1. Affichage des effets
Reconnaissance de visage:
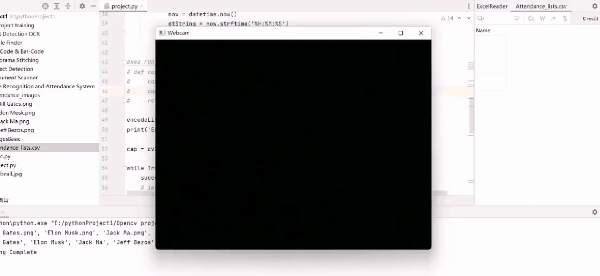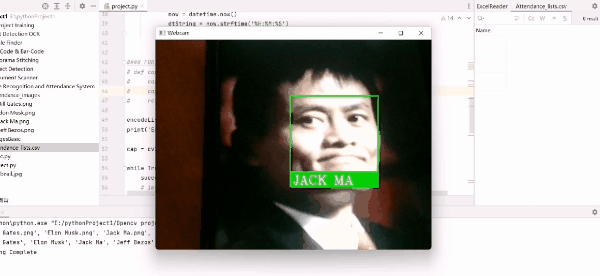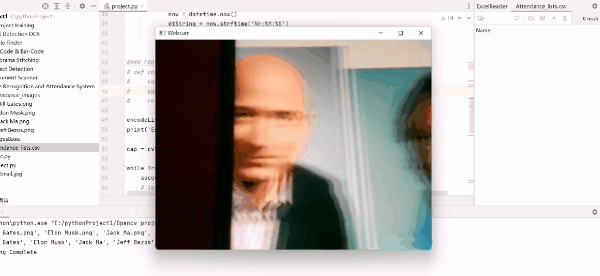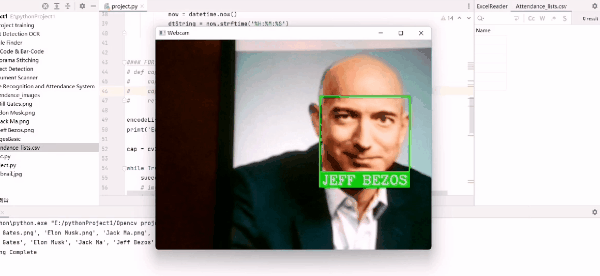
Effet fréquentation :
2. Présentation du projet
Ensuite, nous apprendrons comment effectuer une reconnaissance faciale avec une grande précision, en commençant par une brève introduction à la théorie et en apprenant la mise en œuvre de base. Ensuite, nous créerons un projet de présence qui utilisera une webcam pour détecter les visages et enregistrer la fréquentation en temps réel dans une feuille Excel.
3. Théorie de base du projet
(1) Construction du lot projet
Avant cela, vous devriez avoir lu cet article et terminé la construction du package du projet (37 messages) Le moyen le plus simple pour Python 3.7 de résoudre le problème de téléchargement de dlib et face_recognition
De plus, nous devons également installer un package, suivez simplement les étapes:
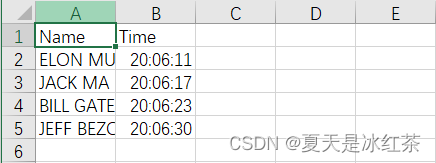
pip install face_recognition_models(2) Construction du fichier
Selon la configuration illustrée dans la figure, le contenu du fichier Attendance.csv est uniquement (Nom, Heure). Dans le fichier Attendance_images, vous pouvez ajouter des images que vous souhaitez ajouter, de préférence des images de personnages individuels, et nommer les images avec leurs noms anglais.
(3) affichage et explication du code basic.py
import cv2
import face_recognition
imgElon = face_recognition.load_image_file('ImagesBasic/Elon Musk.png')
imgElon = cv2.cvtColor(imgElon, cv2.COLOR_BGR2RGB)
imgTest = face_recognition.load_image_file('ImagesBasic/Elon test.png')
imgTest = cv2.cvtColor(imgTest, cv2.COLOR_BGR2RGB)
faceLoc = face_recognition.face_locations(imgElon)[0]
encodeElon = face_recognition.face_encodings(imgElon)[0]
cv2.rectangle(imgElon, (faceLoc[3], faceLoc[0]), (faceLoc[1], faceLoc[2]), (255, 0, 255), 2)
faceLocTest = face_recognition.face_locations(imgTest)[0]
encodeTest = face_recognition.face_encodings(imgTest)[0]
cv2.rectangle(imgTest, (faceLocTest[3], faceLocTest[0]), (faceLocTest[1], faceLocTest[2]), (255, 0, 255), 2)
results = face_recognition.compare_faces([encodeElon], encodeTest)
faceDis = face_recognition.face_distance([encodeElon], encodeTest)
print(results, faceDis)
cv2.putText(imgTest, f'{results} {round(faceDis[0], 2)}', (50, 50), cv2.FONT_HERSHEY_COMPLEX, 1, (0, 0, 255), 2)
cv2.imshow('Elon Musk', imgElon)
cv2.imshow('Elon Test', imgTest)
cv2.waitKey(0)
Nous utiliserons la photo de M. Musk comme test standard, "Elon Musk.png". Les deux autres photos sont de M. Bill Gates et M. Musk.
L'explication d'aujourd'hui sera divisée en deux parties, c'est la partie de base de l'explication.
- Tout d'abord, importez les images dans ces deux codes. Nous utilisons la fonction load_image_file dans face_recognition, qui chargera le fichier image (.jpg, .png, etc.) dans un tableau numpy, et le format par défaut mode='RGB', donc il y a une transformation ici.
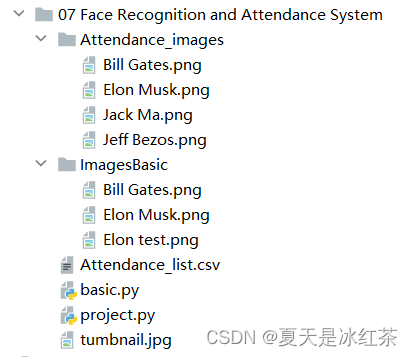
- Deuxièmement, faceLoc accepte le tableau de la boîte englobante du visage dans l'image renvoyée par la fonction face_locations (), veuillez consulter la note 1, prenez le premier nombre, il attendra jusqu'à un tuple, nous devons appuyer sur css (haut, droite, bas , gauche ) liste des tuples de positions de visage trouvées séquentiellement. La fonction encodeElon() renvoie une liste d'encodage de visage à 128 dimensions (une pour chaque visage de l'image), pourquoi est-elle à 128 dimensions ? Voir Remarque 2. Après cela, c'est à nouveau l'opération de trame. Je crois que ceux qui ont lu mes articles précédents doivent la connaître trop. Entrez les coordonnées selon la note 3.
- Après cela, compare_faces() compare la liste des encodages de visage avec les encodages candidats pour voir s'ils correspondent, rappelez-vous, seul le premier est une liste, qui renverra une liste de valeurs vrai/faux ; face_distance() nécessite un encodage de visage donné liste, comparez-la avec des codages de visage connus et obtenez la distance euclidienne pour chaque visage comparé. La distance vous dira à quel point les visages sont similaires. Encore une fois, seul le premier est une liste. Voir la remarque 4 ci-dessus.
- Enfin, placez les informations encadrées dans un emplacement approprié pour afficher l'image.
Remarque 1 : [(44, 306, 152, 199)]
Remarque 2 : L'apprentissage automatique est amusant ! Partie 4 : Reconnaissance faciale moderne et apprentissage en profondeur - Classement Fintech (fintechranking.com) par Adam Geitgey .
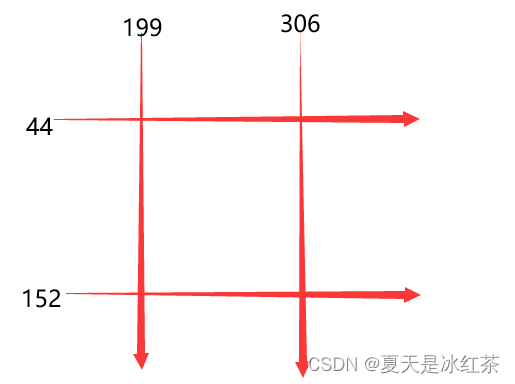
Remarque 3 : Diagramme de coordonnées
Remarque 4 : [Vrai] [0,4559636]
(5) Affichage des effets
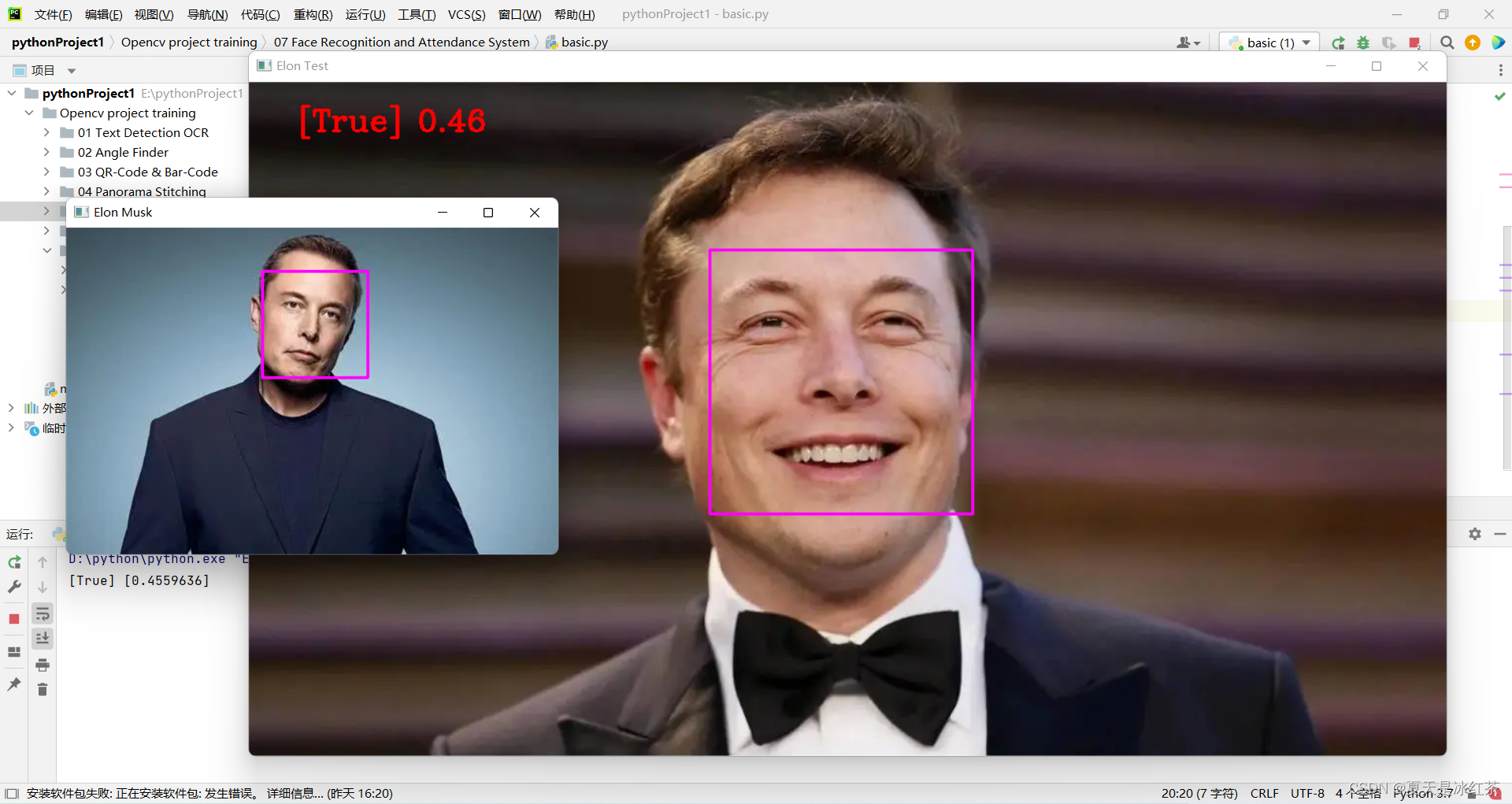
En modifiant le code ici, nous avons initialement implémenté la reconnaissance faciale.
imgTest = face_recognition.load_image_file('ImagesBasic/Bill Gates.png')
imgTest = cv2.cvtColor(imgTest, cv2.COLOR_BGR2RGB)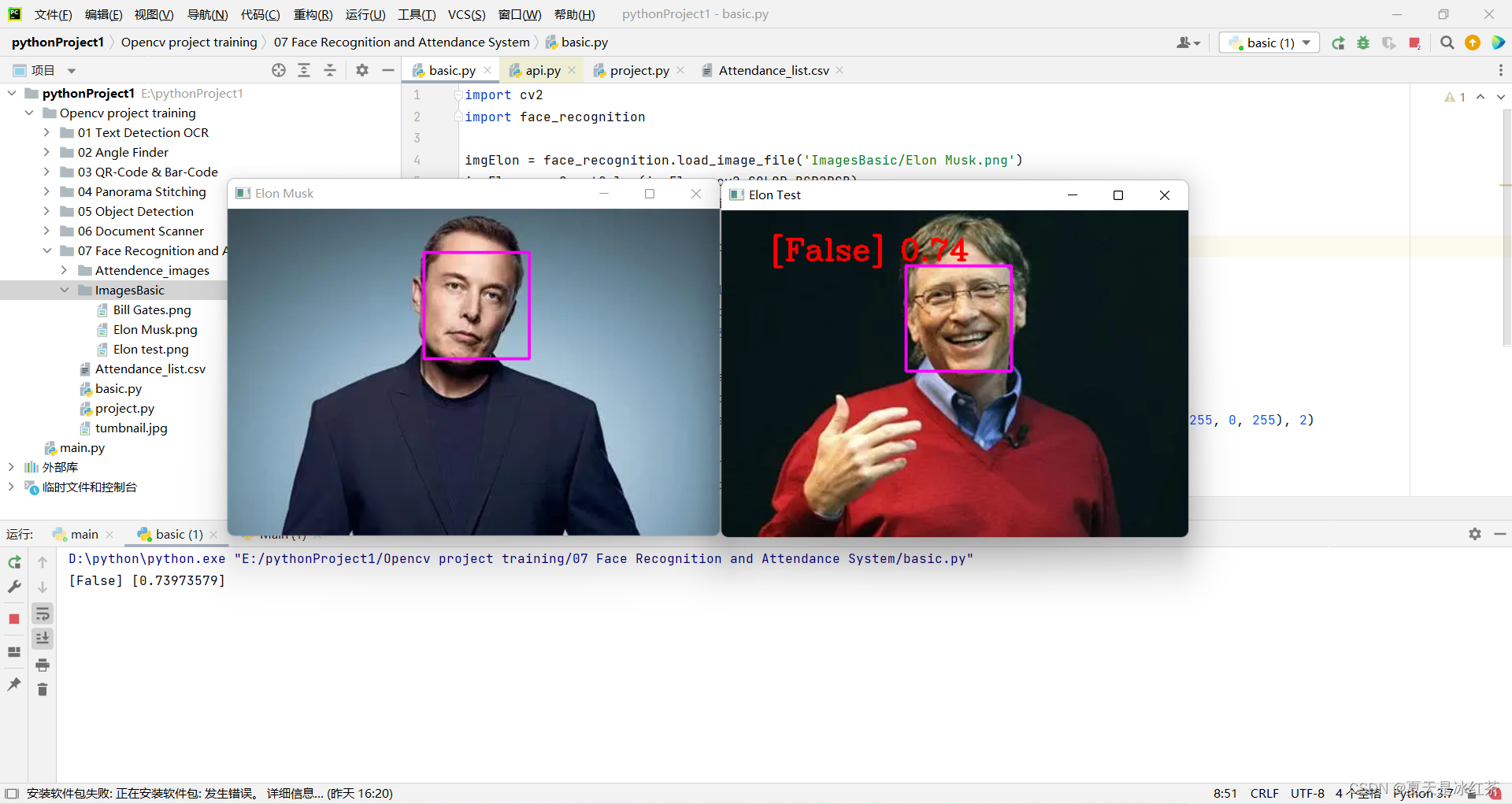
4. Affichage du code de projet et explication
import cv2
import numpy as np
import face_recognition
import os
from datetime import datetime
# from PIL import ImageGrab
path = 'Attendance_images'
images = []
classNames = []
myList = os.listdir(path)
print(myList)
for cl in myList:
curImg = cv2.imread(f'{path}/{cl}')
images.append(curImg)
classNames.append(os.path.splitext(cl)[0])
print(classNames)
def findEncodings(images):
encodeList = []
for img in images:
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
encode = face_recognition.face_encodings(img)[0]
encodeList.append(encode)
return encodeList
def markAttendance(name):
with open('Attendance_lists.csv', 'r+') as f:
myDataList = f.readlines()
nameList = []
for line in myDataList:
entry = line.split(',')
nameList.append(entry[0])
if name not in nameList:
now = datetime.now()
dtString = now.strftime('%H:%M:%S')
f.writelines(f'\n{name},{dtString}')
#### FOR CAPTURING SCREEN RATHER THAN WEBCAM
# def captureScreen(bbox=(300,300,690+300,530+300)):
# capScr = np.array(ImageGrab.grab(bbox))
# capScr = cv2.cvtColor(capScr, cv2.COLOR_RGB2BGR)
# return capScr
encodeListKnown = findEncodings(images)
print('Encoding Complete')
cap = cv2.VideoCapture(1)
while True:
success, img = cap.read()
# img = captureScreen()
imgS = cv2.resize(img, (0, 0), None, 0.25, 0.25)
imgS = cv2.cvtColor(imgS, cv2.COLOR_BGR2RGB)
facesCurFrame = face_recognition.face_locations(imgS)
encodesCurFrame = face_recognition.face_encodings(imgS, facesCurFrame)
for encodeFace, faceLoc in zip(encodesCurFrame, facesCurFrame):
matches = face_recognition.compare_faces(encodeListKnown, encodeFace)
faceDis = face_recognition.face_distance(encodeListKnown, encodeFace)
# print(faceDis)
matchIndex = np.argmin(faceDis)
if matches[matchIndex]:
name = classNames[matchIndex].upper()
# print(name)
y1, x2, y2, x1 = faceLoc
y1, x2, y2, x1 = y1 * 4, x2 * 4, y2 * 4, x1 * 4
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.rectangle(img, (x1, y2 - 35), (x2, y2), (0, 255, 0), cv2.FILLED)
cv2.putText(img, name, (x1 + 6, y2 - 6), cv2.FONT_HERSHEY_COMPLEX, 1, (255, 255, 255), 2)
markAttendance(name)
cv2.imshow('Webcam', img)
cv2.waitKey(1)Certaines des opérations ici ont été mentionnées dans mon blog précédent, et je l'ai expliqué très clairement, donc je vais en parler brièvement.
- Tout d'abord, lisez le nom de l'image dans le fichier Attendance_images, notez qu'il a .png, et que notre dénomination ne l'exige pas, alors prenez un [0].
- Deuxièmement, écrivez findEncodings() pour stocker les encodages des images standard, sous la forme d'une liste. La fonction markAttendance() est utilisée pour lire les informations du fichier de Attendance_lists.csv et les écrire dans Excel, où l'heure peut également être écrite.
- Ensuite, pour le reste, je pense qu'il ne devrait y avoir aucun problème en se référant à l'explication ci-dessus. Parlons de y1, x2, y2, x1 = y1 * 4, x2 * 4, y2 * 4, x1 * 4, pourquoi multiplier par 4, rappelez-vous le redimensionnement ci-dessus, il ne nécessite pas de changement de pixel, mais se rétrécit Le rapport est exactement 0,25.
5. Matériaux du projet
6. Résumé du projet
Le projet d'aujourd'hui est encore plus difficile que la détection d'objet précédente. Pour moi, l'efficacité actuelle n'est pas très élevée. Le téléchargement des packages dlib et face_recognition hier n'a vraiment pas été fait. J'ai changé un projet temporairement, et je l'ai fait aujourd'hui longtemps .
Alors j'espère que vous vous amuserez avec ce projet! !
