teneur
4. Comparaison avec les bases de données relationnelles traditionnelles
5. Comparaison avec d'autres composants Big Data
Quatre phrases couramment utilisées
1. Construire une table commune
2. Créer une table de partition
7. Ajouter une seule partition
8. Supprimer une seule partition
9. Ajouter plusieurs partitions
10. Supprimer plusieurs partitions
13. Modifier le nom de la colonne
14. Partitionnement en plusieurs colonnes
2. Ajouter une nouvelle partition
Une série d'articles sur la prise en main du Big Data
Voici une brève introduction à certains noms communs de Kudu, une structure simple et quelques déclarations couramment utilisées. En ce qui concerne l'introduction plus détaillée de suivi, ce composant sera présenté en détail séparément, et vous pouvez suivre le blog pour une lecture de suivi.
1. Conception

Kudu est un nouveau type de système de stockage en colonnes open source de Cloudera. Il fait partie de l'écosystème Apache Hadoop. Il est conçu pour analyser rapidement les données qui changent rapidement et combler le vide de la couche de stockage Hadoop précédente.
Kudu fournit des fonctions et des modèles de données plus proches du RDBMS, fournissant une structure de stockage similaire aux bases de données relationnelles pour stocker les données, permettant aux utilisateurs d'insérer, de mettre à jour et de supprimer des données de la même manière que les bases de données relationnelles.
Kudu n'est qu'une couche de stockage, il ne stocke pas de données, mais s'appuie sur des moteurs de traitement Hadoop externes (MapReduce, Spark, Impala). Kudu stocke les données dans le système de fichiers Linux sous-jacent dans son propre format de stockage en colonnes.
Le cœur de Kudu est un moteur de stockage basé sur des tables. Kudu stocke ses propres informations de métadonnées (sur la table) et les données utilisateur, stockées dans la tablette.
Kudu a Upsert pour mettre à jour les données, similaire à Merge d'Oracle.
2.Architecture

Semblable à HDFS et HBase, Kudu utilise un seul nœud maître, qui gère les métadonnées du cluster, et n'importe quel nombre de nœuds Tablet Server (comparez le rôle RegionServer dans HBase) pour stocker les données réelles. Plusieurs nœuds maîtres peuvent être déployés pour améliorer la tolérance aux pannes. Les données d'une table Table sont divisées en une ou plusieurs tablettes, qui sont déployées sur Tablet Server pour fournir des services de lecture et d'écriture de données.
1.Serveur maître
Le leader du cluster Kudu peut avoir plusieurs serveurs maîtres pour améliorer la tolérance aux pannes du cluster, mais un seul serveur maître fournit des services externes et est responsable de la gestion du cluster et de la gestion des métadonnées.
2.Serveur de tablette
Il peut y avoir n'importe quel nombre de jeunes frères dans le cluster Kudu, responsables du stockage des données et de la lecture et de l'écriture des données. Les tablettes sont stockées sur le serveur de tablette. Pour une tablette, un seul des serveurs de table sert de leader pour fournir des services de lecture et d'écriture, tandis que les autres serveurs de table sont tous des suiveurs et ne fournissent que des services de lecture.
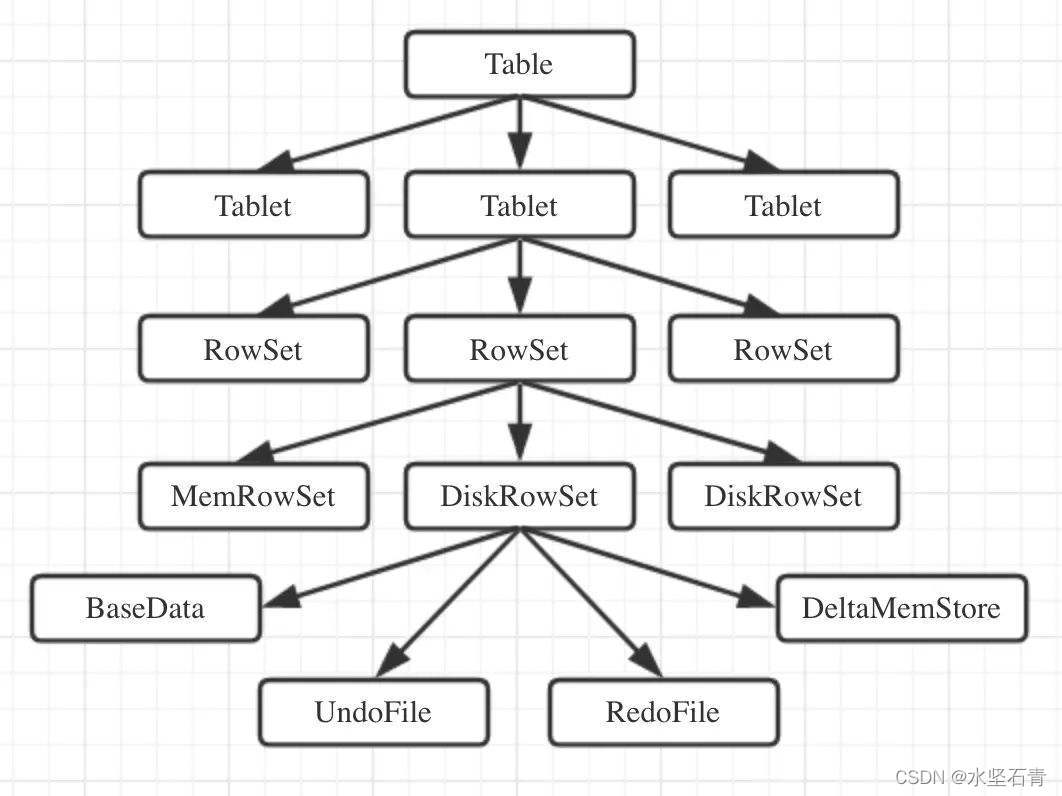
3.Tableau
Table : le concept de table dans Kudu comprend les concepts de schéma et de clé primaire. La table dans Kudu sera divisée horizontalement en plusieurs fragments de tablette et stockée sur le serveur de tablette.
4. Tablette
Une tablette est un segment continu d'une table, une tablette est une partition horizontale d'une table, les plages de clés primaires entre les tablettes ne se chevauchent pas et tous les segments de tablette d'une table constituent toutes les plages de clés primaires de la table. La tablette sera stockée de manière redondante sur plusieurs serveurs de tablette pour configurer des répliques. À tout moment, un seul serveur de tablette est le leader et les autres sont des suiveurs.
3. Caractéristiques
1.Importance
1. La complexité de l'analyse des mégadonnées est souvent due aux limites du système de stockage. Les limites de Kudu sont beaucoup plus petites, ce qui simplifie dans une certaine mesure l'analyse des mégadonnées.
2. De nouveaux scénarios d'application nécessitent Kudu, comme de plus en plus d'applications axées sur les données générées par la machine et l'analyse en temps réel.
3. Adaptez-vous au nouvel environnement matériel, apportant ainsi des performances et une flexibilité d'application supérieures.
2. Facilité d'utilisation
1. Fournir des fonctions et des modèles de données plus proches du SGBDR ;
2. Fournir une structure de stockage de table de base de données de type SGBDR ;
3. Permettre aux utilisateurs d'insérer, de mettre à jour et de supprimer des données de la même manière que le SGBDR.
3. Avantages
Kudu a également la capacité d'insérer ligne par ligne, un accès aléatoire à faible latence, une mise à jour et une analyse d'analyse rapide, ce qui le rend bien pris en charge à la fois dans OLAP et OLTP.Ces architectures complexes qui nécessitaient à l'origine plusieurs systèmes de stockage pour prendre en charge en même temps temps ont été remplacés Il n'y a qu'un seul système de stockage, et toutes les données sont stockées dans ce système de stockage, ce qui simplifie grandement l'architecture du Big Data.
4. Comparaison avec les bases de données relationnelles traditionnelles
1. Comme les bases de données relationnelles, les tables Kudu ont une clé primaire unique.
2. Les fonctionnalités courantes des bases de données relationnelles, telles que les transactions, les clés étrangères et les index de clés non primaires, ne sont actuellement pas prises en charge dans Kudu.
3. Kudu possède certaines fonctionnalités OLAP et OLTP, mais ne prend pas en charge l'atomicité inter-lignes, la cohérence, l'isolation et les transactions persistantes.
4. Kudu peut être classé comme une base de données de type Hybrid Transaction/Analytic Processing (HTAP).
5.Kudu prend en charge la récupération rapide de la clé primaire et peut analyser les données pendant que les données sont saisies en continu, et les performances de la base de données OLAP ne sont généralement pas très bonnes dans ce scénario.
6. La garantie de persistance de Kudu est plus proche de celle d'une base de données OLTP.
7. La fonctionnalité Quorum de Kudu peut implémenter un mécanisme appelé miroirs fracturés, c'est-à-dire qu'un ou deux nœuds utilisent le stockage en ligne et les autres nœuds utilisent le stockage en colonne. De cette façon, les requêtes de type OLTP peuvent être exécutées sur les nœuds du magasin de lignes, et les requêtes OLAP peuvent être exécutées sur les nœuds du magasin de colonnes, mélangeant les deux charges de travail.
5. Comparaison avec d'autres composants Big Data
1. HDFS est bon pour la numérisation à grande échelle, mais pas bon pour la lecture aléatoire. À proprement parler, il ne prend pas en charge l'écriture aléatoire. Il peut simuler l'écriture aléatoire par fusion, mais le coût est très élevé.
2. HBase et Cassandra sont bons pour l'accès aléatoire, lisant et modifiant les données de manière aléatoire, mais les performances sont médiocres pour l'analyse à grande échelle.
3. L'objectif de Kudu est de doubler les performances d'analyse de HDFS, tandis que les performances de lecture aléatoire sont connectées à HBase et Cassandra.L'objectif réel est d'obtenir une latence de lecture/écriture aléatoire sur SSD en 1 ms.
Quatre phrases couramment utilisées
1. Construire un tableau
Kudu nécessite une clé primaire pour créer une table, et la clé primaire ne peut pas être vide.
1. Construire une table commune
create table test.test1 (
date_timekey string not null,
username string null,
product_qty string null
)
stored as kudu2. Créer une table de partition
create table test.test1 (
date_timekey string not null,
username string null,
product_qty string null,
primary key (date_timekey)
)
partition by range (date_timekey) (value='20220417')
stored as kudu
2. Supprimer le tableau
drop table if exists test.test1;
3. Interroger les données
Remarque : Lors de l'interrogation des données, il est préférable d'amener les colonnes à interroger, ce qui peut réduire le nombre de colonnes de requête et réduire le chargement de la requête. Lors de l'écriture de SQL, l'utilisation des colonnes spécifiées met moins de pression sur le cluster Big Data et rend le système plus robuste.
select date_timekey,username from test.test1
4. Ajouter des données
Remarque : Avant d'insérer des données dans une table partitionnée, vous devez d'abord créer une partition.
insert into test.test1 (date_timekey,username)values('20200330','shuijianshiqing');
Remarque : La clé primaire des données ajoutées ne peut pas être vide, sinon les données ne seront pas saisies.
insert into test.test1 (date_timekey,b)values(null,'shuijianshiqing');
5. Mettre à jour les données
upsert into test.test1 (date_timekey,username)values('20200330','shuijianshiqing');
6. Supprimer les données
Remarque : lors de la suppression de données, vous ne pouvez pas utiliser la suppression d'alias, comme test.test t, puis la condition est t.date_timekey, de sorte que les données ne peuvent pas être supprimées.
delete from test.test1 where date_timekey='20200328';
7. Ajouter une seule partition
alter table test.test1 add range partition value='20200325';
8. Supprimer une seule partition
alter table test.test1 drop range partition value='20200325';
9. Ajouter plusieurs partitions
alter table test.test1 add range partition '20200327'<=values<'20200331';
10. Supprimer plusieurs partitions
alter table test.test1 drop range partition '20200327'<=values<'20200331';11. Nouvelle colonne
alter table test.test1 add columns(column_new string);
12. Supprimer des colonnes
alter table test.test1 drop column column_new;
13. Modifier le nom de la colonne
username est l'ancien nom de la colonne, username_new est le nom de la nouvelle colonne,
alter table test.test1 change column username username_new string;
14. Partitionnement en plusieurs colonnes
1. Créer un nouveau tableau
drop table if exists test.test2;
create table test.test2 (
id String not null,
date_timekey String not null,
hour_timekey String not null,
username STRING,
password STRING,
interface_time String,
primary key (id,date_timekey,hour_timekey)
)
partition by range (date_timekey,hour_timekey) (partition value=('20200601','20200601 0730'))
stored as kudu
2. Ajouter une nouvelle partition
alter table test.test2_kudu add range partition value=('20200601','20200601 0830');
3. Supprimer la partition
alter table test.test2_kudu drop range partition value=('20200601','20200601 0830');Cinq, le vernaculaire
Kudu est un moteur de stockage, similaire à RDBMS, qui peut ajouter, supprimer, modifier et interroger, ce qui rend l'analyse de données volumineuses plus pratique. Son stockage n'est pas basé sur Hadoop, mais il dispose d'un système indépendant sous Linux. Quant au contenu plus détaillé de la lecture et de l'écriture de Kudu, il sera présenté en détail plus tard.
6. Autres
Soupe au Poulet : Le monde a le plus peur du mot sérieux, ces deux mots valent des milliers de dollars, et des milliers de dollars ne s'échangent pas !
Une série d'articles sur la prise en main du Big Data
1. Introduction au Big Data - Qu'est-ce que le Big Data ?
2. Introduction au Big Data - Présentation de la technologie Big Data (1)
3. Introduction au Big Data - Présentation de la technologie Big Data (2)
4. Introduction au big data - comprendre Hadoop en trois minutes
5. Introduction au big data - cinq minutes pour comprendre HDFS
6. Introduction au big data - cinq minutes pour comprendre Hive
Ne manquez pas les beaux mecs et les beautés qui passent, faites attention et aimez le pinacle de la vie ! ! !