1. Commencez par la synchronisation
1.1 Génération de synchronisation
Lors de la lecture ou de l'écriture du code du noyau, vous devez toujours prendre un prérequis par défaut : tout flux d'exécution peut être interrompu après n'importe quelle instruction, puis revenir pour s'exécuter à nouveau après un temps indéterminé.
Par conséquent, il est souvent nécessaire de se poser la question suivante : si l'environnement d'exécution dont l'instruction dépend à l'origine changera pendant le processus d'interruption et de retour au point d'arrêt pour continuer l'exécution. Le problème correspondant est que l'environnement sur lequel l'exécution de l'instruction dépend est exclusif est toujours partagé. S'il est exclusif, il est sûr et s'il est partagé, il peut être accidentellement modifié, ce qui entraînera des problèmes de synchronisation. Le traitement des problèmes de synchronisation est généralement résolu par des mécanismes de synchronisation tels que les variables atomiques et le verrouillage.
Le jugement de la plupart des ingénieurs sur l'opportunité d'utiliser le mécanisme de synchronisation est basé sur un concept simple : le fonctionnement des variables globales doit être verrouillé, mais pas les variables locales.
Dans la grande majorité des cas, cette peine est applicable. La raison pour laquelle j'ai remplacé global et local par partagé et exclusif est que dans certaines circonstances, les variables locales ne sont pas égales aux ressources exclusives, et il en va de même pour les variables globales. La question de savoir s'il faut introduire un mécanisme de synchronisation n'est pas statique. Pour exemple, les situations suivantes :
(1) Un problème qui doit être noté est que nous considérons généralement le comportement de retour d'un pointeur vers une ressource sur la pile comme un bogue absolu sans y penser, mais nous ignorons la cause de ce bogue : les données sur la pile après le les retours de fonction seront écrasés. Mais que se passe-t-il si la fonction ne revient pas ? Vous pouvez voir un tel code dans le noyau : initialisez certaines ressources sur la pile, puis liez-les à la liste liée globale, puis tombez en veille, et le cycle de vie des données sur la pile restera jusqu'à ce qu'elle soit réveillée. Étant donné que les données de la pile peuvent être exportées vers d'autres emplacements, elles passent naturellement d'exclusives à partagées, et les problèmes de synchronisation doivent être pris en compte.
(2) Lorsque nous concentrons toute notre attention sur les données, ou lorsque nous tenons pour acquis que la pile doit être exclusive comme mentionné au premier point, nous ignorons en fait la forme de leur propre existence : qu'il s'agisse d'une instruction ou d'un Qu'il s'agisse de données, de zone de pile ou de zone de tas, ils existent tous dans la mémoire et les attributs matériels de la mémoire elle-même sont lisibles et inscriptibles. Par exemple, le segment de code est en lecture seule, et la pile est indépendante de chaque processus, qui n'est qu'un attribut qui leur est donné par le système d'exploitation. Si nous ne sommes que des utilisateurs du système d'exploitation, nous pouvons naturellement appliquer par défaut ces lois , mais si nous sommes des développeurs, y a-t-il une possibilité de modifier le segment de code ou les autres besoins de la partie non-données ? Et y aura-t-il des problèmes de synchronisation avec ces modifications ? Ainsi, parfois, les problèmes de synchronisation ne se limitent pas aux données.
(3) Certaines variables globales peuvent être définies uniquement pour étendre la portée de l'accès, ou bien qu'il s'agisse de ressources partagées, elles ne sont pas générées simultanément dans des scénarios spécifiques (telles que les variables par tâche, les variables percpu). Par conséquent, pour les problèmes de synchronisation, le partage n'est qu'une des conditions nécessaires, il a une autre condition nécessaire : le fonctionnement simultané. Autrement dit, plusieurs flux d'exécution accèdent à la même ressource partagée en même temps.
Comment comprendre la simultanéité en fonctionnement simultané ? Le même instant sous l'échelle de temps ? Si tel est le cas, alors il n'y a jamais eu de simultanéité réelle. La simultanéité que nous définissons est que lorsque A n'a pas terminé un certain travail, B participe également. Cette situation est considérée comme A et B faisant en même temps ce travail. .
Par exemple, bien qu'il n'y ait pas d'exécution de code dans un environnement monocœur, tous les codes sont exécutés en série, mais des problèmes de synchronisation se produiront toujours, comme i++. En effet, la granularité minimale du langage C n'est pas la granularité minimale d'exécution de l'instruction. Une opération i++ est en fait composée d'instructions de chargement/modification/stockage. Si elle est interrompue une fois l'exécution de l'instruction de chargement terminée, exécutez à nouveau i dans d'autres flux d'exécution, de Du point de vue de l'exécution du langage C, i++ n'a pas été exécuté, ce qui entraîne une sorte de "simultanéité". Et ce concept peut également être étendu aux structures composites.
(4) Plusieurs flux d'exécution fonctionnent sur des données partagées en même temps. Lorsque ce scénario se produit, de nombreux ingénieurs n'hésiteront pas à ajouter un mécanisme de synchronisation pour éviter les problèmes. Je ne sais pas si vous y avez pensé, si vous ne le verrouillez pas, cela causera-t-il définitivement des bogues de programme ? Pour comprendre cela, nous devons savoir quelque chose sur le comportement du CPU pendant l'exécution.
Tout d'abord, il est nécessaire de faire la distinction entre lecture et écriture. Habituellement, le problème dont nous parlons est en fait la lecture d'une valeur inattendue lors de l'exécution d'une opération de lecture, et il y aura des problèmes logiques dans le jugement logique ultérieur ou l'opération d'écriture ultérieure, et ce genre de problème Il est causé par l'écriture simultanée de ressources partagées.
En revanche, si le programme n'est pas synchronisé lors de son exécution, il rencontrera plusieurs types de désordre :
Le compilateur effectuera des opérations d'optimisation sur le programme. Le compilateur supposera que le programme compilé s'exécute dans un environnement de flux d'exécution unique et l'optimisera sur cette base, comme la réorganisation du code et l'utilisation du cache de registre au lieu d'écrire le résultat du calcul. Retour à la mémoire, etc. Naturellement, si vous ne voulez pas que le compilateur fasse cela, vous devez désactiver les éléments d'optimisation agressifs via volatile. Pour le noyau, il utilise généralement l'interface WRITE_ONCE/READ_ONCE, ou essayez une barrière pour empêcher comportement désordonné de segments de code spécifiques.
Afin d'améliorer encore les performances de concurrence, le processeur organise également le code dans le désordre. Habituellement, le processeur s'assure uniquement que les instructions qui ont des dépendances logiques sont exécutées dans l'ordre. Par exemple, si une instruction dépend du résultat d'exécution de l'instruction précédente , il sera exécuté dans l'ordre. Pour les autres instructions qui n'ont pas de dépendances logiques, l'ordre ne peut pas être garanti. Quant à la façon dont l'ordre sera désordonné, cela ne fait aucune hypothèse. Dans un environnement multithread et multicœur, ce désordre causera des problèmes, et il peut passer à travers la barrière du CPU pour interdire ce comportement.
Le modèle de mémoire faiblement ordonné des processeurs modernes est lié à l'architecture du processeur. Dans le modèle de mémoire plus faible, les opérations d'écriture ne seront pas soumises à la mémoire dans l'ordre d'exécution. Après qu'un processeur a fini d'écrire, l'autre processeur n'y accédera pas ensuite La nouvelle valeur doit être accessible immédiatement, et l'ordre dans lequel un autre processeur voit l'écriture n'est pas nécessairement le seul moyen d'interdire ce comportement via une barrière de données ou une barrière mémoire spécifique.
Par conséquent, lorsque nous comprenons les problèmes que le programme causera sans utiliser le mécanisme de synchronisation, nous pouvons analyser en détail des problèmes spécifiques, même s'il s'agit du fonctionnement simultané des mêmes données partagées, comme la situation suivante, même si ce n'est pas verrouillé Des problèmes surviennent :
Lecture seule pour les données partagées
Même s'il y a lecture et écriture simultanées, les bogues ne se produisent pas nécessairement. L'exemple le plus courant est de définir certains nœuds dans le répertoire /proc/. Ce paramètre correspond à une variable globale, et seule cette variable est lue dans le code du noyau. Cette situation n'ajoute pas de mesures de synchronisation (ou n'ajoute que des barrières de compilateur) et ne fait généralement que lire l'ancienne valeur au lecteur dans un très court laps de temps, et ne pose généralement pas de problèmes logiques.
Pour l'écriture simultanée, les verrous ne peuvent pas être ajoutés dans des scénarios d'application spécifiques. Reportez-vous à l'image ci-dessous :
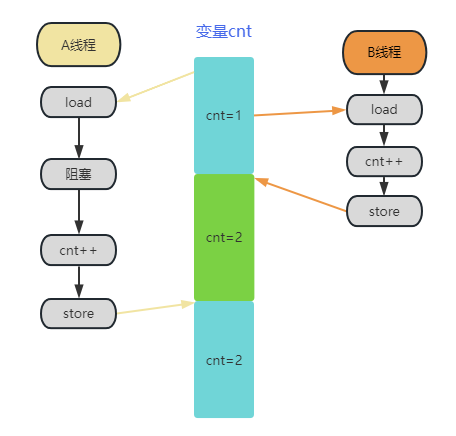
Le thread A et le thread B utilisent la variable cnt en même temps. Bien que A et B exécutent l'opération cnt++, l'opération de B est écrasée et une seule des deux opérations ++ produit finalement un effet. Il semble qu'il doit y avoir être un problème. Cependant, dans le cas des statistiques de paquets de données réseau, la probabilité que cela se produise est très faible. Par rapport à l'énorme perte de performances causée par le verrouillage de tous les chemins, il n'est pas inacceptable d'avoir une légère erreur dans la valeur statistique. Dans ce cas, we Vous ne pouvez ajouter qu'un seul WRITE_ONCE pour limiter l'optimisation du compilateur. Par conséquent, lorsque nous comprenons la perte de performances causée par différentes mesures de synchronisation et les problèmes qu'elles peuvent réellement résoudre, il s'agit davantage de la relation entre performances et précision (il peut également s'agir d'indicateurs tels que le débit et la consommation d'énergie). , plutôt que de se verrouiller involontairement.
1.2 Mécanisme de synchronisation
Lorsqu'il s'agit de problèmes de synchronisation, il est naturellement indissociable de sa solution : le mécanisme de synchronisation Bien sûr, le mécanisme de synchronisation dont nous parlons le plus est le verrou. Puisque les conditions nécessaires à l'apparition de problèmes de synchronisation sont le "partage" et la "simultanéité", il suffit de détruire l'une des conditions pour résoudre le problème de synchronisation.
La solution la plus simple et la plus classique est le spinlock et le mutex. Tant que vous avez été en contact avec linux, vous êtes fondamentalement familier avec ces deux. La logique mise en œuvre par ces deux est d'établir une section critique pour protéger le fonctionnement d'une ressource partagée Un seul visiteur est autorisé à entrer, et lorsque le visiteur sort, le suivant reviendra, détruisant la condition "simultanée" et résolvant le problème de synchronisation.
Spinlock choisira de tourner et d'attendre lorsqu'il ne peut pas acquérir de verrou, et mutex choisira de se mettre en veille lorsqu'il ne pourra pas acquérir de verrou. Ils sont utilisés dans différents scénarios. Pour un système d'exploitation, les deux sont nécessaires. Mais lorsque de nombreux amis regardent les différences entre eux, ils ne remarquent souvent que la différence dans le scénario d'essayer de maintenir le verrou mais échouent, et ignorent la différence après avoir maintenu le verrou :
(1) Le verrou tournant est préempté, mais l'interruption n'est pas nécessairement désactivée. C'est-à-dire que dans la section critique du verrou tournant, il n'y aura pas de planification, mais il peut y avoir une commutation de l'environnement de processus, comme des interruptions et des logiciels. Des scénarios doivent être envisagés.
(2) Le mutex ne peut pas être appliqué dans l'environnement d'interruption, vous n'avez donc pas besoin de considérer la commutation de l'environnement d'exécution du processus, mais le mutex n'est pas lié à la préemption, donc le mutex entraînera également le problème compliqué de nested serrures.
Ces deux problèmes sont incontournables si l'on veut se plonger dans les implémentations de code et même les optimiser. Et si vous utilisez simplement spinlock et mutex comme mesures de synchronisation pour protéger des données globales spécifiques, ces deux problèmes n'ont pas besoin d'être trop pris en compte, et s'il n'y a pas d'autres exigences telles que les performances, il vous suffit de connaître les deux interfaces simples de mutex et spinlock Peut gérer le travail.
Bien sûr, si vous êtes un ami curieux de l'origine des choses, vous pouvez réfléchir profondément au principe d'implémentation du spinlock (mutex), et vous trouverez une contradiction : le rôle du spinlock est de protéger l'exclusion mutuelle des opérations de données en même temps, de sorte qu'un visiteur entre pendant que d'autres attendent, et laisser un visiteur entrer pendant que d'autres attendent nécessite une communication inter-thread.
En d'autres termes, dans l'implémentation de spinlock, le thread en attente doit savoir que le verrou est déjà occupé, et l'occupant doit savoir qu'il a occupé le verrou lorsqu'il essaie de maintenir le verrou.Ils doivent également accéder à une ressource globale pour obtenir ces informations Cela génère-t-il un accès simultané à une ressource partagée ? Alors qui protégera l'implémentation du spinlock lui-même ?
Le logiciel ne peut pas le résoudre, il doit donc être implémenté à l'aide du matériel. Par conséquent, chaque architecture matérielle différente doit implémenter au moins des instructions d'opération atomiques pour les variables à mot unique. Par exemple, sous une plate-forme 64 bits, le matériel doit prendre en charge une classe ou un ensemble d'instructions. Garantir son atomicité lors de l'exécution d'opérations telles que ++ sur une variable de type long.
Avec l'aide de cette opération matérielle atomique, le verrou tournant peut être implémenté de cette manière : ceux qui demandent le verrou en premier peuvent obtenir la propriété d'une variable globale par le biais d'opérations atomiques, puis ceux qui demandent le verrou doivent attendre que le propriétaire précédent libère son propriétaire, c'est-à-dire déverrouiller, et l'une des variables globales mentionnées ci-dessus est une variable de verrouillage.
Par conséquent, on peut voir que le fonctionnement des données globales partagées devient une compétition pour les verrous, et la concurrence pour les verrous est en fait une compétition pour les variables de verrouillage.En substance, la protection des données composites est convergée vers la protection des variables à mot unique . , puis utilisez les instructions atomiques matérielles pour résoudre ce problème.
Par exemple, plusieurs flux d'exécution ont des opérations de lecture et d'écriture sur une instance de structure struct foo. Afin d'éviter les problèmes de synchronisation, ces flux d'exécution passent d'une concurrence pour struct foo à une concurrence pour foo->spinlock, et spinlock est basé sur la variable de verrouillage lock->val implémenté, donc, en fait, tous les flux d'exécution se disputent la variable de verrouillage. Sur cette base, il n'est pas difficile de constater que la réalisation de la serrure n'élimine pas la concurrence, elle réduit simplement la concurrence à une seule variable.
Dans le développement ultérieur, en raison de la nécessité d'équilibrer le délai, le débit, la consommation d'énergie et d'autres facteurs, plus de logique a été progressivement ajoutée au verrou. Par exemple, mutex a d'abord implémenté le mécanisme de mise en file d'attente, puis a introduit une rotation optimiste pour réduire le changement de contexte. , et introduisent le mécanisme de transfert afin de résoudre le problème d'équité apporté par le spin optimiste. Et son cousin rwsem distingue en outre la lecture et l'écriture sur la base du mutex, et la mise en œuvre est plus compliquée.
Comme le dit le proverbe, la médecine est un poison à trois points, et le verrouillage est un médicament puissant pour résoudre les problèmes de synchronisation, mais les problèmes qu'il apporte ne doivent pas être sous-estimés :
Les impasses et la famine sont courantes et provoquent directement le plantage du système.
Les verrous ne font qu'atténuer la concurrence, pas l'éradiquer, donc la concurrence existe toujours, et les frais généraux ne sont toujours pas faibles dans des conditions difficiles.
L'implémentation du verrou devient de plus en plus complexe, et elle consommera également des cycles d'instructions et de l'espace cache, et cette complexité rend l'analyse quantitative de plus en plus difficile.
Des verrous spécifiques ont des problèmes spécifiques. Par exemple, le mécanisme de verrou d'attente entraînera l'inactivité du processeur. Dans certains scénarios hautement concurrentiels, 8 processeurs se disputent le même verrou de verrou d'attente en même temps. En raison de la préemption, ces 8 processeurs ne traitent pas l'interruption, ne peuvent pas plus rien faire, juste un gaspillage inutile de ressources CPU. Le réveil invalide apporté par le mutex et sa propre commutation de processus ont également beaucoup de temps système. Par exemple, dans l'environnement du mutex, lorsque plusieurs processeurs sont en concurrence pour le même verrou, une mauvaise utilisation du verrou ou une conception intempestive entraînera de nombreux réveils invalides. , c'est-à-dire que de nombreux processus ne peuvent pas acquérir de verrous après avoir été réveillés et ne peuvent que dormir à nouveau, et ces frais généraux sont un gaspillage de ressources, ce qui est très coûteux dans un environnement à forte charge.
Ce sont les problèmes de mise en œuvre du verrou lui-même, qui proviennent des contradictions irréconciliables entre performances, équité et débit, et le temps consacré à la concurrence des verrous ne peut produire aucun avantage.
Lorsque la solution elle-même devient le plus gros problème, lorsque le garçon qui tue le dragon est sur le point de devenir le nouveau dragon, nous devons nous tourner pour trouver une solution de synchronisation plus adaptée.
1.3 Autres solutions de synchronisation
Lorsque le schéma de verrouillage général ne peut pas aller plus loin, une autre direction consiste à diviser les scénarios d'utilisation et à trouver des solutions ciblées pour des scénarios spécifiques.
Une idée est de continuer à utiliser la forme de verrouillage, mais de faire la distinction entre lecture et écriture, car la nature de la lecture et de l'écriture est complètement différente.
Dans la description ci-dessus, les rôles qui opèrent sur des ressources partagées sont collectivement appelés visiteurs, mais du point de vue du matériel réel, on constate que la lecture et l'écriture sont fondamentalement différentes dans le fonctionnement des données partagées, et les opérations d'écriture sont généralement amenées Le coupable du problème de synchronisation est que pour le scénario de plus de lecture et moins d'écriture, rwlock et rwsem sont dérivés sur la base de spinlock et mutex (rwsem n'a pas réellement la sémantique de sémaphore, il ressemble plus à la version veille de rwlock ).
L'autre est la conception sans verrouillage, qui est également divisée en plusieurs types. Le premier consiste à ne pas utiliser du tout le mécanisme de synchronisation ou à minimiser l'utilisation du mécanisme de synchronisation, car dans certains scénarios, le la synchronisation des données globales est acceptable. Cela a été démontré ci-dessus.
Une autre solution sans verrouillage plus courante adopte une conception plus détaillée en combinaison avec des scénarios d'application et n'utilise que des opérations atomiques fournies par le matériel sans introduire de logique de verrouillage complexe telle que le spinlock, évitant ainsi de consommer trop de ressources CPU sur les verrous.
En outre, un mécanisme de confirmation secondaire est également couramment utilisé, car certaines opérations de données partagées peuvent entraîner des problèmes de synchronisation. Si la probabilité de conditions concurrentes est suffisamment faible, il n'est parfois pas nécessaire d'utiliser directement des verrous. Nous pouvons Vous pouvez utiliser directement le verrou -opération gratuite, puis vérifiez le résultat de l'opération. Si le résultat ne répond pas à nos attentes, effectuez à nouveau l'opération pour vous assurer que les données sont mises à jour normalement.
Il existe également de nombreuses solutions sans verrou qui visent à "partager" des conditions, telles que l'utilisation de mémoire supplémentaire pour éviter la concurrence. Parmi elles, le mécanisme percpu du noyau est le plus utilisé, bien que la plupart des ingénieurs ne l'utilisent généralement pas. Il est considérée comme une solution de synchronisation, mais elle résout en fait la condition de "partage" causée par le problème de synchronisation, c'est-à-dire que les données globales partagées entre les CPU sont distribuées à chaque CPU, de sorte que bien qu'il y ait toujours le problème de synchronisation entre le processus environnement et l'environnement d'interruption, mais cela réduit considérablement le problème de synchronisation entre plusieurs processeurs et converge de l'environnement multicœur vers l'environnement monocœur.
Dans le même temps, certaines solutions sans verrou sont apparues pour certains scénarios spécifiques. La plus courante est qu'il existe des chemins chauds et froids dans des scénarios spécifiques. La solution sans verrou sous le chemin chaud est réalisée en augmentant la surcharge sous le La définition des chemins chauds et froids dépend entièrement du scénario d'application, de sorte que ces optimisations ne peuvent pas être utilisées comme une solution générale, car leur mise en œuvre est un compromis dans certains cas particuliers.
Et ce dont nous allons parler aujourd'hui, RCU, est également une solution sans verrouillage dans un scénario spécifique.
2. Qu'est-ce que la RCU ?
2.1 Le concept de base de RCU
RCU, lecture-copie-mise à jour, c'est-à-dire lecture-copie-mise à jour, l'idée de base est que lorsque nous devons opérer sur une donnée partagée, nous pouvons d'abord copier une copie de la donnée originale B, et la partie qui doit être être mis à jour Réaliser sur B, puis utiliser B pour remplacer A, qui est également le scénario d'utilisation le plus typique de RCU.
Évidemment, cette solution sans verrouillage vise la fonctionnalité de "partage", après tout, elle n'opère pas directement sur les données cibles.
À partir de ce concept, nous pouvons en fait ressentir très intuitivement la première fonctionnalité de RCU : RCU vise le scénario d'utilisation de plus de lecture et moins d'écriture. Après tout, cette forme d'implémentation augmente évidemment les frais généraux de l'écriture.
Le concept de conception de RCU est si simple que n'importe qui peut le comprendre lorsqu'il l'entend pour la première fois, mais lorsque nous essayons de lire son implémentation de code via son interface de verrouillage/déverrouillage comme spinlock, nous sommes surpris de constater que son verrouillage/déverrouillage interface L'implémentation de déverrouiller n'est qu'un commutateur de préemption. Après avoir confirmé à plusieurs reprises qu'il n'y a pas de problème avec la configuration du noyau, il s'avère que c'est bien le cas, ce qui crée un sentiment très absurde : comment réaliser la lecture-copie-mise à jour uniquement en changeant de préemption ?
2.2 Quel est le problème central de la mise en œuvre de la RCU ?
De nombreux amis intéressés par RCU ont en fait lu de nombreux articles liés à RCU sur Internet, connaissent la forme de fonctionnement de RCU : lire-copier-mettre à jour, et pensent naturellement que c'est une bonne idée, et cela ne semble pas besoin de verrous sont mis en œuvre, car l'opération de mise à jour et le lecteur d'origine lisent des données différentes, qui ne répondent pas aux conditions de partage, puis effectuent le remplacement. De plus, ces trois étapes de fonctionnement peuvent être entièrement complétées par l'utilisateur lui-même, et il est vraiment impossible de penser à un endroit où le système d'exploitation doit intervenir.
Si vous n'arrivez pas à comprendre un problème, réfléchissons-y dans un scénario réel : Supposons qu'il y ait 3 lecteurs et 1 programme de mise à jour qui doivent accéder aux données partagées, et que le lecteur initie des opérations de lecture sur les données en continu, tandis que le programme de mise à jour Lorsque le le lecteur doit mettre à jour, copier de nouvelles données, puis remplacer les anciennes données après l'opération, afin que la mise à jour des données soit terminée et que le lecteur puisse lire les nouvelles données.
Cela semble très raisonnable et efficace, mais le plus gros problème ici est que nous avons mis par défaut une condition préalable qui n'existe pas : le remplacement des nouvelles données prendra effet immédiatement pour tous les lecteurs, et les anciennes données pourront être supprimées immédiatement après le remplacement , et les lecteurs peuvent immédiatement lire les nouvelles données.
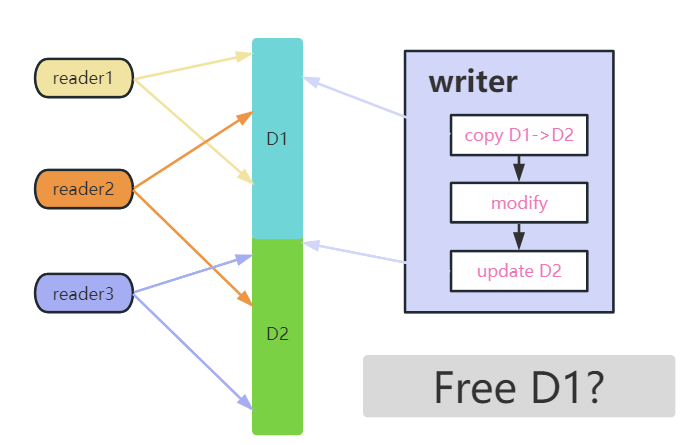
Nous pouvons comprendre ce processus à travers la figure ci-dessus, dans laquelle il y a trois lecteurs, les deux flèches des lecteurs marquent le point de départ et le point final de l'opération de lecture, et celle du milieu indique les données partagées.
Comme on peut le voir sur la figure, l'auteur copie d'abord D2 à partir de D1, puis modifie D2, puis met à jour D2 avec de nouvelles données partagées.Ce processus peut être compris comme une opération de lecture-copie-mise à jour.
Dans l'ensemble du processus, reader1 lit toujours les données de D1, et reader3 lit toujours les nouvelles données de D2, mais reader2 est plus gênant, son opération de lecture s'étend sur le processus de mise à jour de D1 à D2, donc ce qu'il lit est D1 Ou D2, ou lire la moitié des données de D1 et l'autre moitié des données de D2 ?
Selon la méthode traditionnelle de verrouillage de la synchronisation, à ce stade, le rédacteur doit attendre que tous les anciens lecteurs quittent, puis le lecteur attend que le rédacteur ait terminé la mise à jour avant de continuer à lire la section critique. writer doit attendre que reader2 ait fini de lire avant d'effectuer la mise à jour. Avez-vous réalisé que l'écrivain attend que le lecteur quitte, et le lecteur attend que l'écrivain se mette à jour.Cette opération est en fait l'implémentation de rwlock.L'opération RCU est-elle basée sur rwlock ? Alors pourquoi n'utilise-je pas directement rwlock ? De toute évidence, la façon d'implémenter RCU en faisant en sorte que le remplacement prenne effet immédiatement, vous pouvez seulement dire que vous avez créé un nouveau mécanisme de synchronisation, mais il ne sera jamais utilisé par personne.
Ensuite, afin de dépasser les performances de rwlock, d'une part, la synchronisation des verrous entre les lecteurs et les écrivains ne peut pas être effectuée, de sorte que RCU peut avoir des avantages en termes de performances dans des scénarios spécifiques ; d'autre part, si la synchronisation des verrous n'est pas effectuée, il signifie que les lecteurs ne peuvent pas savoir quand l'écrivain est mis à jour, et l'écrivain ne sait pas s'il y a des lecteurs lors de la mise à jour. La seule solution est : même après la mise à jour de l'écrivain, lecteur2 lit toujours les anciennes données de D1 (car lecteur2 ne sait pas que les données ont été mises à jour), Après la mise à jour, les nouveaux lecteurs liront naturellement les nouvelles données.
Dans ce cas, cela signifie que RCU ne peut pas protéger les instances de structures composées comme les verrous ordinaires, mais uniquement pour les pointeurs de données pointant vers des ressources dynamiques. Si vous y réfléchissez un peu plus profondément, vous pouvez constater que si D1 et D2 sont Pour la même structure Par exemple, D2 écrasera les données de D1 et produira un résultat d'erreur indiquant que reader2 lit la moitié de D1 et lit l'autre moitié de D2 après la mise à jour. Et si le lecteur2 doit encore pouvoir lire D1 après la mise à jour, alors D1 et D2 doivent être deux mémoires indépendantes.
Le problème précédent était de savoir comment traiter les lecteurs qui franchissaient le point de mise à jour. Après avoir déterminé que ces lecteurs lisent toujours les anciennes données, le problème restant devient maintenant : juger quand ces lecteurs ont fini de lire les anciennes données, de sorte que les ressources des anciennes les données peuvent être récupérées ?
C'est le problème qu'une implémentation de RCU dans le noyau doit résoudre : comment implémenter à moindre coût l'attente que les lecteurs qui accèdent encore à d'anciennes données quittent ? L'opération de lecture-copie-mise à jour peut être complètement laissée à l'utilisateur.Par conséquent, l'implémentation de RCU dans le noyau n'est pas réellement une opération de lecture-copie-mise à jour, mais un mécanisme permettant d'attendre que le lecteur quitte la section critique.
Dans le même temps, étant donné que RCU attend généralement la sortie de tous les anciens lecteurs, l'opération principale consiste à libérer les anciennes données, de sorte que sa mise en œuvre est également très similaire à un mécanisme de récupération de place.
En combinant les deux points ci-dessus, cela conduit à plusieurs autres fonctionnalités de RCU :
Les lecteurs sont toujours autorisés à lire les anciennes données même après que l'auteur les a mises à jour. L'implémentation RCU du noyau doit garantir que toutes les RCU qui peuvent lire les anciennes données sortent avant de supprimer les anciennes données.
L'objet protégé par le mécanisme de synchronisation RCU ne peut pas être directement une structure composite, seul le pointeur correspondant aux données allouées dynamiquement peut être protégé
La poursuite des performances ultimes du côté lecture est le fondement de RCU dans le noyau.
2.3 Discussion sur la mise en œuvre de la RCU
Si j'ai clairement exprimé la logique implémentée par RCU dans le noyau dans la dernière section, et que vous l'avez comprise, alors la prochaine étape à discuter est : comment implémenter l'attente que les anciens lecteurs quittent la section critique à faible coût. C'est-à-dire qu'à partir de maintenant, nous entrons vraiment dans la mise en œuvre de la RCU.
En attendant la fin d'un événement, la solution la plus couramment utilisée et la plus simple à penser est de le marquer au début, d'entrer dans la salle avec le billet et de rembourser le billet à la sortie de la salle. pour juger si les enregistrements d'entrée et de sortie sont appariés pour déterminer s'il existe toujours. Exiters, bien sûr, cette idée s'est avérée trop inefficace ci-dessus. L'enregistrement du début de la fin de lecture signifie qu'une opération d'écriture globale doit être effectuée, et une fois que la section critique de fin de lecture doit effectuer une opération d'écriture globale, elle sera exécutée simultanément sur plusieurs cœurs Les problèmes de synchronisation ne sont pas faciles à résoudre et la surcharge n'est pas minime. Bien sûr, cette opération d'écriture globale peut être remplacé par le type percpu, afin de réduire certaines pertes de performances, mais cette méthode est toujours une solution temporaire, et notre état idéal Cela signifie qu'il n'y a pas de surcharge de synchronisation côté lecture, c'est-à-dire que l'entrée de la section critique en lecture est pas enregistré.
Une autre idée est, pouvons-nous utiliser d'autres événements pour terminer cette opération d'attente ? C'est-à-dire s'il est possible de juger que les conditions que nous devons attendre ont été remplies à travers certains événements existants, sans qu'il soit nécessaire d'enregistrer directement l'événement.
Dans le noyau, l'implémentation de RCU utilise une manière très ingénieuse : une section critique de lecture est simplement implémentée en désactivant la préemption. Lorsque le lecteur entre dans la section critique, la préemption sera désactivée et la préemption sera activée. lorsque le lecteur quitte la section critique. L'ordonnancement du processus ne se produira que lorsque la préemption est activée. Par conséquent, l'écrivain attend que tous les lecteurs précédents sortent et n'a besoin d'attendre que l'ordonnancement soit exécuté une fois sur tous les processeurs. .
Il est nécessaire d'expliquer davantage ici.Les mots très importants dans le paragraphe précédent sont : tous les lecteurs précédents.
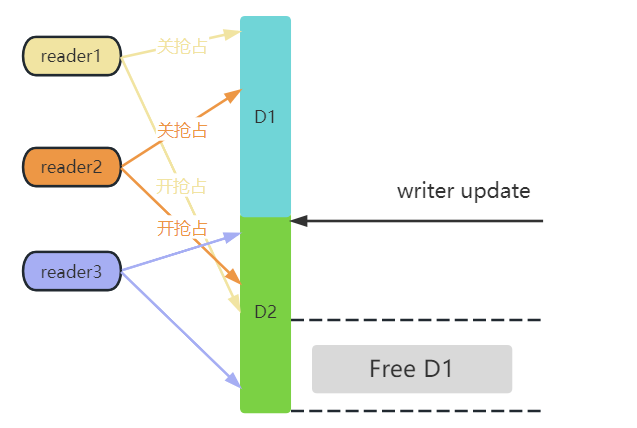
En se référant à la figure ci-dessus, avant que l'écrivain ne soit mis à jour, le lecteur1 et le lecteur2 se réfèrent toujours aux données D1, et le lecteur3 a déjà lu les nouvelles données, il vous suffit donc d'attendre que le lecteur1 et le lecteur2 terminent l'opération de lecture, puis vous peut libérer D1.
Pendant tout le processus de lecture du lecteur 1, il est dans l'état préemptif. Si le lecteur 1 s'exécute sur cpu0, après la mise à jour de l'écrivain, il n'a qu'à juger qu'une fois la planification effectuée sur cpu0, il peut être jugé que le lecteur 1 a quitté la zone critique La prémisse de la planification est que la préemption est activée sur cpu0, ce qui signifie que reader1 a fini de lire.
Une fois que le programme de mise à jour a terminé la mise à jour des données, le processus d'attente pour que tous les lecteurs quittent la section critique est nommé période de grâce (période de grâce), c'est-à-dire qu'une fois la période de grâce passée, cela signifie que le processus de mise à jour des données et de tous la sortie des lecteurs est terminée. À ce stade, les anciennes données peuvent être libérées. S'il s'agit d'une simple opération d'ajout, il n'est naturellement pas nécessaire de supprimer les anciennes données, confirmez simplement que la mise à jour est terminée.
Bien sûr, le processus d'attente pour que tous les lecteurs précédents sortent de la section critique peut être relativement long, voire des dizaines de millisecondes. Par conséquent, cela doit être pris en compte avant de décider d'utiliser RCU comme synchronisation.
Cela conduit à deux autres fonctionnalités de RCU :
La section critique de fin de lecture RCU sous Linux est implémentée en désactivant la préemption, et les performances et l'évolutivité multicœur sont très bonnes, mais il est évident que la section critique de fin de lecture ne prend pas en charge la préemption et la veille.
Le côté écriture a un certain retard. Le lecteur obtiendra des données nouvelles ou anciennes dans un certain laps de temps.
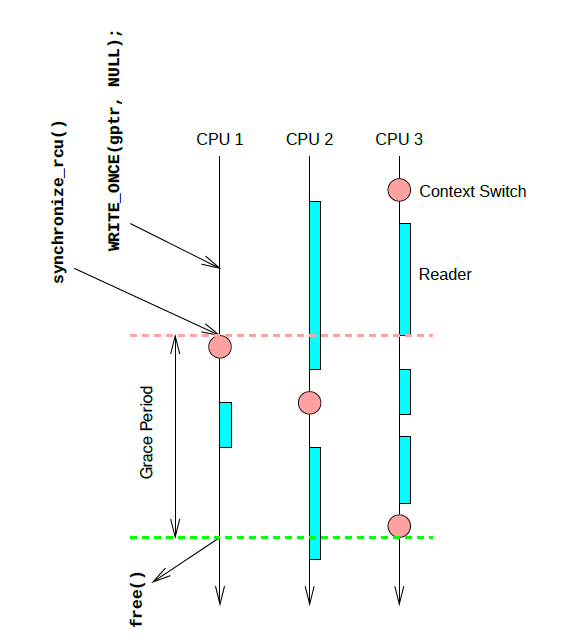
La figure ci-dessus est un exemple simple. Le programme de mise à jour effectue une opération NULL sur gptr sur CPU1, puis appelle synchronize_rcu pour bloquer et attendre que tous les lecteurs précédents quittent la section critique. Après la section critique côté lecture correspondant à la barre, un la planification est exécutée, ce qui signifie également que CPU2 a passé la section critique, et sur CPU3, il a en fait traversé trois étapes d'entrée-sortie de la section critique de lecture, mais comme aucun processus n'est déclenché Commutation, le cœur RCU ne peut pas juger que CPU3 a passé la section critique, jusqu'à ce que finalement CPU3 exécute un ordonnancement, que tout le système ait passé une période de grâce complète, que la tâche bloquée sur CPU1 puisse continuer à s'exécuter, et que la mémoire correspondante soit libérée.
En même temps, résumons les caractéristiques de RCU dans son ensemble :
RCU est destiné aux scénarios d'utilisation avec plus de lectures et moins d'écritures
Le côté écriture a un certain retard. Le lecteur obtiendra des données nouvelles ou anciennes dans un certain laps de temps
Les lecteurs sont toujours autorisés à lire les anciennes données même après que l'auteur les a mises à jour. L'implémentation RCU du noyau doit garantir que tous les lecteurs qui peuvent lire les anciennes données sortent avant de supprimer les anciennes données.
L'objet protégé par le mécanisme de synchronisation RCU ne peut pas être directement une structure composite, seulement un pointeur
RCU poursuit la performance ultime de l'extrémité de lecture, qui est le fondement de RCU dans le noyau
La section critique de fin de lecture RCU classique sous Linux est implémentée par préemption off-on. Les performances et l'évolutivité multicœur sont très bonnes, mais il est évident que la section critique de fin de lecture ne prend pas en charge la préemption et la mise en veille.
3.Conclusion
En fait, il y a encore beaucoup de choses à dire sur le RCU, y compris l'utilisation et la mise en œuvre du RCU, les variantes du RCU, le développement du RCU et l'analyse du code source.L'ensemble du RCU est un très grand système.
Selon mon expérience passée, la longueur de ce type de texte volumineux sans rien d'intéressant ne devrait pas être trop longue. Si vous êtes vraiment intéressé par RCU, la prochaine fois, nous aborderons ensemble l'utilisation et la mise en œuvre de RCU.
les références
1.https://www.kernel.org/doc/Documentation/RCU/Design/Data-Structures/Data-Structures.html
2.https://www.kernel.org/doc/Documentation/RCU/Design/Requirements/Requirements.rst
3.https://lwn.net/Articles/305782/

Appuyez longuement pour suivre Kernel Craftsman WeChat
Technologie Linux Kernel Black | Articles techniques | Tutoriels en vedette