guide
Cet article est compilé à partir du partage de sujet du même nom sur le thème de l'infrastructure d'IA lors de la QCon Global Software Development Conference (Beijing Station) en février 2023. Les applications telles que ChatGPT, Bard et le "Wen Xin Yi Yan" qui vous rencontreront sont toutes basées sur les grands modèles lancés par chaque constructeur. GPT-3 a 175 milliards de paramètres et le grand modèle Wenxin a 260 milliards de paramètres. Prenant l'utilisation du GPU NVIDIA A100 pour former GPT-3 comme exemple, théoriquement, il faut 32 ans pour une seule carte, et un cluster distribué avec une échelle de kilocalories, après diverses optimisations, a encore besoin de 34 jours pour terminer la formation. Ce discours a présenté les défis de la formation de modèles à grande échelle à l'infrastructure, tels que les murs de puissance de calcul, les murs de stockage, la conception de réseaux hautes performances à une seule machine et en cluster, l'accès aux graphes et l'accélération back-end, le fractionnement et la cartographie des modèles, etc., Baidu partagé La méthode de réponse et la pratique d'ingénierie du cloud intelligent ont construit une infrastructure complète du cadre au cluster, combinant logiciel et matériel, et accéléré la formation de bout en bout de grands modèles.
Au cours des deux dernières années, le grand modèle a eu le plus grand impact sur l'architecture technologique de l'IA. Dans le processus de génération, d'itération et d'évolution de modèles à grande échelle, cela pose de nouveaux défis à l'infrastructure sous-jacente.
Le partage d'aujourd'hui est principalement divisé en quatre parties.La première partie consiste à présenter les principaux changements apportés par le grand modèle d'un point de vue commercial. La deuxième partie porte sur les défis que la formation de grands modèles pose à l'infrastructure à l'ère des grands modèles et sur la réponse de Baidu Smart Cloud. La troisième partie consiste à combiner les besoins des modèles à grande échelle et de la construction de plates-formes, et à expliquer l'optimisation conjointe des logiciels et du matériel réalisée par Baidu Smart Cloud. La quatrième partie présente les réflexions de Baidu Smart Cloud sur le développement futur de grands modèles et les nouvelles exigences en matière d'infrastructure.

1. GPT-3 ouvre l'ère des grands modèles
L'ère des grands modèles a été ouverte par GPT-3, qui présente les caractéristiques suivantes :
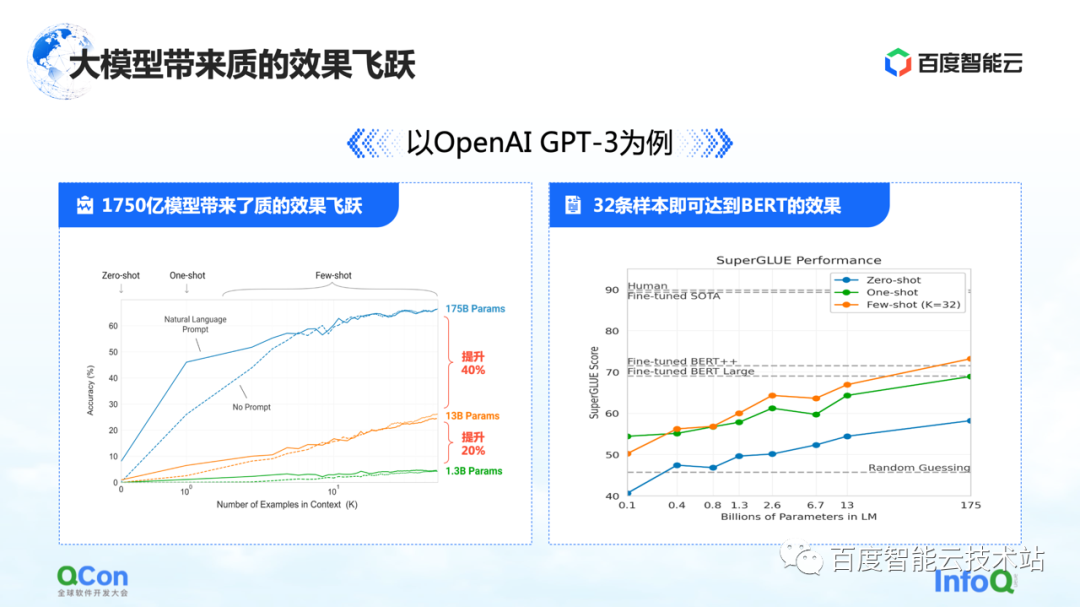
La première caractéristique est que les paramètres du modèle ont été grandement améliorés : un seul modèle a atteint 175 milliards de paramètres, ce qui a également entraîné une augmentation significative de la précision. D'après la figure de gauche, nous pouvons voir qu'avec de plus en plus de paramètres de modèle, la précision du modèle s'améliore également.
L'image de droite montre ses caractéristiques les plus choquantes : sur la base du modèle de 175 milliards de paramètres pré-entraîné, il n'a besoin d'être entraîné qu'avec un petit nombre d'échantillons, et il peut s'approcher de l'effet du BERT après avoir utilisé un entraînement sur un grand échantillon. Cela reflète dans une certaine mesure que l'échelle du modèle devient plus grande, ce qui peut entraîner des améliorations dans les performances du modèle et la polyvalence du modèle.
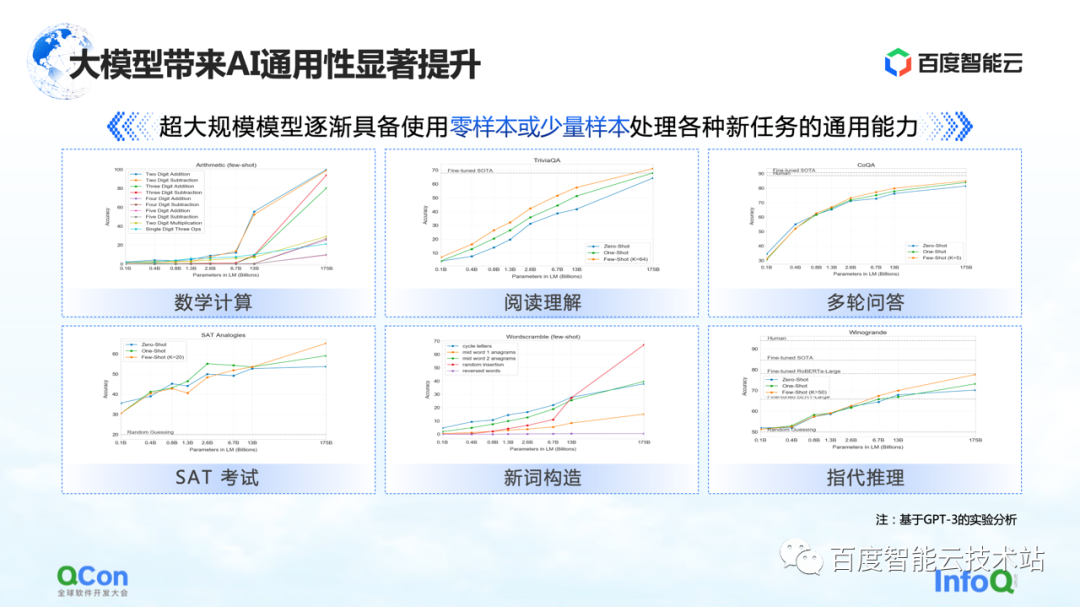
En outre, GPT-3 montre également un certain degré de polyvalence dans des tâches telles que les calculs mathématiques, la compréhension de la lecture et plusieurs séries de questions et réponses Seul un petit nombre d'échantillons peut permettre au modèle d'atteindre une précision plus élevée, même proche de la précision humaine Dépensez.
Pour cette raison, le grand modèle a également apporté de nouveaux changements au modèle global de recherche et de développement de l'IA. À l'avenir, nous pourrions d'abord pré-entraîner un grand modèle, puis effectuer un réglage fin avec un petit nombre d'échantillons pour des tâches spécifiques afin d'obtenir de bons résultats d'entraînement. Au lieu de former le modèle comme maintenant, chaque tâche doit être complètement itérée et formée à partir de zéro.
Baidu a commencé très tôt à former de grands modèles, et le grand modèle Wenxin avec 260 milliards de paramètres a été publié en 2021. Maintenant avec Stable Diffusion, AIGC Vincent graph, et le robot de chat récemment populaire ChatGPT, etc., qui ont attiré l'attention de toute la société, tout le monde se rend vraiment compte que l'ère des grands modèles est arrivée.
Les fabricants proposent également des produits liés aux grands modèles. Google vient de sortir Bard auparavant, et Baidu lancera bientôt "Wen Xin Yi Yan" en mars.
Quelles sont les différentes caractéristiques de la formation des grands modèles ?
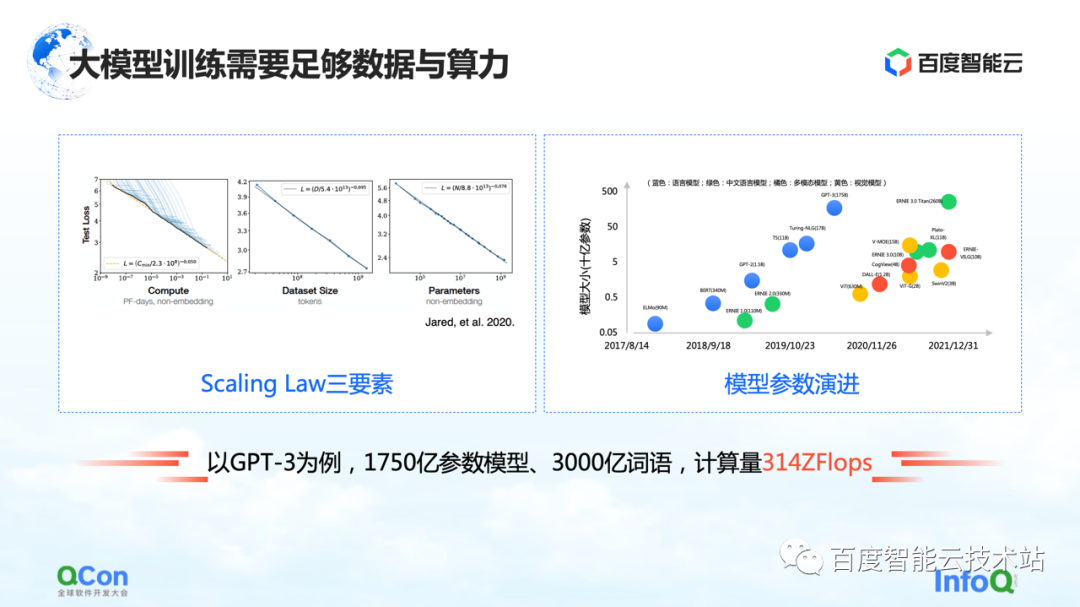
Le grand modèle a une loi d'échelle, comme le montre la figure de gauche, à mesure que l'échelle des paramètres du modèle et les données d'entraînement augmentent, l'effet deviendra de mieux en mieux.
Mais il y a une prémisse ici, les paramètres doivent être suffisamment grands et l'ensemble de données est suffisant pour prendre en charge la formation de l'ensemble du paramètre. La conséquence en est que la quantité de calculs augmente de façon exponentielle. Pour un petit modèle ordinaire, une seule machine et une seule carte peuvent être réalisées. Mais pour un grand modèle, ses exigences en matière de volume de formation nécessitent des ressources à grande échelle pour soutenir sa formation.
En prenant GPT-3 comme exemple, il s'agit d'un modèle avec 175 milliards de paramètres et nécessite 300 milliards de mots de formation pour le soutenir afin d'obtenir un bon effet. Son calcul est estimé à 314 ZFLOP dans l'article. Par rapport au NVIDIA GPU A100, une carte n'a encore que 312 TFLOPS de puissance de calcul AI, et la valeur absolue au milieu est différente de 9 ordres de grandeur.
Par conséquent, afin de mieux prendre en charge le calcul, la formation et l'évolution des grands modèles, la conception et le développement des infrastructures sont devenus un enjeu très important.
2. Panorama des infrastructures modèles à grande échelle
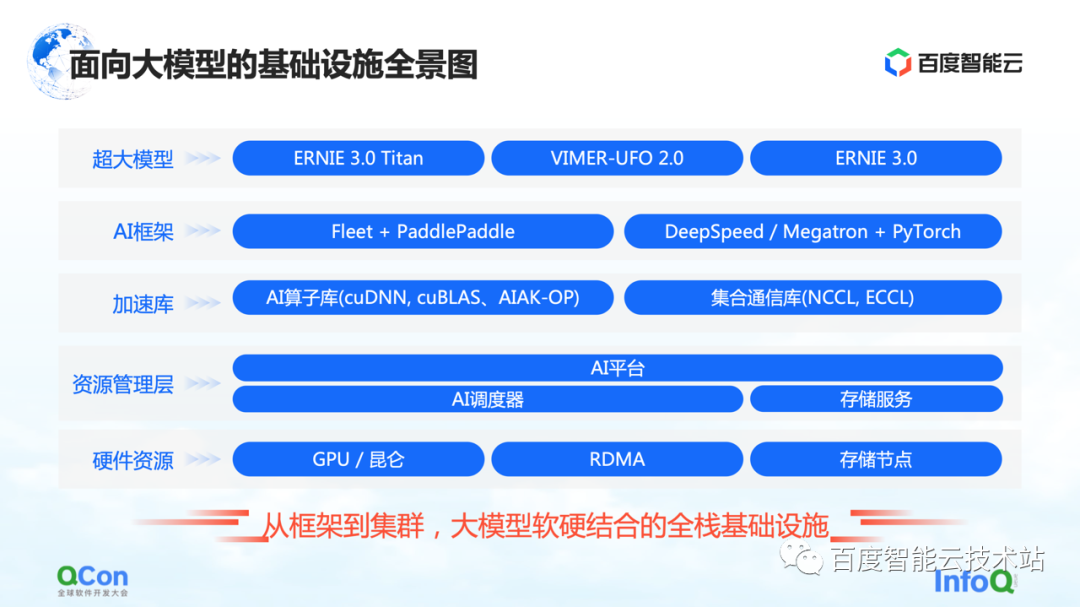
Ceci est un panorama de l'infrastructure de Baidu Smart Cloud pour les grands modèles. Il s'agit d'une infrastructure complète couvrant du framework au cluster, combinant matériel et logiciel.
Dans le grand modèle, l'infrastructure ne couvre plus uniquement l'infrastructure traditionnelle telle que le matériel et les réseaux sous-jacents. Nous devons également intégrer toutes les ressources pertinentes dans la catégorie des infrastructures.
Plus précisément, il est grossièrement divisé en plusieurs niveaux :
-
La couche supérieure est la couche de modèle, y compris les modèles publiés internes et externes et certains composants de support. Par exemple, la pagaie volante de Baidu PaddlePaddle et Fleet, Fleet est une stratégie distribuée sur la pagaie volante . Dans le même temps, dans la communauté open source, telle que PyTorch, il existe des cadres de formation de modèles à grande échelle et des capacités d'accélération basées sur le cadre PyTorch, tels que DeepSpeed/Megatron.
-
Dans ce cadre, nous développerons également les fonctionnalités associées de la bibliothèque d'accélération, y compris l'accélération de l'opérateur IA, l'accélération de la communication, etc.
-
Voici quelques fonctionnalités associées de la gestion partielle des ressources ou de la gestion partielle des clusters.
-
En bas se trouvent les ressources matérielles, telles que la carte unique autonome, les puces hétérogènes et les capacités liées au réseau.
Ce qui précède est un panorama de l'ensemble de l'infrastructure. Aujourd'hui, je vais me concentrer sur le démarrage du cadre d'IA, puis sur la couche d'accélération et la couche matérielle pour partager certains travaux spécifiques de Baidu Smart Cloud.
Commencez d'abord par le meilleur cadre d'IA.
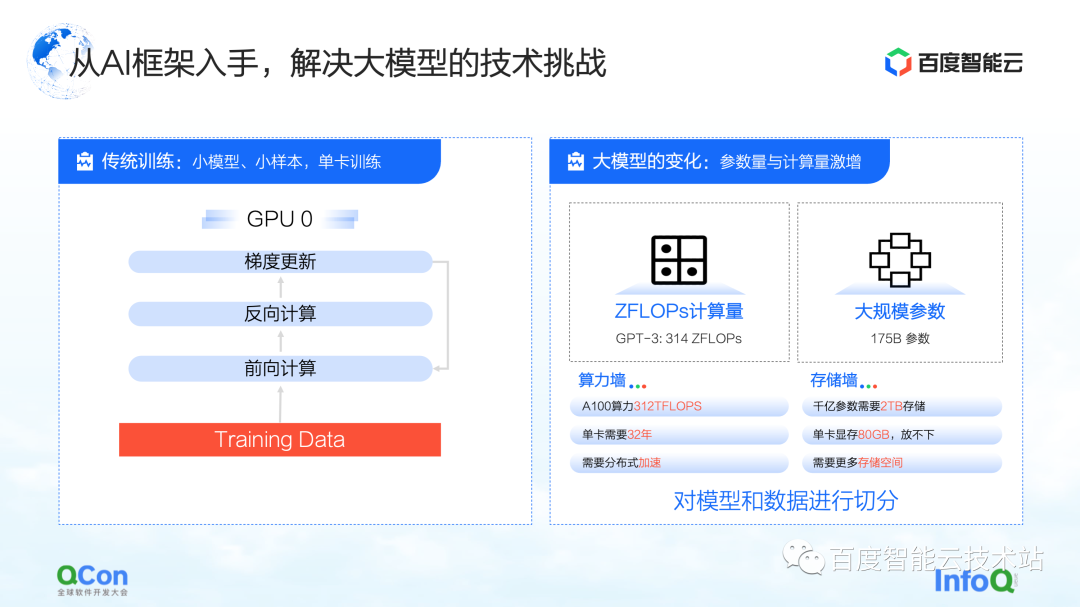
Pour la formation traditionnelle de petits modèles sur une seule carte, nous pouvons compléter la totalité de la formation en utilisant les données de formation pour mettre à jour en continu les gradients avant et arrière. Pour l'entraînement de grands modèles, il existe deux défis principaux : le mur de puissance de calcul et le mur de stockage.
Le mur de puissance de calcul fait référence à la façon dont nous pouvons utiliser des méthodes distribuées pour résoudre le problème du temps trop long pour une puissance de calcul unique si nous voulons terminer la formation du modèle de GPT-3, qui nécessite une puissance de calcul de 314 ZFLOP, mais la carte unique n'a que Puissance de calcul de 312 TFLOPS. . Après tout, il faut 32 ans pour former un modèle avec une seule carte, ce qui n'est évidemment pas faisable.
Vient ensuite le mur de rangement. C'est un plus grand défi pour les modèles plus grands. Lorsqu'une seule carte ne peut pas contenir le modèle, le modèle doit avoir une méthode de segmentation.
Par exemple, le stockage d'un grand modèle de 100 milliards de niveaux (y compris les paramètres, les valeurs intermédiaires d'apprentissage, etc.) nécessite 2 To d'espace de stockage, alors que la mémoire vidéo maximale d'une seule carte n'est actuellement que de 80 Go. Par conséquent, la formation de grands modèles nécessite certaines stratégies de segmentation pour résoudre le problème qu'une seule carte ne peut pas contenir.
Le premier est le mur de puissance de calcul, qui résout le problème de puissance de calcul insuffisante d'une seule carte.
Une idée très simple et la plus familière est le parallélisme des données, qui découpe les échantillons d'apprentissage sur différentes cartes. Dans l'ensemble, le grand processus de formation de modèles que nous observons maintenant adopte principalement une stratégie de mise à jour synchrone des données.

L'accent est mis sur la solution au problème du mur de stockage. La clé est la stratégie et la méthode de segmentation du modèle.
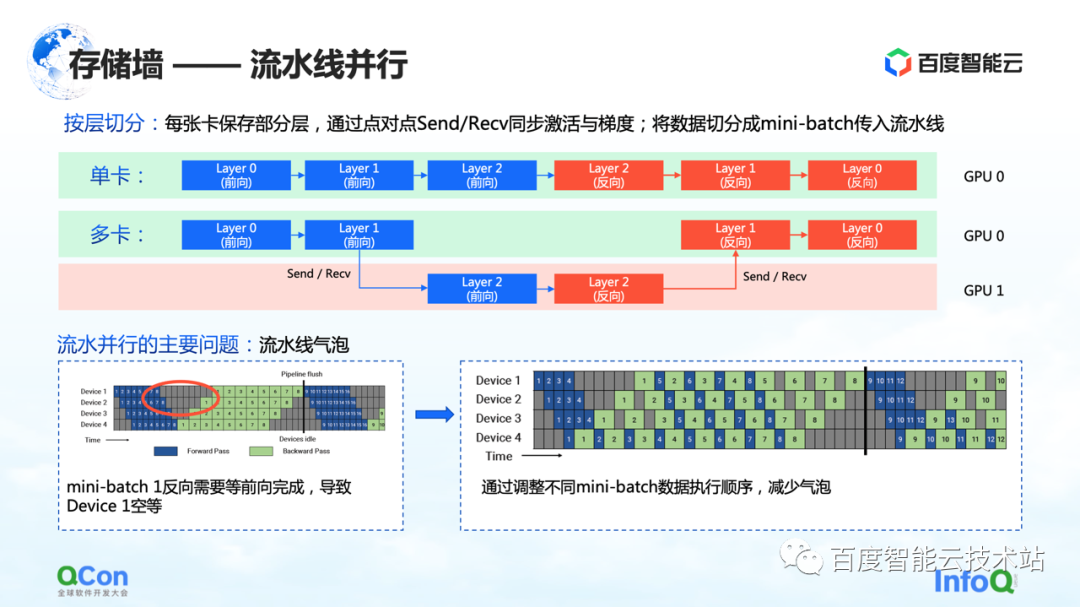
La première méthode de découpage est le parallélisme pipeline.
Utilisons l'exemple de la figure ci-dessous pour illustrer. Pour un modèle, il est composé de plusieurs couches.Lors de l'entraînement, effectuez d'abord la marche avant, puis la marche arrière. Par exemple, les trois calques 0, 1 et 2 de l'image ne peuvent pas tenir sur une seule carte. Après avoir divisé par calque, nous mettrons quelques calques de ce modèle sur la première carte. Par exemple, dans la figure ci-dessous, la zone verte représente le GPU 0 et la zone rouge représente le GPU 1. Nous pouvons mettre les premières couches sur le GPU 0 et les autres couches sur le GPU 1. Lorsque les données circulent, il effectuera d'abord deux transferts vers le GPU 0, puis un transfert vers l'avant et un retour sur le GPU 1, puis reviendra au GPU 0 pour effectuer deux retours. Étant donné que ce processus ressemble particulièrement à un pipeline, nous l'appelons parallélisme de pipeline.
Mais il y a un problème majeur avec le parallélisme des pipelines, à savoir les bulles de pipeline. Parce qu'il y aura des dépendances entre les données et que le gradient dépend du calcul de la couche précédente, donc dans le processus de flux de données, des bulles seront générées, ce qui provoquera un vide. En réponse à de tels problèmes, nous réduisons le temps vide des bulles en ajustant les stratégies d'exécution des différents mini-batchs.
Ce qui précède est la perspective d'un ingénieur en algorithme ou d'un ingénieur en framework pour examiner ce problème. Du point de vue des ingénieurs en infrastructure, nous sommes plus préoccupés par les différents changements que cela apportera à l'infrastructure.
Nous nous concentrons ici sur sa sémantique de communication. Il se situe entre l'avant et l'arrière, et il doit transmettre sa propre valeur d'activation et sa propre valeur de gradient, ce qui entraînera des opérations d'envoi/réception supplémentaires. Et Send/Receive est point à point, nous mentionnerons la solution plus loin dans l'article.
Ce qui précède est la première stratégie de segmentation de modèles parallèles qui brise le mur de stockage : le parallélisme de pipeline.
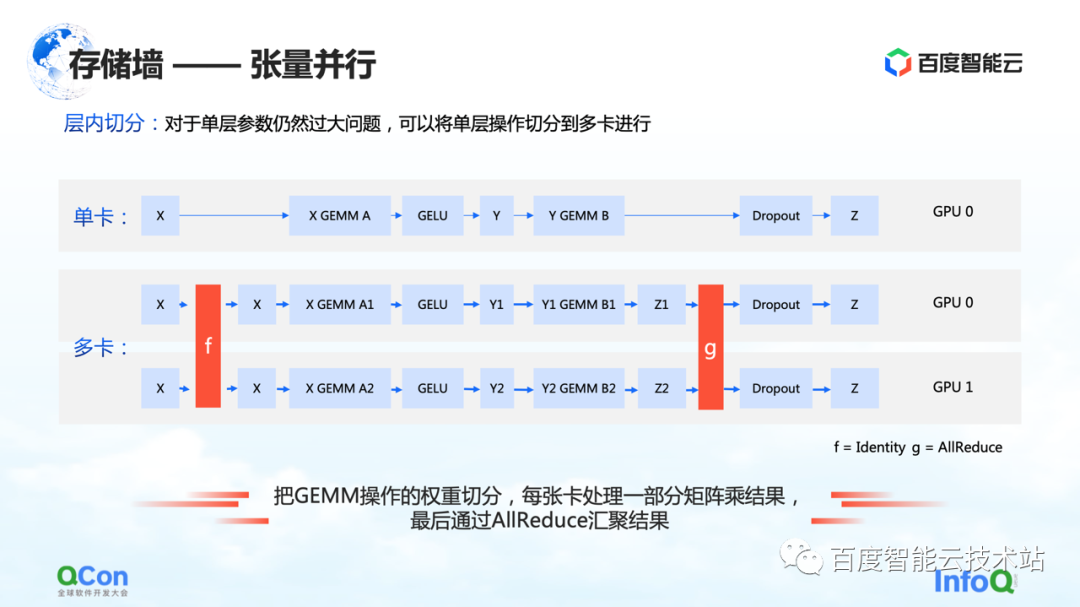
La deuxième méthode de segmentation est le parallélisme tenseur , qui résout le problème des paramètres monocouche trop grands.
Bien que le modèle comporte de nombreuses couches, l'une d'entre elles nécessite beaucoup de calculs. À l'heure actuelle, nous nous attendons à ce que le montant de calcul de cette couche soit calculé conjointement entre les machines ou entre les cartes. Du point de vue d'un ingénieur en algorithmes, la solution consiste à diviser différentes entrées en plusieurs morceaux, puis à utiliser différents morceaux pour effectuer des calculs partiels, et enfin à effectuer une agrégation.
Mais du point de vue des ingénieurs en infrastructure, nous prêtons toujours attention aux opérations supplémentaires introduites dans ce processus. Dans le scénario que nous venons de mentionner, les opérations supplémentaires sont f et g dans le graphe. Que signifient f et g ? Lors de l'exécution en avant, f est une opération invariante, et x est transmis de manière transparente à travers f, et certains calculs peuvent être effectués ultérieurement. Cependant, lorsque les résultats sont agrégés à la fin, la valeur entière doit être transmise. Pour ce cas, il faut introduire l'opération de g. g est l'opération de AllReduce, qui agrège sémantiquement deux valeurs différentes pour s'assurer que la sortie z peut obtenir les mêmes données sur les deux cartes.
Ainsi, du point de vue des ingénieurs en infrastructure, vous verrez qu'il introduit des opérations de communication AllReduce supplémentaires. Le trafic de communication de cette opération est encore relativement important, car les paramètres qu'il contient sont relativement importants. Nous mentionnerons également la méthode de coping plus loin dans l'article
C'est la deuxième méthode d'optimisation qui peut briser les murs de stockage.
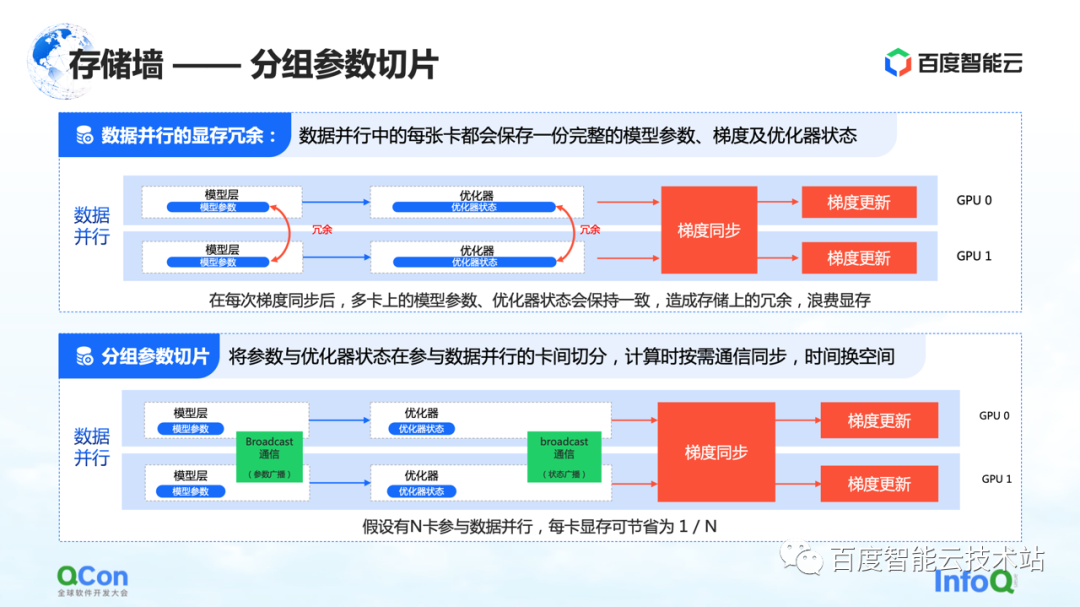
La troisième méthode de découpage est le découpage groupé des paramètres . Cette méthode réduit dans une certaine mesure la redondance de la mémoire dans le parallélisme des données. Dans les exécutions de données traditionnelles, chaque carte aura ses propres paramètres de modèle et état de l'optimiseur. Puisqu'ils doivent être synchronisés et mis à jour au cours de leurs processus d'apprentissage respectifs, ces états sont entièrement sauvegardés sur différentes cartes,
Pour le processus ci-dessus, en effet, les mêmes données et paramètres sont stockés de manière redondante sur des cartes différentes. Un tel stockage redondant est inacceptable car les grands modèles ont des besoins en espace de stockage extrêmement élevés. Afin de résoudre ce problème, nous avons scindé les paramètres du modèle et ne conservons qu'une partie des paramètres sur chaque carte.
Lorsque des calculs sont vraiment nécessaires, nous échangeons du temps contre de l'espace : synchronisez d'abord les paramètres, puis supprimez les données redondantes une fois le calcul terminé. De cette façon, la demande de mémoire vidéo peut être davantage compressée et la formation peut être mieux effectuée sur les machines existantes.
De même, du point de vue des ingénieurs en infrastructure, nous devons introduire des opérations de communication telles que la diffusion, et le contenu de la communication est l'état de ces optimiseurs et les paramètres du modèle.
Ce qui précède est la troisième méthode d'optimisation pour briser le mur de stockage.
En plus des méthodes et stratégies d'optimisation de la mémoire mentionnées ci-dessus, il existe un autre moyen de réduire la quantité de calcul du modèle.
Lorsque la quantité de données est suffisamment importante, plus il y a de paramètres dans le modèle, meilleure est la précision du modèle. Cependant, avec l'augmentation des paramètres, la quantité de calcul augmente également, nécessitant plus de ressources, et en même temps, le temps de calcul sera plus long.
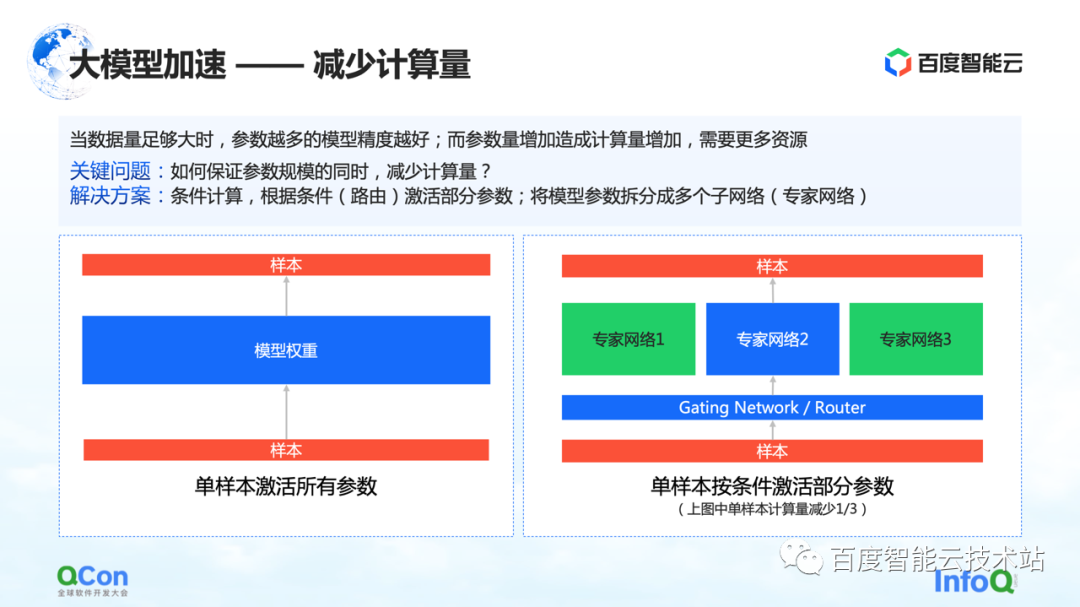
Alors, comment s'assurer que la quantité de calcul est réduite alors que l'échelle des paramètres reste inchangée ? L'une des solutions est le calcul conditionnel : selon certaines conditions (c'est-à-dire la couche Gating sur la figure de droite, ou appelée couche de routage), sélectionner et activer certains des paramètres.
Par exemple, dans la figure de droite, on divise les paramètres en trois parties, et selon les conditions du modèle, seule une partie des paramètres est activée pour le calcul dans le réseau expert 2. Certains paramètres de l'expert 1 et de l'expert 3 ne sont pas calculés. De cette manière, la quantité de calcul peut être réduite tout en garantissant l'échelle des paramètres.
Ce qui précède est une méthode basée sur le calcul conditionnel pour réduire la quantité de calcul.
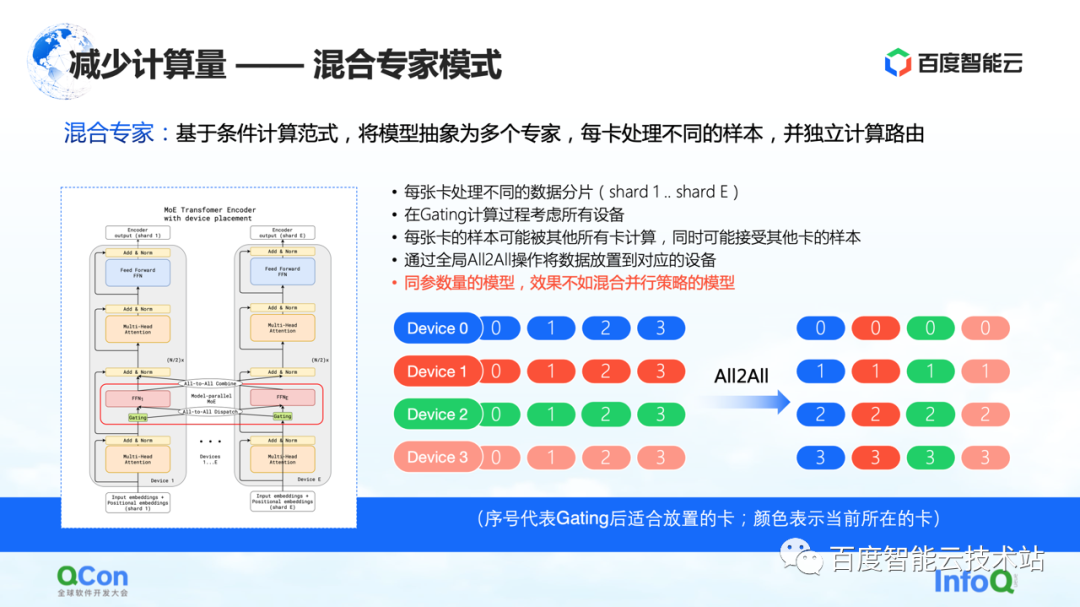
Sur la base de la méthode ci-dessus, l'industrie a proposé un modèle d'experts mixtes , qui consiste à résumer le modèle en plusieurs experts, et chaque carte traite différents échantillons. En effet, certains choix de routage sont insérés dans la couche modèle, puis seuls certains paramètres sont activés en fonction de ce choix. Dans le même temps, les paramètres des différents experts seront conservés sur différentes cartes. De cette façon, dans le processus de distribution des échantillons, ils seront attribués à différentes cartes pour le calcul.
Mais du point de vue d'un ingénieur en infrastructure, nous avons constaté que l'opération All2All a été introduite dans ce processus. Comme le montre la figure de droite ci-dessous, les échantillons tels que 0, 1, 2 et 3 sont stockés sur plusieurs appareils. La valeur dans Appareil indique quelle carte convient pour le calcul, ou quel expert il convient pour le calcul. Par exemple, 0 signifie qu'il convient d'être calculé par l'expert n° 0, c'est-à-dire la carte n° 0, et ainsi de suite. Chaque carte déterminera qui convient pour les données stockées à calculer.Par exemple, la carte n° 1 juge que certains paramètres sont adaptés au calcul par la carte n° 0, et d'autres paramètres sont adaptés au calcul par la carte n° 1. Ensuite, l'action suivante consiste à répartir les échantillons sur différentes cartes.
Après les opérations ci-dessus, les échantillons sur la carte n° 0 sont tous des 0 et les échantillons sur la carte n° 1 sont tous des 1. Le processus ci-dessus est appelé All2All en communication. Du point de vue des ingénieurs en infrastructure, cette opération est une opération relativement lourde, et nous devons faire quelques optimisations connexes sur cette base. Nous allons également introduire plus loin dans le texte suivant.
Dans ce mode, l'un des phénomènes que nous avons observé est que si le mode expert mixte est utilisé, sa précision d'apprentissage est moins bonne que les différentes stratégies parallèles et les stratégies hybrides de superposition évoquées tout à l'heure sous le modèle des mêmes paramètres. à la situation réelle.
Je viens de présenter plusieurs stratégies parallèles, puis je partagerai une pratique interne de Baidu Smart Cloud.
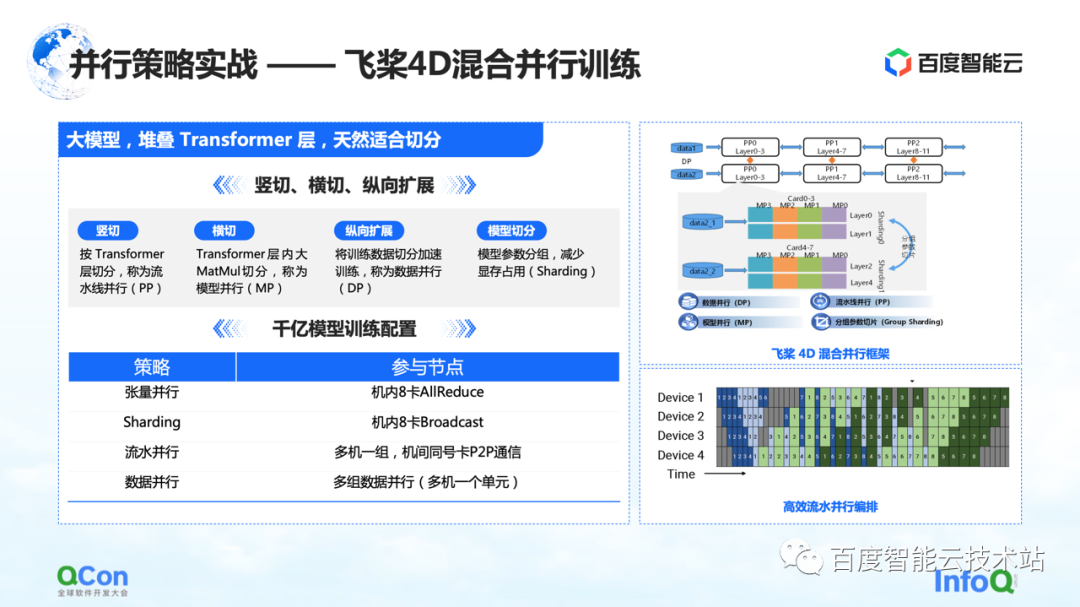
Nous avons formé un grand modèle avec 260 milliards de paramètres à l'aide de Paddle , en empilant certaines couches de classes Transformer optimisées. Nous pouvons le découper horizontalement et verticalement. Par exemple, découpez verticalement le modèle en fonction de la couche Transformer en utilisant la stratégie parallèle du pipeline. La coupe transversale consiste à utiliser la stratégie parallèle de modèle/stratégie parallèle de tenseur pour diviser le calcul de la multiplication de grandes matrices telles que MetaMul dans Transformer. Dans le même temps, nous l'avons complété par une optimisation verticale du parallélisme des données et une optimisation de la mémoire vidéo de la segmentation des paramètres du modèle de regroupement dans le parallélisme des données. À travers les quatre méthodes ci-dessus, nous avons introduit le cadre de l'entraînement parallèle hybride 4D des pagaies volantes .
Dans la configuration d'apprentissage du modèle à 100 milliards de paramètres, nous utilisons huit cartes dans la machine pour effectuer le parallélisme des tenseurs et, en même temps, nous coopérons avec le parallélisme des données pour effectuer certaines opérations de segmentation des paramètres de regroupement. Dans le même temps, plusieurs groupes de machines sont utilisés pour former un pipeline parallèle pour transporter 260 milliards de paramètres de modèle. Enfin, la méthode parallèle des données est utilisée pour le calcul distribué afin de compléter l'entraînement mensuel du modèle.
Ce qui précède est un combat réel de l'ensemble de notre modèle de stratégie parallèle de modèle de paramètres parallèles.
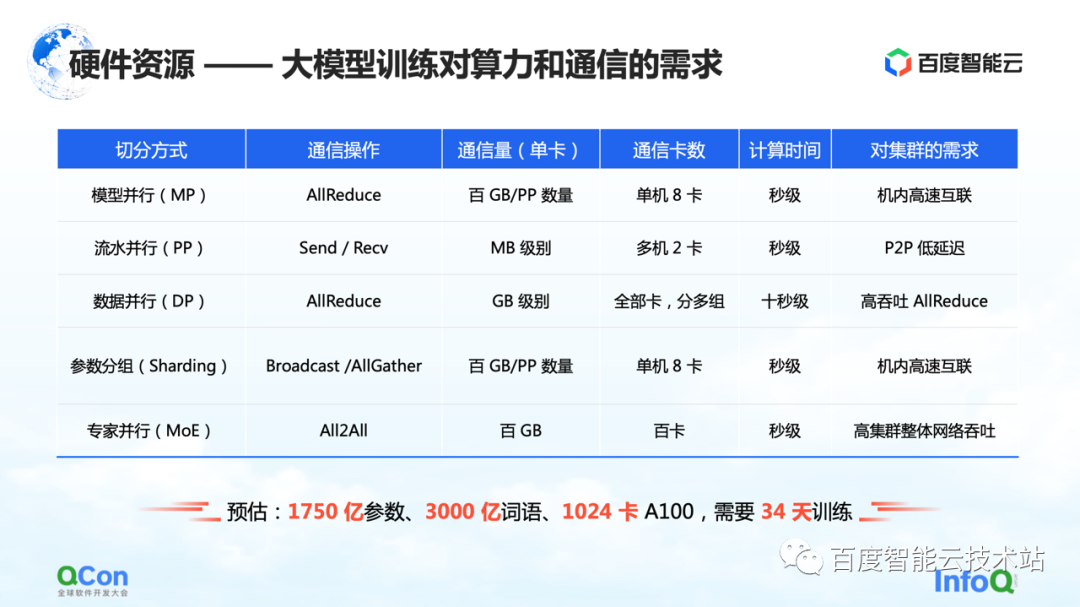
Revenons ensuite au point de vue de l'infrastructure pour évaluer les besoins en communication et en puissance de calcul des différentes stratégies de segmentation dans l'apprentissage des modèles.
Comme le montre le tableau, nous listons le trafic de communication et le temps de calcul requis pour différentes méthodes de segmentation selon l'échelle de 100 milliards de paramètres. Du point de vue de l'ensemble du processus de formation, le meilleur effet est que le processus de calcul et le processus de communication peuvent être complètement couverts ou se chevaucher.
De ce tableau, nous pouvons déduire les exigences du modèle à 100 milliards de paramètres pour les clusters, le matériel, les réseaux et les modes de communication globaux. Basé sur un modèle avec environ 175 milliards de paramètres formés sur 1024 cartes A100 utilisant 300 milliards de mots, il faut 34 jours pour terminer la formation complète de bout en bout.
Ce qui précède est notre évaluation du côté matériel.
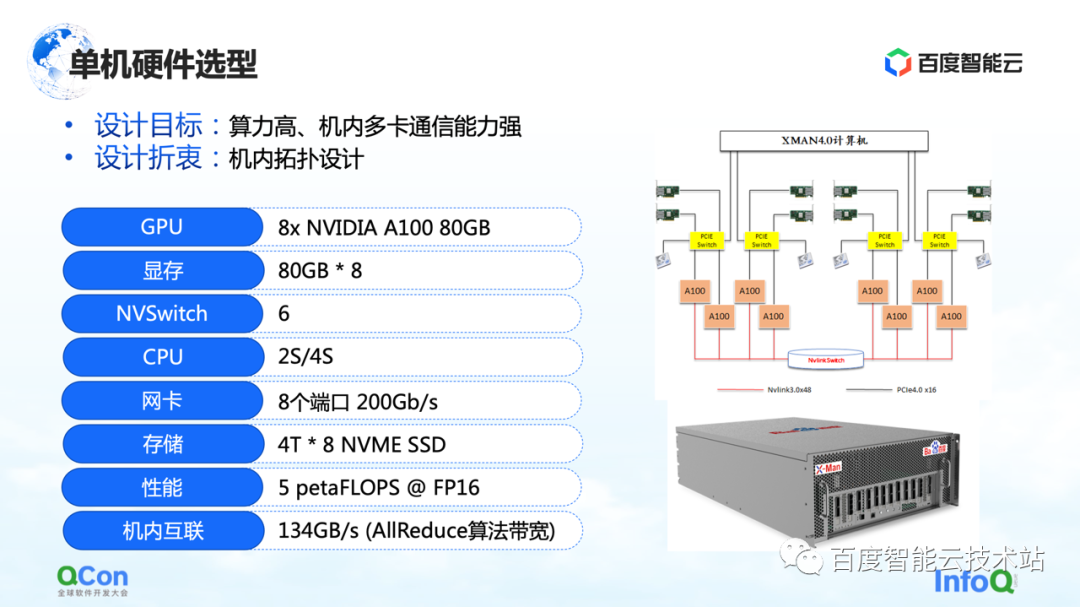
Avec les exigences matérielles, l'étape suivante est la sélection des niveaux autonome et réseau.
Au niveau autonome, étant donné qu'un grand nombre d'opérations AllReduce et Broadcast doivent être effectuées dans la machine, nous espérons que la machine pourra prendre en charge des connexions hautes performances et à large bande passante. Nous avons donc utilisé le package A100 80G le plus avancé dans la sélection de modèles à l'époque, en utilisant 8 A100 pour former une seule machine.
De plus, dans la méthode de connexion au réseau externe, la chose la plus importante est la méthode de connexion topologique. Nous espérons que la carte réseau et la carte GPU pourront être autant que possible sous le même commutateur PCIe, et que le goulot d'étranglement du débit de l'interaction entre les cartes pendant tout le processus de formation pourra être mieux réduit de manière symétrique. Dans le même temps, essayez d'éviter qu'ils ne passent par le port racine PCIe du processeur.
Après avoir parlé du stand-alone, intéressons-nous à la conception du réseau du cluster.
Tout d'abord, évaluons les exigences. Si notre entreprise s'attend à terminer la formation du modèle de bout en bout en un mois, nous devons atteindre le niveau de kilocalorie dans la formation à un seul emploi et le niveau de 10 000 calories dans le grand modèle. pôles de formation. Par conséquent, dans le processus de conception du réseau, nous devons prendre en compte deux points :
Tout d'abord, afin de répondre au fonctionnement point à point d'envoi/réception dans le pipeline, il est nécessaire de réduire le délai P2P.
Deuxièmement, étant donné que le trafic côté réseau dans la formation à l'IA est concentré sur l'opération AllReduce de la même carte, nous espérons également qu'elle a un débit de communication élevé.
pour ce besoin de communication. Nous avons conçu la topologie de l'architecture CLOS à trois niveaux illustrée à droite. Par rapport à la méthode traditionnelle, la chose la plus importante à propos de cette topologie est l'optimisation des huit rails de guidage, de sorte que le nombre de sauts dans la communication de toute carte avec le même numéro dans différentes machines soit aussi petit que possible.
Dans l'architecture CLOS, la couche inférieure est l'unité. Il y a 20 machines dans chaque unité, et nous connectons les cartes GPU du même numéro dans chaque machine au même groupe de TOR avec des numéros correspondants. De cette manière, toutes les cartes du même numéro dans une seule unité peuvent terminer la communication avec un seul saut, ce qui peut grandement améliorer la communication entre les cartes du même numéro.
Cependant, il n'y a que 20 machines avec un total de 160 cartes dans une unité, qui ne peuvent pas répondre aux exigences de la formation sur les grands modèles. Nous avons donc conçu la deuxième couche Feuille. La couche Leaf connecte des cartes avec le même numéro dans différentes unités aux dispositifs de commutation du même groupe de Leafs, ce qui résout toujours le problème de l'interconnexion des cartes avec le même numéro. Grâce à cette couche, nous pouvons à nouveau interconnecter 20 unités. Jusqu'à présent, nous avons pu connecter 400 machines avec un total de 3200 cartes. Pour un tel cluster de 3200 cartes, la communication entre deux cartes du même numéro peut être réalisée en sautant jusqu'à 3 sauts.
Et si nous voulons prendre en charge la communication de cartes avec des numéros différents ? Nous avons ajouté une couche Spine sur le dessus pour résoudre le problème de communication entre les cartes avec des numéros différents.
Grâce à cette architecture à trois couches, nous avons réalisé une architecture globale qui prend en charge 3200 cartes optimisées pour les opérations AllReduce. Si c'est sur l'équipement réseau d'IB, l'architecture peut prendre en charge l'échelle de 16 000 cartes, qui est également la plus grande échelle de mise en réseau de type boîtier IB à l'heure actuelle.
Nous avons comparé l'architecture CLOS avec d'autres architectures réseau, telles que Dragonfly, Torus, etc. Par rapport à eux, la bande passante réseau de cette architecture est plus suffisante et le nombre de sauts entre les nœuds est plus stable, ce qui est très utile pour estimer les performances d'entraînement prévisibles.
Ce qui précède est un ensemble d'idées de construction d'un réseau autonome à un réseau de clusters.

3. Optimisation conjointe de la combinaison de logiciels et de matériel
La formation de modèles à grande échelle ne signifie pas acheter le matériel et le mettre là pour compléter la formation. Nous avons également besoin d'une optimisation conjointe du matériel et des logiciels.
Parlons tout d'abord de l'optimisation des calculs. La formation de grands modèles est toujours un processus intensif en calcul dans son ensemble. En termes d'optimisation informatique, de nombreuses idées et idées actuelles sont basées sur l'accélération multi-backend des graphes statiques. Les graphiques construits par les utilisateurs, qu'il s'agisse de Paddle , PyTorch ou TensorFlow, convertiront d'abord les graphiques dynamiques en graphiques statiques via la capture de graphique, puis laisseront les graphiques statiques entrer dans le backend pour l'accélération.
La figure ci-dessous montre l'ensemble de notre architecture multi-backend basée sur des graphes statiques, qui est divisée en les parties suivantes**. **
Le premier est l'accès aux graphes, qui convertit les graphes dynamiques en graphes statiques.
La seconde est la méthode d'accès multi-backend, qui fournit des capacités d'optimisation basées sur le temps via différents backends.
Le troisième est l'optimisation des graphes. Nous avons effectué une optimisation des calculs et une conversion des graphes pour les graphes statiques, afin d'améliorer encore l'efficacité du calcul.
Enfin, nous utiliserons des opérateurs personnalisés pour accélérer le processus de formation du grand modèle dans son ensemble.
Présentons-les séparément ci-dessous.

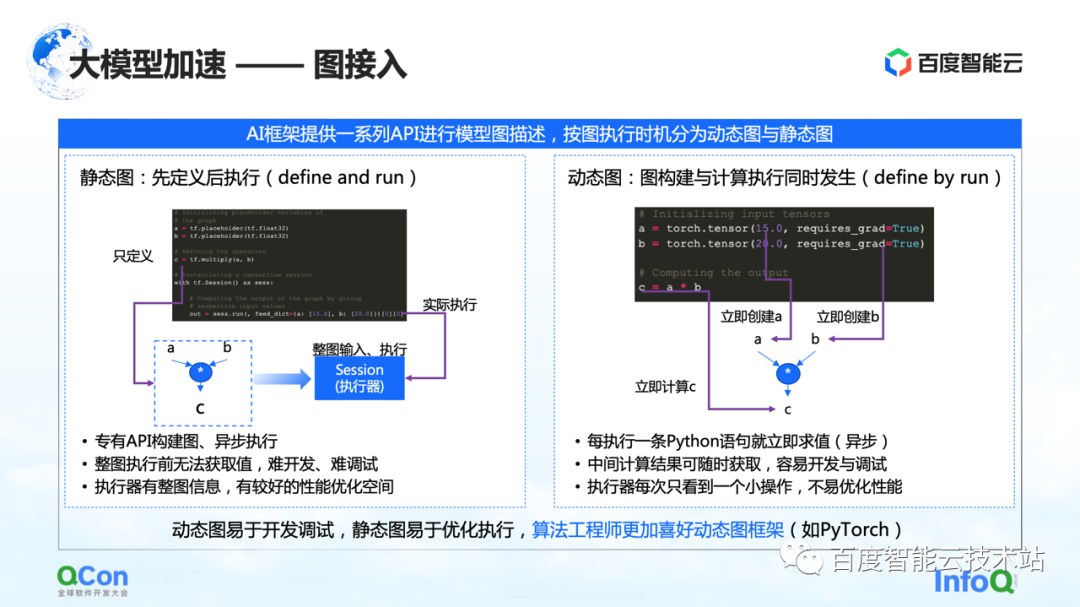
Dans l'architecture d'apprentissage des grands modèles, la première partie est l'accès aux graphes. Lors de la description des graphiques dans le cadre de l'IA, ils sont généralement divisés en graphiques statiques et en graphiques dynamiques.
Le graphe statique est que l'utilisateur construit le graphe avant de l'exécuter, puis l'exécute en combinaison avec son entrée réelle. Combinées à de telles caractéristiques, certaines optimisations de compilation ou d'ordonnancement peuvent être effectuées à l'avance pendant le processus de calcul, ce qui peut mieux améliorer les performances d'entraînement.
Mais lui correspond le processus de construction du graphe dynamique. L'utilisateur écrit du code avec désinvolture, et il est exécuté dynamiquement pendant le processus d'écriture. Par exemple, PyTorch, une fois que l'utilisateur a écrit une instruction, il effectuera l'exécution et l'évaluation associées. Pour les utilisateurs, l'avantage de cette approche est qu'elle est facile à développer et à déboguer. Mais pour l'exécuteur ou le processus d'accélération, parce qu'à chaque fois qu'on le voit c'est une petite partie de l'opération, ce n'est pas très bien optimisé.
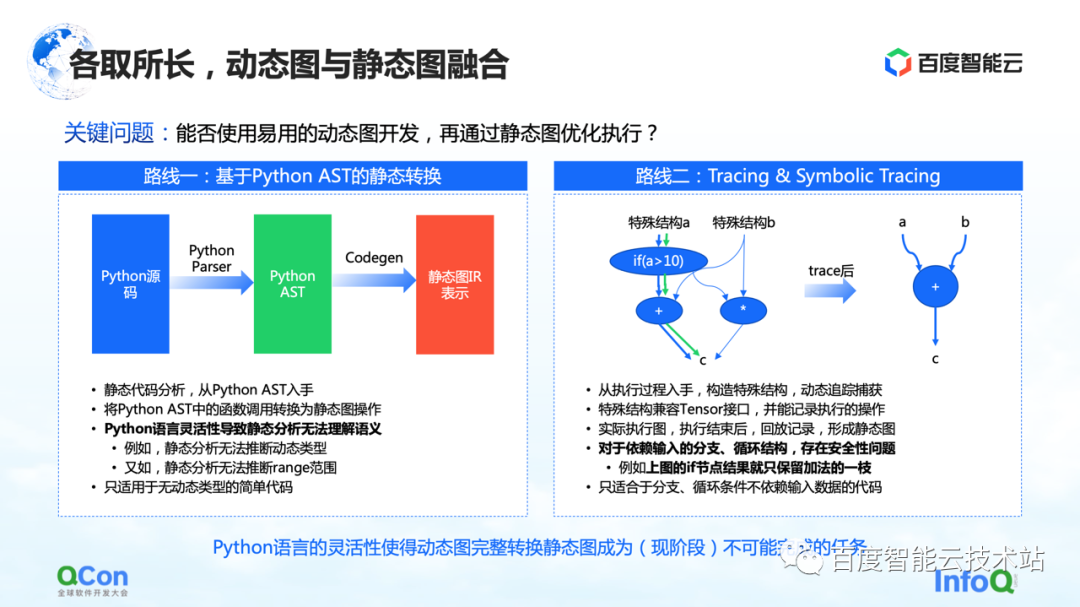
Afin de résoudre ce problème, l'idée générale est d'intégrer des graphes dynamiques et des graphes statiques, d'utiliser des graphes dynamiques pour le développement, puis d'exécuter via des graphes statiques. Il existe principalement deux voies de mise en œuvre que nous voyons maintenant.
La première consiste à effectuer une conversion statique basée sur Python AST. Par exemple, nous obtenons le code source Python écrit par l'utilisateur, le convertissons en un arbre Python AST, puis faisons CodeGen basé sur l'arbre AST. Dans ce processus, le code source dynamique de Python peut être converti en un graphe statique en utilisant la méthode et l'API du graphe de groupe statique.
Mais dans ce processus, le plus gros problème est la flexibilité du langage Python, qui conduit à l'incapacité de l'analyse statique à bien comprendre la sémantique, puis la conversion des images dynamiques en images statiques échoue. Par exemple, dans le processus d'analyse statique, il n'a aucun moyen de déduire le type dynamique, et par exemple, l'analyse statique ne peut pas déduire la plage de la plage, ce qui entraîne des échecs fréquents dans le processus de conversion réel. Ainsi, la conversion statique ne peut être appliquée qu'à certains scénarios de modèles simples.
La deuxième voie consiste à effectuer une exécution et une simulation simples au moyen du traçage ou du traçage symbolique. Tracer enregistre certains nœuds de calcul rencontrés lors du processus d'enregistrement, après avoir enregistré ces nœuds de calcul, il construit a posteriori un graphe statique complet par relecture ou réorganisation. L'avantage de cette méthode est qu'elle peut capturer et calculer le graphe dynamique global en simulant certaines méthodes d'entrée ou en construisant des méthodes de structure spéciales, puis peut capturer un chemin avec plus de succès.
Mais il y a en fait quelques problèmes dans ce processus. Pour les structures de branche ou de boucle qui dépendent de l'entrée, parce que Tracer construit des graphiques statiques en construisant des entrées simulées, Tracer n'ira qu'à certaines des branches, ce qui entraîne des problèmes de sécurité.
Après avoir comparé ces méthodes, nous avons constaté qu'avec la flexibilité du langage existant de Python, il est fondamentalement impossible de terminer la conversion de graphes dynamiques en graphes statiques à ce stade. Par conséquent, notre objectif s'est déplacé vers la manière de fournir aux utilisateurs des capacités de conversion d'images plus sécurisées et faciles à utiliser sur le cloud. A ce stade, il existe plusieurs options comme suit.
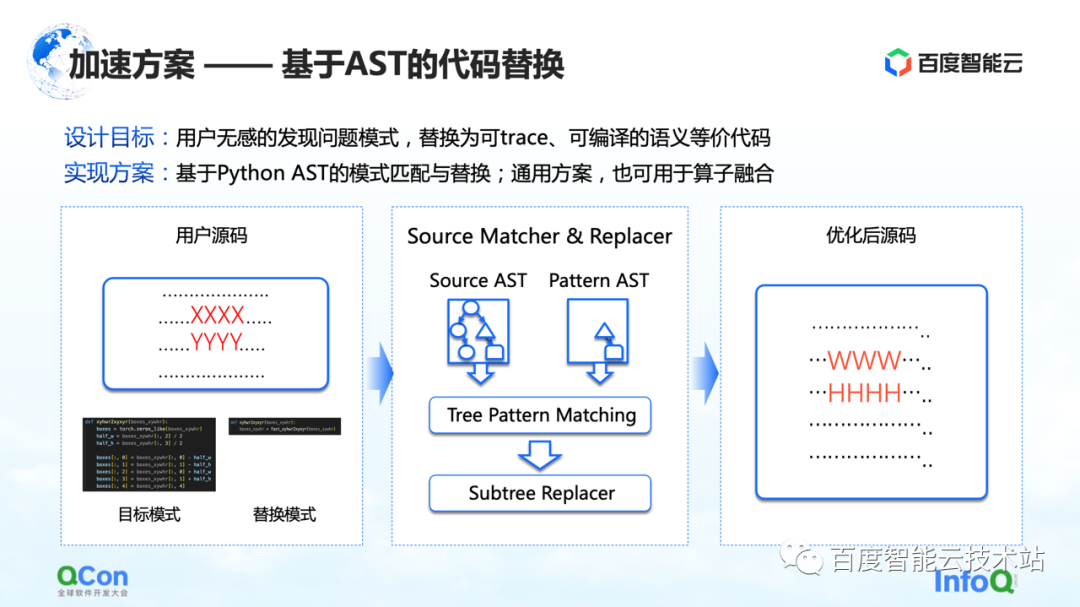
La première solution est de développer une méthode basée sur le remplacement de code AST. Dans cette méthode, Baidu Smart Cloud fournit les capacités de conversion et d'optimisation de modèle correspondantes, qui sont insensibles aux utilisateurs. Par exemple, l'utilisateur entre un morceau de code source, mais une partie du code (indiqué par XXXX et YYYY dans la figure) est en cours de capture d'image statique, d'optimisation de graphique et d'optimisation d'opérateur. le code ne peut pas convertir le graphique dynamique en graphique statique, ou le code a de la place pour l'optimisation des performances. Ensuite, nous écrirons un code de remplacement, comme indiqué sur l'image du milieu. À gauche se trouve un morceau de code Python qui, selon nous, peut être remplacé, et à droite se trouve un autre morceau de code Python que nous avons remplacé. Ensuite, nous utiliserons la méthode de correspondance AST pour convertir l'entrée de l'utilisateur et notre modèle cible d'origine en AST, et exécuterons notre algorithme de correspondance d'arbre de sous-arbre dessus.
De cette façon, nous pouvons changer notre entrée d'origine XXXX, YYYY en WWWW, HHHH, et la transformer en une solution qui peut être mieux exécutée, ce qui améliore le taux de réussite de la conversion d'images dynamiques en images statiques dans une certaine mesure, et améliore le opérateur en même temps.performance, et peut obtenir l'effet que l'utilisateur est fondamentalement insensible.
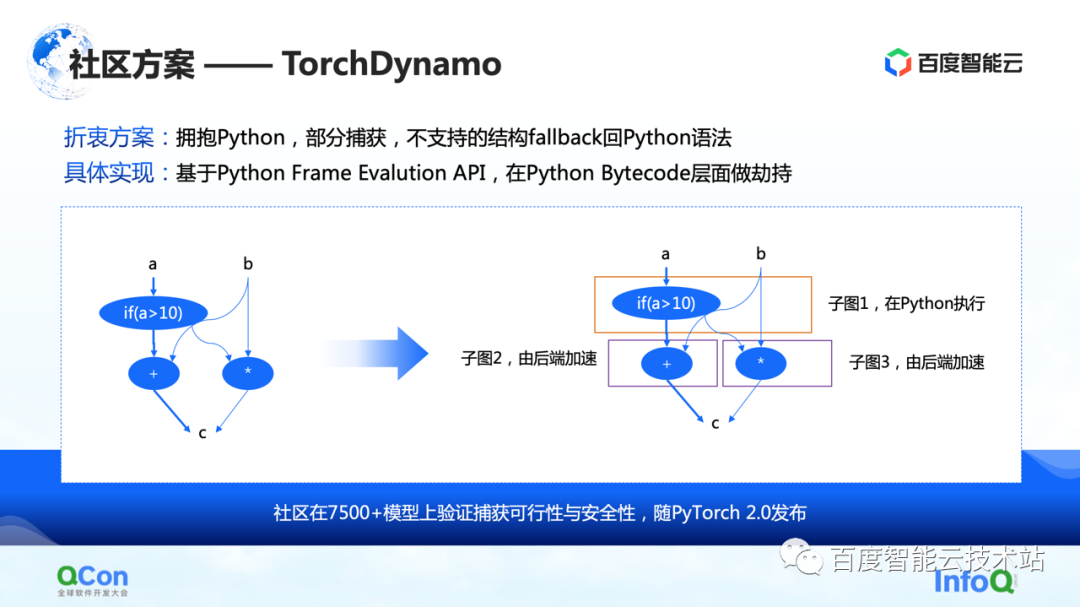
La seconde est quelques solutions dans la communauté, notamment la solution TorchDynamo proposée par PyTorch 2.0, qui est également une solution que nous avons vue jusqu'à présent et qui est plus adaptée à l'optimisation du calcul. Il peut réaliser une capture de graphique partielle et les structures non prises en charge peuvent revenir à Python. De cette façon, il peut cracher certains des sous-graphes vers le backend dans une certaine mesure, puis le backend peut encore accélérer les calculs sur ces sous-graphes.
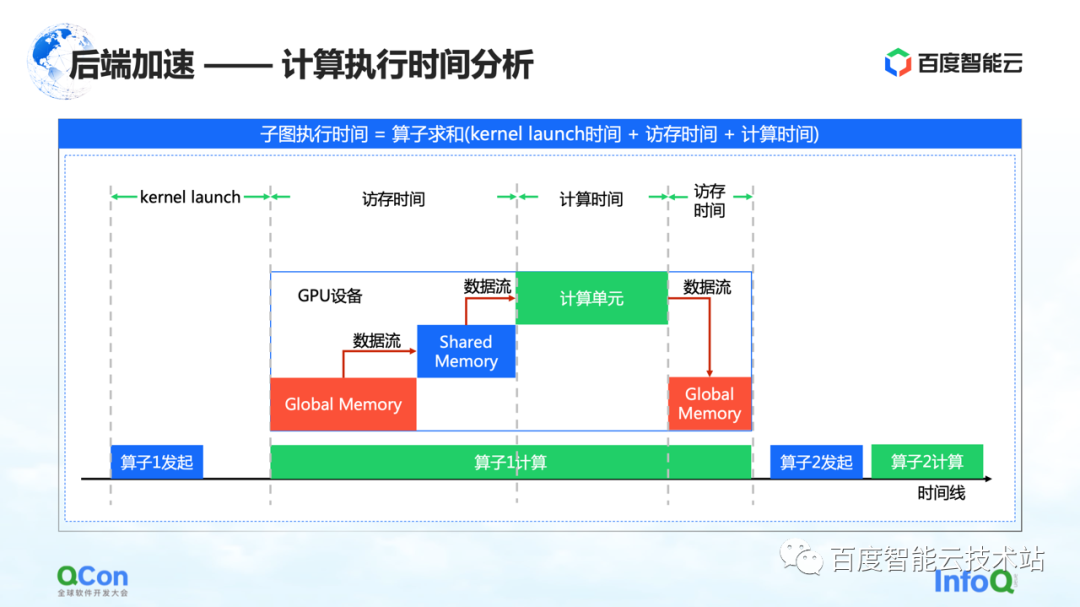
Après avoir capturé l'intégralité du graphique, l'étape suivante consiste à commencer à calculer l'accélération, c'est-à-dire l'accélération principale.
Nous pensons que les points clés du chronogramme du calcul GPU sont le temps d'accès mémoire et le temps de calcul. Nous accélérons cette fois sous les angles suivants.
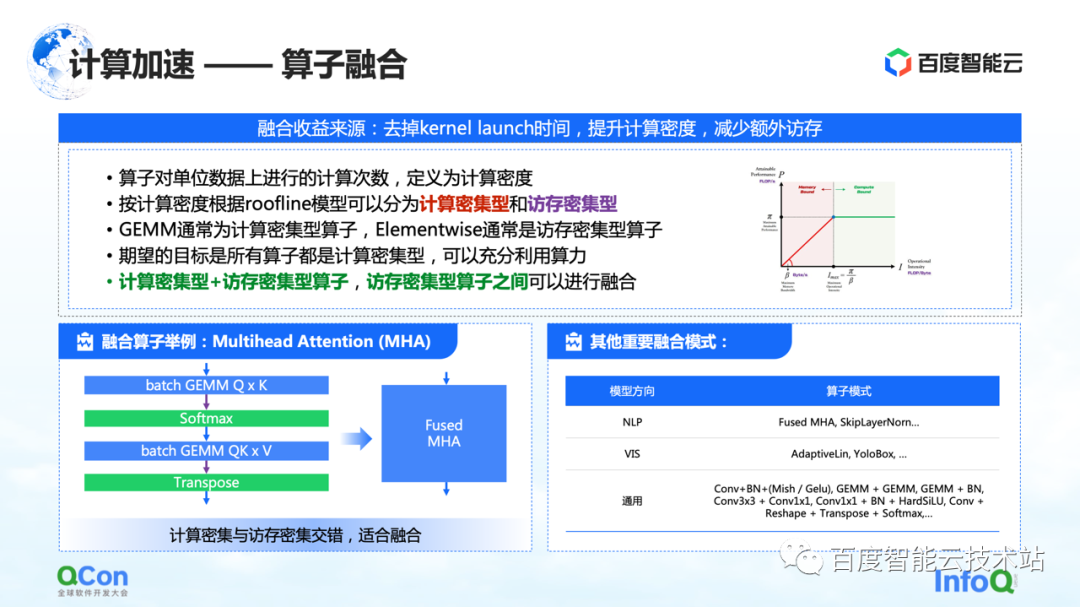
La première est la fusion d'opérateurs. Le principal avantage de la fusion d'opérateurs est de réduire le temps consacré au lancement du noyau, d'augmenter la densité de calcul et de réduire les accès mémoire supplémentaires. Nous définissons le nombre de calculs par unité d'accès mémoire d'un opérateur comme la densité de calcul.
Selon la différence de densité de calcul, nous divisons les opérateurs en deux types : gourmands en calcul et gourmands en mémoire. Par exemple, GEMM est un opérateur typique à forte intensité de calcul et Elementwise est un opérateur typique à forte intensité de mémoire. Nous avons trouvé qu'une bonne fusion peut être faite entre "opérateurs gourmands en calcul + opérateurs gourmands en mémoire" et "opérateurs gourmands en mémoire + opérateurs gourmands en mémoire".
Notre objectif est de convertir tous les opérateurs exécutés sur le GPU en opérateurs partiels gourmands en calculs, afin que nous puissions utiliser pleinement notre puissance de calcul.
À gauche, un exemple de la nôtre. Par exemple, dans la structure Transformer, l'attention multitête la plus importante peut faire une bonne fusion. Dans le même temps, il existe d'autres modèles que nous avons trouvés à droite, et nous ne les énumérerons pas un par un en raison du manque d'espace.
Un autre type d'optimisation informatique est l'optimisation de la mise en œuvre de l'opérateur.
La question essentielle de la mise en œuvre de l'opérateur est de savoir comment combiner la logique de calcul avec l'architecture de la puce, afin de mieux réaliser l'ensemble du processus de calcul. Nous voyons actuellement trois types de scénarios :
La première catégorie est celle des opérateurs manuscrits. Les fabricants concernés fourniront des bibliothèques d'opérateurs telles que cuBLAS et cuDNN. Les performances de l'opérateur qu'il fournit sont les meilleures, mais les opérations qu'il prend en charge sont limitées et la prise en charge du développement personnalisé est relativement médiocre.
La deuxième catégorie est celle des modèles semi-automatisés, tels que CUTLASS. Cette méthode crée une abstraction open source, permettant aux développeurs d'y effectuer un développement secondaire. C'est également la méthode que nous utilisons actuellement pour réaliser la fusion d'opérateurs gourmands en calculs et gourmands en mémoire.
Le troisième est l'optimisation basée sur la recherche. Nous avons prêté attention à certaines méthodes de compilation comme Halide et TVM dans la communauté. À l'heure actuelle, on constate que cette méthode est efficace sur certains opérateurs, mais qu'elle doit encore être peaufinée sur d'autres opérateurs.
En pratique, ces trois méthodes ont leurs propres avantages, nous vous fournirons donc la meilleure mise en œuvre grâce à la sélection du moment.

Après avoir parlé de l'optimisation de l'informatique, partageons plusieurs méthodes d'optimisation de la communication.
Le premier est la résolution du problème de collision de hachage de commutateur. La figure ci-dessous est une expérience que nous avons faite. Nous avons mis en place une tâche de 32 cartes et effectué 30 opérations AllReduce à chaque fois. La figure ci-dessous montre la bande passante de communication que nous avons mesurée, nous pouvons voir qu'il y a une forte probabilité qu'elle ralentisse. C'est un problème sérieux dans la formation de grands modèles.
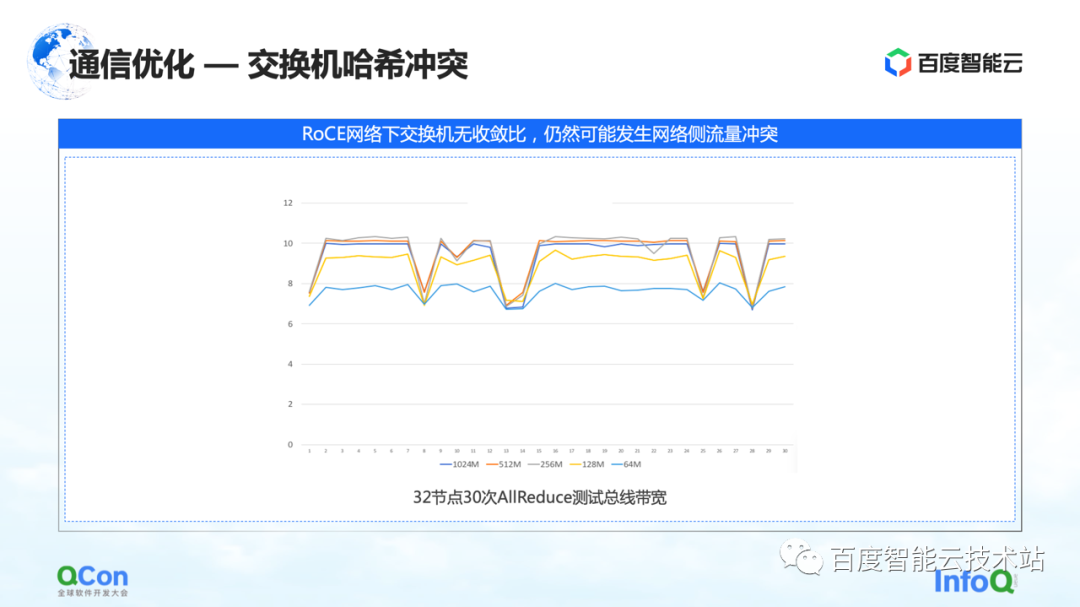
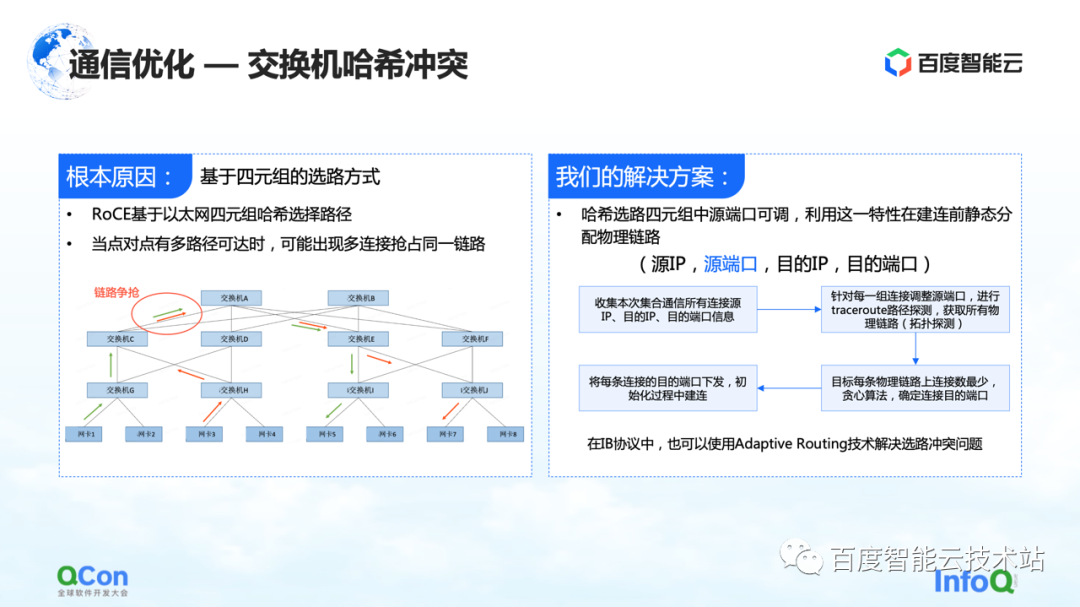
La raison du ralentissement est due aux collisions de hachage. Bien que dans la conception du réseau, le commutateur n'ait pas de taux de convergence, c'est-à-dire que les ressources de bande passante dans notre conception de réseau sont suffisantes, mais en raison de l'utilisation de RoCE, une méthode basée sur le routage quadruple Ethernet, les conflits de trafic côté réseau peuvent encore se produire.
Par exemple, dans l'exemple de la figure ci-dessous, les machines vertes doivent communiquer entre elles et les machines rouges doivent également communiquer entre elles. Ensuite, lors du processus de sélection de l'itinéraire, la communication de chacun se disputera la même bande passante en raison de Bien que la bande passante globale du réseau soit suffisante, des points d'accès au réseau local continueront de se former, ce qui entraînera un ralentissement des performances de communication.
Notre solution est en fait assez simple. Dans l'ensemble du processus de communication, il existe quatre tuples d'adresse IP source, de port source, d'adresse IP de destination et de port de destination. L'adresse IP source, l'adresse IP de destination et le port de destination sont fixes, tandis que le port source peut être ajusté. Profitant de cette fonctionnalité, nous ajustons en permanence le port source pour sélectionner différents chemins, puis utilisons l'algorithme glouton global pour minimiser l'occurrence de collisions de hachage.
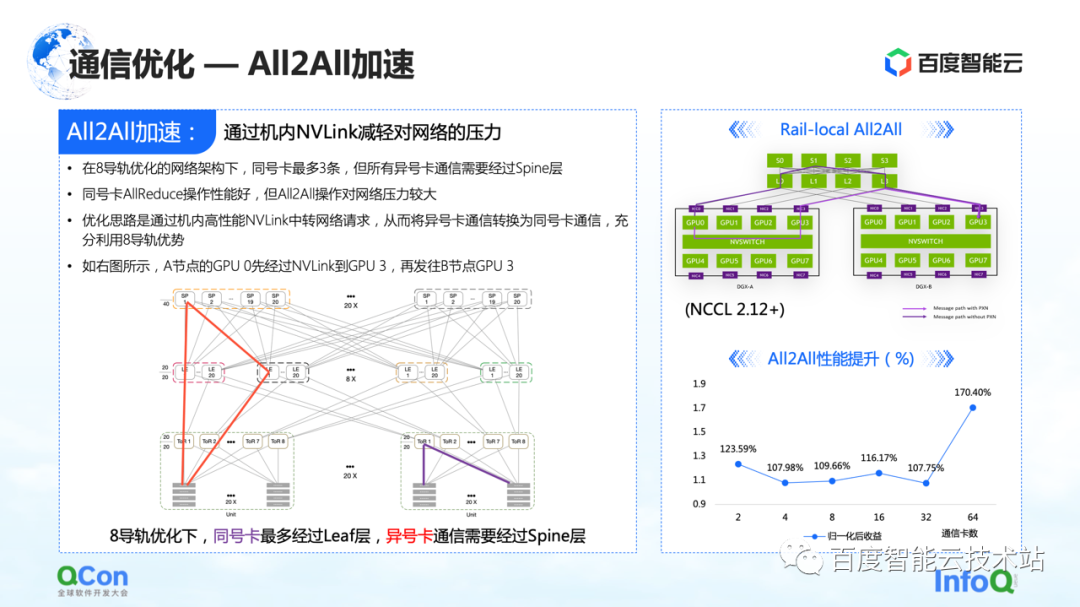
Dans l'optimisation de la communication, en plus de certaines optimisations sur AllReduce que nous venons de mentionner, il existe également une certaine marge d'optimisation sur All2All, en particulier notre réseau spécialement personnalisé pour huit rails.
Ce réseau mettra beaucoup de pression sur le commutateur dorsal de la couche supérieure dans le fonctionnement de l'ensemble All2All. La méthode d'optimisation consiste à utiliser le Rail-Local All2All dans NCCL, ou l'optimisation de PXN. Le principe est de convertir la communication entre cartes de numéros différents en communication entre cartes de même numéro grâce au NVLink haute performance à l'intérieur de la machine.
De cette manière, nous convertissons toutes les communications réseau entre les machines qui sont montées à l'origine dans la couche dorsale en communication intra-machine, de sorte que seule la communication de la couche TOR ou de la couche feuille peut être utilisée pour réaliser la communication de cartes avec des numéros différents, et les performances seront également améliorées. Il y a une grande amélioration.
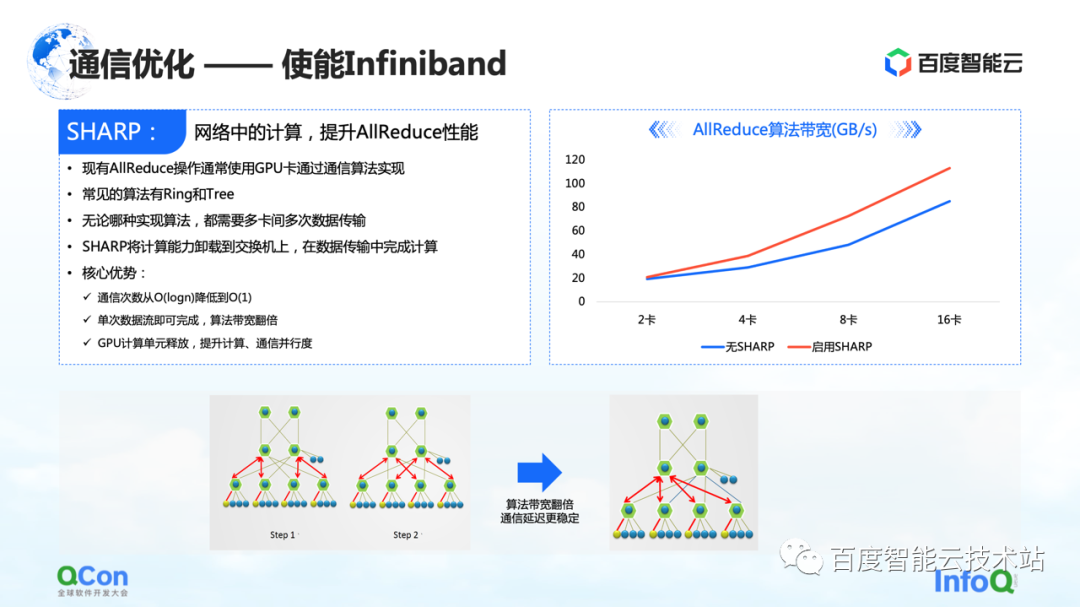
De plus, en plus de ces optimisations effectuées sur RoCE, il existe un autre effet direct qui peut être obtenu en activant Infiniband. Par exemple, le conflit de hachage de commutateur que nous venons de mentionner peut être géré par son propre routage adaptatif. Pour AllReduce, il dispose également de certaines fonctionnalités avancées telles que Sharp, qui peut bien décharger une partie des opérations informatiques d'AllReduce sur nos périphériques réseau, afin de libérer des unités de calcul et d'améliorer les performances de calcul. Grâce à cette méthode, nous pouvons bien améliorer à nouveau l'effet d'entraînement d'AllReduce.
A peine fini de parler d'optimisation de l'informatique et de la communication, regardons ce problème de bout en bout.
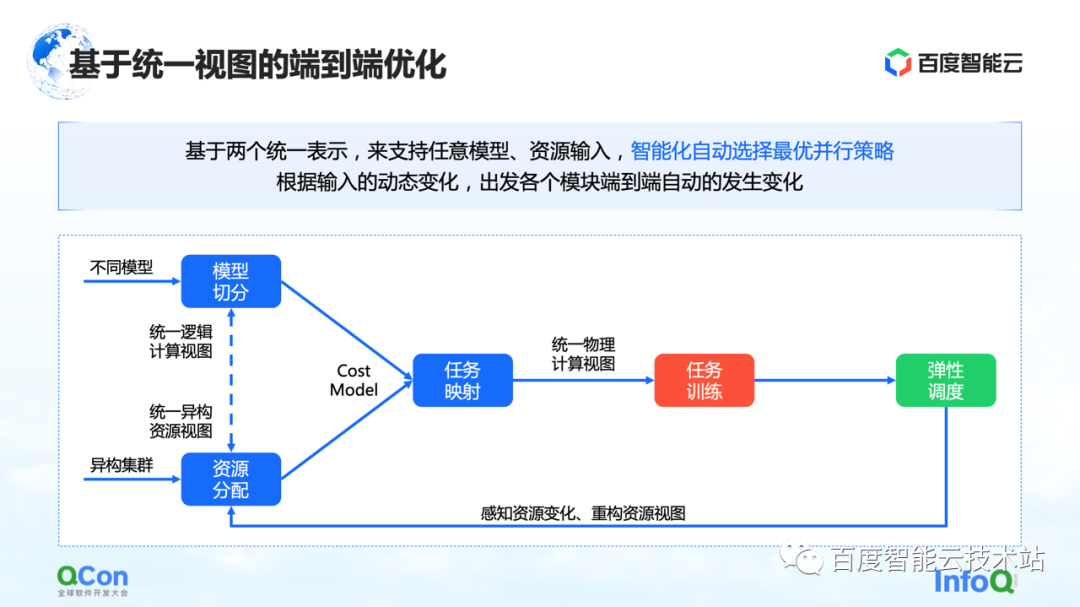
Du point de vue de l'ensemble de la formation du grand modèle, il est en fait divisé en deux parties, la première partie est le code modèle et la seconde partie est le réseau haute performance. A ces deux niveaux différents, il y a un problème à résoudre de toute urgence : quelle carte est la plus appropriée pour placer le modèle après de multiples stratégies de segmentation ?
Prenons un exemple : lorsque nous faisons du parallélisme tenseur, nous devons diviser le calcul d'un tenseur en deux parties. Étant donné qu'un grand nombre d'opérations AllReduce sont nécessaires entre les résultats de calcul des blocs, une bande passante élevée est nécessaire.
Si nous mettons deux morceaux d'un tenseur coupés en parallèle sur deux cartes de machines différentes, une communication réseau sera introduite, causant des problèmes de performances. Au contraire, si nous mettons ces deux pièces dans la même machine, nous pouvons effectuer efficacement les tâches informatiques et améliorer l'efficacité de la formation. Par conséquent, l'intérêt principal du problème de placement est de trouver la relation de mappage la plus appropriée ou la plus performante entre le modèle segmenté et le matériel hétérogène.
Dans nos premières formations sur les modèles, la cartographie était effectuée manuellement sur la base de connaissances empiriques d'experts. Par exemple, l'image ci-dessous montre que lorsque nous coopérons avec l'équipe commerciale, lorsque nous pensons que la bande passante dans la machine est bonne, nous recommandons de la mettre dans la machine. Si nous pensons qu'il peut y avoir des améliorations dans la salle des machines, il est recommandé de la mettre dans la salle des machines.
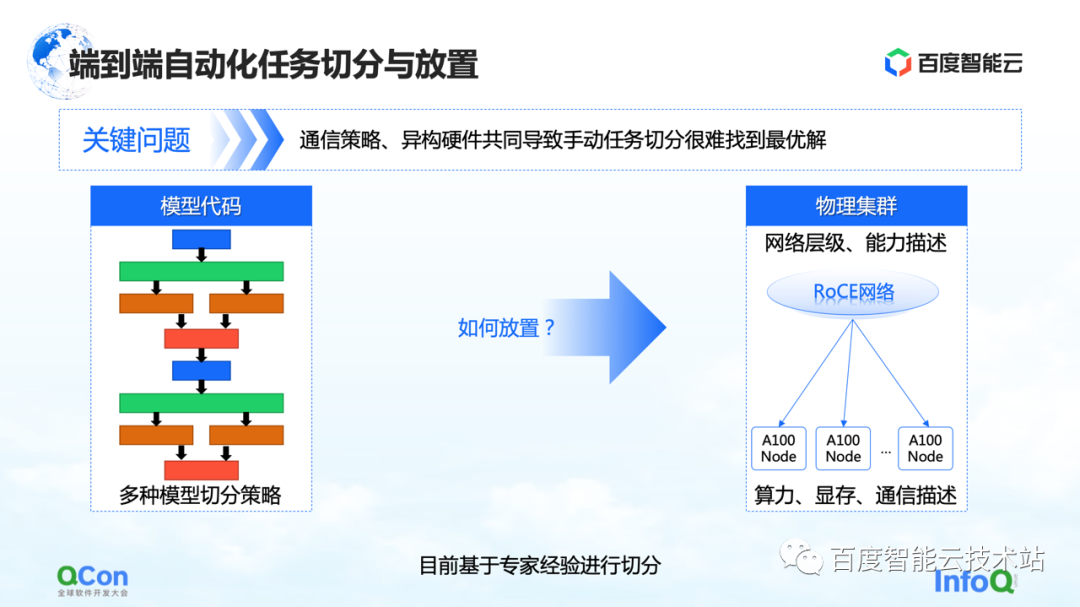
Existe-t-il une solution d'ingénierie ou systématique?
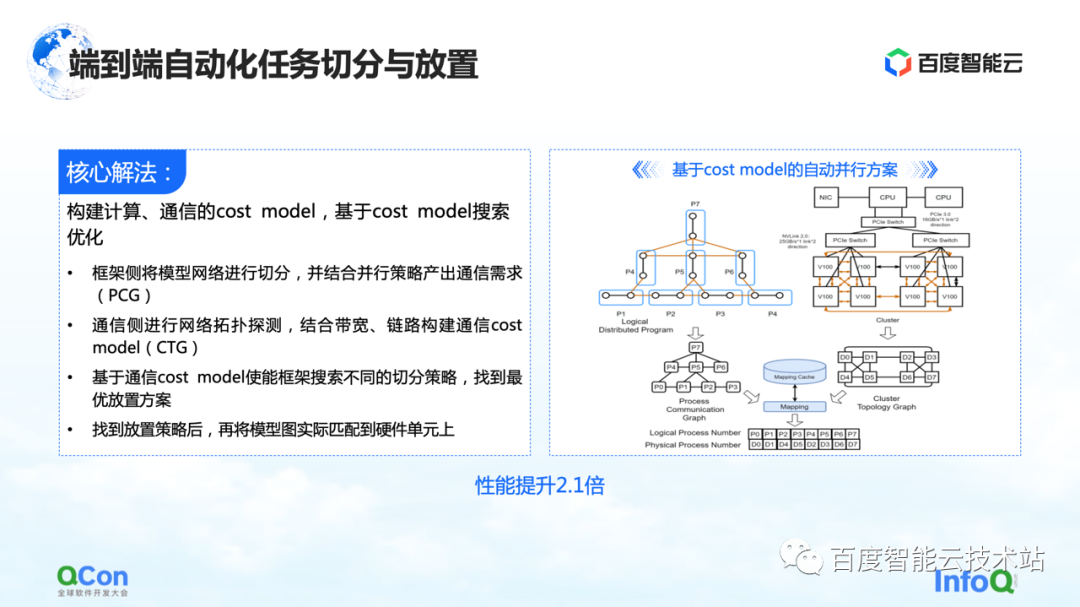
Notre solution principale consiste à créer un modèle de coût pour l'informatique et la communication, puis à optimiser la recherche en fonction du modèle de coût. De cette façon, une cartographie optimale est produite.
Dans l'ensemble du processus, le réseau modèle côté cadre sera d'abord abstrait et segmenté, puis mappé dans un diagramme de cadre informatique. Dans le même temps, les capacités de calcul et de communication du stand-alone et du cluster seront modélisées pour créer une carte topologique du cluster.
Lorsque nous avons les exigences de calcul et de communication sur le modèle sur le côté gauche de l'image de droite, et les capacités de calcul et de communication sur le matériel sur le côté droit de l'image, nous pouvons diviser et cartographier le modèle à l'aide d'algorithmes de graphe ou d'autres outils de recherche. méthodes, et enfin obtenir une solution optimale en bas de la figure de droite.
Dans le processus réel de formation de grands modèles, les performances finales peuvent être améliorées de 2,1 fois de cette manière.
4. Le développement de grands modèles favorise l'évolution des infrastructures
Enfin, je discuterai avec vous des nouvelles exigences que le grand modèle imposera à l'infrastructure à l'avenir.
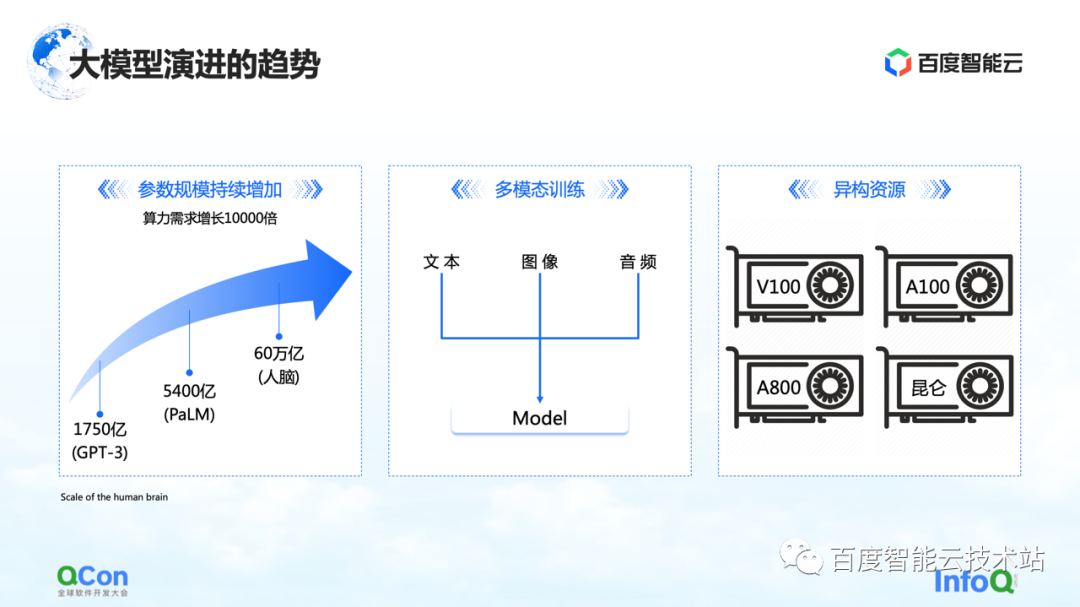
Il y a trois changements que nous voyons jusqu'à présent. Le premier concerne les paramètres du modèle, et les paramètres du modèle continueront de croître, passant de 175 milliards en GPT-3 à 540 milliards en PaLM. En ce qui concerne la valeur finale de la croissance future des paramètres, nous pouvons nous référer au cerveau humain avec une échelle d'environ 60 000 milliards de paramètres.
La seconde est la formation multimodale. À l'avenir, nous traiterons davantage de données modales. Différentes données modales apporteront plus de défis au stockage, au calcul et à la mémoire vidéo.
Le troisième concerne les ressources hétérogènes. À l'avenir, nous aurons des ressources de plus en plus hétérogènes. Dans le processus de formation, différents types de puissance de calcul, comment mieux les utiliser est également un défi urgent à résoudre.
Dans le même temps, d'un point de vue commercial, il peut y avoir différents types d'emplois dans un processus de formation complet, et il peut y avoir en même temps une formation GPT-3 traditionnelle, une formation d'apprentissage par renforcement et des tâches d'étiquetage des données. Comment mieux placer ces tâches hétérogènes sur notre cluster hétérogène sera un problème plus important.
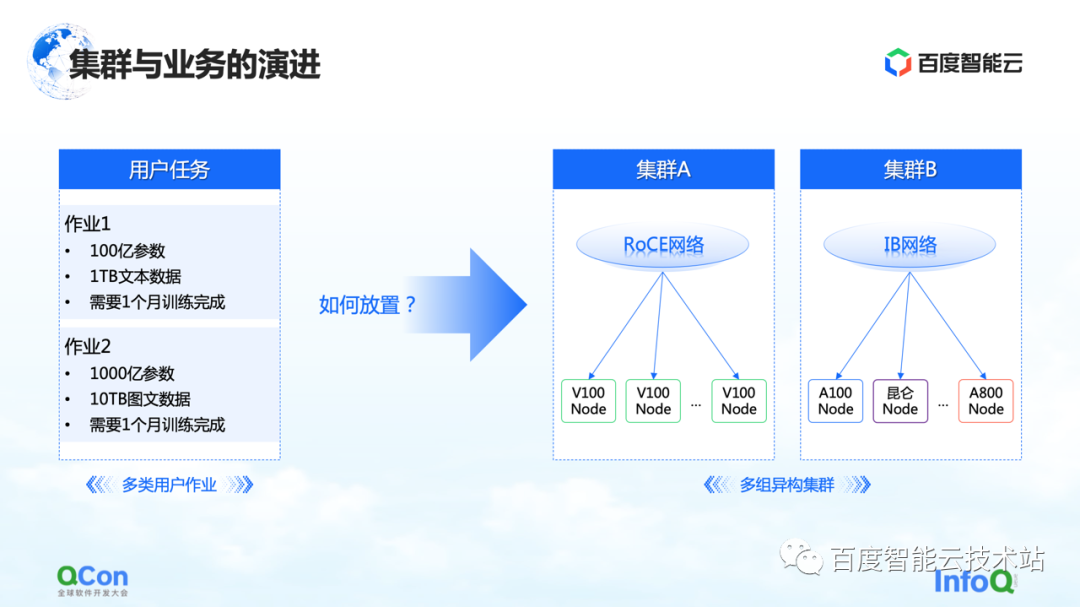
Nous avons vu plusieurs méthodes maintenant, dont l'une est l'optimisation de bout en bout basée sur une vue unifiée : unifier le modèle entier et les ressources hétérogènes sur la vue, et étendre le modèle de coût basé sur la vue unifiée, qui peut prendre en charge un seul tâche et multi-emplois en placement sous des grappes de ressources hétérogènes. Combiné avec la capacité de planification élastique, il peut mieux détecter les changements des ressources du cluster.
Toutes les capacités mentionnées ci-dessus ont été intégrées dans la plate-forme informatique hétérogène AI de Baidu Baige.
--FIN--
Lecture recommandée :
Parler de l'application de l'algorithme de graphe dans la scène d'activité dans l'anti-triche
Méthode de décomposition d'action dans une application d'animation d'images
Performance Platform Data Acceleration Road
Montage de la pratique d'arrangement du processus de production vidéo AIGC
Les ingénieurs de Baidu parlent de la compréhension vidéo