Modèle GPT
Modèle GPT : pré-formation générative
L'ossature générale :
Pré-formation non supervisée
Mise au point supervisée pour les tâches en aval
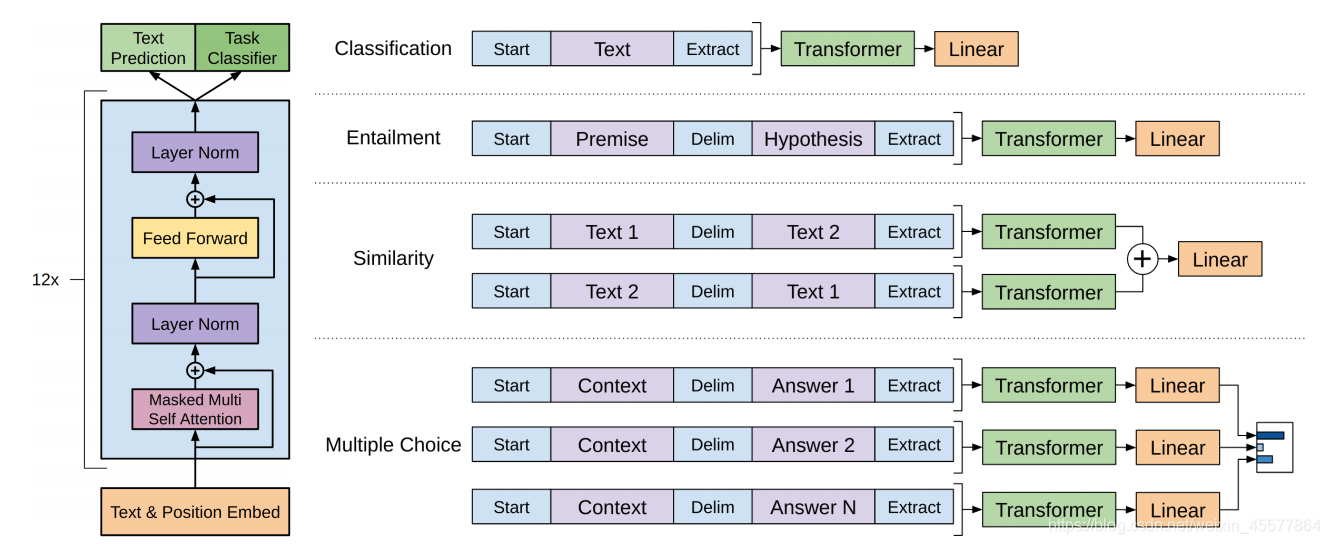
Structure centrale : la partie centrale est principalement composée de 12 blocs Transformer Decoder empilés
L'image suivante reflète plus intuitivement la structure globale du modèle :
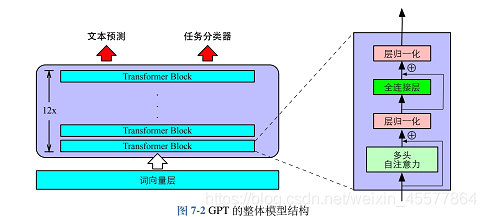
Description du modèle
GPT utilise la structure de décodeur de Transformer et apporte quelques modifications au décodeur de transformateur. Le décodeur d'origine contient deux structures d'attention multi-têtes, et GPT ne conserve que l'attention multi-têtes de masque, comme illustré dans la figure ci-dessous .
(Beaucoup de données indiquent qu'il est similaire à la structure du décodeur, car le mécanisme de masque du décodeur est utilisé, mais à part cela, il ressemble en fait plus à l'encodeur, donc parfois il est implémenté en ajustant l'encodeur à la place. Ne vous embêtez pas )
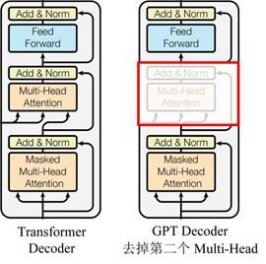
Par rapport à la structure du transformateur d'origine
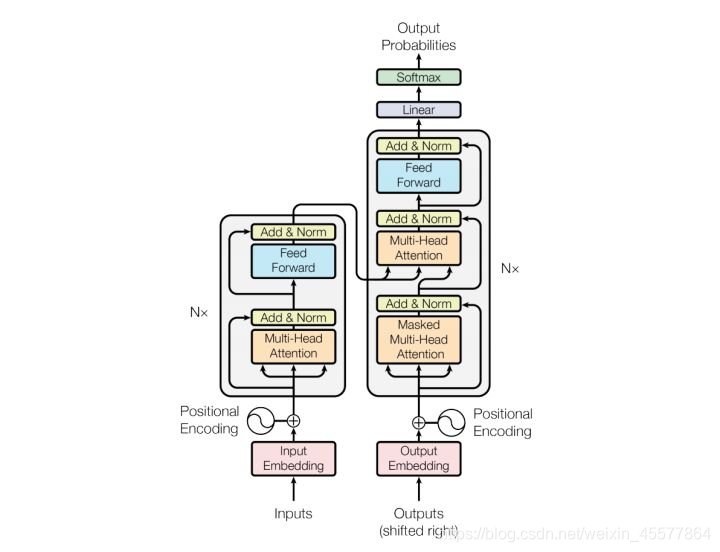
description de l'étape
Phase de pré-formation :



L'étape de pré-formation est la prédiction de texte, c'est-à-dire la prédiction du mot actuel sur la base des mots historiques existants. Les trois formules 7-2, 7-3 et 7-4 correspondent au diagramme de structure GPT précédent, et la sortie P (x) est la sortie. La probabilité que chaque mot soit prédit, puis utilisez la formule 7-1 pour calculer la fonction de vraisemblance maximale et construisez une fonction de perte basée sur cela, c'est-à-dire que le modèle de langage peut être optimisé.
Phase de mise au point de la tâche aval

fonction de perte
Une combinaison linéaire de tâches en aval et de pertes de tâches en amont

processus de calcul :
- entrer
- Intégration
- Bloc transformateur multicouche
- Obtenir deux résultats de sortie
- calculer la perte
- rétropropagation
- paramètres de mise à jour
Un exemple de code GPT spécifique :
vous pouvez voir que dans la fonction directe du modèle GPT, l'opération d'intégration est effectuée en premier, puis l'opération est effectuée dans le bloc du transformateur à 12 couches, puis la valeur de calcul finale est obtenue via deux transformations linéaires (une pour la prédiction de texte), une pour le classificateur de tâche), le code est cohérent avec le schéma de structure du modèle présenté au début.
Référence : Ne vous embêtez pas
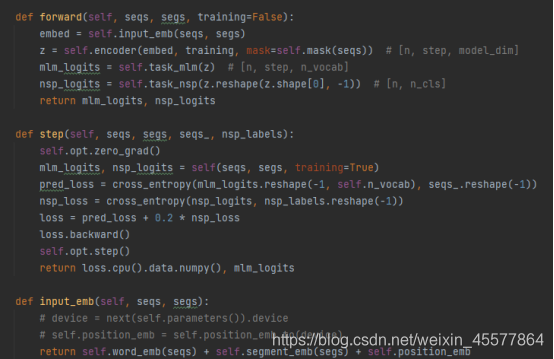
avec le code d'implémentation Python GPT Concentrons-nous sur les étapes de calcul 2 et 3
Détails du calcul :
[Couche d'intégration] :
La couche d'intégration pour l'opération de recherche de table
est une couche entièrement connectée avec un nœud chaud comme entrée et des nœuds de couche intermédiaire comme dimensions de vecteur de mot. Et le paramètre de cette couche entièrement connectée est une "table de vecteurs de mots".

La multiplication matricielle du type à chaud unique équivaut à une recherche de table, elle utilise donc directement la recherche de table comme opération au lieu de l'écrire dans une matrice pour le calcul, ce qui réduit considérablement la quantité de calcul. Il est à nouveau souligné que la réduction de la quantité de calcul n'est pas due à l'émergence de vecteurs de mots, mais parce que l'opération de matrice à chaud est simplifiée en une opération de consultation de table.
[Couche de décodeur similaire au transformateur dans GPT] :
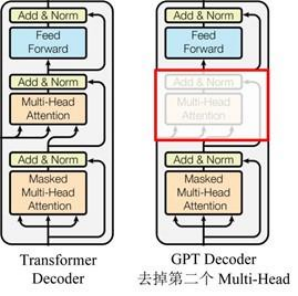
Chaque couche de décodeur contient deux sous-couches
- sublayer1 : couche d'attention multi-têtes pour masque
- sublayer2 : ffn (feed-forward network) feedforward network (perceptron multicouche)
sublayer1 : couche d'attention multi-têtes du masque
输入:q, k, v, mask
计算注意力:Linéaire (multiplication matricielle)→Scaled Dot-Product Attention→Concat (résultats d'attention multiples, remodelage)→Linear(multiplication matricielle)
残差连接和归一化操作:Opération d'abandon → connexion résiduelle → opération de normalisation de couche
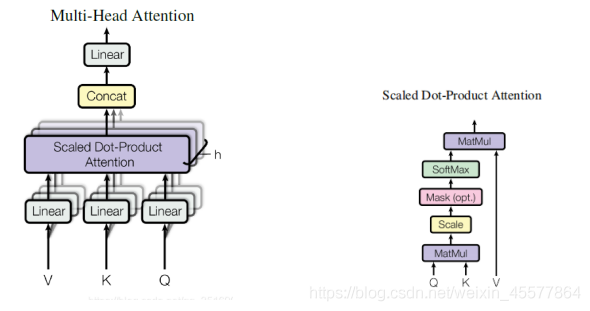
processus de calcul :
Le paragraphe suivant décrit le processus global de calcul de l'attention :

Consignes d'explosion :
Masque Multi-tête Attention
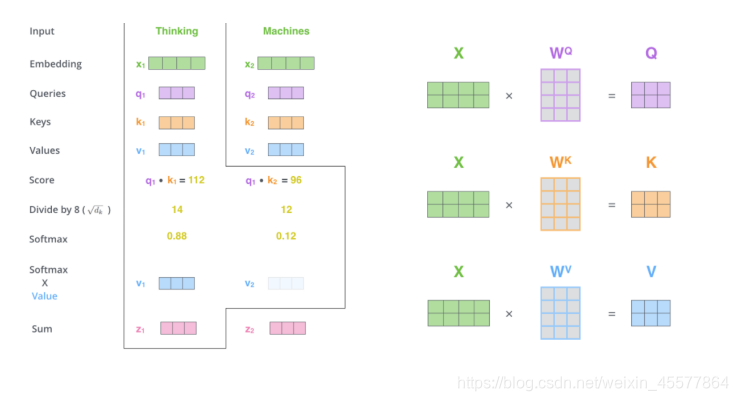
1. Multiplication matricielle :
Transformer l'entrée q, k, v
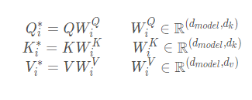
2. Attention au produit scalaire mis à l'échelle
L'essentiel est d'effectuer le calcul de l'attention et l'opération de masque Opération de masque
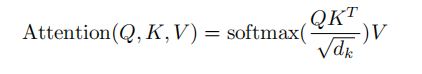
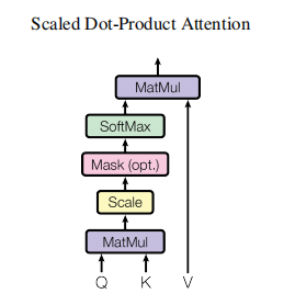
: masked_fill_(mask, value)
masque opération, remplit l'élément dans le tenseur correspondant à la valeur 1 dans le masque avec valeur. La forme du masque doit correspondre à la forme du tenseur à remplir. (Ici, le rembourrage -inf est utilisé, de sorte que le softmax devient 0, ce qui équivaut à ne pas voir les mots suivants)
L'opération de masque dans le transformateur
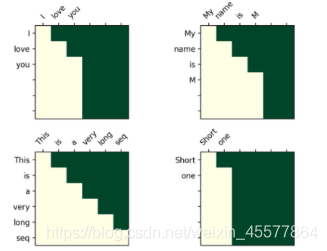
Matrice de visualisation après masque :
La compréhension intuitive est que chaque mot ne peut voir que le mot qui le précède (car le but est de prédire le futur mot, si vous le voyez, vous n'avez pas besoin de le prédire)
3. Opération concat :
La combinaison des résultats de plusieurs têtes d'attention transforme en fait la matrice : permutation, opérations de remodelage et réduction de la dimensionnalité. (Comme indiqué dans l'encadré rouge de la figure ci-dessous)
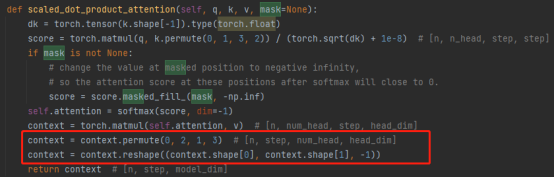
4. Multiplication matricielle : une couche linéaire, qui transforme linéairement les résultats de l'attention
La couche d'attention multi-têtes de l'ensemble du masque代码 :
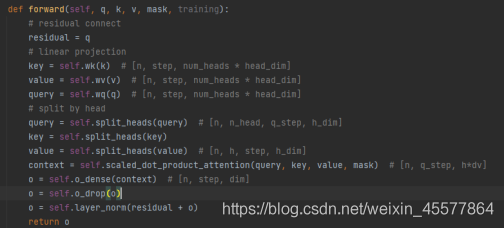
Remarque : les lignes suivantes dans le code ci-dessus expliquent 残差连接和归一化操作
le processus des résultats d'attention :
Opérations de connexion et de normalisation résiduelles :
5.Couche d'abandon
6. Ajout de matrice
7. Normalisation des calques
La normalisation par lots est la normalisation d'un seul neurone entre différentes données d'entraînement, et la normalisation de couche est la normalisation d'une seule donnée d'entraînement parmi tous les neurones d'une certaine couche.
Normalisation d'entrée, normalisation de lot (BN) et normalisation de couche (LN)
代码展示:
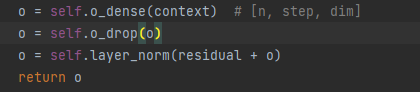
sous-couche2 : ffn (réseau d'anticipation) réseau d'anticipation
1. Couche linéaire (multiplication matricielle)
2. Activation de la fonction Relu
3. Couche linéaire (multiplication matricielle)
4. Opération de décrochage
5. Normalisation des calques
[Calque linéaire] :
Les résultats de sortie du bloc multicouche sont placés dans deux couches linéaires pour la transformation, ce qui est relativement simple et ne sera pas décrit en détail.
Supplément : organigramme de la couche d'attention
Les références
1. Document de référence : Radford et al., « Improving Language Undersatnding by Generative Pre-Training »
2. Ouvrage de référence : « Natural Language Processing Based on Pre-training Model Method » Che Wanxiang, Guo Jiang, Cui Yiming
3. La source du code dans cet article : Ne vous embêtez pas avec le code d'implémentation Python GPT
4. Autres liens de référence (parties mentionnées dans le billet de blog) :
Analyse du processus de calcul de l'incorporation de mots
Analyse de la dimension de la matrice du transformateur et explication détaillée du masque