Table des matières
1. Quelques points de connaissance introductifs à la reconnaissance des gestes humains
2. Brève introduction de l'algorithme Blazepose
3. Réalisation du système de fitness AI
avant-propos
Avec la montée de l'engouement national pour le fitness, de plus en plus de personnes participent activement à des exercices de fitness, mais en raison du manque de conseils scientifiques en matière d'exercices, il est difficile d'obtenir des résultats correspondants en matière de fitness. Selon une étude de marché, aucun produit ne peut analyser automatiquement les exercices de fitness et fournir des conseils. Ces dernières années, le réseau de neurones profonds a connu un grand succès dans la reconnaissance de la posture du corps humain.En réponse à ce phénomène, cet article conçoit un système de coaching de fitness basé sur OpenCv et l'algorithme BlazePose dans MediaPipe. Le contenu principal du système comprend la détection des points clés d'un seul corps humain, la connexion des points clés et l'affichage des changements d'angle des points clés dans le sport et le fitness. Le système de coaching de fitness AI peut lire des images ou des fichiers vidéo à traiter et afficher les changements d'angle des points clés de l'exercice.
1. Quelques points de connaissance introductifs à la reconnaissance des gestes humains
-
N'importe qui
-
où sont les gens
-
Qui est ce gars
-
dans quel état est cette personne en ce moment
-
Que fait cette personne dans la période actuelle
-
De haut en bas
-
Détectez d'abord le corps humain , utilisez le réseau de détection de cible frontal pour identifier la boîte englobante du corps humain dans l'image, HRnet () améliore Étant donné que Top-down élimine la majeure partie du fond dans l'étape de détection de la cible, il y a peu de bruits de fond ou d'autres points clés humains, ce qui simplifie l'estimation de la carte thermique des points clés, mais consomme beaucoup de coûts de calcul dans l'étape de détection de la cible humaine. et n'est pas un algorithme de bout en bout
-
Inconvénients : cela dépend beaucoup des résultats de la détection de la posture du corps humain (si deux personnes sont proches l'une de l'autre, parfois une seule information de boîte sera obtenue et le résultat final sera une personne de moins), la vitesse de l'algorithme et le nombre de personnes sur la photo En proportion directe, s'il y a 30 personnes sur une photo, il faut répéter 30 fois l'estimation du corps humain d'une seule personne, ce qui rend cette méthode très lente dans les scènes complexes
-
-
De bas en haut
-
Il prédit d'abord les positions de tous les points clés humains dans l'image, puis connecte les points clés dans différentes instances du corps humain.
-
Le travail représentatif comprend :
-
La méthode DeepCut et la méthode DeeperCut ont été les pionnières du problème d'association de points clés en tant que problème de programmation linéaire entière, qui peut être résolu efficacement, mais le temps de traitement peut atteindre plusieurs heures.
-
La méthode Openpose peut essentiellement réaliser une détection en temps réel. Le composant PAF est utilisé pour prédire la disparition du corps humain et les points clés que les liens peuvent appartenir à la même personne. La méthode PifPaf étend encore cette méthode et améliore la précision. de la connexion.
-
La méthode d'intégration associative mappe chaque point clé à une "étiquette" à laquelle appartient l'objet reconnu, et l'étiquette associe directement chaque point clé prédit à d'autres points clés du même groupe pour obtenir la pose humaine prédite.
-
La méthode PersonLab utilise un décalage à courte distance pour améliorer la précision de la prédiction des points clés, puis regroupe les points clés prédits dans une instance d'estimation de pose via un décodage gourmand et un vote de Hough.
-
-
Bottom-up est généralement moins complexe et plus rapide que les algorithmes Top-down , et c'est un algorithme de bout en bout . La précision de Top-down est relativement plus élevée .
-

-
2. Brève introduction de l'algorithme Blazepose
La démo a été inspirée par un article publié par Google dans CVPR 2020. Blazepose appartient à un type de Bottom-up.
La caractéristique de cet algorithme est que la vitesse globale a été considérablement améliorée.
Blaze est une flamme, c'est-à-dire que le point central de cet algorithme est que sa vitesse est très rapide, plutôt que sa précision.Par rapport à la pose ouverte traditionnelle, son fps est plusieurs fois plus élevé et l'écart de précision n'est pas très grand Cela rend cet algorithme très adapté au développement des appareils mobiles d'aujourd'hui
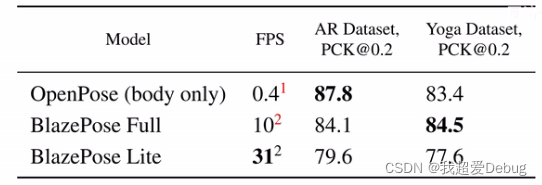
Grâce à la comparaison des fps, on peut clairement voir que la vitesse de Blazepose s'est améliorée.
([email protected] est un indicateur classique de détection de posture humaine, ce qui signifie que la distance euclidienne entre les coordonnées des points prédits par le modèle et les coordonnées réelles des points est inférieure à 20 % de la distance de l'ensemble du corps humain, et il est jugé comme une prédiction Oui)
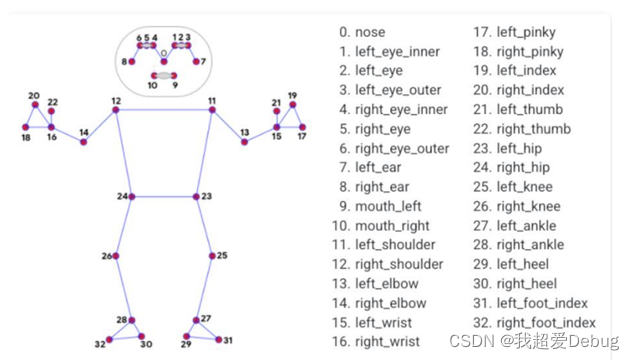
Le concours traditionnel de jeux de données coco nécessite 18 points clés, on peut voir que blazepose peut atteindre 33 points clés,
Les principaux apports de cet article sont :
(1) Une nouvelle solution de suivi de la posture du corps humain ;
(2) Réseau d'estimation de pose humaine légère.
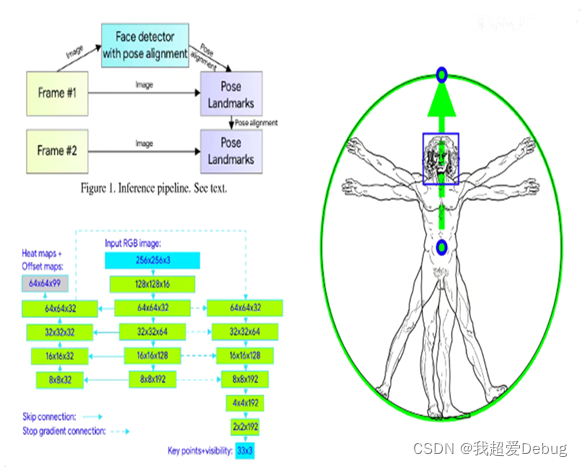
1. Une nouvelle méthode de suivi de la posture du corps humain
Le détecteur de posture du corps humain traditionnel est mis à niveau vers un détecteur de visage , et les données de sortie de l'image de trame précédente peuvent être utilisées comme entrée de l'image de trame suivante.Lorsqu'il n'y a pas de visage dans l'image de la trame précédente, il sera redétecté, ce qui rendra le taux global plus élevé
Cette idée est née du diagramme d'inspiration "Homme de Vitruve" de Da Vinci, à travers le visage humain, le centre des épaules et le milieu des deux hanches pour former un segment de ligne verticale, de manière à dessiner un cercle circonscrit pour définir la boîte englobante du corps humain.
2. Réseau d'estimation de la pose humaine légère
Le modèle de réseau combine deux techniques courantes,
cartes thermiques (technologie de carte thermique et encodeur de régression (technologie d'encodeur de régression,
La carte thermique signifie que ce que je produis est une image en niveaux de gris, dont la taille est la même que l'image d'origine, mais les pixels représentent la probabilité qu'un certain point clé apparaisse, par exemple, à la position du coude, vous pouvez voir le signe à travers la carte thermique Voici la zone où se trouvent les points clés du coude Contrairement à la technologie basée sur les cartes thermiques, bien que la méthode basée sur la régression ait des exigences de calcul plus faibles et une évolutivité plus élevée, même si le nombre de paramètres est petit, empilé L'architecture en sablier empilé peut également améliorer considérablement la précision de la prédiction. Une architecture de réseau encodeur-décodeur est utilisée pour prédire les cartes thermiques pour toutes les articulations, suivie d'un autre encodeur qui régresse directement vers toutes les coordonnées des articulations. Dans le processus de raisonnement, nous pouvons abandonner la sortie graphique de la carte thermique, mais obtenir directement les résultats de sortie des points clés. La ligne continue représente les connexions sautées et la ligne pointillée signifie qu'elle ne se propagera pas le long de la flèche.
Dans la prédiction réelle, nous n'avons pas besoin de la carte de sortie de la carte thermique, mais obtenons directement les résultats de sortie des points clés, de sorte que l'objectif d'augmenter la vitesse puisse être atteint
3. Réalisation du système de fitness AI
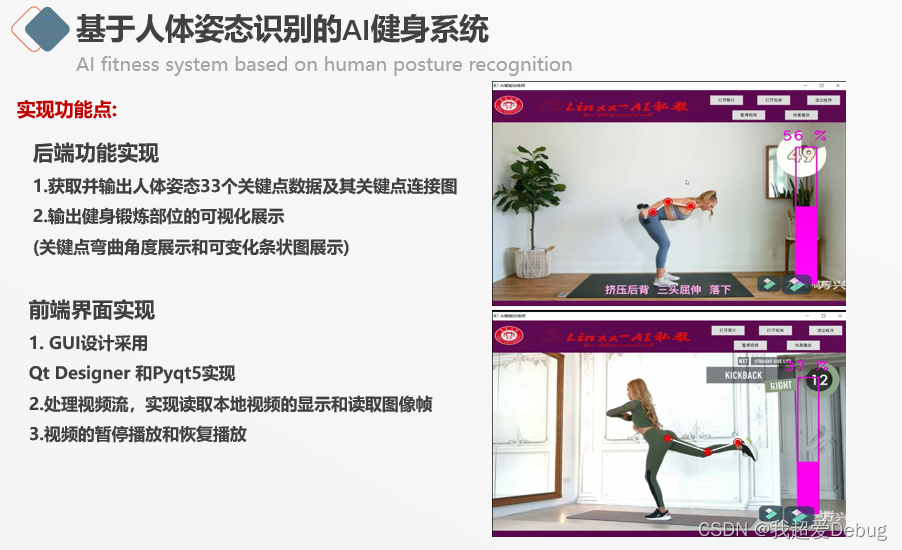
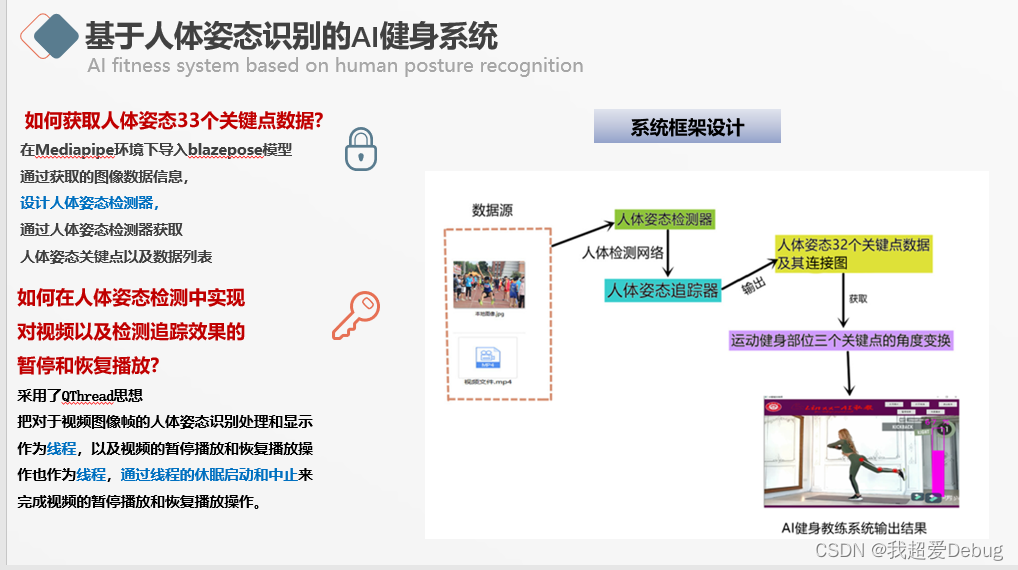
Media Pipe - Media Pipe est un framework multiplateforme open source permettant de créer des pipelines d'apprentissage automatique multimodèles. Il peut être utilisé pour mettre en œuvre des modèles de pointe tels que la détection de visage, le suivi à plusieurs mains, la segmentation des cheveux, la détection et le suivi d'objets, etc.
Le backend réalise principalement l'acquisition et la sortie de données de 33 points clés de la posture du corps humain, car ce que je fais est un système de fitness AI, et les points clés des parties à exercer sont connectés, et la flexion de l'exercice les pièces peuvent être clairement vues visuellement L'angle, ainsi que l'affichage du graphique à barres variable à côté, résolvent le problème de l'effort de puissance peu clair des actions de fitness dans les modèles de fitness traditionnels
L'interface graphique frontale est implémentée avec Qt Designer et pyqt5. La difficulté ici est qu'il ne s'agit pas d'une pause vidéo ordinaire et de la reprise de la lecture. Ici, les points clés de la posture du corps humain ont été identifiés et détectés, ainsi que la visualisation correspondante. dont nous avons besoin est de synchroniser les extrémités avant et arrière pour faire une pause et reprendre,
Tout d'abord, l'image vidéo est extraite et divisée en une image image par image. Étant donné que le module de détection de cible et le module de reconnaissance de pose humaine bidimensionnelle utilisent des images comme entrée, la vidéo doit être transformée en images. Le modèle de réseau blazepose importé dans l'environnement Mediapipe obtient les points clés de la posture du corps humain en concevant un détecteur de posture du corps humain.La reconnaissance et le traitement des gestes humains dans le cadre de l'image vidéo, la pause et la lecture vidéo sont également utilisés comme fils , et la pause et la reprise de la lecture de l'image entière est complétée par le démarrage et l'arrêt de la mise en veille du fil
affichage vidéo