de fonction. Lorsque les points de fonction de deux cadres d'images doivent être mis en correspondance, seuls les points de fonction au même nœud peuvent être mis en correspondance, ce qui réduit le nombre de points de fonction qui doivent être mis en correspondance.
3. Vérification de bouclage
Référence: [1] Lu Yabing. Recherche sur la méthode de positionnement et de cartographie en temps réel basée sur la vision binoculaire [D]. Harbin Institute of Technology, 2018.
La nécessité d'une vérification de bouclage
L'algorithme de détection de bouclage décrit précédemment obtient le résultat de la détection de bouclage en fonction de la similitude entre les trames d'image. Dans ce cas, il peut y avoir une fausse détection, de sorte que le résultat final de la détection de bouclage doit être obtenu davantage par le biais d'un contrôle de continuité et d'un contrôle géométrique
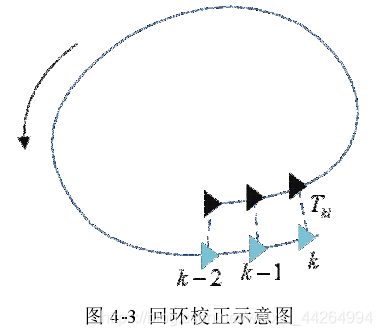
Contrôle de continuité
Le contrôle de continuité signifie que les images clés de bouclage candidates obtenues par l'algorithme de détection de bouclage pour plusieurs images clés consécutives sont également continues. Comme le montre la figure ci-dessous, les trames de bouclage correspondant aux trois moments représentés sur la figure ont des observations communes, elles sont donc connectées les unes aux autres dans la vue commune.
Vérification de la géométrie
La vérification de la géométrie fait référence au calcul de la transformation de pose entre deux images clés en fonction des informations de pose entre l'image actuelle et les images clés obtenues par détection de bouclage.
4. Implémenter la détection de bouclage
Supposons qu'il existe déjà une arborescence de dictionnaires visuels intégrée et que l'index d'ordre et l'index d'ordre inversé soient établis entre le temps initial et l'image actuelle:
Effectuez les opérations suivantes sur l'image à l'heure actuelle (vérifiez si elle est arrivée avant, en formant une boucle):
1. Extraire les points caractéristiques de l'image actuelle, calculer les descripteurs d'entités correspondants et obtenir le vecteur de mots décrivant l'image de l'image
2. Utiliser l'index d'ordre inverse sur l'arborescence du dictionnaire visuel pour trouver une série d'images avec les mêmes mots que l'image actuelle pour la détection de boucle Image candidate;
3. Calculez la similitude entre l'image actuelle et l'image candidate (image précédente), et utilisez la similitude la plus élevée comme paire de boucles;
4. Vérifiez la paire de boucles obtenue pour vérifier si c'est la bonne boucle.
