Auteur : JD Retail Zhang Luyao
1. Scénarios d'application
À l'heure actuelle, de nombreuses fonctions du système nécessitent un traitement différé : annulation du délai de paiement, délai d'attente de la file d'attente, envoi différé de SMS, WeChat et autres rappels, actualisation du jeton, expiration de la carte de membre, etc. Grâce au traitement différé, les ressources système sont considérablement économisées et il n'est pas nécessaire d'interroger la base de données pour les tâches de traitement.
À l'heure actuelle, la plupart des fonctions sont complétées par des tâches de temporisation. Il existe deux types de tâches de temporisation : quartz et xxljob. Le temps d'interrogation est court et exécuté une fois par seconde, ce qui met une certaine pression sur la base de données et a un délai de 1 seconde. erreur. Le temps d'interrogation est long, par exemple, une fois toutes les 30 minutes, une donnée est insérée à 03h01 et l'expiration est normalement exécutée à 3h31, mais lorsque l'interrogation est effectuée à 3h30, les données de 3h00-3h30 est scanné, mais le scan est inférieur à 3 : Les données de 31 ne peuvent être scannées qu'à 4h00, ce qui équivaut à un retard de 29 minutes !
2. Recherche sur les méthodes de traitement différé
1.DelayQueue
1. Mode de mise en œuvre :
La file d'attente de blocage de retard fournie par jvm trie les tâches avec différents temps de retard dans la file d'attente prioritaire, bloque la condition et acquiert les tâches retardées pendant le délai de veille.
Lorsqu'une nouvelle tâche est ajoutée, il jugera si la nouvelle tâche est la première tâche à exécuter. Si c'est le cas, la file d'attente sera libérée pour empêcher les éléments nouvellement ajoutés qui doivent être exécutés et ne peuvent pas être normalement obtenus par l'exécution fil de discussion.
2. Problèmes existants :
1. Fonctionnement autonome, une fois le système en panne, une nouvelle tentative efficace ne peut pas être effectuée
2. Échec de la journalisation et de la sauvegarde
3. Pas de mécanisme de nouvelle tentative
4. Lorsque le système redémarre, la tâche sera effacée !
5. La consommation de fragments n'est pas autorisée
3. Avantages : mise en œuvre simple, blocage en l'absence de tâche, économie de ressources et temps d'exécution précis
2. Retarder la file d'attente mq
Méthode de mise en œuvre : s'appuyer sur mq et réaliser la fonction de consommation retardée en définissant le temps de consommation retardé. Comme rabbitMq et jmq, vous pouvez définir le temps de consommation retardé. RabbitMq est implémenté en définissant le délai d'expiration du message et en le plaçant dans la file d'attente de lettres mortes pour consommation.
Problèmes existants :
1. Le réglage de l'heure n'est pas flexible. Chaque file d'attente a un délai d'expiration fixe. Chaque fois qu'une file d'attente de retard est nouvellement créée, une nouvelle file d'attente de messages doit être créée.
Avantages : S'appuyant sur jmq, il peut surveiller, consommer des enregistrements et réessayer efficacement, a la capacité de consommer plusieurs machines en même temps et n'a pas peur des temps d'arrêt
3. Tâches planifiées
Interroger des données qualifiées via des tâches planifiées
défaut:
1. Il est nécessaire de lire la base de données métier, ce qui met une certaine pression sur la base de données.
2. Il y a un retard
3. Lorsque la quantité de données numérisées est trop importante, elle utilise trop de ressources système.
4. La fragmentation ne peut pas être consommée
avantage:
1. Après l'échec de la consommation, vous pouvez continuer à consommer la prochaine fois et avoir la possibilité de réessayer.
2. Pouvoir d'achat stable
4.redis
Les tâches sont stockées dans redis et la file d'attente zset de redis est utilisée pour trier en fonction du score. Le programme obtient en permanence la consommation de données de file d'attente via le thread pour réaliser la file d'attente de retard.
avantage:
1. L'interrogation de redis est plus rapide que la base de données, et la longueur de la file d'attente définie est trop grande, et la requête sera effectuée selon la structure de la table de saut, qui est très efficace
2. Redis peut être trié en fonction de l'horodatage, il vous suffit d'interroger la tâche du score dans l'horodatage actuel
3. Aucune crainte de redémarrage de la machine
4. Consommation distribuée
défaut:
1. Limité par les performances de Redis, 10 W simultanés
2. Plusieurs commandes ne peuvent pas garantir l'atomicité. L'utilisation de scripts lua nécessitera que toutes les données soient sur une seule partition redis.
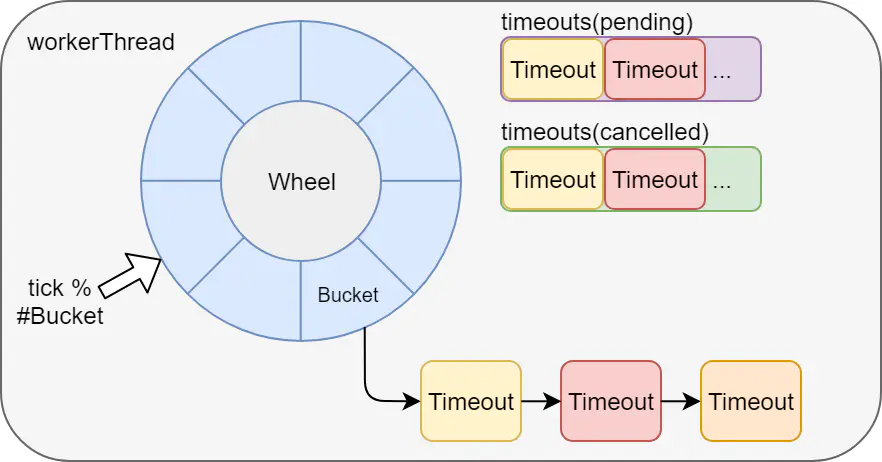
5. Roue du temps
L'exécution différée des tâches via la roue temporelle est également basée sur le fonctionnement autonome de jvm. Par exemple, kafka et netty implémentent tous deux des roues temporelles, et le chien de garde de redisson est également réalisé via la roue temporelle de netty.
Inconvénients : il ne convient pas à l'utilisation de services distribués et les tâches seront perdues après un temps d'arrêt.
3. Atteindre les objectifs
Compatible avec les composants d'événements asynchrones actuellement utilisés et fournit des composants de retard plus fiables, réessayables, enregistrés, de surveillance des alarmes et hautes performances.
• Fiabilité de la transmission des messages : après qu'un message est entré dans la file d'attente, il est garanti qu'il sera consommé au moins une fois.
•Le client prend en charge riche : prend en charge plusieurs langues.
• Haute disponibilité : prend en charge le déploiement multi-instance. Après la suspension d'une instance, une instance de secours continue à fournir des services.
•Temps réel : une certaine erreur de temps est autorisée.
• Prise en charge de la suppression des messages : les utilisateurs professionnels peuvent supprimer des messages spécifiés à tout moment.
• Prise en charge de la requête de consommation
• Prend en charge les nouvelles tentatives manuelles
• Augmenter la surveillance de l'exécution de l'événement asynchrone en cours
4. Conception architecturale
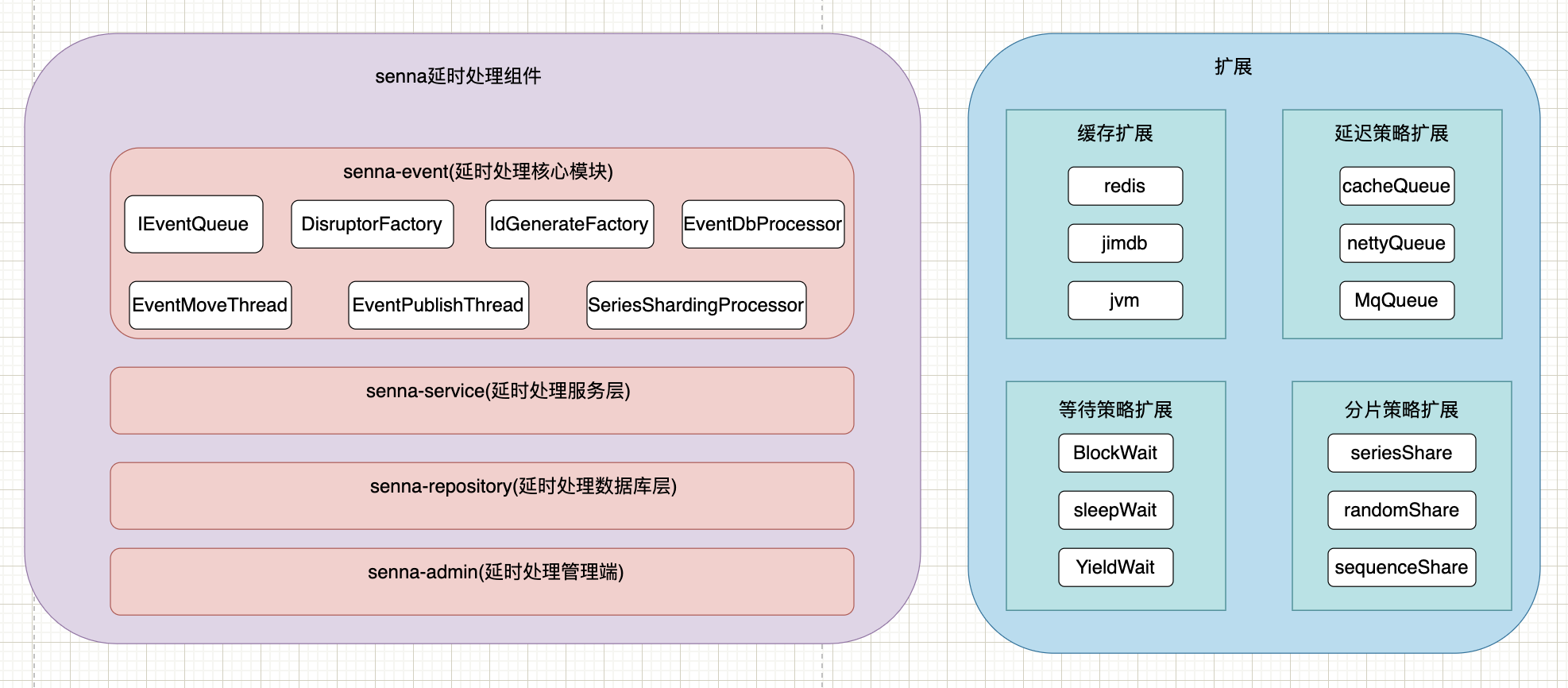
5. Retarder la mise en œuvre des composants
1. Principe de mise en œuvre
À l'heure actuelle, nous choisissons d'utiliser jimdb pour implémenter la fonction de retard via zset, et stockons l'identifiant de la tâche et le temps d'exécution correspondant en tant que score dans la file d'attente zset. Par défaut, ils seront triés par score, et chaque fois que nous prendrons l'identifiant de la tâche de 0-score dans l'heure actuelle,
Lors de l'envoi d'une tâche retardée, un identifiant unique sera généré en fonction de la séquence timestamp + machine ip + queueName +, et le corps du message sera construit, chiffré et placé dans la file d'attente zset.
En déplaçant le thread, la tâche qui a atteint le temps d'exécution est déplacée vers la file d'attente de publication, en attendant que le consommateur l'obtienne.
La partie surveillance intègre ump
Les enregistrements de consommation sont complétés par la sauvegarde redis + la persistance de la base de données.
La méthode implémentée par la mise en cache n'est qu'un type d'implémentation, laquelle méthode d'implémentation peut être contrôlée via des paramètres et peut être librement étendue via spi.
2. Structure des messages
Chaque Job doit contenir les attributs suivants :
• Sujet : type de travail, c'est-à-dire QueueName
•Id : l'identifiant unique du Job. Utilisé pour récupérer et supprimer les informations de tâche spécifiées.
•Délai : le travail doit retarder l'heure. Unité : secondes. (Le serveur le convertira en temps absolu)
• Corps : le contenu de la tâche, qui est stocké au format json pour permettre aux consommateurs d'effectuer un traitement métier spécifique.
• traceId : le traceId du thread d'envoi, une fois que le pfinder suivant prend en charge la définition de traceId, il peut partager le même traceid avec le thread d'envoi, ce qui est pratique pour le suivi des journaux
La structure spécifique est illustrée dans la figure ci-dessous :

Le TTR est conçu pour assurer la fiabilité de la transmission des messages.
3. Flux de données et organigramme

Publiez et consommez en fonction de la méthode redis-disruptor, qui peut être utilisée comme un message. Les consommateurs utilisent la file d'attente sans verrouillage du perturbateur d'événement asynchrone d'origine pour la consommation, et il n'y a pas de verrouillage entre les différentes applications et les différentes files d'attente
1. Prend en charge l'application pour publier uniquement, ne pas consommer et réaliser la fonction de file d'attente de messages.
2 : prise en charge du regroupement. Pour le problème des clés volumineuses, s'il y a de nombreux événements, vous pouvez définir le nombre de files d'attente de retard et de seaux de file d'attente de tâches pour réduire le problème de blocage redis causé par les clés volumineuses.
3 : Grâce à la configuration ducc, les performances sont étendues. Actuellement, seule la consommation est activée et la consommation est désactivée.
4 : Prise en charge de la configuration du délai d'expiration pour empêcher les threads consommateurs de s'exécuter trop longtemps
Goulot d'étranglement : la vitesse de consommation est lente et la vitesse de production est trop rapide, ce qui entraînera le remplissage de la file d'attente de la mémoire tampon. Lorsque l'application actuelle est à la fois un producteur et un consommateur, le producteur se met en veille et les performances dépendent de la vitesse de consommation La machine peut être agrandie horizontalement pour améliorer directement les performances. Surveillez la longueur de la file d'attente Redis. Si elle continue de croître, envisagez d'ajouter des consommateurs pour améliorer directement les performances.
Situation possible : étant donné qu'une application partage un disrupteur et possède 64 threads consommateurs, si la consommation d'un certain événement est trop lente, les 64 threads consomment cet événement, ce qui entraînera la consommation d'autres événements par aucun thread consommateur, et le producteur thread consommera également est bloqué, entraînant le blocage de la consommation de tous les événements.
Pour observer ultérieurement s'il existe un tel goulot d'étranglement des performances, vous pouvez attribuer à chaque file d'attente un pool de threads consommateur.
6. exemple de démonstration
Ajouter un fichier de configuration
Déterminez s'il faut activer jd.event.enable:true
<dependency> <groupId>com.jd.car</groupId>
<artifactId>senna-event</artifactId>
<version>1.0-SNAPSHOT</version> </dependency>
configuration
jd:
senna:
event:
enable: true
queue:
retryEventQueue:
bucketNum: 1
handleBean: retryHandle
Code consommation :
package com.jd.car.senna.admin.event;
import com.jd.car.senna.event.EventHandler;
import com.jd.car.senna.event.annotation.SennaEvent;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
/**
* @author zhangluyao
* @description
* @create 2022-02-21-9:54 下午
*/
@Slf4j
@Component("retryHandle")
public class RetryQueueEvent extends EventHandler {
@Override
protected void onHandle(String key, String eventType) {
log.info("Handler开始消费:{}", key);
}
@Override
protected void onDelayHandle(String key, String eventType) {
log.info("delayHandler开始消费:{}", key);
}
}
Formulaire d'annotation :
package com.jd.car.senna.admin.event;
import com.jd.car.senna.event.EventHandler;
import com.jd.car.senna.event.annotation.SennaEvent;
import lombok.extern.slf4j.Slf4j;
/**
* @author zhangluyao
* @description
* @create 2022-02-21-9:54 下午
*/
@Slf4j
@SennaEvent(queueName = "testQueue", bucketNum = 5,delayBucketNum = 5,delayEnable = true)
public class TestQueueEvent extends EventHandler {
@Override
protected void onHandle(String key, String eventType) {
log.info("Handler开始消费:{}", key);
}
@Override
protected void onDelayHandle(String key, String eventType) {
log.info("delayHandler开始消费:{}", key);
}
}
envoyer le code
package com.jd.car.senna.admin.controller;
import com.jd.car.senna.event.queue.IEventQueue;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Lazy;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.util.concurrent.CompletableFuture;
/**
* @author zly
*/
@RestController
@Slf4j
public class DemoController {
@Lazy
@Resource(name = "testQueue")
private IEventQueue eventQueue;
@ResponseBody
@GetMapping("/api/v1/demo")
public String demo() {
log.info("发送无延迟消息");
eventQueue.push("no delay 5000 millseconds message 3");
return "ok";
}
@ResponseBody
@GetMapping("/api/v1/demo1")
public String demo1() {
log.info("发送延迟5秒消息");
eventQueue.push(" delay 5000 millseconds message,name",1000*5L);
return "ok";
}
@ResponseBody
@GetMapping("/api/v1/demo2")
public String demo2() {
log.info("发送延迟到2022-04-02 00:00:00执行的消息");
eventQueue.push(" delay message,name to 2022-04-02 00:00:00", new Date(1648828800000));
return "ok";
}
}
Reportez-vous à la conception de Youzan : https://tech.youzan.com/queuing_delay/
7. Candidature en cours :
1. Yunxiu annulera automatiquement après 24 heures de file d'attente au magasin
2. Meituan demande un rafraîchissement régulier du jeton.
3. La carte de garantie sera générée dans les 24 heures
5. Report de la génération des relevés
6. Envoi de SMS retardé