table des matières
11 、 AJOUTER UNIQUEMENT LE MODE
Dans le blog précédent, nous avons présenté comment installer Redis.Il existe un fichier de configuration très important redis.conf (sous le répertoire /opt/redis-4.0.9) dans le répertoire de décompression de Redis.La configuration de nombreuses fonctions de Redis est ici. Ceci est fait dans le fichier, comme je l'ai dit dans la dernière conférence, généralement afin de ne pas endommager les fichiers installés, il est préférable de ne pas changer la configuration d'usine par défaut, nous avons donc copié ce fichier de configuration dans le répertoire / etc / redis /.
Ouvrez ce fichier avec la commande vim /etc/redis/redis.conf. Ci-dessous, nous présenterons ce fichier de configuration en détail.
ps: Peu importe si vous ne comprenez pas la signification de ces configurations, nous les présenterons dans des exemples spécifiques plus tard, familiarisez-vous d'abord avec elles.
1. Au début
Il n'y a rien à dire ici.Il faut noter que lorsque vous avez besoin d'utiliser la taille de la mémoire plus tard, vous pouvez spécifier l'unité, généralement sous la forme de k, gb, m, et l' unité n'est pas sensible à la casse .
2 、 COMPREND
Nous savons que Redis n'a qu'un seul fichier de configuration. Si plusieurs personnes développent et maintiennent, plusieurs fichiers de configuration de ce type sont nécessaires. À ce stade, plusieurs fichiers de configuration peuvent être configurés ici via include /path/to/local.conf. Le fichier de configuration redis.conf sert de porte principale.
ps: Si vous avez utilisé le développement struts2, dans le cas du développement multi-personnes dans l'équipe de projet, il y aura généralement plusieurs fichiers struts2.xml, qui seront également introduits via la configuration de classe.
De plus, lorsque vous devez faire attention, si vous écrivez cette configuration au début du fichier redis.conf, la configuration suivante écrasera la configuration du fichier importé. Si vous voulez vous concentrer sur la configuration du fichier importé, vous devez écrire la configuration d'inclusion dans redis.conf La fin du fichier.
3 、 MODULES

La fonction explosive de redis3.0 est l'ajout de clusters, et redis4.0 ajoute de nombreuses nouvelles fonctions sur la base de 3.0, dont la configuration du module personnalisé ici est l'une d'entre elles. Grâce à la configuration de loadmodule ici, un module personnalisé sera introduit pour ajouter certaines fonctions.
4 、 RÉSEAU
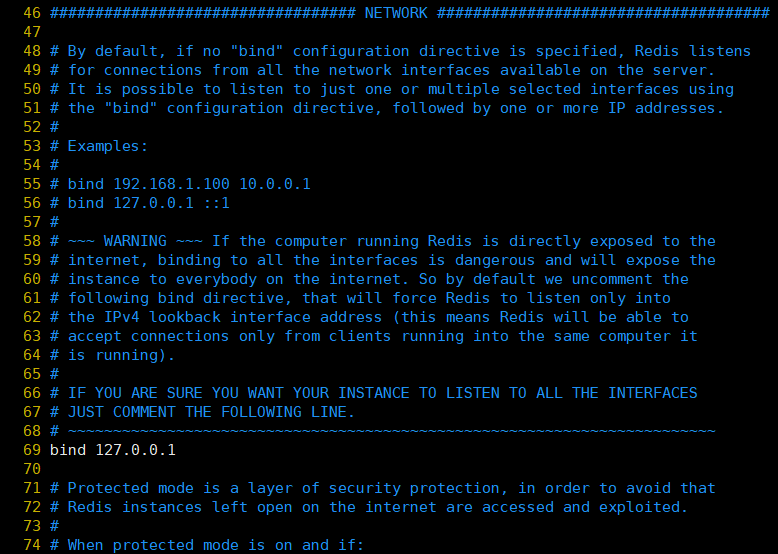
ps: La configuration ici est plus longue, je n'ai intercepté qu'une partie, la même en dessous.
①, bind: liez l'IP de la carte réseau du serveur redis, la valeur par défaut est 127.0.0.1, qui est l'adresse de bouclage locale. Dans ce cas, l'accès au service redis ne peut se faire que via la connexion client locale, mais pas via la connexion distante. Si l'option de liaison est vide, elle acceptera toutes les connexions des interfaces réseau disponibles.
②, port: spécifiez le port sur lequel redis s'exécute, la valeur par défaut est 6379. Étant donné que Redis est un modèle à un seul thread, le port sera modifié lorsque plusieurs processus Redis sont ouverts sur une seule machine.
③, timeout: définissez le délai d'expiration lorsque le client est connecté, en secondes. Lorsque le client n'émet aucune instruction dans ce délai, la connexion est fermée. La valeur par défaut est 0, ce qui signifie qu'elle n'est pas fermée.
④, tcp-keepalive: l'unité est en secondes, ce qui signifie que SO_KEEPALIVE sera utilisé périodiquement pour détecter si le client est toujours dans un état sain pour éviter que le serveur ne soit bloqué. La valeur officielle recommandée est 300 s. Si elle est définie sur 0, elle ne le sera pas périodiquement Détection.
5 、 GÉNÉRAL
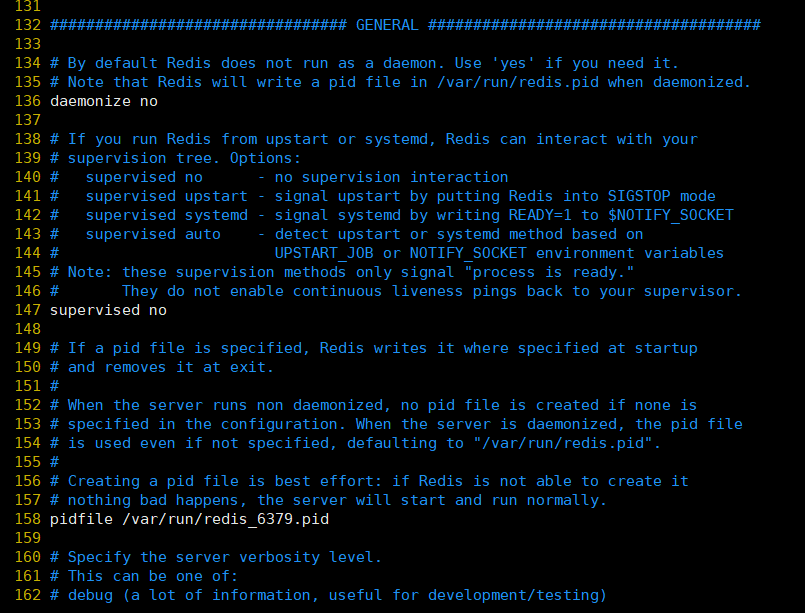
Détails de configuration détaillés:
①, daemonize: défini sur yes pour spécifier que Redis est démarré en tant que démon (démarrage en arrière-plan). La valeur par défaut est non
②, pidfile: configurez le chemin du fichier PID, lorsque redis est exécuté en tant que démon, il écrira le pid dans le fichier /var/redis/run/redis_6379.pid par défaut
③, loglevel: définissez le niveau de journalisation. La valeur par défaut est notice, qui a les 4 valeurs suivantes:
debug (enregistrez une grande quantité d'informations de journal, adaptées aux phases de développement et de test)
verbeux (plus d'informations sur le journal)
avis (informations de journal appropriées, utilisées dans l'environnement de production)
avertissement (seules certaines informations importantes et clés seront enregistrées)
④, fichier journal: configurez l'adresse du fichier journal, qui est imprimée par défaut dans la fenêtre du terminal de ligne de commande
⑤ Bases de données: définissez le nombre de bases de données. La base de données par défaut est DB 0. Vous pouvez utiliser la commande select <dbid> pour sélectionner une base de données différente à chaque connexion. Dbid est une valeur comprise entre 0 et databases-1. La valeur par défaut est 16, ce qui signifie que Redis a 16 bases de données par défaut.
6 、 INSTANTANÉ
La configuration ici est principalement utilisée pour les opérations de persistance.
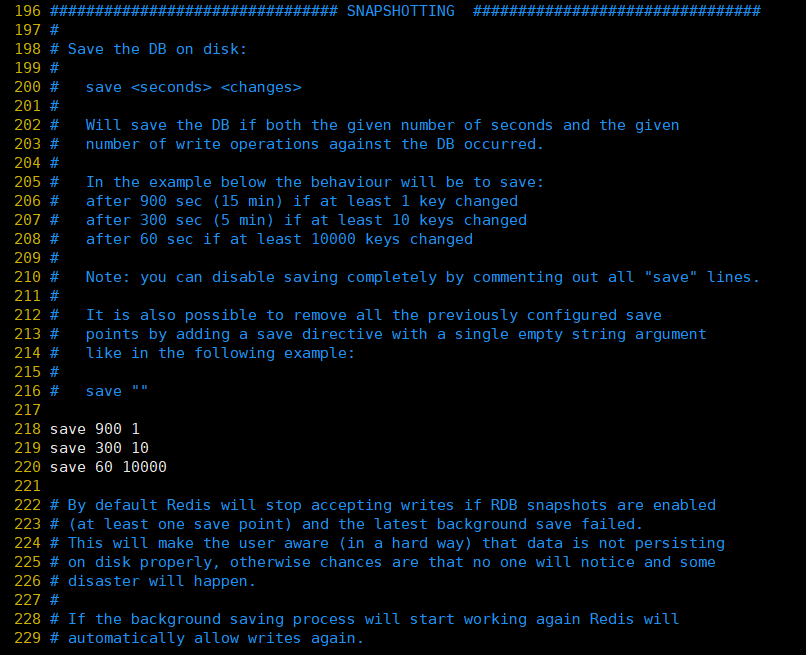
①, enregistrer: il s'agit de configurer les conditions de persistance qui déclenchent Redis, c'est-à-dire quand enregistrer les données en mémoire sur le disque dur. La configuration par défaut est la suivante:
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存
save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存
save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存Bien sûr, si vous utilisez uniquement la fonction de mise en cache de Redis et que vous n'avez pas besoin de persistance, vous pouvez commenter toutes les lignes de sauvegarde pour désactiver la fonction de sauvegarde. Vous pouvez le désactiver directement avec une chaîne vide: save ""
②, stop-writes-on-bgsave-error: La valeur par défaut est yes. Lorsque RDB est activé et que la dernière fois que l'arrière-plan enregistre les données échoue, si Redis arrête de recevoir des données. Cela permettra aux utilisateurs de se rendre compte que les données ne sont pas correctement conservées sur le disque, sinon personne ne remarquera qu'une catastrophe s'est produite. Si Redis redémarre, vous pouvez recommencer à recevoir des données
③, rdbcompression; la valeur par défaut est yes. Pour les instantanés stockés sur le disque, vous pouvez définir s'il faut compresser le stockage. Si tel est le cas, redis utilisera l'algorithme LZF pour la compression. Si vous ne souhaitez pas utiliser le processeur pour la compression, vous pouvez désactiver cette fonctionnalité, mais les instantanés stockés sur le disque seront plus volumineux.
④, rdbchecksum: la valeur par défaut est yes. Après avoir stocké l'instantané, nous pouvons également laisser redis utiliser l'algorithme CRC64 pour la vérification des données, mais cela augmentera la consommation de performances d'environ 10%. Si vous souhaitez obtenir une amélioration maximale des performances, vous pouvez désactiver cette fonction.
⑤, dbfilename: définit le nom de fichier du snapshot, la valeur par défaut est dump.rdb
Â. Dir: définit le chemin de stockage du fichier de capture instantanée. Cet élément de configuration doit être un répertoire et non un nom de fichier. Utilisez le nom de fichier db ci-dessus comme nom de fichier enregistré.
7 、 RÉPLICATION

①, slave-serve-stale-data: la valeur par défaut est yes. Lorsqu'un esclave perd le contact avec le maître ou qu'une réplication est en cours, l'esclave peut avoir deux comportements:
1) Si oui, l'esclave répondra toujours à la demande du client, mais les données renvoyées peuvent être obsolètes, ou les données peuvent être vides lors de la première synchronisation
2) Si ce n'est pas le cas, lorsque vous exécutez d'autres commandes à l'exception de l'info qu'il salveof, l'esclave retournera une erreur "SYNC avec maître en cours"
 Slave-read-only: configurez si l'instance esclave de Redis accepte les opérations d'écriture, c'est-à-dire si l'esclave est en lecture seule Redis. La valeur par défaut est yes.
③, repl-diskless-sync: indique si la réplication de données maître-esclave utilise la fonction de réplication sans disque. La valeur par défaut est non.
④, repl-diskless-sync-delay: Lorsqu'aucune sauvegarde sur disque dur n'est activée, le serveur attend un certain temps avant de transmettre le fichier RDB à la station esclave via le socket. Ce temps d'attente est configurable. Ceci est important car une fois la transmission démarrée, il est impossible de desservir un esclave nouvellement arrivé. L'esclave fera la queue pour la prochaine transmission RDB. Le serveur attend donc un moment l'arrivée d'autres esclaves. Le temps de retard est en secondes et la valeur par défaut est de 5 secondes. Pour désactiver cette fonction, réglez-la simplement sur 0 seconde et la transmission commencera immédiatement. La valeur par défaut est 5.
⑤ repl-disable-tcp-nodelay: Indique s'il faut désactiver TCP_NODELAY sur la station esclave après la synchronisation. Si vous choisissez yes, redis utilisera une plus petite quantité de paquets TCP et de bande passante pour envoyer des données à la station esclave. Mais cela entraînera un petit retard des données dans la station esclave. Le noyau Linux a un délai allant jusqu'à 40 millisecondes dans la configuration par défaut. Si vous sélectionnez non, le délai de données de l'esclave ne sera pas tellement élevé, mais la bande passante requise pour la sauvegarde est relativement importante. Par défaut, nous optimisons les facteurs potentiels, mais c'est une bonne idée de le basculer sur oui dans des conditions de charge élevée ou lorsque les stations maître et esclave sautent. La valeur par défaut est non.
8 、 SÉCURITÉ

①, rename-command: commande renommer, pour certaines commandes dangereuses telles que:
flushdb (effacer la base de données)
flushall (effacer tous les enregistrements)
config (Le serveur peut être configuré une fois le client connecté)
clés (une fois le client connecté, toutes les clés existantes peuvent être visualisées)
En tant que serveur redis-server, il est souvent nécessaire de désactiver les commandes ci-dessus pour rendre le serveur plus sécurisé. La méthode spécifique de désactivation est la suivante:
- commande renommer FLUSHALL ""
Vous pouvez également garder la commande mais pas facile à utiliser, il suffit de renommer cette commande:
- commande renommer FLUSHALL abcdefg
De cette façon, après le redémarrage du serveur, vous devez utiliser la nouvelle commande pour effectuer l'opération, sinon le serveur signalera une erreur de commande inconnue.
②, requirepass: définissez le mot de passe de connexion redis
Par exemple: requirepass 123 signifie que le mot de passe de connexion redis est 123.
9 、 CLIENTS

Â, maxclients: définissez le nombre maximal de connexions client simultanées. La valeur par défaut est illimitée. Le nombre de connexions client que Redis peut ouvrir en même temps est le plus grand fichier que le processus Redis peut ouvrir. Le nombre de descripteurs-32 (le serveur redis lui-même en utilisera), si vous définissez maxclients sur 0. N'indique aucune restriction. Lorsque le nombre de connexions client atteint la limite, Redis fermera la nouvelle connexion et retournera un nombre maximal de clients atteints un message d'erreur au client
10 、 GESTION DE LA MÉMOIRE

①, maxmemory: définit la mémoire maximale de Redis, si elle est définie sur 0. N'indique aucune restriction. Il est généralement utilisé en conjonction avec le paramètre maxmemory-policy décrit ci-dessous.
②, maxmemory-policy: lorsque l'utilisation de la mémoire atteint la valeur maximale définie par maxmemory, la stratégie d'effacement de la mémoire utilisée par redis. Il existe plusieurs options:
1) Volatile-lru utilise l'algorithme LRU pour supprimer la clé avec un délai d'expiration (LRU: le moins récemment utilisé)
2) allkeys-lru utilise l'algorithme LRU pour supprimer n'importe quelle clé
3) volatile-aléatoire supprime les clés aléatoires avec un délai d'expiration défini
4) allkeys-random supprimer ke aléatoire
5) volatile-ttl supprime la clé sur le point d'expirer (TTL mineur)
6) noeviction noeviction ne supprime aucune clé, mais renvoie une erreur d'écriture, l'option par défaut
③, maxmemory-samples: les algorithmes LRU et TTL minimal ne sont pas des algorithmes précis, mais des algorithmes relativement précis (afin d'économiser de la mémoire). Vous pouvez choisir la taille de l'échantillon à tester à volonté. Redis sélectionne par défaut 3 échantillons à tester. Vous pouvez définir le nombre d'échantillons via maxmemory-samples.
11 、 AJOUTER UNIQUEMENT LE MODE

 Appendonly: le redis par défaut utilise la persistance RDB, ce qui est suffisant dans de nombreuses applications. Cependant, si redis plante au milieu, cela peut entraîner une perte de données pendant plusieurs minutes. Selon la stratégie de sauvegarde pour la persistance, Ajouter uniquement un fichier est une autre méthode de persistance qui peut fournir de meilleures caractéristiques de persistance. Redis écrira les données écrites à chaque fois dans le fichier appendonly.aof après réception. Redis lira d'abord les données de ce fichier en mémoire à chaque démarrage, et ignorera d'abord le fichier RDB. La valeur par défaut est non.
②, appendfilename: nom de fichier Aof, la valeur par défaut est "appendonly.aof"
③, appendfsync: la configuration de la stratégie de persistance aof; no signifie que fsync n'est pas exécuté, et le système d'exploitation garantit que les données sont synchronisées avec le disque, ce qui est le plus rapide; signifie toujours que fsync est exécuté pour chaque écriture pour s'assurer que les données sont synchronisées sur le disque; everysec signifie chaque L'exécution de fsync une fois par seconde peut entraîner la perte de ces données 1s
④, no-appendfsync-on-rewrite: Quand AOF réécrit ou écrit des fichiers RDB, une grande quantité d'E / S sera exécutée. À ce stade, pour le mode AOF d'Everysec et Always, l'exécution de fsync provoquera un blocage trop long, non- Le champ appendfsync-on-rewrite est défini sur no par défaut. Pour les applications avec des exigences de latence élevées, ce champ peut être défini sur yes, sinon il est toujours défini sur no, ce qui est un choix plus sûr pour les fonctionnalités de persistance. La valeur yes signifie que la nouvelle opération d'écriture ne sera pas synchronisée pendant la réécriture, qu'elle sera temporairement stockée dans la mémoire et sera écrite une fois la réécriture terminée. La valeur par défaut est non, et oui est recommandé. La politique fsync par défaut de Linux est de 30 secondes. 30 secondes de données peuvent être perdues. La valeur par défaut est non.
⑤ auto-aof-rewrite-pourcentage: la valeur par défaut est 100. Aof réécrit automatiquement la configuration. Lorsque la taille actuelle du fichier AOF dépasse la dernière taille du fichier AOF réécrit, il sera réécrit, c'est-à-dire que lorsque le fichier AOF atteint une certaine taille, Redis peut appeler bgrewriteaof pour réécrire le fichier journal. . Lorsque la taille actuelle du fichier AOF est deux fois la taille du fichier AOF obtenu à partir de la dernière réécriture du journal (définie sur 100), un nouveau processus de réécriture du journal démarre automatiquement.
⑥, auto-aof-rewrite-min-size: 64 Mo. Définissez la taille minimale du fichier aof qui permet la réécriture pour éviter la réécriture lorsque le pourcentage convenu est atteint mais que la taille est encore petite.
⑦, aof-load-truncated: le fichier aof peut être incomplet à la fin.Au démarrage de redis, les données du fichier aof sont chargées en mémoire. Un redémarrage peut se produire après l'arrêt du système d'exploitation hôte sur lequel redis est arrêté, en particulier si l'option data = ordonné n'est pas ajoutée au système de fichiers ext4. Ce phénomène se produit lorsque la redistribution ou l'arrêt anormal n'entraînera pas une interruption incomplète de la queue, vous pouvez choisir de laisser redis quitter , Ou importez autant de données que possible. Si vous sélectionnez oui, lorsque le fichier aof tronqué est importé, un journal sera automatiquement publié sur le client, puis chargé. Si ce n'est pas le cas, l'utilisateur doit redis-check-aof manuellement pour réparer le fichier AOF. La valeur par défaut est yes.
12 ÉCRITURE UA LUA
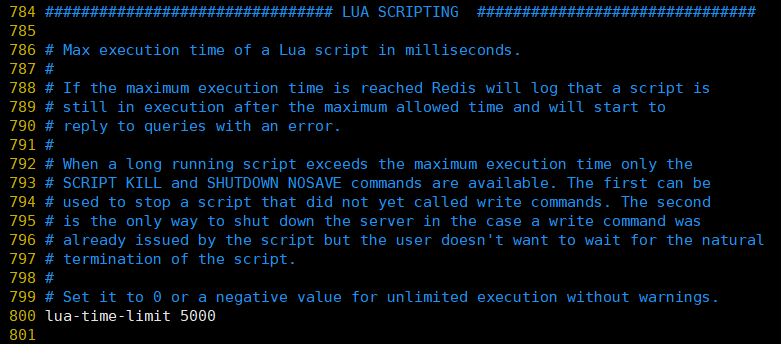
①, lua-time-limit: le temps maximum d'exécution d'un script lua, en ms. La valeur par défaut est 5000.
13 、 REDIS CLUSTER

①, cluster-enabled: commutateur de cluster, la valeur par défaut n'est pas d'ouvrir le mode cluster.
②, cluster-config-file: le nom du fichier de configuration du cluster, chaque nœud a un fichier de configuration lié au cluster, qui conserve les informations du cluster. Ce fichier n'a pas besoin d'être configuré manuellement. Ce fichier de configuration est généré et mis à jour par Redis. Chaque nœud de cluster Redis nécessite un fichier de configuration distinct. Veuillez vous assurer qu'il n'est pas en conflit avec le nom du fichier de configuration dans le système sur lequel l'instance est exécutée. La configuration par défaut est nodes-6379.conf.
③, cluster-node-timeout: la valeur configurable est 15000. Seuil de délai d'expiration d'interconnexion de nœud, délai d'expiration du nœud de cluster en millisecondes
④, facteur de validité de l'esclave du cluster: la valeur peut être définie sur 10. Lors du basculement, tous les esclaves demanderont à être maîtres, mais certains esclaves peuvent être déconnectés du maître pendant un certain temps, ce qui entraîne des données trop périmées. Ces esclaves ne doivent pas être promus maître. Ce paramètre permet de déterminer si le temps de déconnexion entre le nœud esclave et le maître est trop long. La méthode de jugement est la suivante: comparez le temps de déconnexion de l'esclave avec (noeud-timeout * slave-validité-factor) + repl-ping-slave-period. La période de repl-ping-slave par défaut est de 10 secondes, c'est-à-dire que si elle dépasse 310 secondes, l'esclave n'essaiera pas de basculer
⑤, cluster-migration-barrière: la valeur configurable est 1. Si le nombre d'esclaves du maître est supérieur à cette valeur, les esclaves peuvent être migrés vers d'autres maîtres isolés. Si ce paramètre est défini sur 2, ce n'est que lorsqu'un nœud maître a 2 nœuds esclaves fonctionnels, l'un de ses nœuds esclaves essaiera de migrer .
⑥ cluster-require-full-coverage: par défaut, tous les emplacements du cluster sont responsables des nœuds et l'état du cluster est correct pour fournir des services. Défini sur non pour fournir des services lorsque l'emplacement n'est pas entièrement alloué. Il n'est pas recommandé d'ouvrir cette configuration, car le maître de la petite partition acceptera toujours les demandes d'écriture pendant la partition, ce qui entraînera une incohérence des données pendant une longue période.