Conférence 08 : Comment diviser l'exemple d'application en microservices
Après avoir présenté les concepts de base de la conception pilotée par le domaine dans la leçon 07, cette leçon présentera comment appliquer les idées liées à la conception pilotée par le domaine dans la division des microservices.
Pôle Microservices
Dans la conception et la mise en œuvre d'applications d'architecture de microservices, si vous voulez découvrir la tâche la plus importante, ce doit être la division des non-microservices . Le cœur de l'architecture de microservices est un système distribué composé de plusieurs microservices coopérants. Ce n'est qu'une fois la division des microservices terminée que les responsabilités de chaque microservice peuvent être clarifiées et que le mode d'interaction entre les microservices peut être déterminé, puis continuer. La conception de l'API de chaque microservice est la mise en œuvre, le test et le déploiement finaux de chaque microservice.
Comme le montre le processus ci-dessus, la division des microservices est le premier maillon de toute la chaîne de conception et de mise en œuvre d'applications. Les changements dans chaque maillon de la chaîne auront un impact sur les maillons suivants. En tant que premier maillon de la division microservice, s'il y a un changement, cela affectera tous les maillons suivants. La dernière chose que vous souhaitez est de réaliser que certaines fonctionnalités doivent être migrées vers d'autres microservices lors de la mise en œuvre des microservices. Si cela se produit, l'API et l'implémentation du microservice associé devront être modifiées.
Bien sûr, dans le développement actuel, il est irréaliste d'éviter complètement les modifications de la division des microservices. Au stade de la division des microservices, si vous consacrez suffisamment d'énergie à l'analyse, les avantages que vous obtenez sont absolument énormes.
Microservices et contextes délimités
Dans la classe 07, nous avons introduit le concept de contexte défini dans la conception pilotée par le domaine. Si l'idée de conception pilotée par le domaine est appliquée à l'architecture des microservices, nous pouvons établir une correspondance biunivoque entre les microservices et le contexte défini. . Chaque contexte délimité correspond directement à un microservice, puis utilise le modèle de mappage de contexte pour définir le mode d'interaction entre les microservices.
De cette manière, le problème de la division des microservices est transformé en problème de division du contexte défini dans la conception pilotée par le domaine. Si vous avez déjà une solide compréhension de la conception pilotée par le domaine, ce sera un avantage ; sinon, le contenu de la leçon 07 peut vous aider à démarrer rapidement.
Prenons l'exemple d'application dans cette colonne comme exemple pour une explication spécifique.
Partitionnement du microservice de l'exemple d'application
La leçon 06 présente les scénarios utilisateur de l'exemple d'application. Sur la base de ces scénarios, le domaine de l'application peut être déterminé. Dans le développement d'applications proprement dit, les experts du domaine et le personnel de l'entreprise sont généralement tenus de participer.Grâce à la communication avec le personnel de l'entreprise, nous pouvons avoir une meilleure compréhension du domaine. En ce qui concerne l'exemple d'application, étant donné que le domaine d'application est relativement proche de la vie, et afin de simplifier l'introduction associée, nous effectuerons nous-mêmes une analyse de domaine. Cependant, cela présente un inconvénient, c'est-à-dire que l'analyse de domaine effectuée par les développeurs ne reflète pas nécessairement le processus métier réel. Cependant, pour l'exemple d'application, cela suffit.
La conception axée sur le domaine prend le domaine comme noyau, et le domaine est divisé en espace de problème et espace de solution .
L'espace de problèmes nous aide à penser au niveau de l'entreprise et est la partie du domaine dont dépend le domaine principal, qui comprend le domaine principal et d'autres sous-domaines selon les besoins. Le domaine principal doit être créé à partir de zéro, car il s'agit du cœur du système logiciel que nous allons développer ; d'autres sous-domaines peuvent déjà exister ou doivent également être créés à partir de zéro. La question centrale de l'espace du problème est de savoir comment identifier et diviser les sous-champs.
L'espace de solution consiste alors en un ou plusieurs contextes bornés, et les modèles dans les contextes. Idéalement, il existe une correspondance biunivoque entre les contextes et les sous-domaines définis. De cette manière, la division peut être lancée à partir du niveau métier, puis la même méthode de division peut être adoptée au niveau de la mise en œuvre, de sorte que l'intégration parfaite de l'espace des problèmes et de l'espace des solutions puisse être réalisée. Dans la pratique réelle, il est peu probable qu'il y ait une correspondance univoque entre des contextes et des sous-domaines définis. Lors de la mise en œuvre d'un système logiciel, il doit généralement être intégré aux systèmes hérités existants et aux systèmes externes, et ces systèmes ont leurs propres contextes définis. En pratique, il est plus réaliste que plusieurs contextes bornés appartiennent au même sous-domaine, ou qu'un contexte borné corresponde à plusieurs sous-domaines.
L'idée de la conception pilotée par le domaine est de partir du domaine, de diviser d'abord le sous-domaine, puis d'abstraire le contexte défini et le modèle dans le contexte du sous-domaine.Chaque contexte défini correspond à un microservice.
zones centrales
Le domaine central est l'endroit où la valeur du système logiciel existe, et c'est aussi le point de départ de la conception. Avant de démarrer le système logiciel, vous devez avoir une compréhension claire de la valeur fondamentale du système logiciel. Si ce n'est pas le cas, vous devez d'abord examiner les arguments de vente du système logiciel. Différents systèmes logiciels ont des domaines de base différents. En tant qu'application de taxi, son cœur de métier est de faire voyager les passagers rapidement, confortablement et en toute sécurité, ce qui est également le cœur des applications de taxi comme Didi Taxi et Uber. Pour l'application Happy Travel, par exemple, une telle zone centrale est un peu trop grande. L'application Happy Travel simplifie la zone centrale et se concentre uniquement sur la manière de faire voyager les passagers rapidement.
Nous devons donner au domaine principal un nom approprié. Le domaine central du voyage heureux est de savoir comment faire correspondre rapidement les passagers qui ont besoin d'appeler une voiture et les chauffeurs qui fournissent des services de voyage. Une fois que l'utilisateur a créé l'itinéraire, le système le distribue aux conducteurs disponibles. Après que le conducteur a reçu l'itinéraire, le système sélectionne un conducteur pour distribuer l'itinéraire. La zone centrale se concentre sur la répartition des itinéraires, d'où le nom de distribution d'itinéraires .
notions dans le domaine
Nous énumérons ensuite les concepts du domaine. Il s'agit d'un processus de remue-méninges qui peut être effectué sur un tableau blanc pour répertorier tous les concepts connexes qui viennent à l'esprit un par un. Les concepts sont des noms. Le premier concept est l'itinéraire, ce qui signifie un voyage d'un certain point de départ à un point d'arrivée. À partir de l'itinéraire, le concept de passagers et de conducteurs peut être dérivé. Le passager est l'initiateur de l'itinéraire, et le conducteur est l'achèvement de l'itinéraire. Chaque itinéraire a un point de départ et un point d'arrivée, et le concept correspondant est l'adresse. Les conducteurs utilisent des véhicules personnels pour effectuer des trajets, les véhicules sont donc un autre concept.
On retrouve d'autres sous-domaines basés sur des concepts, et le concept de voyage appartient au domaine de base. Les conducteurs et les passagers doivent appartenir à différents sous-domaines indépendants puis être gérés séparément, ce qui donne lieu à deux sous-domaines de la gestion des passagers et de la gestion des conducteurs . Le concept d'adresse appartient au sous-domaine de la gestion des adresses ; le concept de véhicule appartient au sous-domaine de la gestion des conducteurs.
Après avoir divisé les sous-domaines par les concepts du domaine, l'étape suivante consiste à continuer à découvrir de nouveaux sous-domaines à partir des opérations du domaine. Dans le scénario utilisateur, il est mentionné que l'itinéraire doit être vérifié, et cette opération a son sous-champ vérification d'itinéraire correspondant . Une fois le voyage terminé, le passager doit effectuer un paiement, et cette opération a son sous-champ correspondant gestion des paiements .
La figure suivante montre les sous-domaines dans l'exemple d'application.
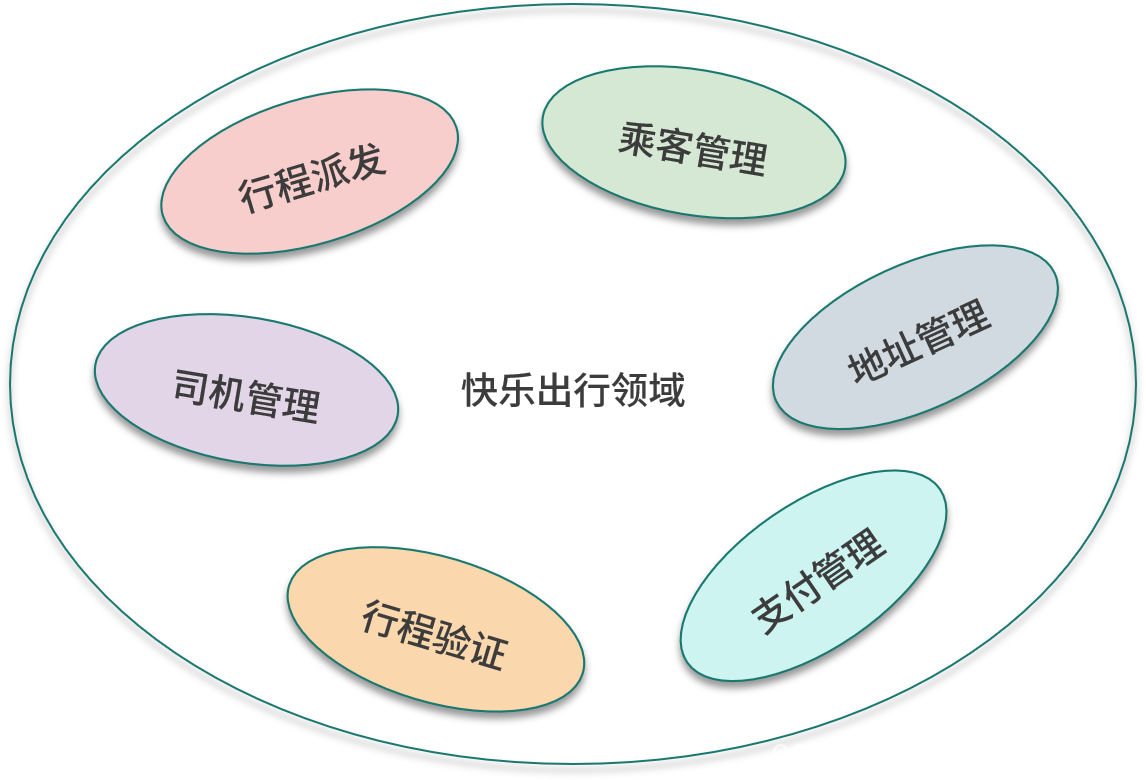 

contexte délimité
Après avoir identifié le domaine central et les autres sous-domaines, l'étape suivante peut être de passer de l'espace du problème à l'espace de la solution. Premièrement, les sous-domaines sont mappés au contexte délimité, et le contexte délimité porte le même nom que le sous-domaine ; ensuite, le contexte délimité est modélisé, et la tâche principale de la modélisation est de concrétiser les concepts associés.
Répartition des itinéraires
L'entité importante dans le modèle de répartition d'itinéraire est l'itinéraire, qui est également la racine de l'agrégat dans lequel réside l'itinéraire. Un trajet a ses emplacements de début et de fin, exprimés sous forme d'adresses d'objets de valeur. L'itinéraire est initié par le passager, donc l'entité d'itinéraire doit avoir une référence au passager. Lorsque le système sélectionne un conducteur pour accepter l'itinéraire, l'entité d'itinéraire a une référence au conducteur. Pendant tout le cycle de vie, le trajet peut être dans différents états, et il existe un attribut et son type d'énumération correspondant pour décrire l'état du trajet.
La figure ci-dessous montre les entités et les objets de valeur dans le modèle.
 

gestion des passagers
L'entité importante dans le modèle de gestion des passagers est le passager, qui est également la racine de l'agrégat dans lequel réside le passager. Les attributs de l'entité passager incluent le nom, l'adresse e-mail, le numéro de contact, etc. L'entité passager a une liste d'adresses enregistrées qui lui sont associées, et l'adresse est une entité.
La figure ci-dessous montre les entités du modèle.
 

gestion des chauffeurs
L'entité importante dans le modèle de gestion des pilotes est le pilote, qui est également la racine de l'agrégat dans lequel réside le pilote. Les attributs de l'entité conducteur incluent le nom, l'adresse e-mail, le numéro de contact, etc. En plus de l'entité conducteur, l'agrégation inclut également l'entité véhicule. Les attributs de l'entité véhicule incluent le fabricant, le modèle, la date de fabrication et la licence. numéro de la plaque.
La figure ci-dessous montre les entités du modèle.
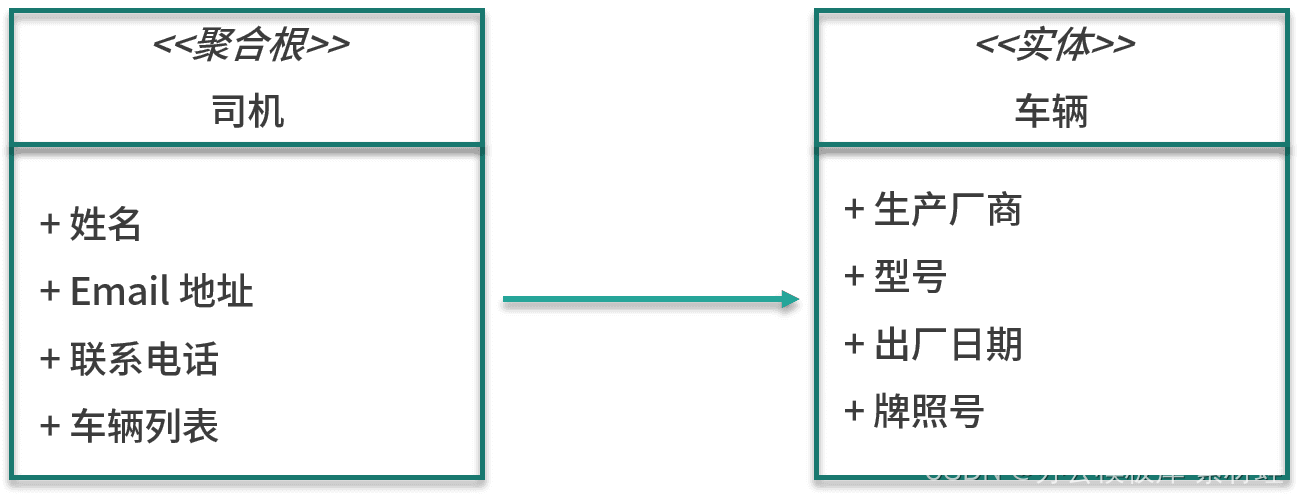 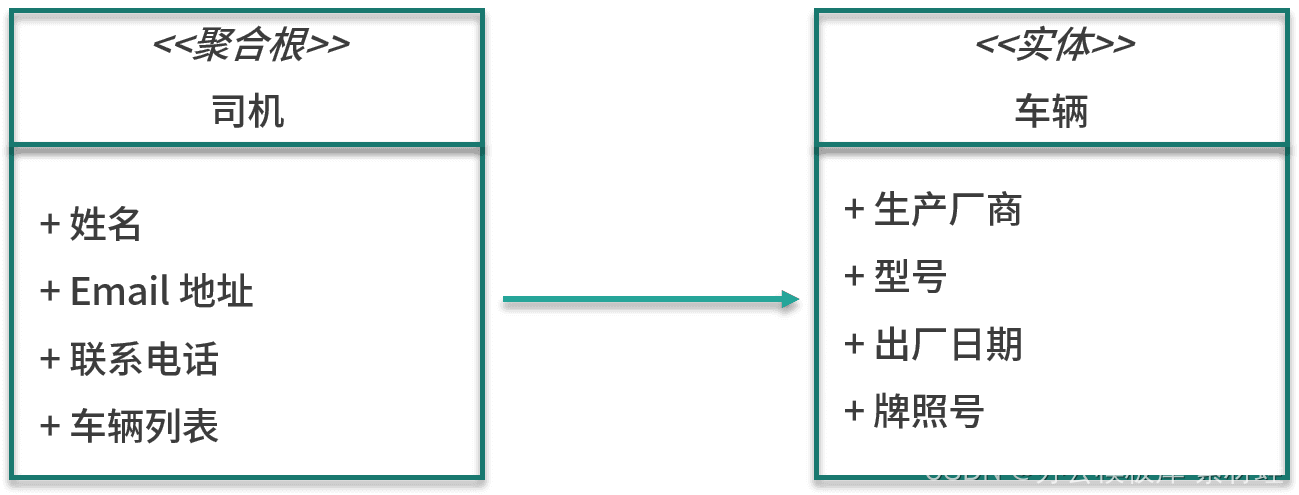

gestion des adresses
L'entité importante dans le modèle de gestion des adresses est l'adresse, qui est hiérarchique, allant des provinces, des municipalités et des régions autonomes aux villages et aux rues. En plus de l'adresse hiérarchique, il existe une autre information importante, à savoir les coordonnées géographiques de l'emplacement, y compris la longitude et la latitude.
vérification de l'itinéraire
Le modèle de vérification d'itinéraire ne contient pas d'entités spécifiques, mais des services et des implémentations d'algorithmes associés qui vérifient l'itinéraire.
gestion des paiements
Une entité importante dans le modèle de gestion des paiements est le dossier de paiement, qui contient des informations telles que les références aux itinéraires et le statut du paiement.
Interaction entre contextes délimités
Dans le modèle de notre contexte défini, l'entité d'itinéraire du modèle de répartition d'itinéraire doit faire référence à l'entité racine du « passager » agrégé dans le modèle de gestion des passagers, et à l'entité racine du « conducteur » agrégé dans le modèle de gestion du conducteur. . Dans la leçon 07, nous avons mentionné que les objets externes ne peuvent faire référence qu'à l'entité racine de l'agrégat, et lors du référencement, l'identifiant de l'entité racine de l'agrégat doit être référencé, pas l'entité elle-même. Les identifiants de l'entité Passager et de l'entité Conducteur sont tous deux de type chaîne, de sorte que l'entité Voyage contient deux propriétés de type Chaîne pour faire référence respectivement à l'entité Passager et à l'entité Conducteur.
Lorsque le même concept apparaît dans des modèles dans différents contextes délimités, le mappage est requis, et nous pouvons utiliser le mode de mappage de contexte mentionné dans la leçon 07 pour le mappage.
Dans les contextes de gestion d'adresses et d'expédition d'itinéraires, il y a la notion d'adresse. L'entité d'adresse dans la gestion des adresses est une structure complexe, comprenant des noms géographiques de différents niveaux, qui consiste à réaliser une sélection d'adresses à plusieurs niveaux et une requête d'adresse. Dans le cadre d'une expédition d'itinéraire, une adresse se compose simplement d'un nom complet et de coordonnées géographiques. Afin de mapper entre les deux contextes, nous pouvons ajouter une couche anti-corrosion au contexte de répartition des déplacements pour la conversion du modèle.
Migration d'applications monolithiques existantes
L'exemple d'application dans cette colonne est une nouvelle application créée à partir de zéro, il n'y a donc pas d'implémentation existante à laquelle se référer lors de la division des microservices. Lors de la migration d'une application monolithique existante vers une architecture de microservices, la division des microservices sera plus traçable. À partir de l'implémentation existante de l'application monolithique, vous pouvez en apprendre davantage sur l'interaction réelle de chaque partie du système, ce qui vous aidera à mieux comprendre. est bon de les répartir selon leurs responsabilités. Les microservices ainsi divisés sont plus proches de la situation de fonctionnement réelle.
Sam Newman de ThoughtWorks a partagé son expérience dans la division microservices du produit SnapCI dans son livre "Building Microservices".En raison de l'expérience pertinente du projet open source GoCD, l'équipe SnapCI a rapidement divisé les microservices de SnapCI. Cependant, il existe quelques différences entre les scénarios d'utilisation de GoCD et de SnapCI. Après un certain temps, l'équipe de SnapCI a constaté que la division actuelle des microservices posait de nombreux problèmes. Ils doivent souvent apporter des modifications à plusieurs microservices, ce qui entraîne des frais généraux élevés. . .
Ce que l'équipe SnapCI a fait, c'est de fusionner ces microservices en un seul monolithe, ce qui leur a donné plus de temps pour comprendre comment le système fonctionnait réellement. Un an plus tard, l'équipe de SnapCI a redivisé ce système monolithique en microservices. Après cette division, les frontières des microservices sont devenues plus stables. Cet exemple de SnapCI illustre que la connaissance du domaine est essentielle lors du partitionnement des microservices.
Résumer
Le partitionnement des microservices est crucial dans le développement d'applications de l'architecture des microservices. En appliquant l'idée de conception pilotée par le domaine, la division des microservices est transformée en division de sous-domaines dans la conception pilotée par le domaine, puis les concepts du domaine sont modélisés à travers le contexte défini. Les transformations de modèle peuvent être effectuées via des modèles de mappage entre des contextes définis.
Conférence 09 : Environnement et cadre de développement de déploiement rapide
Ce cours présentera le contenu lié à "l'environnement et le cadre de développement de déploiement rapide".
Au cours des heures de cours précédentes, nous avons présenté les connaissances de base liées à l'architecture de microservices cloud native, et les prochaines heures de cours entreront dans le développement réel des microservices. Ce cours est le premier cours lié au développement de microservices. Il se concentrera sur la préparation de l'environnement de développement local et présentera le framework, les bibliothèques tierces et les outils utilisés dans l'exemple d'application.
Nécessaire au développement
Les prérequis de développement font référence à ceux nécessaires à l'environnement de développement.
Java
Les microservices de l'exemple d'application sont développés sur la base de Java 8. Même si Java 14 a été publié, l'exemple d'application utilise toujours l'ancienne version de Java 8, car cette version est encore largement utilisée et les nouvelles fonctionnalités ajoutées après Java 8 ne sont pas utiles à l'exemple d'application. Si JDK 8 n'est pas installé, il est recommandé d'aller sur le site Web AdoptOpenJDK pour télécharger le programme d'installation d'OpenJDK 8. Sur MacOS et Linux, vous pouvez utiliser SDKMAN! pour installer JDK 8 et gérer différentes versions de JDK.
Voici la sortie de java -version :
openjdk version "1.8.0_242" OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_242-b08) OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.242-b08, mode mixte)
Maven
L'outil de génération utilisé par l'exemple d'application est Apache Maven. Vous pouvez installer manuellement Maven 3.6 ou utiliser l'outil Maven intégré dans l'IDE pour générer le projet. HomeBrew est recommandé pour MacOS et Linux , et Chocolatey est recommandé pour Windows .
Environnement de développement intégré
Un bon IDE peut grandement améliorer la productivité des développeurs. En termes d'IDE, il y a principalement deux choix : IntelliJ IDEA et Eclipse ; en termes de choix d'IDE, il n'y a pas beaucoup de différence entre les deux. J'utilise IntelliJ IDEA Community Edition 2020.
Docker
L'environnement de développement local doit utiliser Docker pour exécuter les services de support requis par l'application, y compris la base de données et le middleware de messagerie. Grâce à Docker, le problème d'installation de différents services logiciels est résolu, ce qui rend la configuration de l'environnement de développement très simple. D'autre part, l'environnement de production et d'exécution de l'application est Kubernetes, qui est également déployé à l'aide de la conteneurisation, ce qui garantit la cohérence entre l'environnement de développement et l'environnement de production. Afin de simplifier le processus de développement local, Docker Compose est utilisé dans l'environnement local pour l'orchestration des conteneurs.
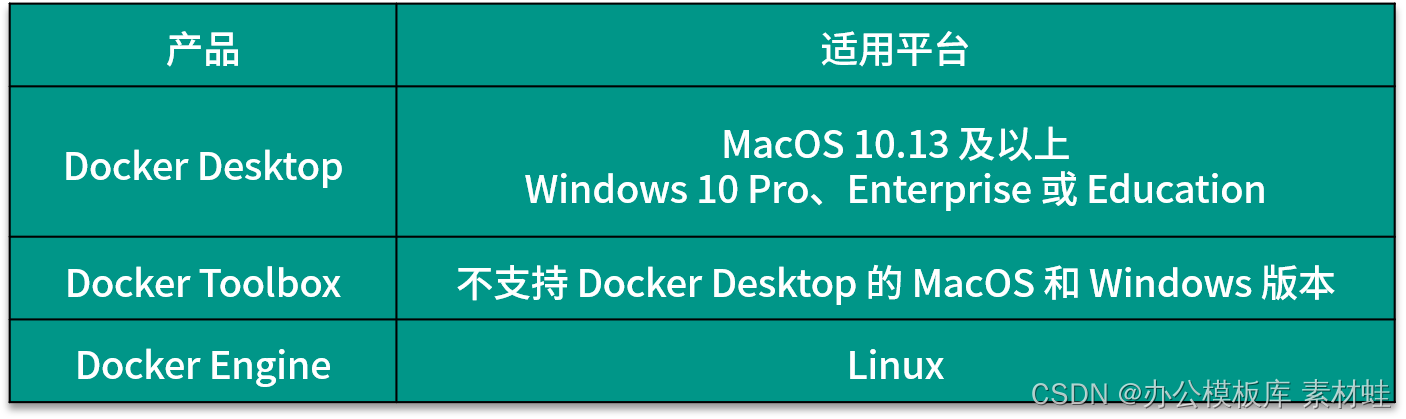
Selon le système d'exploitation de l'environnement de développement, la manière d'installer Docker est différente. Il existe 3 produits Docker différents qui peuvent être utilisés pour installer Docker, à savoir Docker Desktop, Docker Toolbox et Docker Engine.Le tableau suivant présente les plates-formes applicables de ces 3 produits. Pour MacOS et Windows, si la version le prend en charge, Docker Desktop doit être installé en premier, puis Docker Toolbox doit être pris en compte.
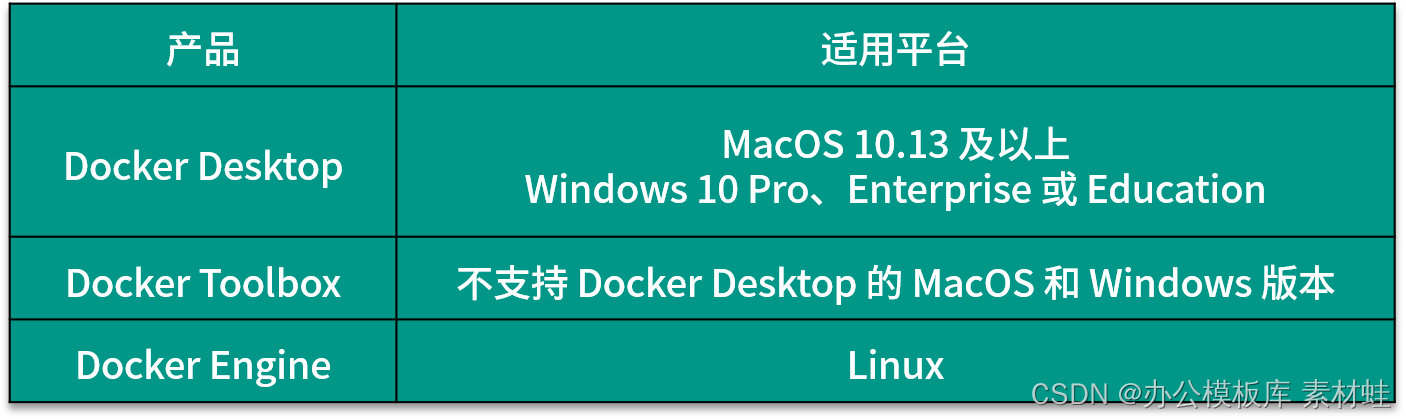 

Le produit Docker Desktop comprend de nombreux composants, notamment Docker Engine, Docker Command Line Client, Docker Compose, Notary, Kubernetes et Credential Helper. L'avantage de Docker Desktop est qu'il peut utiliser directement le support de virtualisation fourni par le système d'exploitation, ce qui peut fournir une meilleure intégration.De plus, Docker Desktop fournit également une interface de gestion graphique. La plupart du temps, nous exploitons Docker via la ligne de commande docker. Si la commande docker -v peut afficher les informations de version correctes, cela signifie que Docker Desktop est installé avec succès.
La figure ci-dessous montre les informations de version de Docker Desktop.
 

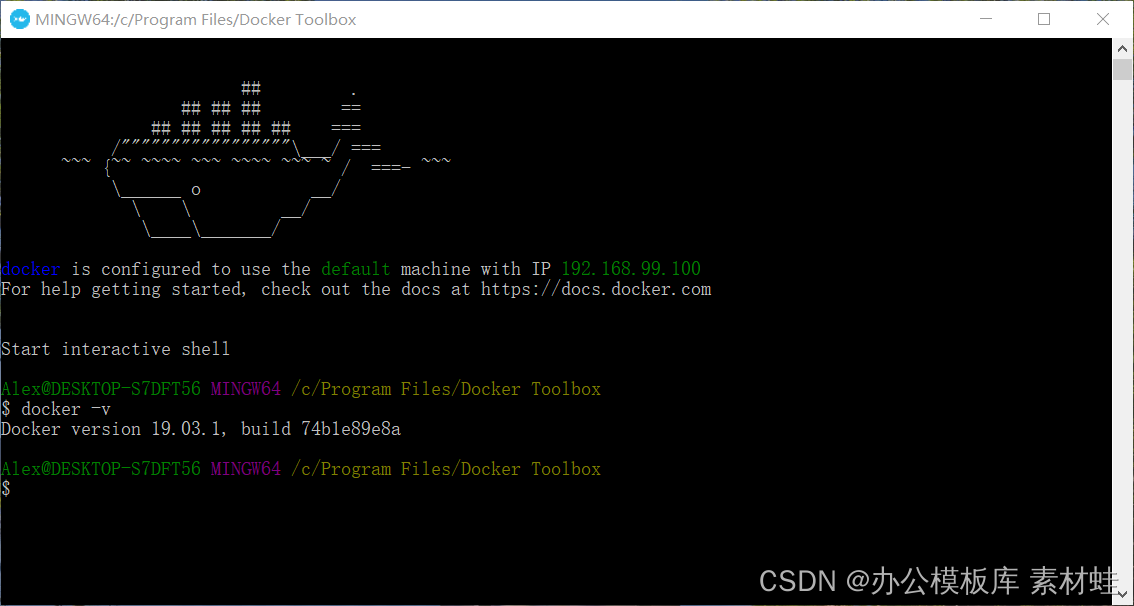
Docker Toolbox est le prédécesseur de Docker Desktop. Docker Toolbox utilise VirtualBox pour la virtualisation, dont la configuration système est faible. Docker Toolbox comprend Docker Machine, Docker Command Line Client, Docker Compose, Kitematic et Docker Quickstart Terminal. Une fois l'installation terminée, lancez un terminal via Docker Quickstart pour exécuter les commandes Docker.
La figure ci-dessous est l'effet de fonctionnement du terminal Docker Quickstart.

Sous Linux, nous ne pouvons installer Docker Engine que directement, et nous devons également installer manuellement Docker Compose.
Il existe une différence significative dans l'utilisation de Docker Desktop et de Docker Toolbox. Le conteneur s'exécutant sur Docker Desktop peut utiliser le réseau sur l'hôte de l'environnement de développement actuel, et le port exposé par le conteneur est accessible à l'aide de localhost ; le conteneur s'exécutant sur Docker Toolbox s'exécute en fait sur une machine virtuelle de VirtualBox, à laquelle il faut accéder via l'adresse IP de la machine virtuelle pour y accéder. Nous pouvons obtenir l'adresse IP via la commande docker-machine ip sur le terminal démarré par Docker Quickstart, par exemple 192.168.99.100. Le port exposé par le conteneur doit être accessible à l'aide de cette adresse IP, qui n'est pas fixe. La pratique recommandée consiste à ajouter un nom d'hôte appelé dockervm dans le fichier hosts et à pointer vers cette adresse IP. Utilisez toujours le nom d'hôte dockervm lors de l'accès aux services dans les conteneurs. Lorsque l'adresse IP de la machine virtuelle change, seul le fichier hosts doit être mis à jour.
Kubernetes
Lors du déploiement d'applications, nous avons besoin d'un cluster Kubernetes disponible. Généralement, il existe trois façons de créer un cluster Kubernetes.
La première consiste à utiliser la plate-forme cloud pour créer des fichiers . De nombreuses plates-formes cloud prennent en charge Kubernetes. La plate-forme cloud est responsable de la création et de la gestion des clusters Kubernetes. Il vous suffit d'utiliser l'interface Web ou les outils de ligne de commande pour créer rapidement des clusters Kubernetes. L'avantage d'utiliser la plate-forme cloud est qu'elle permet d'économiser du temps et des efforts, mais qu'elle coûte cher.
La deuxième méthode consiste à installer un cluster Kubernetes sur une machine virtuelle ou un bare metal physique . La machine virtuelle peut être fournie par la plate-forme cloud, ou elle peut être créée et gérée par elle-même, et il est également possible d'utiliser le cluster physique bare-metal maintenu par lui-même. Il existe de nombreux outils d'installation open source de Kubernetes, tels que RKE , Kubespray , Kubicorn , etc. L'avantage de cette méthode est que la surcharge est relativement faible, mais l'inconvénient est qu'elle nécessite une pré-installation et une post-maintenance.
La troisième méthode consiste à installer Kubernetes sur l'environnement de développement local . Docker Desktop est déjà livré avec Kubernetes, il vous suffit de l'activer. De plus, vous pouvez également installer Minikube . L'avantage de cette approche est qu'elle a le moins de frais généraux et qu'elle est hautement contrôlable, mais l'inconvénient est qu'elle mobilise beaucoup de ressources dans l'environnement de développement local.
Parmi les trois méthodes ci-dessus, la méthode de la plateforme cloud est adaptée au déploiement de l'environnement de production. Pour l'environnement de test et de préparation de la livraison (mise en scène), vous pouvez choisir une plate-forme cloud ou vous pouvez choisir de créer vous-même l'environnement du point de vue du coût. Kubernetes sur l'environnement de développement local est également nécessaire dans de nombreux cas.
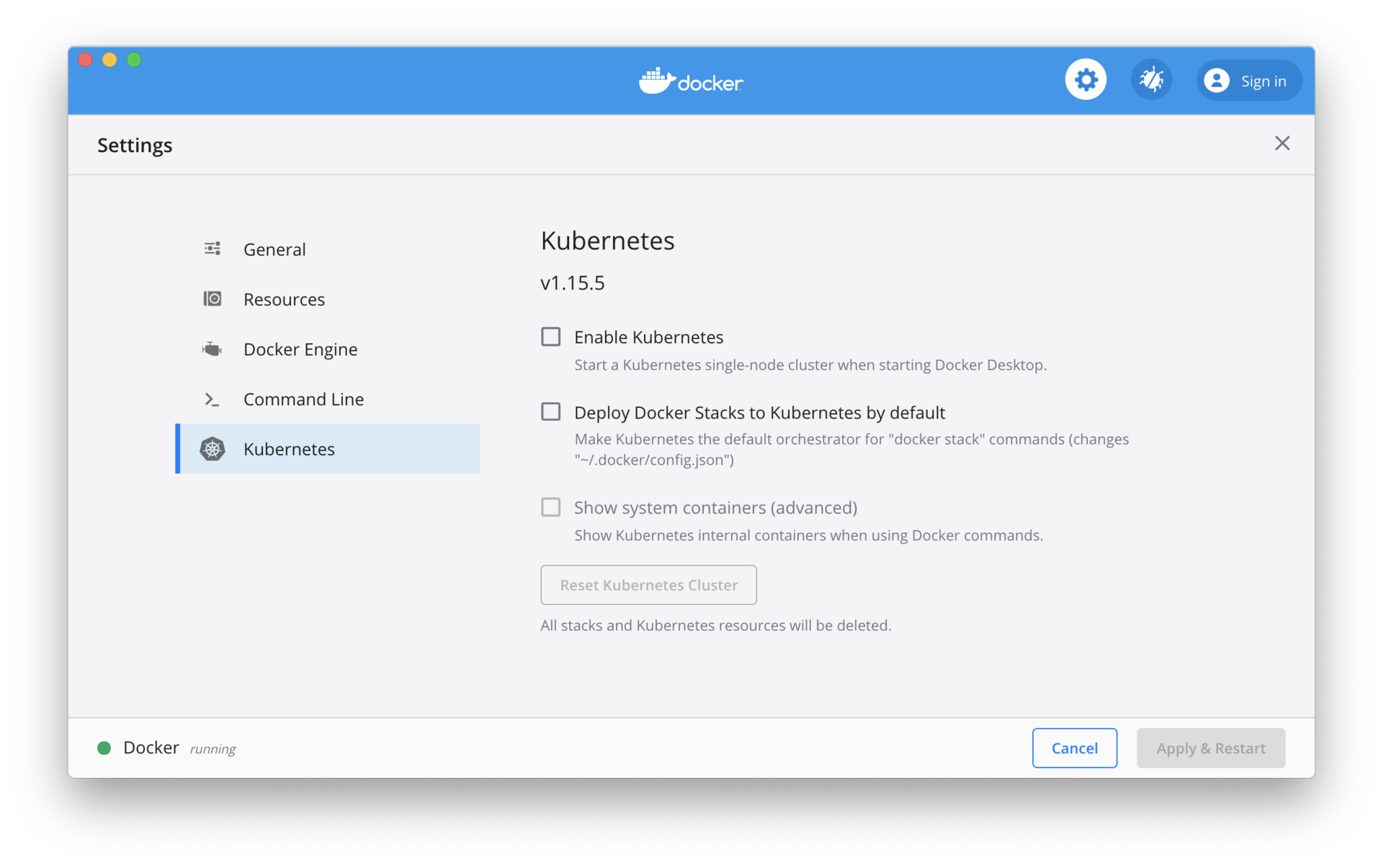
Dans un environnement de développement local, Kubernetes pour Docker Desktop doit être activé manuellement. Pour Minikube, vous pouvez vous référer à la documentation officielle pour l'installer. La différence entre les deux est que la version de Kubernetes fournie avec Docker Desktop a généralement quelques versions mineures derrière. Comme indiqué dans la figure ci-dessous, cochez l'option "Activer Kubernetes" pour démarrer le cluster Kubernetes. La version de Kubernetes fournie avec Docker Desktop est la 1.15.5 et la dernière version de Kubernetes est la 1.18.

Frameworks et bibliothèques tierces
L'exemple d'application utilise des frameworks et des bibliothèques tierces, qui sont brièvement présentés ci-dessous.
Spring Framework et Spring Boot
Il est difficile de développer des applications Java sans le framework Spring. Spring Boot est également l'un des choix les plus populaires pour le développement de microservices en Java à l'heure actuelle.L'introduction de Spring et Spring Boot dépasse le cadre de cet article. Les microservices de l'exemple d'application utiliseront certains sous-projets du framework Spring, notamment Spring Data JPA, Spring Data Redis et Spring Security.
Tramway événementiel
Eventuate Tram est une structure de message transactionnel utilisée par l'exemple d'application. Le mode de message transactionnel joue un rôle important dans le maintien de la cohérence des données. Eventuate Tram prend en charge les modèles de messagerie transactionnelle et inclut également la prise en charge de la messagerie asynchrone. Eventuate Tram s'intègre à PostgreSQL et Kafka.
Serveur et framework Axon
L'exemple d'application utilise également l'approvisionnement en événements et la technologie CQRS, et l'implémentation de l'approvisionnement en événements utilise le serveur Axon et le framework Axon. Le serveur Axon fournit le stockage des événements ; le framework Axon se connecte au serveur Axon et fournit la prise en charge de CQRS.
Services et outils d'assistance
Les services de support de l'exemple d'application sont nécessaires lors de l'exécution et les outils associés peuvent être utilisés lors du développement.
Apache Kafka et ZooKeeper
L'exemple d'application utilise des messages asynchrones entre différents microservices pour assurer la cohérence finale des données. Un middleware de message est donc requis. Apache Kafka est le middleware de messagerie utilisé dans l'exemple d'application, et ZooKeeper est requis pour exécuter Kafka.
PostgreSQLName
Certains des microservices de l'exemple d'application utilisent une base de données relationnelle pour stocker les données. Parmi de nombreuses bases de données relationnelles, PostgreSQL est choisi comme base de données pour certains microservices dans l'exemple d'application.
outil de gestion de base de données
En développement, nous pouvons avoir besoin de visualiser les données dans une base de données relationnelle. De nombreux clients PostgreSQL sont disponibles, notamment DBeaver , pgAdmin 4 , OmniDB, etc. Vous pouvez également utiliser des plug-ins IDE, tels que le plug-in Database Navigator sur IntelliJ IDEA.
Facteur
Lors du développement et des tests, nous devons souvent envoyer des requêtes HTTP pour tester les services REST. Il existe de nombreux outils liés au test des services REST, tels que Postman , Insomnia et Advanced REST Client . Je recommande d'utiliser Postman car il peut directement importer des fichiers de spécification OpenAPI et générer des modèles de requête REST correspondants. Étant donné que nos microservices adoptent une approche de conception axée sur l'API, chaque API de microservice a un fichier de spécification OpenAPI correspondant. Pendant le développement, nous n'avons qu'à importer le fichier OpenAPI dans Postman, puis nous pouvons commencer les tests, en épargnant le travail de création manuelle des demandes.
Résumer
Avant d'expliquer le combat réel, nous devons d'abord préparer l'environnement de développement local. Ce cours présente d'abord comment installer et configurer Java, Maven, l'environnement de développement intégré, Docker et Kubernetes ; puis présente brièvement le framework et les bibliothèques tierces utilisées dans l'exemple d'application ; enfin présente les services de support utilisés par l'exemple d'application, et les outils nécessaires au développement.
Conférence 10 : Conception d'API d'abord avec OpenAPI et Swagger
À partir de ce cours, nous entrerons dans le développement proprement dit d'applications d'architecture de microservices cloud-native.Avant d'introduire l'implémentation spécifique des microservices, la première tâche consiste à concevoir et déterminer l'API ouverte de chaque microservice . L'API ouverte a été très populaire ces dernières années, et de nombreux services en ligne et agences gouvernementales ont fourni une API ouverte, qui est devenue une fonction standard des services en ligne. Les développeurs peuvent utiliser l'API ouverte pour développer diverses applications.
Bien qu'il existe une certaine relation entre l'API ouverte dans l'application de microservice et l'API ouverte dans le service en ligne, leurs fonctions sont différentes. Dans l'application de l'architecture de microservices, les microservices ne peuvent interagir que par le biais d'une communication inter-processus, généralement en utilisant REST ou gRPC. Une telle méthode d'interaction doit être fixée de manière formalisée, formant une API ouverte. Une API ouverte d'un microservice protège les détails d'implémentation interne du service des utilisateurs externes, et est également le seul moyen pour les utilisateurs externes d'interagir avec lui ( bien sûr, ici fait référence à l'intégration entre les microservices uniquement via l'API, si des événements asynchrones sont utilisés pour l'intégration, ces événements sont également interactifs). À partir de là, nous pouvons voir l'importance de l'API de microservice. Du point de vue du public, les utilisateurs des API de microservices sont principalement d'autres microservices, c'est-à-dire principalement des utilisateurs internes de l'application, ce qui est différent de l'API des services en ligne, qui sont principalement orientés vers des utilisateurs externes. En plus d'autres microservices, l'interface Web de l'application et les clients mobiles doivent également utiliser l'API du microservice, mais ils utilisent généralement l'API du microservice via une passerelle API.
En raison de l'importance de l'API de microservice, nous devons concevoir l'API très tôt, c'est-à-dire la stratégie API-first.
Une stratégie axée sur l'API
Si vous avez de l'expérience dans le développement d'API de services en ligne, vous constaterez que la mise en œuvre vient généralement en premier, suivie de l'API publique, car l'API publique n'a pas été prise en compte avant la conception, mais a été ajoutée plus tard. Le résultat de cette approche est que l'API ouverte ne reflète que l'implémentation réelle actuelle, et non ce que l'API devrait être. La méthode de conception de l'API d'abord (API First) consiste à placer la conception de l'API avant l'implémentation spécifique. L'API souligne d'abord que la conception de l'API doit être davantage considérée du point de vue des utilisateurs de l'API.
Avant d'écrire la première ligne de code d'implémentation, le fournisseur d'API et l'utilisateur doivent avoir une discussion complète sur l'API, combiner les opinions des deux parties, déterminer enfin tous les détails de l'API et les corriger dans un format formel pour devenir une spécification d'API. Après cela, le fournisseur de l'API s'assure que l'implémentation réelle répond aux exigences de la spécification de l'API, et l'utilisateur écrit l'implémentation du client conformément à la spécification de l'API. La spécification API est un contrat entre le fournisseur et l'utilisateur, et la stratégie API-first a été appliquée dans le développement de nombreux services en ligne. Une fois l'API conçue et mise en œuvre, l'interface Web et l'application mobile du service en ligne lui-même, comme d'autres applications tierces, sont mises en œuvre à l'aide de la même API.
La stratégie API-first joue un rôle plus important dans la mise en œuvre de l'application de l'architecture de microservice. Il faut ici distinguer deux types d'API : l'une est l'API fournie pour les autres microservices, et l'autre est l'API fournie pour l'interface web et les clients mobiles. Lors de l'introduction de la conception pilotée par le domaine dans la 07e classe, j'ai mentionné le service d'hôte ouvert et le langage public dans le mode de mappage du contexte délimité, et les microservices correspondent au contexte délimité un à un. Si vous combinez le service hôte ouvert avec le langage commun, vous obtenez l'API du microservice, et le langage commun est la spécification de l'API.
À partir de là, nous pouvons savoir que le but du premier type d'API de microservice est le mappage de contexte, ce qui est très différent du rôle du deuxième type d'API. Par exemple, le microservice de gestion des passagers fournit des fonctions de gestion des passagers, notamment l'enregistrement des passagers, la mise à jour des informations et la requête. Pour l'application passager, ces fonctions nécessitent le support de l'API. Si d'autres microservices ont besoin d'obtenir des informations sur les passagers, ils doivent également appeler l'API du microservice de gestion des passagers. Il s'agit de cartographier le concept de passagers entre différents microservices.
Implémentation de l'API
Dans l'implémentation de l'API, l'un des premiers problèmes est de choisir la méthode d'implémentation de l'API. En théorie, les API internes des microservices n'ont pas d'exigences élevées en matière d'interopérabilité et peuvent utiliser des formats privés. Cependant, pour utiliser la grille de services, il est recommandé d'utiliser un format standard commun. Le tableau suivant montre le format d'API commun. Choisissez généralement entre REST et gRPC, sauf en utilisant moins de SOAP. La différence entre les deux est que REST utilise un format texte et que gRPC utilise un format binaire ; les deux diffèrent par leur popularité, leur difficulté de mise en œuvre et leurs performances. En bref, REST est relativement plus populaire et moins difficile à mettre en œuvre, mais ses performances ne sont pas aussi bonnes que gRPC.
 

L'API de l'exemple d'application dans cette colonne est implémentée à l'aide de REST, bien qu'il y ait une classe consacrée à gRPC. Ce qui suit décrit la spécification OpenAPI liée à l'API REST.
Spécification OpenAPI
Afin de mieux communiquer entre les fournisseurs d'API et les utilisateurs, nous avons besoin d'un format standard pour décrire les API. Pour les API REST, ce format standard est défini par la spécification OpenAPI.
La spécification OpenAPI (OAS) est une spécification d'API ouverte gérée par l'OpenAPI Initiative (OAI) sous la Linux Foundation. L'objectif de l'OAI est de créer, faire évoluer et promouvoir un format de description d'API indépendant du fournisseur. La spécification OpenAPI est basée sur la spécification Swagger, offerte par SmartBear Corporation.
Le document OpenAPI décrit ou définit l'API, et le document OpenAPI doit répondre à la spécification OpenAPI. La spécification OpenAPI définit le format de contenu d'un document OpenAPI, c'est-à-dire les objets et leurs attributs qui peuvent y être contenus. Un document OpenAPI est un objet JSON qui peut être représenté au format de fichier JSON ou YAML. Ce qui suit est une introduction au format du document OpenAPI. Les exemples de code de cette leçon utilisent tous le format YAML.
Plusieurs types de base sont définis dans la spécification OpenAPI, à savoir entier, nombre, chaîne et booléen. Pour chaque type de base, le format spécifique du type de données peut être spécifié via le champ de format, par exemple, le format du type de chaîne peut être date, date-heure ou mot de passe.
Les champs et leurs descriptions pouvant apparaître dans l'objet racine du document OpenAPI sont donnés dans le tableau ci-dessous La dernière version de la spécification OpenAPI est la 3.0.3.
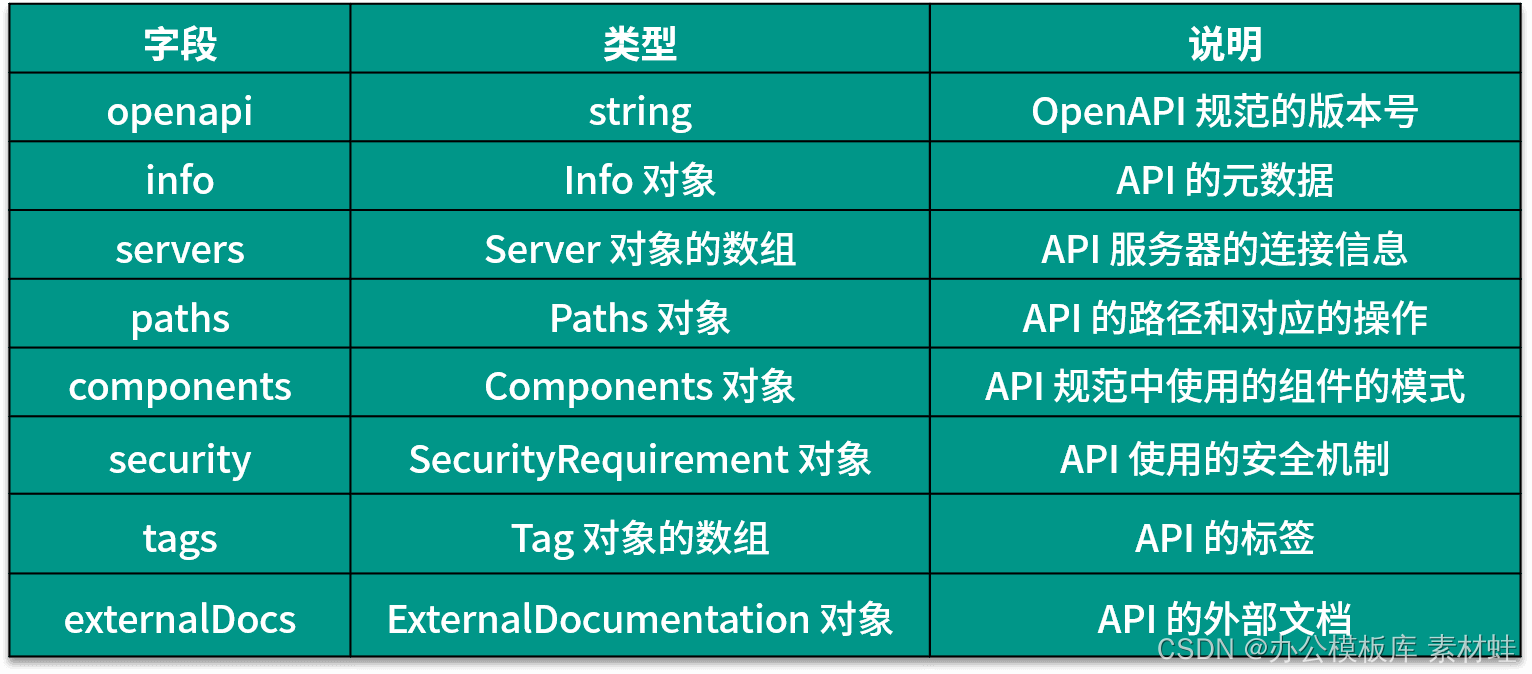 

Objet d'information
L'objet Info contient les métadonnées de l'API, qui peuvent aider les utilisateurs à mieux comprendre les informations pertinentes de l'API. Le tableau suivant montre les champs qui peuvent être inclus dans l'objet Info et leurs descriptions.
 

Le code suivant est un exemple d'utilisation de l'objet Info.
titre : description du service de test : ce service est utilisé pour des tests simples TermsOfService : http://myapp.com/terms/ contact : nom : administrateur URL : http://www.myapp.com/support e-mail : support@myapp .com licence : nom : Apache 2.0 url : https://www.apache.org/licenses/LICENSE-2.0.html version : 2.1.0
Objet serveur
L'objet Server représente le serveur de l'API. Le tableau suivant présente les champs qui peuvent être inclus dans l'objet Server et leurs descriptions.
 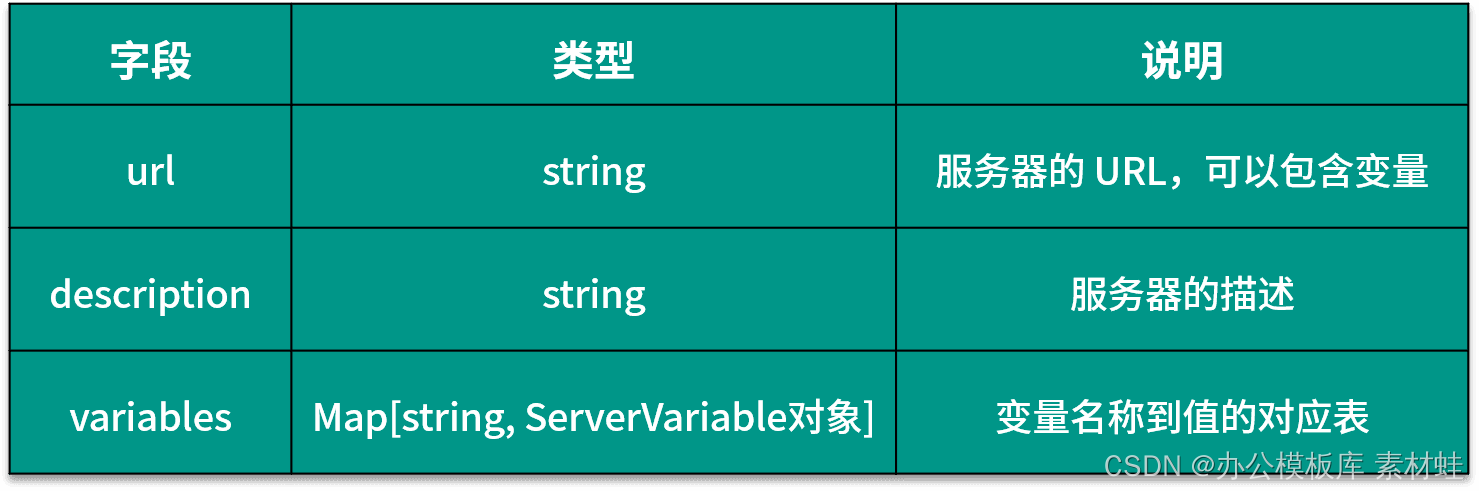

Le code suivant est un exemple d'utilisation de l'objet Server, où l'URL du serveur contient deux paramètres, port et basePath, port est un type d'énumération et les valeurs facultatives sont 80 et 8080.
url : http://test.myapp.com :{port}/{basePath}
description : Tester
les variables du serveur :
port :
enum :
- '80'
- '8080'
par défaut : '80'
basePath :
par défaut : v2
Objet Chemins
Les champs de l'objet Paths sont dynamiques. Chaque champ représente un chemin, commençant par "/", le chemin peut être un modèle de chaîne contenant des variables. La valeur du champ est un objet PathItem, dans lequel vous pouvez utiliser des champs communs tels que résumé, description, serveurs et paramètres, et des noms de méthode HTTP, y compris get, put, post, delete, options, head, patch et trace , qui Le champ de nom de méthode définit les méthodes HTTP prises en charge par le chemin correspondant.
Objet opération
Dans l'objet Paths, le type valeur du champ correspondant à la méthode HTTP est un objet Operation, représentant une opération HTTP. Le tableau suivant présente les champs et leurs descriptions qui peuvent être inclus dans l'objet Operation. Parmi ces champs, les paramètres, requestBody et les réponses sont plus couramment utilisés.
 

Objet paramètre
Un objet Parameter représente les paramètres d'une opération. Le tableau suivant montre les champs qui peuvent être inclus dans un objet Parameter et leurs descriptions.
 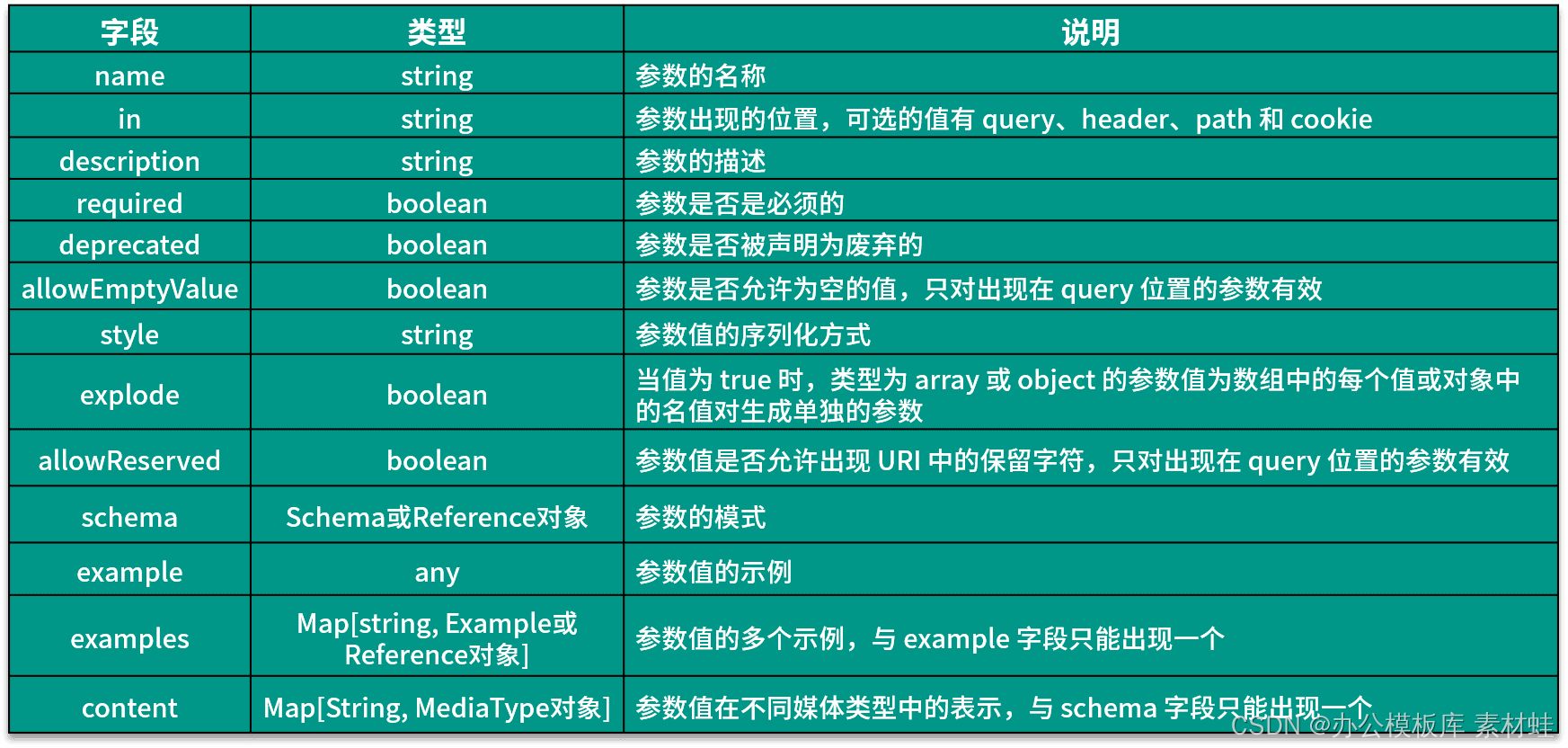

Le code suivant est un exemple d'utilisation de l'objet Parameter. L'ID de paramètre apparaît dans le chemin d'accès et son type est chaîne.
nom : id dans : description du chemin : 乘客ID requis : vrai schéma : type : chaîne
Objet RequestBodyRequestBody object
L'objet RequestBody représente le contenu de la requête HTTP. Le tableau suivant montre les champs qui peuvent être inclus dans l'objet RequestBody et leurs descriptions.
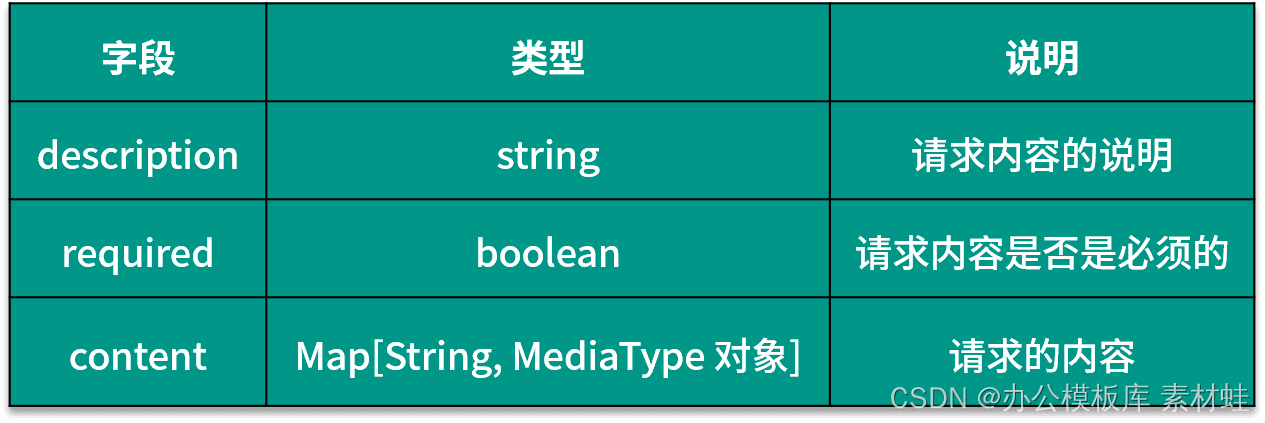 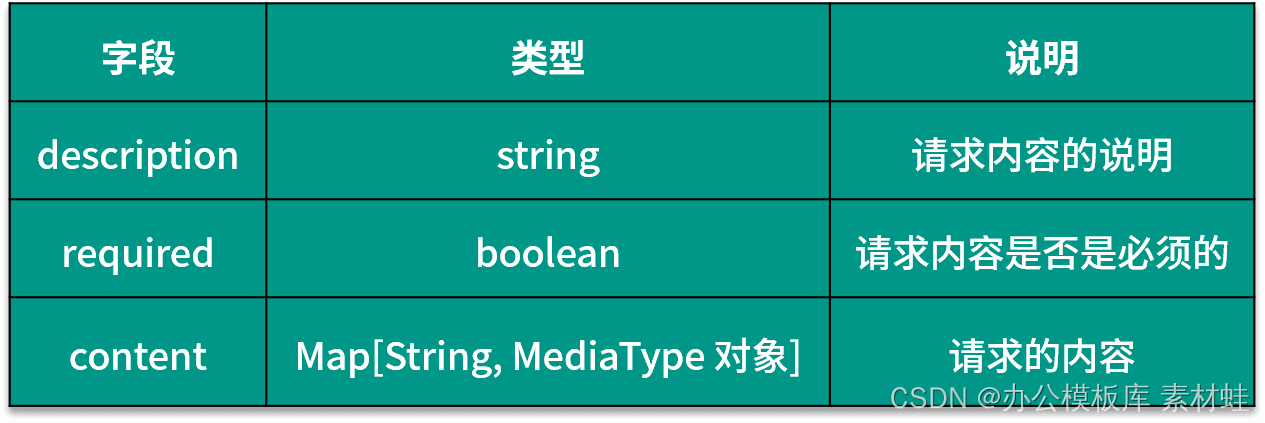

Objet Réponses
L'objet Responses représente la réponse à la requête HTTP et les champs de cet objet sont dynamiques. Le nom du champ est le code d'état de la réponse HTTP et le type de la valeur correspondante est un objet Response ou Reference. Le tableau suivant montre les champs qui peuvent être inclus dans l'objet Response et leurs descriptions.
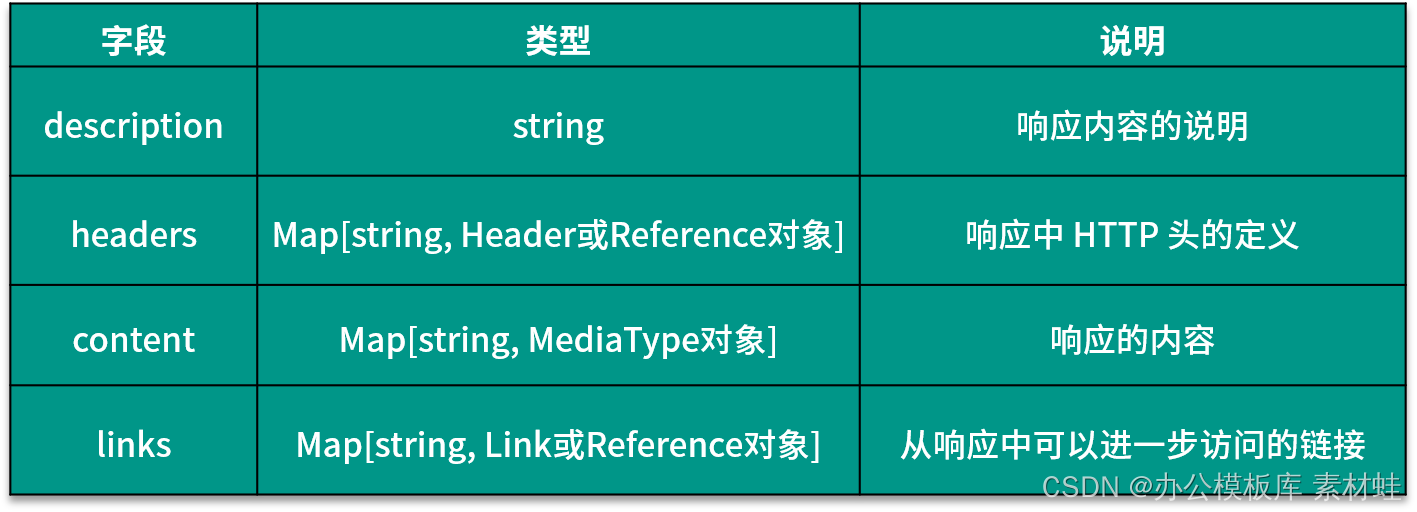 

Objet de référence
Dans la description des différents types d'objets, le type du champ peut être un objet Reference, qui représente une référence à d'autres composants, qui ne contient qu'un champ $ref pour déclarer la référence. Les références peuvent provenir de composants dans le même document ou de fichiers externes. Dans le document, différents types de composants réutilisables peuvent être définis dans l'objet Components et référencés par l'objet Reference ; la référence à l'intérieur du document est un chemin d'objet commençant par #, tel que #/components/schemas/CreateTripRequest.
Objet de schéma
L'objet Schéma est utilisé pour décrire la définition du type de données. Le type de données peut être un type simple, un tableau ou un type d'objet. Le type peut être spécifié via le type de champ, et le champ de format indique le format du type . S'il s'agit d'un type tableau, c'est-à-dire que la valeur de type est tableau, vous devez utiliser les éléments de champ pour représenter le type des éléments du tableau ; s'il s'agit d'un type objet, c'est-à-dire que la valeur de type est objet , vous devez utiliser les propriétés du champ pour représenter le type de propriétés dans l'objet.
Exemple de documentation complète
Vous trouverez ci-dessous un exemple de document OpenAPI complet. Dans l'objet paths, trois opérations sont définies, et la définition de type du contenu de la demande et du format de réponse de l'opération est définie dans le champ schemas de l'objet Components. Les champs requestBody et les réponses d'une opération sont référencés à l'aide d'un objet Reference.
openapi: '3.0.3'
info:
title: Trip service
version: '1.0'
servers:
- url: http://localhost:8501/api/v1
tags:
- name: trip
description: Trip related
paths:
/:
post:
balises :
-
résumé du voyage : créer
un ID d'opération de voyage : createTrip
requestBody :
contenu :
application/json :
schéma :
$ref : "#/components/schemas/CreateTripRequest"
requis :
réponses vraies :
'201' :
description : créé avec succès
/{tripId} :
obtenir :
tags:
- résumé du trajet
:
get trip
operationId :
paramètres getTrip :
-
name : tripId
in
: description du chemin
:
ID
du
trajet
requis
:
vrai
$ref : "#/components/schemas/TripVO"
'404' :
description : Trip not found
/{tripId}/accept :
post :
tags :
- trip
récapitulatif
: 接受行程
operationId : acceptTrip
paramètres :
-
nom
: tripId
dans :
description
du chemin
:
行程
ID
requis
: vrai
réponses :
'200' :
description : 接受成功
components :
schémas :
CreateTripRequest :
type :
propriétés de l'objet :
PassengerId :
type : chaîne
startPos :
$ref : "#/components/schemas/PositionVO"
endPos :
$ref : "#/components/schemas/PositionVO"
requis :
- PassengerId
- startPos
- endPos
AcceptTripRequest :
type :
propriétés de l'objet :
driverId :
type : chaîne
posLng :
type :
format de nombre : double
posLat :
type :
format de nombre : double
requis :
- driverId
- posLng
- posLat
TripVO :
type :
addressId :
propriétés :
id :
type : chaîne
PassengerId :
type : chaîne
DriverId :
type : chaîne
startPos :
$ref : « #/components/schemas/PositionVO »
endPos :
$ref : « #/components/schemas/PositionVO »
state :
type : chaîne
PositionVO :
type :
propriétés de l'objet :
lng :
type :
format de nombre : double
lat :
type :
format de nombre : double
type : chaîne
requise :
-lng
-lat
Outils OpenAPI
Nous pouvons utiliser certains outils pour assister le développement lié à la spécification OpenAPI. En tant que prédécesseur de la spécification OpenAPI, Swagger fournit de nombreux outils liés à OpenAPI.
Éditeur fanfaron
Swagger Editor est une version Web de l'éditeur de documentation Swagger et OpenAPI. Sur le côté gauche de l'éditeur se trouve l'éditeur et sur la droite se trouve un aperçu de la documentation de l'API. L'éditeur Swagger fournit de nombreuses fonctions utiles, notamment la coloration syntaxique, l'ajout rapide de différents types d'objets, la génération de code serveur et la génération de code client, etc.
Lorsque vous utilisez l'éditeur Swagger, vous pouvez utiliser la version en ligne directement ou l'exécuter localement. Le moyen le plus simple de l'exécuter localement consiste à utiliser l'image Docker swaggerapi/swagger-editor.
Le code suivant démarre le conteneur Docker de l'éditeur Swagger. Une fois le conteneur démarré, il est accessible via localhost:8000.
docker run -d -p 8000:8080 swaggerapi/swagger-editor
La figure ci-dessous est l'interface de l'éditeur Swagger.
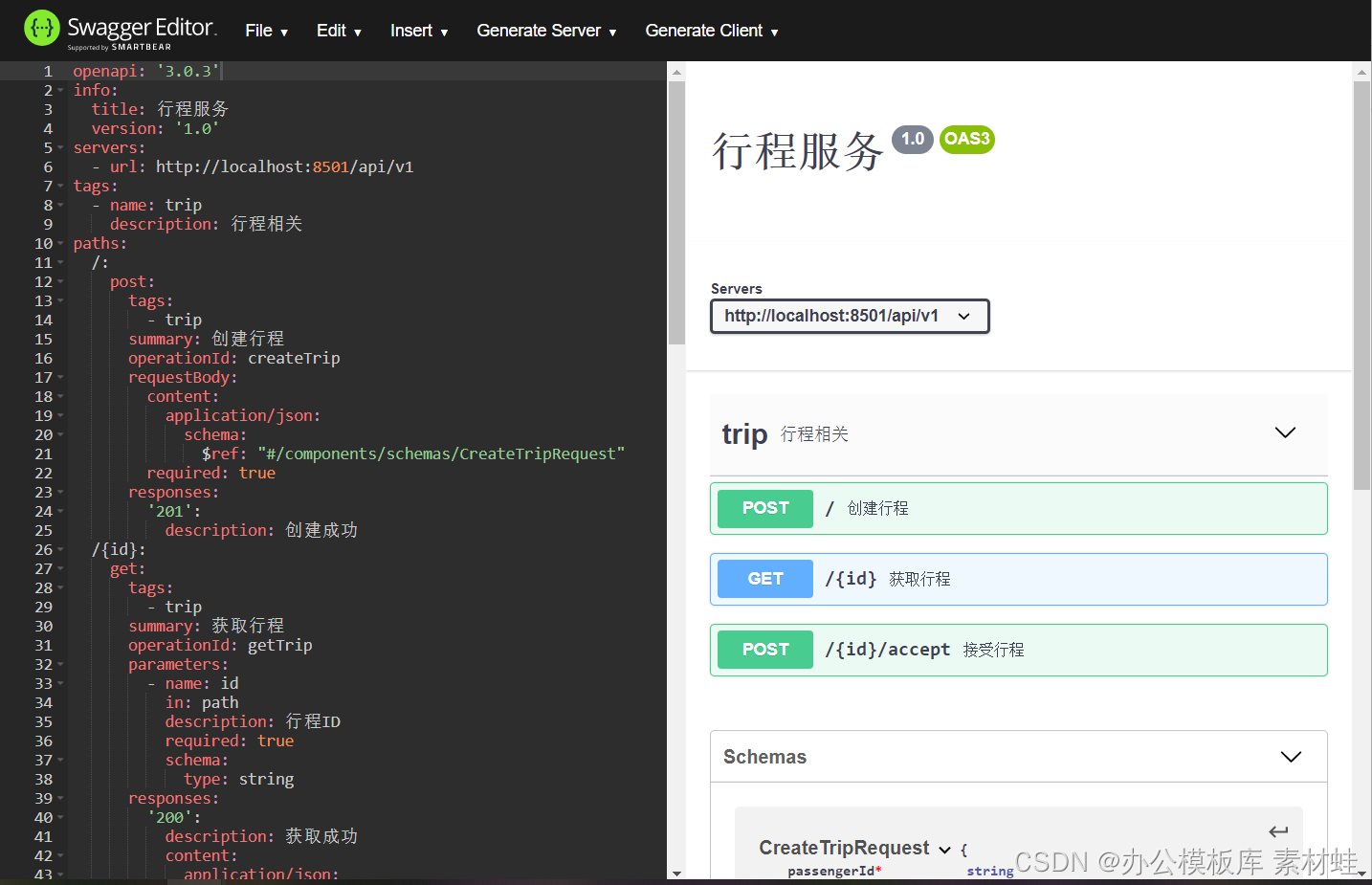 

Interface fanfaronne
L'interface Swagger offre un moyen intuitif de visualiser et d'interagir avec la documentation de l'API. Grâce à cette interface, vous pouvez envoyer directement des requêtes HTTP au serveur d'API et afficher les résultats de la réponse.
De même, nous pouvons utiliser Docker pour démarrer l'interface Swagger comme indiqué dans la commande ci-dessous. Une fois le conteneur démarré, il est accessible via localhost:8010.
docker run -d -p 8010:8080 swaggerapi/swagger-ui
Pour la documentation OpenAPI locale, une image Docker peut être configurée pour utiliser cette documentation. En supposant qu'il existe un document OpenAPI openapi.yml dans le répertoire actuel, vous pouvez utiliser la commande suivante pour démarrer l'image Docker afin d'afficher le document.
docker run -p 8010:8080 -e SWAGGER_JSON=/api/openapi.yml -v $PWD:/api swaggerapi/swagger-ui
La figure ci-dessous est une capture d'écran de l'interface Swagger.
 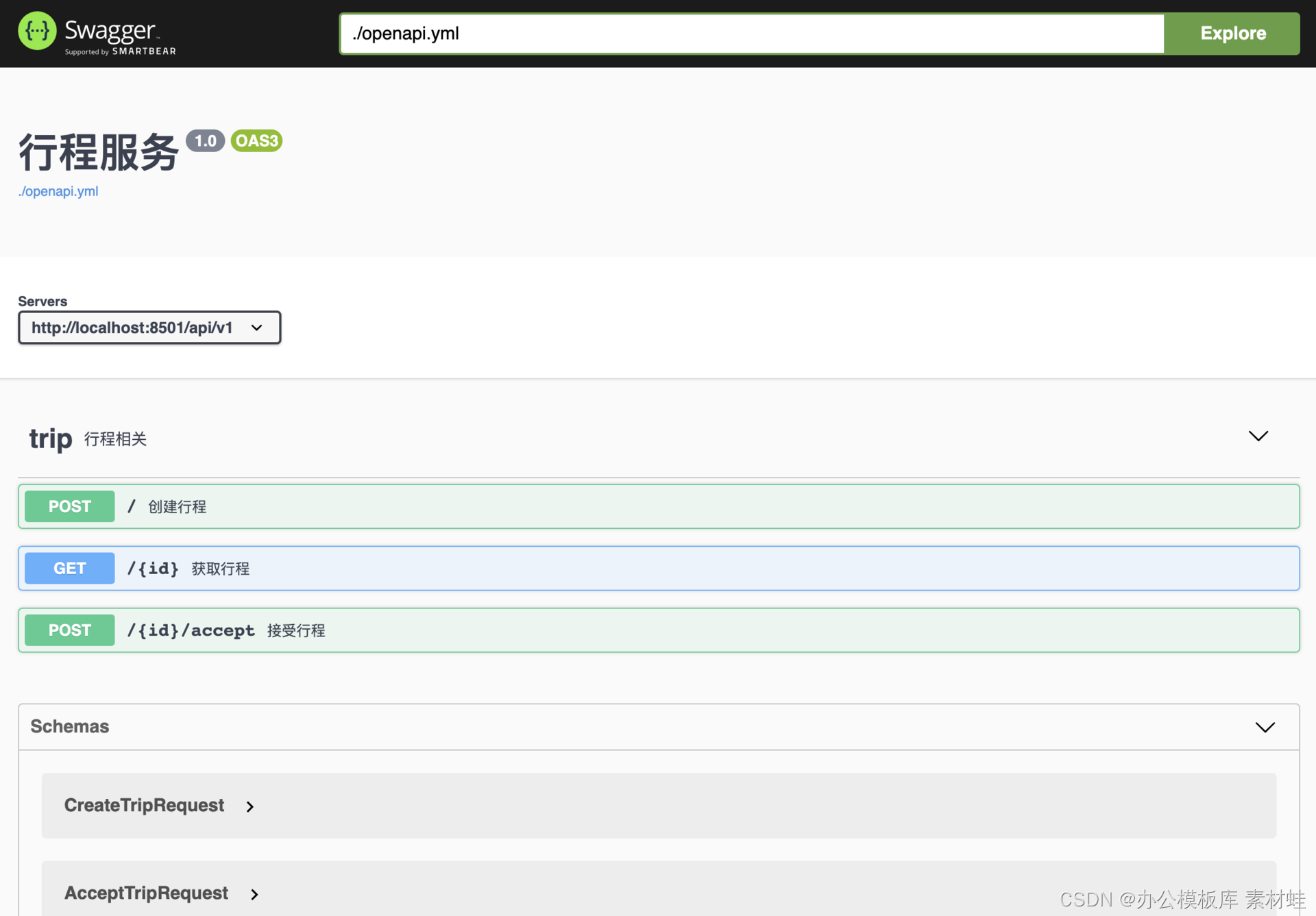

génération de code
Grâce au document OpenAPI, vous pouvez utiliser l'outil de génération de code fourni par Swagger pour générer automatiquement le code stub du serveur et le client. Différents langages de programmation et frameworks peuvent être utilisés pour la génération de code.
Les langages de programmation et les frameworks supportés par les outils de génération de code sont donnés ci-dessous.
aspnetcore, csharp, csharp-dotnet2, go-server, dynamique-html, html, html2, java, jaxrs-cxf-client, jaxrs-cxf, inflecteur, jaxrs-cxf-cdi, jaxrs-spec, jaxrs-jersey, jaxrs- di, jaxrs-resteasy-eap, jaxrs-resteasy, micronaut , printemps, nodejs-server, openapi, openapi-yaml, kotlin-client, kotlin-server, php, python, python-flask, r, scala, scal a- akka -serveur http, swift3, swift4, swift5, tapuscrit angulaire, javascript
L'outil de génération de code est un programme Java qui peut être exécuté directement après le téléchargement. Après avoir téléchargé le fichier JAR swagger-codegen-cli-3.0.19.jar , vous pouvez utiliser la commande suivante pour générer le code client Java, où le paramètre -i spécifie le document OpenAPI d'entrée, -l spécifie la langue générée et - o spécifie la table des matières en sortie.
java -jar swagger-codegen-cli-3.0.19.jar générer -i openapi.yml -l java -o /tmp
En plus de générer du code client, un code de talon de serveur peut également être généré. Le code suivant permet de générer le code stub du serveur NodeJS :
java -jar swagger-codegen-cli-3.0.19.jar générer -i openapi.yml -l nodejs-server -o /tmp
Résumer
La stratégie API-first garantit que l'API de microservice est conçue en tenant pleinement compte des besoins des utilisateurs de l'API, faisant de l'API un bon contrat entre le fournisseur et l'utilisateur. Cette classe présente d'abord la stratégie de conception de l'API, puis présente les différentes méthodes de mise en œuvre de l'API, puis introduit la spécification OpenAPI de l'API REST, et enfin introduit les outils associés d'OpenAPI.