1. Introduction
-
Utiliser le CPU pour exécuter la version C++ de RWKV
-
rwkv.cpp peut convertir les paramètres du modèle original RWKV en float16 et quantifier en int4 , ce qui peut fonctionner plus rapidement sur le CPU et économiser plus de mémoire.
2. Télécharger le projet
## git clone --recursive https://github.com/saharNooby/rwkv.cpp.git
cd rwkv.cpp
3. Téléchargez les dépendances ou compilez vous-même
-
Utilisez CPU-Z pour vérifier si votre CPU prend en charge AVX2 ou AVX-512. Si c'est le cas, vous pouvez télécharger directement la bibliothèque de dépendances compilée par l'auteur
-

-
Je prends en charge le jeu d'instructions AVX ici, donc j'utilise directement la bibliothèque dépendante compilée par l'auteur
-
Versions ouvertes · saharNooby/rwkv.cpp · GitHub
-
Les développeurs de rwkv.cpp ont des bibliothèques dépendantes pré-compilées sur différentes plates-formes, qui peuvent être téléchargées ici
-
Télécharger rwkv-master-a3178b2-bin-win-avx-x64.zip
-

-
Après la décompression est un fichier dll, placez-le dans le répertoire racine
-
S'il n'y a pas de bibliothèque dépendante adaptée à votre plate-forme ci-dessus, vous devez la compiler vous-même
compiler
cmake .
cmake --build . --config Release
4. Préparez le modèle
- Lors du téléchargement du poids du projet, il existe deux options, l'une consiste à télécharger le modèle bin que l'auteur a quantifié, l'autre consiste à télécharger le modèle pat, puis à le quantifier manuellement vous-même
- BlinkDL (BlinkDL)
4.1. Paramètres pour le nom du modèle
- Le préfixe unifié rwkv-4 indique qu'ils sont tous basés sur l'architecture de 4ème génération de RWKV.
- Pile représente le modèle de base, qui est pré-formé sur la pile et d'autres corpus de base sans réglage fin, et peut être personnalisé par Gaowan.
- roman représente le modèle du roman, affiné sur des romans en différentes langues, adapté à l'écriture de romans.
- corbeau signifie modèle de dialogue, qui est affiné sur divers matériaux de dialogue open source, adapté au chat, aux questions et réponses et à l'écriture de code.
- 430m, 7b Il s'agit des grandeurs paramétriques du modèle.

- je l'ai téléchargé ici
Q8_0-RWKV-4-Raven-7B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230430-ctx8192.bin
Les poids peuvent être utilisés directement après le téléchargement sans conversion ni quantification. Si vous souhaitez quantifier manuellement, vous pouvez continuer à voir les étapes suivantes
- Q8_0-RWKV-4-Raven-7B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230430-ctx8192.bin BlinkDL/rwkv-4-raven au niveau principal
- Le fichier est relativement volumineux, si la vitesse du réseau est lente, vous devez attendre un moment
4.2. Modèle de conversion
- Dans des circonstances normales, ce modèle peut s'exécuter après avoir téléchargé le code dans l'entrepôt ChatRWKV, mais son support CPU n'est que FP32i8, et le modèle 7B a besoin de 12 Go de mémoire pour fonctionner. Par conséquent, le rwkv.cpp que nous utilisons peut convertir RWKV Les paramètres du modèle d'origine sont convertis en float16 et quantifiés en int4, ce qui peut fonctionner plus rapidement sur le processeur et économiser plus de mémoire
- Placez le modèle PyTorch téléchargé dans le chemin de rwkv.cpp et exécutez la commande suivante
### python rwkv/convert_pytorch_to_ggml.py RWKV-4-Raven-7B-v7-EngAndMore-20230404-ctx4096.pth ./rwkv.cpp-7B.bin float16
- La commande de ce code est de laisser Python exécuter le code de ce modèle de conversion rwkv/convert_pytorch_to_ggml.py,
- RWKV-4-Raven-7B-v7-EngAndMore-20230404-ctx4096.pth est le poids à convertir, selon le fichier que vous avez téléchargé, modifiez-le de manière appropriée
- rwkv.cpp-7B.bin est le chemin du modèle converti et float16 fait référence à la conversion du modèle en type float16


- Le modèle généré, par rapport au modèle d'origine, n'a pas changé de taille

4.3 Modèle de quantification
- Le modèle rwkv.cpp-7B.bin après la conversion ci-dessus est en fait prêt à être utilisé, mais il prend encore beaucoup de mémoire vidéo, environ 16 Go de mémoire.Afin de réduire davantage l'utilisation de la mémoire et d'accélérer la vitesse de raisonnement de le modèle, vous pouvez utiliser Ce modèle est quantifié en int4, ce qui peut économiser la moitié de la mémoire
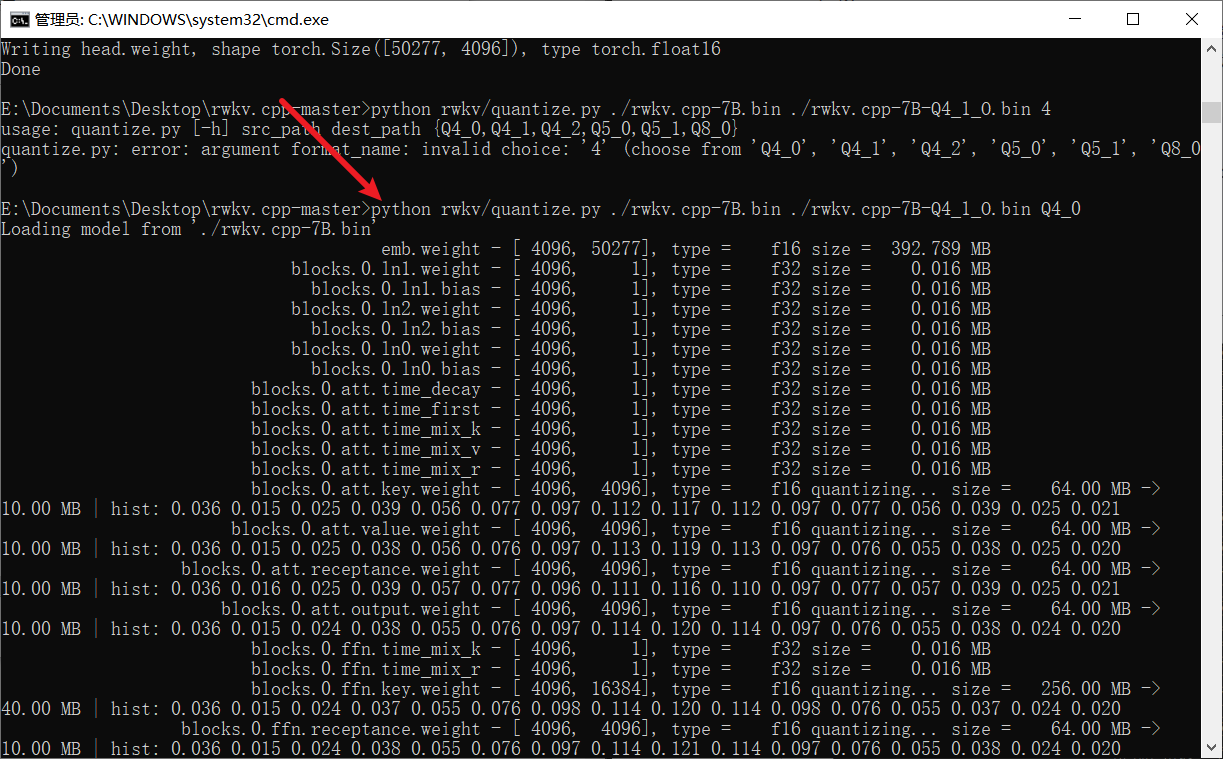
### python rwkv/quantize.py ./rwkv.cpp-7B.bin ./rwkv.cpp-7B-Q4_1_O.bin Q4_0
- Comme indiqué ci-dessous, les paramètres facultatifs ici sont Q4_0, Q4_1, Q4_2, Q5_0, Q5_1, Q8_0, vous pouvez choisir en fonction de votre situation réelle


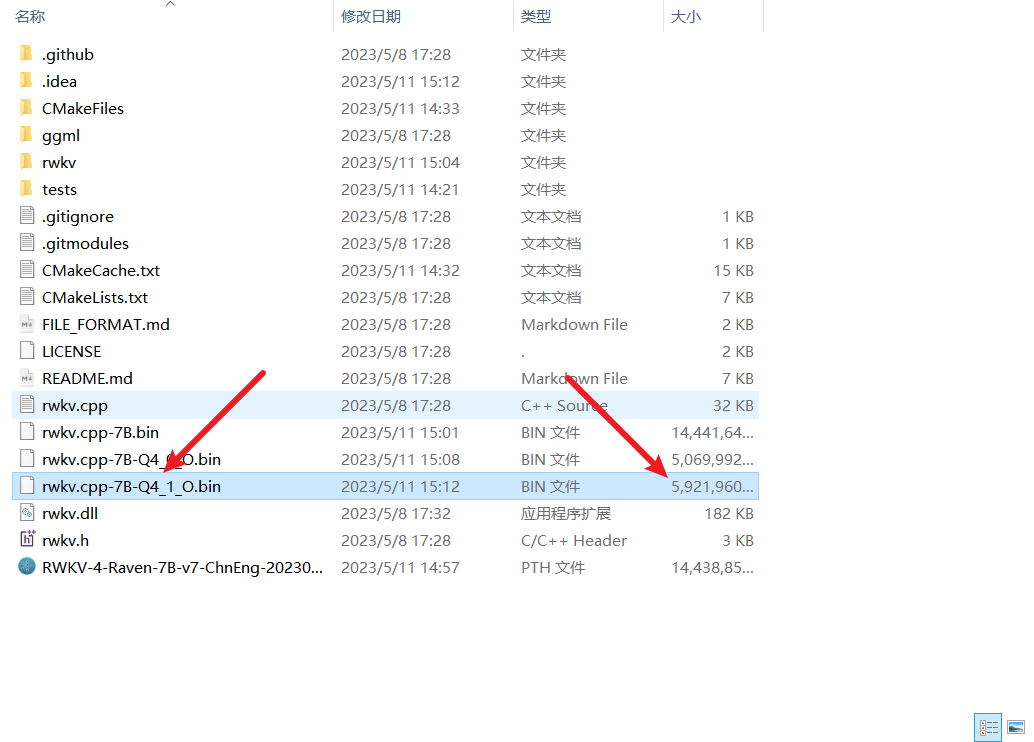
- On peut voir que le modèle quantifié n'a que 6 G de taille
5. Exécutez le modèle
- Après la conversion et la quantification précédentes, il est très simple d'exécuter le modèle et une seule ligne de commandes est nécessaire.
- Si vous souhaitez générer le modèle, utilisez le suivant pour exécuter
### python rwkv\generate_completions.py rwkv.cpp-7B-Q4_1_O.bin
### python rwkv/chat_with_bot.py rwkv.cpp-7B-Q4_1_O.bin
- Il faut beaucoup de temps pour démarrer, veuillez patienter un moment

Après le démarrage, testez

6. Effet d'essai
- Je ne sais pas pourquoi, il a répondu qu'il est ChatGPT formé par OpenAI

- La longueur du texte généré est tout à fait acceptable. Dites-lui de continuer pendant le dialogue, et il pourra continuer à le générer

et peut également être programmé
-

-
Mais lors de l'écriture du code, il y a toujours un problème que la longueur de sortie est trop courte
-
[Transfert d'image de lien externe...(img-zVNWyhth-1683796408249)]
et peut également être programmé
- [Transfert image lien externe...(img-KiL0hZzE-1683796408250)]
- Mais lors de l'écriture du code, il y a toujours un problème que la longueur de sortie est trop courte