Table des matières
1. L'origine du mécanisme de l'attention
2. Régression du noyau de Nadaraya-Watson
Avec la popularité du modèle Transformer dans les domaines de la PNL, du CV et même du CG, le mécanisme d'attention (mécanisme d'attention) a été remarqué par de plus en plus d'érudits, et il est introduit dans diverses tâches d'apprentissage en profondeur pour améliorer les performances. L'équipe du professeur Hu Shimin de l'Université Tsinghua a récemment publié une revue Attention sur CVM [1], qui a présenté en détail les progrès de la recherche connexe dans ce domaine. Pour les applications de nuages de points, l'introduction d'un mécanisme d'attention et la conception d'un nouveau modèle d'apprentissage en profondeur est naturellement un point chaud de la recherche. Cet article prend le mécanisme de l'attention comme objet, décrit son développement et son application réussie dans le domaine des applications de nuages de points, et fournit des références aux étudiants qui s'attendent à faire des percées dans cette direction de recherche.
1. L'origine du mécanisme de l'attention
Reportez-vous au manuel d'apprentissage approfondi de M. Li Mu [2] pour l'introduction du mécanisme de l'attention.Voici une explication simple du mécanisme de l'attention. Le mécanisme d'attention est un mécanisme qui simule la perception visuelle humaine et filtre sélectivement les informations pour la réception et le traitement. Lors du filtrage d'informations, si aucune invite autonome n'est fournie, c'est-à-dire lorsqu'une personne lit un texte, observe une scène ou écoute un son sans aucune réflexion, le mécanisme d'attention est biaisé vers des informations anormales, telles qu'une scène en noir et blanc. Une fille en rouge, ou un point d'exclamation dans un paragraphe, etc. Lorsque des invites autonomes sont introduites, par exemple lorsque vous souhaitez lire des phrases liées à un certain nom ou des scènes associées à divers objets, le mécanisme d'attention introduit cette invite et augmente la sensibilité à ces informations lorsque les informations sont filtrées. Afin de modéliser mathématiquement le processus ci-dessus, le mécanisme d'attention introduit trois éléments de base, à savoir la requête, la clé et la valeur. Ces trois éléments constituent ensemble l'unité de traitement de base du module Attention. La clé (Key) et la valeur (Value) correspondent à l'entrée et à la sortie d'informations, et la requête (Query) correspond à l'invite autonome. L'unité de traitement de base du module Attention est illustrée dans la figure ci-dessous.
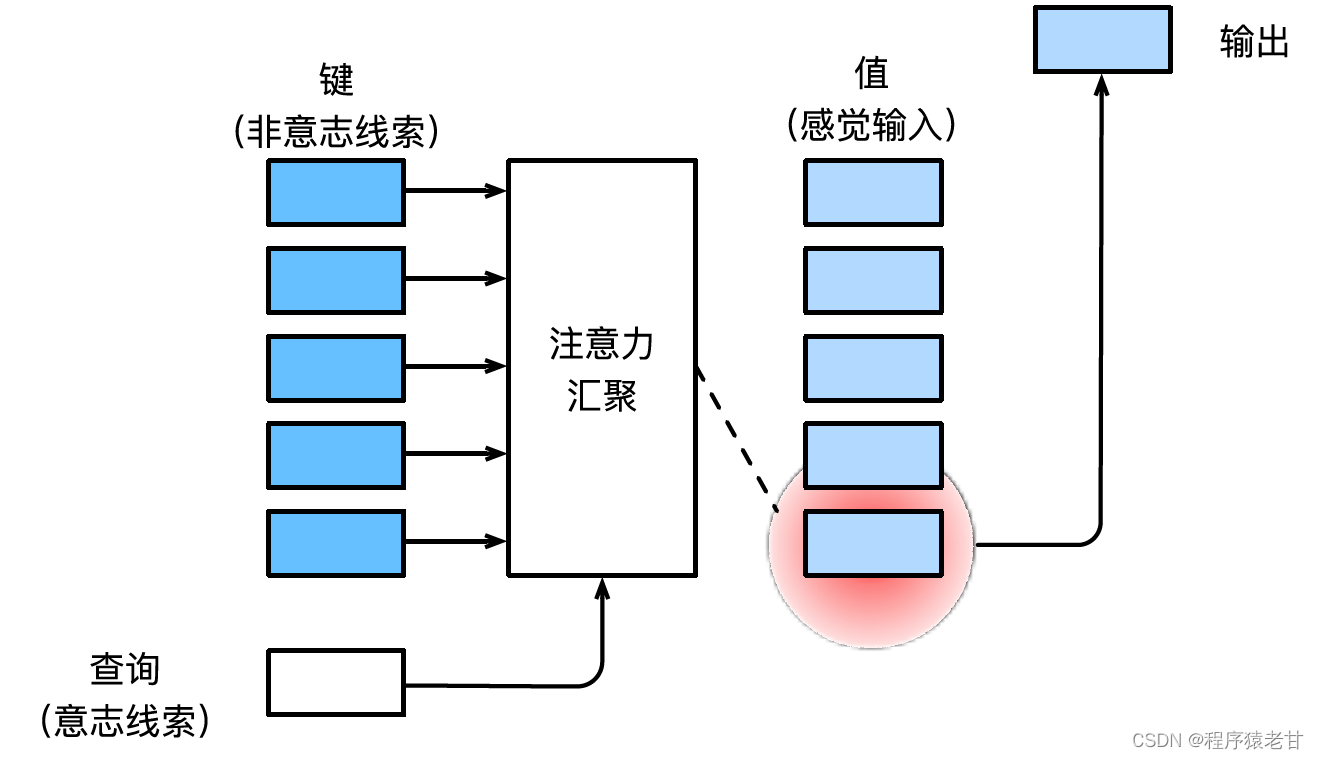
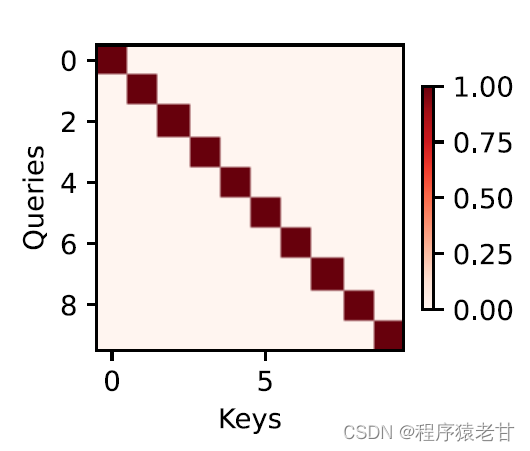
Le mécanisme d'attention combine la requête et la clé par le biais de la mise en commun de l'attention pour réaliser la tendance de sélection de la valeur. La clé et la valeur sont appariées, tout comme l'entrée et la sortie dans la tâche d'entraînement, qui est une distribution de données connue ou une correspondance de catégorie. Le mécanisme d'attention entre la requête dans le pool d'attention, établit le code de pondération de la requête à chaque clé, obtient la relation entre la requête et la clé, puis guide la sortie de la valeur correspondante. En bref, lorsque la requête est plus proche d'une clé, la sortie de la requête est plus proche de la valeur correspondant à la clé. Ce processus introduit l'attention sur la correspondance clé-valeur plus près de la requête pour guider la sortie conforme à l'attention. Si une matrice de relation bidimensionnelle est établie correspondant à la requête et à la clé, lorsque les valeurs sont identiques, c'est 1, et lorsqu'elles sont différentes, c'est 0, et le résultat de la visualisation peut être exprimé comme :
2. Régression du noyau de Nadaraya-Watson
Voici un modèle de mécanisme d'attention classique, la régression du noyau de Nadaraya-Watson [3] [4], pour comprendre la logique de fonctionnement de base du mécanisme d'attention. Supposons que nous ayons un ensemble de données de correspondance clé-valeur {(x1,y1),(x2,y2),...(xi,yi)} contrôlé par une fonction f, la tâche d'apprentissage consiste à établir f et à guider le nouveau Évaluation de la touche x. Dans cette tâche, (xi, yi) correspond à la clé et à la valeur, l'entrée x représente la requête et le but est d'obtenir sa valeur correspondante. Selon le mécanisme d'attention, il est nécessaire d'établir la prédiction de sa valeur en examinant la relation de similarité entre x et chaque valeur clé dans l'ensemble de données de correspondance de valeur clé. Lorsque l'entrée x est plus proche d'une certaine clé xi, la valeur de sortie est plus proche de yi. L'estimateur le plus simple pour les valeurs-clés ici est la moyenne :
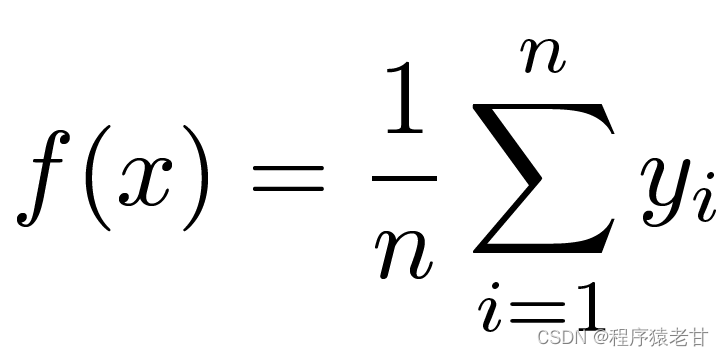
De toute évidence, ce n'est pas une bonne idée. Parce que la mise en commun moyenne ignore l'écart de l'échantillon dans la distribution clé-valeur. Si la différence clé-valeur est introduite dans le processus d'évaluation, le résultat deviendra naturellement meilleur. La régression du noyau de Nadaraya-Watson utilise une telle idée et propose une méthode d'évaluation pondérée :
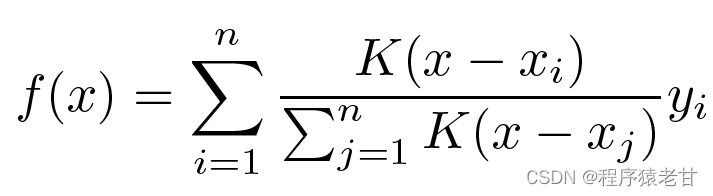
K est considéré comme le noyau, c'est-à-dire compris comme un poids pour mesurer l'écart par rapport à la différence. Si la formule ci-dessus est réécrite en fonction du poids de la différence entre l'entrée et la clé, sa propre formule peut être obtenue :
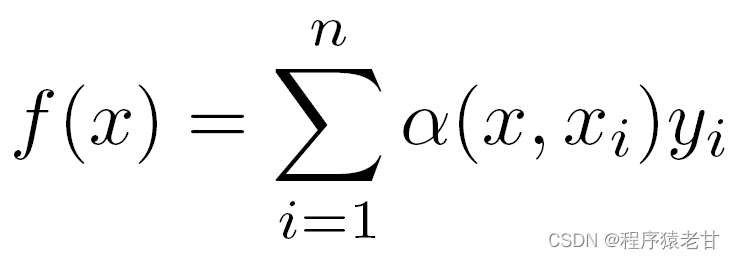
Si les poids ci-dessus sont remplacés par un poids gaussien piloté par un noyau gaussien, alors la fonction f peut être exprimée comme suit :
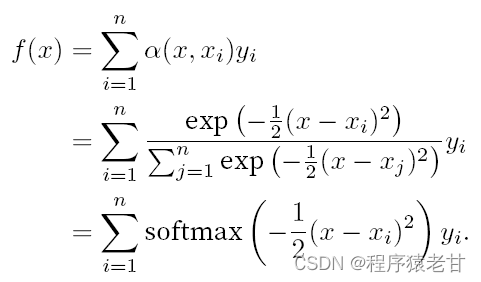
Un schéma est donné ici pour comparer l'ajustement de différents f à l'échantillon de paires clé-valeur dérivées de la mise en commun moyenne (panneau de gauche) et de la mise en commun de l'attention basée sur le noyau gaussien (panneau de droite). On constate que les performances de montage de ce dernier sont bien meilleures.
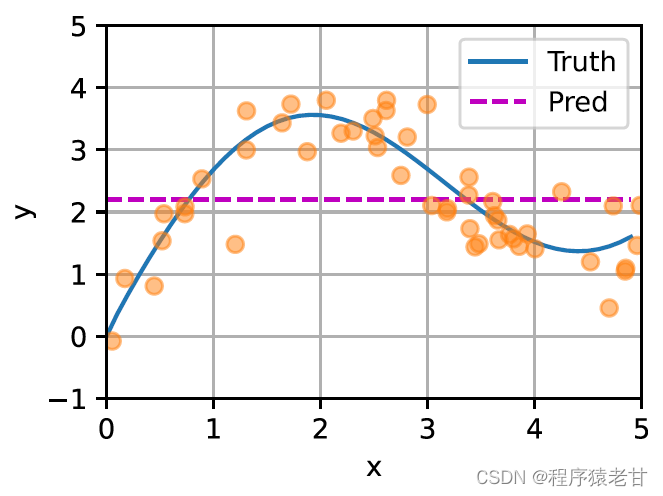
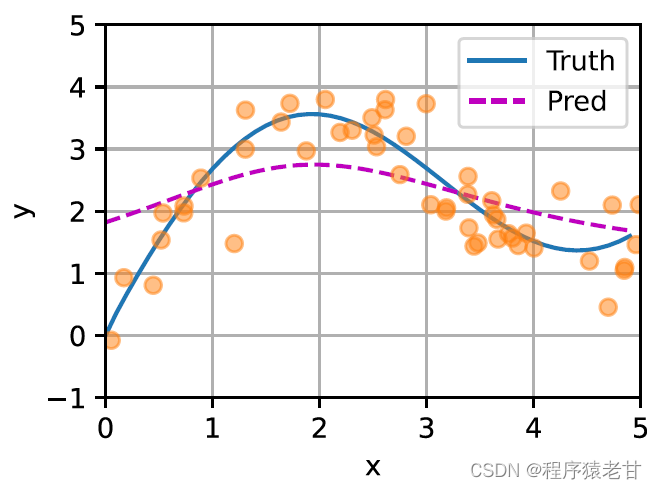
Le modèle ci-dessus est un modèle non paramétrique, pour le cas avec des paramètres apprenables, il est recommandé de lire le chapitre sur le mécanisme d'attention de [2]. Le noyau gaussien et son poids gaussien correspondant utilisés ici sont utilisés pour décrire la relation entre la requête et la clé. Dans le mécanisme de l'attention, la représentation quantitative de cette relation est le score d'attention. Le processus mentionné ci-dessus d'établissement de prédictions pour les valeurs de requête peut être exprimé en établissant un score basé sur des paires clé-valeur pour la requête, et en attribuant des poids aux scores pour obtenir des valeurs de requête, exprimées comme suit :
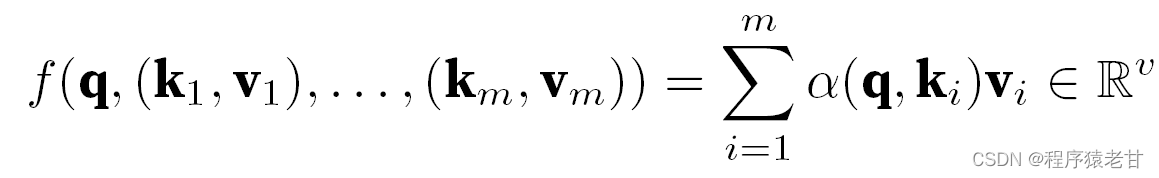
Où α représente le poids, q représente la requête et kv représente la paire clé-valeur. Dans le manuel [2], il est également présenté comment traiter la méthode de traitement de l'attention additive du temps de non-concordance des requêtes et des longueurs de clé et l'attention du produit scalaire scalaire, qui est utilisée pour définir le score d'attention, et ne sera pas détaillée ici.
3. Attention multi-tête et auto-attention
1) Attention multi-tête
L'attention multi-tête est utilisée pour combiner des requêtes et des représentations de sous-espace avec différentes valeurs clés, et réaliser l'organisation de différents comportements basés sur le mécanisme d'attention pour apprendre des connaissances structurées et des dépendances de données. Différentes projections linéaires sont apprises indépendamment pour transformer les requêtes, les clés et les valeurs. Ensuite, la requête transformée et la valeur-clé sont envoyées au pool d'attention en parallèle, puis les sorties de plusieurs pools d'attention sont assemblées et transformées par une autre projection linéaire qui peut être apprise, et la sortie finale est générée. Cette conception est appelée attention multi-tête [5]. La figure ci-dessous montre un modèle d'attention à plusieurs têtes pouvant être appris :
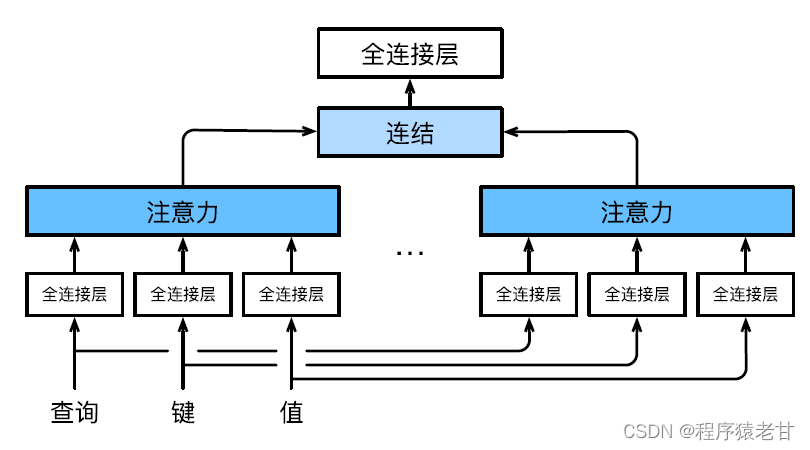
La définition mathématique de chaque tête d'attention est donnée ici. Étant donné une requête q, une clé k et une valeur v, la méthode de calcul de chaque tête d'attention h est :
![]()
Ici, f peut être une attention additive et une attention de produit scalaire mise à l'échelle. La sortie de l'attention multi-tête subit une autre transformation linéaire pour concaténer les sorties de plusieurs mécanismes d'attention afin d'imiter des fonctions plus complexes.
2) Auto-attention et encodage de position
Sur la base du mécanisme d'attention, la séquence lexicale du problème PNL est entrée dans le pool d'attention, et un groupe d'éléments lexicaux est utilisé en même temps comme requêtes et valeurs clés. Chaque requête s'occupe de toutes les paires clé-valeur et produit une sortie d'attention. Étant donné que la requête et les valeurs de clé proviennent toutes du même ensemble d'entrées, on parle de mécanisme d'auto-attention. Une méthode de codage basée sur le mécanisme d'auto-attention sera donnée ici.
Étant donné une séquence d'entrée de jeton x1,x2,...,xn, la sortie correspondante est une séquence identique y1,y2,...,yn. y est exprimé par :
![]()
Je n'ai pas bien compris cette formule au début. Cependant, combiné à la tâche spécifique de traduction de texte, il est facile à comprendre. La signification ici est qu'un élément à une certaine position d'un jeton correspond à l'entrée et à la sortie. Autrement dit, la valeur-clé est l'élément lui-même. Nous devons apprendre la fonction qui construit la prédiction de la valeur en apprenant les poids de chaque mot et de tous les mots du jeton.
Lorsqu'il s'agit de jetons, les opérations séquentielles sont abandonnées en raison de la nécessité d'un calcul parallèle de l'auto-attention. Afin d'utiliser les informations de séquence, des codages de position peuvent être ajoutés à la représentation d'entrée pour injecter des informations de position absolues ou relatives. En ajoutant une matrice d'intégration de position de la même forme à la matrice d'entrée pour obtenir un codage de position absolue , les éléments correspondant aux lignes et aux colonnes sont exprimés comme suit :
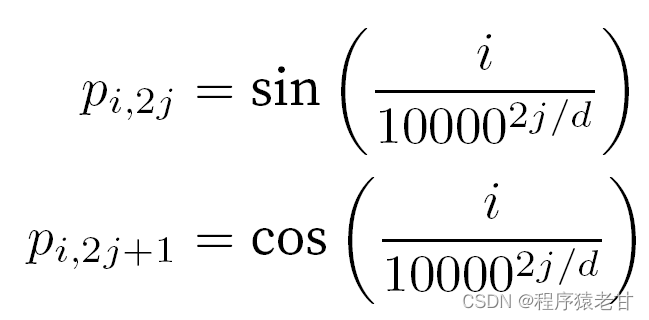
Cette représentation basée sur la trigonométrie de l'intégration positionnelle des éléments de la matrice n'est pas intuitive. Nous savons seulement qu'il existe une relation entre la dimension codée et la fréquence des courbes entraînées par les fonctions trigonométriques. C'est-à-dire que les informations de différentes dimensions à l'intérieur de chaque unité lexicale ont différentes fréquences de courbes de fonction trigonométriques correspondantes, comme le montre la figure :
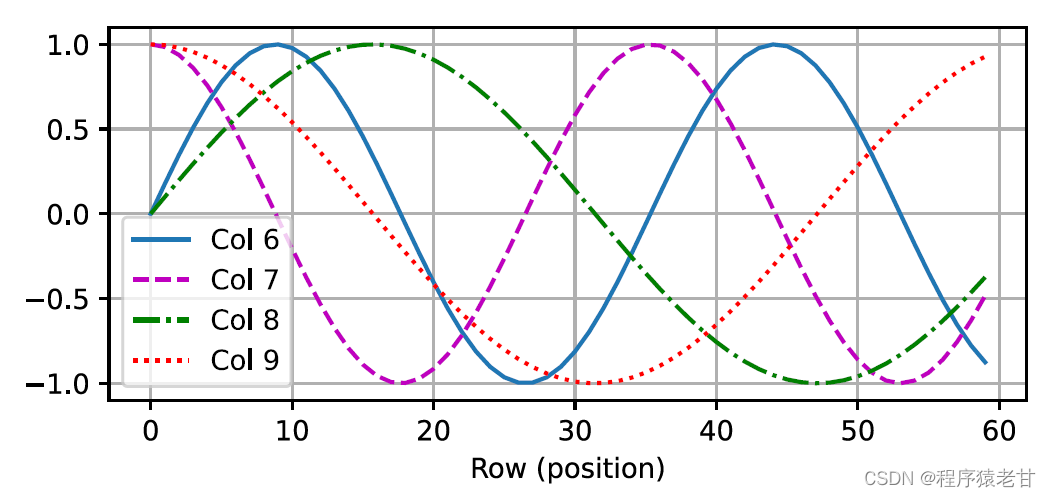
Il semble que plus la dimensionnalité de chaque lemme augmente, plus la fréquence correspondant à son intervalle diminue. Afin de clarifier la relation entre ce changement de fréquence et la position absolue, un exemple est utilisé ici pour expliquer. Cela imprime la représentation binaire de 0-7 (la carte thermique de fréquence est à droite):

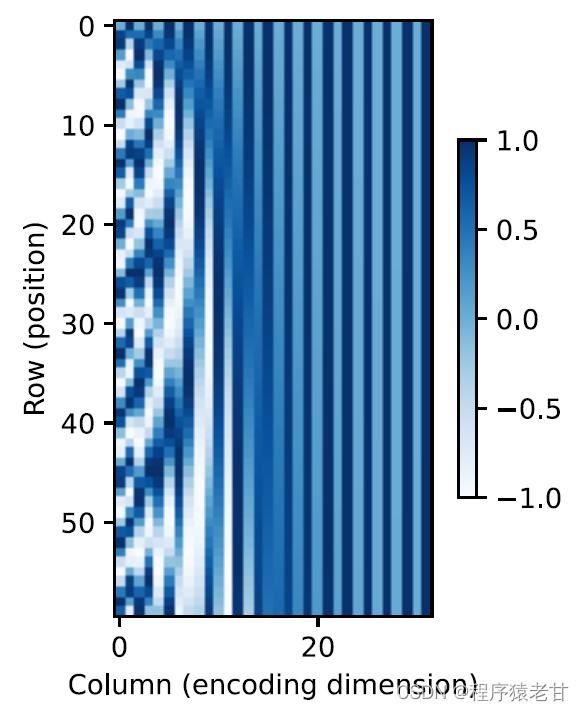
Ici, les bits supérieurs sont alternés moins fréquemment que les bits inférieurs. Grâce à l'utilisation du codage de position, le codage de différentes dimensions d'étymologie sur la base de la transformation de fréquence est réalisé, puis l'ajout d'informations de position est réalisé. Le codage de position relative ne sera pas décrit en détail ici.
4. Modèle de transformateur
Il est enfin temps de s'exciter ! Après avoir compris les connaissances ci-dessus, nous avons jeté les bases de l'apprentissage de Transformer. Comparé au modèle d'auto-attention précédent qui s'appuie toujours sur le réseau neuronal cyclique pour réaliser la représentation d'entrée, le modèle Transformer est entièrement basé sur le mécanisme d'auto-attention sans couche convolutive ni couche de réseau neuronal cyclique.
Le modèle Transformer est une architecture de codec, et le schéma d'architecture global est le suivant :
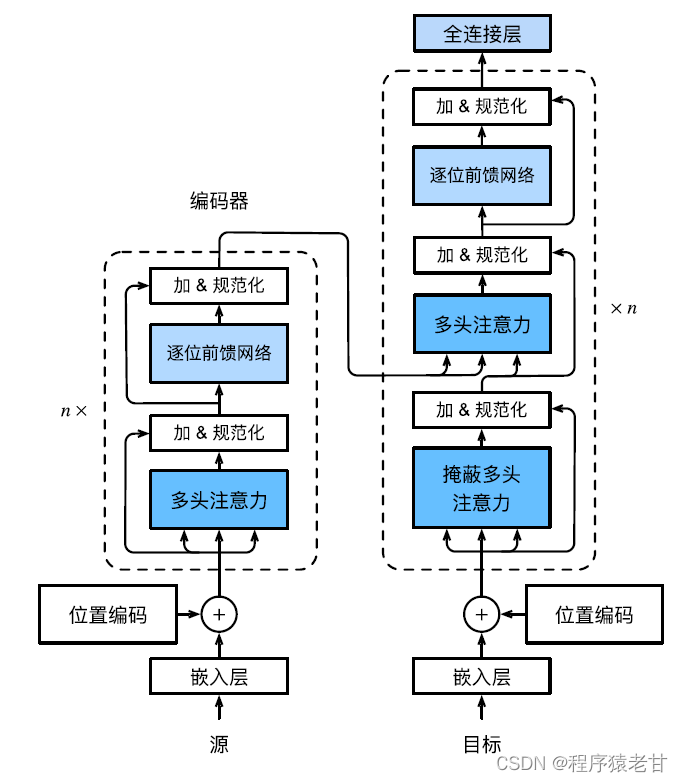
Le transformateur est composé d'un encodeur et d'un décodeur. Il est construit sur la base d'un module d'auto-attention. La séquence source (entrée) et la séquence cible (sortie) incorporant la représentation seront ajoutées avec un codage positionnel, puis entrées dans le codeur et décodeur respectivement. L'encodeur est construit en empilant plusieurs couches identiques, chacune avec deux sous-couches. La première sous-couche est la mise en commun de l'auto-attention multi-têtes et la deuxième sous-couche est un réseau d'anticipation basé sur la position. Les requêtes, les clés et les valeurs calculées par la couche d'encodeur proviennent de la sortie de la couche précédente. Chaque sous-couche utilise des connexions résiduelles. Semblable à l'encodeur , le décodeur est également composé de plusieurs couches identiques et utilise des connexions résiduelles et une normalisation de couche. En plus des deux sous-couches décrites dans l'encodeur, le décodeur ajoute une sous-couche intermédiaire appelée couche d'attention encodeur-décodeur. Les requêtes de cette couche proviennent de la sortie de la couche de décodeur précédente, tandis que les clés et les valeurs proviennent de la sortie de l'ensemble de l'encodeur. Dans l'auto-attention du décodeur, les requêtes, les clés et les valeurs sont toutes dérivées de la sortie de la couche de décodeur précédente. Chaque position dans le décodeur ne peut prendre en compte que toutes les positions précédentes. Cette attention masquée préserve les propriétés autorégressives, garantissant que les prédictions ne dépendent que des jetons de sortie qui ont été générés. La mise en oeuvre spécifique des différents modules ne sera pas décrite en détail.
Remarque : L'explication du terme ci-dessus, l'introduction du principe et la formule sur le mécanisme de l'attention se réfèrent principalement au manuel de l'enseignant Li Mu [2].
Sur la base du principe du mécanisme d'attention mentionné ci-dessus, un modèle d'apprentissage en profondeur du mécanisme d'attention pour les tâches de traitement de nuages de points est proposé. Nous présenterons en détail les travaux connexes dans le prochain blog, bienvenue pour continuer à prêter attention à mon blog.
Référence
[1] MH. Guo, TX, Xu, JJ. Liu, et al. Mécanismes d'attention en vision par ordinateur : une enquête[J]. Médias visuels computationnels, 2022, 8(3): 331-368.
[2] A. Zhang, ZC. Lipton, M. Li et AJ. Smola. Dive into Deep Learning [B]. https://zh-v2.d2l.ai/d2l-zh-pytorch.pdf .
[3] EA. Nadaraya. Sur l'estimation de la régression[J]. Théorie des probabilités et ses applications, 1964, 9(1): 141-142.
[4] GS. Watson. Analyse de régression lisse. Sankhyā: The Indian Journal of Statistics, série A, pp. 359‒372.
[5] A. Vaswani, N. Shazeer, N. Parmar, et al. L'attention est tout ce dont vous avez besoin. Avancées dans les systèmes de traitement de l'information neuronale, 2017,5998‒6008.