Déployer ChatGLM2-6B en tant que service d'API OpenAI
0. Contexte
Récemment, j'ai utilisé l'API d'OpenAI pour apprendre et faire des recherches. En utilisant l'API d'OpenAI, l'un entraînera des coûts, l'autre consistera à résoudre les problèmes de réseau et le troisième consistera à avoir diverses limites de vitesse d'accès.
Essayez donc d'utiliser le grand modèle de langage open source pour créer un service d'API OpenAI local.
La technologie open source utilisée cette fois est FastChat.
1. Déploiement de FastChat à l'aide de ChatGLM2-6B
1-1. Créer un environnement virtuel
conda create -n fastchat python==3.10.6 -y
conda activate fastchat
1-2. Cloner le code
git clone https://github.com/lm-sys/FastChat.git; cd FastChat
pip install --upgrade pip # enable PEP 660 support
1-3. Installer les bibliothèques dépendantes
pip install -e .
pip install transformers_stream_generator
pip install cpm_kernels
1-4. Inférence à l'aide de l'interface utilisateur
démarrer le contrôleur,
python3 -m fastchat.serve.controller
Démarrez le(s) travailleur(s) modèle(s),
python3 -m fastchat.serve.model_worker --model-path THUDM/chatglm2-6b
Après avoir démarré le(s) travailleur(s) modèle(s), démarrez le serveur Web Gradio,
python3 -m fastchat.serve.gradio_web_server
Posez-lui quelques questions, les captures d'écran des questions et réponses sont les suivantes,
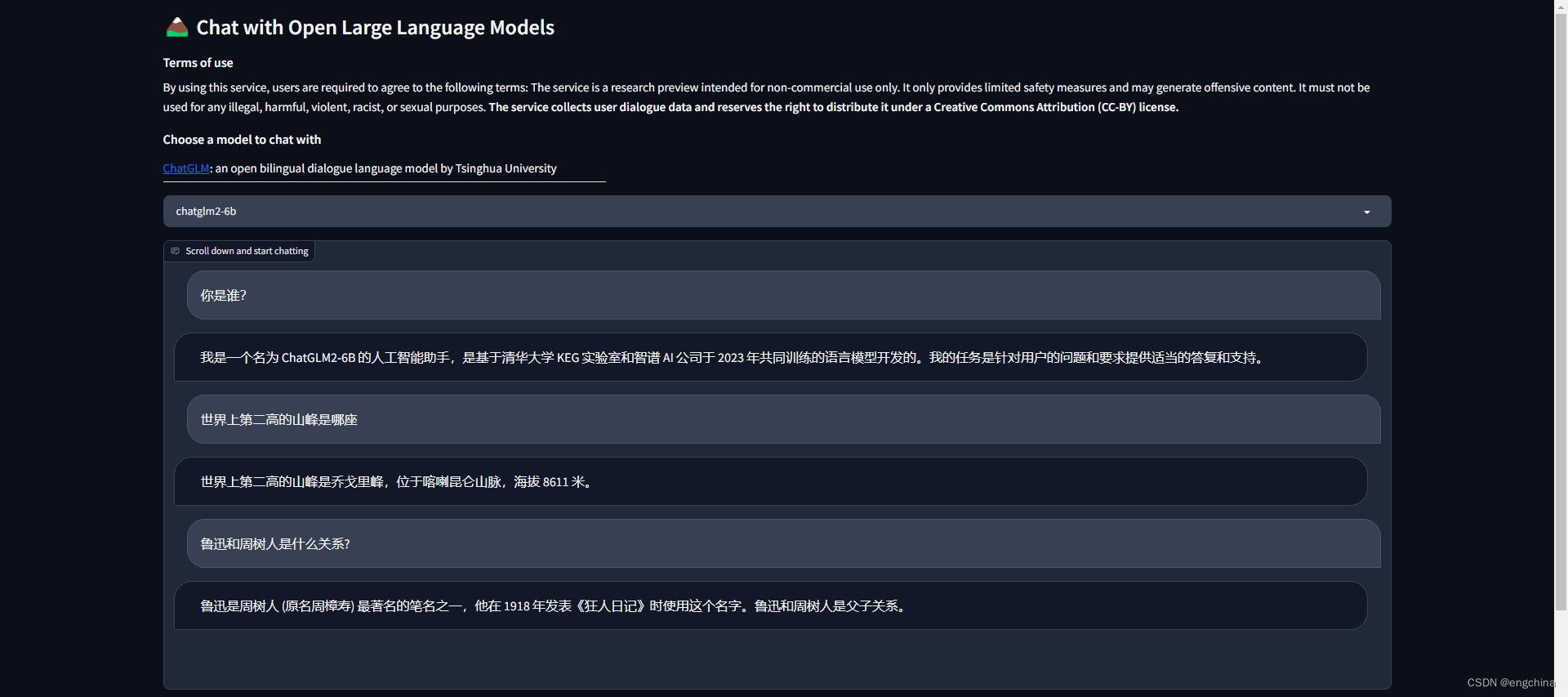
1-5. Inférence à l'aide de l'API OpenAI
démarrer le contrôleur,
python3 -m fastchat.serve.controller
Démarrez le(s) travailleur(s) modèle(s),
python3 -m fastchat.serve.model_worker --model-names "gpt-3.5-turbo,text-davinci-003,text-embedding-ada-002" --model-path THUDM/chatglm2-6b
Démarrez le serveur d'API RESTful,
python3 -m fastchat.serve.openai_api_server --host localhost --port 8000
Définir l'URL de base OpenAI,
export OPENAI_API_BASE=http://localhost:8000/v1
Définir la clé API OpenAI,
export OPENAI_API_KEY=EMPTY
Posez-lui quelques questions, les captures d'écran de code et de réponse sont les suivantes,
import os
import openai
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
os.environ['OPENAI_API_KEY'] = 'EMPTY'
os.environ['OPENAI_API_BASE'] = 'http://localhost:8000/v1'
openai.api_key = 'none'
openai.api_base = 'http://localhost:8000/v1'
def get_completion(prompt, model="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0,
)
return response.choices[0].message["content"]
get_completion("你是谁?")

get_completion("世界上第二高的山峰是哪座")

get_completion("鲁迅和周树人是什么关系?")

(Facultatif) Si vous obtenez une erreur OOM lors de la création de l'intégration, utilisez la variable d'environnement pour définir un BATCH_SIZE plus petit,
export FASTCHAT_WORKER_API_EMBEDDING_BATCH_SIZE=1
(Facultatif) Si vous rencontrez une erreur de délai d'attente,
export FASTCHAT_WORKER_API_TIMEOUT=1200
refer1 : https://github.com/lm-sys/FastChat/blob/main/docs/langchain_integration.md
refer2 : https://github.com/lm-sys/FastChat
fin!