1. Structure de stockage logique :


Espace table (fichier ibd) : Une instance Mysql peut correspondre à plusieurs espaces table pour stocker des enregistrements, des index et d'autres données.
Segment : divisé en segment de données, segment d'index, segment d'annulation,
InnoDB est une table d'organisation d'index, le segment de données est le nœud feuille de l'arbre B+, le segment d'index est le nœud non feuille de l'arbre B+, et le segment est utilisé pour gérer plusieurs zones (Extent)
Zone : la structure de l'unité dans l'espace table. La taille de chaque zone est de 1 Mo. Par défaut, la taille de page du moteur de stockage InnoDB est de 16 Ko, c'est-à-dire qu'il y a 64 pages consécutives dans une zone.
Page : Il s'agit de la plus petite unité de gestion de disque du moteur de stockage InnoDB. La taille de chaque page est de 16 Ko. Afin d'assurer la continuité de la page, le moteur de stockage InnoDB s'applique à chaque fois à 4-5 zones du disque.
Ligne : le moteur de stockage InnoDB est stocké par ligne
Trx_id : chaque fois qu'un enregistrement est modifié, l'ID de la transaction correspondante sera attribué à la colonne masquée trx_id, qui est l'ID de la dernière transaction d'opération
Roll_pointer : chaque fois qu'un enregistrement est modifié, l'ancienne version sera écrite dans le journal d'annulation, puis cette colonne masquée équivaut à un pointeur, à travers lequel les informations avant la modification de l'enregistrement peuvent être trouvées
2. Architecture InnoDB

2.1 Structure de la mémoire
2.1.1 BufferPool : pool de tampons
Le pool de mémoire tampon est une zone de la mémoire qui peut mettre en cache les données réelles fréquemment utilisées sur le disque. Lors de l'exécution d'ajouts, de suppressions, de modifications et de requêtes, les données du pool de mémoire tampon seront traitées en premier (s'il n'y a pas données dans la mémoire tampon à ce moment, elles seront chargées à partir du disque et du cache), puis actualisées sur le disque à une certaine fréquence ou règle pour réduire le nombre d'E/S de disque et accélérer le traitement.
S'il n'y a pas de mémoire tampon, chaque opération d'ajout, de suppression, de modification et de requête s'effectuera sur l'espace disque, et il y aura un grand nombre d'E/S disque. Dans l'entreprise, les E/S disque sont des E/S aléatoires, ce qui prend beaucoup de temps et consommatrice de performances, il est donc nécessaire de réduire au maximum les E/S disque.
L'unité de traitement du pool de mémoire tampon est une page, et la couche inférieure utilise une structure de données de liste chaînée pour gérer la page. Selon l'état, la page est divisée en trois types :
- page libre : page libre, non utilisée
- page propre : page utilisée, les données n'ont pas été modifiées
- Page sale : page sale, page utilisée, les données ont été modifiées et les données sont incohérentes avec les données du disque
2.2.2 Changer de tampon : changer le tampon
Lors de l'exécution d'une instruction DML, si les pages de données ne sont pas dans le Buffer Pool, le disque ne sera pas directement exploité, mais les modifications de données actuelles seront stockées dans le Change Buffer (tampon de modification), et lorsque les données sont lues dans le future , puis fusionnez et restaurez les données dans le pool de mémoire tampon, puis actualisez les données fusionnées sur le disque.
Fonction : chaque opération sur le disque entraînera de nombreuses E/S sur le disque. Avec ChangeBuffer, le processus de fusion peut être effectué dans le pool de mémoire tampon, ce qui réduira considérablement les E/S sur le disque.
2.2.3 Index de hachage adaptatif:
L'index de hachage adaptatif est utilisé pour optimiser la requête des données du pool de tampons (pool de tampons). InnoDB surveillera la requête de chaque page d'index sur la table et créera un index de hachage s'il constate que l'index de hachage peut améliorer la vitesse. Remarque : L'index de hachage adaptatif, sans intervention manuelle, est automatiquement complété par le système en fonction de la situation.
L'index de hachage adaptatif a un commutateur d'indicateur pour définir s'il faut l'activer : adaptive_hash_index.
2.2.4 Tampon de journal : tampon de journal
Tampon de journal, enregistrez les données du journal (journal de rétablissement, journal d'annulation) à écrire sur le disque, la valeur par défaut est de 16 Mo, le journal sera périodiquement actualisé sur le disque, si vous devez mettre à jour, insérer ou supprimer de nombreuses lignes de transactions, augmenter la taille de la mémoire tampon du journal Peut économiser les E/S du disque
paramètre:
InnoDB_log_buffer_size : taille du tampon,
InnoDB_flush_log_at_trx_commit : Lorsque le journal est vidé sur le disque (ce paramètre a 3 valeurs : 1, 0, 2)
1. Chaque fois qu'une transaction est validée, elle est vidée sur le disque
0. Les journaux sont écrits et vidés sur le disque toutes les secondes
2. Une fois chaque transaction validée, elle est actualisée sur le disque toutes les secondes
2.2 Structure du disque
2.2.1 Tablespace système : le tablespace système est la zone de stockage de [Change Buffer ] dans la structure de la mémoire. Paramètres : innodb_data_file_path
2.2.2 Espace de table fichier par table : l'espace de table de chaque fichier de table contient les données et les index d'une seule table InnoDB et est stocké dans un seul fichier de données sur le système de fichiers. Paramètre : innodb_file_per_table (activé par défaut)
2.2.3 Tablespace général : tablespace général , qui doit être créé via la syntaxe create TableSpace, qui peut être spécifiée lors de la création d'une table. (équivalent au fait que nous pouvons créer manuellement le tablespace nous-mêmes, puis spécifier le tablespace que nous avons créé manuellement lors de la création d'une nouvelle table)
2.2.4 Tablespace d'annulation : undo tablespace , l'instance MySQL créera automatiquement deux tablespaces d'annulation par défaut (16 Mo par défaut) lors de l'initialisation pour stocker les journaux d'annulation.
2.2.5 Espace de table temporaire : espace de table temporaire , InnoDB utilisera l'espace de table temporaire de session et l'espace de table temporaire global pour stocker les données de la table temporaire créées par les utilisateurs, etc.
2.2.6 Fichiers tampons en double écriture : tampon en double écriture. Avant que le moteur InnoDB ne vide la page de données du pool de tampons sur le disque, il écrit d'abord la page de données dans le fichier tampon en double écriture, ce qui est pratique pour la récupération des données lorsque le système est anormal.
2.2.7 Redo Log : Redo log , qui réalise la persistance des transactions, se compose d'un redo log buffer (redo buffer) et d'un redo log file (redo log) , le premier est en mémoire et le second sur disque. Lorsque la transaction est validée, toutes les informations de modification seront placées dans le journal, qui est utilisé pour la récupération des données lorsque des erreurs se produisent lors du vidage des pages modifiées sur le disque.
2.3 Fils d'arrière-plan
Fonction : rafraîchir les données du pool de mémoire tampon InnoDB dans le fichier disque au bon moment.
2.3.1 Fil principal
Le thread d'arrière-plan principal est responsable de la planification d'autres threads et est également responsable de l'actualisation asynchrone des données du pool de mémoire tampon sur le disque pour maintenir la cohérence des données. Il inclut également l'actualisation des pages modifiées, la fusion et l'insertion de caches et le recyclage des pages d'annulation.
2.3.2 Fil d'E/S
Dans le moteur de stockage InnoDB, AIO est largement utilisé pour traiter les requêtes IO, ce qui peut grandement améliorer les performances de la base de données, et IO Thread est principalement responsable du rappel de ces requêtes IO.

2.3.3 Fil de purge
Il est principalement utilisé pour recycler le journal d'annulation qui a été soumis par la transaction. Une fois la transaction validée, le journal d'annulation ne peut pas être utilisé, il est donc utilisé pour recycler
2.3.4 Fil de nettoyage de page
Un thread qui aide le Master Thread à vider les pages sales sur le disque, ce qui peut réduire la pression de travail du Master Thread et réduire le blocage
3. Principe commercial
Une transaction est un ensemble d'opérations. Il s'agit d'une unité de travail indivisible. Une transaction soumet ou annule une demande d'opération au système dans son ensemble. Ces opérations réussissent ou échouent en même temps .
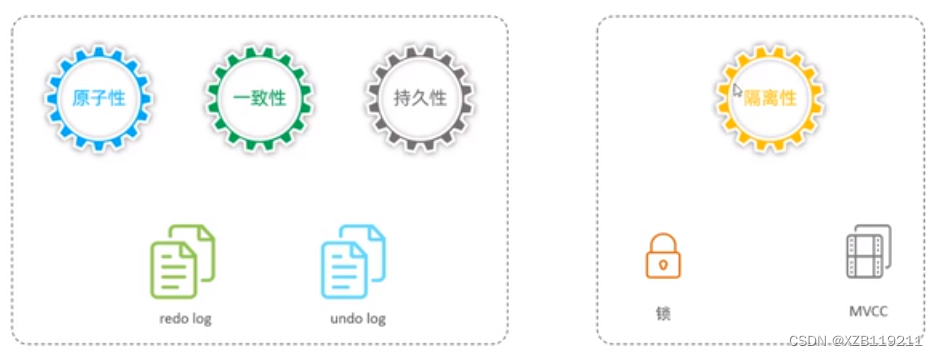
1. Atomicité Une transaction doit être considérée comme une unité minimale indivisible. Toutes les opérations de l'ensemble de la transaction sont soit soumises avec succès, soit toutes échouent. Pour une transaction, il est impossible de n'effectuer qu'une partie des opérations.
2. Cohérence (Cohérence) Si la base de données est cohérente avant l'exécution de la transaction, la base de données est toujours cohérente après l'exécution de la transaction ;
3. Isolation Les opérations de transaction sont indépendantes et transparentes sans s'affecter mutuellement. Les transactions s'exécutent indépendamment. Ceci est généralement réalisé à l'aide de serrures. Si le résultat d'un traitement de transaction affecte d'autres transactions, alors d'autres transactions seront retirées. L'isolement à 100 % des transactions nécessite de sacrifier la vitesse.
4. Durabilité (Durability) Une fois la transaction validée, le résultat est permanent. Même si une défaillance du système se produit, elle peut être récupérée.
L'atomicité, la cohérence et la durabilité sont contrôlées par redolog et undo log
L'isolement est contrôlé par des serrures et MVCC
—> La persistance est garantie par redo log
Redo Log : redo log, qui réalise la persistance des transactions. Il se compose d'un redo log (redo buffer) et d'un redo log (redo log). Le premier est en mémoire et le second est sur le disque. Une fois la transaction validée, tous les informations de modification sont placées dans le journal, qui est utilisé pour la récupération des données lorsqu'une erreur se produit lors du vidage des pages modifiées sur le disque.

Explication : La figure montre le mécanisme de traitement dans InnoDB pour assurer la persistance de la transaction après la validation d'une transaction. Tout d'abord, une fois la transaction validée, elle ira à la page de données correspondante dans le pool de tampons de la structure de la mémoire pour modifier le données Attendez l'opération, une fois l'opération terminée, la transaction dans la mémoire a été exécutée à ce moment, mais n'a pas été actualisée sur le disque à temps, la page de données mise à jour dans la mémoire actuelle est appelée une page sale, et lorsque l'opération est effectuée dans le Buffer Pool, la page de données dans la mémoire Toutes les opérations seront enregistrées dans le Redolog Buffer dans la zone, puis périodiquement actualisées dans le Redo Log du disque par le thread d'arrière-plan, puis lorsqu'un se produit lorsque les données du pool de mémoire tampon sont actualisées sur le disque, les données peuvent être traitées via le journal redo dans la récupération de disque. Lorsque les données du pool de tampons sont correctement synchronisées sur le disque, le redolog du disque est inutile, de sorte que les deux redologs du disque sont copiés l'un sur l'autre pour obtenir des mises à jour en temps opportun. Cette méthode d'écriture des journaux d'abord puis de synchronisation des données est appelée WAL (Write-Ahead Log)
Alors pourquoi s'embêter, d'abord écrire dans le Redolog Buffer, puis le transférer dans le Redo Log, ne suffirait-il pas d'actualiser les données du Buffer Pool sur le disque après chaque transaction ? Il y a un problème ici. La plupart des opérations sur les pages de données d'une transaction sont aléatoires. Si chaque transaction est immédiatement vidée sur le disque, plusieurs E/S de disque seront générées, ce qui consommera beaucoup de performances. Nous passons donc Redolog pour garantir que les données persévérance dans cette voie.
—> L'atomicité est garantie par undo log
journal d'annulation : journal de restauration, utilisé pour enregistrer les informations avant que les données ne soient modifiées, le rôle comprend : fournir une restauration et MVCC (concurrence de contrôle multi-version)
Undo log et redo log record logs physiques diffèrent. Il s'agit d'un journal logique. On peut considérer que lorsqu'un enregistrement est supprimé, un enregistrement d'insertion correspondant sera enregistré dans le journal d'annulation, et vice versa. Lorsqu'un enregistrement est mis à jour, un l'enregistrement correspondant sera enregistré. mettre à jour les enregistrements, lors de l'exécution de la restauration, vous pouvez lire le contenu correspondant à partir des enregistrements logiques dans le journal d'annulation et la restauration.
Destruction du journal d'annulation : il est généré lorsque la transaction est exécutée. Lorsque la transaction est validée, le journal d'annulation ne sera pas supprimé immédiatement. Ces journaux peuvent également être utilisés pour MVCC.
Stockage du journal d'annulation : il est géré et enregistré sous forme de segments, stockés dans le segment de restauration rollback, qui contient 1 024 segments de journal d'annulation.
4、MVCC
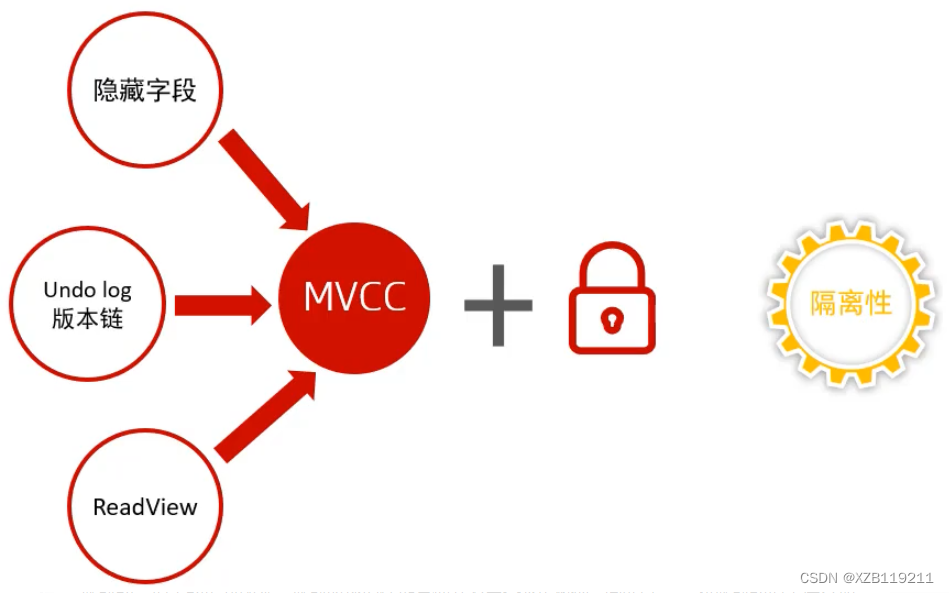
4.1 Conception
Qu'est-ce que le MVCC ?
MVCC consiste à gérer plusieurs versions de données lors de l'accès simultané à la base de données, afin d'éviter de bloquer la demande de lecture de données en raison de la nécessité d'ajouter un verrou en écriture lors de l'écriture de données, ce qui entraîne le problème que les données ne peuvent pas être lues lors de l'écriture de données.
En termes simples, MVCC enregistre la version historique des données et décide d'afficher ou non les données en fonction du numéro de version des données comparées. Il peut obtenir l'effet d'isolation de la transaction sans ajouter de verrou de lecture et peut enfin lire les données. Modifiez en même temps, lors de la modification des données, vous pouvez les lire en même temps, ce qui améliore considérablement les performances de concurrence des transactions.
4.2 Points de connaissance de base de la mise en œuvre d'InnoDB MVCC
4.2.1 Numéro de version de l'opération
Avant que chaque transaction ne soit démarrée, un ID de transaction à croissance automatique sera obtenu à partir de la base de données, et l'ordre d'exécution des transactions peut être jugé à partir de l'ID de transaction.
4.2.2 Colonnes masquées des tableaux
| DB_TRX_ID | Enregistrez l'ID de transaction de la transaction de données ; |
| DB_ROLL_PTR | Pointeur vers le pointeur de position des données de la version précédente dans le journal d'annulation ; |
| DB_ROW_ID | ID masqué, lors de la création d'une table sans index approprié en tant qu'index clusterisé, l'ID masqué sera utilisé pour créer un index clusterisé ; |
4.2.3 Journal d'annulation
Le journal d'annulation est principalement utilisé pour enregistrer le journal avant que les données ne soient modifiées. Avant que les informations de la table ne soient modifiées, les données seront copiées dans le journal d'annulation. Lorsque la transaction est annulée, les données du journal d'annulation peuvent être restaurées.
Objectif du journal d'annulation
(1) Garantir l'atomicité et la cohérence lorsque la transaction est annulée. Lorsque la transaction est annulée, les données du journal d'annulation peuvent être utilisées pour la récupération.
(2) Les données utilisées pour la lecture de l'instantané MVCC. Dans le contrôle multi-version MVCC, en lisant les données de version historiques du journal d'annulation, différents numéros de version de transaction peuvent avoir leurs propres versions de données d'instantané indépendantes.
4.2.4 Relation entre le numéro de version de la transaction, la colonne masquée de la table et le journal d'annulation
Nous utilisons un processus de simulation de modification des données pour comprendre la relation entre le numéro de version de la transaction, les colonnes masquées et l'annulation du journal.
(1) Préparez d'abord un tableau de données original
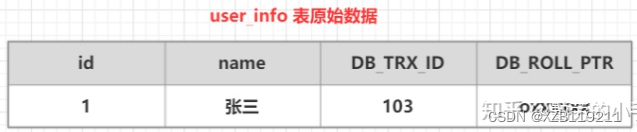
(2) Démarrez une transaction A : exécutez la mise à jour user_info set name = "Li Si" où id=1 sur la table user_info, et le processus suivant sera exécuté
| 1. Obtenez d'abord un numéro de transaction 104 |
| 2. Copiez les données avant modification de la table user_info dans le journal d'annulation |
| 3. Modifier les données de la table user_info id=1 |
| 4. Remplacez le numéro de version de la transaction de données modifiée par le numéro de version de la transaction actuelle et faites pointer l'adresse DB_ROLL_PTR vers l'adresse des données du journal d'annulation. |
(3) Le résultat de l'exécution finale est montré dans la figure

4.2.5 déconnecter la chaîne de version
Si vous modifiez le même enregistrement par différentes transactions ou par la même transaction, le journal d'annulation de l'enregistrement générera une liste liée de versions d'enregistrement. Le début de la liste liée est le dernier enregistrement ancien et la fin de la liste liée est le plus ancien. enregistrer.

4.2.6 Vue Lire
Après l'ouverture de chaque transaction dans InnoDB, vous en obtiendrez une (vue Lire). La copie enregistre principalement les numéros d'identification des transactions actives (sans validation) dans le système de base de données actuel. En fait, pour parler simplement, cette copie enregistre une liste d'autres ID de transaction dans le système qui ne devraient pas être vus par cette transaction. ( Lorsque chaque transaction est ouverte, un ID lui est attribué, qui est incrémenté, de sorte que la dernière transaction a une valeur d'ID plus grande )
Nous savons donc que Read View est principalement utilisé pour le jugement de visibilité, c'est-à-dire que lorsque nous exécutons une lecture instantanée pour une certaine transaction, nous créons une vue de lecture Read View pour l'enregistrement et la comparons à une condition pour juger si la transaction actuelle peut voir quelle version des données peut être la dernière donnée actuelle, ou une certaine version des données dans le journal d'annulation enregistré dans cette ligne.
Read View suit un algorithme de visibilité, retirant principalement le DB_TRX_ID (c'est-à-dire l'ID de transaction actuel) dans le dernier enregistrement des données à modifier, et le comparant avec les ID d'autres transactions actives dans le système (maintenu par Read View ), si DB_TRX_ID suit Les attributs de Read View ont effectué des comparaisons, qui ne sont pas conformes à la visibilité, puis utilisez le pointeur d'annulation DB_ROLL_PTR pour retirer le DB_TRX_ID dans le journal d'annulation et comparez-les à nouveau, c'est-à-dire, traversez le DB_TRX_ID de la liste chaînée (du début de la chaîne à la fin de la chaîne, c'est-à-dire depuis la modification et la vérification les plus récentes), jusqu'à ce que vous trouviez un DB_TRX_ID remplissant certaines conditions, alors l'ancien enregistrement où se trouve ce DB_TRX_ID est le dernière ancienne version que la transaction en cours peut voir
Plusieurs propriétés importantes de Read View :
| m_ids : ensemble de numéros de version de transaction actifs (non validés) du système actuel |
| min_trx_id : ID de transaction active minimum |
| max_trx_id : ID de transaction pré-alloué, l'ID de transaction maximum actuel + 1 (car l'ID de transaction s'auto-incrémente) |
| creator_trx_id : crée le numéro de version de la transaction de la vue de lecture actuelle |
Lire les conditions de correspondance des vues :

1. ID de transaction de données==creator_trx_id
Si établi, vous pouvez accéder à cette version, indiquant que les données ont été modifiées par la transaction en cours
2. Si l'ID de transaction de données est <min_trx_id, il sera affiché
Si l'ID de transaction de données est inférieur à l'ID de transaction active minimum dans la vue de lecture, il est certain que les données existaient déjà avant le démarrage de la transaction en cours, elles peuvent donc être affichées.
3. L'ID de transaction de données>=max_trx_id ne sera pas affiché
Si l'ID de transaction de données est supérieur à l'ID de transaction maximum du système actuel dans la vue de lecture, cela signifie que les données sont générées après la création de la vue de lecture actuelle, de sorte que les données ne seront pas affichées.
4. Si min_trx_id<=ID de transaction de données<max_trx_id, il correspond à l'ensemble de transactions actif trx_ids
Si l'ID de transaction des données est supérieur au plus petit ID de transaction active et inférieur ou égal au plus grand ID de transaction du système, cette situation indique que les données n'ont peut-être pas été soumises lorsque la transaction en cours a démarré.
Donc, à ce stade, nous devons faire correspondre l'ID de transaction des données avec l'ensemble de transactions actif trx_ids dans la vue de lecture actuelle :
Cas 1 : si l'ID de transaction n'existe pas dans la collection trx_ids (cela signifie que la transaction a été validée lorsque la vue de lecture est générée), les données dans ce cas peuvent être affichées.
Cas 2 : Si l'ID de transaction existe dans trx_ids, cela signifie que les données n'ont pas été soumises lorsque la vue en lecture est générée, mais si l'ID de transaction des données est égal à creator_trx_id, cela signifie que les données sont générées par le transaction en cours elle-même, et les données générées par elles-mêmes peuvent être vues par elles-mêmes, donc Dans ce cas, les données peuvent également être affichées.
Cas 3 : si l'ID de transaction existe dans trx_ids et n'est pas égal à creator_trx_id, cela signifie que les données n'ont pas été soumises lors de la génération de la vue de lecture et qu'elles ne sont pas générées par elles-mêmes. Les données ne peuvent donc pas être affichées dans ce cas. .
5. Lorsque la condition de la vue en lecture n'est pas satisfaite, les données sont obtenues à partir du journal d'annulation
Lorsque l'ID de transaction des données ne répond pas à la condition d'affichage en lecture, la version historique des données est obtenue à partir du journal d'annulation, puis le numéro de transaction de la version historique des données est mis en correspondance avec la condition d'affichage en lecture jusqu'à ce qu'un morceau des données historiques qui remplissent la condition sont trouvées, ou si elles ne sont pas trouvées, renvoie un résultat vide ;
4.3 Le principe d'InnoDB implémentant MVCC

4.3.1 Simuler le processus de mise en œuvre du MVCC
Ci-dessous, nous simulons le flux de travail de MVCC en ouvrant deux transactions simultanées.
(1) Créez une table user_info et insérez une donnée d'initialisation

(2) La transaction A et la transaction B modifient et interrogent user_info en même temps
Transaction A : mettre à jour le nom de l'ensemble d'informations utilisateur = "Lisi"
Transaction B : sélectionnez * depuis user_info où id=1
question:
Démarrez d'abord la transaction A et exécutez la transaction B après que la transaction A a modifié les données mais ne s'est pas validée. Quel est le résultat final du retour.
Le flux d'exécution est le suivant :

La description du flux d'exécution dans la figure ci-dessus :
1. Transaction A : Pour démarrer une transaction, obtenez d'abord un numéro de transaction 102 ;
2. Transaction B : ouvrez la transaction et obtenez le numéro de transaction 103 ;
3. Transaction A : Pour modifier l'opération, copiez d'abord les données d'origine dans le journal d'annulation, puis modifiez les données, marquez le numéro de transaction et l'adresse de la dernière version des données dans le journal d'annulation.

4. Transaction B : à ce moment, la transaction B obtient une vue en lecture, et la valeur correspondante de la vue en lecture est la suivante

5. Transaction B : Exécutez l'instruction de requête et les données modifiées de la transaction A sont obtenues à ce moment

6. Transaction B : faire correspondre les données avec la vue en lecture

Il s'avère que les conditions d'affichage de la vue de lecture ne sont pas remplies, de sorte que les données de la version historique sont obtenues à partir d'undo lo puis mises en correspondance avec la vue de lecture, et finalement les données renvoyées sont les suivantes.

4.4 Lecture d'instantané et lecture actuelle
En train de lire:
Ce qui est lu est la dernière version de l'enregistrement. Lors de la lecture, il faut s'assurer que d'autres transactions concurrentes ne peuvent pas modifier l'enregistrement en cours, et l'enregistrement lu sera verrouillé. Pour les opérations quotidiennes, telles que : sélectionner ... verrouiller en mode partage (verrou partagé), sélectionner ... pour mettre à jour, mettre à jour, insérer, supprimer (verrou exclusif) sont tous en cours de lecture
Instantané lu :
Une simple sélection (sans verrou) est une lecture d'instantané. La lecture d'instantané lit la version visible des données enregistrées, qui peuvent être des données historiques. Déverrouillé est un verrou non bloquant
Lecture validée : chaque fois que vous sélectionnez, un instantané de lecture est généré
Lecture répétable : la première instruction select après le démarrage de la transaction est l'endroit où l'instantané est lu
Sérialisable : la lecture de l'instantané dégénère en lecture actuelle
Il existe trois types de scénarios de concurrence de base de données :
lecture-lecture : pas de problèmes et pas besoin de contrôle de la concurrence
Lecture-écriture : il existe des problèmes de sécurité des threads, qui peuvent entraîner des problèmes d'isolation des transactions et peuvent rencontrer des lectures incorrectes, des lectures fantômes et des lectures non répétables
Écriture-écriture : il existe des problèmes de sécurité des threads, et il peut y avoir des problèmes de mises à jour perdues, telles que la première catégorie