# coding = utf-8
'' '
Film Reptile Douban, prise en charge de l'exploration chronologique
'' '
temps d'importation
demandes d'importation
les importer
importer re
importer json
importer Save_Data
journalisation d'importation
#Définissez le niveau de journalisation et le nom du fichier journal
logging.basicConfig (
# Niveau de journal
level = "ERROR",
# Format de l'heure d'impression du journal
datefmt = "% Y-% m-% d% H:% M:% S",
# Format du contenu d'impression du journal
format = '% (asctime) s% (filename) s [ligne:% (lineno) d]% (message) s',
# Consigner la sortie dans un fichier
filename = ("log_2010.txt"),
# Mode superposition
filemode = 'w'
)
# Définissez l'en-tête de la demande
en-têtes = {
"Referer": "https://movie.douban.com/explore",
"User-Agent": "Mozilla / 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit / 537.36 (KHTML, comme Gecko) Chrome / 78.0.3904.108 Safari / 537.36"
}
# Définir l'intervalle de temps pour obtenir l'année
year_dict = {
"80 年代": "1980,1989",
"90 年代": "1990, 1999",
"2000 年代": "2000,2009",
"2010 年代": "2010,2019",
}
# Définir le nombre de pages de films acquises à chaque génération
max_page = {
"80 年代": "376",
"90 年代": "752",
"2000 年代": "1342",
"2010 年代": "2315",
}
def get_doubanmovie_index (time_start, idx, headers):
'' '
Obtenir le contenu de la page de catégorie de film
: param movie_type: catégorie de film
: en-têtes de param: demande d'informations d'en-tête
: return: données de la page de catégorie de film
'' '
proxy global
proxy = ''
my_proxy = {
'http': 'http: //' + proxy,
'https': 'https: //' + proxy,
}
logging.error (proxy)
logging.error (my_proxy)
# page_idx = idx * 20
url = "https://movie.douban.com/j/new_search_subjects?" \
"sort = U & range = 0,10 & tags =% E5% 8A% A8% E6% BC% AB & start = {}" \
"& countries =% E6% 97% A5% E6% 9C% AC & year_range = {}". format (idx, time_start)
essayer:
logging.error (my_proxy)
ret = requests.get (url, headers = headers, timeout = (2,4))
# ret.raise_for_status () #Déterminez si le code d'état dans l'en-tête HTTP est 200
sauf:
print ("Erreur lors de l'obtention du film:% s contenu de la page; URL:% s"% (time_start, url))
logging.error ("Erreur lors de l'obtention du film: contenu de la page% s; url:% s"% (time_start, url))
logging.error ('')
revenir ""
retour ret.text
def get_movie_list (données):
'' '
Analyser les données de la page du film, principalement pour obtenir le nom du film et l'URL de la page des détails du film
: données param: données de la page de catégorie de film
: retour: nom du film et URL de la page des détails du film
'' '
movie_list = []
essayer:
tmp_data = json.loads (données)
topics_data = tmp_data ["données"]
pour i dans topics_data:
movice_name = i ["title"]
movie_url = i ["url"]
movie_list.append ([movice_name, movie_url])
sauf:
imprimer ("Impossible d'obtenir le nom du film et la page des détails du film ~")
logging.error ("Impossible d'obtenir le nom du film et la page des détails du film ~")
logging.error (données)
si len (movie_list) == 0:
logging.error (données)
revenir []
return movie_list
def movie_content_page (url, en-têtes):
'' '
Obtenir le contenu de la page des détails du film
: param url: URL de la page de détail du film
: en-têtes de param: en-têtes de demande
: retour: données de la page de détail du film
'' '
proxy global
my_proxy = {
'http': 'http: //' + proxy,
'https': 'https: //' + proxy,
}
logging.error (proxy)
logging.error (my_proxy)
essayer:
logging.error (my_proxy)
ret = requests.get (url, headers = headers, timeout = (2,4))
# ret.raise_for_status ()
sauf:
# proxy = MyProxy.get_proxy ()
print ("Impossible d'obtenir la page des détails du film, URL:% s"% URL)
logging.error ("Impossible d'obtenir la page des détails du film, URL:% s"% URL)
logging.error ('')
revenir ""
retour ret.text
def handle_movie_data (données):
'' '
Analyser les données de la page de détail du film, extraire la liste des acteurs, introduction du tracé
: param data: toutes les données de la page de détail du film
: retour: distribution de film
: retour: Introduction à l'intrigue du film
'' '
movie_info = []
mark_pattern = re.compile ('property = \ "v: average \"> (. *?) </strong>')
mark_and_count = re.findall (mark_pattern, data)
count_pattern = re.compile ('property = \ "v: votes \"> (. *?) </span>')
count = re.findall (count_pattern, data)
movie_year_pattern = re.compile ('\ "datePublished \". *?:. *? \ "(. *?) \"')
movie_name_pattern = re.compile ('property = \ "v: itemreviewed \"> (. *?) </span>')
movie_name = re.findall (movie_name_pattern, data)
movie_year_bk = re.findall ('class = \ "year \"> (. *?) </span>', données)
movie_year = re.findall (movie_year_pattern, data)
essayer:
#Nom du film
_name = (movie_name [0])
sauf:
_name = ""
essayer:
# Année du film
_year_bk = (str (movie_year_bk [0]). replace ("(", ""). replace (")", ""))
sauf:
_year_bk = ""
essayer:
_year = (movie_year [0])
sauf:
_year = ""
essayer:
_count = (count [0])
sauf:
_count = ""
essayer:
_mark = (mark_and_count [0])
sauf:
_mark = ""
essayer:
movie_info.append ([_ name, _year_bk, _year, _mark, _count])
sauf:
imprimer ("err")
logging.error ("ERROR movie_name:% s movie_year:% s movie_mark:% s movie_count:% s"% (
nom_film,
movie_year_bk,
movie_year,
mark_and_count,
compter))
return movie_info
def main (year_type, count):
proxy global
my_count = 1
mk_path = 'Ensemble de données' + "\\" + type_année
# Si le dossier de catégorie n'existe pas, créez-le
sinon os.path.exists (mk_path):
os.makedirs (mk_path)
# Extraire l'année de début
time_start = year_dict.get (year_type)
pour idx dans la plage (nombre):
page_idx = idx * 20
si page_idx> int (max_page.get (year_type)):
Pause
pour i dans la plage (5):
# Obtenez le contenu de la page d'accueil du film dans cette catégorie
index_data = get_doubanmovie_index (time_start, page_idx, headers)
# Analyser le contenu de la page d'accueil, obtenir ["nom du film", "URL de la page des détails du film"]
movie_url_list = get_movie_list (index_data)
si len (index_data)> 0 et len (movie_url_list)> 0:
Pause
autre:
logging.error ("------------% s"% proxy)
time.sleep (2)
si i> 3:
Pause
logging.error ("La page% d a réussi! length_html:% d"% (
(page_idx + 1),
len (index_data)
)
)
pour url_list dans movie_url_list:
logging.error (url_list)
movie_url = url_list [1]
pour i dans la plage (5):
# Obtenez le contenu de la page des détails du film
movie_content_data = movie_content_page (movie_url, en-têtes)
# Obtenez le casting du film et l'introduction de l'intrigue
movie_info_list = handle_movie_data (movie_content_data)
si len (movie_content_data)> 0 et len (movie_info_list)> 0:
print ('Vous avez déjà% d données de film'% my_count)
my_count + = 1
Pause
autre:
logging.error ("------------% s"% proxy)
si i> 3:
Pause
# Enregistrer l'introduction du film
Save_Data.save_content (mk_path, movie_info_list)
logging.error ("La page% d a réussi! url:% s"% (
(page_idx + 1),
liste_url [1]
)
)
si __name__ == '__main__':
sinon os.path.exists ('ensemble de données'):
os.mkdir ('Ensemble de données')
# Définir la liste des catégories à explorer
want_get_movie = ["80s", "90s", "2000s", "2010s"]
# Définissez le nombre de pages explorées, 20 par page
COUNT = 2315
# Parcourez la liste des catégories à explorer
pour type_name dans want_get_movie:
main (nom_type, COUNT)
# coding = utf-8
'' '
Module de stockage de données pour enregistrer les données du film
'' '
importer csv
journalisation d'importation
def save_actor (chemin_fichier, données):
'' '
Enregistrer les informations sur l'acteur de film
: param file_path: informations de chemin enregistrées
: données param: informations sur l'acteur de film
:revenir:
'' '
file_name = file_path + "\\" + "Actor Table.csv" #Sous le dossier du nom du film, enregistrez les données dans Actor Table.csv
o_file = open (nom_fichier, "w", newline = "", encoding = "utf-8-sig")
f = csv.writer (o_file)
pour i dans les données:
f. écrivain (i)
o_file.close ()
def save_content (chemin_fichier, données):
'' '
: param file_path: informations de chemin enregistrées
: données param: informations sur le film
:revenir:
'' '
essayer:
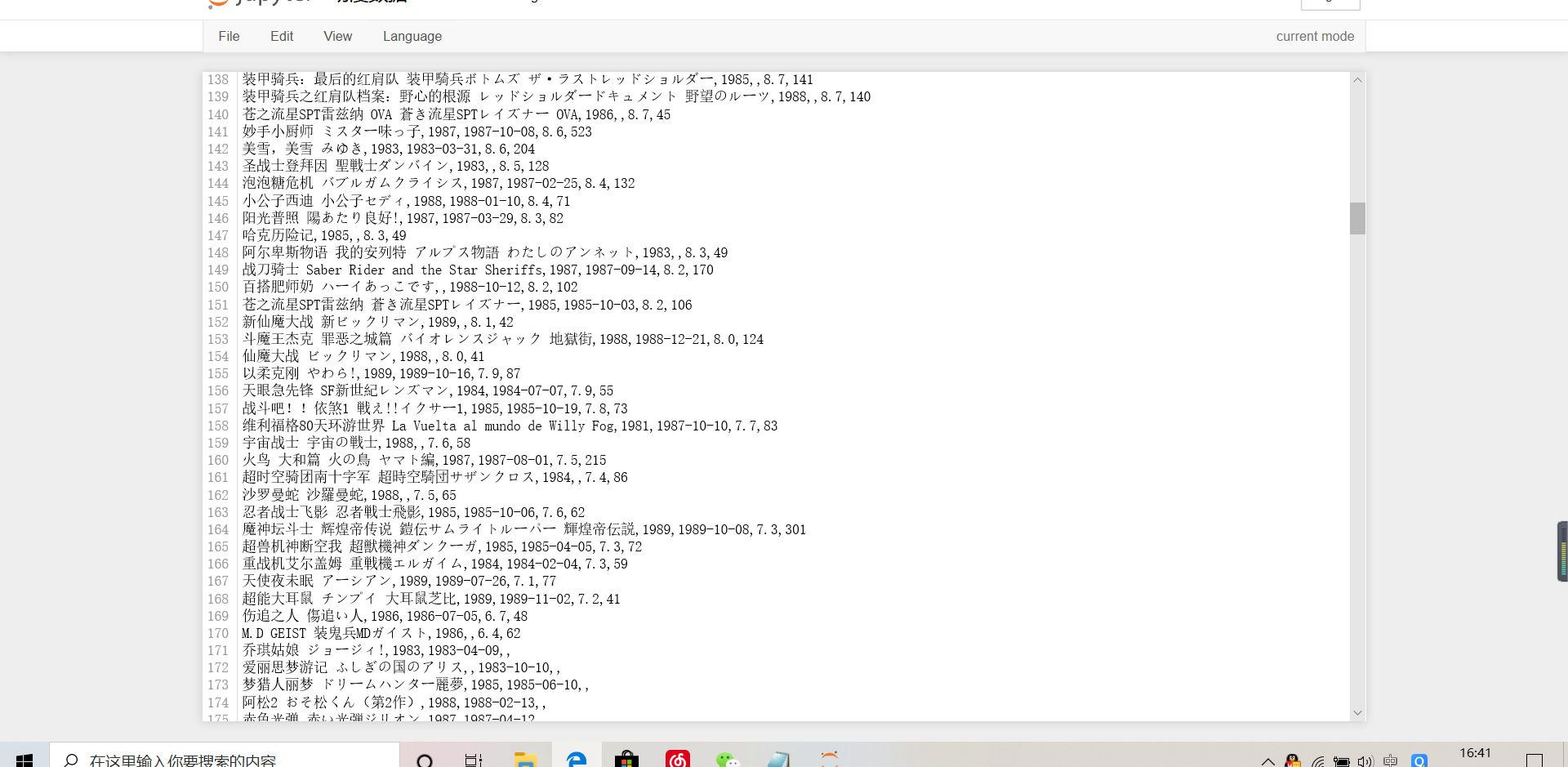
file_name = file_path + "\\" + "Anime data.csv"
f = open (nom_fichier, "a", encoding = "utf-8-sig", newline = "")
c_f = csv.writer (f)
pour i dans les données:
c_f.writerow (i)
f.close ()
sauf:
logging.error ("Échec de l'enregistrement des données:% s"% de données)