Auteur : Équipe des opérations Internet de Vivo - Duan Chengping
Dans les scénarios d'entreprise à grande échelle, il n'est plus possible de fournir des services via une seule machine, ce qui nécessite un équilibrage de charge. Afin de répondre à la charge appropriée et fiable, cet article partira d'exigences de base simples, étape par étape et expliquera comment construire une plate-forme d'équilibrage de charge.
1. Comment garantir la fiabilité de votre entreprise
Réfléchissez à une question : Supposons que vous ayez 10 serveurs qui fournissent le même service au monde extérieur, comment vous assurez-vous que ces 10 serveurs peuvent gérer les requêtes externes de manière stable ?
Il peut y avoir de nombreuses solutions ici , mais elles traitent toutes essentiellement des deux problèmes suivants :
① À quel serveur la requête du client doit-elle être allouée ?
② En cas de défaillance de certains serveurs, comment isoler les serveurs défaillants ?
Problème 1. Si la gestion n'est pas bonne, certains des 10 serveurs peuvent être affamés et aucune requête client n'est allouée ou très peu allouée, tandis que l'autre partie a traité un grand nombre de requêtes, ce qui a entraîné une surcharge.
Si le problème ② n'est pas traité correctement, la disponibilité (A) dans le principe CAP peut ne pas être garantie sauf si le système ne nécessite pas A.
Pour résoudre les problèmes ci-dessus, vous devez implémenter un ensemble de contrôleurs capables de planifier les demandes métier et de gérer les serveurs métier. Malheureusement, ce contrôleur est souvent le goulot d'étranglement de l'ensemble du système dans la plupart des cas. Car si le système de contrôle ne va pas en profondeur chez le client, il doit s'appuyer sur un mécanisme décisionnel centralisé, qui doit porter toutes les demandes du client. À ce stade, vous devez tenir compte de la redondance et de l'isolement des pannes du contrôleur, qui devient sans fin.
2. Isolement des affaires et du contrôle
Alors, comment résoudre les problèmes ci-dessus?
Autrement dit, les choses professionnelles sont laissées aux plates-formes professionnelles, c'est-à-dire que nous avons besoin d'un équilibrage de charge indépendant pour fournir des solutions aux deux points ci-dessus.
Pour le client, chaque fois qu'un site est demandé, cela se transformera éventuellement en une demande d'une certaine adresse IP. Ainsi, tant que nous pouvons contrôler l'adresse IP à laquelle accède le client, nous pouvons contrôler sur quel serveur principal la requête doit tomber, afin d'obtenir l'effet de planification. C'est ce que fait DNS. Ou, détournez tout le trafic de demande client et redistribuez les demandes de trafic au serveur principal. C'est la méthode de traitement de Nginx, LVS, etc.
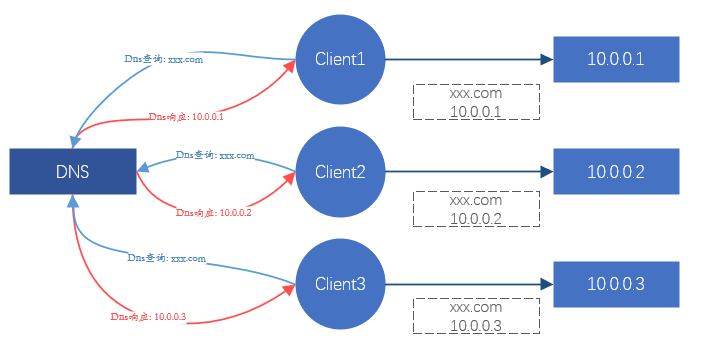
Figure 1. Diagramme schématique de l'effet de l'équilibrage de charge via DNS
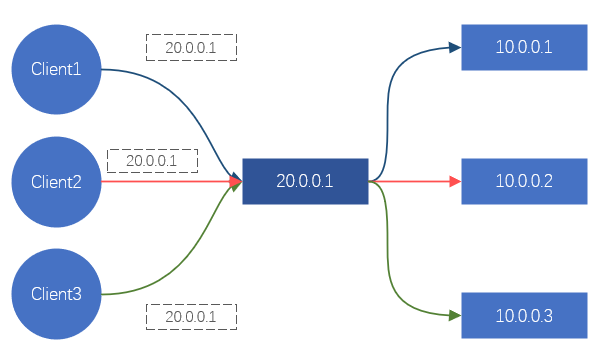
Figure 2. Diagramme schématique de l'effet de l'équilibrage de charge via LVS/Nginx
Ces deux méthodes peuvent obtenir l'effet d'équilibrage de charge. Mais il y a un sérieux problème ici. Des services tels que DNS, Nginx et LVS ne peuvent pas fournir de services sur une seule machine à l'ère d'Internet. Ils sont tous en cluster (c'est-à-dire composés de N serveurs), donc la fiabilité et la stabilité de ces clusters Et comment le garantir ?
Le DNS est principalement responsable de la résolution des noms de domaine et a un certain effet d'équilibrage de charge, mais l'effet de charge est souvent très faible, ce n'est donc pas la principale considération. Nginx fournit un équilibrage de charge de couche 7, s'appuyant principalement sur les noms de domaine pour la différenciation et la charge des entreprises. LVS est un équilibrage de charge de couche 4, reposant principalement sur le protocole TCP/UDP, l'adresse IP, le port TCP/UDP pour distinguer les services et les charges.
Afin de résoudre l'équilibrage de charge et la fiabilité des clusters d'équilibrage de charge tels que Nginx et LVS, nous pouvons faire les solutions simples suivantes :
-
La charge et la fiabilité du serveur métier sont garanties par Nginx ;
-
La charge et la fiabilité de Nginx sont garanties par LVS.
La solution ci-dessus suit la logique métier <-- charge de la couche 7 <-- charge de la couche 4 , et implémente en fait une charge à deux niveaux dans la couche application <-- couche de transport dans le modèle en couches réseau . On voit que cette solution utilise en fait une autre couche d'équilibrage de charge pour résoudre les problèmes de charge et de fiabilité de la couche courante. Cependant, des problèmes subsistent avec cette solution : la charge et la fiabilité de la couche métier et du cluster Nginx sont garanties, mais quid de la fiabilité de la couche cluster LVS ?
Puisque nous avons deux niveaux de charge dans la couche application <-- couche transport dans le modèle en couches réseau , est-il possible d'atteindre une charge à trois niveaux de la couche application <-- couche transport <-- couche réseau ? Heureusement, basés sur le routage IP, les équipements réseau (commutateurs, routeurs) ont naturellement la fonction d'équilibrage de charge de la couche réseau.
A ce stade, nous pouvons implémenter toute la chaîne d'équilibrage de charge : entreprise <-- charge de la couche 7 (Nginx) <-- charge de la couche 4 (LVS) <-- charge de la couche 3 (NetworkDevices) ;
On en déduit que pour garantir l'efficacité et la fiabilité de l'ensemble du système d'équilibrage de charge, il doit être construit à partir de la couche réseau. Les services de haut niveau peuvent fournir des charges pour les services de bas niveau. Par rapport au métier de bas niveau, le métier de haut niveau peut être considéré comme le plan de contrôle du métier de bas niveau, qui peut être mis en œuvre et géré par une équipe professionnelle.Le côté métier de bas niveau doit uniquement se concentrer sur le réalisation de l'entreprise elle-même.
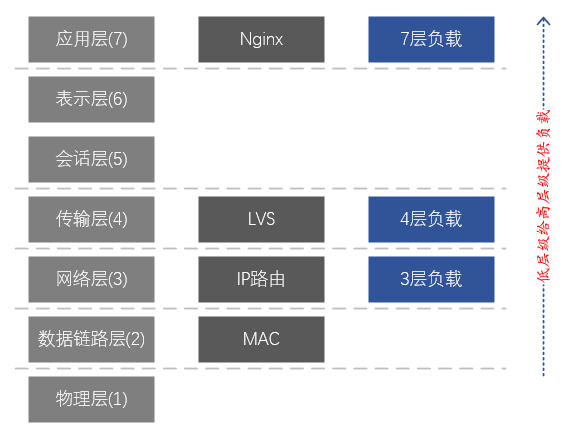
Figure 3. Correspondance entre le modèle de réseau à 7 couches et LVS et Nginx
Description du modèle en couches à 7 couches du réseau :
7. Couche application : prend en charge les applications réseau. Les protocoles d'application ne sont qu'une partie des applications réseau. Les processus exécutés sur différents hôtes utilisent les protocoles de la couche application pour communiquer. Les principaux protocoles sont : HTTP, FTP, Telnet, SMTP, POP3, etc.
6. Couche présentation : représentation, sécurité et compression des données. (En pratique, cette couche a été fusionnée avec la couche application)
5. Couche session : établir, gérer et terminer des sessions. (En pratique, cette couche a été fusionnée avec la couche application)
4. Couche transport : responsable de la fourniture de services de transmission de données entre les programmes d'application pour les sources et les destinations. Cette couche définit principalement deux protocoles de transport, le protocole de contrôle de transmission (TCP) et le protocole de datagramme utilisateur (UDP).
3. Couche réseau : responsable de l'envoi de datagrammes indépendamment de la source à la destination, résolvant principalement des problèmes tels que le routage, le contrôle de la congestion et l'interconnexion du réseau.
2. Couche liaison de données : chargée d'encapsuler les datagrammes IP dans des formats de trame adaptés à la transmission sur le réseau physique et de les transmettre, ou de décapsuler les trames reçues du réseau physique, de retirer les datagrammes IP et de les transmettre à la couche réseau.
1. Couche physique : responsable de la transmission du flux binaire entre les nœuds, c'est-à-dire responsable de la transmission physique. Le protocole à cette couche est lié à la fois au lien et au support de transmission.
3. Comment mettre en œuvre l'équilibrage de charge de couche 4
Comme mentionné ci-dessus, la charge de la couche 3 est naturellement fournie par l'équipement réseau, mais en utilisation réelle, elle est étroitement couplée à la charge de la couche 4 et ne fournit généralement pas de services de manière indépendante. La charge de la couche 4 peut fournir directement des services pour la couche métier sans dépendre de la charge de la couche 7 (la charge de la couche 7 est principalement destinée aux services tels que HTTP/HTTPS), nous nous concentrons donc principalement sur la charge de la couche 4 ici .
3.1 Comment transférer le trafic
Pour réaliser l'équilibrage de charge, l'implication est de réaliser la redirection du trafic, donc le premier problème à résoudre est de savoir comment transférer le trafic.
4 problèmes à résoudre :
① Comment attirer le trafic client vers l'équilibreur de charge ?
② Comment l'équilibreur de charge sélectionne-t-il un serveur principal approprié ?
③ Comment l'équilibreur de charge envoie-t-il les données de la requête au serveur principal ?
④ Comment le serveur principal répond-il aux données de la requête ?
Pour ①,
La solution est très simple, fournir à un lot de serveurs back-end une adresse IP indépendante, que nous appelons Virtual IP (également appelée VIP). Tous les clients n'ont pas besoin d'accéder directement à l'adresse IP principale, mais à la place d'accéder au VIP. Pour le client, cela équivaut à bloquer le backend.
Pour ②,
Compte tenu de la polyvalence de l'équilibrage de charge de bas niveau, les stratégies de charge complexes ne sont généralement pas mises en œuvre. Des solutions telles que RR (round robin) et WRR (round robin with weight) sont plus adaptées et peuvent répondre aux exigences de la plupart des scénarios.
Pour ③,
Le choix ici affectera souvent le choix de ④. Idéalement, nous nous attendons à ce que les données de la demande du client soient envoyées intactes au backend, afin d'empêcher la modification du paquet de données. Dans le modèle en couches de réseau à sept couches susmentionné, le transfert de la couche de liaison de données peut être réalisé sans affecter le contenu des paquets de données de couche supérieure, de sorte qu'il peut être transféré sans modifier les données demandées par le client. C'est ce que le réseau appelle souvent le transfert de couche 2 (couche de liaison de données, la deuxième couche du modèle de réseau à sept couches), qui repose sur l'adressage d'adresse MAC de la carte réseau pour transférer les données.
Alors, est-il possible de supposer que le paquet de données de demande du client est conditionné comme un élément de données d'application et envoyé au serveur principal ? Cette méthode équivaut à établir un tunnel entre l'équilibreur de charge et le backend, et à transmettre les données de demande du client au milieu du tunnel, afin qu'il puisse également répondre à la demande.
Parmi les deux solutions ci-dessus, la solution qui s'appuie sur le transfert de la couche liaison de données est appelée Route directe (Direct Route) , c'est-à-dire le mode DR ; l'autre solution qui nécessite un tunnel est appelée mode Tunnel . Le mode DR présente un inconvénient, car en s'appuyant sur le transfert d'adresse MAC, le serveur principal et l'équilibreur de charge doivent être dans le même sous-réseau (il ne peut pas être strictement considéré comme le même segment de réseau), ce qui conduit au fait que seul le même sous-réseau en tant qu'équilibreur de charge Les serveurs du réseau sont accessibles et il n'y a aucune possibilité d'utiliser l'équilibrage de charge s'ils ne sont pas dans le même sous-réseau.Ceci est évidemment impossible à répondre à l'activité à grande échelle actuelle. Le mode Tunnel présente également des inconvénients : la transmission des données dépendant du tunnel, un tunnel doit être établi entre le serveur backend et l'équilibreur de charge. Comment s'assurer que différents membres du personnel de l'entreprise peuvent configurer correctement le tunnel sur le serveur et surveiller le fonctionnement normal du tunnel est très difficile.Une plate-forme de gestion complète est nécessaire, ce qui signifie que le coût de gestion est trop élevé.
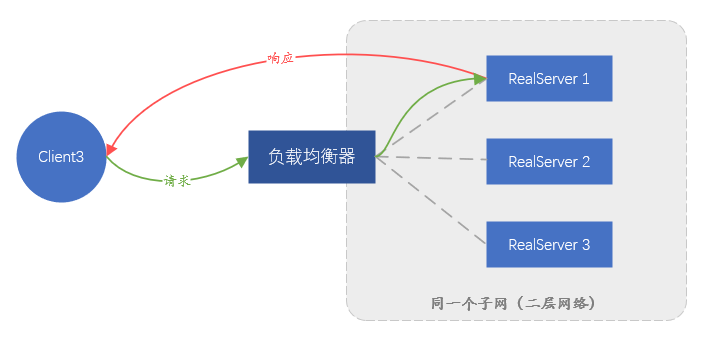
Figure 4. Schéma de principe du transfert en mode DR, le trafic de réponse ne passera pas par l'équilibreur de charge
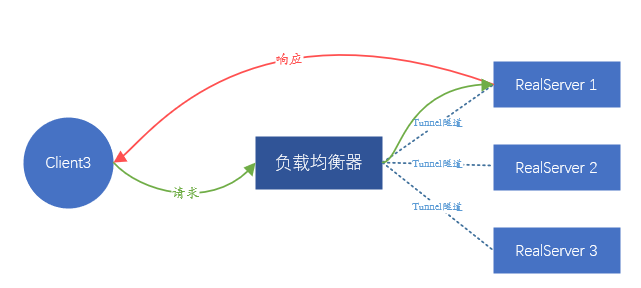
Figure 5. Schéma de principe du transfert en mode tunnel Comme DR, le trafic de réponse ne passera pas par l'équilibreur de charge
Puisqu'aucun d'entre eux n'est idéal, y a-t-il une autre solution?
Ce que nous attendons, c'est que le serveur back-end ne perçoive pas l'existence d'un équilibrage de charge dans le front-end, et le service peut être placé n'importe où sans aucune configuration excessive. Puisqu'il est impossible de transmettre le paquet de données du client intact, alors proxy la demande du client. C'est-à-dire que la traduction d'adresse IP est effectuée sur l'IP source et l'IP de destination des paquets de données envoyés par le client.
En détail, après avoir reçu la demande du client A, l'équilibreur de charge initie la même demande au serveur principal dans le rôle du client. La charge utile de la demande provient de la charge utile de la demande du client A, qui garantit que les données de la demande sont cohérent.
À ce stade, l'équilibreur de charge équivaut à initier une nouvelle connexion (différente de la connexion initiée par le client A), et la nouvelle connexion utilisera l'adresse IP de l'équilibreur de charge (appelée LocalIP) comme adresse source pour contacter directement le Communication IP du serveur principal.
Lorsque le backend renvoie des données à l'équilibreur de charge, les données sont renvoyées au client A via la connexion du client A. L'ensemble du processus implique deux connexions, correspondant à deux traductions d'adresse IP,
-
Heure de la requête : CIP→VIP, converti en LocalIP→IP du serveur principal,
-
Heure de retour des données : IP du serveur principal → IP locale, convertie en VIP → CIP.
Le processus de transfert des données du client est entièrement basé sur l'adresse IP au lieu de l'adresse MAC. Tant que le réseau est accessible, les données peuvent être transmises en douceur entre le client et le backend.
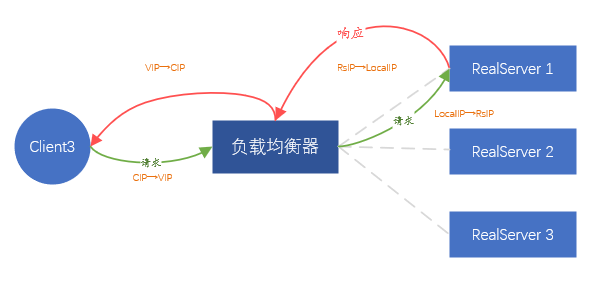
Figure 6. Mode de transfert FULLNAT
La solution ci-dessus est appelée mode de transfert FULLNAT , c'est-à-dire que deux traductions d'adresse sont réalisées. De toute évidence, cette méthode est assez simple, ne nécessite aucun ajustement du serveur backend et ne limite pas l'endroit où le backend est déployé. Mais il y a aussi un problème évident, c'est-à-dire que toutes les requêtes vues par le backend proviennent de l'équilibreur de charge, et les vraies informations IP du client sont complètement invisibles, ce qui équivaut à bloquer le vrai client. Heureusement, la grande majorité des applications du centre de données n'ont pas besoin de connaître les informations d'adresse IP du client réel. Même si les informations IP du client réel sont requises, l'équilibreur de charge peut charger cette partie des informations dans le protocole TCP/UDP. données de protocole, via Installer certains plug-ins selon les besoins.
Basé sur les solutions ci-dessus, le mode FULLNAT est le meilleur pour notre scénario d'entreprise (environnement non virtualisé).
Puisque nous avons l'intention d'utiliser le mode FULLNAT , il n'y a aucune difficulté à résoudre ④, car l'équilibreur de charge agit indirectement en tant que client, et toutes les données back-end doivent être transmises à l'équilibreur de charge, puis envoyées au vrai client par le fin de l'équilibreur de charge.
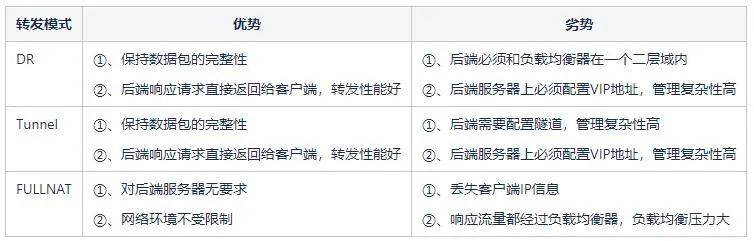
Tableau 1 : Analyse des avantages et inconvénients des différents modes
3.2 Comment éliminer les serveurs principaux anormaux
L'équilibrage de charge fournit généralement un mécanisme de détection de vérification de l'état du backend, de sorte que les adresses IP anormales du backend peuvent être rapidement éliminées. Idéalement, la détection basée sur la sémantique est la meilleure, et elle peut détecter plus efficacement si le backend est anormal. Mais cette méthode apportera beaucoup de consommation de ressources, surtout lorsque le backend est énorme ; ce n'est pas particulièrement grave, le plus grave est que le backend peut exécuter de nombreux types de HTTP, DNS, Mysql, Redis, etc. Protocoles, gestion les configurations sont très diverses et trop complexes. La combinaison des deux problèmes rend le bilan de santé trop lourd, ce qui va occuper beaucoup de ressources utilisées à l'origine pour la transmission des données, et le coût de gestion est trop élevé. Par conséquent, une méthode simple et efficace est nécessaire.Puisqu'il s'agit d'une charge de couche 4, nous n'identifions pas ce qu'est l'entreprise en amont, mais faisons seulement attention à savoir si le port TCP ou UDP est accessible. Le travail d'identification du métier de la couche supérieure est confié à la charge à 7 couches de type Nginx.
Par conséquent, tant que vous vérifiez régulièrement si tous les ports TCP/UDP backend sont ouverts, le service backend est considéré comme normal s'il est ouvert, et le service est considéré comme anormal s'il n'est pas ouvert. .
Alors comment le détecter ? Puisqu'il s'agit uniquement de juger si le port TCP est normalement ouvert, il suffit d'essayer d'établir une connexion TCP, si l'établissement réussit, cela indique que le port est normalement ouvert. Mais pour UDP, parce qu'UDP est sans connexion, il n'y a rien de tel que de créer une nouvelle connexion, mais il peut également atteindre l'objectif de détection en envoyant directement des données. Autrement dit, envoyez une donnée directement, en supposant que le port UDP est normalement ouvert, de sorte que le backend ne répond généralement pas. Si le port n'est pas ouvert, le système d'exploitation renverra un état de port icmp inaccessible, qui peut être utilisé pour déterminer que le port est inaccessible. Mais il y a un problème. Si le paquet de détection UDP contient une charge utile, cela peut amener le backend à penser qu'il s'agit de données commerciales et à recevoir des données non pertinentes.
3.3 Comment mettre en œuvre l'isolation des pannes de l'équilibreur de charge
Comme nous l'avons dit précédemment, l'équilibrage de charge de couche 4 repose sur l'équilibrage de couche réseau pour garantir que la charge entre les équilibreurs de charge de couche 4 est équilibrée, de sorte que l'isolation des pannes des équilibreurs de charge dépend de la couche réseau.
Comment faire?
En fait, nous nous appuyons sur le routage pour l'équilibrage de charge au niveau de la couche réseau.Chaque serveur du cluster d'équilibrage de charge notifie la même adresse VIP au périphérique réseau (commutateur ou routeur) via le protocole de routage BGP, et le périphérique réseau reçoit le même VIP Si un VIP provient de différents serveurs, une route à coût égal (ECMP) sera formée, et l'implication est de former un équilibrage de charge. Donc si on veut isoler un certain load balancer, il suffit de révoquer le VIP émis par le protocole de routage BGP sur le serveur, pour que le switch amont pense que le serveur a été isolé et ne transmette plus de données au correspondant serveur sur l'appareil.
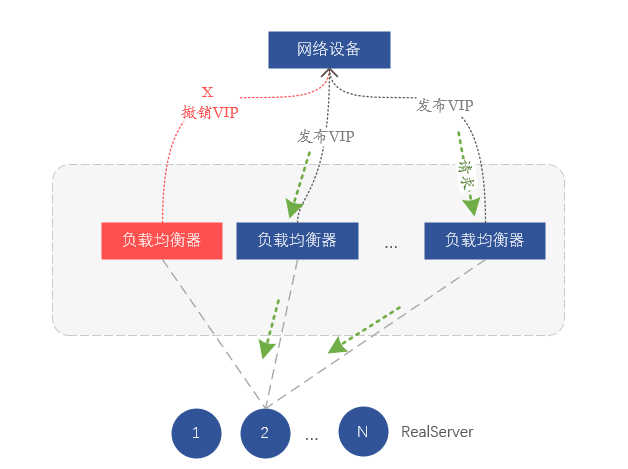
Figure 7. Isolation des pannes en supprimant les routes VIP
Jusqu'à présent, nous avons implémenté un modèle d'architecture d'équilibrage de charge basé sur FULLNAT, qui s'appuie principalement sur les ports de protocole de couche 3 pour les contrôles de santé, et réalise des émetteurs-récepteurs VIP via BGP et l'amarrage des périphériques réseau.
4. Mise en œuvre de VGW
Sur la base de l'architecture de charge à 4 couches mentionnée ci-dessus, nous avons construit VGW (vivo Gateway), qui fournit principalement des services d'équilibrage de charge à 4 couches pour les services intranet et extranet. Ensuite, nous expliquerons l'architecture logique, l'architecture physique, la garantie de redondance et comment améliorer les performances de transfert de gestion.
4.1 Composants VGW
La fonction principale de VGW est l'équilibrage complexe, et il a également des fonctions telles que la vérification de l'état et le drainage des affaires.Par conséquent, les composants qui composent VGW sont principalement le module de transfert d'équilibrage de charge de base, le module de vérification de l'état et le module de contrôle de routage.
-
Module de transfert d'équilibrage de charge : principalement responsable du calcul de charge et du transfert de données ;
-
Module de vérification de l'état : principalement responsable de la détection de l'état disponible du backend (RealServer) et de la suppression du backend indisponible à temps, ou de la restauration du backend disponible ;
-
Module de contrôle de routage : effectuez principalement la libération et le drainage VIP et isolez les serveurs VGW anormaux.
4.2 Schéma d'architecture logique
Pour la commodité de la compréhension, nous appelons le lien du client à la VGW le réseau externe (External), et le lien de la VGW au backend (RealServer) est plus complexe que le réseau interne (Internal). En termes d'architecture logique, la fonction de VGW est très simple, c'est-à-dire répartir équitablement les requêtes métier externes vers le RealServer interne.
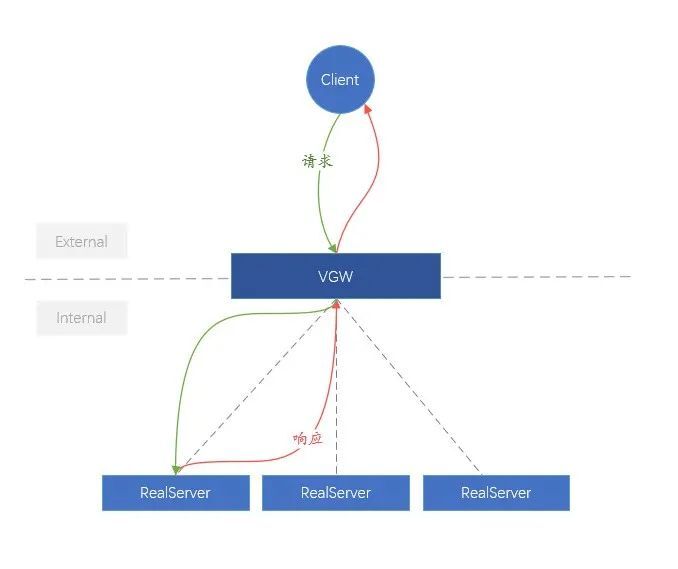
Figure 8. Schéma logique de VGW
4.3 Schéma d'architecture physique
En termes d'architecture physique, il existe certaines différences entre la VGW qui fournit le réseau interne et la VGW qui fournit le réseau externe.
Le cluster VGW de réseau externe utilise au moins deux cartes réseau, qui sont respectivement connectées aux périphériques réseau du côté réseau externe et aux périphériques réseau du côté réseau interne. Pour le serveur VGW, deux ports réseau étendent deux liaisons, similaires à une paire de bras humains, ce mode est donc appelé mode à double bras et un paquet de données ne passe qu'une seule fois par une seule carte réseau du serveur VGW.
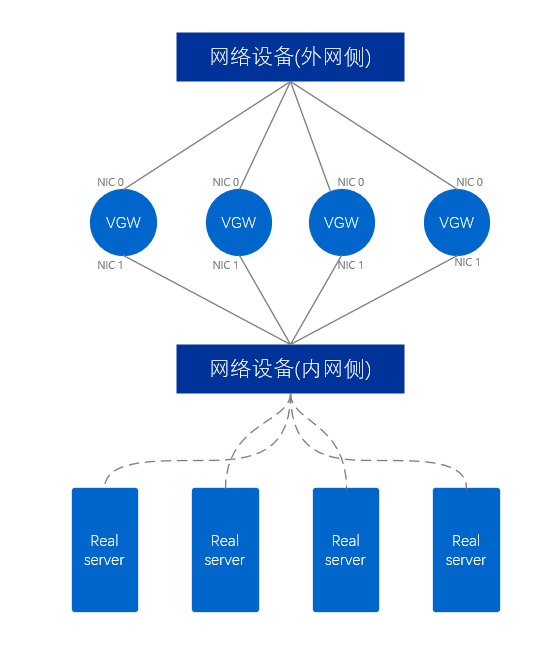
Figure 9. Schéma physique du réseau externe VGW
Le réseau interne VGW est différent du réseau externe et le réseau interne VGW n'utilise qu'une seule carte réseau pour se connecter directement à l'équipement réseau du côté du réseau interne. En conséquence, cette méthode est appelée mode à bras unique. Un paquet de données doit d'abord entrer à partir d'une seule carte réseau, puis sortir de la carte réseau et enfin le transférer vers l'extérieur, en passant par la carte réseau deux fois au total.
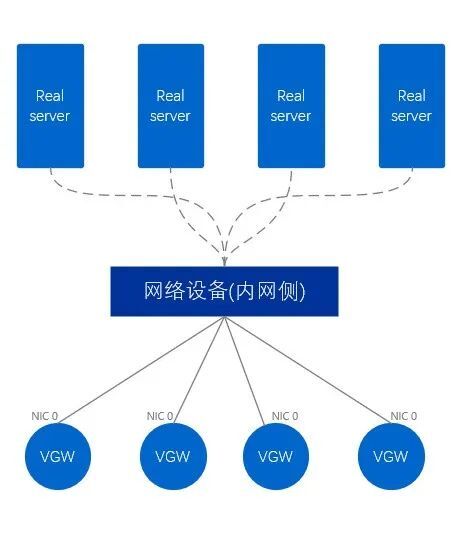
Figure 10. Schéma physique de l'intranet VGW
4.4 Modèle commercial existant de VGW
Comme nous l'avons dit précédemment, l'équilibrage de charge peut fournir un niveau d'équilibrage de charge plus élevé pour les charges de la couche 7.
-
À l'heure actuelle, le trafic commercial le plus important de VGW provient du trafic de la plate-forme d'accès à 7 couches (c'est-à-dire Nginx), et Nginx porte essentiellement la plupart des activités principales de l'entreprise.
-
Bien sûr, Nginx ne peut pas prendre en charge tous les types de services. Nginx de couche 7 ne prend pas en charge le type de trafic non HTTP construit directement au-dessus de TCP et UDP. Ces services sont directement transmis au serveur de service par VGW, sans autres liens. entre les deux. , comme Kafka, Mysql, etc.
-
Une autre partie de l'activité est que les utilisateurs ont construit diverses plates-formes proxy, similaires à Nginx, etc., mais VGW leur fournit également un équilibrage de charge de couche 4.
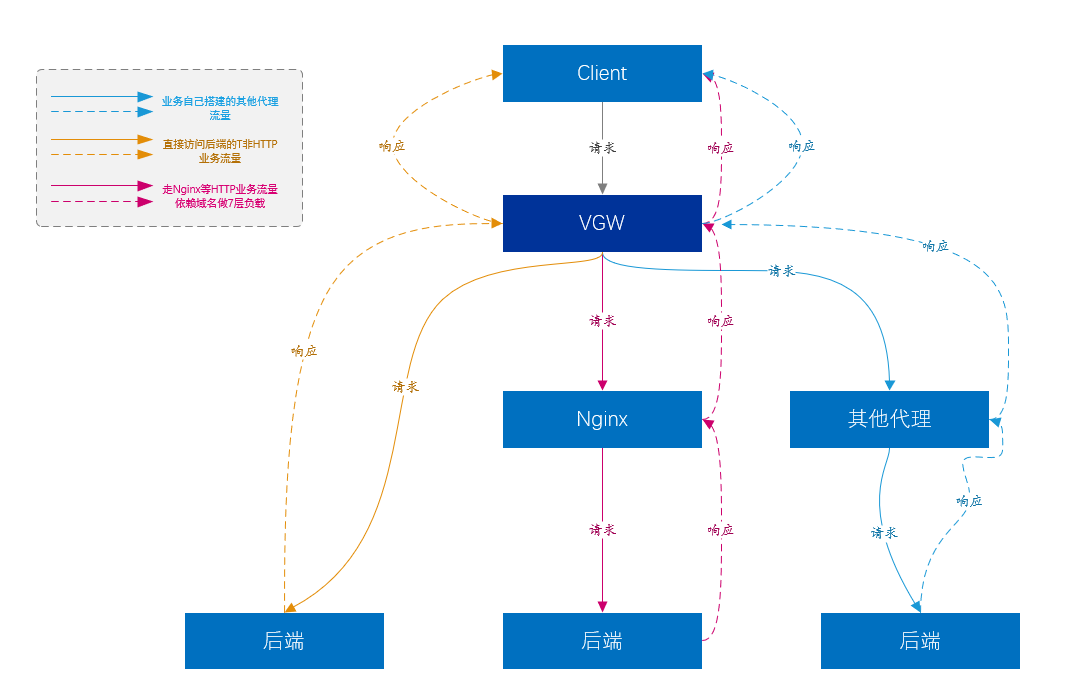
Figure 11. Diagramme du modèle commercial VGW
4.5 Garantie de redondance VGW
Afin d'améliorer la convivialité, quels risques faut-il prendre en compte ? Tout le monde envisage naturellement des scénarios tels qu'une panne de serveur et une panne de processus. Cependant, d'autres éléments doivent être pris en compte dans le scénario VGW, car l'ensemble du système VGW comprend des liaisons, des périphériques réseau, des serveurs, des processus, etc. Et nous ne pouvons pas simplement considérer le simple scénario d'indisponibilité de l'appareil.En fait, la situation la plus gênante est que l'un des appareils mentionnés ci-dessus ne tombe pas en panne mais avance anormalement.
Par conséquent, la première étape consiste à vérifier si le transfert du service VGW est normal.Nous établissons régulièrement des connexions avec les VIP via des nœuds de détection déployés dans différentes salles informatiques et régions, et utilisons le taux d'échec de connexion comme norme pour mesurer si le VGW est normal. En fait, cette surveillance équivaut à détecter si les liens et la retransmission de tous les liens impliquant la VGW sont bons.
La surveillance ci-dessus couvre la détection au niveau du cluster. Bien sûr, nous avons également mis en place d'autres surveillances plus fines pour trouver des problèmes spécifiques.
Après avoir surveillé les données de première main, nous pouvons fournir des capacités de gestion des pannes au niveau du serveur et des pannes au niveau du cluster.
-
VGW isole automatiquement les temps d'arrêt directs de tous les niveaux d'équipement ;
-
Toutes les anomalies au niveau de la liaison, dont certaines peuvent être automatiquement isolées ;
-
Toutes les exceptions au niveau du processus peuvent être automatiquement isolées ;
-
Pour les autres anomalies qui ne sont pas des pannes complètes, une intervention manuelle est nécessaire pour les isoler.
L'isolation des pannes au niveau du serveur signifie que certains serveurs VGW annuleront la libération de VIP via l'ajustement de l'itinéraire, afin d'atteindre l'objectif d'isolation ;
L'isolation des pannes au niveau du cluster consiste à annuler la publication du VIP de l'ensemble du cluster VGW, de sorte que le trafic soit automatiquement attiré par le cluster de secours et que le cluster de secours prenne en charge tout le trafic professionnel.
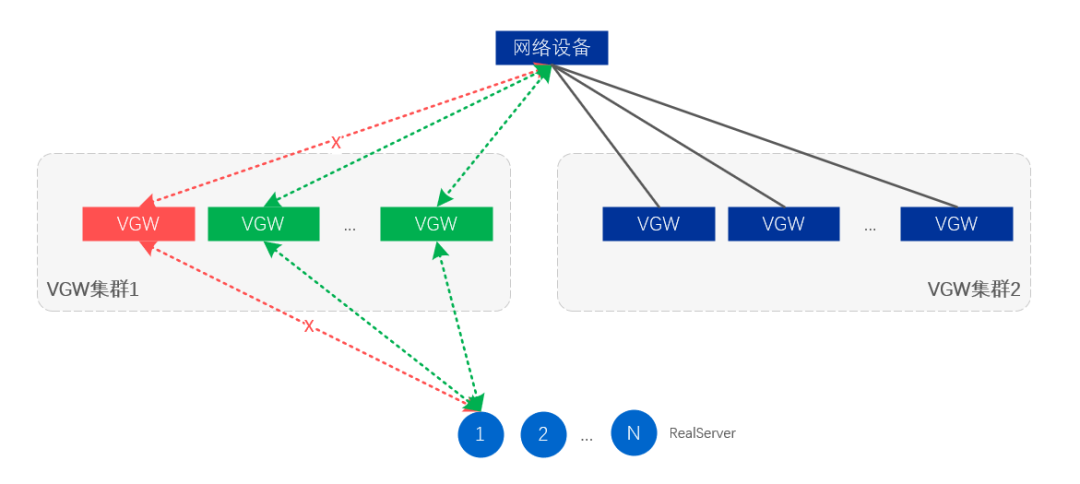
Figure 12. Isolation des pannes au niveau du serveur et de la liaison
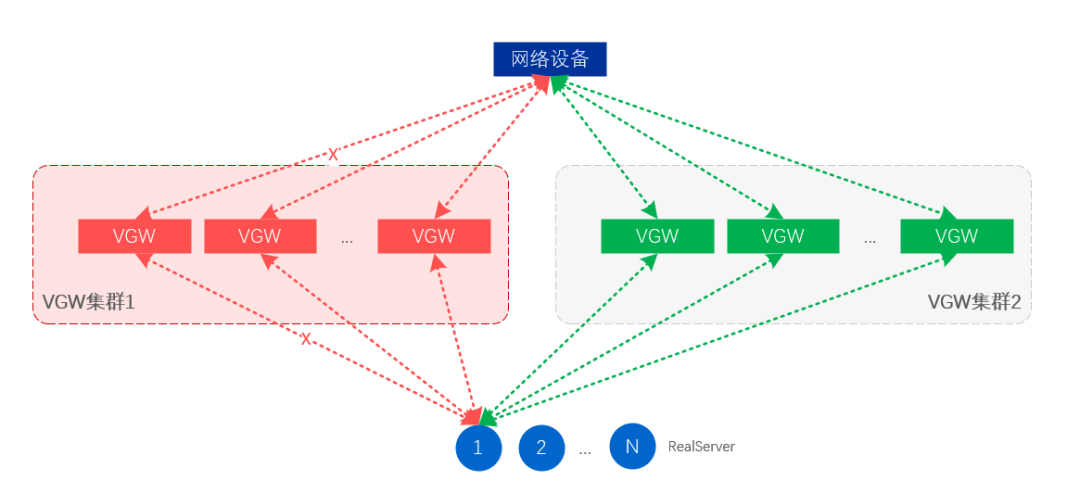
Figure 13. Isolation des pannes au niveau du cluster
4.6 Comment améliorer les performances de VGW
À mesure que le volume d'activité devient de plus en plus important, un seul VGW doit recevoir près d'un million de requêtes QPS et, en même temps, atteindre une capacité de traitement de paquets de plus de 500 W/s. De toute évidence, les serveurs généraux ne peuvent pas atteindre un si grand nombre de requêtes et de vitesses de traitement de paquets, principalement en raison du mécanisme de traitement réseau de Linux. Tous les paquets de données réseau doivent passer par le noyau Linux. Une fois que la carte réseau reçoit les paquets de données, elle doit envoyer une interruption au CPU, qui sera traitée par le CPU dans le noyau, puis une copie sera copiée dans l'application. programme. L'envoi de données doit également être traité par le noyau. Les interruptions fréquentes et la copie constante de données entre l'espace utilisateur et l'espace noyau entraînent une forte consommation de temps CPU dans le traitement des données réseau.Plus le débit de paquets est élevé, plus les performances sont mauvaises. Bien sûr, il existe d'autres problèmes tels que Cache Miss, consommation de copie de données inter-CPU, etc.
Il est facile de penser ici, le sale travail effectué par le processeur ci-dessus peut-il être envoyé à la carte réseau pour le faire, et le processeur ne peut traiter que des données commerciales. A l'heure actuelle, de nombreuses solutions reposent sur cette idée, la solution matérielle comprend des cartes réseau à puce, et la solution purement logicielle utilise actuellement DPDK (Intel Data Plane Development Kit). Évidemment, le coût de la carte réseau à puce sera élevé, et elle est encore en phase de développement, et l'application a un certain coût. Le logiciel pur DPDK est bien meilleur en termes de coût et de contrôlabilité.Nous avons choisi DPDK comme composant de transfert de paquets sous-jacent (en fait un développement secondaire basé sur le DPVS open source d'iQIYI).
DPDK intercepte principalement le processus de traitement des paquets du noyau et envoie directement les paquets de données utilisateur au programme d'application au lieu d'être traités par le noyau. Dans le même temps, le comportement consistant à s'appuyer sur l'interruption de la carte réseau pour traiter les données est ignoré et la méthode d'interrogation est utilisée pour lire les données de la carte réseau, afin d'atteindre l'objectif de réduction de l'interruption du processeur. Bien sûr, l'affinité du processeur est également utilisée et un processeur fixe est utilisé pour traiter les données de la carte réseau, ce qui réduit la consommation de commutation de processus. De plus, il existe de nombreuses technologies d'optimisation concernant le cache et la mémoire. En général, la vitesse de traitement des paquets de la carte réseau du serveur peut atteindre des dizaines de millions de PPS, ce qui améliore considérablement la capacité de traitement des paquets de la carte réseau, puis peut augmenter le CPS (nombre de nouvelles connexions par seconde) du serveur. À l'heure actuelle, nous pouvons atteindre une capacité de traitement d'entreprise de 100w+ CPS et 1200w+PPS sous la carte réseau 100G (résultats de test dans des conditions limitées, pas de valeurs théoriques).
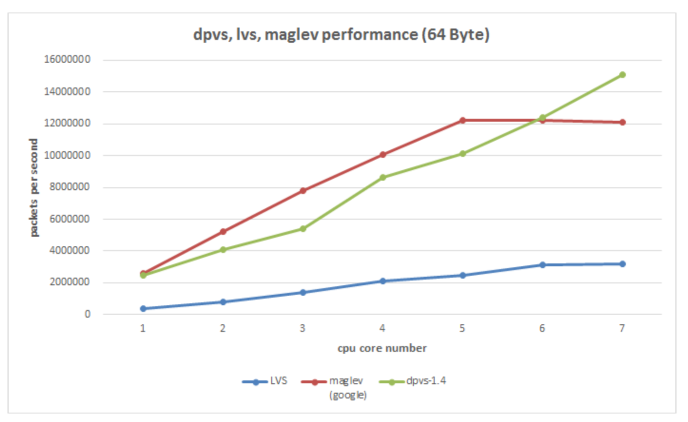
Figure 14. L'outil sous-jacent DPVS (DPDK+LVS) utilisé par VGW compare les performances de plusieurs solutions d'équilibrage de charge existantes
V. Résumé
À travers les explications ci-dessus, nous avons progressivement déduit un ensemble de solutions d'équilibrage de charge réalisables à partir d'une exigence de fiabilité de l'entreprise, et combinés aux besoins réels de vivo, nous avons mis en place notre plate-forme d'accès d'équilibrage de charge VGW. Bien sûr, le schéma d'équilibrage de charge actuel est le résultat de nombreux compromis, et il est impossible d'être parfait. Dans le même temps, nous serons également confrontés au problème de la prise en charge de nouveaux protocoles commerciaux à l'avenir, ainsi qu'au conflit entre le modèle commercial décentralisé du centre de données et le contrôle centralisé de l'équilibrage de charge. Mais la technologie a progressé, mais il y aura toujours une solution adaptée !