1. Introduction à XPath
Pour analyser la relation hiérarchique des pages Web, la fonction de sélection de XPath est très puissante, elle fournit une expression de sélection de chemin très simple et claire.
En outre, il fournit également plus de 100 fonctions intégrées pour la correspondance de chaînes, numériques et temporelles, ainsi que le traitement des nœuds et des séquences.
Presque tous les nœuds de positionnement peuvent être sélectionnés à l'aide de XPath.
Site officiel: https://www.w3.org/TR/xpath
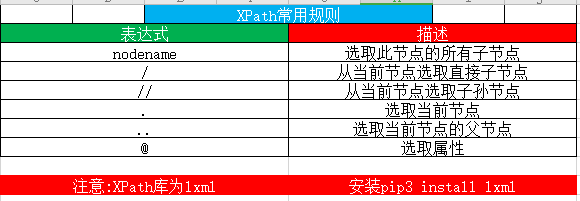
1. Règles communes XPath:
2. Utilisation de base
depuis lxml import etree text = '' ' <div> <ul> <li class = "one"> <a href="link1"> 1 </a> </li> <li class = "two"> <a href = "link2"> 2 </a> </li> <li class = "three"> <a href="link3"> 3 </a> </li> <li class = "four"> <a href = "link4"> 4 </a> </li> <li class = "five"> <a href="link5"> 5 </a> </ul> </div> '' ' # 将 文本转换 为 网页 类型 , 并 修复 补 全 html = etree.Le code HTML (texte) # Le complément complet de la structure de la page Web, le fichier chemin ouvert # HTML etree.parse = ( 'demo.html', etree.HTMLParser ()) Imprimer (HTML) # convertir la page en type de texte, sous forme d' octets = Résultat etree.tostring (HTML) # dans str type Résultat = result.decode ( " UTF-. 8 " ) Imprimer (Résultat)
1. Sélection de correspondance (tous les nœuds)
depuis lxml import etree text = '' ' <div> <ul> <li class = "one"> <a href="link1"> 1 </a> </li> <li class = "two"> <a href = "link2"> 2 </a> </li> <li class = "three"> <a href="link3"> 3 </a> </li> <li class = "four"> <a href = "link4"> 4 </a> </li> <li class = "five"> <a href="link5"> 5 </a> </ul> </div> '' ' # 将 文本转换 为 网页 类型 , 并 修复 补 全 html = etree.Le code HTML (texte) # sélectionné correspondant contenu Résultat = html.xpath ( ' // * ' ) Imprimer (Résultat)

2. Noeuds enfants
depuis lxml import etree text = '' ' <div> <ul> <li class = "one"> <a href="link1"> 1 </a> </li> <li class = "two"> <a href = "link2"> 2 </a> </li> <li class = "three"> <a href="link3"> 3 </a> </li> <li class = "four"> <a href = "link4"> 4 </a> </li> <li class = "five"> <a href="link5"> 5 </a> </ul> </div> '' ' # 将 文本转换 为 网页 类型 , 并 修复 补 全 html = etree.Le code HTML (texte) # sélectionné correspondant contenu Résultat = html.xpath ( ' // Li / A ' ) Imprimer (Résultat)
Ici "/" représente les nœuds enfants directs, "//" représente tous les nœuds descendants

3. Noeud parent
Noeud parent: utilisez " .. ", vous pouvez également utiliser parent :: pour représenter le parent
depuis lxml import etree text = '' ' <div> <ul> <li class = "one"> <a href="link1"> 1 </a> </li> <li class = "two"> <a href = "link2"> 2 </a> </li> <li class = "three"> <a href="link3"> 3 </a> </li> <li class = "four"> <a href = "link4"> 4 </a> </li> <li class = "five"> <a href="link5"> 5 </a> </ul> </div> '' ' # 将 文本转换 为 网页 类型 , 并 修复 补 全 html = etree.Le code HTML (texte) # sélectionné correspondant contenu # attribut est une balise d'attribut de classe parente link4 Résultat = html.xpath ( « //a[@href="link4"]/../@class » ) #@ 表示 属性 result1 = html.xpath ( ' // a [@ href = "link4"] / parent :: * / @ class ' ) print (result) print (result1)

4. Acquisition de texte
depuis lxml import etree text = '' ' <div> <ul> <li class = "one"> <a href="link1"> 1 </a> </li> <li class = "two"> <a href = "link2"> 2 </a> </li> <li class = "three"> <a href="link3"> 3 </a> </li> <li class = "four"> <a href = "link4"> 4 </a> </li> <li class = "five"> <a href="link5"> 5 </a> </ul> </div> '' ' # 将 文本转换 为 网页 类型 , 并 修复 补 全 html = etree.Le code HTML (texte) # correspondant contenu sélectionné # attribut est une balise attribut classe parente link4 Résultat = html.xpath ( ' // un [@ href = "link4"] / texte () ' ) Imprimer(résultat)

5. Correspondance multi-valeurs d'attribut
depuis lxml import etree text = '' ' <div> <ul> <li class = "one"> <a href="link1"> 1 </a> </li> <li class = "two"> <a href = "link2"> 2 </a> </li> <li class = "three two"> <a href="link3"> 3 </a> </li> <li class = "four"> < un href = "link4"> 4 </a> </li> <li class = "five"> <a href="link5"> 5 </a> </ul> </div> '' ' # 将文本 转换 为 网页 类型 , 并 修复 补 全 html = etree.Le code HTML (texte) # correspondant contenu sélectionné # le contient (@ propriété, valeur) Résultat = html.xpath ( ' // Li [le contient (@class, "Trois")] / A / text () ' ) imprimer (résultat)
6. Correspondance multi-attributs
Plusieurs attributs déterminent un nœud, puis vous devez faire correspondre plusieurs attributs
depuis lxml import etree text = '' ' <div> <ul> <li class = "one"> <a href="link1"> 1 </a> </li> <li class = "two three" name = "item"> <a href="link2"> 2 </a> </li> <li class = "three two"> <a href="link3"> 3 </a> </li> <li class = "four"> <a href="link4"> 4 </a> </li> <li class = "five"> <a href="link5"> 5 </a> </ul> </ div > '' ' # Convertis type de page de texte et fixer le complément HTML = etree.HTML (texte) # correspondant contenu sélectionné # le contient (@ propriété, valeur) Résultat = html.xpath ( ' // Li [le contient (@class, « Trois ") et @ name =" item "] / a / text ()' ) print (résultat)
7. Choisissez dans l'ordre
depuis lxml import etree text = '' ' <div> <ul> <li class = "one"> <a href="link1"> 1 </a> </li> <li class = "two three" name = "item"> <a href="link2"> 2 </a> </li> <li class = "three two"> <a href="link3"> 3 </a> </li> <li class = "four"> <a href="link4"> 4 </a> </li> <li class = "five"> <a href="link5"> 5 </a> </ul> </ div > '' ' # Convertis type de page de texte et fixer le complément HTML = etree.HTML (texte) # sélectionné correspondant contenu # premier match Li RESULT1 = html.xpath ( ' // Li [. 1] / A / text () ' ) #Enfin, un compte à rebours 2 result2 = html.xpath ( ' // Li [Last () - 2] / A / texte () ' ) # dernière result3 = html.xpath ( ' // Li [Dernière ()] / A / texte () ' ) # . moins de 3 result4 = html.xpath ( ' // Li [ la position () <3.] / A / texte () ' ) # fonctions intégrées 100, http: //www.w3school.com.cn/ xpath / xpath_functions.asp print (result1) print (result2) print (result3) print (result4)

8. Sélection de l'axe des nœuds
# Attribut d'un attribut de classe parent link4 tag