предисловие
Новый курс по квантованию модели TensorRT, запущенный Handwriting AI, ссылка: Квантование модели под TensorRT .
Схема курса следующая:

1. Определение и значение количественного определения
1.1 Что такое количественная оценка?
определение
Квантование относится к процессу представления высокоточных чисел с плавающей запятой (например, float32) в виде целых чисел низкой точности (например, int8), тем самым повышая эффективность и производительность нейронных сетей. В частности, квантование предназначено для преобразования нашей обученной модели, будь то весовая или расчетная операция, в расчет с низкой точностью. На самом деле квантование, о котором мы говорим, больше похоже на квантование INT8.
Общие методы количественной оценки
Обычно используемые методы квантования включают симметричное квантование и асимметричное квантование:
- Симметричное квантование заключается в равномерном распределении диапазона весов как в положительном, так и в отрицательном направлениях и отображении чисел с плавающей запятой в диапазон положительных и отрицательных целых чисел;
- Асимметричное квантование относится к квантованию каждого канала с использованием масштабного коэффициента и нулевой точки.
Следует отметить, что квантование модели будет иметь определенное влияние на точность и правильность модели, поскольку квантованная модель может не полностью сохранить всю информацию и признаки исходной модели. Следовательно, при выполнении квантования модели необходимо сделать соответствующие компромиссы и оптимизации.
Модели, которые мы обычно обучаем, такие как YOLOv5, экспортируются нормально, и по умолчанию используется точность FP32. Перед квантованием параметры веса и смещения сетевой модели представлены высокоточными числами с плавающей запятой FP32, а вычисление чисел с плавающей запятой потребует большого объема памяти и вычислительных ресурсов.
Теперь давайте посмотрим на входные данные, вес, смещение и тип выходных данных модели ONNX, экспортируемой ResNet 18. Код для экспорта ResNet18 в ONNX выглядит следующим образом:
import torch
import torchvision.models as models
model = models.resnet18(pretrained = False) # 懒得下载预训练权重,这里只是用于测试一下而已
input = torch.randn(1,3,224,224)
torch.onnx.export(model,input,"resnet18.onnx")
Используйте netron для просмотра модели onnx. При просмотре сетевого уровня вход, вес и смещение оказываются типами данных FP32. На следующем рисунке показаны тип ввода и вес в первом ядре свертки:
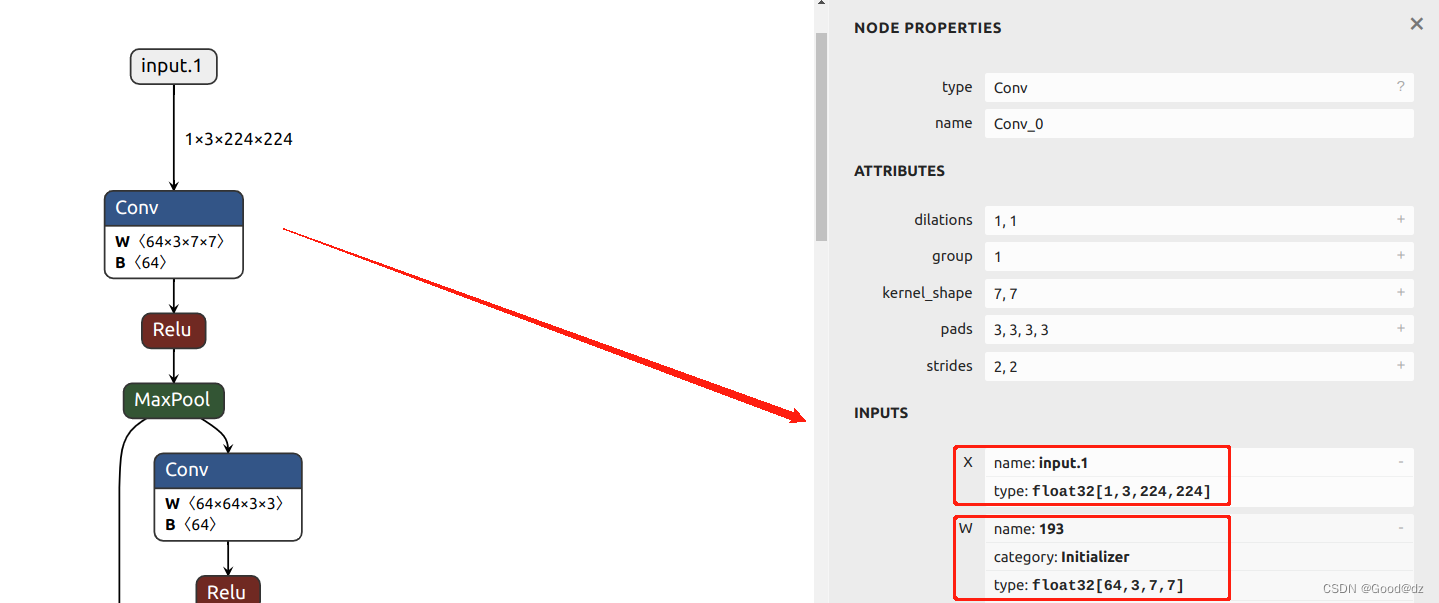
1.2 Зачем проводить количественную оценку
Проблемы, не поддающиеся количественной оценке
Модели, которые мы обычно обучаем, такие как YOLOv5, обычно экспортируются, а по умолчанию используется точность FP32.В процессе глубокого обучения и рассуждений наиболее часто используемой точностью является FP32. Перед квантованием параметры веса и смещения сетевой модели представлены высокоточными числами с плавающей запятой FP32, а вычисление чисел с плавающей запятой потребует большого объема памяти и вычислительных ресурсов.
Количественные преимущества:
- Чтобы ускорить рассуждения, один доступ к 32-битному типу с плавающей запятой может получить доступ к четырем целочисленным типам int8, а операции с целыми числами выполняются быстрее, чем операции с плавающей запятой;
- Уменьшите пространство для хранения, что более важно, когда места для хранения на периферийной стороне недостаточно;
- Уменьшенный объем памяти, меньшие размеры моделей означают отсутствие необходимости в дополнительной памяти;
- Снижение энергопотребления устройства, меньшее потребление памяти, более высокая скорость вывода, что естественным образом снижает энергопотребление устройства.
Недостатки после количественной оценки:
- Квантование модели увеличивает операционную сложность, и во время квантования необходимо выполнить некоторую специальную обработку, иначе потеря точности будет более серьезной.
Различные типы различий:
- FP32 — это число одинарной точности с плавающей запятой, представленное 32-битным двоичным числом, в котором 1 бит — это бит знака, 8 бит — бит экспоненты, а 23 бита — бит мантиссы;
- FP16 — это число с плавающей запятой половинной точности, представленное 16-разрядным двоичным числом, в котором 1 бит — знаковый бит, 5 бит — бит экспоненты, а 10 бит — бит мантиссы;
- INT8 — это 8-битное целое число, представленное 8-битным двоичным числом, из которых 1 бит является битом знака, а 7 бит — битом значения.
Для чисел с плавающей запятой биты экспоненты представляют достижимый динамический диапазон для этой точности, а биты мантиссы представляют точность.
From FP32=>FP16 является своего рода квантованием, но поскольку FP32=>FP16 почти без потерь (используйте __float2half в CUDA для прямого преобразования), калибратор не нуждается в исправлении, не говоря уже о переобучении. И падение точности FP16 не сильно скажется на большинстве задач, и даже некоторые задачи будут улучшены.
1.3 Как измерить?
случай
Как описать массив с плавающей запятой [-0,61, -0,52, 1,62] в виде int? Возьмем в качестве примера симметричное квантование.
- Вычислить общий масштаб в массиве
Scale = (float_max - float_min) / (quant_max - quant_min)
= (1.62-(-0.61)) / (127 - (-128)) = 0.0087109
- операция квантования
0.61 / 0.0087109 = -70.0272072
-0.52 / 0.0087109 = -59.6953242 ==> [-70,-59,185] 取整
1.62 / 0.0087109 = 185.9738947
- операция усечения
[-70,-59,185] ==> [-70,-59,127]
# 因为对称量化的范围在-127到127,185已经超过范围了,所以要进行截断操作
- Операция обратного квантования
量化前:[-0.61,-0.52,1.62]
量化后:[-0.609763,-0.5139431,1.1062843]
Видно, что окончательное обратное квантование усеченного значения сильно отличается от исходного значения (1,62 и 1,1062843).
2. Подробное объяснение параметров -export
torch.onnx.export() — это функция для экспорта модели PyTorch в формат ONNX. Его параметры следующие:
- модель: модель PyTorch, которую необходимо экспортировать в формат ONNX.
- args: входные параметры модели, которые могут быть тензором или кортежем, содержащим несколько тензоров.
- f: сохранить путь или файловый объект экспортированной модели ONNX.
- export_params: следует ли экспортировать параметры модели, по умолчанию установлено значение True.
- verbose: следует ли печатать информацию о процессе экспорта, по умолчанию — False.
- do_constant_folding: выполнять ли постоянную оптимизацию свертывания, по умолчанию — True.
- input_names: имена входных узлов модели, по умолчанию ["input"]
- output_names: имена выходных узлов модели, по умолчанию ["output"]
- dynamic_axes: динамические размеры
- opset_version: экспортированный номер версии ONNX, по умолчанию 9
- keep_initializers_as_inputs: сохранять ли инициализаторы в качестве входных узлов, по умолчанию — False.
- operator_export_type: тип экспортируемого оператора, по умолчанию — torch.onnx.OperatorExportTypes.ONNX.
Ссылка на ссылку: