Auteur : équipe du serveur Internet vivo - Zhou Changqing
1. Introduction au principe de FastDFS
FastDFS est un système de fichiers distribué léger open source implémenté en langage C.
Prend en charge Linux, FreeBSD, AID et d'autres systèmes Unix, résout le problème du stockage de fichiers de grande capacité et de l'accès simultané élevé, et réalise l'équilibrage de charge pour l'accès aux fichiers, adapté au stockage de petits fichiers entre 4 Ko et 500 Mo, particulièrement adapté aux fichiers en ligne avec des fichiers en tant que transporteur Services, tels que des images, des vidéos, des documents, etc.
2. Architecture FastDFS
FastDFS se compose de trois parties :
-
Client (Client)
-
TrackerServer
-
Serveur de stockage (StorageServer)
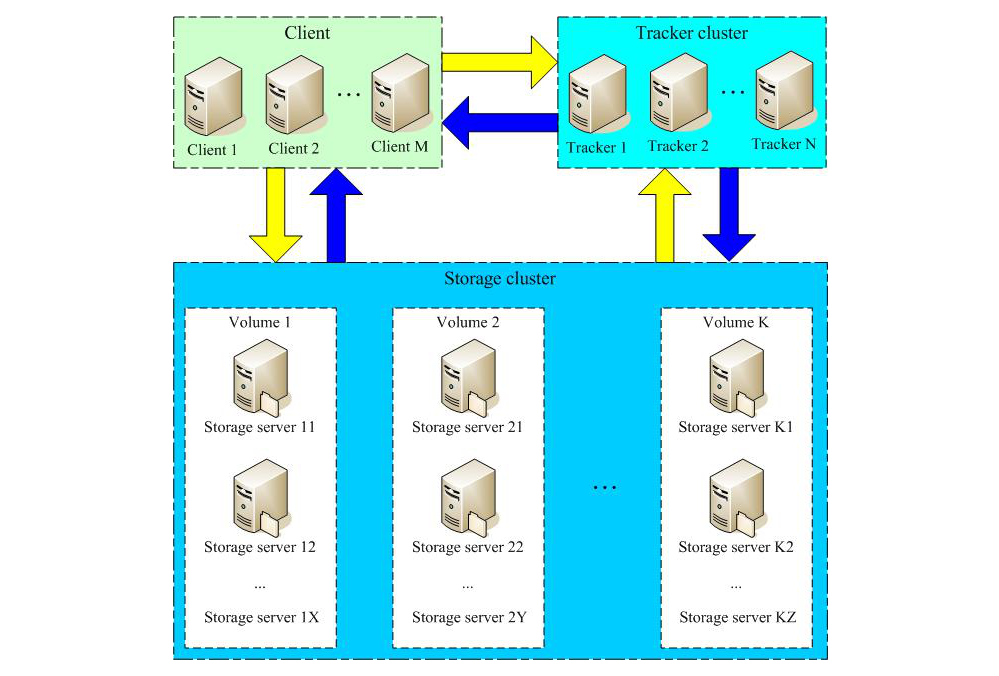
2.1 Serveur de suivi
Tracker Server (serveur de suivi) effectue principalement un travail de planification et joue un rôle dans l'équilibrage de charge.
**(1) [Enregistrement du service]** Gérez le cluster de stockage StorageServer. Lorsque le StorageServer démarre, il s'enregistre auprès de TrackerServer et signale régulièrement ses propres informations d'état, y compris des statistiques telles que l'espace disque restant, l'état de la synchronisation des fichiers, et temps de chargement et de téléchargement des fichiers.
**(2) [Découverte de service]** Avant que le client accède au StorageServer, il doit d'abord accéder au TrackerServer pour obtenir dynamiquement les informations de connexion du StorageServer, et les données finales sont transmises à un StorageServer disponible.
(3) [Équilibre de la charge]
- stratégie d'allocation des groupes de magasins :
0 : mode d'interrogation
1 : Spécifiez le groupe
2 : Load balance (sélectionnez le groupe (volume) avec le plus grand espace restant à télécharger)
- stratégie d'allocation de serveur de magasin :
0 : mode d'interrogation
1 : Trier par adresse IP et sélectionner le premier serveur (celui avec la plus petite adresse IP)
2 : Trier par priorité (la priorité de téléchargement est définie par le serveur de stockage et le nom du paramètre est upload_priority)
- affectation de chemin stroe :
0 : À tour de rôle, plusieurs répertoires stockent les fichiers en séquence
2 : Sélectionnez le répertoire avec le plus grand espace restant pour stocker le fichier (remarque : l'espace disque restant est dynamique, de sorte que le répertoire ou le disque qui y est stocké peut également changer)
2.2 Serveur de suivi
Tracker Server (serveur de suivi) fournit principalement des services de capacité et de sauvegarde.
**[Gestion de groupe]** Prenez le groupe comme unité, chaque groupe contient plusieurs serveurs de stockage et les données sont sauvegardées les unes avec les autres. La capacité de stockage est basée sur le stockage avec le plus petit contenu du groupe. Le stockage de le groupe est organisé comme une unité pour faciliter l'isolation et le chargement des applications Équilibrer et répliquer la personnalisation des données.
**Inconvénients : **La capacité du groupe est limitée par la capacité de stockage d'une seule machine, et la récupération des données ne peut s'appuyer que sur les autres machines du groupe pour se resynchroniser.
**[Synchronisation des données]** La synchronisation des fichiers ne peut être effectuée qu'entre les serveurs de stockage d'un groupe et la méthode push est utilisée, c'est-à-dire que le serveur source est synchronisé avec le serveur cible. Le serveur source lit le fichier binlog, analyse le contenu du fichier et l'envoie au serveur cible conformément à la commande d'opération, et le service cible fonctionne conformément à la commande.
3. Processus de chargement et de téléchargement
3.1 Analyse du processus de téléchargement
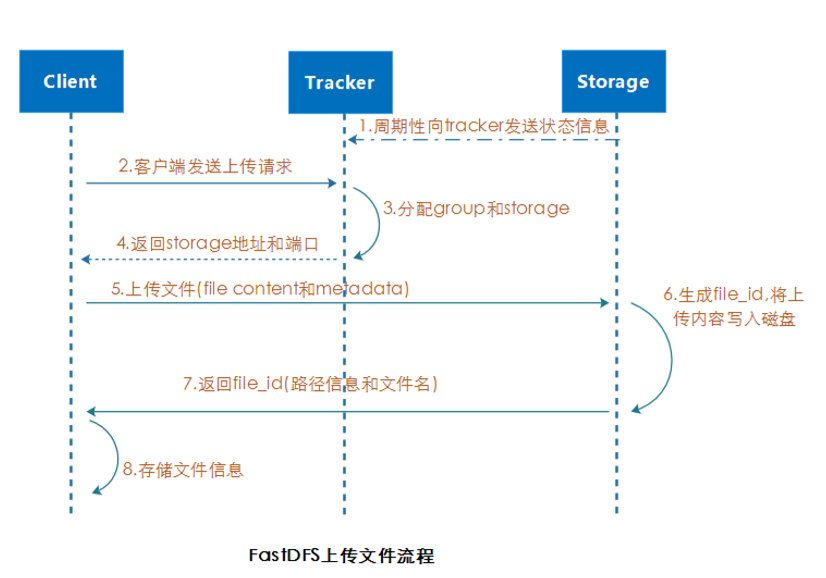
3.1.1 Sélectionner le serveur de suivi
Les trackers du cluster sont tous égaux et le client peut choisir n'importe quel tracker lors du téléchargement de fichiers.
3.1.2 Attribuer un groupe, un serveur de stockage et un chemin de stockage (disque ou point de montage)
Lorsque le tracker reçoit une demande de téléchargement, il attribue d'abord un groupe qui peut être stocké au fichier, puis attribue un serveur de stockage au client dans le groupe. Enfin, lors de la réception d'une demande d'écriture de fichier du client, le serveur de stockage attribuera un répertoire de stockage de données et écrira.
(Pour la stratégie d'allocation dans ce processus, veuillez vous référer à : [Load Balance])
3.1.3 Générer file_id pour écrire et retourner
Le stockage générera un file_id comme nom de fichier actuel. Le file_id est encodé en base64, y compris : l'adresse IP du serveur de stockage source, l'heure de création du fichier, la taille du fichier, la somme de contrôle CRC32 du fichier et le nombre aléatoire. Il existe deux sous-répertoires 256*256 sous chaque répertoire de stockage.
Le stockage hachera la route vers l'un des sous-répertoires deux fois en fonction de file_id.
Enfin, utilisez file_id comme nom de fichier pour stocker le fichier dans le sous-répertoire et renvoyer le chemin du fichier au client.
Chemin de stockage du fichier final :
**groupe|disque|sous-répertoire|nom de fichier**
group1/M00/00/89/eQ6h3FKJf_PRl8p4AUz4wO8tqaA688.apk
-
【Groupe】 : Attribuez un groupe lors du téléchargement du fichier.
-
[Disk path] : chemin virtuel configuré par le serveur de stockage, correspondant au paramètre de configuration store_path. Par exemple, M00 correspond à store_path0 et M01 correspond à store_path1.
-
[Répertoire à deux niveaux] : Le répertoire à deux niveaux créé par le serveur de stockage sous chaque chemin de disque virtuel est utilisé pour stocker les fichiers.
3.2 Télécharger l'analyse du processus
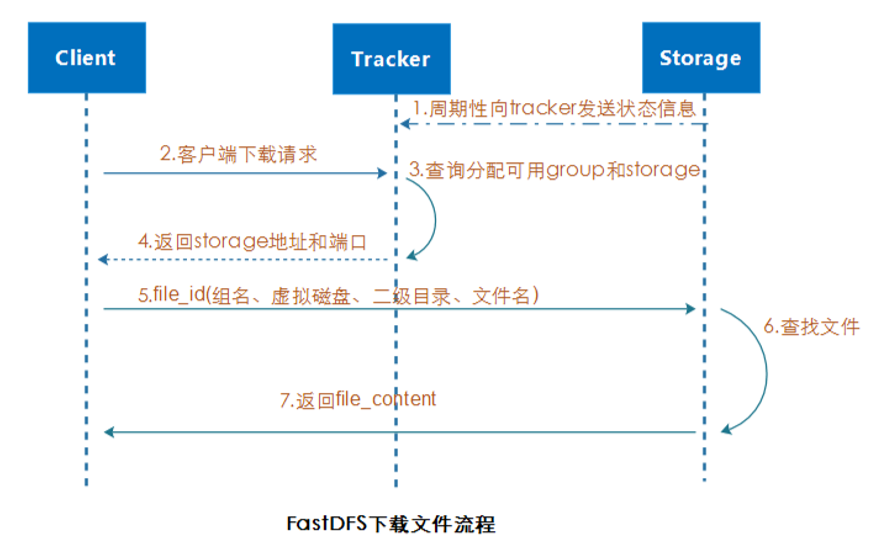
3.2.1 Analyser le chemin et la route
Lorsque le tracker reçoit la demande de téléchargement envoyée par le client, le tracker analyse le groupe, la taille, l'heure de création et d'autres informations à partir du nom de fichier, puis sélectionne un serveur de stockage en fonction du groupe à renvoyer.
3.2.2 Vérifier la lecture et le retour
Le client établit un lien avec le serveur de stockage, vérifie si le fichier existe et renvoie enfin les données du fichier.
**Inconvénients : **La synchronisation des fichiers entre les groupes est effectuée de manière asynchrone et les fichiers téléchargés peuvent ne pas être synchronisés avec la machine du serveur de stockage actuellement consultée ou en raison de retards, ce qui entraînera l'apparition de 404 dans les fichiers téléchargés. Ainsi, l'introduction de nginx_fastdfs_module peut très bien résoudre les problèmes de synchronisation et de retard.
3.3 Télécharger l'architecture après avoir introduit le composant fastdfs_nginx_module
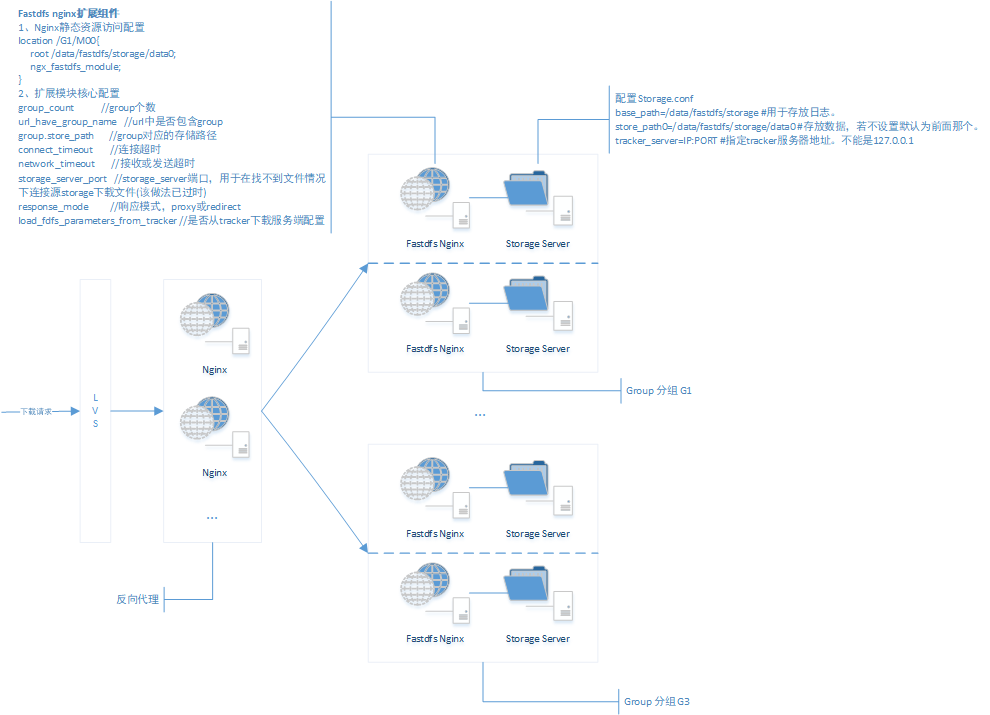
Présentation de la fonction du module FastDFS Nginx
(1) [Inspection de la chaîne antivol]
Utilisez l'extension FastDFS nginx pour générer dynamiquement des jetons et définir la configuration http.conf.
- Activer la fonction anti-sangsue
http.default_content_type =
application/flux d'octets
http.mime_types_filename=mime.types
- Activer la fonction anti-sangsue du jeton
http.anti_steal.check_token=true
délai d'expiration du jeton
http.anti_steal.token_ttl=900
- clé
http.anti_steal.secret_key=xxx
Le contenu renvoyé après l'expiration du jeton
http.anti_steal.token_check_fail=/etc/fdfs/anti-steal.jpg
[Algorithme de génération de jetons] : md5(fileid_without_group + privKey + ts) et ts ne dépasse pas la plage de ttl.
Le serveur vérifiera automatiquement la validité en fonction du jeton, st et de la clé secrète définie. Liens d'accès sous forme de :
(2) [Analyse des métadonnées du fichier]
Obtenez des informations de métadonnées basées sur file_id, y compris : l'adresse IP de stockage source, le chemin du fichier, le nom, la taille , etc.
(3) [Routage d'accès aux fichiers]
Étant donné que le file_Id du fichier contient l'adresse IP du serveur de stockage source lors du téléchargement du fichier, le composant d'extension FastDFS sera redirigé ou obtenu par proxy en fonction de l'adresse IP du serveur source lorsque le fichier sous la machine locale ne peut pas être obtenu (en cas d'absence synchronisation ou retard).
- mode de redirection
Élément de configuration response_mode = redirect, le serveur renvoie 302, URL de redirection
http://sourcestorageip :port/filepath?redirect=1
- mode proxy
L'élément de configuration response_mode = proxy, utilisez l'adresse de stockage source comme hôte du proxy proxy et les autres parties restent inchangées
4. Mécanisme de synchronisation
4.1 Règles de synchronisation
La synchronisation se produit uniquement entre les serveurs de stockage de ce groupe.
Seules les données source doivent être synchronisées et les données de sauvegarde n'ont pas besoin d'être synchronisées à nouveau.
Lors de l'ajout d'un nouveau serveur de stockage, un serveur de stockage existant synchronisera toutes les données existantes (données source et données de sauvegarde) avec le nouveau serveur.
4.2 Réplication du journal binaire
La synchronisation de fichiers FastDFS adopte le mode de réplication asynchrone binlog. Le serveur de stockage utilise des fichiers binlog pour enregistrer le téléchargement, la suppression et d'autres opérations de fichiers, et synchronise les fichiers en fonction de Binlog. Seuls l'ID de fichier et l'opération sont enregistrés dans Binlog, et le contenu du fichier n'est pas enregistré. Le format de binlog est le suivant :
Horodatage | Type d'opération | Nom de fichier
1490251373 C M02/52/CB/CtAqWVjTbm2AIqTkAAACd_nIZ7M797.jpg
Type d'opération (partiel) :
-
C pour la création de source, c pour la création de copie
-
Un ajout de source signifie, un ajout de copie signifie
-
D signifie suppression de la source, d signifie suppression de la copie
-
. . . . . . .
4.3 Processus de synchronisation
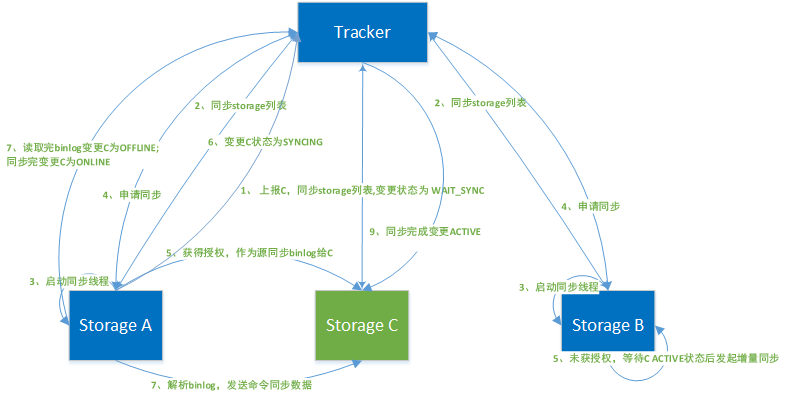
Après l'ajout d'un nouveau serveur de stockage, les autres serveurs de serveur de stockage du groupe démarrent des threads de synchronisation et lancent des opérations de synchronisation complètes et incrémentielles sur les serveurs nouvellement ajoutés sous la coordination du tracker.
(1) Une fois le stockage C démarré, il signale le groupe, l'adresse IP, le port, le numéro de version, le nombre de répertoires de stockage, le nombre de sous-répertoires, l'heure de démarrage, si la synchronisation des anciennes données est terminée et l'état actuel au tracker.
(2) Une fois que le tracker a reçu la demande de rejoindre le stockage C, il met à jour la liste de stockage local, la renvoie à C et la synchronise avec A et B en temps opportun.
(3) La mémoire C demande une demande de synchronisation au dispositif de suivi et change son état en WAIT_SYNC après la réponse.
(4) Les stockages A et B trouvent qu'il n'y a pas de C dans la nouvelle liste de stockage synchronisée avec eux pendant le cycle de pulsation, puis démarrez le fil de synchronisation, lancez d'abord une application de synchronisation sur le tracker (TRACKER_PROTO_CMD_STORAGE_SYNC_SRC_REQ), et le tracker renverra le horodatage de synchronisation au niveau IP de la source de synchronisation vers A et B, si l'IP source est cohérente avec sa propre adresse IP locale, se marque comme source de synchronisation pour l'ancienne synchronisation des données (source de synchronisation complète), en cas d'incohérence, se marque comme source de synchronisation incrémentielle (uniquement lorsque l'état du nœud C est Actif synchronisé). Cette décision est générée par la sélection du tracker, et A et B ne peuvent pas être utilisés comme sources de synchronisation en même temps, et ils sont synchronisés sur C en même temps.
(5) La source de synchronisation (en supposant que le stockage A) enregistre les informations de synchronisation de la machine cible dans un fichier avec un suffixe .mark et signale le changement d'état du stockage C comme SYNCING.
(6) Lire binlog.index à partir du répertoire /data.sync, l'identifiant du fichier binlog, lire ligne par ligne binlog.000 et l'analyser (voir le format dans binlog ci-dessus) Envoyer les données vers le stockage C, C Recevoir et enregistrer.
(7) Le processus de changement d'état du stockage C pendant la synchronisation des données est OFFLINE->ONLINE->ACTIVE. ACTIVE est l'état final, indiquant que le stockage C a fourni des services au monde extérieur.
5. Stockage de fichiers
5.1 Problème LOSF
Problèmes rencontrés par Small File Storage (LOSF):
-
Le nœud interne du système de fichiers local est prioritaire et le nombre de petits fichiers stockés est limité.
-
La hiérarchie des répertoires et le nombre de fichiers dans le répertoire peuvent entraîner une surcharge élevée (temps d'E/S élevés) pour accéder aux fichiers.
-
Le stockage, la sauvegarde et la restauration de petits fichiers sont inefficaces.
Pour les petits problèmes de stockage de fichiers, FastDFS fournit une solution de fusion de fichiers. FastDFS crée un fichier volumineux de 64 Mo par défaut. Un fichier volumineux peut stocker de nombreux petits fichiers. L'espace pour un petit fichier s'appelle un emplacement. La taille minimale de solt est de 256 octets et la taille maximale est de 16 Mo. Lorsque la taille est inférieure à 256 octets, elle est stockée sur 256 octets et les fichiers de plus de 16 Mo sont stockés séparément.
5.2 Méthode de stockage
**(1) [Méthode de stockage par défaut]** Si la fusion n'est pas activée, le file_id généré par FastDFS correspond au fichier réellement stocké sur le disque.
**(2) [Méthode de stockage combiné]** Plusieurs fichiers correspondant à file_id sont stockés dans un fichier volumineux. Format du nom du fichier tronc : /fastdfs/data/00/000001 Le nom du fichier augmente de 1. Le file_id généré est plus long et 16 octets de contenu supplémentaire seront ajoutés pour enregistrer le décalage et d'autres informations.
comme suit:
[file_size] : occupe l'espace des fichiers volumineux (notez que l'alignement est effectué en fonction de l'emplacement minimal de 256 octets)
[mtime] : heure de modification du fichier
[crc32] : Le code crc32 du contenu du fichier
[formatted_ext_name] : extension de fichier
[alloc_size] : la taille du fichier est égale à la taille
[id] : ID de fichier volumineux tel que 000001
[offset] : le décalage du contenu du fichier dans le fichier de tronc
【taille】 : taille du fichier.
5.3 Gestion de l'espace de stockage
**(1) [Trunk Server]** Sélectionné par le responsable du suivi dans un groupe de serveurs de stockage et notifié à tous les serveurs de stockage du groupe, responsables de l'allocation d'espace pour toutes les opérations de téléchargement dans le groupe.
**(2) [Idle Balance Tree] ** le serveur principal construira un arbre de solde inactif pour chaque store_path, et des blocs libres de la même taille sont stockés dans la liste liée, et chaque fois qu'une demande de téléchargement est faite, elle sera envoyé à l'arbre d'équilibre en fonction de la taille du fichier téléchargé. Trouvez un bloc libre qui est plus grand ou proche de celui-ci, puis divisez l'excédent du bloc libre en un nouveau bloc libre, et rejoignez l'arbre équilibré. S'il n'est pas trouvé, un nouveau fichier tronc sera reconstruit et ajouté à l'arborescence de la balance. Le processus d'allocation est un processus de maintien d'un arbre équilibré inactif.
**(3) [Trunk Binlog]** Une fois le stockage fusionné activé, le serveur Trunk aura un TrunkBinlog supplémentaire à synchroniser. Le TrunkBinlog enregistre toutes les opérations de bloc libre allouées et récupérées par le TrunkServer, et est synchronisé par le Trunk Server avec les autres serveurs de stockage du même groupe.
Le format TrunkBinlog est le suivant :
horodatage | type d'opération | store_path_index | sub_path_high | sub_path_low | file.id | décalage | taille 1410750754 A 0 0 0 1 0 67108864
La signification de chaque champ est la suivante :
[ file.id ] : nom du fichier TrunkFile, par exemple 000001
[offset] : le décalage dans le fichier TrunkFile
[taille] : la taille occupée, alignée en fonction de l'emplacement
6. Déduplication de fichiers
FastDFS n'a pas la capacité de dédupliquer les fichiers, donc FastDHT doit être introduit pour le compléter. FastDHT est un système de hachage distribué efficace pour les paires clé-valeur. La couche inférieure utilise Berkeley DB pour la persistance de la base de données et la méthode de synchronisation utilise la réplication binlog. Dans le scénario de déduplication FastDFS, hachez le contenu du fichier, puis évaluez si les fichiers sont cohérents.
Une fois le fichier téléchargé avec succès, vérifiez le chemin de stockage correspondant au stockage de stockage et vous constaterez qu'un lien symbolique est renvoyé. Après cela, chaque téléchargement répété renvoie un lien symbolique pointant vers le fichier téléchargé pour la première fois. Il garantit également qu'une seule copie du fichier est enregistrée.
(Remarque : FastDFS ne renverra pas l'index du fichier d'origine, tous les liens renvoyés sont des liens symboliques, lorsque tous les liens symboliques sont supprimés, le fichier d'origine sera également supprimé de FastDFS).
7. Résumé
FastDFS n'est en réalité qu'un système de gestion de fichiers (système de fichiers au niveau de l'application), tel que la gestion de fichiers téléchargés, d'images, etc. Contrairement au système de fichiers du disque système NTFS ou FAT et à d'autres systèmes de fichiers au niveau du système.