Principe de mise en œuvre Docker / principe du conteneur
Cet article vous permet principalement de comprendre ce qu'est un conteneur, qu'est-ce que Docker, quelle est la relation entre un conteneur et Docker et comment Docker l'implémente
Principe de mise en œuvre Docker / principe du conteneur
Le conteneur est une technologie fournie par le noyau Linux et Docker n'est qu'un outil de conteneur . Conteneur Docker ≠
Parler de Docker doit parler de conteneurs, d'abord comprendre ce qu'est un conteneur
Qu'est-ce qu'un conteneur (conteneur)
Selon la définition de WIKI, le concept de conteneur est le suivant:
- Un conteneur est un outil de base; il fait généralement référence à tout outil pouvant être utilisé pour contenir d'autres éléments, qui peuvent être partiellement ou complètement fermés, et est utilisé pour contenir, stocker et transporter des éléments. Les objets peuvent être placés dans un conteneur et le conteneur peut protéger le contenu.
- L'histoire de l'utilisation humaine des conteneurs remonte à au moins 100 000 ans, et peut même avoir une histoire de millions d'années;
Si vous souhaitez comprendre la technologie des conteneurs dans le domaine informatique, vous devez d'abord comprendre les problèmes rencontrés par la virtualisation traditionnelle. Regardez d'abord la section suivante.
récipient

La technologie des conteneurs informatiques elle-même est également une sorte de technologie de virtualisation (virtualisation légère). Avant la naissance de la technologie des conteneurs, nous disposions déjà de la virtualisation traditionnelle: KVM, VMware, Xen et d'autres implémentations de virtualisation traditionnelles. Alors pourquoi devrais-je utiliser un conteneur?
Problèmes d'architecture traditionnelle

Comme le montre la figure ci-dessus, la virtualisation traditionnelle est divisée en deux types: Type-I (bare metal) et Type-2 (embarquement). Imaginez le scénario suivant:
je veux exécuter un Nginx, et ce qui doit être fait sous le deux types de virtualisation:
1. Type-I: Vous devez créer un système d'exploitation pour le programme Nginx avant de pouvoir exécuter Nginx. Nginx s'exécute dans l'espace utilisateur du système d'exploitation virtuel.
Le lien de virtualisation des ressources matérielles est hyperviseur-> espace noyau du système d'exploitation-> espace utilisateur du système d'exploitation- > Nginx.
2. Type-II: Vous devez créer un système d'exploitation pour le programme Nginx avant de pouvoir exécuter Nginx. Nginx s'exécute dans l'espace utilisateur du système d'exploitation virtuel.
Le lien de virtualisation des ressources matérielles est le système d'exploitation hôte-> hyperviseur-> espace noyau du système d'exploitation-> espace utilisateur du système d'exploitation- > Nginx
En résumé, je veux exécuter Nginx. Dans la virtualisation traditionnelle, un système d'exploitation doit être préparé pour que Nginx exécute Nginx. L'installation et la configuration de la machine virtuelle prennent beaucoup de temps, puis vous pouvez commencer à évaluer ou tester les logiciels requis. Ces paramètres incluent l'installation du système d'exploitation, les mises à jour logicielles de sécurité ou de compatibilité, le réseau, le réglage du système, etc.
Remarque: la ligne horizontale n'est pas quelque chose qui peut être résolu par la technologie de conteneur elle-même. Docker fournit un mécanisme d'image pour le résoudre.
Revenons à l'essence de ce problème. Le fonctionnement du programme d'application dépend de la bibliothèque fournie par le système d'exploitation, du logiciel dépendant et de la structure de données ou du système de fichiers spécifique au système. Nous devons donc fournir un système d'exploitation virtuel pour l'application, et le système d'exploitation virtuel fournit également un noyau virtuel. Le noyau virtuel gère les périphériques matériels virtuels.
** Résumé: la virtualisation traditionnelle a un coût d'utilisation élevé, fournissant des périphériques matériels virtuels et des systèmes d'exploitation virtuels. Bien sûr, il y a aussi la pression du processeur et de la mémoire causée par ceux-ci. Dans ce cas, pourquoi ne pas simplement supprimer le système d'exploitation virtuel? La technologie des conteneurs est donc née.
Quel est le conteneur
Après avoir supprimé la couche du système d'exploitation virtuel, l'environnement que nous poursuivons est le suivant:
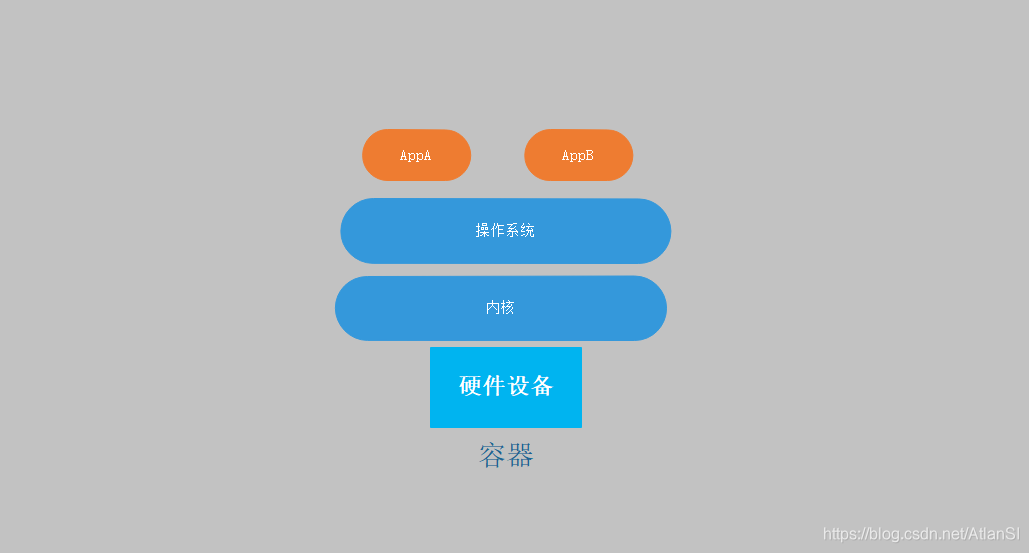
Créez plusieurs environnements d'isolation. L'application doit s'exécuter dans l'espace utilisateur. Le noyau fournit l'espace noyau. Le processus doit maintenant s'exécuter dans un environnement isolé. Il n'y a qu'un seul espace utilisateur dans un noyau, ce qui signifie que l'espace utilisateur doit être isolé. On s'attend donc à isoler l'espace utilisateur en plusieurs groupes sans interférer les uns avec les autres, et un espace utilisateur peut exécuter une partie ou une partie du processus. (Notez qu'il y a généralement un espace de nom avec des privilèges, généralement le premier espace utilisateur, la classe est Xen et KVM) Ensuite, le processus démarre et s'exécute dans l'espace utilisateur, et de nombreux espaces utilisateur peuvent partager le même noyau au niveau de la couche inférieure, et être la même gestion du noyau. Mais la limite que le processus peut voir lorsqu'il est en cours d'exécution est la limite de l'espace utilisateur auquel il appartient. De cette façon, ils sont isolés les uns des autres. (Cette isolation n'est pas aussi complète que l'isolation de virtualisation d'hôte) À ce stade, cet espace utilisateur fournit un environnement en cours d'exécution pour le processus et peut éviter que le processus interne ne soit interféré par d'autres processus. C'est la technologie des conteneurs des ordinateurs.
Comment le conteneur est implémenté

L'objectif principal d'un espace utilisateur est d'isoler l'environnement. Tout processus s'exécutant dans l'espace utilisateur, le processus pense qu'il s'agit du seul processus s'exécutant dans l'espace utilisateur au-dessus du noyau actuel, et tous les processus qu'il peut voir sont les processus actuels. Tous les processus de l'hôte ont disparu. Un espace de noms doit avoir ces composants: UTS (nom d'hôte et nom de domaine), Mount (système de fichiers racine), IPC (canal de communication dédié entre les processus dans le même espace de noms), PID (nombre de processus), User (utilisateur), Net ( carte réseau, interface réseau, ensemble complet de connecteurs). Ces ressources sont toutes exposées par le noyau via le mécanisme d'espace de noms et encapsulées sous forme d'appels système. Il existe également un mécanisme chroot très important, à savoir changer le répertoire racine (changer le répertoire racine). Dans un système Linux, la structure de répertoire par défaut du système commence par /, qui commence par root. Après avoir utilisé chroot, la structure de répertoires du système utilisera l'emplacement spécifié comme emplacement /.Dans les ordinateurs modernes, les conteneurs sont implémentés via les six espaces de noms et chroot fournis par le noyau.
Le noyau n'a pas fourni le mécanisme d'isolation des ressources ci-dessus au début de la conception. Voici la correspondance entre chaque isolation d'espace de noms dans le noyau.
L'isolation des ressources correspond au numéro de version du noyau
| espace de noms | Paramètres d'appel système | Contenu de la quarantaine | Version du noyau |
|---|---|---|---|
| UTS | CLONE_NEWUTS | Nom d'hôte et de domaine | 2.6.19 |
| IPC | CLONE_NEWIPC | Sémaphore, file d'attente de messages et mémoire partagée | 2.6.19 |
| PID | CLONE_NEWPID | Numéro de processus | 2.6.24 |
| Réseau | CLONE_NEWNET | Équipement réseau, piles réseau, ports, etc. | 2.6.29 |
| Monter | CLONE_NEWNS | Point de montage (système de fichiers) | 2.4.19 |
| Utilisateur | CLONE_NEWUSER | Utilisateurs et groupes d'utilisateurs | 3,8 |
Groupes C
Qu'est-ce que Cgroups
cgroups , dont le nom est dérivé de l'abréviation des groupes de contrôle (anglais: groupes de contrôle), est une fonction du noyau Linux utilisé pour limiter, contrôler et séparer les ressources d'un groupe de processus (telles que CPU, mémoire, entrée de disque et sortie, etc.).
Ce projet a été lancé pour la première fois par les ingénieurs de Google (principalement Paul Menage et Rohit Seth) en 2006, et le premier nom était les conteneurs de processus. En 2007, parce que le terme conteneur a de nombreuses significations différentes dans le noyau Linux, pour éviter toute confusion, il a été renommé en groupes de contrôle et fusionné dans le noyau 2.6.24. Depuis, de nombreuses fonctionnalités ont été ajoutées.
Quel problème résolvent Cgroups
Au cas où il y aurait une situation inattendue dans un processus à l'intérieur du conteneur, il accaparerait follement les ressources système, telles que le processeur, la mémoire, etc., comme un cheval sauvage en cours d'exécution. Le processeur est en fait bon car il s'agit d'une ressource compressible. Une fois la mémoire épuisée, le système rencontrera des exceptions telles que le MOO (programme outburst) et les processus dans d'autres conteneurs échoueront également en raison du manque de mémoire. Étant donné que les conteneurs partagent le même noyau, une fois que les ressources sont pillées de manière extravagante, les autres processus en cours d'exécution seront affectés. Comment cela peut-il fonctionner? Ainsi, Cgroup est utilisé pour résoudre le problème de la limitation des ressources du conteneur. Utilisez Cgroups dans le noyau pour limiter les ressources pour chaque espace de noms.
Comment fonctionnent les groupes C
Cgroups n'est rien de plus qu'un processus qui divise les ressources au niveau du système en plusieurs groupes de ressources (sous-systèmes), puis affecte ou alloue la quantité de ressources de chaque groupe à un espace utilisateur spécifique.
Les groupes de contrôle peuvent diviser les ressources en plusieurs groupes de ressources (sous-systèmes) comme suit:
- blkio: bloquer les E / S du périphérique
- cpu: CPU
- cpuacct: rapport d'utilisation des ressources CPU
- cpuset: CPU sur une plate-forme multiprocesseur
- appareils: accès aux appareils
- congélateur: suspendre ou reprendre des tâches
- mémoire: utilisation de la mémoire et rapports
- perf_event: Effectuer un test de performance unifié sur la course dans le groupe de contrôle
- net_cls: l'identificateur de catégorie du message de données créé par la tâche dans le groupe de contrôle
Hiérarchie des groupes de contrôle (hiérarchie)
Le noyau utilise la structure de groupe de contrôle pour représenter la limite de ressources d'un groupe de contrôle à un ou plusieurs groupes de ressources de groupe de contrôle. La structure du groupe de contrôle peut être organisée en un arbre, et l'arbre composé de chaque groupe de contrôle est appelé une structure hiérarchique de groupe de contrôle. La structure hiérarchique des groupes de contrôle peut attacher un ou plusieurs groupes de ressources de groupes de contrôle, et la structure hiérarchique peut utiliser le groupe de ressources des groupes de contrôle attaché pour la restriction des ressources.

La figure ci-dessus montre une structure hiérarchique de groupes de contrôle, une structure arborescente dans une structure hiérarchique, chaque nœud de l'arbre est une structure de groupe de contrôle (comme cpuRoot, cpu2, CM3). Cette structure hiérarchique de cgroups attache le groupe de ressources cpu et le groupe de ressources cpuacct, de sorte que le groupe de ressources actuel peut limiter les ressources cpu et effectuer des statistiques sur l'utilisation cpu du processus. Dans chaque hiérarchie de groupes de contrôle , chaque nœud (structure de groupe de contrôle) peut définir différents poids de restriction pour les ressources, et les nœuds enfants suivront le poids du nœud parent par défaut . Comme le montre la figure ci-dessus, les processus du groupe cpu2 peuvent utiliser 60% de la tranche de temps du processeur et les processus du groupe CM3 peuvent utiliser 40% de la tranche de temps du processeur.

Après avoir créé le nœud (structure de groupe de contrôle) dans la hiérarchie des groupes de contrôle, le processus peut être ajouté à la liste des tâches de contrôle d'un nœud. Tous les processus de la liste de contrôle d'un nœud seront limités par les ressources du nœud actuel. Un certain processus d'un collègue peut également être ajouté aux nœuds de différents niveaux de groupes de contrôle, car différentes structures hiérarchiques de groupes de contrôle peuvent être responsables de différentes ressources système. Le processus et le nœud (structure de groupe de contrôle) ont une relation plusieurs-à-plusieurs, mais les nœuds (structure de groupe de contrôle) ne peuvent pas être dans la même hiérarchie de groupes de contrôle.
LXC
Qu'est-ce que LXC

LXC , dont le nom vient de l'abréviation de Linux Containers, une technologie de virtualisation au niveau du système d'exploitation, est une interface d'espace utilisateur pour les fonctions de conteneur du noyau Linux. Il conditionne le système logiciel d'application dans un conteneur logiciel (Container), qui contient le code du logiciel d'application lui-même, ainsi que les cœurs et bibliothèques du système d'exploitation requis. Allouez les ressources matérielles disponibles de différents conteneurs logiciels via un espace de noms unifié et une API partagée, créant un environnement d'exécution sandbox indépendant pour les applications, ce qui permet aux utilisateurs Linux de créer et de gérer facilement des systèmes ou des conteneurs d'applications.
Dans le noyau Linux, la fonction cgroups est fournie pour réaliser la séparation des ressources. Il fournit également la fonction de séparation des espaces de noms, de sorte que l'environnement du système d'exploitation vu par l'application est divisé en sections indépendantes, y compris l'arborescence d'itinéraire, le réseau, l'ID utilisateur et le système de fichiers monté. Mais les groupes de contrôle n'ont pas nécessairement besoin de démarrer une machine virtuelle.
LXC utilise les fonctions des groupes de contrôle et des espaces de noms pour fournir un environnement de système d'exploitation indépendant pour les logiciels d'application. LXC ne nécessite pas la couche logicielle d'Hypervisor, et le conteneur logiciel (Container) lui-même est extrêmement léger, ce qui améliore la vitesse de création de machines virtuelles. Le logiciel Docker permet de gérer l'environnement LXC.
Quel problème LXC résout
Grâce à l'introduction ci-dessus, nous savons que la combinaison de conteneurs (6 espaces de noms) et de groupes de contrôle peut réaliser un environnement de conteneur complet et isolé. Mais l'espace de noms de contrôle et les groupes de contrôle sont tous deux des appels système. Combien de personnes peuvent le maîtriser? Alors LXC est apparu, LXC est de permettre aux utilisateurs de créer et de gérer facilement des systèmes ou des conteneurs d'applications .
Comment fonctionne LXC
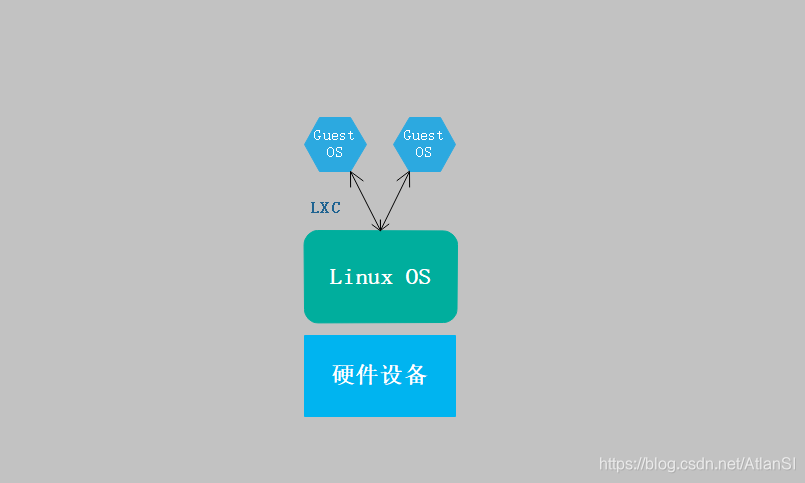
Les conteneurs LXC sont généralement considérés comme se situant entre le chroot et la virtualisation traditionnelle. Le but de LXC est de créer un environnement d'installation Linux aussi proche que possible du standard, mais ne nécessitant pas de noyau séparé. En d'autres termes, LXC fournit une VM comme la virtualisation traditionnelle, mais partage le même noyau avec le système d'embarquement (pas la même chose que docker)
Le mode de fonctionnement de LXC est le suivant: utilisez lxc-create pour créer un conteneur (espace de nom), puis exécutez le processus d'installation via un modèle (premier script shell, script yaml actuel). Ce modèle implémentera automatiquement le processus d'installation. Cette installation fait référence à l'entrepôt de la version système du conteneur (espace de noms) que vous souhaitez créer. Utilisez le package de l'entrepôt pour télécharger vers le local afin de terminer le processus d'installation. Donc, ce conteneur (espace de nom) est utilisé comme une machine virtuelle.
Exemple de modèle
lxc-centos Modèle lxc-centos: https://github.com/AtlanCI/LXC-Centos_template/blob/main/lxc-centos
Dcoker
Qu'est-ce que Docker

Docker est un logiciel open source et une plate-forme ouverte pour développer des applications, expédier des applications et exécuter des applications. Docker permet aux utilisateurs de séparer les applications de l'infrastructure (infrastructure) en particules plus petites (conteneurs), augmentant ainsi la vitesse de livraison des logiciels.
Les conteneurs Docker sont similaires aux machines virtuelles, mais ils sont différents en principe. Les conteneurs virtualisent la couche du système d'exploitation et les machines virtuelles sont du matériel virtualisé. Par conséquent, les conteneurs sont plus portables et utilisent les serveurs de manière efficace. Le conteneur est davantage utilisé pour représenter une unité standardisée de logiciel. En raison de la standardisation du conteneur, il peut être déployé à n'importe quel endroit, quelle que soit la différence d'infrastructure. En outre, Docker offre également une meilleure compatibilité d'isolation de l'industrie pour les conteneurs.
Quel problème Docker résout
Grâce à la description ci-dessus, nous savons que LXC est utilisé pour gérer les conteneurs, mais l'utilisation de LXC pour gérer les conteneurs rencontrera les problèmes suivants:
- Si vous souhaitez utiliser LXC pour gérer les conteneurs, vous devez apprendre les bons outils LXC. Liste des commandes LXC
- Personnalisez le modèle si nécessaire
- Chaque espace de nom est généré par l'installation. Les processus exécutés dans cet espace de nom génèrent certains fichiers (bases de données, etc.). En cas de défaillance de l'hôte, comment migrer vers d'autres hôtes
- Difficile à créer en batch

Pour résumer, la complexité de l'utilisation des conteneurs de gestion LXC n'est pas beaucoup plus faible que celle des machines virtuelles virtualisées traditionnelles, sans oublier que l'isolation n'est pas aussi bonne que les machines virtuelles. Bien entendu, l'avantage est que chaque conteneur peut utiliser directement les performances de l'hôte sans surcharge supplémentaire (économie de ressources). LXC n'a pas une bonne méthode de distribution et d'utilisation à grande échelle . C'est donc plus tard que Docker est apparu. Le premier Docker peut être considéré comme une version améliorée de LXC (résolvant principalement la distribution et l'utilisation à grande échelle).
Docker lui-même n'est pas un conteneur, Docker est juste un outil facile à utiliser pour les conteneurs. Les conteneurs sont la technologie du noyau Linux, et Docker simplifie simplement l'utilisation de cette technologie .
À l'heure actuelle, LXC a encore été mis à jour vers LXD (bien sûr, la méthode d'utilisation est toujours similaire à celle des machines virtuelles, la distribution et l'utilisation à grande échelle seront bien meilleures), si vous voulez savoir, veuillez vous référer à: https: //linuxcontainers.org/lxd/introduction/
Comment fonctionne Docker
Il y a beaucoup d'articles sur Docker sur Internet, voici seulement une brève introduction sur la façon de résoudre la distribution et la technologie à grande échelle.

Comme mentionné ci-dessus, LXC est confronté à une utilisation à grande échelle et il est difficile de répliquer des conteneurs (distribution) sur d'autres hôtes, alors Docker a entrepris de résoudre ce problème. Ainsi, le premier Docker était l'emballage secondaire de LXC. Fonctionnellement, LXC est utilisé comme moteur de gestion de conteneurs, mais lors de la création d'un conteneur, il n'est pas installé et généré sur site avec un modèle, mais via une technologie appelée mise en miroir à l'avance. Organisez tous les composants utilisés dans l'espace utilisateur d'un système d'exploitation et regroupez-les dans un seul fichier après la disposition. Ce fichier s'appelleImage. Lorsque vous utilisez Docker pour créer un conteneur, Docker n'active pas la création et l'installation du modèle LXC. Au lieu de cela, il se connecte au référentiel miroir et télécharge une image nécessaire pour créer le conteneur. Docker simplifie grandement l'utilisation des conteneurs. Par exemple, si vous souhaitez exécuter un nginx, vous pouvez directement docker exécuter nginx.
Chaque conteneur lui-même peut exécuter un ou plusieurs processus. Afin de faciliter la gestion de l'utilisation du conteneur, Docker utilise un processus à exécuter dans un conteneur Docker. Cela apportera des avantages et des inconvénients.
avantage:
1. Chaque conteneur n'exécute qu'un seul processus et plusieurs processus communiquent entre les conteneurs (plus d'isolement, plus de distribution de conteneurs)
préjudice:
1. L'espace de stockage requis a augmenté
2. Il est plus difficile de déboguer le processus dans le conteneur
Un bon programme développé par un développeur n'a besoin que d'être emballé dans une image Docker, puis il peut être exécuté partout sur une machine appartenant à Docker. Certains processus spéciaux sont similaires aux bases de données et doivent utiliser le stockage partagé pour mieux résoudre le problème de distribution. En conditionnant l'application en tant que mécanisme de mise en miroir, le problème de distribution peut être bien résolu. Il est également très simple dans les scénarios d'utilisation à grande échelle: un seul fichier miroir est nécessaire sur chaque machine pour démarrer N exemples. (Reportez-vous à l'image Docker, fonction de montage de joint de déploiement hiérarchique)
Avec le mécanisme de mise en miroir de Docker, la distribution et l'utilisation à grande échelle peuvent être très bien résolues. Bien sûr, si vous souhaitez bien utiliser les conteneurs, vous avez toujours besoin d'outils d'orchestration de conteneurs.
référence
Cgroups : https: //tech.meituan.com/2015/03/31/cgroups.html
introduction LXC : https: //linuxcontainers.org/lxc/introduction/
introduction LXD : https: //linuxcontainers.org/lxd/introduction /