SeaweedFS est un système de stockage de fichiers distribué efficace.Le premier prototype de conception fait référence à Haystack de Facebook, qui a la capacité de lire et d'écrire rapidement de petits blocs de données. Cet article aidera les lecteurs à faire un choix plus approprié en comparant les différences de conception et de fonction entre SeaweedFS et JuiceFS.
Structure du système SeaweedFS
SeaweedFS se compose de 3 parties, le serveur de volume pour le stockage de fichiers sous-jacent, le serveur maître pour la gestion des clusters et un composant facultatif Filer qui fournit plus de fonctionnalités vers le haut.
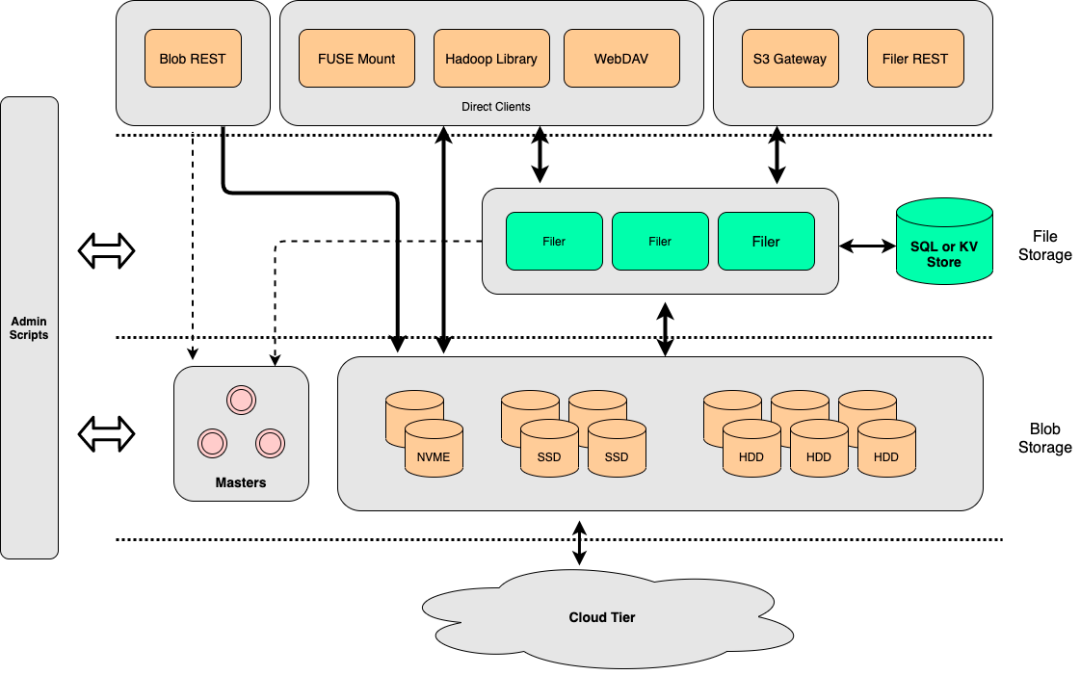
Serveur de volume 与 Serveur maître
En termes de fonctionnement du système, Volume Server et Master Server servent ensemble au stockage de fichiers. Volume Server se concentre sur l'écriture et la lecture de données, tandis que Master Server a tendance à être un service de gestion de cluster et de volumes.
Lors de la lecture et de l'écriture de données, l'implémentation de SeaweedFS est similaire à celle de Haystack. Un volume créé par l'utilisateur est un fichier disque volumineux (Superblock dans la figure ci-dessous). Dans ce volume, tous les fichiers écrits par l'utilisateur (Needle dans la figure ci-dessous) seront fusionnés dans ce grand fichier disque.
Avant de commencer à écrire des données, l'appelant doit s'adresser à SeaweedFS (serveur maître), puis SeaweedFS renverra un ID de fichier (composé de l'ID de volume et du décalage) en fonction du volume de données actuel. les informations de métadonnées (longueur du fichier, Chunk et autres informations) sont également écrites ; lorsque l'écriture est terminée, l'appelant doit associer et enregistrer le fichier et l'ID de fichier renvoyé dans un système externe (tel que MySQL). Lors de la lecture des données, étant donné que l'ID de fichier contient déjà toutes les informations pour calculer la position du fichier (décalage), le contenu du fichier peut être lu efficacement.
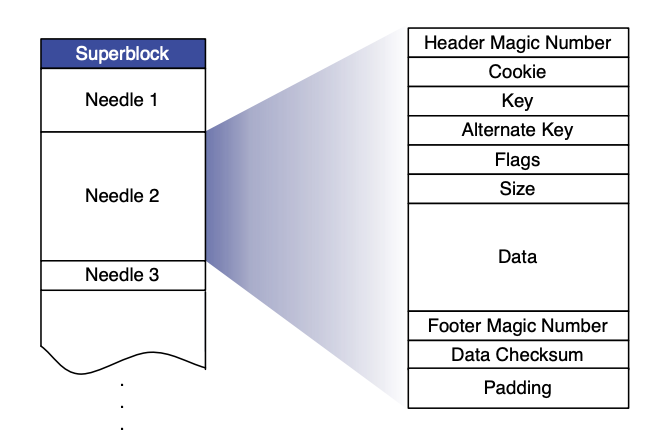
Déposant
En plus de l'unité de stockage sous-jacente mentionnée ci-dessus, SeaweedFS fournit un composant appelé Filer. En connectant Volume Server et Master Server vers le bas, il fournit une multitude de fonctions et de fonctionnalités (telles que le support POSIX, WebDAV, l'interface S3, etc.). Comme JuiceFS, Filer doit également se connecter à une base de données externe pour enregistrer les informations de métadonnées.
Pour la commodité de l'explication, le SeaweedFS mentionné ci-dessous inclut le composant Filer.
Structure du système JuiceFS
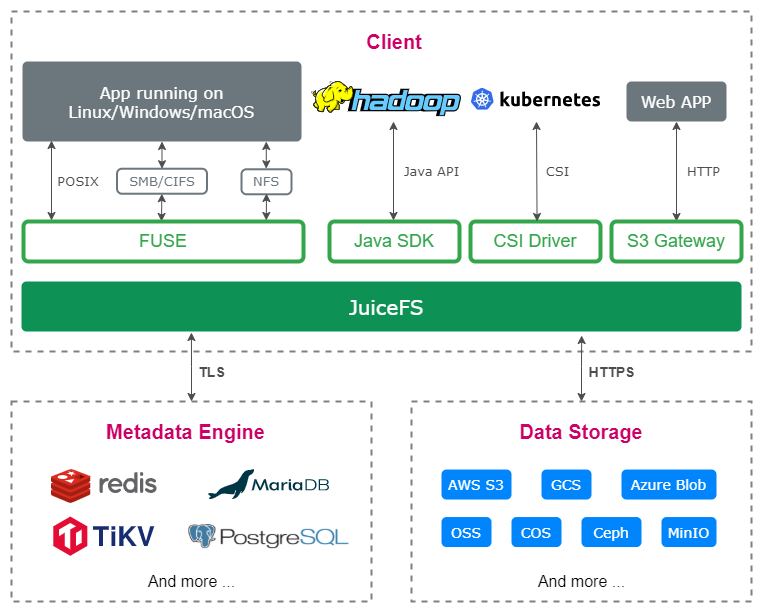
JuiceFS adopte une architecture de stockage distincte pour les "données" et les "métadonnées". Les données du fichier elles-mêmes seront segmentées et stockées dans le stockage d'objets (comme Amazon S3), tandis que les métadonnées seront stockées dans une base de données au choix de l'utilisateur (comme Redis, MySQL). En partageant la même base de données et le même stockage d'objets, JuiceFS implémente un système de fichiers distribué avec une forte garantie de cohérence, et dispose également de nombreuses fonctionnalités telles que la "compatibilité POSIX complète" et les "hautes performances".
comparaison de métadonnées
SeaweedFS et JuiceFS prennent en charge le stockage des informations de métadonnées du système de fichiers via une base de données externe. En termes de prise en charge des bases de données, SeaweedFS prend en charge jusqu'à 24 bases de données. JuiceFS a des exigences élevées en matière de capacités de transaction de base de données (voir ci-dessous) et prend actuellement en charge 3 types de bases de données de transaction au total.
opération atomique
Afin d'assurer l'atomicité de toutes les opérations de métadonnées, JuiceFS doit utiliser une base de données avec des capacités de traitement des transactions au niveau de la mise en œuvre. Cependant, SeaweedFS ne permet que la transaction de certaines bases de données (SQL, ArangoDB et TiKV) lors de l'exécution de l'opération de changement de nom, et a des exigences moindres pour la capacité de transaction de la base de données. Dans le même temps, étant donné que Seaweed FS ne verrouille pas le répertoire ou le fichier d'origine lors de la copie des métadonnées lors de l'opération de changement de nom, les données mises à jour au cours du processus peuvent être perdues.
journal des modifications
SeaweedFS générera un journal des modifications pour toutes les opérations de métadonnées, et ce journal peut être utilisé pour la réplication des données (voir ci-dessous), l'audit des opérations et d'autres fonctions, tandis que JuiceFS n'a pas encore implémenté cette fonctionnalité.
comparaison de stockage
Comme mentionné ci-dessus, le stockage de données de SeaweedFS est implémenté par Volume Server + Master Server, qui prend en charge des fonctionnalités telles que le "stockage fusionné" et le "code d'effacement" de petits blocs de données. Le stockage de données de JuiceFS est basé sur le service de stockage d'objets, et les fonctionnalités associées sont également fournies par le stockage d'objets sélectionné par l'utilisateur.
fractionnement de fichier
Lors du stockage des données, SeaweedFS et JuiceFS divisent le fichier en plusieurs petits blocs et les conservent dans le système de données sous-jacent. SeaweedFS divise les fichiers en blocs de 8 Mo, et pour les fichiers très volumineux (plus de 8 Go), il enregistre également l'index Chunk dans le système de données sous-jacent. JuiceFS est d'abord désassemblé en bloc de 64 Mo, puis désassemblé en objet de 4 Mo. Grâce au concept de tranche interne, les performances d'écriture aléatoire, de lecture séquentielle et d'écriture répétée sont optimisées. (Pour plus de détails, voir Lire le flux de traitement des demandes de compensation )
Stockage hiérarchique
Pour les volumes nouvellement créés, SeaweedFS stockera les données localement, tandis que pour les volumes plus anciens, SeaweedFS prend en charge leur téléchargement sur le cloud pour séparer les données chaudes et froides . À cet égard, JuiceFS doit s'appuyer sur des services externes.
compression des données
JuiceFS prend en charge l'utilisation de LZ4 ou ZStandard pour compresser toutes les données écrites, tandis que SeaweedFS choisit de compresser en fonction de l'extension et du type de fichier du fichier écrit.
cryptage du stockage
JuiceFS prend en charge le chiffrement en transit (chiffrement en transit) et le chiffrement au repos (chiffrement au repos). Lorsque l'utilisateur active le chiffrement statique, l'utilisateur doit transmettre une clé autogérée, et toutes les données écrites seront basées sur cette clé. . Voir " Cryptage des données " pour plus de détails.
SeaweedFS prend également en charge le chiffrement en transit et le chiffrement au repos. Une fois le cryptage des données activé, toutes les données écrites sur le serveur de volume seront cryptées avec une clé aléatoire, et les informations de clé aléatoire correspondantes seront gérées par le "Filer" qui gère les "métadonnées".
accord d'accès
Compatibilité POSIX
JuiceFS est entièrement compatible avec POSIX , tandis que SeaweedFS n'est que partiellement compatible POSIX ( "Issue 1558" et Wiki ), et la fonction est toujours en cours d'amélioration.
Protocole S3
JuiceFS implémente la fonction de passerelle S3 via la passerelle MinIO S3 . Il fournit une API RESTful compatible S3 pour les fichiers dans JuiceFS et peut utiliser s3cmd, AWS CLI, MinIO Client (mc) et d'autres outils pour gérer les fichiers stockés sur JuiceFS lorsqu'il n'est pas pratique de les monter.
SeaweedFS prend actuellement en charge environ 20 API S3, couvrant les requêtes couramment utilisées telles que la lecture, l'écriture, la requête et la suppression, et a également réalisé des extensions fonctionnelles pour certaines requêtes spécifiques (telles que la lecture).Pour plus de détails, consultez Amazon-S3- API .
Protocole WebDAV
JuiceFS et SeaweedFS prennent en charge le protocole WebDAV.
Compatibilité HDFS
JuiceFS est entièrement compatible avec l'API HDFS . Non seulement compatible avec Hadoop 2.x et Hadoop 3.x, mais également compatible avec divers composants de l'écosystème Hadoop. SeaweedFS offre une compatibilité de base avec l'API HDFS , mais ne prend pas encore en charge certaines opérations (telles que turncate, concat, checksum et attributs étendus, etc.).
Chauffeur CSI
JuiceFS et SeaweedFS fournissent tous deux le "Pilote Kubernetes CSI" pour aider les utilisateurs à utiliser le système de fichiers correspondant dans l'écosystème Kubernetes.
extensions
cache client
JuiceFS propose une variété de stratégies de mise en cache côté client, couvrant toutes les parties, des métadonnées à la mise en cache des données, permettant aux utilisateurs de régler en fonction de leurs propres scénarios d'application ( détails ), tandis que SeaweedFS n'a pas de capacités de mise en cache côté client.
Réplication de données de cluster
Pour la réplication de données entre plusieurs clusters, SeaweedFS prend en charge deux modes de réplication asynchrone, "actif-actif" et "actif-passif". Les deux modes assurent la cohérence entre les données dans différents clusters en passant le journal des modifications et en réappliquant le mécanisme. Pour chaque journal des modifications, il y aura une information de signature pour s'assurer que la même modification ne sera pas cyclée plusieurs fois. En mode actif-actif avec plus de 2 nœuds dans le cluster, certaines opérations de SeaweedFS (telles que renommer des répertoires) seront soumises à certaines restrictions.
JuiceFS ne prend pas en charge de manière native la synchronisation des données entre les clusters et doit s'appuyer sur le moteur de métadonnées et les capacités de réplication des données du stockage d'objets.
Cache de données sur le cloud
SeaweedFS peut être utilisé comme cache pour le stockage d'objets sur le cloud et prend en charge le préchauffage manuel des données via des commandes. Les modifications apportées aux données mises en cache sont synchronisées de manière asynchrone avec le stockage d'objets. JuiceFS doit stocker les fichiers dans le stockage d'objets en morceaux et ne prend pas encore en charge l'accélération de la mise en cache pour les données déjà dans le stockage d'objets.
corbeille
JuiceFS active la fonction de corbeille par défaut, qui déplacera automatiquement les fichiers supprimés par l'utilisateur vers le répertoire .trash sous le répertoire racine de JuiceFS, et conservera les données pendant une durée spécifiée avant de nettoyer les données. SeaweedFS ne prend pas encore en charge cette fonctionnalité.
Outil d'exploitation et de maintenance
JuiceFS fournit deux sous-commandes, juciefs stats et juicefs profile, qui permettent aux utilisateurs de visualiser les indicateurs de performance actuels ou de rejouer pendant une certaine période de temps en temps réel. Dans le même temps, JuiceFS développe également l' interface de métriques en externe, et les utilisateurs peuvent facilement connecter les données de surveillance à Prometheus et Grafana.
SeaweedFS réalise deux façons de connecter Prometheus et Grafana en même temps , Push et Pull , et fournit un outil interactif de weed shell pour aider les utilisateurs à effectuer une série de tâches d'exploitation et de maintenance (telles que l'affichage de l'état actuel du cluster, la liste des listes de fichiers , etc.).
autre
-
En termes de temps de sortie, SeaweedFS est sorti en avril 2015 et compte actuellement un total de 16,4K étoiles, tandis que JuiceFS est sorti en janvier 2021 et compte jusqu'à présent un total de 7,3K étoiles.
-
En termes de projets, JuiceFS et SeaweedFS adoptent la licence Apache 2.0, plus conviviale sur le plan commercial.SeaweedFS est principalement maintenu par Chris Lu, tandis que JuiceFS est principalement maintenu par Juicedata.
-
JuiceFS et SeaweedFS sont écrits en langage Go.
liste de comparaison
| AlguesFS | JusFS | |
|---|---|---|
| métadonnées | multimoteur | multimoteur |
| Atomicité des opérations de métadonnées | pas garantie | Garanti par les transactions de la base de données |
| journal des modifications | ont | aucun |
| stockage de données | Inclure | prestation externe |
| code d'effacement | soutien | S'appuyer sur des services externes |
| fusion de données | soutien | S'appuyer sur des services externes |
| fractionnement de fichier | 8 Mo | 64 Mo + 4 Mo |
| Stockage hiérarchique | soutien | S'appuyer sur des services externes |
| compression des données | Pris en charge (basé sur l'extension) | Prise en charge (paramètre global) |
| cryptage du stockage | soutien | soutien |
| Compatibilité POSIX | basique | ensemble |
| Protocole S3 | basique | basique |
| Protocole WebDAV | soutien | soutien |
| Compatibilité HDFS | basique | ensemble |
| Chauffeur CSI | soutien | soutien |
| cache client | pas de support | soutien |
| Réplication de données de cluster | Asynchrone bidirectionnel, multimode | pas de support |
| Cache de données sur le cloud | Prise en charge (synchronisation manuelle) | pas de support |
| corbeille | pas de support | soutien |
| Outil d'exploitation et de maintenance | fournir | fournir |
| temps de libération | 2015.4 | 2021.1 |
| mainteneur principal | Personnel (Chris Lu) | Entreprise (Juicedata Inc) |
| langue | Aller | Aller |
| accord open source | Licence Apache 2.0 | Licence Apache 2.0 |
Si vous êtes utile, veuillez prêter attention à notre projet Juicedata/JuiceFS ! (0ᴗ0✿)