Demander une bibliothèque de demandes
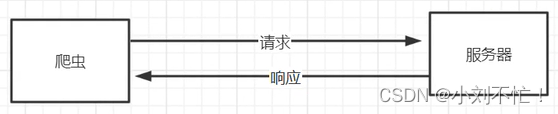
Comment fonctionnent les robots d'exploration
Tout d'abord, revoyez le principe de base du fonctionnement du crawler (ce qui suit est un langage écrit plus formel) :
un crawler est un programme automatisé utilisé pour obtenir des informations sur Internet,
- Lancer une requête : le robot d'exploration doit d'abord lancer une requête HTTP pour demander le contenu de la page au site Web cible. Cette requête peut contenir des paramètres spécifiques, des en-têtes, une authentification, etc.
- Recevoir une réponse : après avoir reçu la demande, le site Web cible renverra une réponse HTTP. La réponse contient le contenu de la page et d'autres informations pertinentes, telles que le code d'état, les informations d'en-tête, etc.
- Analyse de la page : après avoir reçu la réponse, le robot d'exploration doit analyser la page pour extraire les données requises. Les méthodes d'analyse couramment utilisées incluent les expressions régulières, XPath, les sélecteurs CSS, etc.
- Extraire les données : en analysant la page, le robot d'exploration peut extraire les données requises. Ces données peuvent être des informations sous diverses formes telles que du texte, des images et des liens.
- Stocker les données : le robot d'exploration stocke les données extraites dans des fichiers locaux ou des bases de données pour un traitement et une analyse ultérieurs.
- Traiter la page suivante : après avoir exploré les données d'une seule page, le robot d'exploration peut avoir besoin de traiter les données de la page suivante. Cela implique généralement une opération de tournage de page, et le contenu de la page suivante peut être obtenu en simulant des clics d'utilisateurs ou en modifiant des paramètres d'URL.
- Répéter l'opération : le robot d'exploration peut effectuer les étapes ci-dessus en boucle selon les besoins pour obtenir plus de données ou d'informations sur différentes pages.
Mais pour nous, ce que nous voyons, ce sont presque toutes les interfaces graphiques, mais le crawler peut renvoyer les paramètres correspondant à la page. Cette partie est représentée par du code, que nous ne pouvons pas voir en surface, comme le code d'état, la page portant des cookies, etc. . Le crawler simule le processus de nos utilisateurs visitant des pages Web.
Bibliothèque de requêtes de requêtes
Pour accéder à la page Web, nous avons également besoin de l'outil correspondant - Bibliothèque de requêtes Requests.
La bibliothèque de requêtes Requests est une bibliothèque de requêtes HTTP, à travers laquelle nous pouvons lancer une requête sur le site Web.
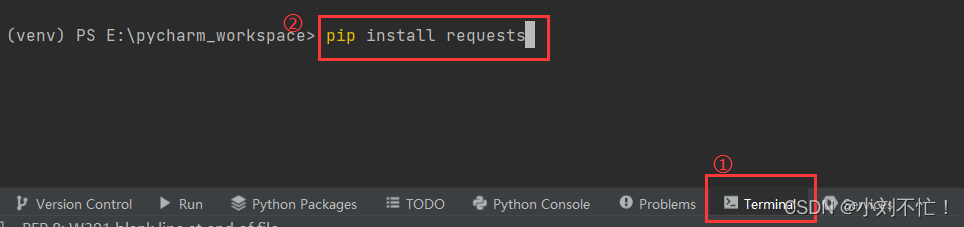
Environnement d'installation
Installez la bibliothèque dans Pycharm. Si l'installation échoue, vous pouvez trouver une source miroir domestique, de sorte que l'installation sera plus fluide.
Utilisation de la bibliothèque Requests
Ouvrez pycharm, créez un nouveau fichier, puis entrez les requêtes d'importation pour voir s'il y a une erreur :

Ensuite, comprenez la syntaxe simple des requêtes :
En Python, requestsest une bibliothèque tierce populaire pour l'envoi de requêtes HTTP. Il fournit une interface simple et conviviale qui facilite l'envoi de requêtes HTTP. Voici requestsquelques utilisations et syntaxes courantes de la bibliothèque :
- Envoyez une requête GET :
import requests
response = requests.get(url)
où urlest l'URL cible à laquelle vous souhaitez envoyer la requête. requests.get()La méthode enverra une requête GET à l'URL spécifiée et renverra un Responseobjet.
- Envoyez une requête GET avec les paramètres :
import requests
payload = {
'key1': 'value1', 'key2': 'value2'}
response = requests.get(url, params=payload)
Dans l'exemple ci-dessus, payloadest un dictionnaire contenant les paramètres. requests.get()Les paramsparamètres de la méthode permettent d'ajouter ces paramètres à l'URL demandée.
Étant donné que le contenu de la requête GET peut être vu dans le lien, par exemple, la charge utile ici fait référence à :

- Envoyez une requête POST :
import requests
payload = {
'key1': 'value1', 'key2': 'value2'}
response = requests.post(url, data=payload)
Dans cet exemple, payloadun dictionnaire contenant les données à envoyer. requests.post()La méthode enverra une requête POST à l'URL spécifiée et l'utilisera payloadcomme données demandées. Ceci est différent de la requête GET, ces paramètres ne sont pas visibles dans le lien ouvert.
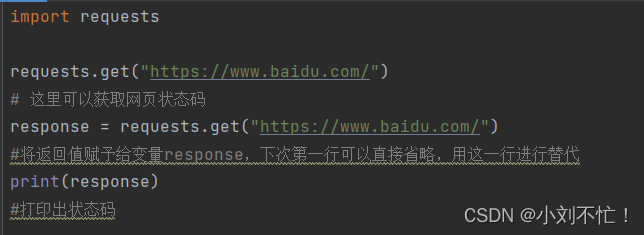
- Gérer la réponse :
import requests
response = requests.get(url)
print(response.status_code) # 打印状态码
print(response.text) # 打印响应内容
response.status_codeIl s'agit du code d'état de la réponse, qui est utilisé pour déterminer si la requête aboutit. response.textest le contenu de la réponse, qui peut être utilisé pour obtenir les données renvoyées par le serveur.
code d'état
Prenons Baidu comme exemple :

voici l'URL à visiter.
Le résultat de l'utilisation de print(response.status_code) ici est cohérent avec print(response).
Vérifiez le résultat du retour :

le code de retour est 200, ce qui signifie que nous pouvons accéder normalement.
contenu Web
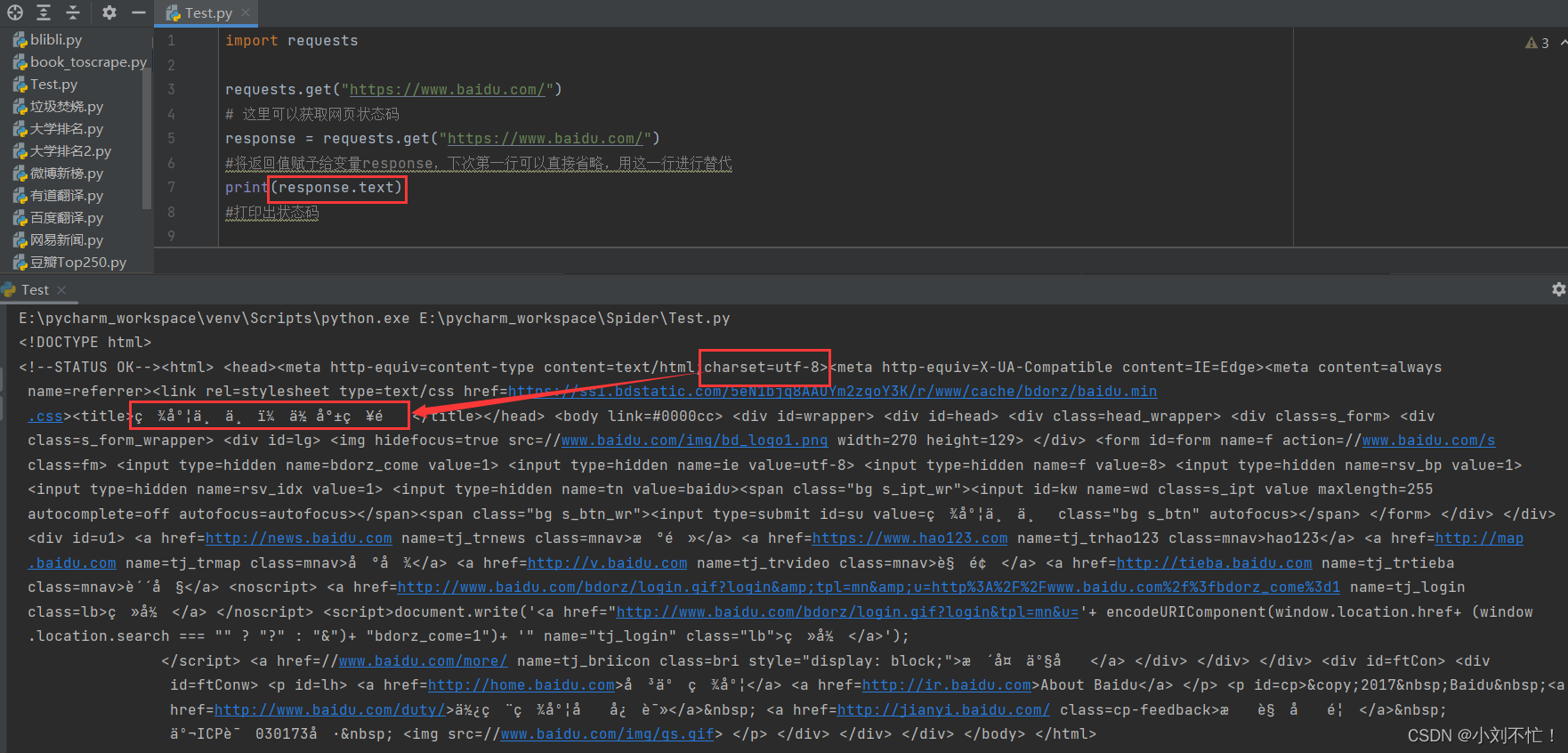
Ensuite, récupérez le contenu de la page Web, ou prenez Baidu comme exemple :
ici, utilisez response.text pour sortir, vous pouvez voir que le contenu de la page est sorti, mais certains d'entre eux sont brouillés. Il peut être trouvé à partir du code que l'encodage d'origine de la page Web est utf-8, nous le gardons donc cohérent avec l'encodage d'origine de la page Web et le changeons en utf-8.
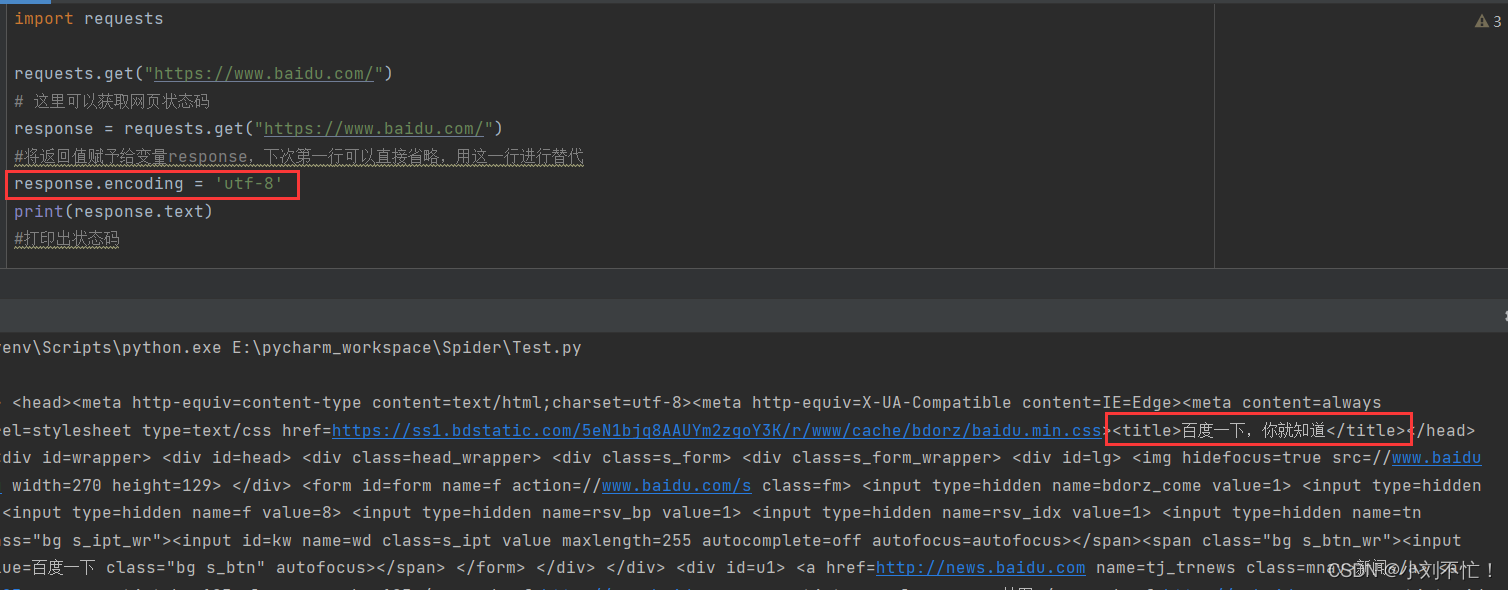
A ce moment, le contenu de la page peut être affiché normalement.