Annuaire d'articles
Récemment, ChatGPT a été populaire et les étudiants en PNL se sentiront certainement plus profondément. C'est une bonne chose que l'application de la PNL soit connue et activement déployée, mais chaque scénario d'application au niveau de l'application est une tâche qui a été continuellement surmontée par le modèle SOTA dans le domaine passé. Mais malheureusement, ces dernières années, les percées dans la résolution d'une seule tâche au niveau de l'algorithme ont considérablement ralenti, mais le niveau de l'application s'est accéléré.
ps: À l'heure actuelle, le mot "Skynet" n'a pas été mentionné dans les informations, hhhhhhh, à l'époque où VR et AR n'avaient rien, les mentions de "Skynet" arrivaient partout dans les montagnes et les plaines.
Ici, nous utilisons un modèle d'apprentissage automatique SVM relativement simple et couramment utilisé pour aider à chronométrer et obtenir des rendements excédentaires

Application de l'apprentissage automatique aux modèles quantitatifs
Scénarios d'application de quantification d'apprentissage automatique
L'application d'apprentissage automatique et la stratégie quantitative résumées par le blogueur ont les trois scénarios suivants :
- Construire une stratégie quantitative avec un taux de gain supérieur à 50. Peu importe que le modèle soit explicable ou non, en augmentant le nombre de transactions, le résultat global sera décalé vers la moyenne mobile pour obtenir le rendement excédentaire attendu
- Sur un cadre logique qui peut obtenir des rendements excédentaires, utilisez le modèle d'apprentissage automatique pour optimiser les détails, de sorte que le rendement moyen attendu passera à un rendement plus élevé sous la bénédiction du modèle
- Sur la base du modèle de tarification, obtenez des rendements excédentaires à partir du marché révisé
Et chaque scénario correspond à différentes idées de quantification, et correspond également au système de connaissances des différents chercheurs :
- Le premier type est adapté aux formations d'ingénieurs avec un professionnalisme suffisant. La difficulté réside dans la prémisse que "l'histoire ne se répétera pas". Le modèle de démonstration peut obtenir des rendements excédentaires, et l'obtention de rendements excédentaires est également un événement à forte probabilité. trading de fréquence
- Le deuxième type est adapté au personnel financier ayant des capacités de programmation.La difficulté réside dans la démonstration de la chaîne logique qui peut obtenir des rendements excédentaires
- Le troisième type convient au personnel financier ayant des capacités et de l'expérience en programmation.La difficulté réside dans l'identification et l'élimination des informations parasites sur le marché, ou la correction et l'optimisation du modèle de tarification.
Penser à l'efficacité des modèles quantitatifs
Le consensus actuel est que la complexité des tâches d'investissement est bien au-delà de la portée de l'apprentissage automatique, il est donc généralement nécessaire d'utiliser des modèles d'apprentissage automatique pour optimiser dans un cadre logique artificiellement cadré.
Après avoir étudié jusqu'à présent, j'ai lu beaucoup de livres et de stratégies quantitatives. Le blogueur a quelques réflexions et souhaite partager avec vous :
- En fait, beaucoup d'étudiants, comme les blogueurs, sont passés de l'informatique à la finance, donc la "quantification" est une bonne porte d'entrée pour nous. Plus on penche vers l'analyse de données, plus c'est confortable pour nous. Mais humains contre algorithmes :
- Les avantages de l'être humain sont : s'affranchir du bruit, résumer et lire de moins en moins de livres
- Les avantages des machines sont : les statistiques, le raisonnement et la possibilité de lire des livres de plus en plus épais
Le modèle économétrique, développé depuis plus d'un demi-siècle, a montré que les « données de résultat » de la finance et de la tarification sont chaotiques et aléatoires dans leur composition d'information. Par conséquent, il est préférable de ne pas laisser les machines « remplacer la réflexion par vous-même ». ", les résultats de l'algorithme ne peuvent qu'inspirer tout au plus, loin d'aider à la réflexion. En même temps, "n'ayez pas plus de fonctionnalités, mieux c'est". Les fonctionnalités inutiles sont la source du bruit, et les machines ne peuvent pas les filtrer par elles-mêmes. Par conséquent, les "humains" doivent d'abord comprendre la finance et avoir une logique, puis "les humains " construire des algorithmes.
- En plus des paramètres de réglage, l'amélioration des modèles d'apprentissage automatique a généralement deux effets :
- Séquences de fonctionnalités construites artificiellement qui peuvent résister à un examen logique
- Ne pré-éliminez pas les fonctionnalités selon les règles inhérentes à l'analyse des données
Expérience, comme le modèle de forêt aléatoire couramment utilisé par les blogueurs, lorsque vous souhaitez améliorer l'effet uniquement en ajustant les fonctionnalités et les données sans paramètres de réglage, tout d'abord, ne supprimez pas cette fonctionnalité basée sur une distribution biaisée ou quelque chose du genre. Parce que chaque caractéristique est une perspective, certaines perspectives sont plus précises, mais certaines perspectives sont claires et étranges. Mais chaque point de vue est précieux. À ce stade, nous avons besoin de la participation humaine pour construire des perspectives appropriées pour correspondre à ces caractéristiques et retraiter les caractéristiques. Moins la fonctionnalité est importante, plus la source d'inspiration est grande, plus la marge d'amélioration est grande ! Ce serait une grande perte de l'éliminer à l'avance.
- La différence de connaissances professionnelles nous fera regarder le monde d'un autre point de vue.Comme le dit le dicton, "quiconque apprend devient un personnage". Les étudiants qui se spécialisent en finance mettront la "gestion des risques" en premier lieu, et en même temps auront une reconnaissance presque instinctive des incidents de "biais du survivant", ce qui est très puissant ! Cependant, selon mon observation, afin de poursuivre la "moyenne théorique", de nombreuses stratégies quantitatives s'appuieront sur la théorie des données et se livreront au modèle, ce qui nécessite une attention particulière.
Ce blog utilise uniquement le modèle SVM pour les calculs. Pour plus de modèles d'apprentissage automatique, veuillez vous référer à : https://blog.csdn.net/weixin_35757704/article/details/89280669
Application des modèles d'apprentissage automatique dans la synchronisation quantitative
Processus d'entraînement et de prédiction
L'utilisation de l'apprentissage automatique comporte généralement les étapes suivantes :
- nettoyage des données
- Séparer l'ensemble d'entraînement et l'ensemble de test
- À l'aide de l'ensemble d'apprentissage, effectuez une validation croisée de la stabilité du modèle
- L'ensemble de test juge l'efficacité du modèle
- Calcul du modèle d'application et backtesting
Par conséquent, nous divisons le temps en deux parties suivantes :
- Heure des données de formation et de test: 2015-01-01 au 2020-01-01
- Calcul du modèle d'application et délai de backtest : 01/01/2020 au 01/01/2023
Construction de fonctionnalités de données de formation
Ici, nous construisons une fonctionnalité plus simple pour votre commodité :
- Taux de roulement moyen au cours des 5 derniers jours
- Taux de roulement moyen au cours des 10 derniers jours
- Changement au cours des 5 derniers jours
- Changement au cours des 10 derniers jours
- Indicateur MACD Valeur DIF
- Indicateur MACD Valeur DEA
- Valeur MACD
- Indicateur Aroon (un indicateur d'élan) valeur DOWN
- Valeur UP de l'indice Aroon
Modèle et calcul SVM
Entraînement et prédiction SVM
Habituellement, après avoir obtenu les données, le modèle avec le revenu final comme objectif a principalement les objectifs de formation suivants :
- Prédire directement le taux de rendement pour une période de temps dans le futur
- Prévoir la fourchette de revenus pour une période de temps dans le futur
En raison des performances limitées du modèle d'apprentissage automatique, lorsque l'objectif ultime est généralement le taux de rendement, il choisira de "prédire la fourchette de revenus pour une période de temps dans le futur"
Par conséquent, nous nous entraînons et prédisons selon les règles suivantes :
- 70 % des données sont utilisées comme ensemble d'apprentissage et 30 % des données sont utilisées comme ensemble de test
- Prenez la [montée et la chute dans les 5 prochains jours] comme objectif de prévision, et en même temps divisez les données en groupes et divisez-les en :
- Plage de rendement : [moins l'infini, -1]
- Intervalle de rendement : [-1, 1]
- Plage de rendement : [1, infini positif]
- Dans l'ensemble d'entraînement, effectuez 10 fois la validation croisée
- L'ensemble de test calcule la matrice de confusion et la visualise
La "validation croisée" ci-dessus vise à juger du problème de sur-ajustement et de sous-ajustement. De nombreux articles ont tendance à blâmer le "sur-ajustement" pour de mauvais résultats, mais il y a évidemment un problème. Pour le surajustement et le sous-ajustement, veuillez vous référer à : https://blog.csdn.net/weixin_35757704/article/details/123931046
Mesure d'effet
Le processus de calcul est le suivant :
- Récupérez tous les stocks non ST du 01/01/2015 au 01/01/2020
- Ensuite, selon la tendance du cours des actions individuelles, construisez les 9 caractéristiques ci-dessus
- Selon 70 % des données en tant qu'ensemble d'apprentissage, 30 % des données en tant qu'ensemble de test
- Faire 10 validations croisées sur l'ensemble d'entraînement
Selon les règles d'entraînement et de prédiction ci-dessus, les résultats de modèle suivants sont obtenus :
-
Calculé selon le processus de calcul ci-dessus, le taux de précision sur l'ensemble de test est de 0,4751
-
La matrice de confusion normalisée est la suivante :
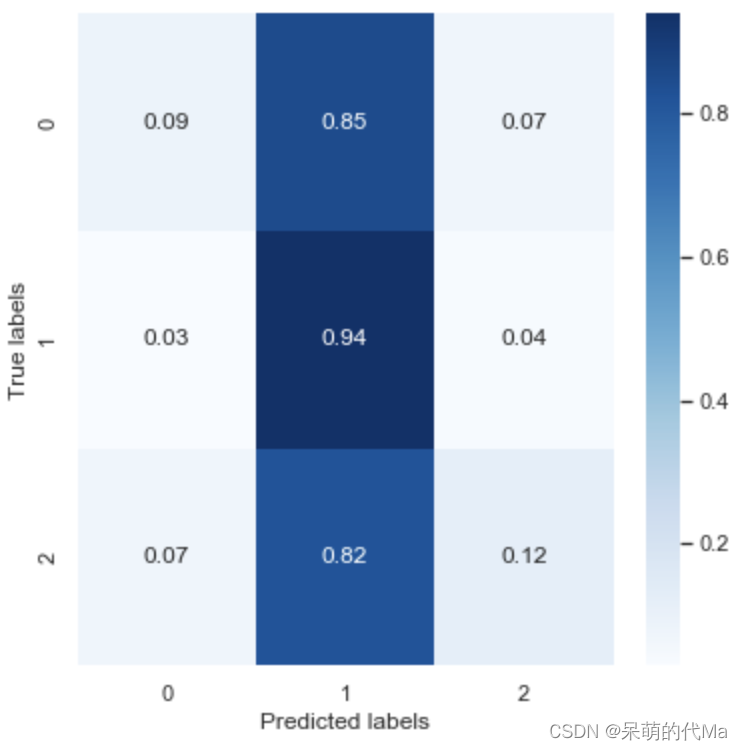
-
Les résultats utilisant la validation croisée 10 fois sont les suivants :
| Effet de précision | 0,492502 | 0,488092 | 0,478529 | 0,473529 | 0,485882 | 0,477647 | 0,477059 | 0,484118 | 0,480882 | 0,486176 |
|---|
En usage réel, on jugera selon l'effet logique du modèle : si le modèle prédit un rendement positif, on achètera, si le modèle prédit un rendement négatif, on vendra ;
Analyse d'efficacité
- L'effet de la validation croisée est similaire à l'effet de prédiction de l'ensemble de test, indiquant que les performances du modèle SVM sont relativement stables
- SVM ne prédit presque aucune différence dans des catégories telles que 0, 1 et 2 en tant que catégorie 1, et le taux de précision du calcul de 0 et 2 n'est que de 10 %, quelle que soit la catégorie elle-même.
Cet effet est tout à fait satisfaisant, car il n'y a pas d'optimisation, d'ajustement ou de caractéristiques structurelles subjectives, l'effet du modèle nu est presque le même effet...